强化学习[chapter9] [page1 ]Actor-Critic Methods
一REINFORCE1Policy Gradient 优化目标目标是最大化 episode return 的数学期望 2 Policy Gradient 伪代码3Policy Gradient 两个问题参考李宏毅 DRL Lecture 1: Policy Gradient (Reviewhttps://www.bilibili.com/video/BV1nHgreKEqD/?spm_id_fro
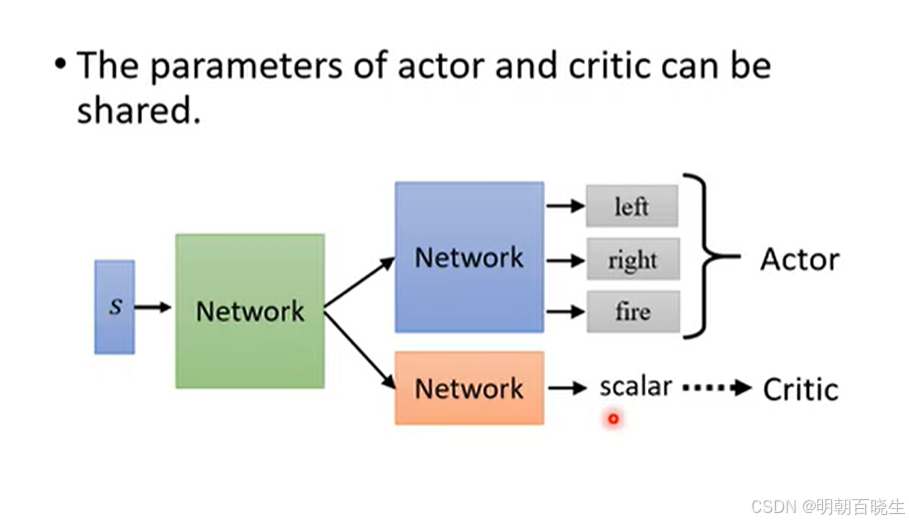
本节介绍最简单的Actor-Critic算法QAC。
目录:
- REINFORCE
- Actor-Critic 算法
- MC vs TD 在 Actor-Critic 中的对比
- Critic 与优势函数
- 伪代码
一 REINFORCE
1 Policy Gradient 优化目标
目标是最大化 episode return 的数学期望
轨迹的概率分布如下
优化器及对应的梯度为:
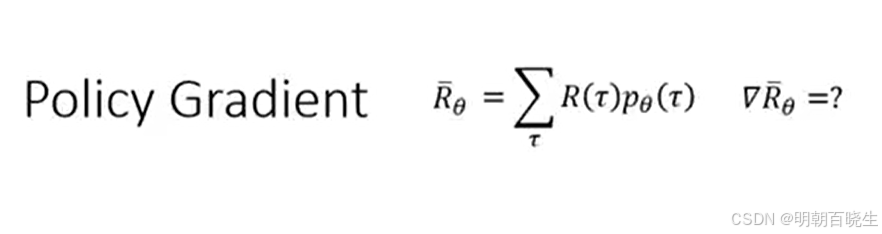

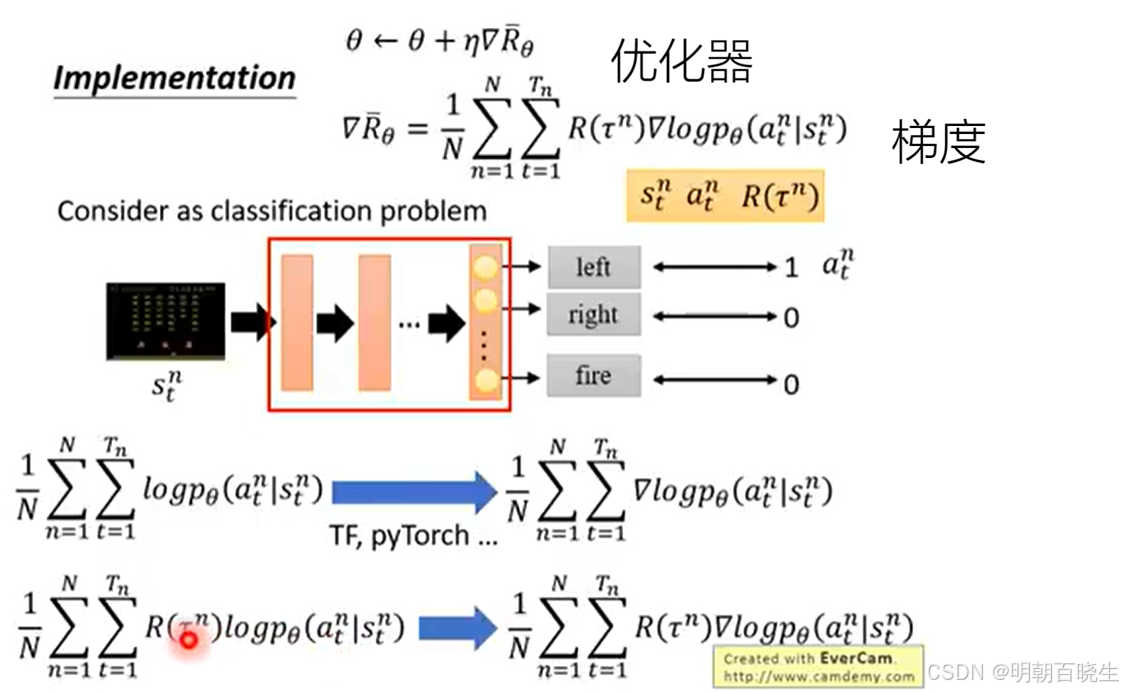
2 Policy Gradient 伪代码

3 Policy Gradient 两个问题
参考李宏毅 DRL Lecture 1: Policy Gradient (Review
https://www.bilibili.com/video/BV1nHgreKEqD/?spm_id_from=333.337.search-card.all.click
问题一:训练过程采样效率低
REINFORCE 属于同策略(On-policy)方法,即用于学习的智能体与与环境交互的智能体必须是同一个。每当策略参数 θ 发生更新,之前采集的轨迹数据就无法继续使用,必须重新采样。这意味着每次梯度更新都需要与环境重新交互收集一批新数据,导致训练效率低下、时间成本高
问题二:梯度更新方差大且存在不合理分配
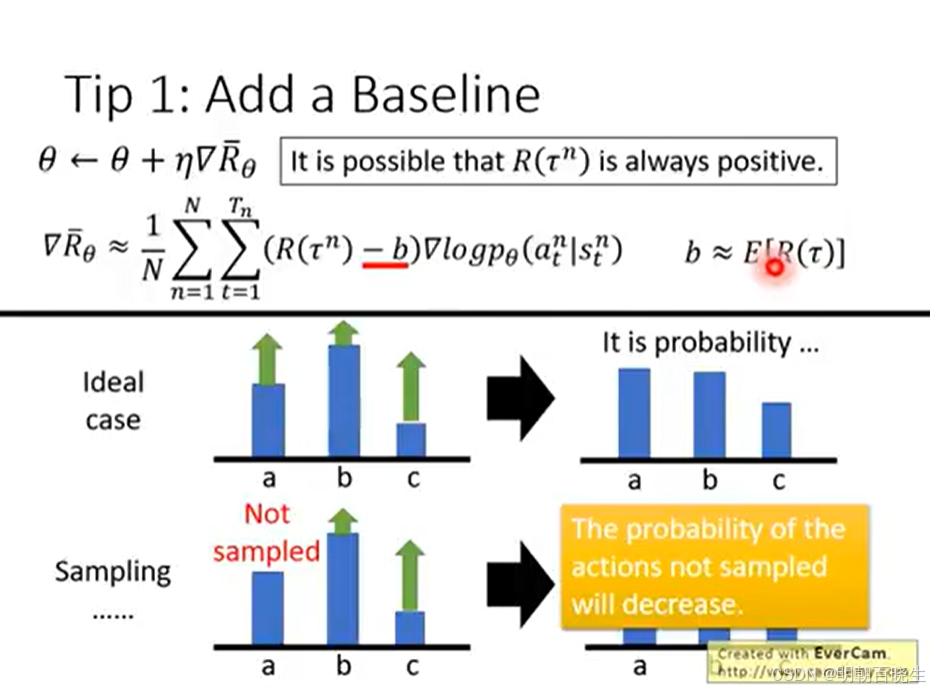
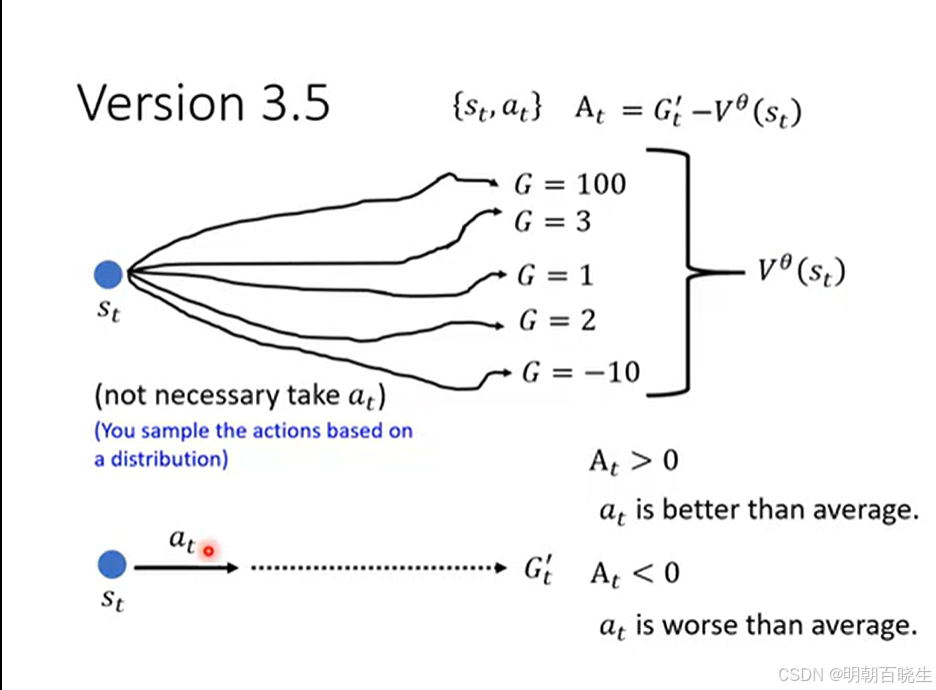
奖励总是为正时的不合理情况:由于 R(τ)始终为正,所有被采样到的动作概率都会被提升。虽然奖励高的动作提升更多、奖励低的动作提升较少,但那些未被采样到的动作概率会被动下降。这种“奖励全为正”的设定可能导致概率分配失真。解决方案增加baseLine,这个baseLine ,前面讲过这个baseLine也可以是个神经网络,通过训练得到,或者直接取平均值.
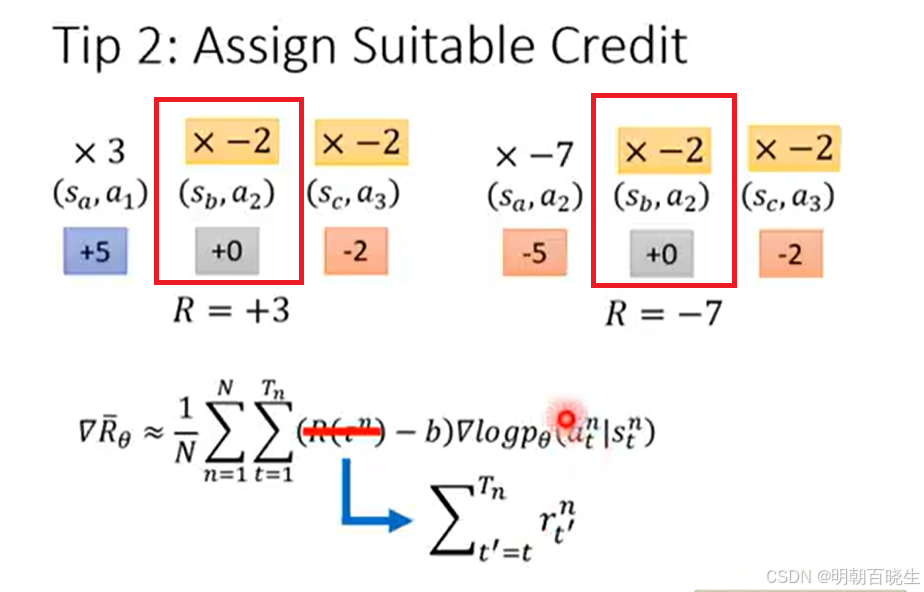
2 权重分配不公:同一轨迹中,无论动作好坏,所有状态-动作对都乘以相同的总奖励权重 R(τ)。然而,一个动作对最终结果的贡献理应与其发生时刻相关——动作只影响后续奖励,不应为之前的奖励负责。理想情况下需要给每个动作分配合理的信用(Credit Assignment. 如下图同样的
在两个轨迹里面的权重是完全相反的,一个为正,增加策略,一个为负降低策略,导致训练不稳定。
也可以用
折扣
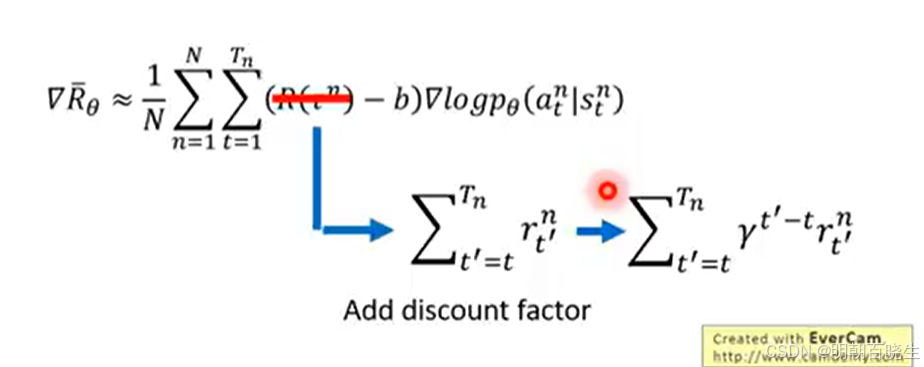
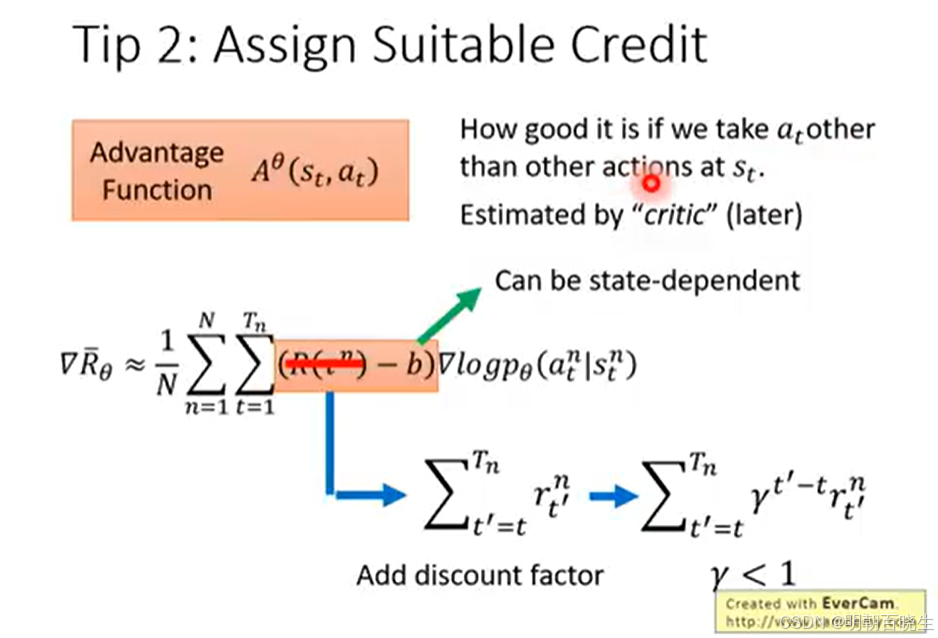
4 policy gradient episode return 优化方案
R-b 可以通过一个神经网络训练得到,该网络称为 Advantage Function(优势函数),即下文所述的 Critic
二 Actor-Critic 算法
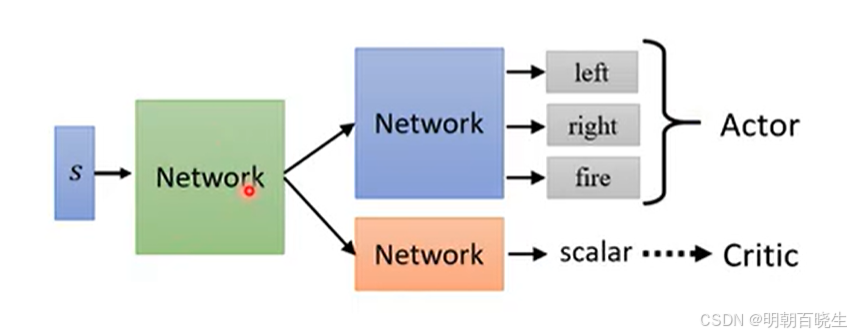
Actor-Critic 是一种结合了基于策略(Policy-Based)和基于价值(Value-Based)两种方法的强化学习算法。
Actor(演员):负责学习策略 π(a∣s),根据当前状态选择动作,目标是最大化累积奖励
Critic(评论家):负责评估 Actor 的表现,计算价值函数 V(s) 或优势函数 A(s,a),指导 Actor 更新
两者相互配合:Actor 做出决策,Critic 给出反馈,Actor 根据反馈改进策略。
1 Critic 设计原理
主要是计算价值函数,有三种方法
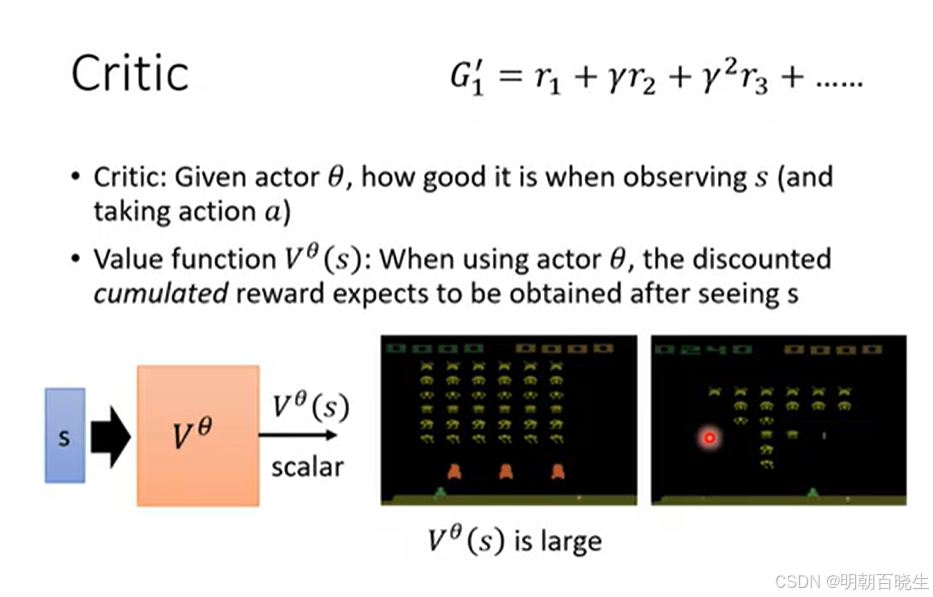
方法一: Monte-Carlo 方法
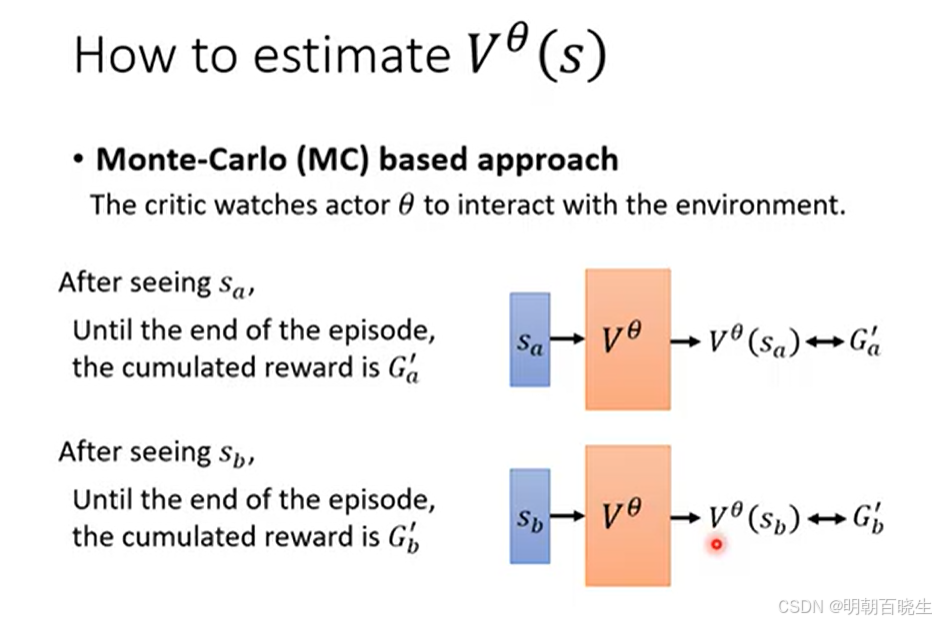
方法二 TD 算法
我们可以通过TD 公式的误差部分或定义法得到


三 MC vs TD 在 Actor-Critic 中的对比
通过下面例子我们可以看到MC 和 TD 得到V 并不相同
如下有8个轨迹,求的状态值,这里面我们不考虑折扣的情况
1. MC
根据 MC 算法的定义


2 TD 算法
算出来两个状态值是一样的

四 Critic 与优势函数
我们在 Policy Gradient 中讲过的优势函数,其中的基线 b 可以用一个训练出来的网络来替代。具体来说,我们先训练出一个 Critic 网络,然后用它来帮助训练 Actor,这就是 Actor-Critic 方法的基本思想


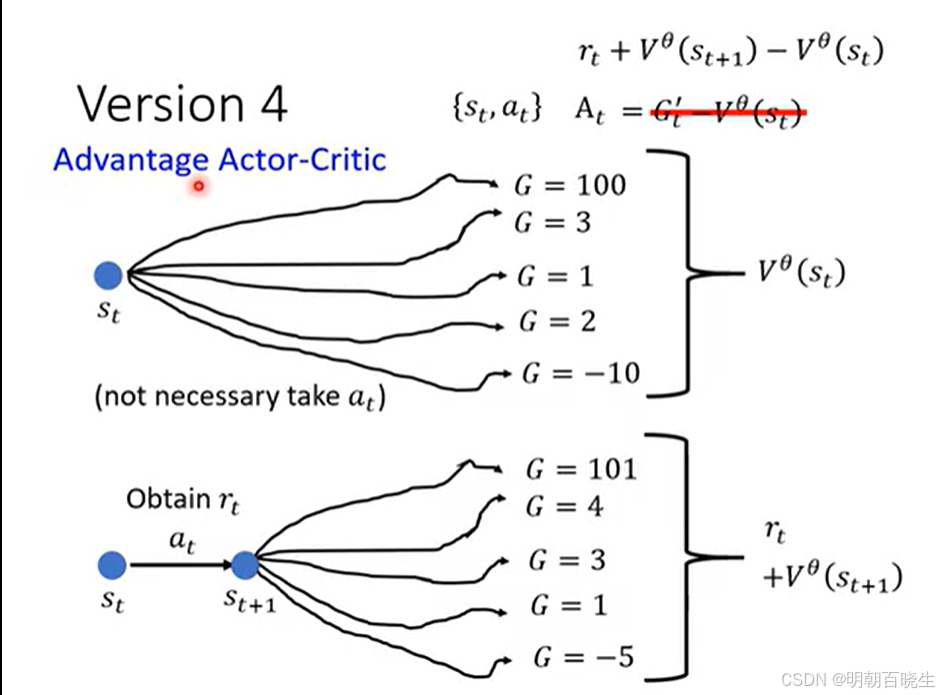
https://www.bilibili.com/video/BV1rRbkz2Egx?spm_id_from=333.788.videopod.sections
五 伪代码
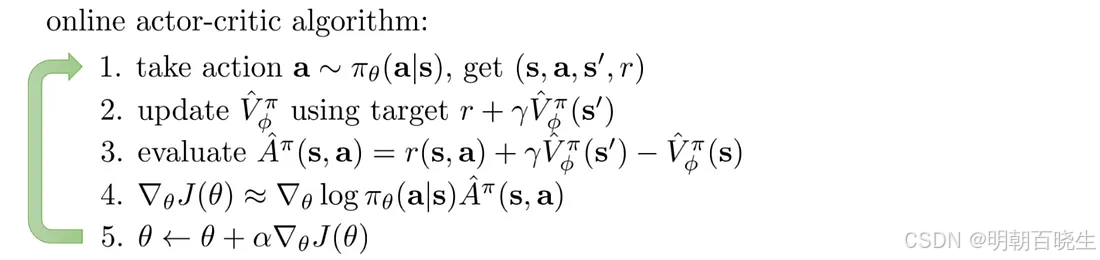
参考:
机器学习2021 | 强化学习概述(二)—— Policy Gradient 与课程心得
视频链接:https://www.bilibili.com/video/BV1CDbkzJEAZ/机器学习2021 | 强化学习概述(三)—— Actor-Critic
视频链接:https://www.bilibili.com/video/BV1rRbkz2Egx机器学习2021 | 强化学习概述(三)—— Actor-Critic(续)
视频链接:https://www.bilibili.com/video/BV1rRbkz2Egx?p=2https://jonathan-hui.medium.com/rl-actor-critic-methods-a3c-gae-ddpg-q-prop-e1c41f268541
必看

开源鸿蒙跨平台开发社区汇聚开发者与厂商,共建“一次开发,多端部署”的开源生态,致力于降低跨端开发门槛,推动万物智联创新。
更多推荐


 12
12 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)