揭秘Intern-S1-Pro:从微观生命到宏观宇宙的跨领域科学统一理解能力
另外,研究团队还同步打造了面向科学时序理解与生成的系统性评测基准 SciTS,覆盖天文、地球科学、生物声学、气象学、神经科学、数学等 12 个学科的 43 个典型场景,可科学呈现文本、多模态大模型与传统时序模型在科学时序任务中的表现。围绕这一目标,上海人工智能实验室开展了跨领域科学时序信号统一建模的探索,将原创的专用时序模块应用于书生科学多模态大模型 Intern-S1-Pro,助力模型首次具备统
随着大模型能力持续跃迁,AGI for Science(AGI4S)正成为通用人工智能的重要方向。我们期待科学大模型不仅理解文本与图像知识,还能直接解析科学观测数据,参与推理与发现。科学研究中,时序信号是自然规律的直接观测形式——无论是物理演化、生理节律,还是环境变化,本质上都以时间序列呈现。
由此引出一个关键问题:能否统一建模时序信号表达形式,使模型能够直接理解来自不同学科的数据?若能实现,将赋予模型跨学科迁移与泛化能力,并直接支持科学观测理解与假设生成。
围绕这一目标,上海人工智能实验室开展了跨领域科学时序信号统一建模的探索,将原创的专用时序模块应用于书生科学多模态大模型 Intern-S1-Pro,助力模型首次具备统一处理百万级采样的各类信号的能力,实现科学感知能力大幅提升。
另外,研究团队还同步打造了面向科学时序理解与生成的系统性评测基准 SciTS,覆盖天文、地球科学、生物声学、气象学、神经科学、数学等 12 个学科的 43 个典型场景,可科学呈现文本、多模态大模型与传统时序模型在科学时序任务中的表现。
Intern-S1-Pro HuggingFace 链接:
https://huggingface.co/internlm/Intern-S1-Pro
Intern-S1-Pro GitHub 链接:
https://github.com/InternLM/Intern-S1
SciTS HuggingFace 链接:
https://huggingface.co/datasets/OpenTSLab/SciTS
科学时序统一建模的挑战
科学时序数据在形态与任务层面呈现出高度复杂性。不同学科的时序信号在采样率、序列长度、通道结构与数值范围等方面差异巨大,从极短片段到百万级时间步、从单通道记录到高维多通道信号,均可能在同一建模框架中出现。同时,这类数据通常标注成本高、规模有限且长尾分布普遍存在,而任务形态又涵盖分类、检测、预测、描述与事件定位等多种形式。上述因素共同导致传统时序模型往往呈现出明显的任务特化与领域特化特征,难以实现跨领域迁移与统一理解。
原创专用时序模块赋予 Intern-S1-Pro 跨领域科学统一理解能力
在现有多模态大模型体系中,时序信号仍未得到充分支持。常见处理方式通常将数值序列编码为文本,或转换为图像后输入模型,但此类间接表示方式往往难以支撑对科学时序信号的全面理解。与此同时,现有通用时序模型多聚焦于预测或分析中的单一方向,其在处理非周期性、强异质科学信号时的有效性仍有待进一步验证。
为解决上述问题,Intern-S1 系列科学多模态大模型引入原创专用时序模块,并在 Intern-S1-Pro 中实现全面升级。在 Intern-S1 已覆盖天文学、地球科学与神经科学任务的基础上,Intern-S1- Pro 进一步拓展至生理信号与生物声学等领域,支持脑电抑郁症检测、狨猴叫声识别、心电异常监测等多样应用场景。
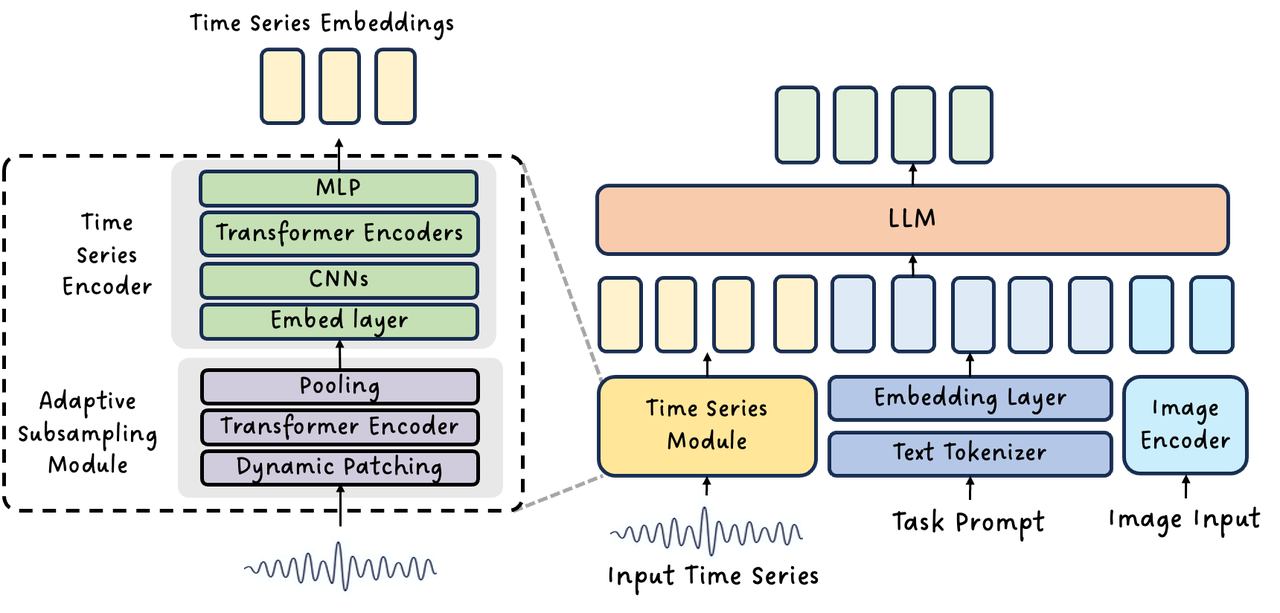
图1:Intern-S1- Pro时序模块示意图
在架构层面,Intern-S1- Pro 时序模块进行了全新设计(图1),支持多种原生时序数据格式输入,可处理多通道高维信号,并引入可变降采样机制,使模型能够灵活应对从极短到超长序列(10⁰–10⁶ 采样点)。
如图2所示,该模块会根据输入信号及其采样率自适应地计算降采样的 patch size 与 stride,将极长或极短的序列映射到相对统一的长度范围内,从而使模型既能灵活兼容不同尺度的输入,又能在保证关键信息保留的同时高效学习时序表征。整体设计目标是在保留时序信号原生信息的同时,使其能够自然融入大模型推理过程,为跨领域统一建模提供基础能力。
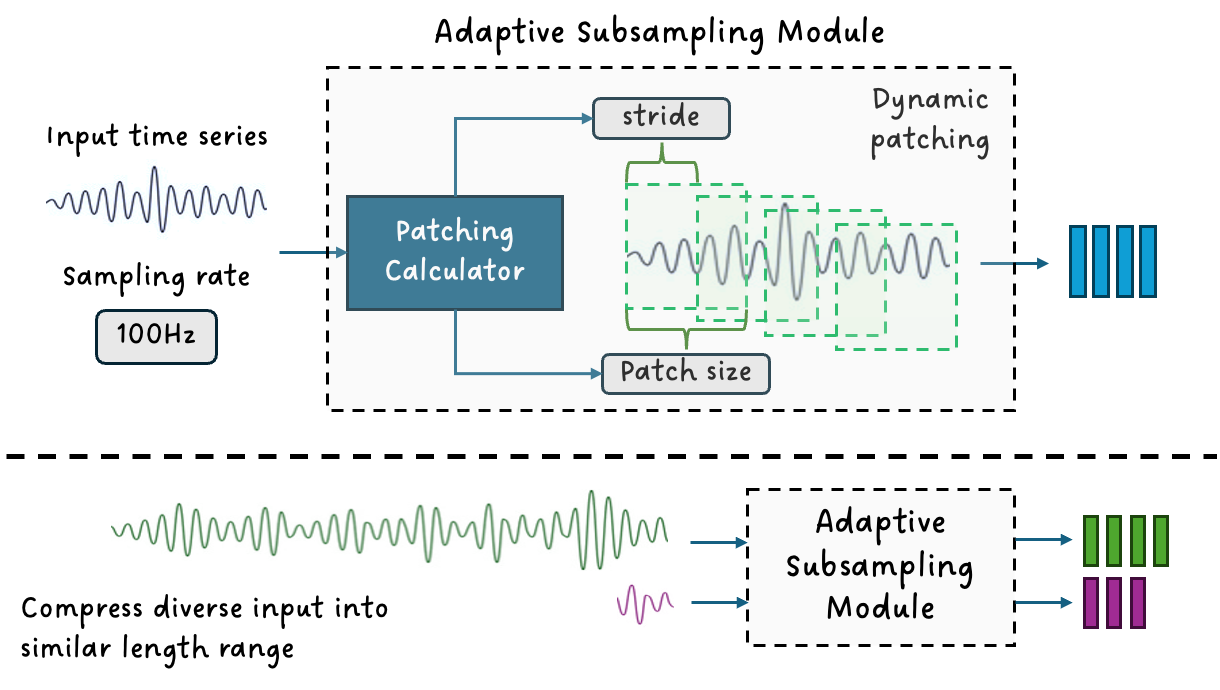
图2:可变降采样模块结构示意图
面向科学时序理解与生成的系统性评测基准
为进一步推动科学时序建模研究,研究团队构建了 SciTS benchmark,一个面向科学时序理解与生成的系统性评测基准,相关论文已被 ICLR 2026 接收。SciTS 覆盖了天文、地球科学、生物声学、气象学、神经科学、数学等 12 个学科的 43 个典型场景(如图3所示),包含问答、异常检测、补全与预测等 7 类任务(如图4所示),总计 5 万余条样本,在采样频率、序列长度与多变量维度方面具有广泛多样性。
基于 SciTS,团队系统评测了多个文本大模型、多模态大模型与传统时序模型在科学时序任务中的表现,并观察到两个重要现象:一方面,大语言模型在跨任务与跨领域设置下展现出比传统时序模型更强的适应性与泛化潜力;另一方面,将时序信号转化为文本或图像会带来信息损失,并在效率与数值保真度方面产生限制。这些结果表明,要有效刻画复杂科学动态过程,大模型仍需要与专门的时序处理模块相结合。
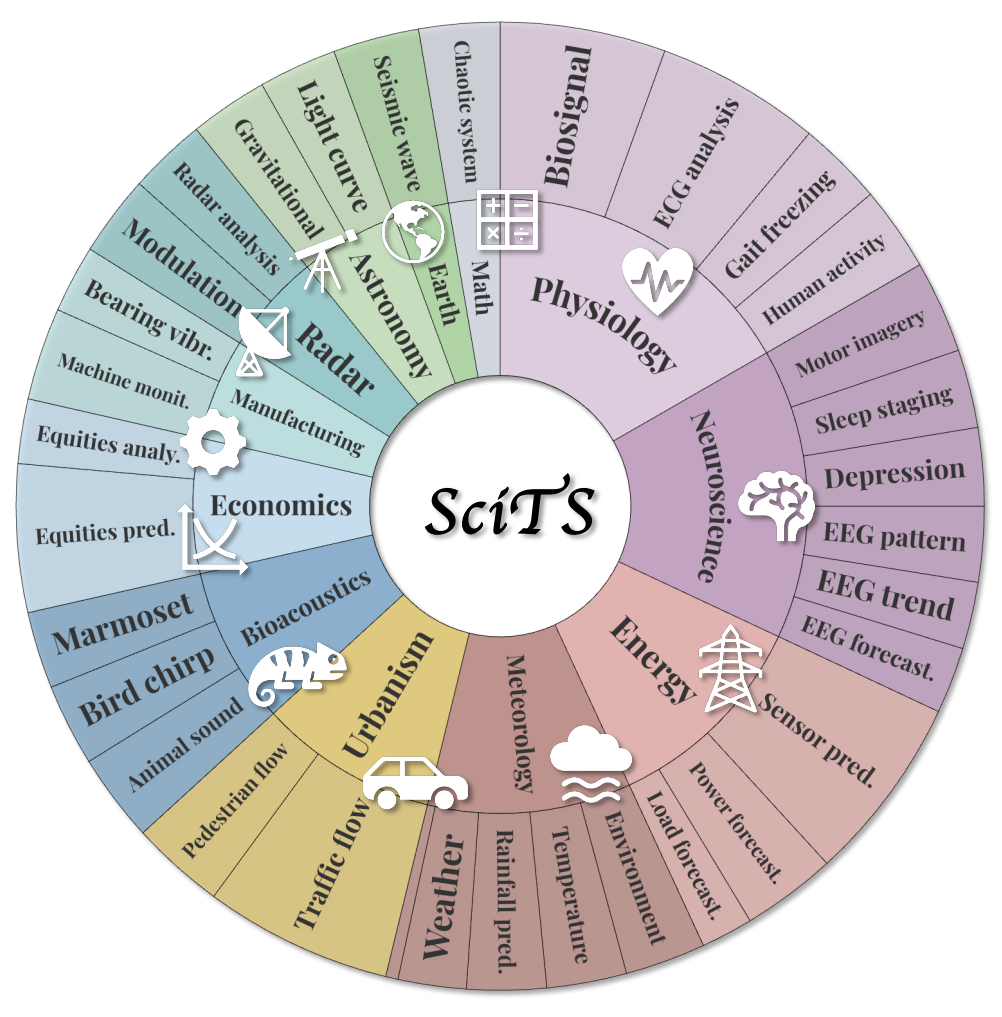 图3:SciTS 涵盖 12 个学科
图3:SciTS 涵盖 12 个学科
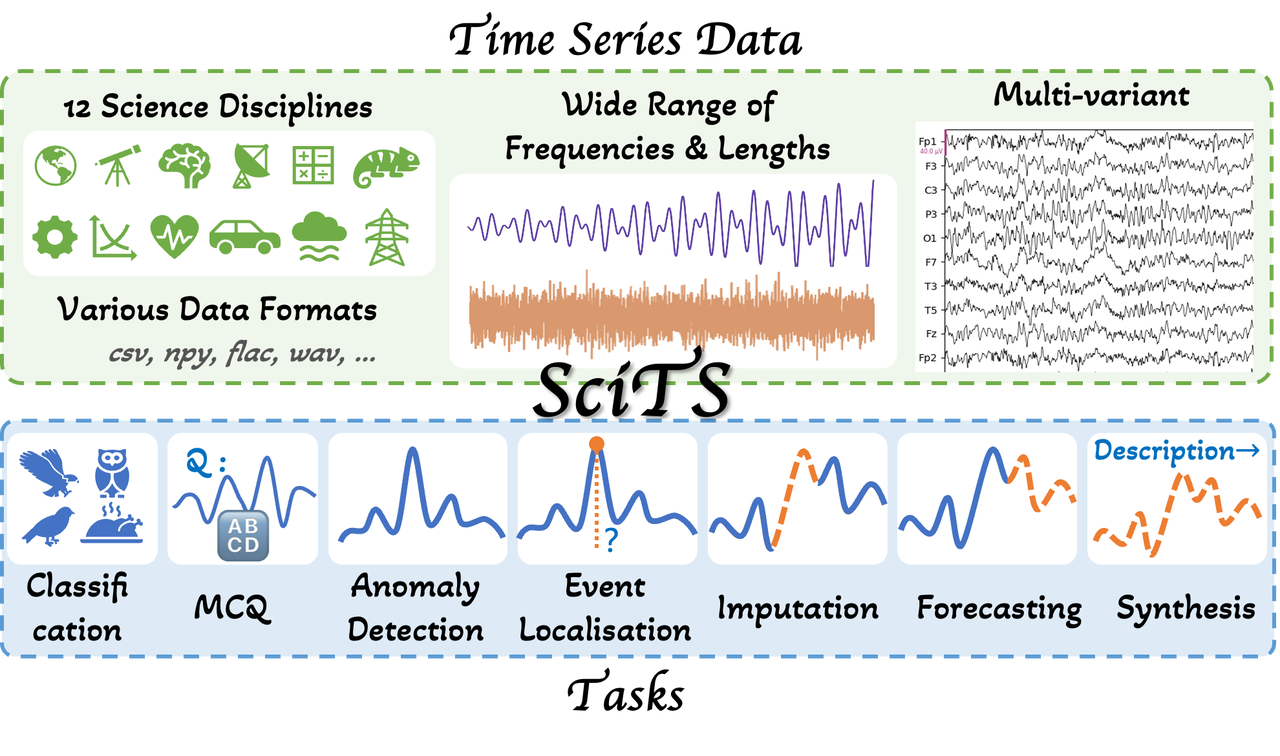
图4:SciTS 概览
跨领域科学时序统一建模仍处于探索阶段,仍面临诸多瓶颈与挑战。我们期待与社区共同推动更大规模跨领域数据集的构建、更开放统一的评测体系,以及更高效的时序与大模型融合范式。

开源鸿蒙跨平台开发社区汇聚开发者与厂商,共建“一次开发,多端部署”的开源生态,致力于降低跨端开发门槛,推动万物智联创新。
更多推荐


 5
5 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)