基于MATLAB的深度学习时间序列回归预测——使用RNNs模型(包括LSTM、GRU和biLS...
总之时间序列预测这玩意,七分靠特征处理,三分靠模型调参,剩下的九十分靠运气(不是)。时间序列预测这玩意儿在实际场景里太常见了,从股票价格到电力负荷,到处都能用得上。最后说个玄学问题:同一组数据跑多次结果可能波动,别慌,这是神经网络初始化的随机性导致的。遇到预测结果滞后的问题,试试在数据预处理阶段加差分操作,或者调整滑窗步长。RNNs模型,包括长短期记忆(LSTM),门限循环单元(GRU)和双向长短
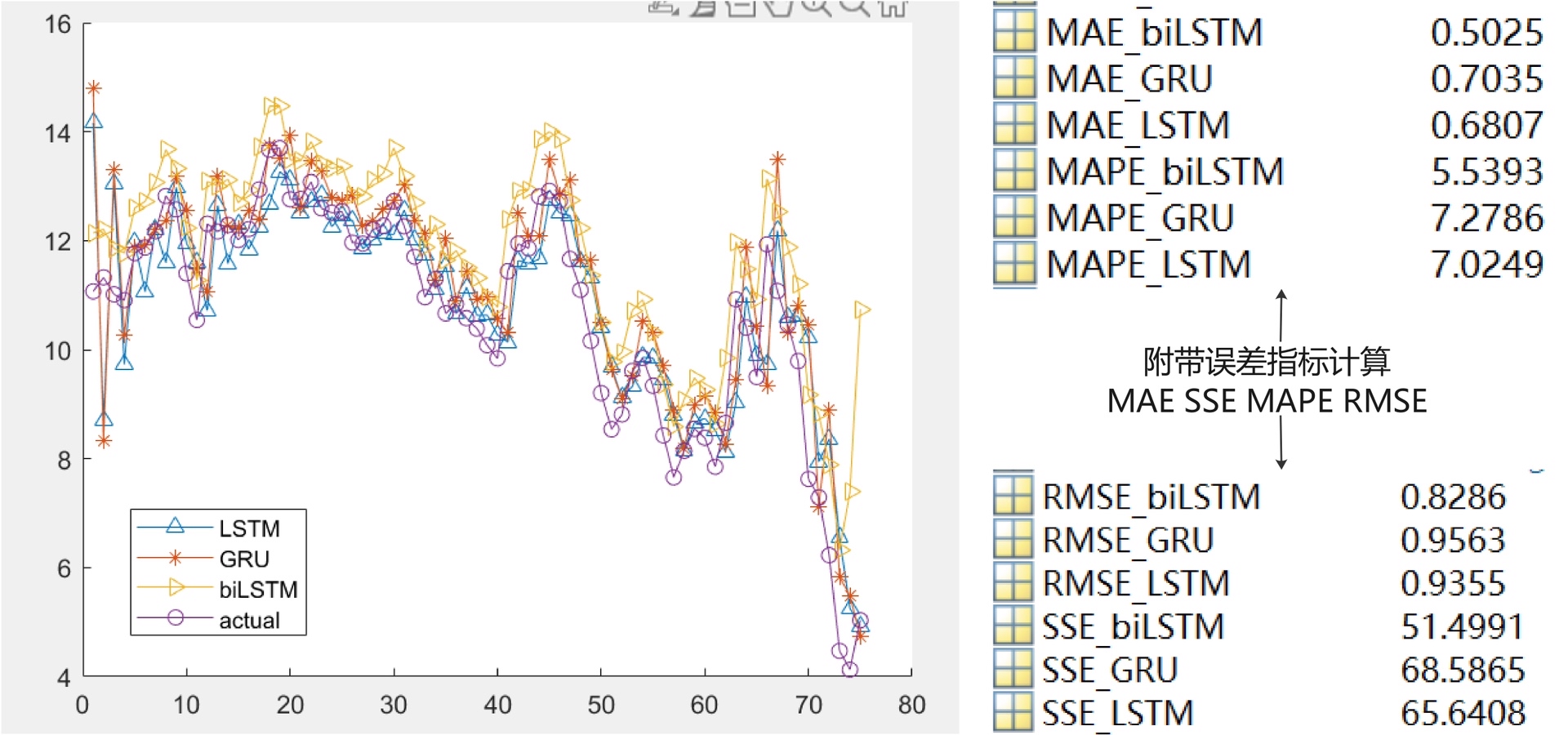
深度学习时间序列回归预测,基于MATLAB。 RNNs模型,包括长短期记忆(LSTM),门限循环单元(GRU)和双向长短期记忆(biLSTM)。 有实例,替换数据即可直接运行。 有训练集和测试集划分,输出预测结果的同时计算测试集上的误差指标,如RMSE,MAPE。 可以进行多步预测。
时间序列预测这玩意儿在实际场景里太常见了,从股票价格到电力负荷,到处都能用得上。今天咱们拿MATLAB搞点有意思的——用循环神经网络整活时间序列预测,手把手把LSTM、GRU这些模型玩出花来。
先准备个能跑的数据集。假设咱们手头有个正弦波叠加随机噪声的样本,先造个假数据热热身:
t = 0:0.1:20;
data = sin(t) + 0.2*randn(size(t)); % 加噪的正弦波接下来得把数据处理成RNN能吃的格式。这里需要注意时间步长的滑窗操作,举个栗子:
lookback = 10; % 用前10个点预测下一个点
[X, Y] = getTimeSeriesTrainData(data, lookback); % 自定义数据生成函数这个getTimeSeriesTrainData函数核心部分其实就是滑动窗口切片(代码太占篇幅不展开,文末给完整代码)。数据分训练测试集时要注意时序连续性,别乱打乱:
train_ratio = 0.8;
split_idx = floor(length(Y)*train_ratio);
x_train = X(:,1:split_idx);
y_train = Y(1:split_idx);搭建LSTM模型其实没想象中复杂。重点注意输入输出维度和层结构:
numFeatures = 1; % 单变量时间序列
numResponses = 1;
layers = [
sequenceInputLayer(numFeatures)
lstmLayer(128)
fullyConnectedLayer(numResponses)
regressionLayer];这里有个坑:如果做多变量预测,记得调整numFeatures值。训练参数设置讲究点,别让模型跑飞了:
options = trainingOptions('adam', ...
'MaxEpochs',100, ...
'MiniBatchSize',32, ...
'Plots','training-progress');训练过程可视化很重要,盯着loss曲线别让它过拟合。训练完直接预测:
net = trainNetwork(x_train,y_train,layers,options);
y_pred = predict(net, x_test, 'MiniBatchSize',1);效果评估部分得整点硬指标。RMSE和MAPE这两个老搭档不能少:
rmse = sqrt(mean((y_test - y_pred).^2));
mape = mean(abs((y_test - y_pred)./y_test))*100;有时候需要预测未来多个时间点,这时候得搞点骚操作。举个三步预测的例子:
multi_step_pred = [];
current_seq = x_test(:,1); % 取测试集第一个序列
for i = 1:3
pred = predict(net, current_seq);
multi_step_pred = [multi_step_pred pred];
current_seq = [current_seq(:,2:end) pred]; % 滚动更新输入序列
end这种滚动预测法会累积误差,所以预测步数别贪多。想换GRU或者双向LSTM?改个层类型就完事:
% GRU版本
gruLayer(128)
% 双向LSTM版本
bilstmLayer(128)实测发现双向LSTM在复杂波形预测上表现更骚,但训练时间直接翻倍。遇到预测结果滞后的问题,试试在数据预处理阶段加差分操作,或者调整滑窗步长。
完整代码打包时注意封装成函数,方便替换数据源。比如预测电力负荷时,把正弦波数据换成.csv读取就成:
raw_data = readmatrix('power_load.csv');
data = raw_data(:,2); % 假设第二列是数值最后说个玄学问题:同一组数据跑多次结果可能波动,别慌,这是神经网络初始化的随机性导致的。想要稳定结果可以固定随机数种子,不过现实中本来就需要这种泛化性不是?
代码扔GitHub上记得写清楚数据格式要求,不然隔三差五有人问为啥跑不起来。完整实现里加了数据归一化、异常值处理这些细节,这里篇幅有限就不展开了。总之时间序列预测这玩意,七分靠特征处理,三分靠模型调参,剩下的九十分靠运气(不是)。

开源鸿蒙跨平台开发社区汇聚开发者与厂商,共建“一次开发,多端部署”的开源生态,致力于降低跨端开发门槛,推动万物智联创新。
更多推荐

 8
8 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)