数据采集环境搭建
注意!!!为后续方便,本文提到的三台主机在后续用户都变为了magicat,但在Hadoop软件安装之前的设置大多是按hadoop100-magicat,hadoop101-root,hadoop102-root来进行脚本的代码编写依据的。所以前后用户配置可能会有些微差异。
本人血泪教训,如果你的环境刚开始搭建,最好让各主机用户名统一,能避免非常多的麻烦!
本文中所有指令对应好自己主机情况!不要盲目复制!
一、服务器创建与集群搭建
1.1修改服务器主机名
# 1. 使用hostnamectl设置(立即生效) sudo hostnamectl set-hostname hadoop102 # ✅ 永久性:修改 /etc/hostname 文件,重启后保持 # 2. 确保hosts文件配置正确 echo "127.0.1.1 hadoop102" | sudo tee -a /etc/hosts # ✅ 永久性:直接写入配置文件 # 3. 重新加载shell exec bash # 🔄 临时操作:只是为了立即生效,不影响持久性 # 4. 验证结果 hostname hostnamectl status # 🔄 检查命令:只查看状态
[注:] 永久生效
hadoop102就是你要更新的主机名字
1.2集群搭建
在云主机上配置SSH免密登录
ssh-keygen -t rsa ssh-copy-id hadoop100 ssh-copy-id hadoop101 ssh-copy-id hadoop102
一般这样做即可,但针对主机名不一的情况,例如hadoop100用户为magicat,另外两个都是root。
如果照常输入ssh-copy-id hadoop101会提示拒绝服务,需要在前面加上用户名:
ssh-copy-id root@hadoop101
这是针对用户名与当前主机名字不一致情况用的,下面详细描述我某一台机器配置ssh免密登录流程:
1. 在hadoop100生成密钥对(当前用户magicat)
ssh-keygen -t rsa # 全部按回车使用默认值
生成的文件位于:~/.ssh/id_rsa(私钥)和~/.ssh/id_rsa.pub(公钥)。
2. 分发公钥到三台主机
-
(1)配置hadoop100本机(magicat用户)
将公钥添加到本机的
authorized_keys:ssh-copy-id hadoop100 # 输入magicat用户的密码
-
(2)配置hadoop101(root用户)
需指定目标用户为
root:ssh-copy-id root@hadoop101 # 输入hadoop101的root密码
-
(3)配置hadoop102(root用户)
同样指定目标用户:
ssh-copy-id root@hadoop102 # 输入hadoop102的root密码
关键提醒:
ssh-copy-id默认使用当前用户名(magicat),但hadoop101/102需显式指定root@。如果提示
Permission denied,检查目标主机是否允许root密码登录。如果三台主机名相同就可以不用加上用户名
3. 测试免密登录
# 测试本机(hadoop100) ssh hadoop100 # 无需密码 # 测试hadoop101(以root登录) ssh root@hadoop101 # 应直接登录 # 测试hadoop102 ssh root@hadoop102
注:后面为了脚本编写方便,已将所有用户名统一为magicat。
1.3编写集群分发脚本xsync
需求:循环复制文件到所有节点相同目录下
目的:动态执行指令
1.3.1需求分析
-
rsync命令原始拷贝:
rsync -av /home/magicat/Hadoop_learn_dir/module root@hadoop100:/home/magicat/Hadoop_learn_dir/
-
期望脚本:xsync 要同步的文件名称
-
\color{red}{说明:在/home/magicat/bin这个目录下存放的脚本,magicat用户可以在系统任何地方直接执行}
(base) magicat@hadoop100:~$ echo $PATH /home/magicat/.local/bin:/home/magicat/bin:/usr/local/cuda-12.6/bin:/home/magicat/.nvm/versions/node/v22.12.0/bin:/home/magicat/anaconda3/bin:/home/magicat/anaconda3/condabin:/usr/local/cuda-12.6/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/usr/games:/usr/local/games:/snap/bin:/home/magicat/Hadoop_learn_dir/module/jdk1.8.0_212/bin
1.3.2脚本实现
-
在用户的家目录/home/magicat下创建bin文件夹
-
在/home/magicat/bin目录下创建xsync文件,以便全局调用
-
编写以下代码(用户为root的):
# 定义主机-用户映射(格式:主机名:用户名)
declare -A HOST_USER_MAP=(
["hadoop100"]="magicat"
["hadoop101"]="root"
["hadoop102"]="root"
)
# 1.判断参数个数
if [ $# -lt 1 ]
then
echo Not Enough Argument!
exit;
fi
# 2.遍历集群所有机器
for host in hadoop100 hadoop101 hadoop102
do
user=${HOST_USER_MAP[$host]}
echo "==================== Syncing to $user@$host ===================="
#3.遍历所有目录,挨个发送
for file in $@
do
#4,判断文件是否存在
if [ -e $file ]
then
#5.获取父目录
pdir=$(cd -P $(dirname $file); pwd)
echo "DEBUG: pdir=$pdir"
#6.获取当前文件的名称
fname=$(basename $file)
echo "DEBUG: fname=$fname"
# ========== 关键修改点 ==========
# 动态构建远程路径(保持与本地相同的路径结构)
# 例如:本地 /home/magicat/bin/xsync → 远程 /home/magicat/bin/xsync(用户 magicat)
# 或 /root/bin/xsync(用户 root
if [ "$user" == "magicat" ]; then
# 对于magicat用户,直接使用/root前缀
remote_path="/home/magicat/${pdir#/root/}/$fname"
crdir_path="/home/magicat/${pdir#/root/}"
else
remote_path="${pdir/$HOME/~}/$fname"
crdir_path="${pdir/$HOME/~}"
fi
echo "DEBUG: remote_path=$remote_path"
echo "DEBUG: crdir_path=$crdir_path"
if ssh "$user@$host" "[ ! -d \"$remote_path\" ]"; then
echo "Directory $remote_path does not exist on $host. Creating..."
ssh "$user@$host" "target_dir=\"\$(echo $(dirname "$remote_path"))\"; sudo mkdir -p \$target_dir && sudo chown $user:$user \$target_dir"
else
echo "Directory $remote_path already exists on $host."
fi
echo "remote_dir $(dirname "$remote_path") on $host..."
# rsync -av $pdir/$fname $user@$host:$remote_path
rsync -av --rsync-path="sudo rsync" "$pdir/$fname" "$user@$host:$crdir_path/"
else
echo $file does not exists!
fi
done
done
-
针对magicat用户的:
# 定义主机-用户映射(格式:主机名:用户名) declare -A HOST_USER_MAP=( ["hadoop100"]="magicat" ["hadoop101"]="root" ["hadoop102"]="root" ) # 1.判断参数个数 if [ $# -lt 1 ] then echo Not Enough Argument! exit; fi # 2.遍历集群所有机器 for host in hadoop100 hadoop101 hadoop102 do user=${HOST_USER_MAP[$host]} echo "==================== Syncing to $user@$host ====================" #3.遍历所有目录,挨个发送 for file in $@ do #4,判断文件是否存在 if [ -e $file ] then #5.获取父目录 pdir=$(cd -P $(dirname $file); pwd) #6.获取当前文件的名称 fname=$(basename $file) # ========== 关键修改点 ========== # 动态构建远程路径(保持与本地相同的路径结构) # 例如:本地 /home/magicat/bin/xsync → 远程 /home/magicat/bin/xsync(用户 magicat) # 或 /root/bin/xsync(用户 root if [ "$user" == "root" ]; then # 对于magicat用户,直接使用/root前缀 remote_path="/root/${pdir#/home/magicat/}/$fname" crdir_path="/root/${pdir#/home/magicat/}" else remote_path="${pdir/$HOME/~}/$fname" crdir_path="${pdir/$HOME/~}" fi # 在远程机器创建目录(需sudo权限) echo "Creating directory $(dirname "$remote_path") on $host..." ssh "$user@$host" "target_dir=\"\$(echo $(dirname "$remote_path"))\"; sudo mkdir -p \$target_dir && sudo chown $user:$user \$target_dir" # rsync -av $pdir/$fname $user@$host:$remote_path rsync -av --rsync-path="sudo rsync" "$pdir/$fname" "$user@$host:$crdir_path" else echo $file does not exists! fi done done
1.3.3同步脚本可能会遇到的问题
原分发脚本部分代码:
1.不同主机间有不同用户名
解决办法: 定义主机-用户映射(格式:主机名:用户名)
declare -A HOST_USER_MAP=(
["hadoop100"]="magicat"
["hadoop101"]="root"
["hadoop102"]="root"
)
并且令user=${HOST_USER_MAP[$host]}
然后把每个$host都变为:$user@$host
2. ~ 提前在本地解析
如果当前需要同步的主机是hadoop100用户为magicat
由于各个主机的用户名不一,我们需要转换一下pdir的地址,我们希望所有/home/magicat都变成其他主机上对应用户的家目录:
remote_path="${pdir/$HOME/~}/$fname"
这个语句的作用是将pdir中的$HOME部分(也就是/home/magicat/)替换为~
这样就能对应到各自的家目录了,正常逻辑就是这样。
但我们执行ssh语句ssh $user@$host "mkdir -p $remote_path"时实际上$user@$pdir与$host解析的是当前主机上的信息,如果当前需要同步的主机是hadoop100用户为magicat,即时这个语句是要执行在hadoop101和hadoop102上的,ssh语句中的变量也会提前解析。即执行到其他主机上的语句依然是:
mkdir -p /homr/magicat/要同步的文件或文件夹路径
解决办法:使用硬编码
if [ "$user" == "root" ]; then
# 对于magicat用户,直接使用/root前缀
remote_path="/root/${pdir#/home/magicat/}/$fname"
else
remote_path="${pdir/$HOME/~}/$fname"
fi
3.出现 ~/同步文件夹/同步文件夹/文件内容 的情况
注意我们remote_path的组成:
if [ "$user" == "root" ]; then
# 对于magicat用户,直接使用/root前缀
remote_path="/root/${pdir#/home/magicat/}/$fname"
else
remote_path="${pdir/$HOME/~}/$fname"
fi
我们是加上了我们需要同步文件或文件夹的名字的。这对同步文件没什么大影响,但对于同步文件夹却有很大影响。
假设我们需要同步的文件夹是:~/module/dir1
dir1里有一文件:test.txt
当前主机为hadoop100,用户为magicat
那么:
pdir = /home/magicat/module
fname = dir1
remote_path = /home/magicat/module/dir1
执行同步语句:
rsync -av --rsync-path="sudo rsync" "$pdir/$fname" "$user@$host:$remote_path"
就会出现同步到home/magicat/module/dir1/dir1的情况
原理是rsync在同步目录时,如果目标路径已存在,会在目标路径下创建同名子目录,而我们的remote_path包含了最后的目录名,导致重复创建,正确的remote路径不应该包含dir1,也就是fname。
4.非root用户同步sudo权限问题
我们的hadoop100的用户为magicat,拥有sudo权限,但是如果在别的主机打算同步文件过来而该路径需要创建文件夹时,我们用ssh创建hadoop100的文件夹时需要sudo权限,那么每一次遇到这种情况我们都需要输入密码,甚至可能造成同步失败的结果。
我的解决办法是:magicat用户调用sudo权限无需输入密码。
在命令行输入:
sudo visudo
在最后一行加上:
magicat ALL=(ALL) NOPASSWD: ALL
\color{red}{注意!!修改sudo文件是很危险的行为,谨慎操作!!容易造成sudo语句失效!!!}
如果文件确实改错了
-
无法执行任何
sudo命令:包括修复sudoers文件本身。 -
可能锁死系统管理权限:如果没有其他管理员账户,可能需要单用户模式修复。
解决方案
方法1:通过 pkexec恢复(需要桌面环境)
如果系统有图形界面(如Ubuntu Desktop),可以尝试:
pkexec visudo
输入管理员密码后修复文件。我这次是登上服务器管理平台,靠这个可视化修改的sudo文件,删掉添加进去的语句
方法2:通过 root用户修复
如果已启用 root密码登录:
su - root visudo
二、JDK准备
2.1 数据仓库项目JDK配置建议
核心答案:集群服务器必须保持JDK版本一致!
为什么需要版本一致
-
兼容性问题:Hadoop、Spark等大数据框架对JDK版本敏感
-
运行稳定性:不同节点JDK版本差异可能导致序列化/反序列化错误
-
避免诡异问题:版本不一致可能在某些操作中表现正常,在分布式计算时出现难以排查的问题
2.2 JDK环境搭建
首先,我们确定本次项目所用到的所有软件都放到:Hadoop_learn_dir/software
卸载所有Java相关包
sudo apt purge openjdk-* -y sudo apt autoremove -y
解压
准备好JDK压缩包
tar -zxvf /root/jdk-8u212-linux-x64.tar.gz -C /root/Hadoop_learn_dir/module
# 压缩包所在位置 # 解压到的位置
配置环境变量
nano /etc/profile.d/my_env.sh
export JAVA_HOME=/home/magicat/Hadoop_learn_dir/module/jdk1.8.0_212 export PATH=$PATH:$JAVA_HOME/bin
激活环境变量
source /etc/profile.d/my_env.sh
分发JDK文件
xsync ~/Hadoop_learn_dir/module/jdk1.8.0_212
环境变量配置说明
Linux的环境变量可在多个文件中配置,如/etc/profile , /etc/profile/*.sh , ~/.bashrc , ~/.bash_profile等。
如上我们在/etc/profile.d/my_env.sh创建了一个文件,里面的内容就会自动生效。

三、模拟日志数据生成
我们现在需要准备LogServer中的模拟数据,因为我们并没有一个真实的系统。
3.1模拟日志执行程序
1.创建文件夹并赋予权限
sudo mkdir ~/Hadoop_learn_dir/module/applog chmod 777 ~/Hadoop_learn_dir/module/applog
在UP提供的资料中,找到mock,选取除sql文件外的全部文件,传输到~/Hadoop_learn_dir/module/applog中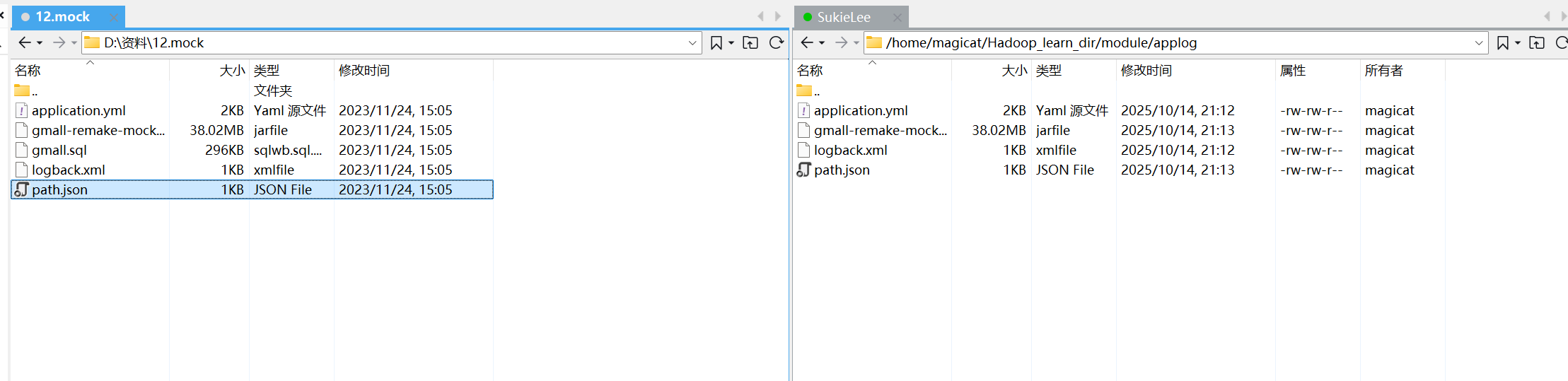
2.修改logback.xml文件
由于与UP设置的路径不同,我们需要修改改文件中日志文件生成的地址部分
<?xml version="1.0" encoding="UTF-8"?>
<configuration>
<property name="LOG_HOME" value="/home/magicat/Hadoop_learn_dir/module/applog/log" />
<appender name="console" class="ch.qos.logback.core.ConsoleAppender">
<target>System.out</target>
<encoder>
<pattern>%msg%n</pattern>
</encoder>
</appender>
<appender name="console_em" class="ch.qos.logback.core.ConsoleAppender">
<target>System.err</target>
<encoder>
<pattern>%msg%n</pattern>
</encoder>
</appender>
<appender name="rollingFile" class="ch.qos.logback.core.rolling.RollingFileAppender">
<file>${LOG_HOME}/app.log</file>
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<fileNamePattern>${LOG_HOME}/app.%d{yyyy-MM-dd}.log</fileNamePattern>
</rollingPolicy>
<encoder>
<pattern>%msg%n</pattern>
</encoder>
</appender>
<!-- 将某一个包下日志单独打印日志 -->
<logger name="com.atguigu.mock.util.LogUtil"
level="INFO" additivity="false">
<appender-ref ref="rollingFile" />
</logger>
<logger name="com.atguigu.gmallre.mock.task.UserMockTask" level="INFO" additivity="false" >
<appender-ref ref="console_em" />
</logger>
<root level="error" >
<appender-ref ref="console_em" />
</root>
</configuration>
3.生成日志
进入到~/Hadoop_learn_dir/module/applog路径,执行以下命令:
java -jar gmall-remake-mock-2023-05-15-3.jar test 100 2022-06-08
① 增加test参数为测试模式,只生成用户行为数据不生成业务数据。
② 100 为产生的用户session数一个session默认产生1条启动日志和5条页面方法日志。
③ 第三个参数为日志数据的日期,测试模式下不会加载配置文件,要指定数据日期只能通过命令行传参实现。
④ 三个参数的顺序必须与示例保持一致
⑤ 第二个参数和第三个参数可以省略,如果test后面不填写参数,默认为1000
后续不会用到了,因为后期需要同时生成行为数据和业务数据
4.问题:logback文件不生效
使用了许多办法,都没有让logback成功生效,也不了解其中原理,绝望的码农最终决定采用迂回的办法:创建软连接
由于执行
java -jar gmall-remake-mock-2023-05-15-3.jar test 100 2022-06-08
程序总是想在/opt/module/applog下创建log文件夹被拒,我最终决定在/opt/目录下创建一个module文件
sudo mkdir /opt/module sudo chmod 777 module
注意!!不要创建applog文件夹,否则后续创建软连接的时候会有问题!
然后为我真正的applog文件夹所在位置:/home/magicat/Hadoop_learn_dir/module/applog创建一个软连接:
sudo ln ~/Hadoop_learn_dir/module/applog/ -s /opt/module/applog # ln 原文件 -s 链接文件
问题解决。
3.2集群日志生成脚本
1.在~/bin目录下创建脚本lg.sh
sudo nano ~/bin/lg.sh
2.在脚本中编写如下内容
#!/bin/bash echo "========== hadoop102 ==========" ssh hadoop102 "cd /opt/module/applog/; nohup java -jar gmall-remake-mock-2023-02-17.jar $1 $2 $3 >/dev/null 2>&1 &"
注:
①/opt/module/applog/为jar包及配置文件所在路径,针对我的情况这里的路径会改为:/home/magicat/Hadoop_learn_dir/module/applog/
②/dev/null代表Linux的空设备文件,所有往这个文件里面写入的内容都会丢失,俗称“黑洞”。
标准输入0:从键盘获得输入 /proc/self/fd/0
标准输出1:输出到屏幕(即控制台) /proc/self/fd/1
错误输出2:输出到屏幕(即控制台) /proc/self/fd/2
给文件赋权:
sudo chmod 777 lg.sh
四、Hadoop软件的安装
4.1 集群命令批量执行脚本
1.在/home/magicat/bin目录下创建脚本xcall
2.在脚本中编写如下内容
# /bin/bash for i in hadoop100 hadoop101 hadoop102 do echo -----------------Now:$i---------------------------- ssh $i "$*" done
3.修改脚本执行权限
chmod 777 xcall
问题:我的每台主机用户名有所差异
解决:要解决三台主机用户名不同的问题,可以通过建立主机名与用户名的映射关系来实现。
以下是修改后的脚本:
#!/bin/bash
declare -A HOST_USER_MAP=(
["hadoop100"]="magicat"
["hadoop101"]="root"
["hadoop102"]="root"
)
for host in hadoop100 hadoop101 hadoop102; do
echo "-----------------Now: $host----------------------------"
# 获取对应用户名
user="${USER_MAP[$host]}"
# 执行远程命令
ssh "$user@$host" "$@"
done
脚本作用:三台机上会同时执行某条你指定的指令
后续执行指令的时候遇到了jsp找不到命令的情况,当时解决问题的时候没有记录,但依稀记得是在形似.bash什么的文件里面加上了JAVA_HOME地址。
4.2安装Hadoop3.3.4
4.2.1解压安装
进入Hadoop安装路径:~/Hadoop_learn_dir/software
解压安装文件到Hadoop_learn_dir/module下面
解压语句:
sudo tar -zxvf hadoop-3.3.4.tar.gz -C ~/Hadoop_learn_dir/module/
4.2.2 将Hadoop添加到环境变量
1.打开编辑/etc/profile.d/my_env.sh 文件
sudo nano /etc/profile.d/my_env.sh
2.在文件末尾添加Hadoop路径:
# HADOOP_HOME export HADOOP_HOME=/home/magicat/Hadoop_learn_dir/module/hadoop-3.3.4 export PATH=$PATH:$HADOOP_HOME/bin export PATH=$PATH:$HADOOP_HOME/sbin
3.分发my_env.sh 文件
xsync /etc/profile.d/my_env.sh
4.在三台主机上分别激活环境变量(或许也可以直接用xcall脚本,这样就不用复制三次了)
source /etc/profile.d/my_env.sh
4.2.3 配置集群
1.核心配置文件core-site.xml
配置core-site.xml
cd $HADOOP_HOME/etc/hadoop sudo nano core-site.xml
文件内容如下:
<?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <!-- 指定NameNode的地址 --> <property> <name>fs.defaultFS</name> <value>hdfs://hadoop100:8020</value> </property> <!-- 指定hadoop数据的存储目录 --> <property> <name>hadoop.tmp.dir</name> <value>/home/magicat/Hadoop_learn_dir/module/hadoop-3.3.4/data</value> </property> <!-- 配置HDFS网页登录使用的静态用户为atguigu --> <property> <name>hadoop.http.staticuser.user</name> <value>atguigu</value> </property> <!-- 配置该atguigu(superUser)允许通过代理访问的主机节点 --> <property> <name>hadoop.proxyuser.atguigu.hosts</name> <value>*</value> </property> <!-- 配置该atguigu(superUser)允许通过代理用户所属组 --> <property> <name>hadoop.proxyuser.atguigu.groups</name> <value>*</value> </property> <!-- 配置该atguigu(superUser)允许通过代理的用户--> <property> <name>hadoop.proxyuser.atguigu.users</name> <value>*</value> </property> </configuration>
注:我的环境中这里的atguigu我都改成了magicat
2.配置HDFS配置文件
配置hdfs-site.xml
sudo nano hdfs-site.xml
文件内容如下:
<?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <!-- nn web端访问地址--> <property> <name>dfs.namenode.http-address</name> <value>hadoop100:9870</value> </property> <!-- 2nn web端访问地址--> <property> <name>dfs.namenode.secondary.http-address</name> <value>hadoop102:9868</value> </property> <!-- 测试环境指定HDFS副本的数量1 --> <property> <name>dfs.replication</name> <value>1</value> </property> </configuration>
3.YARN配置文件
配置yarn-site.xml
sudo nano yarn-site.xml
文件内容如下:
<?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <!-- 指定MR走shuffle --> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <!-- 指定ResourceManager的地址--> <property> <name>yarn.resourcemanager.hostname</name> <value>hadoop100</value> </property> <!-- 环境变量的继承 --> <property> <name>yarn.nodemanager.env-whitelist</name> <value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value> </property> <!--yarn单个容器允许分配的最大最小内存 --> <property> <name>yarn.scheduler.minimum-allocation-mb</name> <value>512</value> </property> <property> <name>yarn.scheduler.maximum-allocation-mb</name> <value>4096</value> </property> <!-- yarn容器允许管理的物理内存大小 --> <property> <name>yarn.nodemanager.resource.memory-mb</name> <value>4096</value> </property> <!-- 关闭yarn对物理内存和虚拟内存的限制检查 --> <property> <name>yarn.nodemanager.pmem-check-enabled</name> <value>true</value> </property> <property> <name>yarn.nodemanager.vmem-check-enabled</name> <value>false</value> </property> </configuration>
4.MapReduce配置文件
配置mapred-site.xml
sudo nano mapred-site.xml
文件内容如下:
<?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <!-- 指定MapReduce程序运行在Yarn上 --> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration>
5.配置workers
sudo nano /opt/module/hadoop/etc/hadoop/workers
在该文件中增加如下内容:
hadoop102 对应我主机上的100 hadoop103 对应我主机上的101 hadoop104 对应我主机上的102
注意:该文件中添加的内容结尾不允许有空格,文件中不允许有空行。
4.3 配置历史服务器
为了查看程序的历史运行情况,需要配置一下历史服务器。具体配置步骤如下:
1)配置mapred-site.xml
sudo nano mapred-site.xml
在该文件里面增加如下配置。
<!-- 历史服务器端地址 --> <property> <name>mapreduce.jobhistory.address</name> <value>hadoop100:10020</value> </property> <!-- 历史服务器web端地址 --> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>hadoop100:19888</value> </property>
4.4 配置日志的聚集
日志聚集概念:应用运行完成以后,将程序运行日志信息上传到HDFS系统上。
日志聚集功能好处:可以方便的查看到程序运行详情,方便开发调试。
\color{red}{注意:开启日志聚集功能,需要重新启动NodeManager 、ResourceManager和HistoryManager。}
开启日志聚集功能具体步骤如下:
配置yarn-site.xml
sudo nano yarn-site.xml
在该文件里面增加如下配置。
<!-- 开启日志聚集功能 --> <property> <name>yarn.log-aggregation-enable</name> <value>true</value> </property> <!-- 设置日志聚集服务器地址 --> <property> <name>yarn.log.server.url</name> <value>http://hadoop100:19888/jobhistory/logs</value> </property> <!-- 设置日志保留时间为7天 --> <property> <name>yarn.log-aggregation.retain-seconds</name> <value>604800</value> </property>
4.5 分发hadoop
xsync ~/Hadoop_learn_dir/module/hadoop-3.3.4/
4.6群起集群
1.启动集群
(1)如果集群是第一次启动,需要在hadoop100节点格式化NameNode(注意格式化之前,一定要先停止上次启动的所有namenode和datanode进程,然后再删除data和log数据)
cd home/magicat/Hadoop_learn_dir/module/hadoop-3.3.4 bin/hdfs namenode -format # -format的作用是格式化namenode
问题: JAVA_HOME does not exist.:
(base) magicat@hadoop100:~/Hadoop_learn_dir/module/hadoop-3.3.4$ bin/hdfs namenode -format ERROR: JAVA_HOME /root/Hadoop_learn_dir/module/jdk1.8.0_212 does not exist.
解决:修改 Hadoop 的 hadoop-env.sh文件
这个文件通常位于 $HADOOP_HOME/etc/hadoop/目录下。
使用文本编辑器打开它:
nano $HADOOP_HOME/etc/hadoop/hadoop-env.sh
找到 JAVA_HOME的设置行(大约在第 54 行左右),取消注释并修改为你的实际 Java 路径(注意,实际上应该在句首加一个export才是最正确的,不然后面还要出错):
JAVA_HOME=/home/magicat/Hadoop_learn_dir/module/jdk1.8.0_212
2.启动HDFS
sbin/start-dfs.sh
同样遇到了java环境问题:
(base) magicat@hadoop100:~/Hadoop_learn_dir/module/hadoop-3.3.4$ sbin/start-dfs.sh Starting namenodes on [hadoop100] hadoop100: ERROR: Unable to write in /home/magicat/Hadoop_learn_dir/module/hadoop-3.3.4/logs. Aborting. Starting datanodes hadoop100: ERROR: Unable to write in /home/magicat/Hadoop_learn_dir/module/hadoop-3.3.4/logs. Aborting. hadoop102: ERROR: JAVA_HOME is not set and could not be found. hadoop101: ERROR: JAVA_HOME is not set and could not be found. Starting secondary namenodes [hadoop102] hadoop102: ERROR: JAVA_HOME is not set and could not be found.
修改 Hadoop 配置文件
发现是之前文件JAVA_HOME前面忘记加export 了
也就是最终应该是这样的:
export JAVA_HOME=/home/magicat/Hadoop_learn_dir/module/jdk1.8.0_212
新问题:Cannot set priority of datanode process
(base) magicat@hadoop100:~/Hadoop_learn_dir/module/hadoop-3.3.4$ sbin/start-dfs.sh Starting namenodes on [hadoop100] Starting datanodes hadoop100: ERROR: Cannot set priority of datanode process 3694729
ERROR: Cannot set priority of datanode process
解决:打开编辑文件,在hadoop-env.sh最后一行加上export语句
nano $HADOOP_HOME/etc/hadoop/hadoop-env.sh export HADOOP_SHELL_EXECNAME=root
3.在配置了ResourceManager节点(hadoop101)启动YARN
sbin/start-yarn.sh
4.检验是否启动成功
xcall jps
输出:
(base) magicat@hadoop100:~/Hadoop_learn_dir/module/hadoop-3.3.4$ xcall jps --------- hadoop100 ---------- 3734159 Jps 3733023 NameNode 1585648 Launcher 3733200 DataNode 1585730 RuoYiApplication 3733894 NodeManager --------- hadoop101 ---------- 207943 Jps 207780 NodeManager 207551 DataNode --------- hadoop102 ---------- 596797 DataNode 597116 NodeManager 596960 SecondaryNameNode 597314 Jps
出现问题,resourcemanager没有出现,可能启动失败,但目前还用不到,以后再说。
Web端查看HDFS的Web页面:http://hadoop100:9870/
Web端查看SecondaryNameNode
① 浏览器中输入:http://hadoop102:9868/status.html
② 查看SecondaryNameNode信息
4.7 Hadoop群起脚本
目的:简化命令
1.在/home/magicat/bin目录下创建hdp.sh
sudo nano ~/bin/hdp.sh
2.写入内容
#!/bin/bash
if [ $# -lt 1 ]
then
echo "No Args Input..."
exit ;
fi
case $1 in
"start")
echo " =================== 启动 hadoop集群 ==================="
echo " --------------- 启动 hdfs ---------------"
ssh hadoop100 "/home/magicat/Hadoop_learn_dir/module/hadoop-3.3.4/sbin/start-dfs.sh"
echo " --------------- 启动 yarn ---------------"
ssh hadoop101 "/home/magicat/Hadoop_learn_dir/module/hadoop-3.3.4/sbin/start-yarn.sh"
echo " --------------- 启动 historyserver ---------------"
ssh hadoop100 "/home/magicat/Hadoop_learn_dir/module/hadoop-3.3.4/bin/mapred --daemon start historyserver"
;;
"stop")
echo " =================== 关闭 hadoop集群 ==================="
echo " --------------- 关闭 historyserver ---------------"
ssh hadoop100 "/home/magicat/Hadoop_learn_dir/module/hadoop-3.3.4/bin/mapred --daemon stop historyserver"
echo " --------------- 关闭 yarn ---------------"
ssh hadoop101 "/home/magicat/Hadoop_learn_dir/module/hadoop-3.3.4/sbin/stop-yarn.sh"
echo " --------------- 关闭 hdfs ---------------"
ssh hadoop100 "/home/magicat/Hadoop_learn_dir/module/hadoop-3.3.4/sbin/stop-dfs.sh"
;;
*)
echo "Input Args Error..."
;;
esac
3.增加权限
sudo chmod 777 ~/bin/hdp.sh
4.启动或停止集群
hdp.sh start hdp.sh stop
五、Zookeeper安装
5.1解压改名
解压
tar -zxvf apache-zookeeper-3.7.1-bin.tar.gz -C ~/Hadoop_learn_dir/module/
改名(原名太长眼花缭乱)
mv apache-zookeeper-3.7.1-bin/ zookeeper-3.7.1
5.2配置服务器编号
1.在~/Hadoop_learn_dir/module/zookeeper-3.7.1目录下创建文件夹
sudo mkdir zkData
注意:记得给文件夹赋权,否则下面启动zookeeper时会出错。
2.在~/Hadoop_learn_dir/module/zookeeper-3.7.1/zkData目录下创建一个myid的文件
sudo nano myid
注意一定要在Linux文件里面创建,在notepad++里面很可能乱码
在文件中添加与server对应的编号
0
5.3配置zoo.cfg文件
5.3.1 重命名配置文件
重命名~/Hadoop_learn_dir/module/zookeeper-3.7.1/conf目录下的zoo_sample.cfg为zoo.cfg(因为原名默认不起作用的)
mv zoo_sample.cfg zoo.cfg
5.3.2 编辑zoo.cfg
1.打开zoo.cfg文件
sudo nano zoo.cfg
2.修改数据存储路径配置
dataDir=/home/magicat/Hadoop_learn_dir/module/zookeeper-3.7.1/zkData
3.增加集群配置
#######################cluster########################## server.0=hadoop100:2888:3888 server.1=hadoop101:2888:3888 server.2=hadoop102:2888:3888
注意server.0,1,2对应的是myid处的值,不要出错!
4.同步zookeeper到其他主机
xsync /home/magicat/Hadoop_learn_dir/module/zookeeper-3.7.1/
5.分别修改另外两台主机上的myid文件
sudo nano ~/Hadoop_learn_dir/module/zookeeper-3.7.1/zkData/myid
6.zoo.cfg配置参数解读
server.A=B:C:D
A是一个数字,表示这个是第几号服务器;
集群模式下配置一个文件myid,这个文件在dataDir目录下,这个文件里面有一个数据就是A的值,Zookeeper启动时读取此文件,拿到里面的数据与zoo.cfg里面的配置信息比较从而判断到底是哪个server。
B是这个服务器的地址;
C是这个服务器Follower与集群中的Leader服务器交换信息的端口;
D是万一集群中的Leader服务器挂了,需要一个端口来重新进行选举,选出一个新的Leader,而这个端口就是用来执行选举时服务器相互通信的端口。
5.4 ZK集群启动停止脚本
5.4.1 创建脚本文件
sudo nano ~/bin/zk.sh
5.4.2 添加如下内容
#!/bin/bash
case $1 in
"start"){
for i in hadoop100 hadoop101 hadoop102
do
echo ---------- zookeeper $i 启动 ------------
ssh $i "/home/magicat/Hadoop_learn_dir/module/zookeeper-3.7.1/bin/zkServer.sh start"
done
};;
"stop"){
for i in hadoop100 hadoop101 hadoop102
do
echo ---------- zookeeper $i 停止 ------------
ssh $i "/home/magicat/Hadoop_learn_dir/module/zookeeper-3.7.1/bin/zkServer.sh stop"
done
};;
"status"){
for i in hadoop100 hadoop101 hadoop102
do
echo ---------- zookeeper $i 状态 ------------
ssh $i "/home/magicat/Hadoop_learn_dir/module/zookeeper-3.7.1/bin/zkServer.sh status"
done
};;
esac
5.4.3 增加脚本执行权限
sudo chmod 777 ~/bin/zk.sh
5.4.4 启动或停止脚本
zk.sh start zk.sh stop
5.4.5 遇见的问题
问题1 JAVA_HOME is not set
(base) magicat@hadoop100:~/Hadoop_learn_dir/module$ zk.sh start ---------- zookeeper hadoop100 启动 ------------ Error: JAVA_HOME is not set and java could not be found in PATH. ---------- zookeeper hadoop101 启动 ------------ Error: JAVA_HOME is not set and java could not be found in PATH. ---------- zookeeper hadoop102 启动 ------------ Error: JAVA_HOME is not set and java could not be found in PATH.
1.出现的原因
来自于zookeeper报错 JAVA_HOME is not set_java home is not set-CSDN博客
zkService 启动的时候,到底做了些什么?
1、启动加载zkEvn文件,
2、启动zkService文件,
也就是说,在zkEvn 文件里面可能有JAVA_HOME 的验证
打开/Hadoop_learn_dir/module/zookeeper-3.7.1/bin/zkEnv.cmd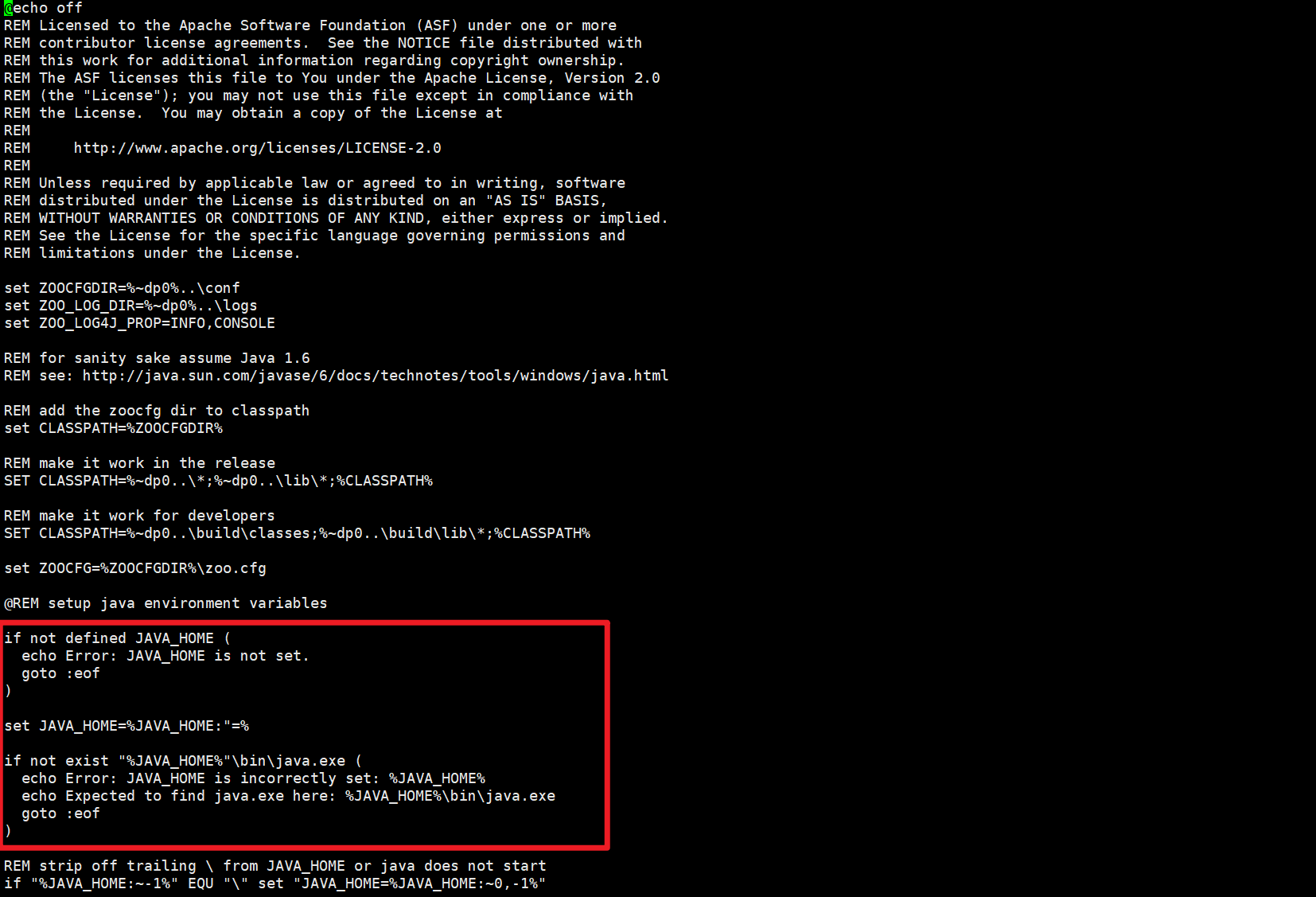
这里有校验!而且校验的时候肯定是不存在的,所以输出错误信息:JAVA_HOME is not set.
2.做过的尝试
# 在 zk.sh 的开头添加: source ~/.bashrc
在 zk.sh中显式指定 JAVA_HOME:
export JAVA_HOME=/your/java/path export PATH=$JAVA_HOME/bin:$PATH
在zkEnv.cmd中添加:
set JAVA_HOME=/home/magicat/Hadoop_learn_dir/module/jdk1.8.0_212
都未成功。
3.成功的解决办法
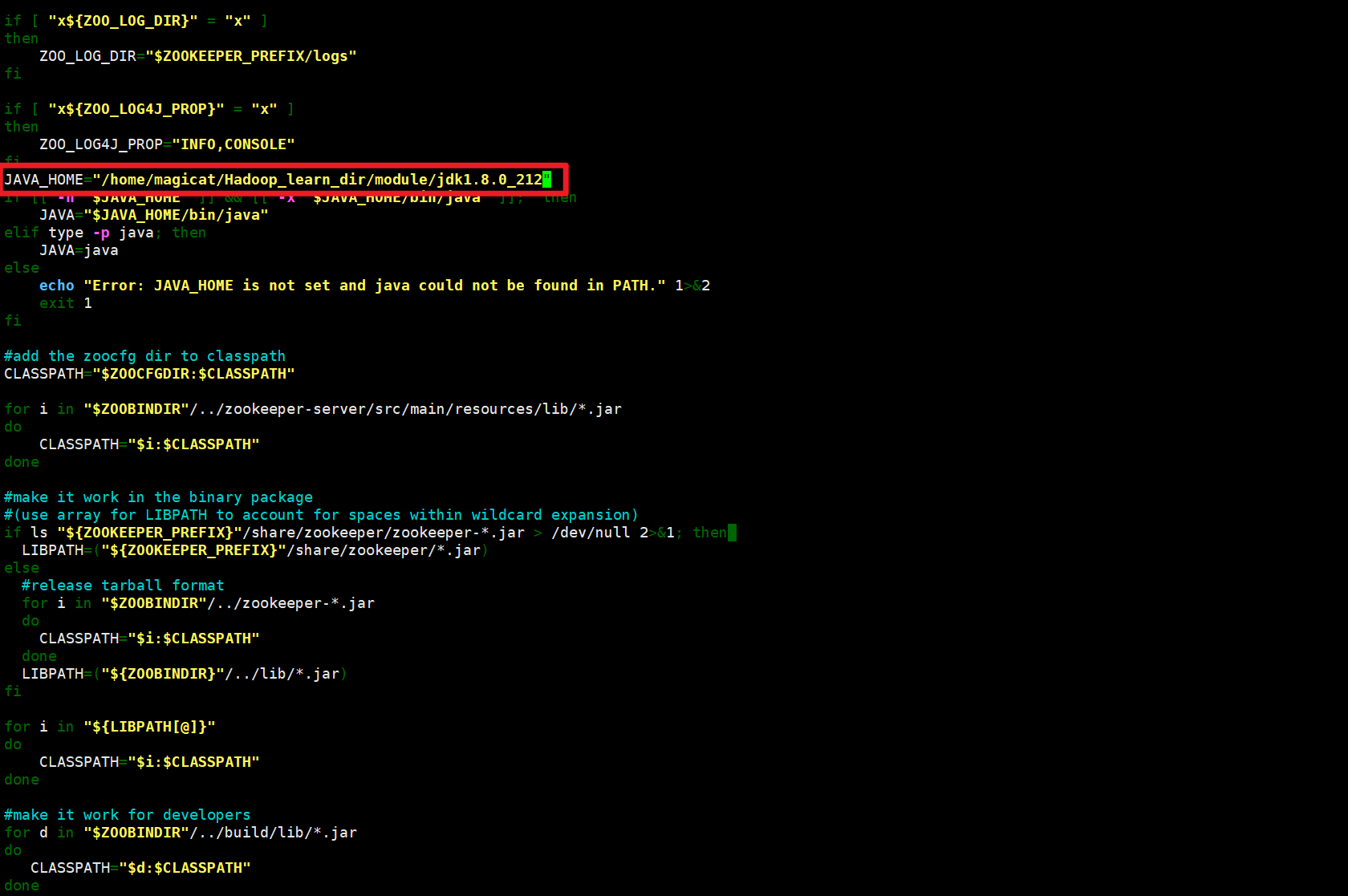
在zkEnv.sh中添加:
JAVA_HOME=/home/magicat/Hadoop_learn_dir/module/jdk1.8.0_212
问题2 FAILED TO WRITE PID
(base) magicat@hadoop100:~/Hadoop_learn_dir/module/zookeeper-3.7.1/bin$ zk.sh start ---------- zookeeper hadoop100 启动 ------------ ZooKeeper JMX enabled by default Using config: /home/magicat/Hadoop_learn_dir/module/zookeeper-3.7.1/bin/../conf/zoo.cfg Starting zookeeper ... /home/magicat/Hadoop_learn_dir/module/zookeeper-3.7.1/bin/zkServer.sh: 行 175: /home/magicat/Hadoop_learn_dir/module/zookeeper-3.7.1/zkData/zookeeper_server.pid: 权限不够 FAILED TO WRITE PID ---------- zookeeper hadoop101 启动 ------------ ZooKeeper JMX enabled by default Using config: /home/magicat/Hadoop_learn_dir/module/zookeeper-3.7.1/bin/../conf/zoo.cfg Starting zookeeper ... /home/magicat/Hadoop_learn_dir/module/zookeeper-3.7.1/bin/zkServer.sh: line 175: /home/magicat/Hadoop_learn_dir/module/zookeeper-3.7.1/zkData/zookeeper_server.pid: Permission denied FAILED TO WRITE PID ---------- zookeeper hadoop102 启动 ------------ ZooKeeper JMX enabled by default Using config: /home/magicat/Hadoop_learn_dir/module/zookeeper-3.7.1/bin/../conf/zoo.cfg Starting zookeeper ... /home/magicat/Hadoop_learn_dir/module/zookeeper-3.7.1/bin/zkServer.sh: line 175: /home/magicat/Hadoop_learn_dir/module/zookeeper-3.7.1/zkData/zookeeper_server.pid: Permission denied FAILED TO WRITE PID
1.出现的原因
这个错误表明 ZooKeeper 无法在 zkData目录下创建或写入 zookeeper_server.pid文件,原因是 权限不足(Permission denied)
ZooKeeper 默认会在 zkData目录下创建 zookeeper_server.pid文件(记录进程 ID)
我们先前忘记了给zkData赋权
2.解决问题
xcall sudo chmod 777 ~/Hadoop_learn_dir//module/zookeeper-3.7.1/zkData/
注:xcall是我们先前写的脚本,功能是使三台主机同时执行一条命令
这样就算启动成功啦~
(base) magicat@hadoop100:~/Hadoop_learn_dir/module/zookeeper-3.7.1/bin$ zk.sh start ---------- zookeeper hadoop100 启动 ------------ ZooKeeper JMX enabled by default Using config: /home/magicat/Hadoop_learn_dir/module/zookeeper-3.7.1/bin/../conf/zoo.cfg Starting zookeeper ... STARTED ---------- zookeeper hadoop101 启动 ------------ ZooKeeper JMX enabled by default Using config: /home/magicat/Hadoop_learn_dir/module/zookeeper-3.7.1/bin/../conf/zoo.cfg Starting zookeeper ... STARTED ---------- zookeeper hadoop102 启动 ------------ ZooKeeper JMX enabled by default Using config: /home/magicat/Hadoop_learn_dir/module/zookeeper-3.7.1/bin/../conf/zoo.cfg Starting zookeeper ... STARTED
(base) magicat@hadoop100:~/Hadoop_learn_dir/module/zookeeper-3.7.1/bin$ xcall jps --------- hadoop100 ---------- 1585648 Launcher 3843632 Jps 1585730 RuoYiApplication 3843366 QuorumPeerMain --------- hadoop101 ---------- 266160 QuorumPeerMain 266344 Jps --------- hadoop102 ---------- 604862 Jps 604675 QuorumPeerMain
5.5客户端常用命令行操作
| 命令基本语法 | 功能描述 |
|---|---|
| help | 显示所有操作命令 |
| ls path | 使用 ls 命令来查看当前znode的子节点 -w 监听子节点变化 -s 附加次级信息 |
| create | 普通创建 -s 含有序列 -e 临时(重启或者超时消失) |
| get path | 获得节点的值 -w 监听节点内容变化 -s 附加次级信息 |
| set | 设置节点的具体值 |
| stat | 查看节点状态 |
| delete | 删除节点 |
| deleteall | 递归删除节点 |
六、Kafka安装
注意,安装启动Kafka前记得启动zookeeper,不启动是不行的。
6.1 解压
tar -zxvf kafka_2.12-3.3.1.tgz -C ~/Hadoop_learn_dir/module/
6.2 修改配置文件
进入~/Hadoop_learn_dir/module/kafka_2.12-3.3.1/config目录,修改server.properties文件
sudo nano server.properties
写入以下内容:
#broker的全局唯一编号,不能重复,只能是数字。 broker.id=0 #broker对外暴露的IP和端口 (每个节点单独配置) advertised.listeners=PLAINTEXT://hadoop100:9092 #处理网络请求的线程数量 num.network.threads=3 #用来处理磁盘IO的线程数量 num.io.threads=8 #发送套接字的缓冲区大小 socket.send.buffer.bytes=102400 #接收套接字的缓冲区大小 socket.receive.buffer.bytes=102400 #请求套接字的缓冲区大小 socket.request.max.bytes=104857600 #kafka运行日志(数据)存放的路径,路径不需要提前创建,kafka自动帮你创建,可以配置多个磁盘路径,路径与路径之间可以用","分隔 log.dirs=/home/magicat/Hadoop_learn_dir/module/kafka_2.12-3.3.1/datas #topic在当前broker上的分区个数 num.partitions=1 #用来恢复和清理data下数据的线程数量 num.recovery.threads.per.data.dir=1 # 每个topic创建时的副本数,默认时1个副本 offsets.topic.replication.factor=1 #segment文件保留的最长时间,超时将被删除 log.retention.hours=168 #每个segment文件的大小,默认最大1G log.segment.bytes=1073741824 # 检查过期数据的时间,默认5分钟检查一次是否数据过期 log.retention.check.interval.ms=300000 #配置连接Zookeeper集群地址(在zk根目录下创建/kafka,方便管理) zookeeper.connect=hadoop100:2181,hadoop101:2181,hadoop102:2181/kafka
重点修改内容:
#broker的全局唯一编号,不能重复,只能是数字。 broker.id=0 #broker对外暴露的IP和端口 (每个节点单独配置) advertised.listeners=PLAINTEXT://hadoop100:9092 #kafka运行日志(数据)存放的路径,路径不需要提前创建,kafka自动帮你创建,可以配置多个磁盘路径,路径与路径之间可以用","分隔 log.dirs=/home/magicat/Hadoop_learn_dir/module/kafka_2.12-3.3.1/datas #配置连接Zookeeper集群地址(在zk根目录下创建/kafka,方便管理) zookeeper.connect=hadoop100:2181,hadoop101:2181,hadoop102:2181/kafka
在下面语句中
zookeeper.connect=hadoop100:2181,hadoop101:2181,hadoop102:2181/kafka
之所以后面带着/kafka是因为一台主机上不一定只有一个Kafka服务,我们用这个来区别不同服务。
6.3分发安装包
进入module目录
xsync kafka_2.12-3.3.1/
6.4 修改其他主机上的配置文件
主要修改broker.id与advertised.listeners两个位置的内容
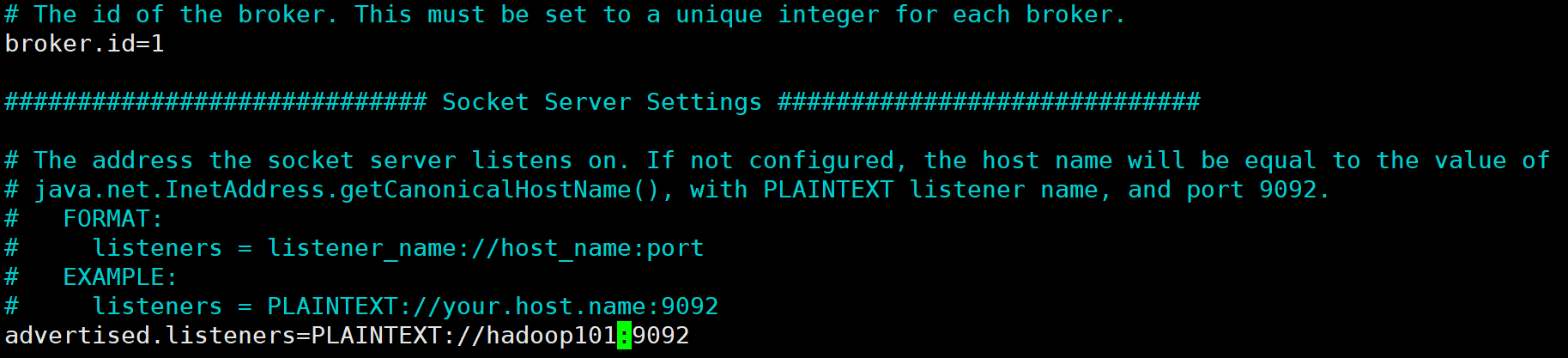
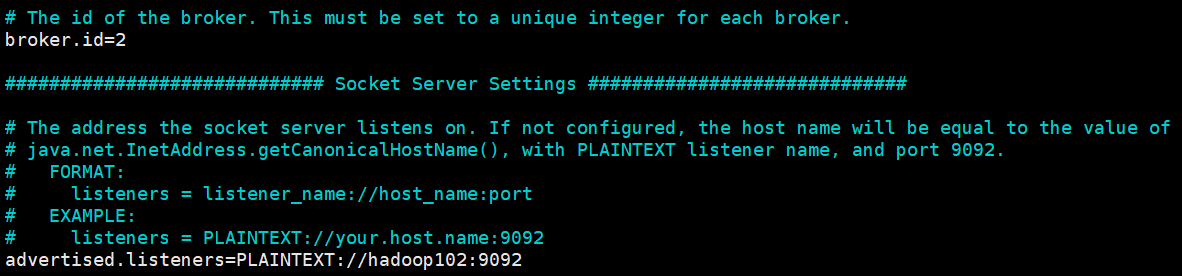
注:broker.id不得重复,整个集群中唯一。
6.5 配置环境变量
(1)在/etc/profile.d/my_env.sh文件中增加kafka环境变量配置
sudo nano /etc/profile.d/my_env.sh
增加如下内容:
#KAFKA_HOME export KAFKA_HOME=/home/magicat/Hadoop_learn_dir/module/kafka_2.12-3.3.1 export PATH=$PATH:$KAFKA_HOME/bin
(2)刷新一下环境变量
source /etc/profile.d/my_env.sh
(3)分发环境变量文件到其他节点,并source。
xsync /etc/profile.d/my_env.sh
6.6 集群启动停止脚本
6.6.1 创建脚本文件
sudo nano ~/bin/kf.sh
脚本内容如下
#! /bin/bash
case $1 in
"start"){
for i in hadoop100 hadoop101 hadoop102
do
echo " --------启动 $i Kafka-------"
ssh $i "/home/magicat/Hadoop_learn_dir/module/kafka_2.12-3.3.1/bin/kafka-server-start.sh -daemon /home/magicat/Hadoop_learn_dir/module/kafka_2.12-3.3.1/config/server.properties"
done
};;
"stop"){
for i in hadoop100 hadoop101 hadoop102
do
echo " --------停止 $i Kafka-------"
ssh $i "/home/magicat/Hadoop_learn_dir/module/kafka_2.12-3.3.1/bin/kafka-server-stop.sh "
done
};;
esac
6.6.2给脚本赋权
sudo chmod 777 ~/bin/kf.sh
6.6.3启动或停止Kafka
kf.sh start kf.sh stop
注意:停止Kafka集群时,一定要等Kafka所有节点进程全部停止后再停止Zookeeper集群。因为Zookeeper集群当中记录着Kafka集群相关信息,Zookeeper集群一旦先停止,Kafka集群就没有办法再获取停止进程的信息,只能手动杀死Kafka进程了。
6.7启动失败问题
6.7.1 启动失败:无法运行命令 'java
magicat@hadoop100:~/Hadoop_learn_dir/module$ kf.sh start --------启动 hadoop100 Kafka------- --------启动 hadoop101 Kafka------- --------启动 hadoop102 Kafka------- magicat@hadoop100:~/Hadoop_learn_dir/module$ xcall jps -m --------- hadoop100 ---------- 3848938 Jps -m 1585648 Launcher spring-boot:run 1585730 RuoYiApplication 3843366 QuorumPeerMain /home/magicat/Hadoop_learn_dir/module/zookeeper-3.7.1/bin/../conf/zoo.cfg --------- hadoop101 ---------- 266160 QuorumPeerMain /home/magicat/Hadoop_learn_dir/module/zookeeper-3.7.1/bin/../conf/zoo.cfg 269931 Jps -m --------- hadoop102 ---------- 606699 Jps -m 604675 QuorumPeerMain /home/magicat/Hadoop_learn_dir/module/zookeeper-3.7.1/bin/../conf/zoo.cfg
没有Kafka对应进程,证明并没有启动成功。
进入日志文件,查看启动失败原因
cd ~/Hadoop_learn_dir/module/kafka_2.12-3.3.1/logs
magicat@hadoop100:~/Hadoop_learn_dir/module/kafka_2.12-3.3.1/logs$ cat kafkaServer.out nohup: 无法运行命令 'java': 没有那个文件或目录
多次发现脚本环境无法加载的情况,这时我决定深入了解并解决这个问题。
解决详情请看第七部分。
6.7.2 成功启动后自动停止服务
1.定位错误
如果 Kafka 启动后过一小会自动停止,可能是由于 配置错误、资源不足、依赖服务异常 等原因导致。Kafka 的日志是最直接的错误来源,默认位于 $KAFKA_HOME/logs/目录下
tail -n 100 $KAFKA_HOME/logs/server.log
或者,得到的核心输出是一样的
grep -i "error\|exception" $KAFKA_HOME/logs/server.log
输出:
[2025-10-19 22:38:58,388] INFO App info kafka.server for 0 unregistered (org.apache.kafka.common.utils.AppInfoParser) [2025-10-19 22:38:58,388] INFO shut down completed (kafka.server.KafkaServer) [2025-10-19 22:38:58,388] ERROR Exiting Kafka due to fatal exception during startup. (kafka.Kafka$) kafka.zookeeper.ZooKeeperClientTimeoutException: Timed out waiting for connection while in state: CONNECTING at kafka.zookeeper.ZooKeeperClient.$anonfun$waitUntilConnected$3(ZooKeeperClient.scala:254) at kafka.zookeeper.ZooKeeperClient.waitUntilConnected(ZooKeeperClient.scala:250) at kafka.zookeeper.ZooKeeperClient.<init>(ZooKeeperClient.scala:108) at kafka.zk.KafkaZkClient$.apply(KafkaZkClient.scala:1980) at kafka.zk.KafkaZkClient$.apply(KafkaZkClient.scala:1967) at kafka.server.KafkaServer.initZkClient(KafkaServer.scala:503) at kafka.server.KafkaServer.startup(KafkaServer.scala:203) at kafka.Kafka$.main(Kafka.scala:109) at kafka.Kafka.main(Kafka.scala) [2025-10-19 22:38:58,389] INFO shutting down (kafka.server.KafkaServer)
错误核心点:
kafka.zookeeper.ZooKeeperClientTimeoutException: Timed out waiting for connection while in state: CONNECTING
2.可能的原因
(1) 网络或防火墙阻断
-
Kafka 节点无法访问 ZooKeeper 的
2181端口。 -
测试连通性:
telnet hadoop100 2181 # 从 Kafka 节点执行
magicat@hadoop100:~/Hadoop_learn_dir/module/kafka_2.12-3.3.1/logs$ telnet hadoop101 2181 Trying 172.16.203.172... Connected to hadoop101. Escape character is '^]'. Connection closed by foreign host.
测试结果来看,虽然 telnet hadoop101 2181能成功建立连接,防火墙未阻断,但连接后立即被关闭(Connection closed by foreign host)表明 ZooKeeper 服务虽然监听端口,但拒绝或无法维持连接。
该原因排除,重点查看zookeeper日志。
(2) ZooKeeper 服务未运行
-
ZooKeeper 进程未启动或崩溃。
-
检查方法:
# 检查 ZooKeeper 进程 jps | grep QuorumPeerMain---进程存在查看 ZooKeeper 日志 tail -n 50 zookeeper文件夹下logs(注意每个人文件名可能有所不同)
tail -n 50 zookeeper-magicat-server-hadoop100.out
输出:
2025-10-19 22:57:09,845 [myid:0] - WARN [QuorumConnectionThread-[myid=0]-564:QuorumCnxManager@401] - Cannot open channel to 1 at election address hadoop101/172.16.203.172:3888 java.net.ConnectException: 拒绝连接 (Connection refused) at java.net.PlainSocketImpl.socketConnect(Native Method) at java.net.AbstractPlainSocketImpl.doConnect(AbstractPlainSocketImpl.java:350) at java.net.AbstractPlainSocketImpl.connectToAddress(AbstractPlainSocketImpl.java:206) at java.net.AbstractPlainSocketImpl.connect(AbstractPlainSocketImpl.java:188) at java.net.SocksSocketImpl.connect(SocksSocketImpl.java:392) at java.net.Socket.connect(Socket.java:589) at org.apache.zookeeper.server.quorum.QuorumCnxManager.initiateConnection(QuorumCnxManager.java:384) at org.apache.zookeeper.server.quorum.QuorumCnxManager$QuorumConnectionReqThread.run(QuorumCnxManager.java:458) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) at java.lang.Thread.run(Thread.java:748)
从日志来看,ZooKeeper 集群节点之间无法建立通信,具体错误是 hadoop101的选举端口 3888被拒绝连接
-
问题本质:ZooKeeper 节点
hadoop100(myid=0)无法连接到节点hadoop101(myid=1)的选举端口3888。 -
可能原因:
hadoop101的 ZooKeeper 服务未启动。防火墙或网络阻断3888端口。hadoop101的zoo.cfg配置错误(如绑定 IP 或端口不匹配)。主机名解析错误(如/etc/hosts或 DNS 配置问题)。
3.解决问题
测试联通性:
magicat@hadoop100:~/Hadoop_learn_dir/module/zookeeper-3.7.1/logs$ telnet hadoop101 3888 Trying 172.16.203.172... telnet: Unable to connect to remote host: Connection refused
极有可能是端口未开放,开放端口:
sudo ufw allow 3888
重启zookeeper后发现还是存在一摸一样的错误
错误本质:hadoop100(myid=0)无法连接到 hadoop101(myid=1)的选举端口 3888。
继续分析,检查 ZooKeeper 绑定 IP
问题场景:ZooKeeper 可能绑定了 127.0.0.1而非 0.0.0.0,导致外部节点无法连接。
-
验证方法:
# 检查监听的 IP 地址 netstat -tulnp | grep 3888如果输出为127.0.0.1:3888,说明绑定到了本地回环地址,需修改配置。 -
解决方案:在
zoo.cfg中显式指定 IP(或确保绑定到0.0.0.0):# 在 zoo.cfg 中添加(替换为实际 IP) quorumListenOnAllIPs=true`
修改完后同步zoo.cfg文件,重启zookeeper,再次尝试启动Kafka,成功!
七、ssh远程连接主机脚本环境变量问题
7.1 profile、profile.d、profile.d/my_env.sh三者关系
在 Linux 系统中,/etc/profile、/etc/profile.d/目录和 /etc/profile.d/my_env.sh文件都与 系统级环境变量和 Shell 初始化 相关,但它们的作用范围和执行顺序不同。以下是它们的区别和联系:
1. /etc/profile
作用
-
系统全局环境变量配置文件,对所有用户(使用
bash或shShell 的用户)生效。 -
在用户登录时执行(仅一次),用于设置 PATH、JAVA_HOME、CLASSPATH 等全局环境变量。
-
通常由系统管理员维护,不建议普通用户直接修改。
执行时机
-
当用户通过 登录 Shell(login shell) 登录时(如
su - username或 SSH 登录),/etc/profile会被自动加载。
示例内容
# /etc/profile 示例(部分内容) export PATH=/usr/local/bin:$PATH export JAVA_HOME=/usr/lib/jvm/java-11-openjdk
2. /etc/profile.d/目录
作用
-
存放系统级 Shell 初始化脚本的目录,用于模块化管理环境变量和别名(
alias)。 -
该目录下的所有
.sh文件会在/etc/profile执行时被 按字母顺序依次加载。 -
目的是避免所有配置都写在
/etc/profile中,便于管理和维护。
特点
-
文件名通常以
.sh结尾(如my_env.sh)。 -
只有 root 用户 可以修改此目录下的文件。
-
适合存放不同软件的环境变量配置(如 Hadoop、Java、Kafka 等)。
示例
# /etc/profile.d/my_env.sh export HADOOP_HOME=/opt/hadoop export PATH=$HADOOP_HOME/bin:$PATH
3. /etc/profile.d/my_env.sh
作用
-
是
/etc/profile.d/目录下的一个自定义环境变量脚本。 -
用于存放 特定应用或服务的环境变量(如 Hadoop、Spark、Java 等)。
-
通过分文件管理,避免
/etc/profile过于臃肿。
示例
# /etc/profile.d/java.sh export JAVA_HOME=/usr/lib/jvm/java-11-openjdk export PATH=$JAVA_HOME/bin:$PATH
三者的关系与执行顺序
-
用户登录时,Shell 会按以下顺序加载配置:
/etc/profile → /etc/profile.d/*.sh → ~/.bash_profile → ~/.bashrc -
/etc/profile是主入口,会主动调用/etc/profile.d/下的所有.sh文件。 -
/etc/profile.d/my_env.sh是模块化配置,方便单独管理某个软件的环境变量。
使用场景对比
| 配置文件 | 适用场景 |
|---|---|
/etc/profile |
存放所有用户共享的全局变量(如系统默认 PATH),但不宜过多,避免维护困难。 |
/etc/profile.d/*.sh |
推荐方式!按软件分文件管理(如 java.sh、hadoop.sh),便于维护和升级。 |
~/.bash_profile |
用户个人环境变量(仅对当前用户生效),优先级高于 /etc/profile。 |
~/.bashrc |
用户个人的 Shell 交互配置(如别名、函数),每次打开终端都会加载。 |
注:以上内容大部分源自AI,如有不对,欢迎指出。
7.2 ssh登录bash模式解析
绝大部分内容来自ssh连接远程主机执行脚本的环境变量问题_c# 远程执行sh文件,环境变量有问题-CSDN博客
7.2.1 non-interactive + non-login shell
该模式为非交互非登陆的shell,创建这种shell典型有两种方式:
-
bash script.sh
-
ssh user@remote command(当前脚本命令形式)
对于这种模式而言,它会去寻找环境变量BASH_ENV,将变量的值作为文件名进行查找,如果找到便加载它。
7.2.2 环境加载测试
测试该环境变量未定义时配置文件的加载情况,这里需要一个测试脚本:
user@remote > cat ~/script.sh echo Hello World
然后运行bash script.sh,将得到以下结果:
Hello World
从输出结果可以得知,这个新启动的bash进程并没有加载前面提到的任何配置文件。接下来设置环境变量BASH_ENV:
user@remote > export BASH_ENV=~/.bashrc
设置环境变量 BASH_ENV的值为当前用户的 ~/.bashrc文件路径
再次执行bash script.sh,结果为:
@ /home/user/.bashrc Hello World
果然,~/.bashrc被加载,而它是由环境变量BASH_ENV设定的。
7.3 做出的尝试
在介绍完bash的这些模式之后,我们再回头来看前面的问题。ssh user@remote ~/myscript.sh属于non-login + non-interactive。对于这种模式,bash会选择加载$BASH_ENV的值所对应的文件,所以为了让它加载/etc/profile,可以在三台主机设定:
xcall export BASH_ENV=/etc/profile
然后执行上面的命令,但是很遗憾,发现错误依旧存在。这是怎么回事?别着急,这并不是我们前面的介绍出错了。仔细查看之后才发现脚本myscript.sh的第一行为#!/usr/bin/env sh,注意看,它和前面提到的#!/usr/bin/env bash不一样,可能就是这里出了问题。我们先尝试把它改成#!/usr/bin/env bash,再次执行,错误果然消失了,这与我们前面的分析结果一致。(博主原话)
我的my_env.sh文件第一行没有什么#!语句,我按博主在第一行加了#!/usr/bin/env bash并没有效果
我的脚本第一行为#! /bin/bash,跟着博主改了变成#! /bin/bash --login之后依旧没有效果。T.T
我没招了,真没招了,到底有没有人跟我一样情况成功的,求借鉴!
7.4 成功解决
不管怎样我最后都没能自动加载出来/etc/profile,最后采用了迂回的办法:
在脚本里ssh语句中带上source /etc/profile,既然你自动加载不了,那我就手动加载!!!
最终kf.sh内容为:
#! /bin/bash
case $1 in
"start"){
for i in hadoop100 hadoop101 hadoop102
do
echo " --------启动 $i Kafka-------"
ssh $i "source /etc/profile;/home/magicat/Hadoop_learn_dir/module/kafka_2.12-3.3.1/bin/kafka-server-start.sh -daemon /home/magicat/Hadoop_learn_dir/module/kafka_2.12-3.3.1/config/server.properties"
done
};;
"stop"){
for i in hadoop100 hadoop101 hadoop102
do
echo " --------停止 $i Kafka-------"
ssh $i "source /etc/profile;/home/magicat/Hadoop_learn_dir/module/kafka_2.12-3.3.1/bin/kafka-server-stop.sh "
done
};;
esac
(之前xcall脚本也是出现类似环境加载不进来的问题,最终也是靠source /etc/profile;解决的)
最后,修改过的文件记得同步哦。
八、Flume安装与介绍
8.1 解压
tar -zxf apache-flume-1.10.1-bin.tar.gz -C ~/Hadoop_learn_dir/module/

8.2 改写配置文件
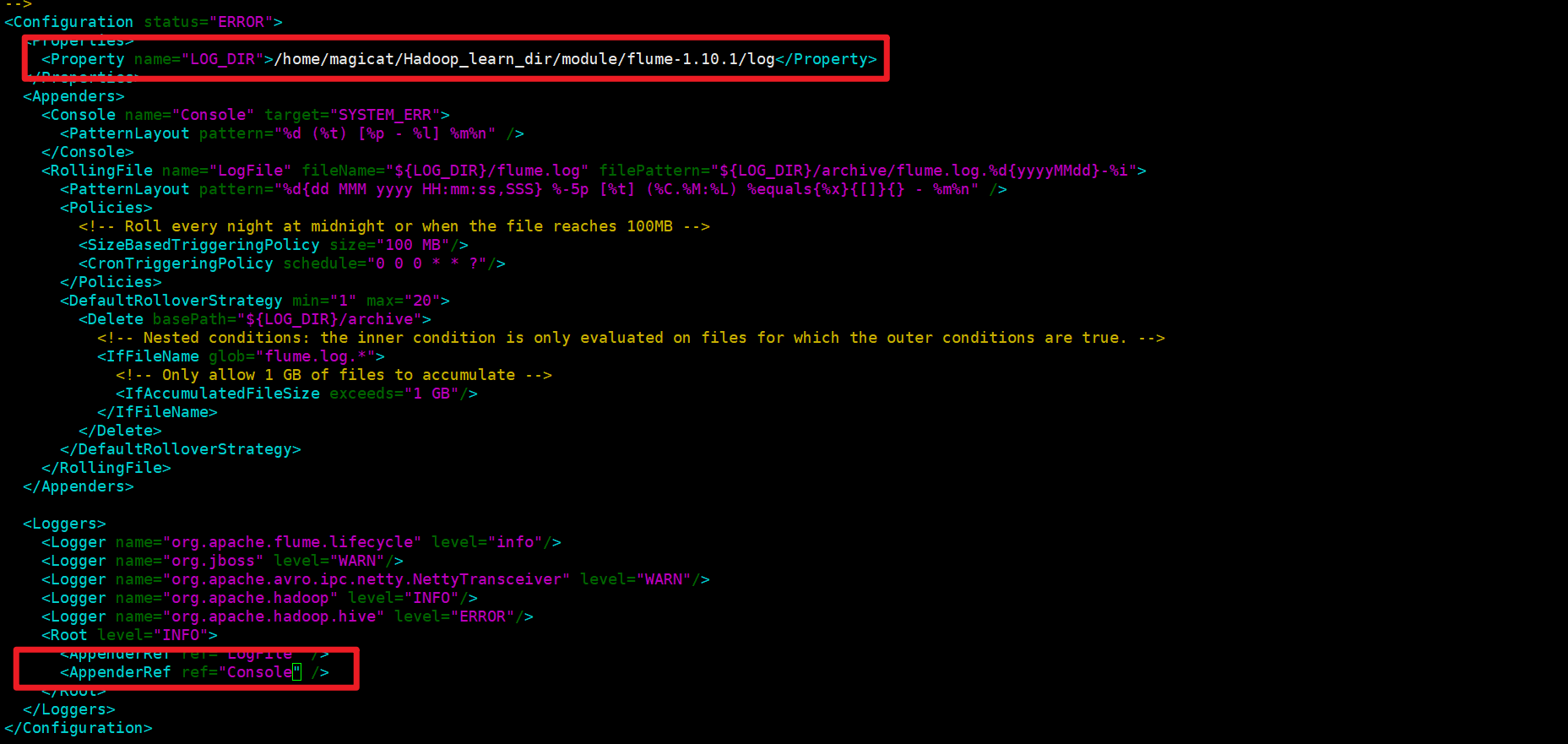
sudo nano flume-1.10.1/conf/log4j2.xml
主要修改以下内容:
<Property name="LOG_DIR">/home/magicat/Hadoop_learn_dir/module/flume-1.10.1/log</Property> ... <AppenderRef ref="Console" /> # Console,表示打印到控制台的意思
九、日志采集Flume
9.1 日志采集Flume配置概述
按照规划,需要采集的用户行为日志文件存放在hadoop100,故需要在该节点配置日志采集Flume。
日志采集Flume需要采集日志文件内容,并对日志格式(JSON)进行校验,然后将校验通过的日志发送到Kafka。
(为什么要校验?JSON具有严格的格式要求,一旦格式不正确会影响到后续程序异常)
此处可选择TaildirSource和KafkaChannel,并配置日志校验拦截器。
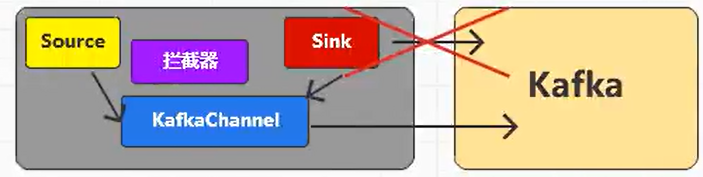
选择TailDirSource和KafkaChannel的原因如下:
1)TailDirSource
TailDirSource相比ExecSource、SpoolingDirectorySource的优势。
TailDirSource:断点续传、多目录。Flume1.6以前需要自己自定义Source记录每次读取文件位置,实现断点续传。
ExecSource可以实时搜集数据,但是在Flume不运行或者Shell命令出错的情况下,数据将会丢失。
SpoolingDirectorySource监控目录,支持断点续传。
2)KafkaChannel(可直接将数据放进Kafka)
采用Kafka Channel,省去了Sink,提高了效率。
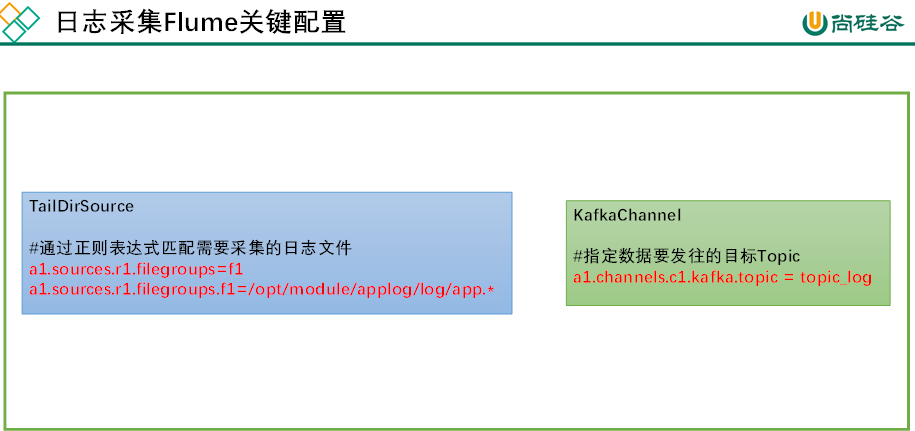
日志采集Flume关键配置如下:
9.2 日志采集Flume配置实操
1.创建Flume配置文件
在hadoop100节点的Flume的job目录下创建file_to_kafka.conf
(base) magicat@hadoop100:~/Hadoop_learn_dir/module/flume-1.10.1$ sudo mkdir job (base) magicat@hadoop100:~/Hadoop_learn_dir/module/flume-1.10.1$ sudo nano job/file_to_kafka.conf
2.配置文件内容
#定义组件 a1.sources = r1 a1.channels = c1 #配置source a1.sources.r1.type = TAILDIR a1.sources.r1.filegroups = f1 a1.sources.r1.filegroups.f1 = /home/magicat/Hadoop_learn_dir/module/applog/log/app.* a1.sources.r1.positionFile = /home/magicat/Hadoop_learn_dir/module/flume-1.10.1/taildir_position.json #配置channel a1.channels.c1.type = org.apache.flume.channel.kafka.KafkaChannel a1.channels.c1.kafka.bootstrap.servers = hadoop100:9092,hadoop101:9092 a1.channels.c1.kafka.topic = topic_log a1.channels.c1.parseAsFlumeEvent = false #组装 a1.sources.r1.channels = c1
a1.channels.c1.parseAsFlumeEvent = false是什么意思呢?
parse -解析
as 作为
所以意思是把数据解析为FlumeEvent ,给了false值,为什么不用这么做?
答:Flume的底层数据为Event
Event header(可有可无) body(可以理解为数据)
Source获取了数据会包装成Event,意味着Source会把Event发给Channel,那么问题就出现了,别人从我们的Kafka取出的数据会是Event了,但Event别人用不上,Event是Flume的内部结构,内部结构不应在外部使用,为了避免这种情况,我们设置:
a1.channels.c1.parseAsFlumeEvent = false
9.3 日志采集Flume测试
前置操作
注意:这里默认为最开始的环境,即所有服务都还未启动,applog日志文件也都为空。
所以要把前面安装环境时启动的服务暂停,生成的日志删除。
kf.sh stop zk.sh stop sudo rm home/magicat/Hadoop_learn_dir/module/applog/log/app.log
1.启动Zookeeper、Kafka集群
zk.sh start kf.sh start
2.启动hadoop100的日志采集Flume
进入Flume安装目录
bin/flume-ng agent -n a1 -c conf/ -f job/file_to_kafka.conf
3.启动一个Kafka的Console-Consumer
bin/kafka-console-consumer.sh --bootstrap-server hadoop102:9092 --topic topic_log
之后的2,3步会用脚本来做
4.生成数据
执行集群日志生成脚本。
lg.sh test 100
出现问题:
再次运行这条指令applog/log下没有app.log文件!
可能的原因(根据弹幕采集):
①applog下的jar包名字与教学视频内的名字不一样(日期),我们直接复制up脚本会因为找不到jar包而生成失败(之前我能正常生成日志,应该不是这个原因)
②applog用户为root,脚本没有权限(我先前777了这个文件夹,并且成功生成过日志)
③思来想去,当时测试脚本时并没有删除原来的app.log文件,所以可能在前面这个脚本就没有成功过,我打开脚本内容一看,心下了然:
#!/bin/bash echo "========== hadoop100 ==========" ssh hadoop100 "cd /home/magicat/Hadoop_learn_dir/module/applog/; nohup java -jar gmall-remake-mock-2023-05-15-3.jar $1 $2 $3 >/dev/null 2>&1 &"
没有source /etc/profile啊!找不到 JAVA_HOME怎么启动jar包!
(为什么要source /etc/profile请看第七部分关于ssh连接环境变量那部分内容)
正确版脚本:
#!/bin/bash echo "========== hadoop100 ==========" ssh hadoop100 "source /etc/profile;cd /home/magicat/Hadoop_learn_dir/module/applog/; nohup java -jar gmall-remake-mock-2023-05-15-3.jar $1 $2 $3 >/dev/null 2>&1 &"
5.观察Kafka消费者是否能消费到数据
进入Kafka Tool工具,配置连接我们的集群
我的配置如下:
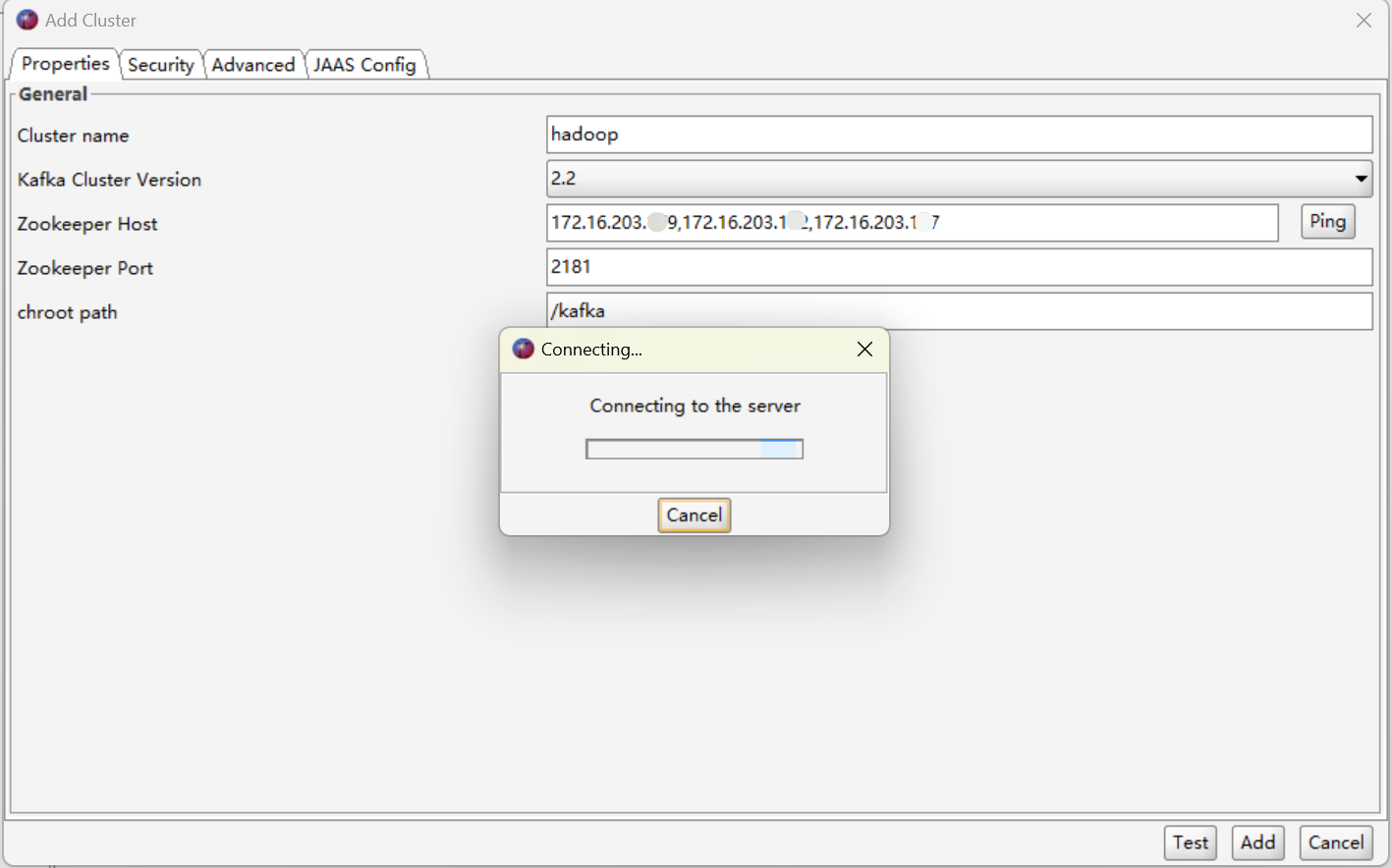
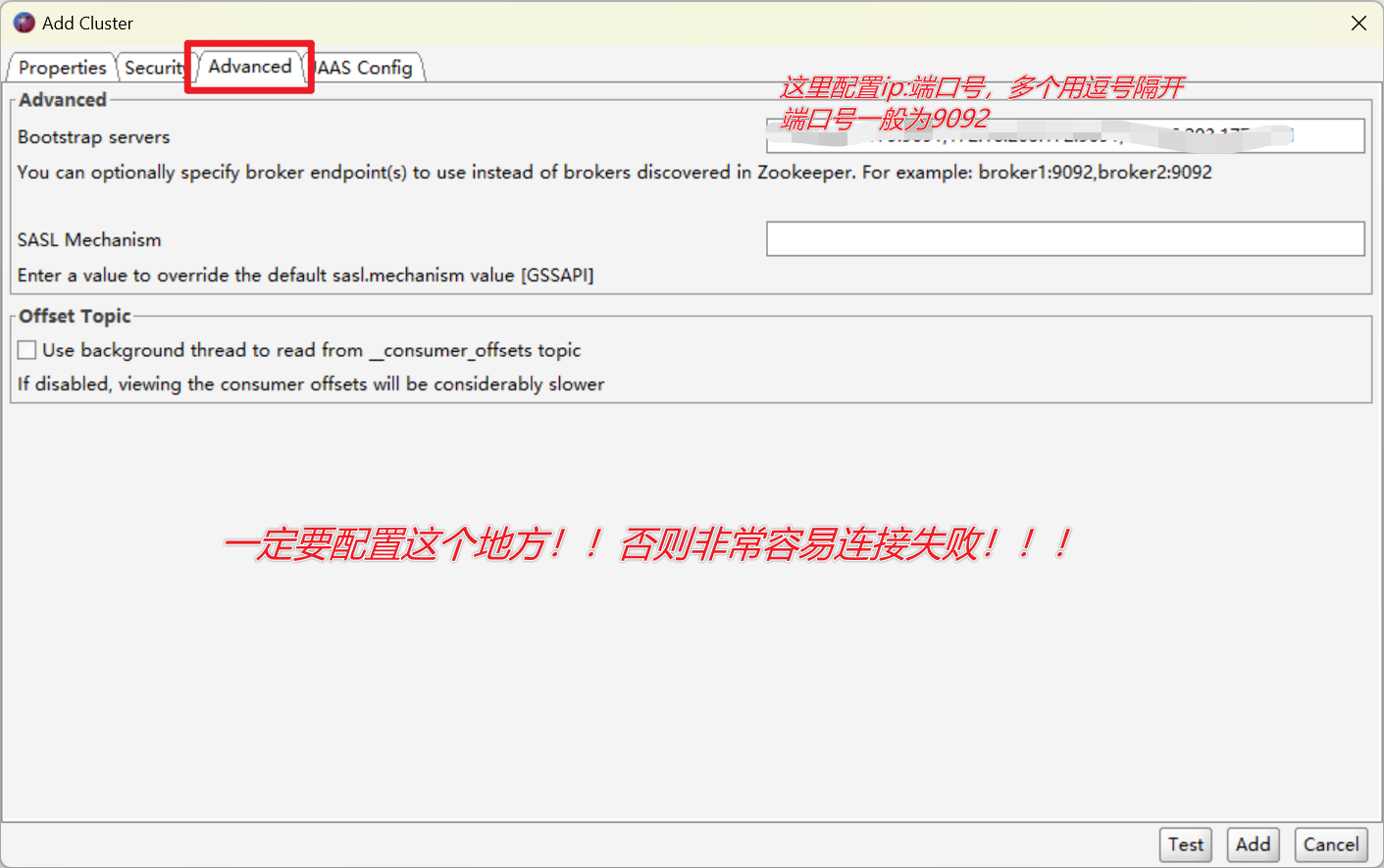
想确定自己的端口号可以在/Hadoop_learn_dir/module/kafka_2.12-3.3.1/config目录下,查看server.properties
主要查看这一设置:
#broker对外暴露的IP和端口 (每个节点单独配置) advertised.listeners=PLAINTEXT://hadoop100:9092
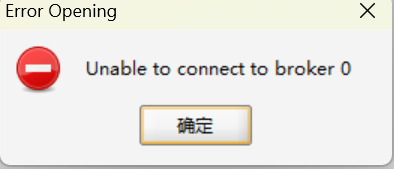
出现问题:Unable to connect to broker 0
完成配置后想查看我的log文件,被提示:
去Kafka Tool安装文件目录下查看错误日志,发现:
20/十月/2025 23:21:39.495 WARN org.apache.kafka.clients.NetworkClient - [AdminClient clientId=adminclient-5] Error connecting to node hadoop100:9092 (id: 0 rack: null) java.net.UnknownHostException: hadoop100 at java.net.InetAddress.getAllByName0(InetAddress.java:1281) at java.net.InetAddress.getAllByName(InetAddress.java:1193) at java.net.InetAddress.getAllByName(InetAddress.java:1127) at org.apache.kafka.clients.ClientUtils.resolve(ClientUtils.java:104) at org.apache.kafka.clients.ClusterConnectionStates$NodeConnectionState.currentAddress(ClusterConnectionStates.java:403) at org.apache.kafka.clients.ClusterConnectionStates$NodeConnectionState.access$200(ClusterConnectionStates.java:363) at org.apache.kafka.clients.ClusterConnectionStates.currentAddress(ClusterConnectionStates.java:151) at org.apache.kafka.clients.NetworkClient.initiateConnect(NetworkClient.java:955) at org.apache.kafka.clients.NetworkClient.ready(NetworkClient.java:289) at org.apache.kafka.clients.admin.KafkaAdminClient$AdminClientRunnable.sendEligibleCalls(KafkaAdminClient.java:969) at org.apache.kafka.clients.admin.KafkaAdminClient$AdminClientRunnable.run(KafkaAdminClient.java:1184) at java.lang.Thread.run(Thread.java:748)
UnknownHostException: hadoop100表示系统无法解析hadoop100地址
原因
我的主机是云服务器,系统为Linux,而我现在在本地Windows系统,虽然连接时配置的是具体的ip地址,但zookeeper内部通信还是靠hadoop100等化名,我们需要在Windows本地配置hosts文件,以便于工具能解析hadoop100地址。
解决问题
在开始菜单搜索cmd,如图以管理员身份运行
在命令行输入:
notepad C:\Windows\System32\drivers\etc\hosts
在文件最下面添加内容:
ip地址 hadoop100 ip地址 hadoop101 ip地址 hadoop102
保存,再回来看就正常了。
另外,如果Message显示异常:
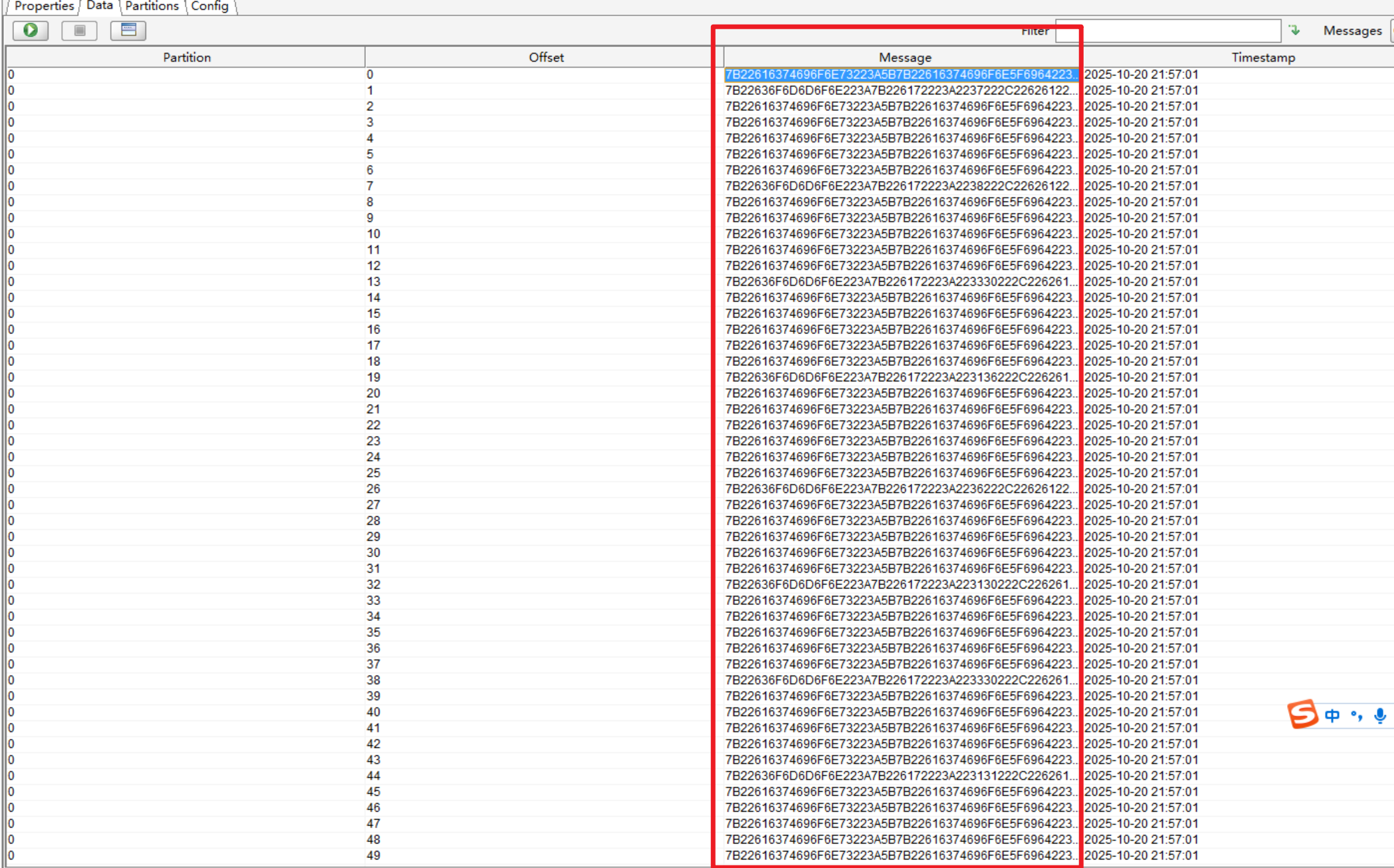
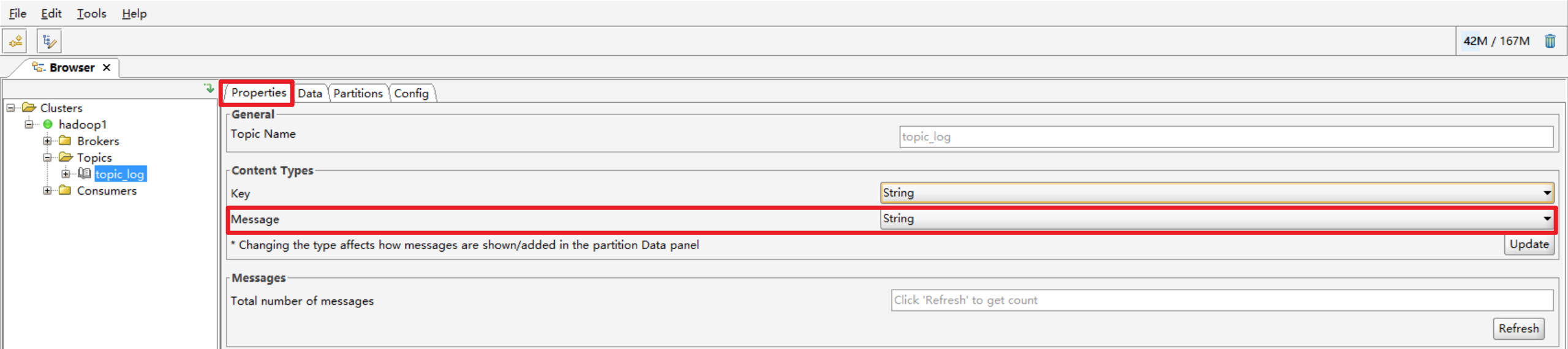
在这里设置一下string就OK了。
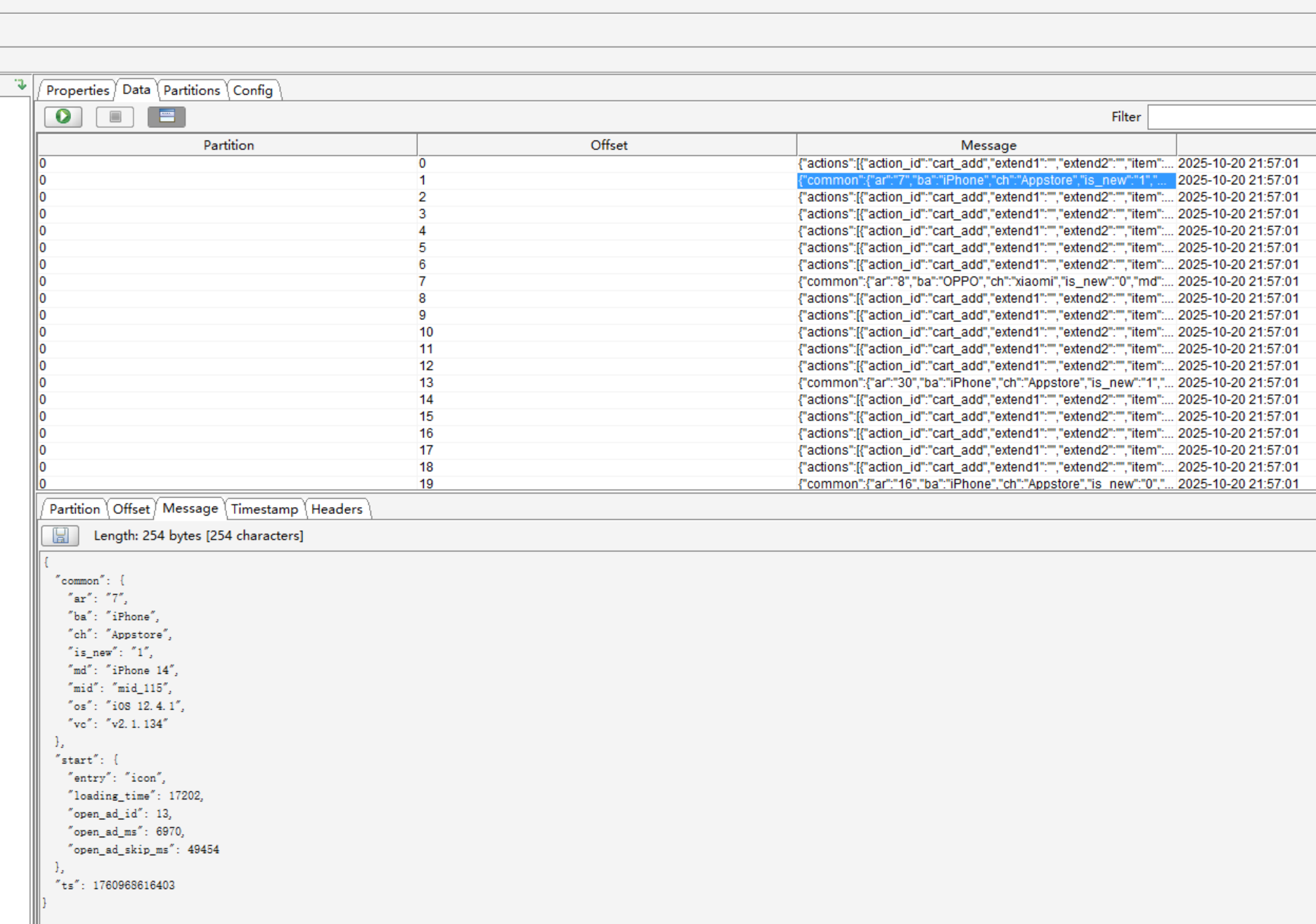
有这些数据代表已经采集成功了~恭喜恭喜~
9.4 日志采集Flume启停脚本
1.在hadoop100节点的/home/magicat/bin目录下创建脚本f1.sh
sudo nano ~/bin/f1.sh
在脚本中添加如下内容:
#!/bin/bash
case $1 in
"start"){
echo " --------启动 hadoop100 采集flume-------"
ssh hadoop100 "source /etc/profile;nohup /home/magicat/Hadoop_learn_dir/module/flume-1.10.1/bin/flume-ng agent -n a1 -c /home/magicat/Hadoop_learn_dir/module/flume-1.10.1/conf/ -f /home/magicat/Hadoop_learn_dir/module/flume-1.10.1/job/file_to_kafka.conf >/dev/null 2>&1 &"
};;
"stop"){
echo " --------停止 hadoop100 采集flume-------"
ssh hadoop100 "source /etc/profile;ps -ef | grep file_to_kafka | grep -v grep |awk '{print \$2}' | xargs -n1 kill -9 "
};;
esac
2.增加脚本执行权限
sudo chmod 777 ~/bin/f1.sh
3.f1启动与停止
f1.sh start f1.sh stop
启动时看看进程中有没有新增一个Application,一般有就是成功了
(base) magicat@hadoop100:~/Hadoop_learn_dir/module/flume-1.10.1$ f1.sh start --------启动 hadoop100 采集flume------- (base) magicat@hadoop100:~/Hadoop_learn_dir/module/flume-1.10.1$ xcall jps -m --------- hadoop100 ---------- 3900735 Application -n a1 -f /home/magicat/Hadoop_learn_dir/module/flume-1.10.1/job/file_to_kafka.conf 3900269 Kafka /home/magicat/Hadoop_learn_dir/module/kafka_2.12-3.3.1/config/server.properties 3900924 Jps -m 1585648 Launcher spring-boot:run 3899681 QuorumPeerMain /home/magicat/Hadoop_learn_dir/module/zookeeper-3.7.1/bin/../conf/zoo.cfg 1585730 RuoYiApplication --------- hadoop101 ---------- 300612 Kafka /home/magicat/Hadoop_learn_dir/module/kafka_2.12-3.3.1/config/server.properties 300961 Jps -m 300074 QuorumPeerMain /home/magicat/Hadoop_learn_dir/module/zookeeper-3.7.1/bin/../conf/zoo.cfg --------- hadoop102 ---------- 620040 Jps -m 619137 QuorumPeerMain /home/magicat/Hadoop_learn_dir/module/zookeeper-3.7.1/bin/../conf/zoo.cfg 619731 Kafka /home/magicat/Hadoop_learn_dir/module/kafka_2.12-3.3.1/config/server.properties

开源鸿蒙跨平台开发社区汇聚开发者与厂商,共建“一次开发,多端部署”的开源生态,致力于降低跨端开发门槛,推动万物智联创新。
更多推荐
 15
15 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)