Logistic回归预测模型的深度验证及Nomogram图、列线图、列线表
今天咱们直接上硬货,手把手拆解模型验证全过程,顺带把临床医生最爱的列线图玩出花。临床使用时,直接把各变量对应的分数相加,查表得最终概率。从统计验证到临床落地,中间隔着的不是技术鸿沟,而是对应用场景的深度理解。这时候列线图上年龄轴的刻度就不再是等间距的了,真实反映变量与结局的非线性关系。坐标轴上的刻度对应原始变量取值,最上面的总得分轴就是各个变量得分的总和。比如年龄变量,直接扔进模型的话,列线图显示
Logistic回归预测模型的深度验证及Nomogram图,列线图,列线表。
刚上手Logistic回归的新手容易陷入误区:模型跑出显著变量就万事大吉。但真正要构建可靠的预测工具,得扒开表面看本质。今天咱们直接上硬货,手把手拆解模型验证全过程,顺带把临床医生最爱的列线图玩出花。
先甩段R代码热热身:
library(rms)
data <- read.csv("cancer_data.csv")
ddist <- datadist(data)
options(datadist='ddist')
fit <- lrm(status ~ age + tumor_size + ER_status, data=data)
cal <- calibrate(fit, method="boot", B=500)
plot(cal)这段代码暗藏玄机。rms包里的lrm不只是普通logistic回归,它自动处理了数据分布问题。calibrate函数用Bootstrap做了500次重抽样校准,生成的校准曲线要是能跟对角线重合,说明预测概率和实际风险严丝合缝。
模型区分度光看AUC不够劲。试试决策曲线分析:
library(rmda)
dca_data <- decision_curve(status ~ age + tumor_size,
data=data,
fitted.risk=TRUE,
thresholds=seq(0,1,by=0.01))
plot_decision_curve(dca_data,
curve.names="Our Model",
cost.benefit.axis=FALSE,
confidence.intervals=FALSE)这个曲线能直观显示模型在不同阈值下的临床净收益。要是你的模型曲线始终高于"全干预"和"不干预"两条基准线,说明医生真能靠这模型做靠谱决策。
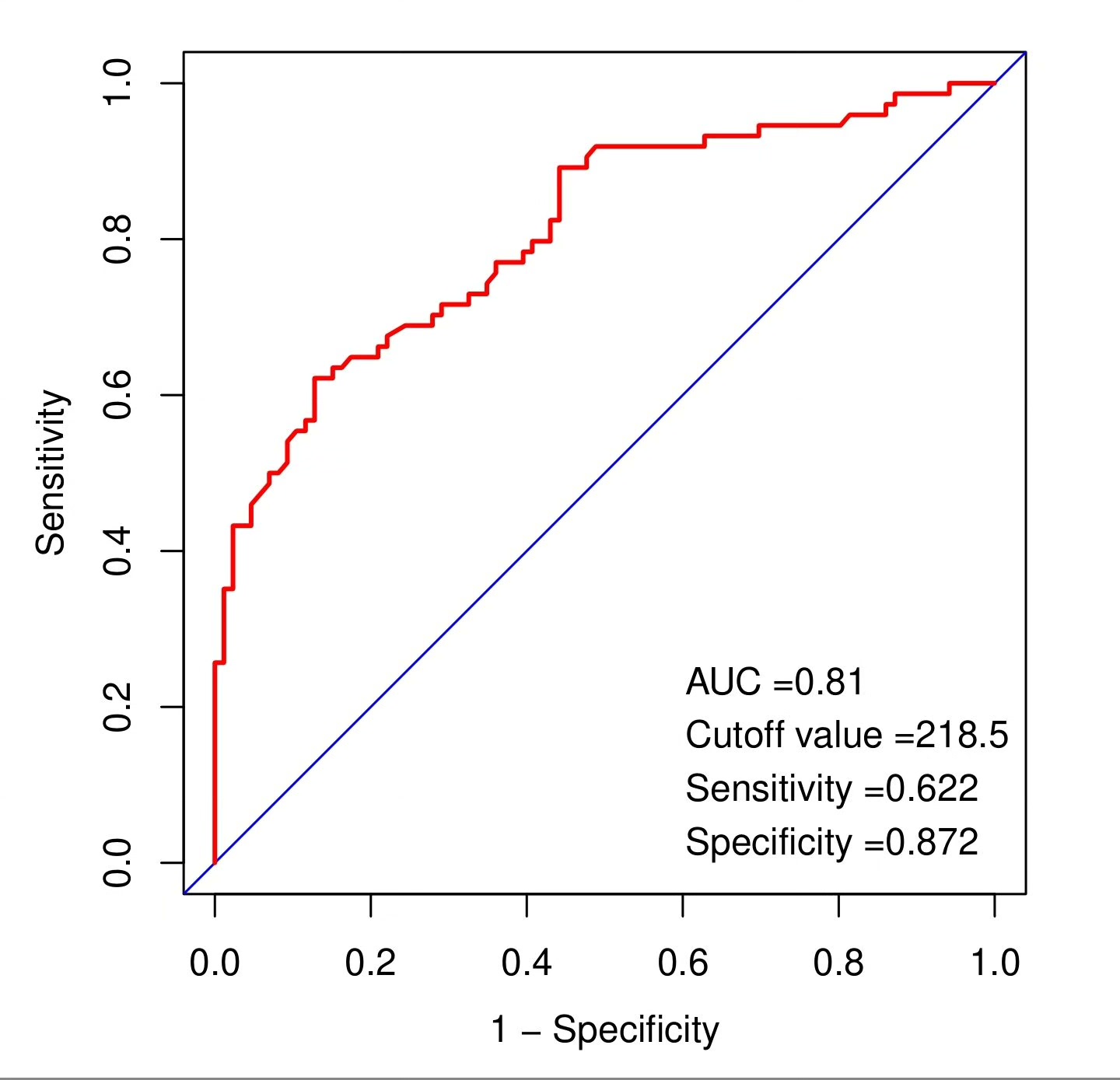
列线图可不是花架子,本质上是个可视化预测方程。看这段绘图代码:
nom <- nomogram(fit,
fun=plogis,
fun.at=c(0.05,0.1,0.25,0.5,0.75,0.9),
funlabel="Risk Probability")
plot(nom)这里的fun=plogis把线性预测值转为概率。坐标轴上的刻度对应原始变量取值,最上面的总得分轴就是各个变量得分的总和。临床使用时,护士拿着直尺在图上比划几下,就能快速算出个体化风险值。
但列线图有个隐藏坑——变量转换问题。比如年龄变量,直接扔进模型的话,列线图显示的是线性刻度。如果实际存在U型关系怎么办?试试限制性立方样条:
fit_nonlinear <- lrm(status ~ rcs(age,3) + tumor_size, data=data)
nom_nonlinear <- nomogram(fit_nonlinear,
fun=plogis,
interact=list(age=seq(20,80,by=5)))rcs(age,3)给年龄变量加了个三节点的样条弯曲。这时候列线图上年龄轴的刻度就不再是等间距的了,真实反映变量与结局的非线性关系。这种处理能让模型预测更贴现实,但需要足够大的样本量支撑。
最后提醒列线表的正确打开方式。很多人直接把回归系数转换成表格,这其实埋了雷。正确的做法是标准化计分:
coef <- coefficients(fit)
score_table <- data.frame(
variable = names(coef[-1]),
points = round(100*coef[-1]/max(coef[-1]))
)每个变量的计分与其回归系数成比例,确保总得分范围合理。临床使用时,直接把各变量对应的分数相加,查表得最终概率。这种"接地气"的呈现方式,比纯数学模型更容易被一线医生接受。
模型验证不是走过场,列线图也不是美工活。从统计验证到临床落地,中间隔着的不是技术鸿沟,而是对应用场景的深度理解。把模型塞进象牙塔容易,让它真正在诊室里跑起来,才是真功夫。


开源鸿蒙跨平台开发社区汇聚开发者与厂商,共建“一次开发,多端部署”的开源生态,致力于降低跨端开发门槛,推动万物智联创新。
更多推荐
 3
3 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)