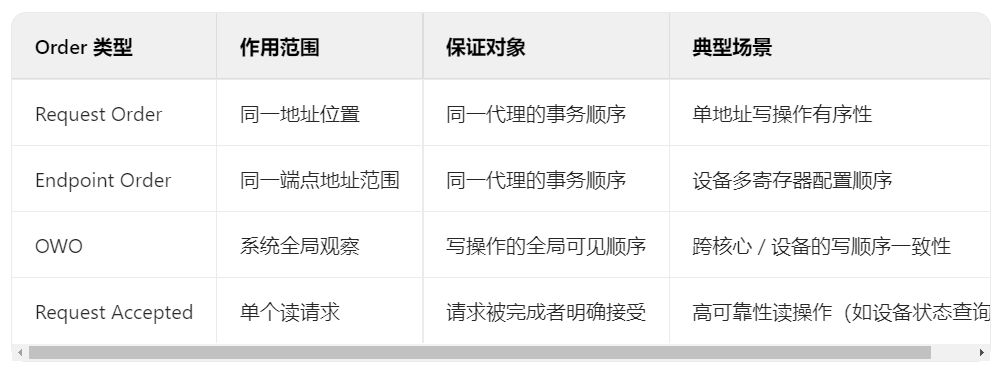
CHI学习---transaction ordering
在 CHI 协议中,可以利用实现系统请求排序,Order 字段用于控制 RN与HNSN之间的事务顺序,确保事务在系统中的执行和观察顺序符合预期。保证同一个RN,发往同一地址的多笔传输的顺序示例:处理器核心向内存地址0x1000发送两个写事务W1和W2:若设置,则系统必须确保W1先完成,W2后完成。若乱序处理(如W2先于W1到达内存),可能导致其他核心或设备看到错误的写顺序,违反多副本原子性保证同一
在 CHI 协议中,可以利用Order 字段实现系统请求排序,Order 字段用于控制 RN与HN或SN之间的事务顺序,确保事务在系统中的执行和观察顺序符合预期。根据不同的排序需求,Order 字段分为以下类型:
1. Request Order(请求顺序)
保证同一个RN,发往同一地址的多笔传输的顺序
示例:处理器核心向内存地址0x1000发送两个写事务W1和W2:若设置Order=Request Order,则系统必须确保W1先完成,W2后完成。若乱序处理(如W2先于W1到达内存),可能导致其他核心或设备看到错误的写顺序,违反多副本原子性
2. Endpoint Order(端点顺序)
保证同一个RN,发往同一个endpoint addr range的多笔传输的顺序。
示例:GPU 向 PCIe 设备的两个寄存器0x2000(控制寄存器)和0x2004(数据寄存器)发送配置事务C1和C2:若设置Order=Endpoint Order,则设备必须先处理C1(如设置工作模式),再处理C2(如写入数据)。若乱序处理,可能导致设备在未正确配置模式时接收数据,引发功能异常。
3. Ordered Write Observation (OWO,有序写观察)
保证同一个agent的一连串写操作(无论地址是否相同,是要是一连串写事务即可),其它agent会以相同顺序观察到。
- 核心场景:跨多个核心 / 设备的写操作需全局有序,例如释放锁前的写必须先于解锁操作被其他核心看到。
- 示例:
处理器核心执行以下操作:- 向内存地址
0x3000写入数据(W_DATA); - 向内存地址
0x3008写入 “解锁” 标志(W_UNLOCK)。
- 若设置
Order=OWO,则其他核心或设备必须先看到W_DATA的更新,再看到W_UNLOCK的更新。 - 若未保证 OWO,可能出现其他核心先看到 “解锁” 标志但未看到实际数据的情况,导致逻辑错误(如错误认为数据已准备好)。
- 向内存地址
4. Request Accepted(请求接受确认)
保证当completer收到了读请求,会返回正向的ack。
- 核心场景:对可靠性要求高的读操作(如关键寄存器读取),需确保请求被正确处理。
- 示例:
处理器读取传感器设备的状态寄存器:- 若设置
Order=Request Accepted,设备必须在接收到读请求后立即返回Ack,表示请求已被接受并处理。 - 若未使用该模式,设备可能因忙或故障忽略请求,处理器无法感知异常,导致读取结果失效。
- 若设置
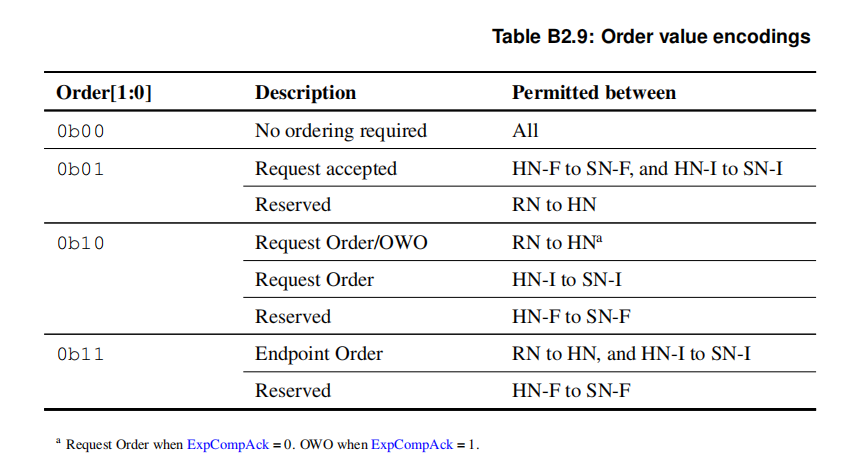
当RN将事务的排序要求更改为更强的排序要求时,必须在其所有事务中将Request Order的排序要求一致更改为Endpoint Order。
---------------------------------------------------------------------------------------------------------------------------------
有order需求的话,以下这些特定事务类型必须设置Order≠0。(也就是针对以下这些请求order可以设置为0,可以不保序;如果有保序需求需要设置order。但是除了这些transaction的其余trans即使order=0,也必须保序,因为涉及到cache一致性)


如果CPU发出的readnosnp order=0,说明没有保序需求,如果HN(看具体实现了,CMN中HN-F或者HN-I会过保序)不进行强制保序,那CPU先发A 再发B,到了HN再到SN顺序可以是先B再A,那就有人会问Device中的边界效应不会影响吗,答案是不影响,因为RN既然发出的无保序需求的请求,说明它不在乎边界效应的影响。
---------------------------------------------------------------------------------------------------------------------------------
不同事务的排序机制
1. 读事务的排序(ReadNoSnp/ReadOnce*)
- 条件:当
Order=Request Order或Endpoint Order时,- Requester 行为:必须等待
ReadReceipt响应,才能发送下一个有序请求。 - Completer 行为:返回
ReadReceipt表示请求已到达排序点(PoS),该排序点会按接收顺序维护请求。若 Completer 支持分离响应(Non-data 和 Data-only),可用RespSepData替代ReadReceipt。
- Requester 行为:必须等待
需要request order的请求,会维护来自同一来源、针对同一地址的请求之间的顺序。
需要endpoint order的请求,会维护来自同一来源、针对同一端点地址范围的请求之间的顺序。
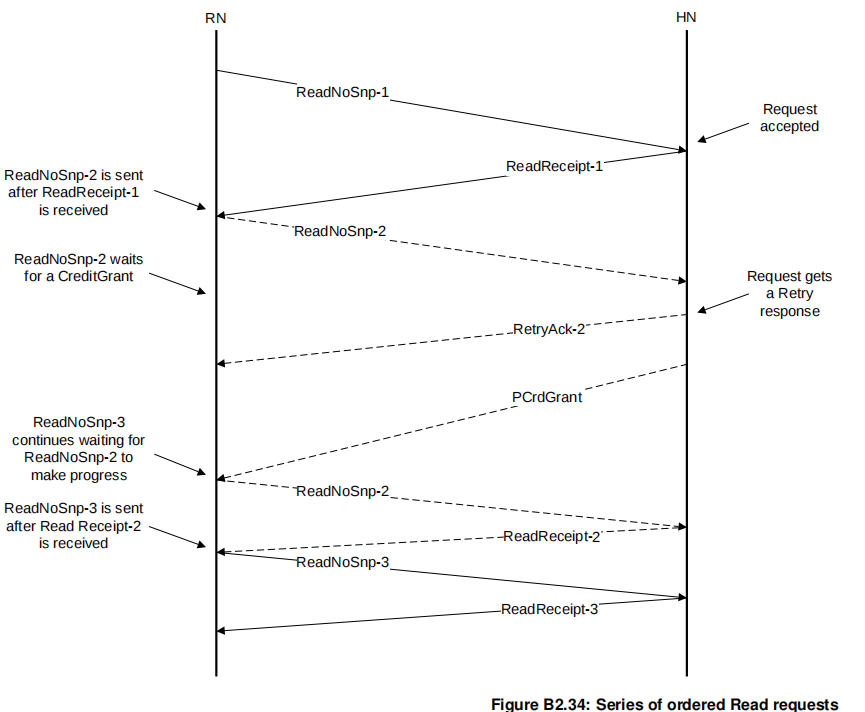
当readnosnp请求的order field=2'b01,completer会利用readreceipt来保证请求已经收到并且可以处理,所以不会发送retryack。
这幅图是来自RN的三个读操作组成的单个有序流。然而,RN可以有多个读操作流,因此请求必须在单个流内保持顺序。但流之间不存在排序依赖关系。例如,当这些流来自RN内的不同线程时。在这种情况下,请求节点仅在发送来自该流的下一个有序请求之前,等待同一线程中前一个请求的 ReadReceipt响应。
总结:
对于读请求(readnosnp/readonce*)的保序: 如果请求节点的order为request order或者endpoint order,completer在收到请求后回复readreceipt,RN才会发起下一笔同一地址的读请求。 如果不设置order,说明没有保序,是可以乱序的(除非HN-F、HN-I的实现中强制保序)
对于其余读请求的保序: 无论order设置多少,都必须按照保序处理,收到前一笔的readrcpt(HN-I会判断order[1]=1,一定回复readrcpt)或者compdata才可以发起下一笔,不能outstanding的发,从RN源头就保序了。
(HN-I是不看order域段的,只针对同个axid保序(也只是限制了dispatch dependency而已),其实保序还是AXI slave去做的)
--------------------------------------------------------------------------------------------------------------------------------
2. 写事务(WriteNoSnp/WriteUnique)的排序
-
WriteNoSnp / non-snoopable atomic:
条件:当Order=Request Order或Endpoint Order时- Requester行为:必须等待
DBIDResp/DBIDRespOrd响应,确认数据缓冲区可用 且请求已排序,才能发送下一个有序请求。 - Completer行为:返回
DBIDResp/DBIDRespOrd响应,该completer会按接收顺序维护请求。DBIDRespOrd额外保证:后续所有同一来源、同一地址的请求(无论读写)都将按此请求的顺序处理。
- Requester行为:必须等待
DbidRespOrd:只要completer返回了dbidrespord,不管request是不是有order需求,不管请求的类型,都需要保序,相比dbidresp有更严格的保序要求。
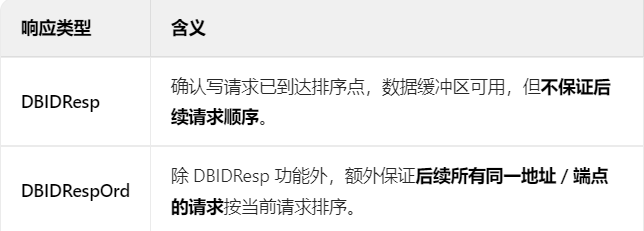
示例:DBIDRespOrd 的强顺序保证
处理器发送写请求 W1(地址 0x1000,Order=Request Order),完成者返回 DBIDRespOrd。
后续无论发送读请求 R1(0x1000)、原子操作 A1(0x1000),还是写请求 W2(0x1000),完成者都必须确保这些请求在 W1 之后处理。
①如果W2的order=0,完成者返回DBIDResp,完成者对W2和W1的顺序不能保证,但是如果完成者返回的是DBIDRespOrd,完成者一定会先处理W1再处理W2。
②如果W2的order=request order,完成者返回DBIDResp,完成者会确保后续的这个request order的请求在W1之后,但是后面的请求是no order的返回DBIDResp就保证不了,只有DBIDRespOrd可以。
假设处理器核心 A 向地址 0x1000 依次发送以下请求:
- 写请求 W1(无 Order 要求,但 Completer 发送
DBIDRespOrd):- 核心 A 写入数据
A,Completer 返回DBIDRespOrd,建立排序点。
- 核心 A 写入数据
- 读请求 R1(地址
0x1000,无 Order 要求):- 核心 A 发送读请求,Completer 必须将 R1 排在 W1 之后处理(因 W1 的
DBIDRespOrd已生效)。
- 核心 A 发送读请求,Completer 必须将 R1 排在 W1 之后处理(因 W1 的
- 原子操作 A1(地址
0x1000,Atomic Add):- 核心 A 发送原子请求,Completer 同样必须将 A1 排在 W1 之后处理。
关键效果:
- 即使 R1 和 A1 无显式 Order 要求,Completer 仍按 W1 的顺序约束处理,确保 W1 → R1 → A1 的顺序。
- 若 W1 包含 CMO(如清理其他核心的缓存),则 CMO 必须在 R1/A1 的缓存访问前完成,避免脏数据。
假设两笔同地址写请求A/B,HN先收到A再收到B,会先回dbidresp_A,再回dbidresp_B,但是有可能B的写数据先到HN,但是因为hn回了dbidresp就意味着已经保序了,后续数据谁先到都可以了,会按照req的顺序reorder。
---------------------------------------------------------------------------------------------------------------------------------
WriteUnique(ExpCompAck=0) / WriteUniqueZero / Snoopable atomic
保序要求:
- Request Order:仅保证同一地址的写事务按顺序处理(因可窥探事务通常涉及全局一致性,访问device不会用到writeunique,主要针对访问mem的)。
- 请求者行为:
- 发送写请求时,设置
Order=Request Order。 - 需等待 DBIDResp/DBIDRespOrd 响应,与不可窥探事务类似。
- 发送写请求时,设置
- 完成者行为:
- 处理写请求时,先通过窥探操作(如 SnpCleanInvalid)通知其他缓存清理旧数据,再执行写操作。
- DBIDRespOrd 额外保证:后续任何事务类型(如读、原子操作)对同一地址的请求,都按当前写请求的顺序处理。
示例:
处理器核心 A 向共享缓存地址 0x1000 发送两个 WriteUnique 请求:
- 写数据 A,设置
Order=Request Order,触发窥探其他核心缓存并清理旧数据。 - 写数据 B,必须等待第一个请求的 DBIDRespOrd 响应,确保核心 B/C 先看到数据 A,再看到数据 B。
-
其他核心的观察顺序:
a.核心 B/C 必须先处理请求 A 的窥探(清理旧数据)→ 看到数据 A 的更新。
b.随后处理请求 B 的窥探 → 看到数据 B 的更新。
c.因此,核心 B/C 观察到的写顺序必然是 A→B,与请求发送顺序一致。
---------------------------------------------------------------------------------------------------------------------------------
针对OWO
适用场景
当 WriteUnique、WriteNoSnp 等写事务需要 OWO(写操作的全局可见顺序与发送顺序一致) 时,必须满足:
- 请求节点(Requester)必须设置
ExpCompAck标志,强制要求完成者返回CompAck响应。 - 写操作在收到
CompAck前不可见:其他核心 / 设备无法观察到该写结果,确保顺序性。 - 完成者(Completer)作为排序点(PoS),保证写操作的一致性动作(如窥探)不依赖后续写操作。
示例:跨核心的写顺序保证
假设核心 A 向共享内存发送两个写事务,要求其他核心按顺序观察:
- 写事务 W_A(
WriteUnique,Order=OWO,ExpCompAck=1):- 核心 A 发送 W_A 到地址
0x2000,写入数据A。 - Completer 处理 W_A,但 暂不将数据公开给核心 B/C(因未收到
CompAck)。
- 核心 A 发送 W_A 到地址
- 写事务 W_B(
WriteUnique,Order=OWO,ExpCompAck=1):- 核心 A 等待 W_A 的
DBIDRespOrd响应后,发送 W_B 到地址0x2000,写入数据B。 - Completer 处理 W_B,但同样暂不公开数据。
- 核心 A 等待 W_A 的
- 核心 A 发送
CompAck:- 核心 A 先对 W_A 发送
CompAck,Completer 收到后将数据A公开给核心 B/C。 - 随后对 W_B 发送
CompAck,数据B公开,确保核心 B/C 先看到A,再看到 B
- 核心 A 先对 W_A 发送
CompAck 是写操作可见性的 “闸门”:未收到时,写结果对其他核心不可见,避免乱序观察!!!

----------------------------------------------------------------------------------------------------------------------------
copyback request order
基础规则
RN - F 在向同一个缓存行发出另一个请求之前,必须等待未完成的回写事务的 CompDBIDResp 或 Comp 响应。这是为了保证缓存一致性和数据的完整性。如果在回写事务还未完成时就发出新的请求,可能会导致数据不一致的问题。例如,若在旧数据还未正确写回主存时又发起了对同一缓存行的新操作,新操作可能会基于旧的、未更新的数据进行,从而产生错误。
特殊情况
- 原子事务的提前发起:当 SnoopMe 标志位被置位时,原子事务可以在等待同一缓存行的未完成回写事务的 CompDBIDResp 或 Comp 响应时被发起。这是因为原子事务具有不可分割性,且设置了 SnoopMe 标志位后会进行窥探操作,能保证在一定程度上与回写事务的并发操作不会破坏数据的一致性。
- 回写事务的提前发起:同样,当 SnoopMe 标志位被置位时,回写事务也可以在等待同一缓存行的未完成原子事务的 CompDBIDResp 或 Comp 响应时被发起。这也是基于对数据一致性的保证机制,在有窥探操作的情况下,允许这两种事务有一定的并发操作。
----------------------------------------------------------------------------------------------------------------------------
Streaming Ordered Write transactions
这种机制只适用于 WriteUnique 和 WriteNoSnp 这两种事务类型,目的是提高 OWO 写操作的流效率。
有序写观察(Ordered Write Observation, OWO)
假设你和朋友在排队买奶茶,你先点了「珍珠奶茶」(写事务 A),然后朋友点了「波霸奶茶」(写事务 B)。
OWO的核心要求:
奶茶店必须先完成你的「珍珠奶茶」(让你拿到饮料),再处理朋友的「波霸奶茶」。
其他排队的人(其他处理器 / 设备)也必须先看到你拿到珍珠奶茶,再看到朋友拿到波霸奶茶,不能颠倒顺序。
-
为什么需要 OWO?
如果奶茶店先做好朋友的波霸奶茶并给他,而你的珍珠奶茶还没好,那么其他人会误以为 “波霸奶茶比珍珠奶茶先点”,这就乱套了。 -
OWO 就是确保:写操作的执行顺序和其他组件 “看到” 的顺序,必须和发起顺序一致。
假设处理器核心 A 执行以下操作:
- 先向内存地址 0x1000 写入数据 “Hello”(写事务 A)。
- 再向内存地址 0x1000 写入数据 “World”(写事务 B)。
-
如果没有 OWO:
可能出现:其他核心先看到 “World”(写事务 B 的结果),后看到 “Hello”(写事务 A 的结果),导致数据混乱。 -
有 OWO 时:
核心 A 会确保:- 写事务 A 完成并被所有观察者看到后,才允许写事务 B 开始。
- 其他核心必须先看到 “Hello”,再看到 “World”,严格遵循发起顺序。
--------------------------------------------------------------------------------------------------------------------------------
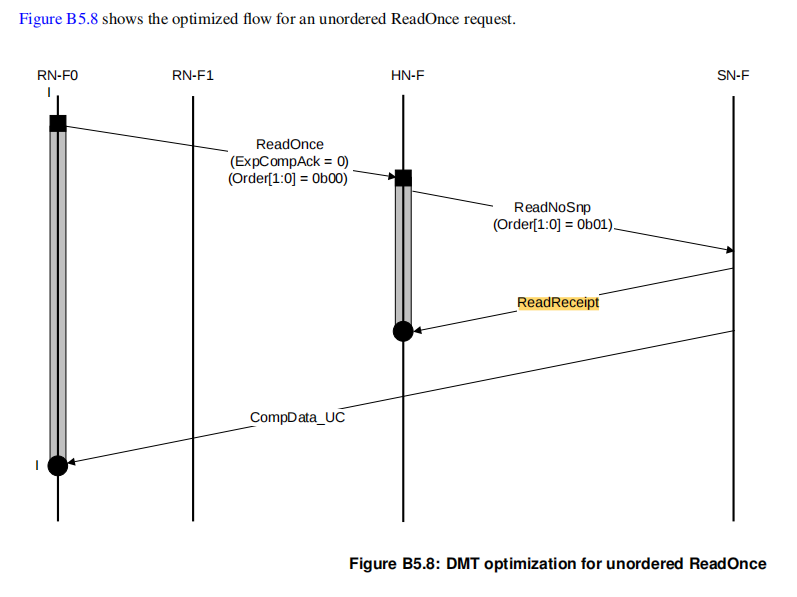
DMT传输:允许SN直接传输数据给RN
在这个flow中,RN-F0先发送了一个没有保序需求的readonce给HN-F,HN-F会对收到的针对相同地址的读请求进行保序,HN-F会设置order=2'b01,会收到SN的readreceipt,之后会deallocate这笔请求并且发出下一笔相同地址的请求,随后SN直接发送compdata给RN-F。(因为这个flow是针对DMT传输而言,所以此处HN-F需要设置order=2'b01,HN-F收到SN-F的read rcpt才可以释放这笔读请求,不然SN直接把数据给了RN,HN不知道什么时候该deallocate这笔请求)
对于非DMT传输而言,如果order=2'b00,且HN-F没有修改order,但是由于HN-F是POS点,当要发出连续两笔相同地址的读请求时,只有收到SN-F的第一笔读请求的compdata之后才会发出第二笔读请求。
其实CHI协议中,只要求了order为request order or endpoint order的情况 才需要收到上一笔请求的readreceipt才会发出下一笔。只是HN-F在实现的时候因为POCQ的缘故,会对同地址请求进行保序,即使order=2'b00。
-------------------------------------------------------------------------------------------------------------------------------
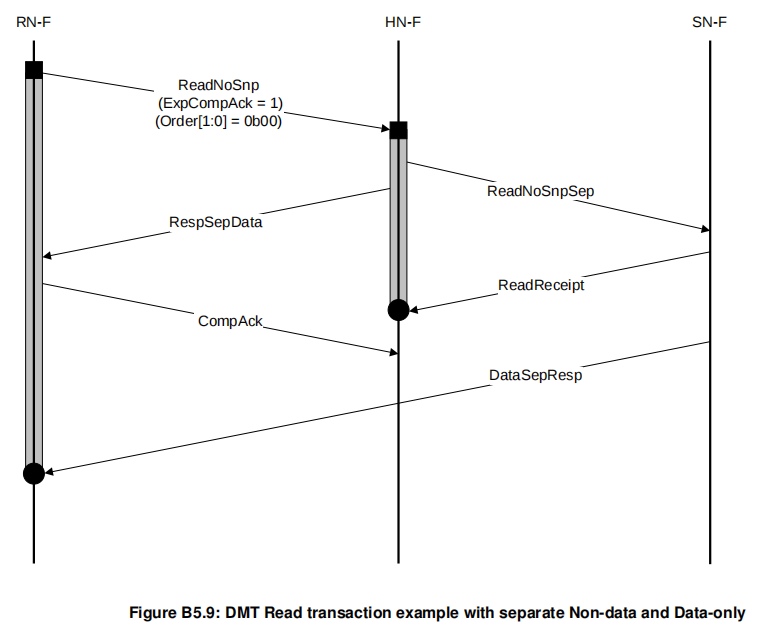
这个flow中无order需求,HN-F收到readrcpt之后就可以deallocate该请求,然后发起下一笔的读,所以这里compack起不到什么作用。
---------------------------------------------------------------------------------------------------------------------------------
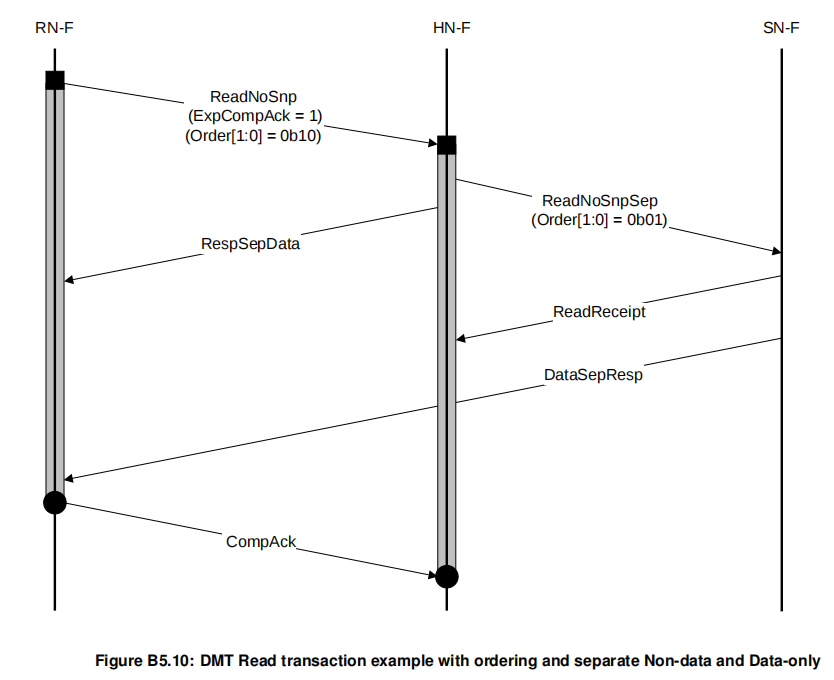
因为该flow中order不为0,有保序需求,且expcompack=1。所以RN必须收到dataresp和respsep之后才可以发送compack,HN-F必须收到comack之后才可以发送下一笔请求。
(这里HN-F修改了order是因为HN-F到SN-F的order只能设置为01,因为设置了是有保序需求的,那HN只有收到了compack之后才可以发送下一笔)
---------------------------------------------------------------------------------------------------------------------------

开源鸿蒙跨平台开发社区汇聚开发者与厂商,共建“一次开发,多端部署”的开源生态,致力于降低跨端开发门槛,推动万物智联创新。
更多推荐
 27
27 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)