【NLP】RNN模型构建⼈名分类器
模型训练的损失降低快慢代表模型收敛程度, 由图可知, 传统RNN的模型收敛情况最 好, 然后是GRU, 最后是LSTM, 这是因为: 我们当前处理的⽂本数据是⼈名, 他们的⻓ 度有限, 且⻓距离字⺟间基本⽆特定关联, 因此⽆法发挥改进模型LSTM和GRU的⻓距 离捕捉语义关联的优势. 所以在以后的模型选⽤时, 要通过对任务的分析以及实验对 ⽐, 选择最适合的模型.LSTM. 构建GRU模型的类cl
一、需求
以⼀个⼈名为输入, 使⽤模型帮助我们判断它最有可能是来⾃哪⼀个国家的⼈名, 这在某 些国际化公司的业务中具有重要意义, 在⽤户注册过程中, 会根据⽤户填写的名字直接给 他分配可能的国家或地区选项, 以及该国家或地区的国旗, 限制⼿机号码位数等等。
二、实施步骤
第⼀步: 导⼊必备的⼯具包。
第⼆步: 对data⽂件中的数据进⾏处理,满⾜训练要求。
第三步: 构建RNN模型(包括传统RNN, LSTM以及GRU)。
第四步: 构建训练函数并进⾏训练。
第五步: 构建评估函数并进⾏预测。
三、代码实现
第⼀步: 导⼊必备的工具包
python版本使⽤3.6.x, pytorch版本使⽤1.3.1
# 从io中导入文件打开方法
from io import open
# 帮助使用正则表达式进行子目录的查询
import glob
import os
# 用于获得常见字母及字符规范化
import string
import unicodedata
# 导入随机工具random
import random
# 导入时间和数学工具包
import time
import math
# 导入torch工具
import torch
# 导入nn准备构建模型
import torch.nn as nn
# 引入制图工具包
import matplotlib.pyplot as plt
第⼆步: 对data⽂件中的数据进⾏处理,满⾜训练要求
定义数据集路径并获取常⽤的字符数量.
# 获取所有常用字符包括字母和常用标点
all_letters = string.ascii_letters + " .,;'"
# 获取常用字符数量
n_letters = len(all_letters)
print("n_letter:", n_letters)
字符规范化之unicode转Ascii函数unicodeToAscii.
# 关于编码问题我们暂且不去考虑
# 我们认为这个函数的作用就是去掉一些语言中的重音标记
# 如: Ślusàrski ---> Slusarski
def unicodeToAscii(s):
# normalize() 第一个参数指定字符串标准化的方式。 NFC表示字符应该是整体组成(比如可能的话就使用单一编码),而NFD表示字符应该分解为多个组合字符表示。
# Python同样支持扩展的标准化形式NFKC和NFKD,它们在处理某些字符的时候增加了额外的兼容特性。
return ''.join(c for c in unicodedata.normalize('NFD', s) if unicodedata.category(c) != 'Mn' and c in all_letters)
构建⼀个从持久化⽂件中读取内容到内存的函数readLines.
data_path = "./data/names/"
def readLines(filename):
"""从文件中读取每一行加载到内存中形成列表"""
# 打开指定文件并读取所有内容, 使用strip()去除两侧空白符, 然后以'\n'进行切分
lines = open(filename, encoding='utf-8').read().strip().split('\n')
# 对应每一个lines列表中的名字进行Ascii转换, 使其规范化.最后返回一个名字列表
return [unicodeToAscii(line) for line in lines]
构建⼈名类别(所属的语⾔)列表与⼈名对应关系字典
# 构建的category_lines形如:{"English":["Lily", "Susan", "Kobe"], "Chinese":["Zhang San", "Xiao Ming"]}
category_lines = {}
# all_categories形如: ["English",...,"Chinese"]
all_categories = []
# 读取指定路径下的txt文件, 使用glob,path中可以使用正则表达式
# glob资料:https://blog.csdn.net/qq_17753903/article/details/82180227
for filename in glob.glob(data_path + '*.txt'):
# 获取每个文件的文件名, 就是对应的名字类别
# os.path.basename():返回path最后的文件名。
# 如果path以/或\结尾,那么就会返回空值,
# 等同于os.path.split(path)的第二个元素。
# >>> import os
# >>> path = '/Users/houxiaojun/Data/data.csv'
# >>> # Get the last component of the path
# >>> os.path.basename(path)
# 'data.csv'
# os.path.splitext:分离文件名和扩展名, 返回两个元素(文件名, 扩展名)
# print('os.path.basename:', os.path.basename(filename))
# print('os.path.splitext:', os.path.splitext(os.path.basename(filename)))
category = os.path.splitext(os.path.basename(filename))[0]
# 将其逐一装到all_categories列表中
all_categories.append(category)
# 然后读取每个文件的内容,形成名字列表
lines = readLines(filename)
# 按照对应的类别,将名字列表写入到category_lines字典中
category_lines[category] = lines
print('category_lines==', category_lines)
# 查看类别总数
n_categories = len(all_categories)
print("n_categories:", n_categories)
# 随便查看其中的一些内容
print(category_lines['Italian'][:5])
将⼈名转化为对应onehot张量表示函数lineToTensor
def lineToTensor(line):
"""将人名转化为对应onehot张量表示, 参数line是输入的人名"""
# 首先初始化一个0张量, 它的形状(len(line), 1, n_letters)
# 代表人名中的每个字母用一个1 x n_letters的张量表示.
tensor = torch.zeros(len(line), 1, n_letters)
# 遍历这个人名中的每个字符索引和字符
for li, letter in enumerate(line):
# 使用字符串方法find找到每个字符在all_letters中的索引
# 它也是我们生成onehot张量中1的索引位置
tensor[li][0][all_letters.find(letter)] = 1
# 返回结果
return tensor
第三步: 构建RNN模型
构建传统的RNN模型的类class RNN.
# 使用nn.RNN构建完成传统RNN使用类
class RNN(nn.Module):
def __init__(self, input_size, hidden_size, output_size, num_layers=1):
"""初始化函数中有4个参数, 分别代表RNN输入最后一维尺寸, RNN的隐层最后一维尺寸, RNN层数"""
super(RNN, self).__init__()
# 将hidden_size与num_layers传入其中
self.hidden_size = hidden_size
self.num_layers = num_layers
# 实例化预定义的nn.RNN, 它的三个参数分别是input_size, hidden_size, num_layers
self.rnn = nn.RNN(input_size, hidden_size, num_layers)
# 实例化nn.Linear, 这个线性层用于将nn.RNN的输出维度转化为指定的输出维度
self.linear = nn.Linear(hidden_size, output_size)
# 实例化nn中预定的Softmax层, 用于从输出层获得类别结果
# 注意点:在softmax层外加了log函数
self.softmax = nn.LogSoftmax(dim=-1)
def forward(self, input, hidden):
"""完成传统RNN中的主要逻辑, 输入参数input代表输入张量, 它的形状是1 x n_letters
hidden代表RNN的隐层张量, 它的形状是self.num_layers x 1 x self.hidden_size"""
# 因为预定义的nn.RNN要求输入维度一定是三维张量, 因此在这里使用unsqueeze(0)扩展一个维度
input = input.unsqueeze(0)
# input = input
# 将input和hidden输入到传统RNN的实例化对象中,如果num_layers=1, rr恒等于hn
rr, hn = self.rnn(input, hidden)
# 将从RNN中获得的结果通过线性变换和softmax返回,同时返回hn作为后续RNN的输入
return self.softmax(self.linear(rr)), hn
def initHidden(self):
"""初始化隐层张量"""
# 初始化一个(self.num_layers, 1, self.hidden_size)形状的0张量
return torch.zeros(self.num_layers, 1, self.hidden_size)
构建LSTM模型的类class
# 使用nn.LSTM构建完成LSTM使用类
class LSTM(nn.Module):
def __init__(self, input_size, hidden_size, output_size, num_layers=1):
"""初始化函数的参数与传统RNN相同"""
super(LSTM, self).__init__()
# 将hidden_size与num_layers传入其中
self.hidden_size = hidden_size
self.num_layers = num_layers
# 实例化预定义的nn.LSTM
self.lstm = nn.LSTM(input_size, hidden_size, num_layers)
# 实例化nn.Linear, 这个线性层用于将nn.RNN的输出维度转化为指定的输出维度
self.linear = nn.Linear(hidden_size, output_size)
# 实例化nn中预定的Softmax层, 用于从输出层获得类别结果
self.softmax = nn.LogSoftmax(dim=-1)
def forward(self, input, hidden, c):
"""在主要逻辑函数中多出一个参数c, 也就是LSTM中的细胞状态张量"""
# 使用unsqueeze(0)扩展一个维度
input = input.unsqueeze(0)
# 将input, hidden以及初始化的c传入lstm中
rr, (hn, c) = self.lstm(input, (hidden, c))
# 最后返回处理后的rr, hn, c
return self.softmax(self.linear(rr)), hn, c
def initHiddenAndC(self):
"""初始化函数不仅初始化hidden还要初始化细胞状态c, 它们形状相同"""
c = hidden = torch.zeros(self.num_layers, 1, self.hidden_size)
return hidden, c
LSTM. 构建GRU模型的类class GRU.
# 使用nn.GRU构建完成传统RNN使用类
# GRU与传统RNN的外部形式相同, 都是只传递隐层张量, 因此只需要更改预定义层的名字
class GRU(nn.Module):
def __init__(self, input_size, hidden_size, output_size, num_layers=1):
super(GRU, self).__init__()
self.hidden_size = hidden_size
self.num_layers = num_layers
# 实例化预定义的nn.GRU, 它的三个参数分别是input_size, hidden_size, num_layers
self.gru = nn.GRU(input_size, hidden_size, num_layers)
self.linear = nn.Linear(hidden_size, output_size)
self.softmax = nn.LogSoftmax(dim=-1)
def forward(self, input, hidden):
input = input.unsqueeze(0)
rr, hn = self.gru(input, hidden)
return self.softmax(self.linear(rr)), hn
def initHidden(self):
return torch.zeros(self.num_layers, 1, self.hidden_size)
第四步: 构建训练函数并进⾏训练
从输出结果中获得指定类别函数categoryFromOutput.
def categoryFromOutput(output):
"""从输出结果中获得指定类别, 参数为输出张量output"""
# 从输出张量中返回最大的值和索引对象, 我们这里主要需要这个索引
# 注意: pytorch.topk()用于返回Tensor中的前k个元素以及元素对应的索引值
top_n, top_i = output.topk(1)
# top_i对象中取出索引的值
category_i = top_i[0].item()
# 根据索引值获得对应语言类别, 返回语言类别和索引值
return all_categories[category_i], category_i
随机⽣成训练数据函数randomTrainingExample.
def randomTrainingExample():
"""该函数用于随机产生训练数据"""
# 首先使用random的choice方法从all_categories随机选择一个类别
category = random.choice(all_categories)
# 然后在通过category_lines字典取category类别对应的名字列表
# 之后再从列表中随机取一个名字
line = random.choice(category_lines[category])
# 接着将这个类别在所有类别列表中的索引封装成tensor, 得到类别张量category_tensor
category_tensor = torch.tensor([all_categories.index(category)], dtype=torch.long)
# 最后, 将随机取到的名字通过函数lineToTensor转化为onehot张量表示
line_tensor = lineToTensor(line)
return category, line, category_tensor, line_tensor
构建传统RNN训练函数trainRNN.
# 定义损失函数为nn.NLLLoss,因为RNN的最后一层是nn.LogSoftmax, 两者的内部计算逻辑正好能够吻合.
# 扩展资料:nn.NLLLoss(): https://blog.csdn.net/jeremy_lf/article/details/102725285
criterion = nn.NLLLoss()
# 设置学习率为0.005
learning_rate = 0.005
def trainRNN(category_tensor, line_tensor):
"""定义训练函数, 它的两个参数是category_tensor类别的张量表示, 相当于训练数据的标签,
line_tensor名字的张量表示, 相当于对应训练数据"""
# 在函数中, 首先通过实例化对象rnn初始化隐层张量
hidden = rnn.initHidden()
# 然后将模型结构中的梯度归0
rnn.zero_grad()
# 下面开始进行训练, 将训练数据line_tensor的每个字符逐个传入rnn之中, 得到最终结果
for i in range(line_tensor.size()[0]):
output, hidden = rnn(line_tensor[i], hidden)
# 因为我们的rnn对象由nn.RNN实例化得到, 最终输出形状是三维张量, 为了满足于category_tensor
# 进行对比计算损失, 需要减少第一个维度, 这里使用squeeze()方法
# 理解:表示的意义为: 在[1, 18]一行18列中, 取出和类别一样的那个预测值和真实值进行损失值的求解过程
loss = criterion(output.squeeze(0), category_tensor)
# 损失进行反向传播
loss.backward()
# 更新模型中所有的参数
for p in rnn.parameters():
# 将参数的张量表示与参数的梯度乘以学习率的结果相加以此来更新参数
p.data.add_(-learning_rate, p.grad.data)
# 返回结果和损失的值
return output, loss.item()
构建LSTM训练函数trainLSTM.
# 与传统RNN相比多出细胞状态c
def trainLSTM(category_tensor, line_tensor):
hidden, c = lstm.initHiddenAndC()
lstm.zero_grad()
for i in range(line_tensor.size()[0]):
# 返回output, hidden以及细胞状态c
output, hidden, c = lstm(line_tensor[i], hidden, c)
loss = criterion(output.squeeze(0), category_tensor)
loss.backward()
for p in lstm.parameters():
p.data.add_(-learning_rate, p.grad.data)
return output, loss.item()
构建GRU训练函数trainGRU.
# 与传统RNN完全相同, 只不过名字改成了GRU
def trainGRU(category_tensor, line_tensor):
hidden = gru.initHidden()
gru.zero_grad()
for i in range(line_tensor.size()[0]):
output, hidden= gru(line_tensor[i], hidden)
loss = criterion(output.squeeze(0), category_tensor)
loss.backward()
for p in gru.parameters():
p.data.add_(-learning_rate, p.grad.data)
return output, loss.item()
构建时间计算函数timeSince.
def timeSince(since):
"获得每次打印的训练耗时, since是训练开始时间"
# 获得当前时间
now = time.time()
# 获得时间差,就是训练耗时
s = now - since
# 将秒转化为分钟, 并取整
m = math.floor(s / 60)
# 计算剩下不够凑成1分钟的秒数
s -= m * 60
# 返回指定格式的耗时
return '%dm %ds' % (m, s)
构建训练过程的⽇志打印函数train.得到损失对⽐曲线和训练耗时对⽐图.
# 设置训练迭代次数
n_iters = 10000
# 设置结果的打印间隔
print_every = 50
# 设置绘制损失曲线上的制图间隔
plot_every = 10
def train(train_type_fn):
"""训练过程的日志打印函数, 参数train_type_fn代表选择哪种模型训练函数, 如trainRNN"""
# 每个制图间隔损失保存列表
all_losses = []
# 获得训练开始时间戳
start = time.time()
# 设置初始间隔损失为0
current_loss = 0
# 从1开始进行训练迭代, 共n_iters次
for iter in range(1, n_iters + 1):
# 通过randomTrainingExample函数随机获取一组训练数据和对应的类别
category, line, category_tensor, line_tensor = randomTrainingExample()
# 将训练数据和对应类别的张量表示传入到train函数中
output, loss = train_type_fn(category_tensor, line_tensor)
# 计算制图间隔中的总损失
current_loss += loss
# 如果迭代数能够整除打印间隔
if iter % print_every == 0:
# 取该迭代步上的output通过categoryFromOutput函数获得对应的类别和类别索引
guess, guess_i = categoryFromOutput(output)
# 然后和真实的类别category做比较, 如果相同则打对号, 否则打叉号.
correct = '✓' if guess == category else '✗ (%s)' % category
# 打印迭代步, 迭代步百分比, 当前训练耗时, 损失, 该步预测的名字, 以及是否正确
print('%d %d%% (%s) %.4f %s / %s %s' % (iter, iter / n_iters * 100, timeSince(start), loss, line, guess, correct))
# 如果迭代数能够整除制图间隔
if iter % plot_every == 0:
# 将保存该间隔中的平均损失到all_losses列表中
all_losses.append(current_loss / plot_every)
# 间隔损失重置为0
current_loss = 0
# 返回对应的总损失列表和训练耗时
return all_losses, int(time.time() - start)
损失对⽐曲线分析:
模型训练的损失降低快慢代表模型收敛程度, 由图可知, 传统RNN的模型收敛情况最 好, 然后是GRU, 最后是LSTM, 这是因为: 我们当前处理的⽂本数据是⼈名, 他们的⻓ 度有限, 且⻓距离字⺟间基本⽆特定关联, 因此⽆法发挥改进模型LSTM和GRU的⻓距 离捕捉语义关联的优势. 所以在以后的模型选⽤时, 要通过对任务的分析以及实验对 ⽐, 选择最适合的模型.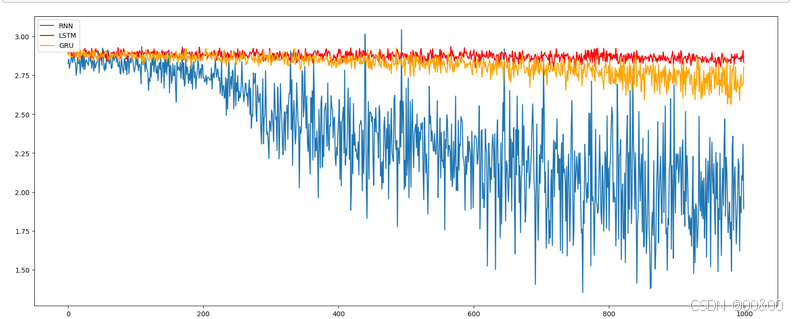
训练耗时对⽐图分析: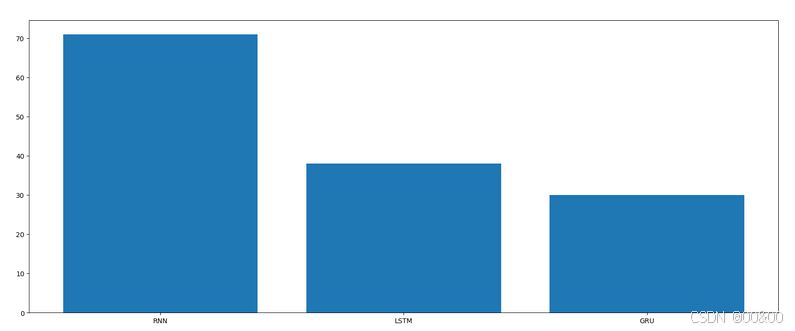
第五步: 构建评估函数并进⾏预测
构建传统RNN评估函数evaluateRNN.
def evaluateRNN(line_tensor):
"""评估函数, 和训练函数逻辑相同, 参数是line_tensor代表名字的张量表示"""
# 初始化隐层张量
hidden = rnn.initHidden()
# 将评估数据line_tensor的每个字符逐个传入rnn之中
print('line_tensor.size==', line_tensor.size())
print('line_tensor.size[]==', line_tensor.size()[0])
for i in range(line_tensor.size()[0]):
print('line_tensor[i]===', line_tensor[i])
output, hidden = rnn(line_tensor[i], hidden)
print('outputsize==', output.size())
# 获得输出结果
return output.squeeze(0)
构建LSTM评估函数evaluateLSTM.
def evaluateLSTM(line_tensor):
# 初始化隐层张量和细胞状态张量
hidden, c = lstm.initHiddenAndC()
# 将评估数据line_tensor的每个字符逐个传入lstm之中
for i in range(line_tensor.size()[0]):
output, hidden, c = lstm(line_tensor[i], hidden, c)
return output.squeeze(0)
构建GRU评估函数evaluateGRU.
def evaluateGRU(line_tensor):
hidden = gru.initHidden()
# 将评估数据line_tensor的每个字符逐个传入gru之中
for i in range(line_tensor.size()[0]):
output, hidden = gru(line_tensor[i], hidden)
return output.squeeze(0)
构建预测函数predict.
def predict(input_line, evaluate, n_predictions=3):
"""预测函数, 输入参数input_line代表输入的名字,
n_predictions代表需要取最有可能的top个"""
# 首先打印输入
print('\n> %s' % input_line)
# 以下操作的相关张量不进行求梯度
with torch.no_grad():
# 使输入的名字转换为张量表示, 并使用evaluate函数获得预测输出
output = evaluate(lineToTensor(input_line))
# 从预测的输出中取前3个最大的值及其索引
topv, topi = output.topk(n_predictions, 1, True)
# 创建盛装结果的列表
predictions = []
# 遍历n_predictions
for i in range(n_predictions):
# 从topv中取出的output值
value = topv[0][i].item()
# 取出索引并找到对应的类别
category_index = topi[0][i].item()
# 打印ouput的值, 和对应的类别
print('(%.2f) %s' % (value, all_categories[category_index]))
# 将结果装进predictions中
predictions.append([value, all_categories[category_index]])
# 调用
for evaluate_fn in [evaluateRNN, evaluateLSTM, evaluateGRU]:
print("-"*18)
predict('Dovesky', evaluate_fn)
predict('Jackson', evaluate_fn)
predict('Satoshi', evaluate_fn)

开源鸿蒙跨平台开发社区汇聚开发者与厂商,共建“一次开发,多端部署”的开源生态,致力于降低跨端开发门槛,推动万物智联创新。
更多推荐

 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)