机器人-强化学习2
深度强化学习,Q-learning,DQN, policy Gradient
决策Π,状态s,可能动作a
深度强化学习:引入神经网络,从高维到低维离散值
Q learning算法
sutton TD算法,考虑当前回报和下一个回报的估计值,右侧V(s)为旧值

QL来源于马尔可夫决策过程,创新点在于引入更新(时间T),与Sutton相比引入动作a
![]()
动作价值函数Q(s,a),用显示与估计的差值进行更新,用了时间差分法(TD temporal difference)
QLearning的学习过程维护一个Q表,在训练过程中不断更新,最终得到的是策略
深度强化学习结合,学出一个策略,这个策略Π(s,a),解决两个问题:连续状态到连续动作空间映射;端到端,高维数据到动作的映射
有哪些:Qlearning,DQN,policy
(结合CNN.CNN输入原始图像数据,输出每个动作对应的value.问题:只有可以作为标签的是reward,是稀少的,只能累计或延迟后才有标签;深度学习样本独立,RL中的status相关;深度学习目标固定,强化学习分布会变化,如游戏场景变化)
DQN=CNN+Qlearning
通过Qlearning使用reward来构造标签;通过经验回放(experience replay)解决相关性与非静态分布问题
Q Learning 算法得到的样本前后是有关系的。为了打破数据之间的关联性,Experience Replay 方法通过存储-采样的方法将这个关联性打破了
因为输入是RGB,像素也高,因此,对图像进行初步的图像处理,变成灰度矩形84*84的图像作为输入,有利于卷积。 接下来就是模型的构建问题,毕竟Q(s,a)包含s和a。
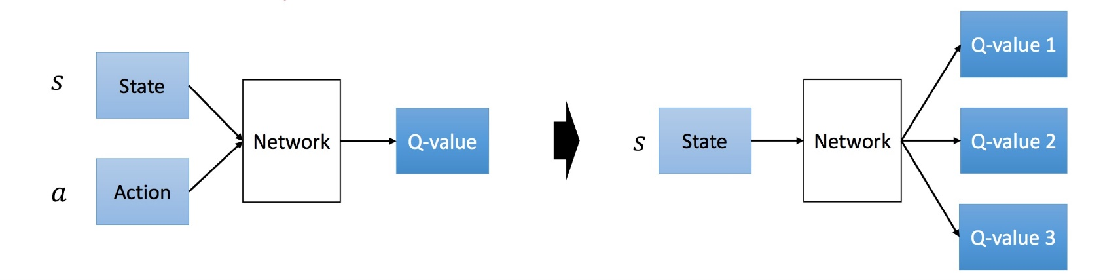
一种方法就是输入s和a,输出q值,这样并不方便,每个a都需要forward一遍网络。
Deepmind的做法是神经网络只输入s,输出则是每个a对应的q。这种做法的优点就是只要输入s,forward前向传播一遍就可以获取所有a的q值,毕竟a的数量有限
算法流程

每个t代表一个样本,对于每个时刻t,用一个可能概率选择一个随机action


-
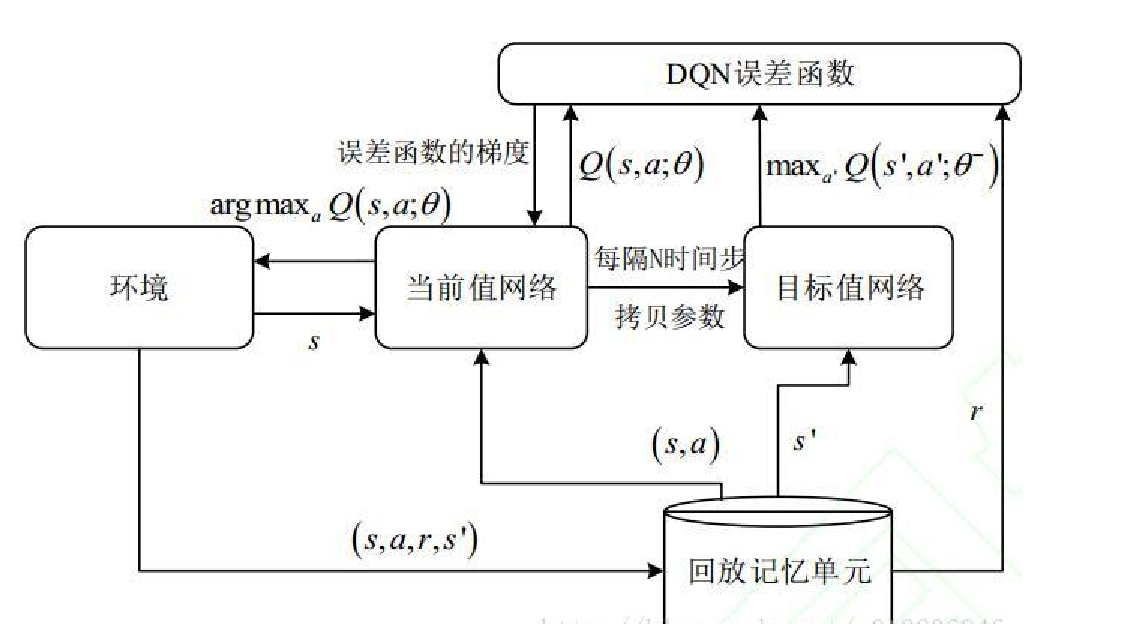
当前网络 (Online Network / Q-network):负责选择动作和训练更新
-
目标网络 (Target Network):负责计算目标Q值,提供稳定的学习目标

目标网络和当前网络的初始化与更新:
-
初始化:目标网络从当前网络"克隆"开始,两者参数完全相同
-
更新方式:
-
当前网络:每个训练步骤都用梯度下降更新
-
目标网络:
-
硬更新:定期完全复制当前网络参数
-
软更新:每次训练都小步混合当前网络参数
-
-
-
设计目的:解决"移动目标"问题,让Q-learning在神经网络近似下能够稳定训练

问题:不适用于连续空间
PolicyGradient
- Value-based:“先评估价值,再根据价值选动作”(间接决策)。需要先训练一个价值函数(Q 网络),再通过 argmax 等操作得到动作。优点是稳定性相对高(价值函数逼近有理论支撑,如 Bellman 方程);缺点是价值函数的近似误差可能传递到策略,且探索策略(如 ϵ-greedy)与价值函数更新耦合(off-policy 学习)。
- Policy-based:“直接学状态到动作的映射”(直接决策)。策略函数天然包含决策逻辑,优化目标就是“让策略直接输出高回报的动作”。优点是避免价值函数逼近的误差,探索自然嵌入在策略的概率分布中(例如 softmax 输出的动作概率,低概率动作也有机会被采样);缺点是策略梯度方法方差大(需通过基线函数、actor-critic 等改进),且通常是 on-policy 学习(必须用当前策略产生的数据更新)
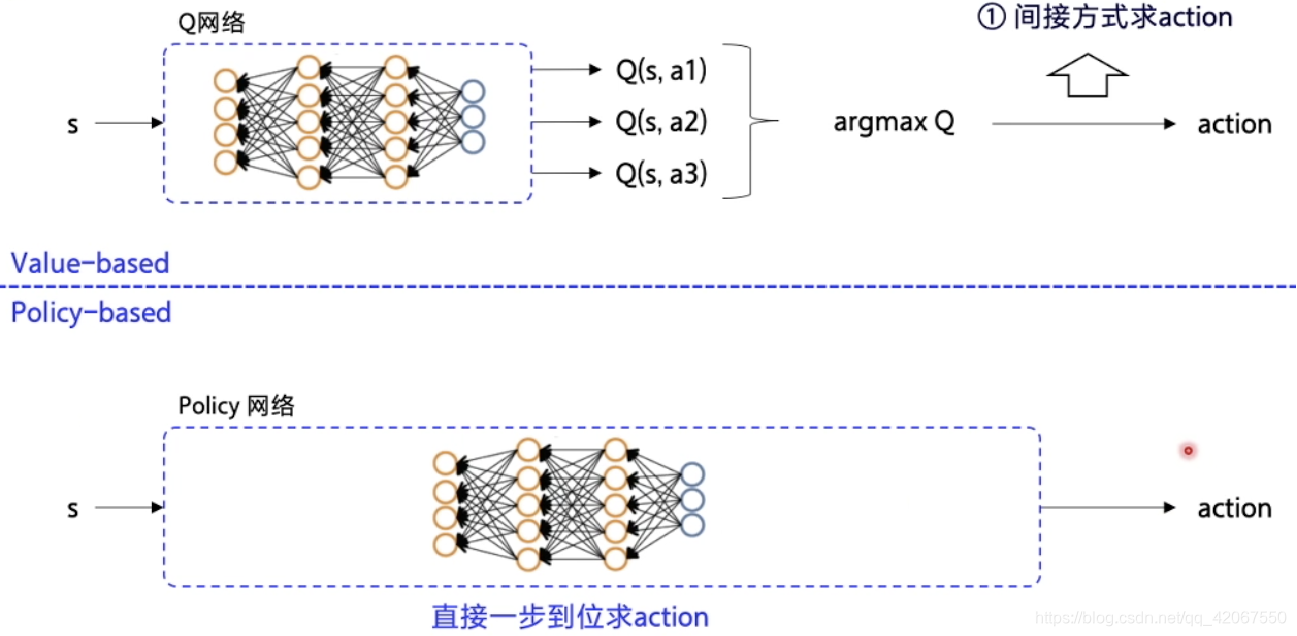
动作一步到位
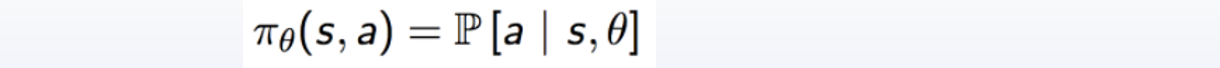
对策略参数化:输入某个状态,然后输出一个动作的概率分布。我们的目标是要寻找一个最优策略并最大化这个策略在环境中的期望回报
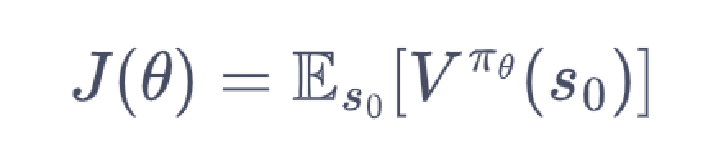
我们将目标函数对策略\theta求导,得到导数后,就可以用梯度上升方法来最大化这个目标函数,从而得到最优策略
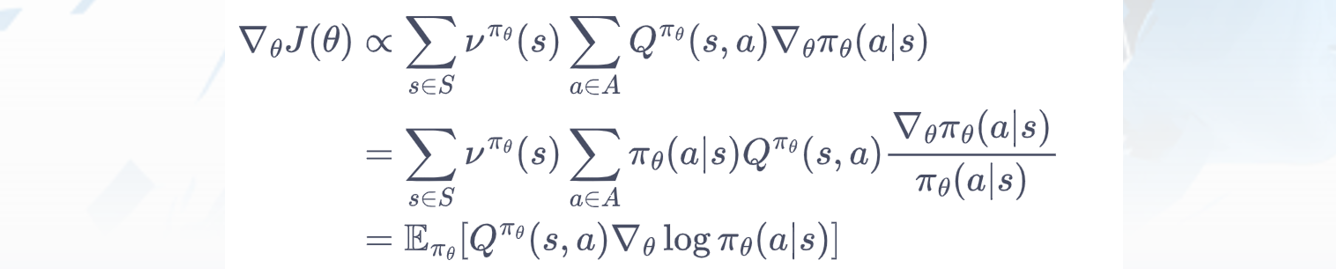
v为驻留分布,ν^π_θ(s) 就是表示在策略 π_θ 下,在状态 s 上的"停留频率"。只要确定了策略,我们就能确定驻留分布。




每一个状态下,梯度的修改是让策略更多地去采样到带来较高值的Q动作,更少地去采样到带来较低值Q的动作。这里用蒙特卡洛采样:


在统计学中,得分函数(Score Function)是指对数似然函数对参数的导数。它表示参数变化对概率分布的影响程度
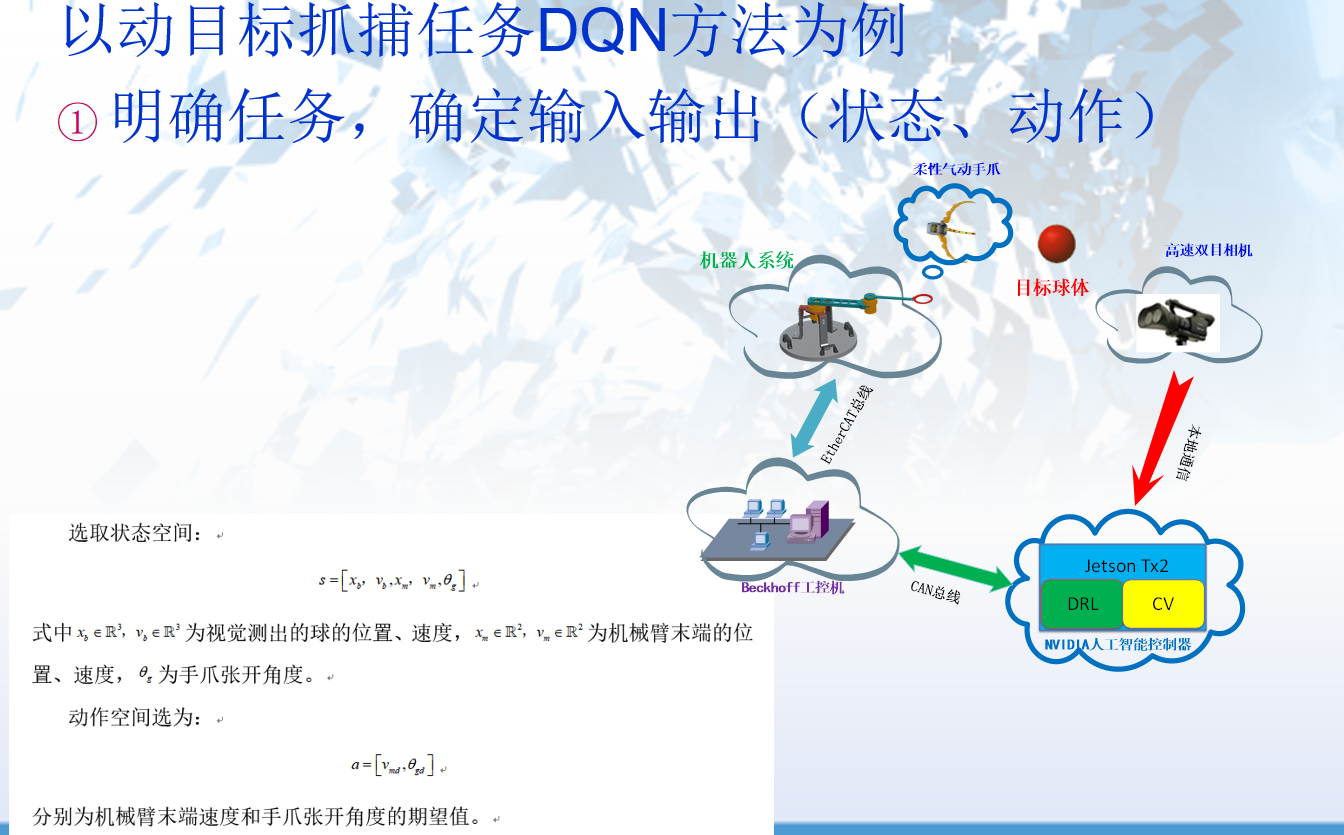



平衡探索与利用
一些训练平台:OpenAI Gym,MuJoCo(机器人打架?)
近年的DPO,GRPO,PPO,前景非常好/开发基于强化学习的游戏?

开源鸿蒙跨平台开发社区汇聚开发者与厂商,共建“一次开发,多端部署”的开源生态,致力于降低跨端开发门槛,推动万物智联创新。
更多推荐

 16
16 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)