深度学习入门:神经网络是如何“学习“的?
目录:在上一篇文章中,咱们聊了机器学习的基础概念。但是!当你在用ChatGPT对话、让Midjourney画图、看特斯拉自动驾驶时,这些背后用的不是普通的机器学习,而是深度学习。深度学习是什么?它和普通机器学习有什么区别?神经网络是怎么"学习"的?今天咱们就用大白话,把这个看起来最深奥的技术讲清楚!先来看几个传统机器学习遇到困难的场景。传统机器学习的方式:特征太难设计了!传统机器学习的方式:问题:
目录:
-
前言 -
背景引入:为什么需要深度学习? -
核心概念一:什么是神经网络 -
核心概念二:神经网络的基本单元——神经元 -
核心概念三:前向传播——信息如何流动 -
核心概念四:反向传播——如何"学习" -
核心概念五:损失函数——如何衡量好坏 -
核心概念六:梯度下降——如何找到最优解 -
核心概念七:深度学习的"深度"在哪里 -
常见的神经网络架构 -
深度学习的实际应用 -
深度学习的挑战和局限 -
本文小结 -
今日思考题
一、前言
在上一篇文章中,咱们聊了机器学习的基础概念。
但是!当你在用ChatGPT对话、让Midjourney画图、看特斯拉自动驾驶时,这些背后用的不是普通的机器学习,而是深度学习。
深度学习是什么?它和普通机器学习有什么区别?神经网络是怎么"学习"的?
今天咱们就用大白话,把这个看起来最深奥的技术讲清楚!
二、背景引入:为什么需要深度学习?
先来看几个传统机器学习遇到困难的场景。
场景一:识别图片中的猫
传统机器学习的方式:
问题:判断图片里是不是猫
传统思路:
1. 手工设计特征
- 耳朵形状?尖的
- 眼睛形状?圆的
- 有胡须?有
- 毛色?橙色
...
2. 用这些特征训练分类器
问题来了:
- 猫的姿势千变万化怎么办?
- 光线不同怎么办?
- 背景复杂怎么办?
- 不同品种的猫怎么办?
特征太难设计了!
场景二:理解人类语言
传统机器学习的方式:
问题:理解这句话的意思
"我今天不想上班"
传统思路:
1. 分词
我/今天/不想/上班
2. 分析语法结构
主语:我
时间:今天
否定:不想
动作:上班
3. 匹配规则
if (不想 + 上班) {
return "情绪低落";
}
问题:
-
同一个意思有无数种说法 -
"今天好累啊"、"周一综合症"、"想躺平" -
语境、语气、双关语怎么处理?
规则太多,根本写不完!
场景三:下围棋
传统机器学习的方式:
问题:围棋下一步该走哪?
传统思路:
1. 评估当前局面
2. 搜索可能的走法
3. 计算每种走法的得分
问题:
- 围棋的可能局面比宇宙原子还多
- 根本无法穷举
- 人类棋手的"直觉"怎么量化?
计算量太大,传统方法不行!
传统机器学习的困境
| 问题类型 | 传统机器学习的困难 |
|---|---|
| 图像识别 | 需要手工设计特征,太复杂 |
| 语音识别 | 声音信号变化太多 |
| 自然语言 | 语言太复杂、太灵活 |
| 复杂决策 | 状态空间太大 |
深度学习的思路:让计算机自己学特征!
三、核心概念一:什么是神经网络
3.1 神经网络的定义
神经网络 = 模仿人脑的算法
听起来很高深?咱们用个类比:
人脑的工作方式:
- 神经元接收信号
- 神经元之间连接
- 通过连接传递信号
- 通过学习调整连接强度
人工神经网络:
- 节点模拟神经元
- 权重模拟连接强度
- 通过训练调整权重
3.2 为什么叫"神经网络"?
因为模仿了人脑的结构
生物神经元:
树突
↓
[细胞体] ← 轴突
↓
突触
(连接到其他神经元)
人工神经元:
输入1 ──→
输入2 ──→ [神经元] ──→ 输出
输入3 ──→
↑
权重(连接强度)
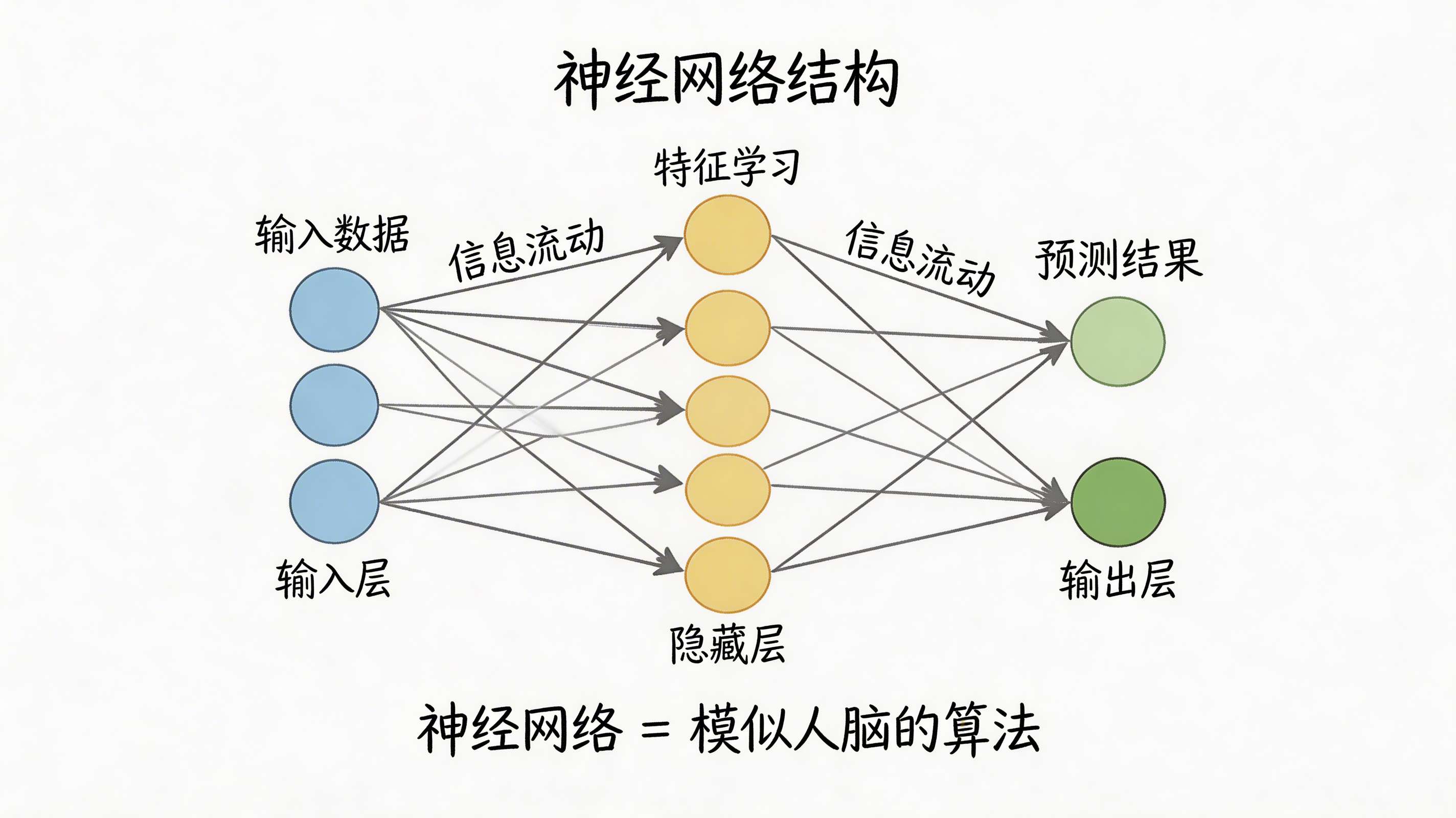
3.3 神经网络的结构
分层结构:输入层 → 隐藏层 → 输出层
┌─────────────────────────────────────────┐
│ 神经网络结构 │
└─────────────────────────────────────────┘
输入层 隐藏层 输出层
[节点1] ───→ [节点1] ───→ [节点1]
[节点2] ───→ [节点2] ───→ [节点2]
[节点3] ───→ [节点3] ───→ [节点3]
[节点4]
[节点5]
每一层都从上一层接收信息,
处理后传递给下一层
3.4 神经网络的三个关键概念
| 概念 | 说明 | 例子 |
|---|---|---|
| 节点(神经元) | 处理单元 | 像人脑的神经元 |
| 权重 | 连接强度 | 决定信息的重要性 |
| 偏置 | 调整阈值 | 像激活的门槛 |
四、核心概念二:神经网络的基本单元——神经元
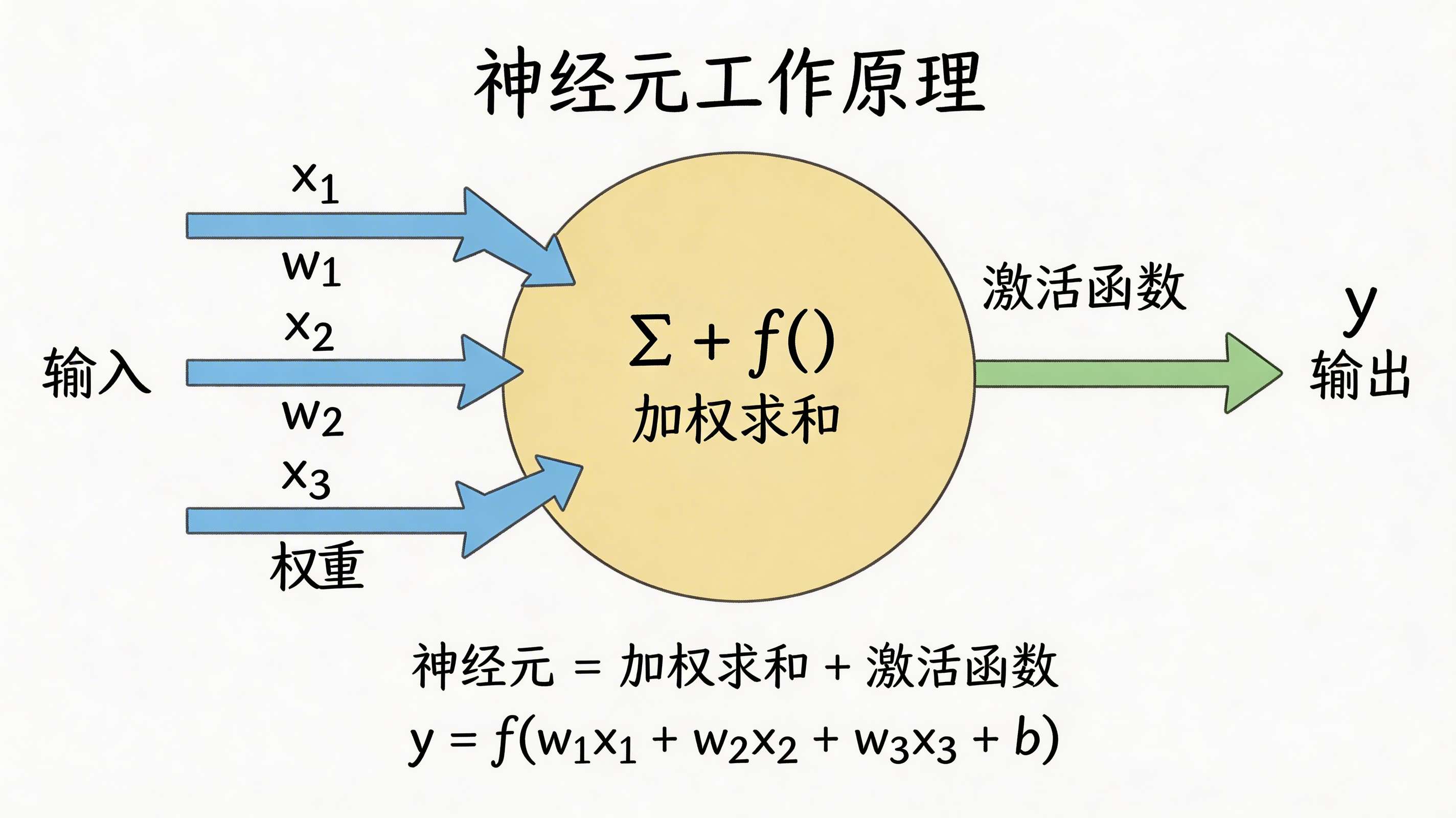
4.1 神经元是怎么工作的?
神经元 = 加权求和 + 激活函数
数学表达:
步骤1:加权求和
z = w₁·x₁ + w₂·x₂ + w₃·x₃ + b
其中:
- x₁, x₂, x₃ 是输入
- w₁, w₂, w₃ 是权重
- b 是偏置
步骤2:激活函数
y = f(z)
其中:
- f 是激活函数
- y 是输出
4.2 一个简单的例子
判断要不要带伞
输入:
x₁ = 是否多云(1=是,0=否)
x₂ = 降雨概率(0-1之间)
x₃ = 有没有伞(1=有,0=没有)
权重:
w₁ = 3(多云很重要)
w₂ = 5(降雨概率最重要)
w₃ = -2(有伞可以降低带伞需求)
偏置:
b = -2(默认不带伞)
计算:
z = 3·x₁ + 5·x₂ + (-2)·x₃ + (-2)
y = sigmoid(z)
如果 y > 0.5 → 带伞
如果 y < 0.5 → 不带伞
4.3 什么是激活函数?
激活函数 = 决定神经元是否"激活"
没有激活函数:
神经元只是线性变换
再多层也只是单层
有激活函数:
引入非线性
可以学习复杂的模式
常见的激活函数:
| 激活函数 | 特点 | 用途 |
|---|---|---|
| Sigmoid | 输出0-1之间 | 二分类输出层 |
| ReLU | 简单,计算快 | 隐藏层常用 |
| Softmax | 输出概率分布 | 多分类输出层 |
4.4 用生活例子理解激活函数
激活函数就像人的"兴奋度"
场景:看到好吃的
输入信息:
- 香味:x₁
- 颜色:x₂
- 之前吃过:x₃
加权求和:
z = 2·x₁ + 1·x₂ + 3·x₃
激活函数(ReLU):
如果 z > 0 → 兴奋(想吃)
如果 z < 0 → 不兴奋(不想吃)
就像:
如果吸引力足够 → 开始分泌口水
如果吸引力不够 → 无动于衷
五、核心概念三:前向传播——信息如何流动
5.1 什么是前向传播?
前向传播 = 输入数据通过网络得到输出
信息流动:
输入层 → 隐藏层 → 输出层
每一层:
1. 接收上一层的输出
2. 加权求和 + 偏置
3. 通过激活函数
4. 传递给下一层
5.2 前向传播的完整例子
识别手写数字"8"
输入层:
28×28 = 784个像素点
每个像素点的灰度值 0-1
隐藏层1:
256个神经元
学习边缘、线条特征
隐藏层2:
128个神经元
学习曲线、拐角特征
隐藏层3:
64个神经元
学习数字部件特征
输出层:
10个神经元
对应数字0-9的概率
输出结果:
[0.01, 0.02, 0.01, 0.01, 0.01, 0.01, 0.01, 0.01, 0.89, 0.02]
↑
识别为"8"的概率89%
5.3 前向传播的计算过程
第1层(输入层):
x = [x₁, x₂, x₃]
第2层(隐藏层):
z² = W²·x + b²
a² = f(z²)
第3层(输出层):
z³ = W³·a² + b³
a³ = f(z³)
最终输出:
y = a³
其中:
- W 是权重矩阵
- b 是偏置向量
- f 是激活函数
- a 是激活值(该层的输出)
5.4 前向传播的关键点
| 关键点 | 说明 |
|---|---|
| 逐层计算 | 每一层只依赖上一层 |
| 权重共享 | 同一层用同一套权重 |
| 非线性 | 激活函数带来非线性 |
| 确定性 | 给定输入,输出就确定 |
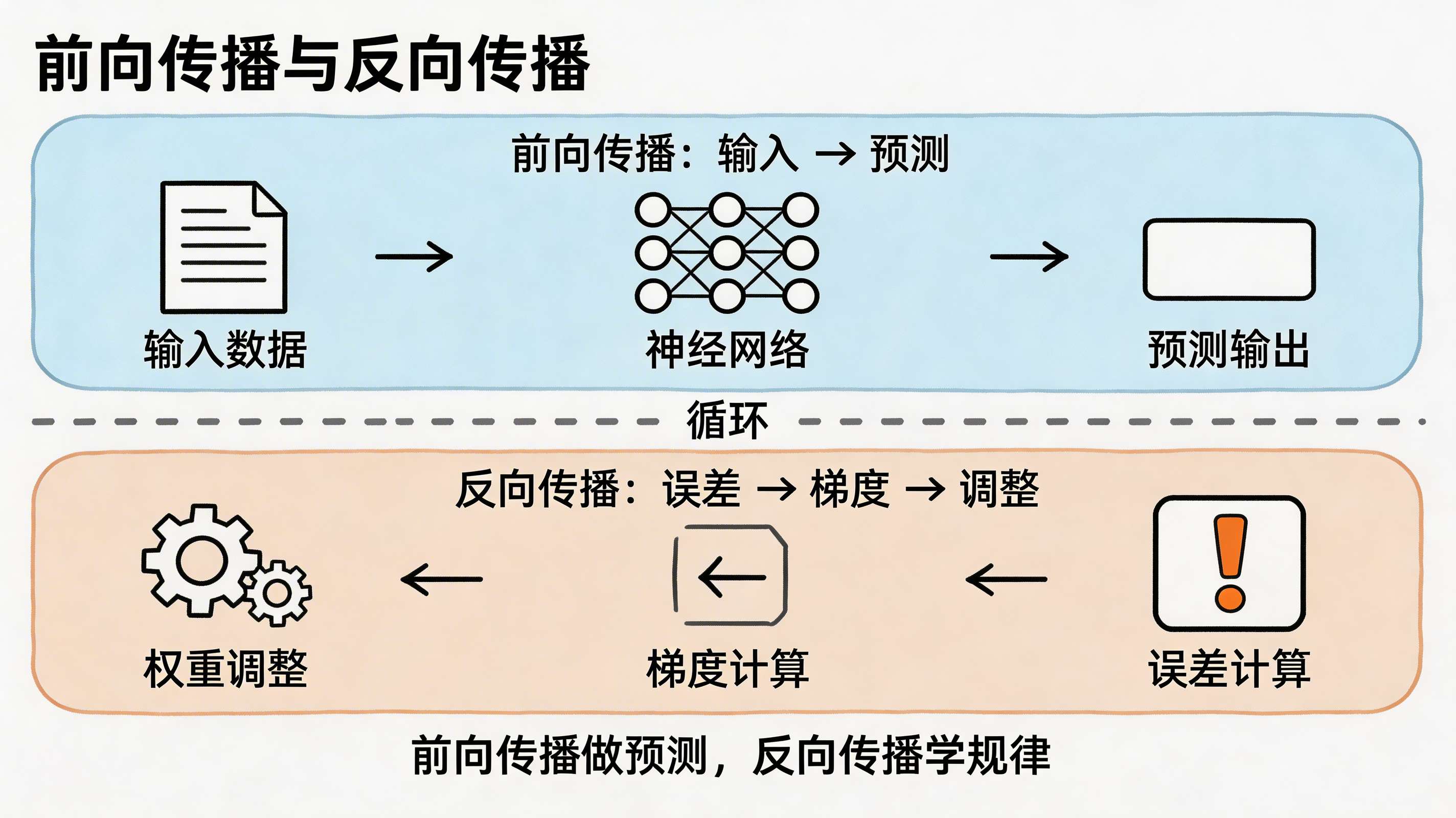
六、核心概念四:反向传播——如何"学习"
6.1 什么是反向传播?
反向传播 = 从错误中学习,调整权重
前向传播:
输入 → 网络 → 预测输出
反向传播:
预测输出 ← 计算误差 ← 真实标签
↓
调整权重
6.2 用生活例子理解反向传播
就像射箭调整姿势
第一次射箭:
- 瞄准靶心
- 结果:偏左10厘米
思考原因:
- 为什么偏左?
- 可能是手臂太靠左
- 可能是力度不够
调整姿势:
- 手臂向右移一点
- 加大力度
第二次射箭:
- 结果:偏左2厘米
- 好多了!
继续调整:
- 再微调一点
- 最终命中靶心
神经网络的学习过程类似
第一次预测:
- 输入:猫的图片
- 预测:狗(错误!)
- 误差:很大
反向传播:
- 计算误差
- 分析哪些权重导致错误
- 调整这些权重
第二次预测:
- 输入:同样的猫
- 预测:猫(正确!)
- 误差:很小
6.3 反向传播的核心思想
链式法则:从输出层反向计算梯度
目标:找到每个权重对误差的贡献
步骤:
1. 计算输出层的误差
2. 计算输出层权重的梯度
3. 反向传播到隐藏层
4. 计算隐藏层权重的梯度
5. 继续反向传播...
6. 直到输入层
6.4 反向传播的数学直觉
梯度 = 误差对权重的敏感度
问题:权重w应该增加还是减少?
计算梯度:
∂误差/∂w = ?
如果梯度为正:
- 增加w会增加误差
- 应该减少w
如果梯度为负:
- 增加w会减少误差
- 应该增加w
直觉:
就像下山
- 梯度告诉你哪个方向下山最快
- 你就往那个方向走
6.5 反向传播的关键点
| 关键点 | 说明 |
|---|---|
| 从后往前 | 从输出层向输入层反向计算 |
| 误差分配 | 将误差分配给每个权重 |
| 梯度计算 | 计算每个权重的梯度 |
| 权重更新 | 根据梯度调整权重 |
七、核心概念五:损失函数——如何衡量好坏
7.1 什么是损失函数?
损失函数 = 衡量预测误差的标准
问题:模型预测得好不好?
解决:计算预测和真实的差距
损失函数:
L = 预测值 - 真实值
目标:
让损失函数最小化
7.2 常见的损失函数
回归问题的损失函数:
均方误差(MSE):
L = (1/n) Σ(预测值 - 真实值)²
例子:
预测房价:
真实值:500万
预测值:480万
误差:(500 - 480)² = 400
分类问题的损失函数:
交叉熵损失:
L = -Σ真实值 × log(预测值)
例子:
分类猫和狗:
真实:猫 [1, 0]
预测:[0.8, 0.2]
损失:-(1×log(0.8) + 0×log(0.2)) = 0.22
7.3 用生活例子理解损失函数
就像考试得分
损失函数 = 得分的反面
考试:
- 做对10题 → 得分100 → 损失0
- 做对8题 → 得分80 → 损失20
- 做对5题 → 得分50 → 损失50
目标:
最小化损失 = 最大化得分
神经网络:
- 预测准确 → 损失小
- 预测错误 → 损失大
训练目标:
调整权重,让损失最小
7.4 损失函数的作用
| 作用 | 说明 |
|---|---|
| 评估模型 | 衡量预测的好坏 |
| 指导训练 | 告诉网络如何改进 |
| 比较模型 | 不同模型对比的标准 |
| 停止训练 | 损失不再下降时停止 |
八、核心概念六:梯度下降——如何找到最优解
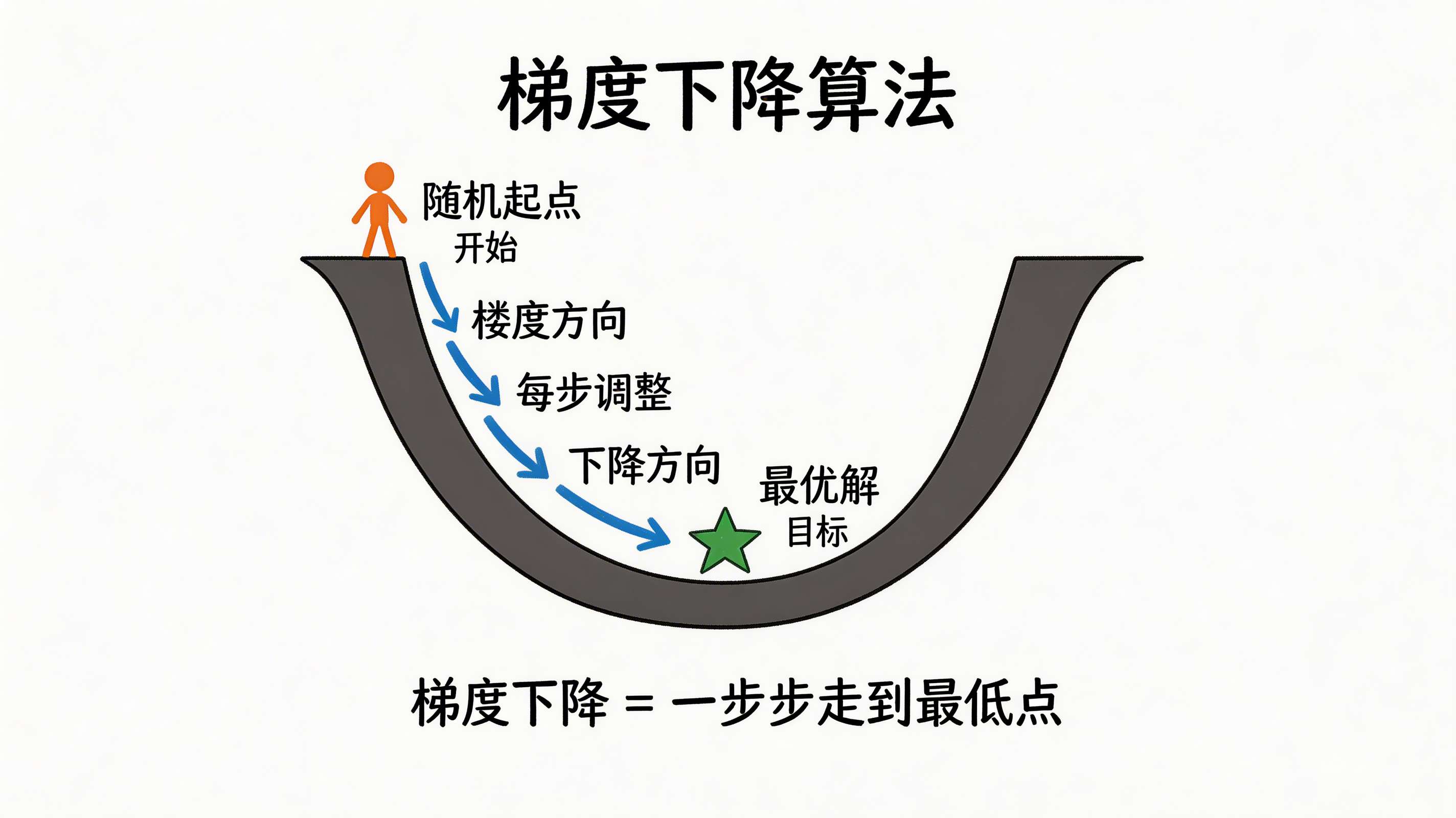
8.1 什么是梯度下降?
梯度下降 = 一步步走到最低点
想象你在山上:
- 目标:走到山谷最低点
- 问题:雾很大,看不清地形
- 方法:感受脚下坡度,往低处走
梯度下降:
1. 计算当前点的梯度(坡度)
2. 沿梯度的反方向走一步
3. 重复1-2,直到到达最低点
8.2 用图理解梯度下降
损失函数就像地形
/\
/ \
/ \
/ \
/ \
/ \____
/ \
_/ \___
起点 最低点
步骤:
1. 随机在起点
2. 感受坡度(梯度)
3. 往下走一步
4. 继续感受、继续走
5. 到达最低点
8.3 梯度下降的三个关键参数
学习率(Learning Rate):
定义:每步走多大
学习率太大:
- 跨过去了
- 可能在最低点附近震荡
- 甚至发散!
学习率太小:
- 走得太慢
- 需要很多步才能到达
- 训练时间太长
合适的:
- 稳定下降
- 到达最低点
批量大小(Batch Size):
定义:每次用多少样本计算梯度
批量梯度下降:
- 用所有样本
- 稳定但慢
随机梯度下降(SGD):
- 用1个样本
- 快但不稳定
小批量梯度下降:
- 用一小批样本(如32、64、128)
- 平衡速度和稳定性
迭代次数(Epochs):
定义:遍历整个数据集多少次
太少:
- 可能没训练好
- 还没到最低点
太多:
- 可能过拟合
- 在训练集上表现好,新数据差
合适:
- 监控验证集损失
- 不再下降时停止
8.4 梯度下降的优化算法
传统梯度下降的问题:
问题:
- 在山谷中震荡
- 收敛速度慢
- 可能卡在局部最优
改进的优化算法:
| 算法 | 特点 | 优势 |
|---|---|---|
| Momentum | 动量加速 | 像滚球,加速收敛 |
| AdaGrad | 自适应学习率 | 稀疏数据效果好 |
| RMSprop | 动量+自适应 | 平衡速度和稳定 |
| Adam | 动量+自适应+偏差修正 | 最常用的算法 |
8.5 梯度下降的问题和解决
问题一:局部最优
问题:
- 可能卡在局部最低点
- 不是全局最低点
解决:
- 随机初始化
- 多次训练取最好
- 使用更好的优化算法
问题二:梯度消失
问题:
- 深层网络梯度很小
- 前层几乎不更新
解决:
- ReLU激活函数
- 残差连接
- 批归一化
问题三:梯度爆炸
问题:
- 梯度变得很大
- 权重更新幅度过大
- 模型不稳定
解决:
- 梯度裁剪
- 权重初始化
- 调整学习率
九、核心概念七:深度学习的"深度"在哪里
9.1 为什么叫"深度"学习?
深度 = 很多隐藏层
浅层神经网络:
输入层 → 1-2个隐藏层 → 输出层
深度神经网络:
输入层 → 10+个隐藏层 → 输出层
为什么需要深度?
- 可以学习层次化的特征
- 每层学习不同抽象级别
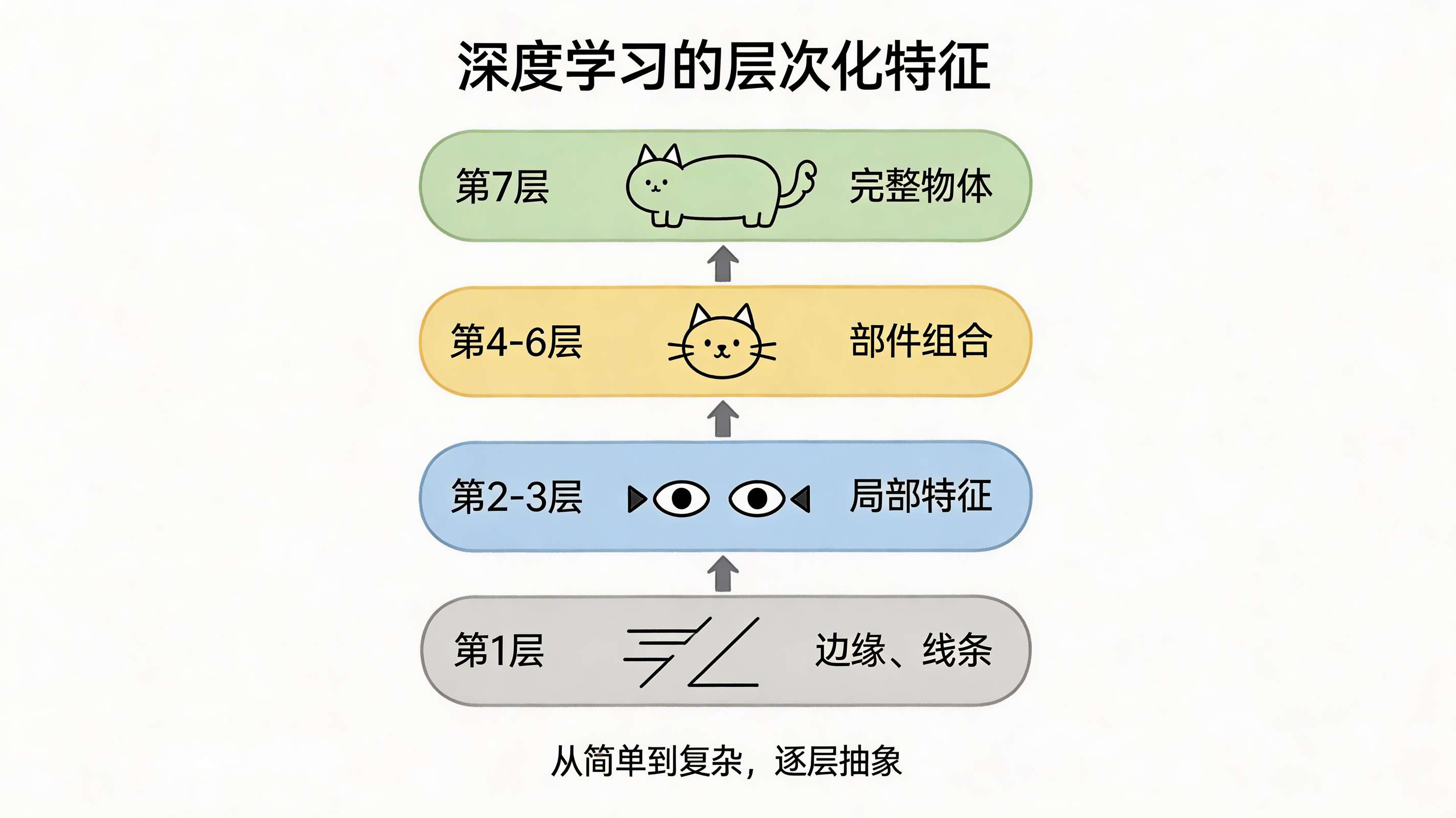
9.2 层次化特征学习
从简单到复杂,逐层抽象
图像识别的例子:
第1层(底层):
- 学习边缘、线条
- 简单的几何形状
- 就像认出"有线条"
第2-3层(中层):
- 学习眼睛、耳朵、鼻子
- 局部特征组合
- 就像认出"有眼睛"
第4-6层(高层):
- 学习脸部、物体部件
- 复杂特征组合
- 就像认出"有猫脸"
第7层以上(顶层):
- 学习完整物体
- 猫、狗、汽车...
- 就像认出"这是猫"
9.3 深度的优势
深度可以表示更复杂的函数
定理:
任何函数都可以用足够深的神经网络表示
直观理解:
- 浅层网络需要很多节点
- 深层网络可以用更少参数
- 层次结构更自然
例子:
- 人脸识别
- 浅层:需要成千上万节点
- 深层:几十层,每层几十节点
- 效果:深度更好
9.4 深度的挑战
挑战一:训练难度
问题:
- 层数越多,越难训练
- 梯度消失/爆炸
- 计算量大
解决:
- 批归一化
- 残差连接(ResNet)
- 更好的优化算法
挑战二:过拟合
问题:
- 参数太多
- 容易记住训练数据
- 泛化能力差
解决:
- 更多数据
- Dropout(随机丢弃神经元)
- 正则化
- 数据增强
挑战三:计算资源
问题:
- 需要大量算力
- 训练时间长
- 需要GPU
解决:
- 分布式训练
- 模型压缩
- 迁移学习
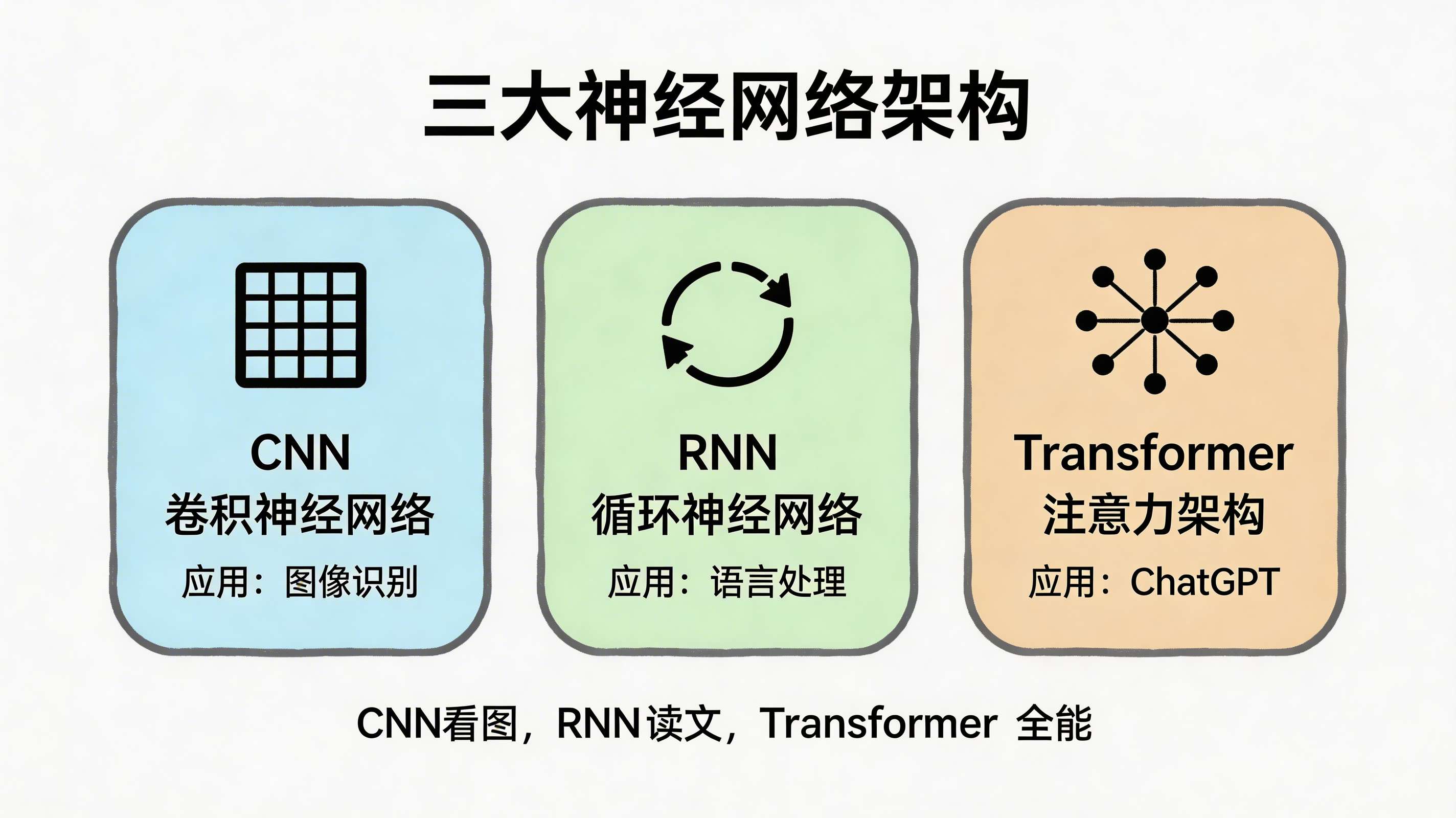
十、常见的神经网络架构
10.1 卷积神经网络(CNN)
专门处理图像的神经网络
核心思想:
- 局部连接
- 权重共享
- 池化降维
结构:
输入层 → 卷积层 → 池化层 → 全连接层 → 输出层
应用:
- 图像分类
- 目标检测
- 人脸识别
- 医学影像分析
CNN的关键概念:
| 概念 | 说明 | 例子 |
|---|---|---|
| 卷积核 | 特征检测器 | 检测边缘、纹理 |
| 特征图 | 卷积后的结果 | 提取的特征 |
| 池化 | 降维 | 最大池化、平均池化 |
| 步长 | 卷积核移动的步幅 | 控制输出大小 |
10.2 循环神经网络(RNN)
专门处理序列的神经网络
核心思想:
- 有"记忆"
- 前面的输出影响后面的输入
- 适合处理序列数据
结构:
输入 → 隐藏层(有循环) → 输出
↑ ↓
└──────────────┘
应用:
- 语言翻译
- 语音识别
- 文本生成
- 时间序列预测
RNN的问题:
长序列问题:
- 梯度消失
- 记不住太久之前的信息
解决:
- LSTM(长短期记忆网络)
- GRU(门控循环单元)
- Attention机制
10.3 Transformer
革命性的架构,ChatGPT的基础
核心思想:
- Self-Attention(自注意力机制)
- 并行处理
- 可以关注序列的不同部分
结构:
输入 → Embedding → 多层Transformer → 输出
↑
Attention层
应用:
- ChatGPT
- 机器翻译
- 文本生成
- 图像生成(ViT)
Transformer的关键创新:
| 创新 | 说明 | 影响 |
|---|---|---|
| Self-Attention | 关注序列内部关系 | 理解上下文 |
| 并行计算 | 不再顺序处理 | 训练速度快 |
| 位置编码 | 保留序列位置信息 | 理解顺序 |
| 多头注意力 | 关注不同特征 | 学习更丰富 |
10.4 生成对抗网络(GAN)
两个网络对抗学习
核心思想:
- 生成器:造假
- 判别器:识别真伪
- 对抗训练,共同进步
结构:
生成器(G):
随机噪声 → 假图像
判别器(D):
图像 → 真/假
训练:
G想让D分不清
D想更好地区分
GAN的应用:
图像生成:
- 生成人脸
- 生成艺术作品
- 图像风格迁移
数据增强:
- 生成训练数据
- 合成罕见样本
图像编辑:
- 去除水印
- 修复老照片
- 改变图像属性
十一、深度学习的实际应用
深度学习已经渗透到生活的方方面面!
11.1 计算机视觉
图像分类:
应用:
- Google Photos自动分类
- 苹果照片识别人物
- 植物识别APP
原理:
CNN提取特征 → 分类器识别
目标检测:
应用:
- 自动驾驶(检测行人、车辆)
- 安防监控(检测异常行为)
- 零售(自动结算)
原理:
CNN检测 + 边界框回归
图像生成:
应用:
- Midjourney
- DALL-E
- Stable Diffusion
原理:
扩散模型、Transformer
11.2 自然语言处理
机器翻译:
应用:
- Google翻译
- DeepL
- ChatGPT
原理:
Transformer编码-解码
文本生成:
应用:
- ChatGPT对话
- 写作助手
- 代码生成
原理:
GPT系列模型
情感分析:
应用:
- 社交媒体监控
- 客户反馈分析
- 舆情分析
原理:
BERT分类模型
11.3 语音处理
语音识别:
应用:
- Siri、小爱同学
- 会议转录
- 语音输入
原理:
CNN + RNN + CTC
语音合成:
应用:
- 导航语音
- 有声书
- AI配音
原理:
Tacotron、WaveNet
11.4 推荐系统
应用:
电商推荐:
- 淘宝商品推荐
- 京东猜你喜欢
内容推荐:
- 抖音视频推荐
- 网易云音乐推荐
广告推荐:
- 精准广告投放
原理:
深度学习 + 协同过滤
- 学习用户兴趣
- 学习物品特征
- 预测用户偏好
11.5 自动驾驶
感知层:
任务:
- 检测车道线
- 识别交通标志
- 检测行人、车辆
技术:
CNN、目标检测、分割
决策层:
任务:
- 路径规划
- 避障
- 控制车速
技术:
强化学习、规划算法
十二、深度学习的挑战和局限
深度学习很强大,但也不是万能的。
挑战一:数据饥渴
需要大量标注数据
问题:
- 深度学习需要大量数据
- 数据标注成本高
- 有些领域数据稀缺
例子:
- 医疗影像:需要医生标注
- 罕见病:样本很少
- 新语言:语料库小
解决:
- 迁移学习
- 数据增强
- 半监督学习
- 合成数据
挑战二:黑盒问题
不知道为什么做出这个决定
问题:
- 深度神经网络太复杂
- 难以解释决策过程
- 关键领域(医疗、金融)需要解释
例子:
医生:"为什么诊断是癌症?"
AI:"因为神经网络这么输出"
(这不是好解释)
解决:
- 可解释AI(XAI)
- 注意力可视化
- 使用更简单的模型
- 人机协同决策
挑战三:计算成本
训练成本高昂
成本类型:
硬件成本:
- GPU很贵
- 需要多卡训练
- 电力消耗大
时间成本:
- 训练时间长
- GPT-3训练了几周
- 需要大量实验
人力成本:
- 需要专业人员
- 调参耗时间
- 需要领域知识
挑战四:鲁棒性
容易被欺骗
对抗样本:
- 人类看不出的变化
- AI会完全误判
例子:
- 熊猫图片加噪声
- AI识别成长臂猿
- 只改变了几个像素
问题:
- 安全隐患
- 不可靠
解决:
- 对抗训练
- 防御机制
- 更鲁棒的模型
挑战五:公平性
可能学习偏见
问题:
- 数据有偏见
- 模型学会偏见
- 放大社会偏见
例子:
- 招聘系统性别歧视
- 人脸识别对少数族裔差
- 信贷系统不公平
解决:
- 意识到问题
- 检查数据公平性
- 算法中加入公平约束
- 持续监控
十三、本文小结
咱们今天聊了很多,来总结一下:
1. 什么是深度学习
深度学习 = 基于深度神经网络的机器学习
模仿人脑结构
自动学习特征
2. 神经网络的基本结构
输入层 → 隐藏层 → 输出层
基本单元:神经元
- 加权求和 + 激活函数
3. 神经网络如何学习
前向传播:输入 → 输出
反向传播:误差 → 梯度 → 调整权重
损失函数:衡量误差
梯度下降:最小化损失
4. 深度的意义
层次化特征学习
从简单到复杂
每层学习不同抽象级别
5. 常见架构
CNN:图像
RNN:序列
Transformer:文本
GAN:生成
6. 应用
计算机视觉
自然语言处理
语音处理
推荐系统
自动驾驶
7. 挑战
数据需求大
黑盒问题
计算成本
鲁棒性
公平性
8. 关键公式
好的深度学习 = 好数据 + 合适架构 + 充分训练 + 仔细调优
十四、今日思考题
今天留两个思考题:
思考题一:
为什么深度学习需要这么多层?能不能用一层很大的网络代替?
提示:
-
层次化特征学习 -
参数效率 -
表达能力
思考题二:
深度学习的"黑盒"问题会影响你在哪些场景下的使用?
提示:
-
医疗诊断 -
金融风控 -
法律判决 -
你想到的场景...
欢迎在评论区分享你的想法!
往期推荐:
如果这篇文章对你有帮助,欢迎点赞关注,我会持续用大白话讲解复杂的技术概念!
本文由 mdnice 多平台发布

开源鸿蒙跨平台开发社区汇聚开发者与厂商,共建“一次开发,多端部署”的开源生态,致力于降低跨端开发门槛,推动万物智联创新。
更多推荐


 7
7 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)