具身智能的“数据破局”:InternData-A1 如何证明合成数据可媲美真实数据?
摘要: 上海人工智能实验室与北京大学联合提出的 InternData-A1 是目前规模最大、保真度最高的机器人操作合成数据集,包含63万条轨迹(7433小时),覆盖4种机器人构型和70个复杂任务。通过自动化流水线生成,其成本低至每条轨迹0.003美元。实验证明,仅用该合成数据预训练的模型性能媲美基于真实数据训练的SOTA模型(如π₀),尤其在灵巧任务中表现突出。研究还量化了仿真与真实数据的“汇率”
引言:机器人学习的“数据饥渴”
在过去的一年里,Vision-Language-Action (VLA) 模型(如 RT-2、 π 0 \pi_0 π0)展现了令人惊叹的通用能力。然而,这些模型的背后是极其昂贵的代价:大规模真实机器人数据的采集。
与训练 LLM 的文本数据不同,高质量的机器人操作数据(Trajectory)极其稀缺。依靠人工遥操作(Teleoperation)采集数据,不仅效率低、成本高,而且很难覆盖长尾场景。
这就引出了一个核心问题:我们能否利用仿真引擎(Simulation)生成无限的高质量数据,来替代昂贵的真实数据?
以往的答案往往是“不仅能,但不够好”。因为 Sim-to-Real Gap(虚实鸿沟)始终存在。但今天介绍的这篇来自上海人工智能实验室与北京大学的最新工作 InternData-A1,给出了一个颠覆性的结论:高质量的合成数据,在预训练阶段完全可以媲美、甚至将来可能替代真实世界数据集。
论文题目:InternData-A1: Pioneering High-Fidelity Synthetic Data for Pre-training Generalist Policy
论文链接:https://alphaxiv.org/abs/2511.16651
数据链接:https://huggingface.co/datasets/InternRobotics/InternData-A1
项目主页:https://internrobotics.github.io/interndata-a1.github.io/
1. InternData-A1 是什么?
InternData-A1 是目前规模最大、保真度最高、任务最丰富的机器人操作合成数据集之一。

核心数据指标
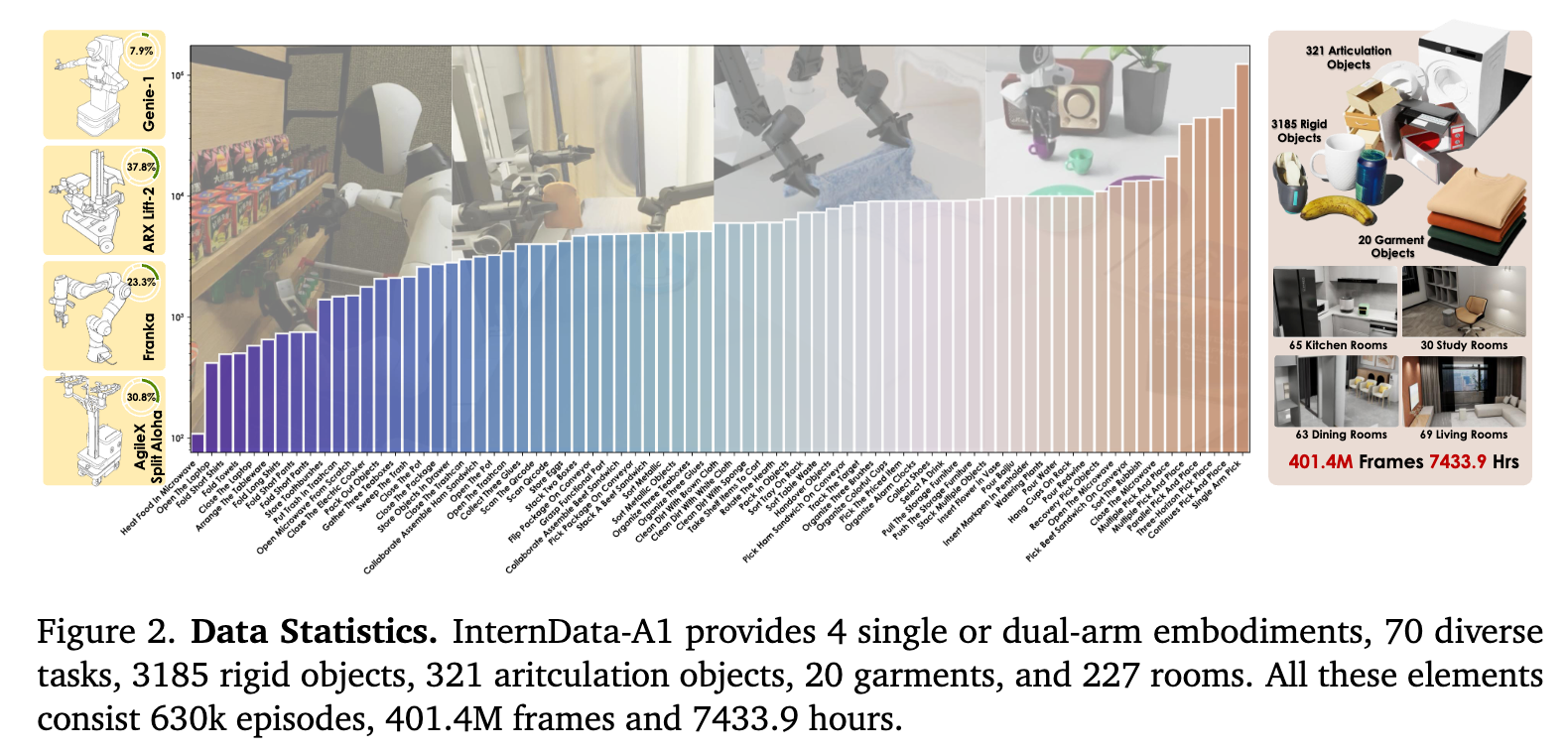
让我们先看一组震撼的数字:
- 规模:包含 63 万 条轨迹,总时长 7433 小时。
- 多样性:
- 4 种机器人构型:不仅有单臂(Franka),还有双臂(Aloha, ARX, Genie),这一点非常关键,因为双臂协作数据在开源界极缺。
- 70 个任务 & 227 个场景:覆盖了从简单的抓取,到复杂的倒水(流体)、折叠衣服(柔性物体)、开关微波炉(关节物体)。
- 物理真实性:它是首个在 VLA 规模上同时涵盖刚体、关节体、流体和变形体的数据集。
相比于之前的 ManiSkill2 或 RoboCasa,InternData-A1 不再局限于刚体抓取,而是真正迈向了复杂的物理交互。
2. 它是如何生成的?自动化的流水线
生成 60 多万条高质量数据,靠人工手动摆放场景是不可能的。作者团队设计了一套完全解耦、高度自动化的生成pipeline。
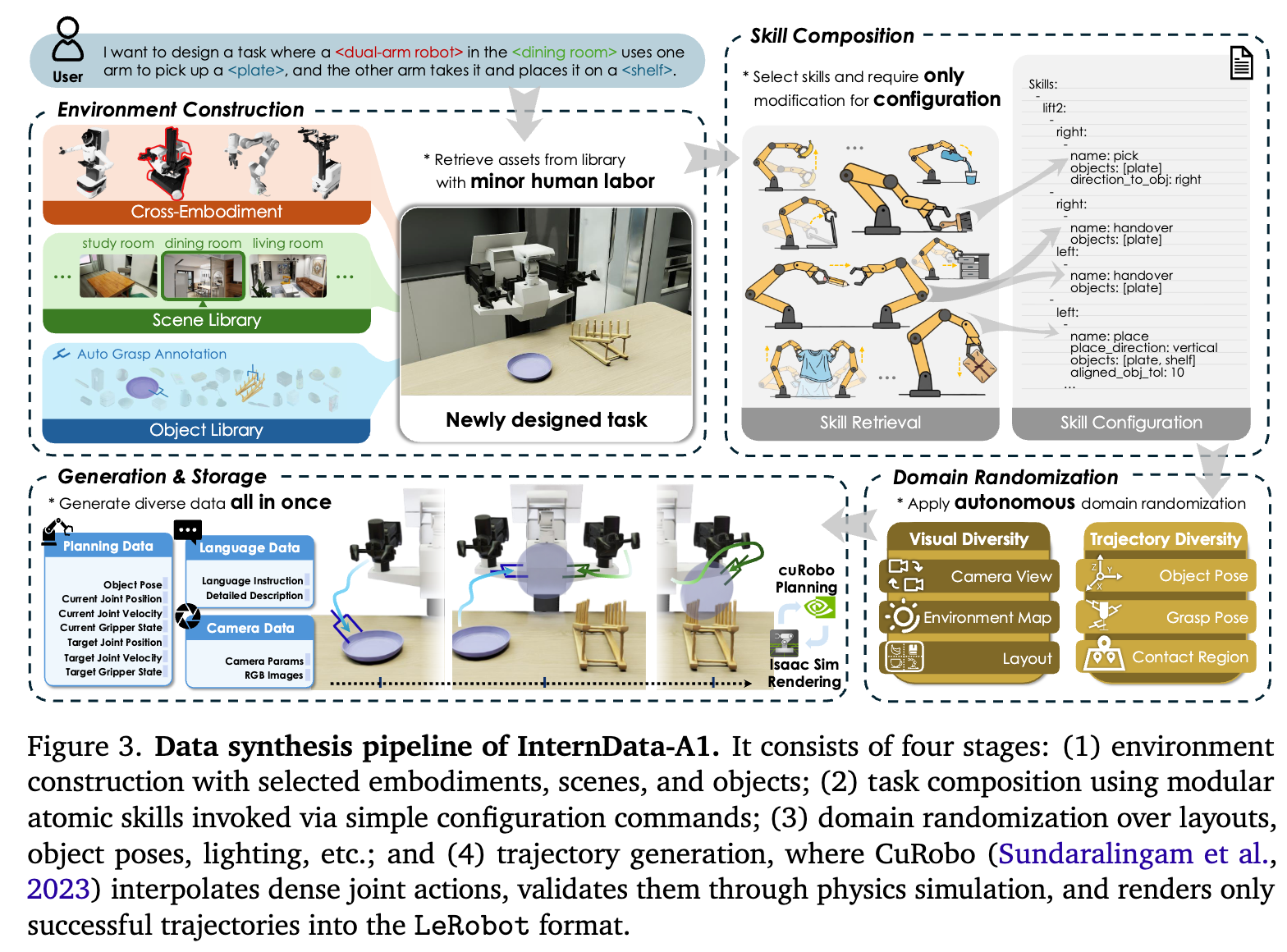
这个pipeline的核心设计哲学是 “组合性”(Compositionality):
- 原子技能(Atomic Skills):系统不直接定义复杂的“做三明治”任务,而是定义“抓取”、“移动”、“倾倒”、“按压”等 18 种基础技能。
- 任务编排:通过配置文件,像搭积木一样将这些技能组合成复杂的长程任务(Long-horizon tasks)。
- 极致优化:为了解决渲染慢的问题,他们将 运动规划(Planning) 和 视觉渲染(Rendering) 解耦。规划失败的轨迹直接丢弃,不进行渲染,从而节省算力。
- 效率:在 8 张 RTX 4090 上,每天可生成 209.7 小时 的数据。
- 成本:每条轨迹的生成成本低于 0.003 美元。
3. 核心验证:合成数据真的能打吗?
这是这篇论文最硬核的部分。为了验证合成数据的有效性,作者做了一个极具挑战性的对比实验:
- 红方:官方的 π 0 \pi_0 π0 模型(使用 π \pi π-dataset,这是目前公认最强的真实世界机器人数据集,但未开源)。
- 蓝方:使用相同架构,但仅使用 InternData-A1 合成数据从头预训练的模型。
实验结果
结果令人惊讶:在真实世界的测试中,蓝方(合成数据)与红方(真实数据)打成了平手!
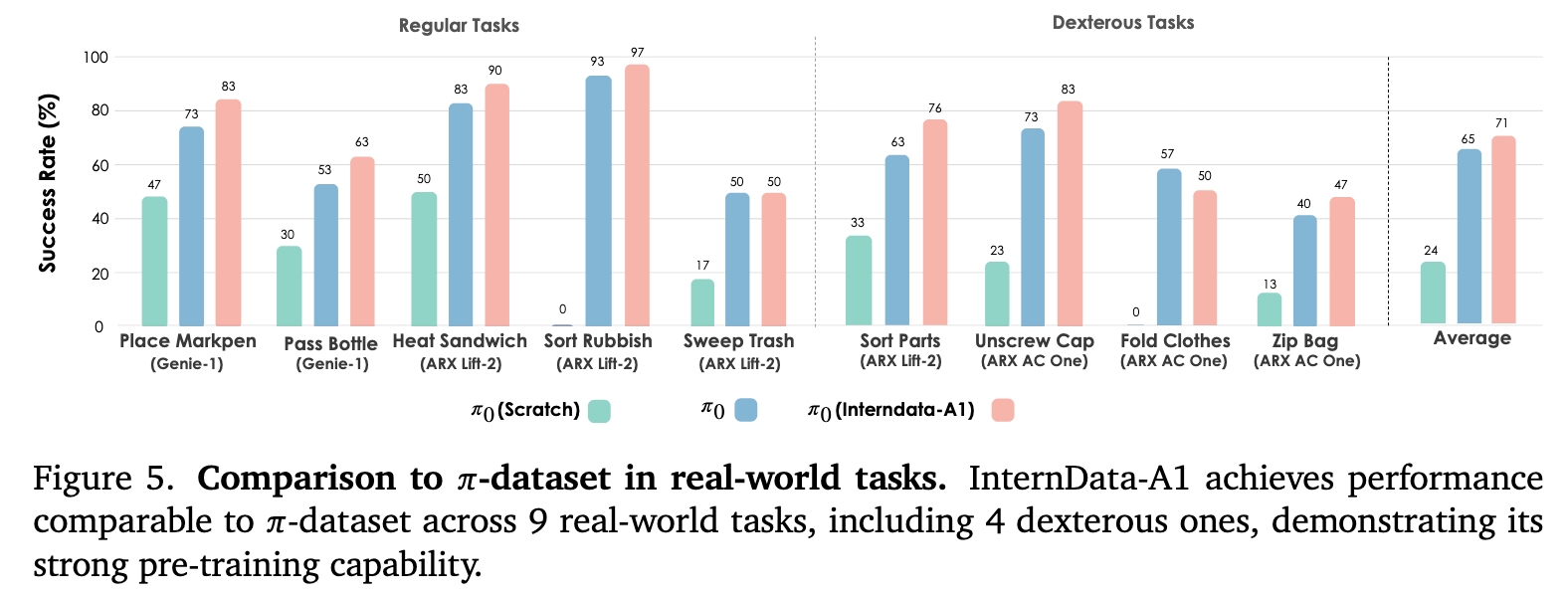
- 常规任务:在垃圾分类、递瓶子等任务上,InternData-A1 模型甚至略优于 π \pi π-dataset。
- 灵巧/长程任务:在折叠衣物、拧瓶盖等极具挑战的任务上,纯合成数据训练的模型展现了极强的泛化能力,成功率与真实数据训练的模型相当。
- 对比开源数据集:相比于使用 Open X-Embodiment (OXE) 或 RoboCasa 训练的模型,InternData-A1 呈现出碾压式的优势(平均提升 50% 以上)。
这一结果打破了业界的刻板印象,证明了只要仿真做得足够好,合成数据完全可以替代真实数据进行 VLA 的预训练(Pre-training)。
4. 深度洞察:Sim-to-Real 的“汇率”是多少?
如果我们想用仿真数据替代真实数据,具体的比例是多少?作者进行了一项有趣的定量分析。
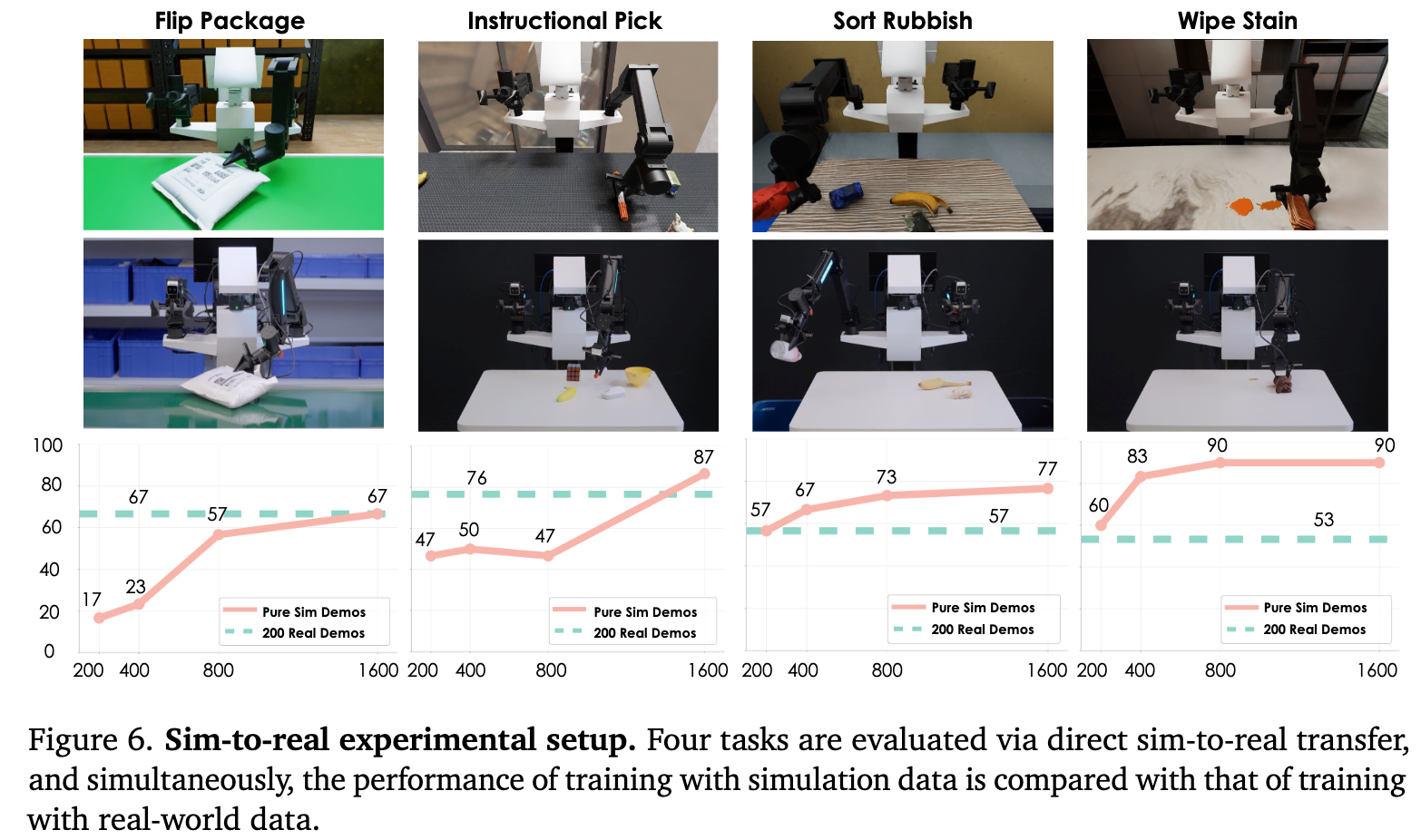
实验表明:
- 对于简单任务(如擦桌子):200 条 仿真数据 ≈ \approx ≈ 200 条 真实数据。
- 对于复杂任务(如需要语言理解的抓取):1600 条 仿真数据 ≈ \approx ≈ 200 条 真实数据。
这意味着,Sim-to-Real 的数据 “汇率”大约在 1:1 到 8:1 之间。考虑到仿真数据的生成成本几乎为零,这个“汇率”是非常划算的!只要我们能以低成本生成海量数据,就能弥补真实数据的不足。
此外,作者还发现,并不需要 1:1 地复刻真实场景。只要摄像机视角和机器人构型对齐,广泛的域随机化(Domain Randomization)(如随机改变光照、桌子纹理)足以让模型忽略仿真与现实的视觉差异。
5. 总结与展望
InternData-A1 不仅仅是一个数据集,它更像是一个风向标。它告诉我们:
- 合成数据的主流化:在 VLA 时代,合成数据将不再是“配菜”,而是“主食”。
- 开源的价值:鉴于 π \pi π-dataset 是闭源的,InternData-A1 的开源将极大地降低具身智能研究的门槛,让没有大规模机器人集群的实验室也能训练 SOTA 级别的模型。
- 多模态物理交互:未来的仿真必须包含流体和柔性物体,单纯的刚体抓取已经不足以支撑通用的具身智能。
项目开源情况:作者承诺将开源数据集以及数据生成管线。对于想要通过仿真扩展数据规模的研究者来说,这绝对是一个值得关注的资源。
如果您对这篇论文感兴趣,欢迎在评论区讨论。您认为合成数据最终能彻底取代真实数据的采集吗?

开源鸿蒙跨平台开发社区汇聚开发者与厂商,共建“一次开发,多端部署”的开源生态,致力于降低跨端开发门槛,推动万物智联创新。
更多推荐
 27
27 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)