【Hung-yi Lee】《Introduction to Generative Artificial Intelligence》(5)
图片来自于 midjourney。

图片来自于 midjourney
Introduction to Generative AI 2024 Spring
第10講:今日的語言模型是如何做文字接龍的 — 淺談Transformer(24.05.03)



ChatGPT 的 T 就是 Transformer 的 T


语言模型是以 token 作为单位来对文字进行处理
token 也可以自动获取,eg Byte Pair Encoding 方法

从字符级别出发,通过不断合并高频相邻对,逐步构建子词(Subword)词表。
WordPiece (Google 方案):BPE 选择频率最高的对,而 WordPiece 选择能最大程度提升语言模型似然概率的对
Unigram Language Model:。它先初始化一个巨大的词表,然后根据概率模型不断剔除对整体似然贡献最小的 Token,直到缩减到预设范围。
| 方法 | 核心逻辑 | 典型代表 |
|---|---|---|
| BPE | 基于频率 合并字符 | GPT 系列, Llama, RoBERTa |
| WordPiece | 基于似然概率 合并字符 | BERT |
| Unigram | 从大词表不断裁剪低效词 | T5, Alpa |

上面展示了实际的例子,每一种颜色表示一个 token
token 是事先定好的

意思相近的 token 会有接近的 embedding

token 转化为 embedding,上面 PPT 没有考虑上下文


position embedding 可以由人来设计,也可以 learning

contextualized token embedding

attention is all you need,不是发明了 attention,而是发现不需要 RNN,只需要 attention 就够了

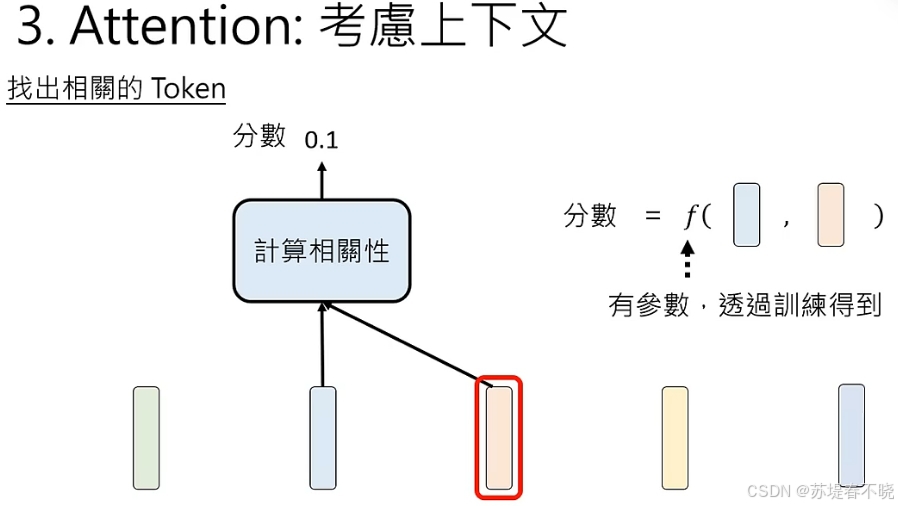

attention weight


计算所有 token 两两间的相关性

实际只会考虑左边(前面)的 token
causal attention(因果关系的 attention)

multi-head,因为相关性不止一种

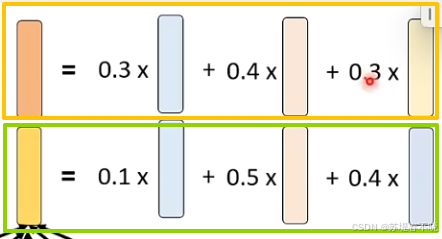
head1、head2

multi-head
feed forward
transformer block






未来的不用管,算过了不用再算属于 KV cache
Incremental Decoding(增量解码)


100k 的 tokens,计算 attention,需要计算 100k 的平方成正比数量的运算


参考
- https://speech.ee.ntu.edu.tw/~hylee/genai/2024-spring.php
- https://www.bilibili.com/video/BV18fXbY6Eis/?spm_id_from=333.1387.homepage.video_card.click&vd_source=8e91f8e604278558ec015e749d1a3719

开源鸿蒙跨平台开发社区汇聚开发者与厂商,共建“一次开发,多端部署”的开源生态,致力于降低跨端开发门槛,推动万物智联创新。
更多推荐
 9
9 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)