SuperGlue: Learning Feature Matching with Graph Neural Networks—使用图神经网络学习特征匹配初步阅读学习
SuperGlue是一个神经网络,它的作用是通过联合地寻找匹配点和排除无法匹配的点,来匹配两组局部特征这个地方实际上是特征匹配任务和SLAM任务中常用的一个部分。考虑的是做方法的迁移。它通过解一个可微的最优运输问题来估计运输成本,其成本由图神经网络来预测和匈牙利算法这种二部图匹配的问题是很类似的一种问题。SuperGlue引入了一种基于注意力机制的灵活上下文聚合方法,使其能够同时考虑3D场景的结构
SuperGlue使用图神经网络学习特征匹配
文章目录
当时在查阅这篇论文的时候就发现了,这篇论文虽然比较早。但感觉和自己想要做的东西有很大的启发。
- 完成的是局部特征点之间的匹配。
- 用到了图神经网络。
- 聚合方式还采用了注意力聚合的方式来进行实现的。
如果有一些可以直接完成点到示例的匹配的方法的话,就可以完成一个创新希望有做过这个方面的大佬可以指导自己一下。
作者:Paul-Edouard Sarlin1∗ Daniel DeTone2 Tomasz Malisiewicz2 Andrew Rabinovich2
单位:ETH Zurich 2 Magic Leap, Inc.
代码: https://github.com/magicleap/SuperGluePretrainedNetwork
期刊/会议:CVPR 2020
摘要概括
- SuperGlue 是一个神经网络,它的作用是通过联合地寻找匹配点和排除无法匹配的点,来匹配两组局部特征
这个地方实际上是特征匹配任务和SLAM任务中常用的一个部分。考虑的是做方法的迁移。
- 它通过解一个可微的最优运输问题来估计运输成本,其成本由图神经网络来预测
和匈牙利算法这种二部图匹配的问题是很类似的一种问题。
- SuperGlue 引入了一种基于注意力机制的灵活上下文聚合方法,使其能够同时考虑 3D 场景的结构和特征分配。

导言与相关介绍
SuperGlue 提出的不是通过改进通用的局部特征学习,再加上简单的匹配启发式方法来进行特征匹配,而是通过一种新的神经网络架构来直接学习匹配过程,从而利用已有的局部特征进行匹配。
在SLAM的上下文中,通常将问题分解为视觉特征提取前端和捆绑调整或姿态估计后端,我们的网络直接位于中间SuperGlue是一个可学习的中间端如下图所示。
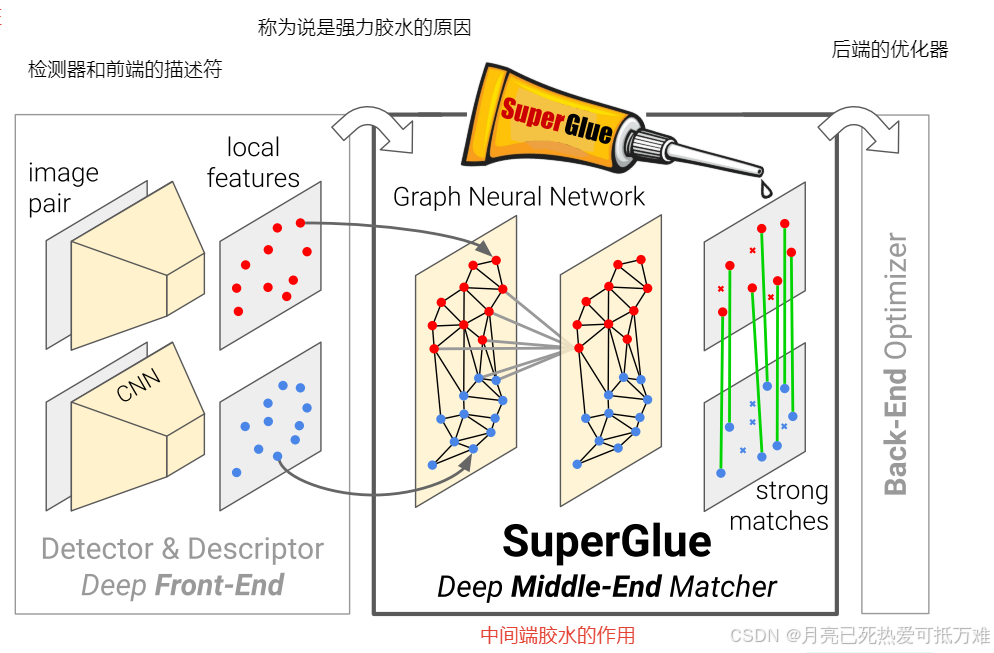
在SLAM这种系统中我们提出的这个特征点匹配算法,充当了前端与后端模块的中间部分,很形象的起名为强力胶水。
它充当手工制作或学习的前端和后端之间的中间端。SuperGlue使用图神经网络和注意力来解决分配优化问题,并优雅地处理部分点的可见性和遮挡,产生部分分配。
SuperGlue 在 SLAM 系统中的关键角色:它通过现成的局部特征(如 SIFT、ORB 等)来建立精确的特征点匹配,从而充当了“中间端”的作用,将前端(特征提取)和后端(优化、位姿估计)连接起来。通过这种方式,SuperGlue 提供了一种高效、灵活的特征匹配机制,能够增强 SLAM 系统的鲁棒性和准确性。
在引言部分我们对整个算法中提到的最为核心的三个主要的部分进行了概括和总结。如下所示。
-
通过求解线性分配问题,我们重新审视了经典的基于图的匹配策略,当将线性分配问题放松为最优运输问题时,可以微分地求解线性分配问题。
-
通过图神经网络(GNN)来预测该优化的成本函数。
-
受Transformer 成功的启发,它使用自我(图像内)和交叉(图像间)注意力来利用关键点的空间关系及其视觉外观。
算法优势与发展历程
传统的局部特征匹配通常通过以下步骤来执行:i)检测兴趣点,ii)计算视觉描述符,iii)将这些与最近邻(NN)搜索进行匹配,iv)过滤不正确的匹配,以及最后v)估计几何变换
结合查询到的一些知识对这五个部分进行具体细节上的介绍。
-
Detecting interest points (检测兴趣点):
- 在图像中,兴趣点(或称为特征点)是那些具有明显且稳定视觉特征的点,通常位于图像中的边缘、角点或者具有纹理变化的区域。这些点被认为是匹配的关键,因为它们在不同的视角或图像中更容易被识别。
- 常见的兴趣点检测方法包括 Harris 角点检测、SIFT(尺度不变特征变换)、ORB(Oriented FAST and Rotated BRIEF)等。
-
Computing visual descriptors (计算视觉描述符):
- 对每个检测到的兴趣点,计算一个视觉描述符(也叫局部描述符)。这个描述符是一个高维向量,能够捕捉兴趣点周围局部区域的外观特征。描述符需要具有一定的尺度不变性、旋转不变性等,确保在不同视角、光照和尺度下依然能够稳定地进行匹配。
- 例如,SIFT 描述符基于局部区域的梯度方向,ORB 使用 FAST 算法检测的兴趣点并结合 BRIEF 描述符。
-
Matching these with a Nearest Neighbor (NN) search (通过最近邻搜索进行匹配):
- 匹配步骤是将不同图像中相似的兴趣点通过其描述符进行配对。这里使用 最近邻搜索(Nearest Neighbor, NN)来寻找描述符最相似的点。即,对于某一图像中的一个兴趣点,它在另一图像中找到描述符最接近的点作为匹配点。
-
Filtering incorrect matches (过滤错误匹配):
- 一旦完成了匹配,就需要过滤掉那些错误的匹配。由于图像中的噪声、相似的纹理区域等,某些匹配可能会是不准确的。常见的过滤方法包括使用 比率测试(如 David Lowe 提出的 SIFT 比率测试),即通过检查最近邻和次近邻之间的距离比值,来剔除不可信的匹配。
-
Estimating a geometric transformation (估计几何变换):
SuperGlue这种通过深度学习的方式来进行特征点匹配的好处涉及到了数据驱动和先验知识两个重要的部分。简单的进行一部分的说明和解释。
SuperGlue 的优势,即通过深度学习和端到端的训练方法,网络能够自动学习和适应几何变换以及 3D 场景的知识,而不需要依赖人工设计的几何规则,这让其在处理复杂场景时具有更大的灵活性和鲁棒性。
数据驱动与先验知识
数据驱动(Data-driven):数据驱动指的是依赖于从数据中自动学习规律和模式的一种方法。在机器学习和深度学习中,这种方法是通过大量的训练数据来帮助模型学习,而不依赖于人类专家的直接干预或预先设定的规则。
先验知识(Prior knowledge):先验知识指的是在处理问题之前已经存在的知识或假设,这些知识通常来源于领域专家的经验、数学理论或已知的规律。与数据驱动方法不同,先验知识依赖的是预先定义的、通过人为分析获得的规律或假设。
在实际应用中,很多现代技术(如SuperGlue、深度学习、强化学习等)会将数据驱动方法和先验知识结合起来。数据驱动方法能使模型根据大量数据自动学习并适应复杂的现实世界,而先验知识可以作为一种约束或引导,帮助模型避免陷入局部最优解或不合理的推断。
核心方法——The SuperGlue Architecture
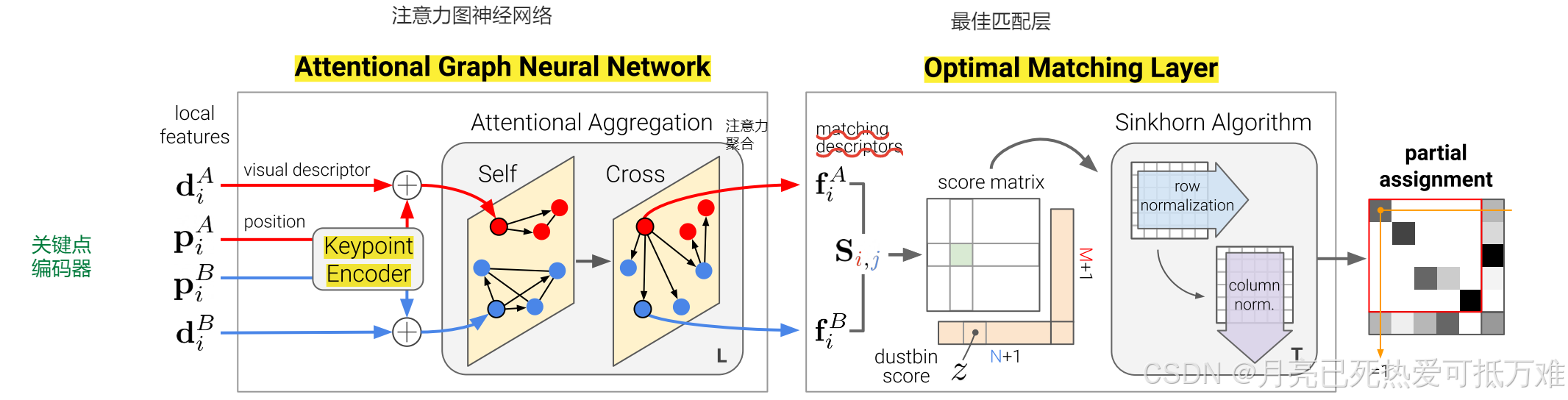
SuperGlue架构。SuperGlue由两个主要组件组成:注意力图神经网络和最佳匹配层。第一个组件使用关键点编码器将关键点位置p及其视觉描述符d映射到单个向量中,然后使用交替的自我和交叉注意层(重复L次)来创建更强大的表示f。最佳匹配层创建一个M × N得分矩阵,用垃圾箱对其进行扩充,然后使用Sinkhorn算法(T次迭代)找到最佳部分分配。
此外,2D关键点通常是显著3D点的投影,如角点或斑点,因此图像之间的对应关系必须遵守某些物理约束:
- i )关键点在另一幅图像中最多只能具有单个对应关系;
- ii )由于检测器的遮挡和故障,一些关键点将不匹配。
整个过程相对的思想并没有那么难,但相对的过程还是很巧妙的结构。
公式描述
考虑两个图像A和B,每个图像具有一组关键点位置p和相关联的视觉描述符d -我们将它们联合(p,d)称为局部特征
-
局部特征的定义是位置和256为的高维向量拼接而成的结构(p,d)
-
位置由 x 和 y 图像坐标以及检测置信度 c、pi := (x, y, c)i 组成。
-
视觉描述符di∈RD可以是像SuperPoint这样的CNN提取的描述符或传统的描述符,如SIFT。图像 A 和 B 有 M 和 N 个局部特征,由 A := {1, …, M } 和 B := {1,…, N },分别表示。
-
我们将部分软分配矩阵
P ∈ [0, 1]M ×N定义为:(类似于双随机散列矩阵的形式)
P 1 N ≤ 1 M and P ⊤ 1 M ≤ 1 N . \mathbf{P} \mathbf{1}_{N} \leq \mathbf{1}_{M} \quad \text { and } \quad \mathbf{P}^{\top} \mathbf{1}_{M} \leq \mathbf{1}_{N} . P1N≤1M and P⊤1M≤1N.
我们的目标是设计一个神经网络,从两组局部特征预测分配P。也就是MxN的这个类似于相似性的矩阵。
注意力图神经网络
除了关键点的位置及其视觉外观外,整合其他上下文线索可以直观地增加其独特性。例如,我们可以将其空间和视觉关系与其他共可见关键点联系起来,例如显著、自相似、统计共发生或相邻关键点。另一方面,第二幅图像中关键点的知识可以通过比较候选匹配或从全局和明确的线索估计相对光度或几何变换来帮助解决歧义。
我们将SuperGlue的第一个主要模块设计为注意力图神经网络。给定初始局部特征,它通过让特征彼此通信来计算匹配描述符fi ∈ RD。
通过图神经网络和两种注意力机制,来聚合点特征信息,重点就是学习具体的聚合策略。
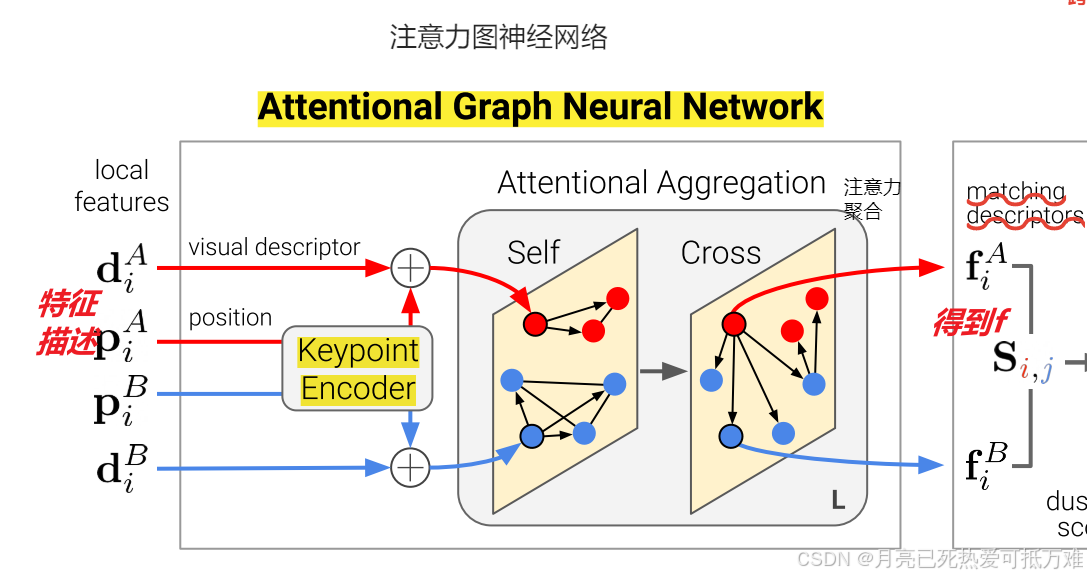
Keypoint Encoder
这个注意力图神经网络的第一个部分就是这个关键点编码器了。
这一部分其中是用来初始化图的节点信息。
- 每个关键点 i 的初始表示 (0)xi 结合了其视觉外观和位置。我们将关键点位置嵌入到具有多层感知器 (MLP) 的高维向量中,如下所示:
( 0 ) x i = d i + MLP e n c ( p i ) { }^{(0)} \mathbf{x}_{i}=\mathbf{d}_{i}+\operatorname{MLP}_{\mathrm{enc}}\left(\mathbf{p}_{i}\right) (0)xi=di+MLPenc(pi)
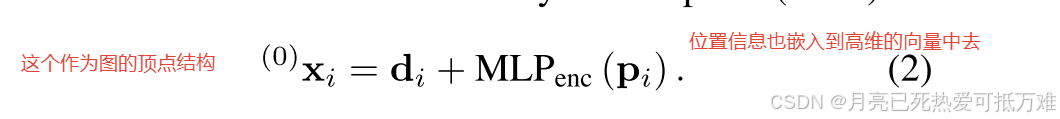
2. 这种编码器使图形网络能够在以后联合地推理外观和位置,特别是当与注意力相结合时,并且是语言处理中流行的“位置编码器”的实例
Multiplex Graph Neural Network
第二部分就是告诉我们应该构造的是什么样的图结构,这里并不是之前的两个完全图来完成匹配的。
而是构造了更为复杂的多重图神经网络Multiplex Graph Neural Network结构。
- 图有两种类型的无向边-它是一个多重图。
下面先具体的说明它采用的是哪两种类型的无向边呢?
- 同图边也叫自边,是表示的是在同一图像内连接关键点的边。具体来说,图中的一个关键点 i会与同一图像中的所有其他关键点相连。
这种L次的聚合方式一看用的就是自注意力的方式来进行聚合的。
E self \mathcal{E}_{\text {self }} Eself
- Inter-image edges(跨图边)则表示的是跨越不同图像的连接关系。一个图像中的关键点 i会与另一个图像中的所有关键点相连。
这种L次的聚合方式一看用的就是交叉注意力的方式来进行聚合的。
E cross \mathcal{E}_{\text {cross }} Ecross

- 我们使用消息传递公式来沿着沿着两种类型的边传播信息。生成的多路图神经网络从每个节点的高维状态开始,并通过同时聚合所有节点的所有给定边的消息来计算每一层的更新表示。
( ℓ ) x i A { }^{(\ell)} \mathbf{x}_{i}^{A} (ℓ)xiA
是图像A中的元素i在层m处的中间表示。
m E → i \mathbf{m}_{\mathcal{E} \rightarrow i} mE→i
是从所有关键点:
{ j : ( i , j ) ∈ E } E ∈ { E self , E cross } \{j:(i, j) \in \mathcal{E}\} \mathcal{E} \in\left\{\mathcal{E}_{\text {self }}, \mathcal{E}_{\text {cross }}\right\} {j:(i,j)∈E}E∈{Eself ,Ecross }
聚合的结果,其中 E ∈ {Eself, Ecross}。A中所有 i 的残差消息传递更新为:
( ℓ + 1 ) x i A = ( ℓ ) x i A + MLP ( [ ( ℓ ) x i A ∥ m E → i ] ) { }^{(\ell+1)} \mathbf{x}_{i}^{A}={ }^{(\ell)} \mathbf{x}_{i}^{A}+\operatorname{MLP}\left(\left[{ }^{(\ell)} \mathbf{x}_{i}^{A} \| \mathbf{m}_{\mathcal{E} \rightarrow i}\right]\right) (ℓ+1)xiA=(ℓ)xiA+MLP([(ℓ)xiA∥mE→i])
其中 [· || ·] 表示连接。可以对图像 B 中的所有关键点同时执行类似的更新。固定数量的具有不同参数的层 L 被链接并沿自边和交叉边交替聚合。因此,从ℓ=1开始,如果ℓ是奇数,则E=Eself,如果ℓ是偶数,则E=Ecross。
图的聚合—Attentional Aggregation
注意力机制执行聚合并计算消息 mE→i。Self edge 基于 self-attention,cross edge 基于交叉注意力。与数据库检索类似,i 的表示,query查询 qi,根据它们的属性(key键 kj)检索某些元素的values值 vj。消息被计算为值的加权平均值:
m E → i = ∑ j : ( i , j ) ∈ E α i j v j \mathbf{m}_{\mathcal{E} \rightarrow i}=\sum_{j:(i, j) \in \mathcal{E}} \alpha_{i j} \mathbf{v}_{j} mE→i=j:(i,j)∈E∑αijvj
其中,注意力权重αij是关键字查询相似度上的Softmax:
α i j = Softmax j ( q i ⊤ k j ) \alpha_{i j}=\operatorname{Softmax}_{j}\left(\mathbf{q}_{i}^{\top} \mathbf{k}_{j}\right) αij=Softmaxj(qi⊤kj)
考虑到查询关键点i在图像Q中并且所有源关键点都在图像S中,(Q,S)∈ {A,B}2,我们可以写为:
q i = W 1 ( ℓ ) x i Q + b 1 [ k j v j ] = [ W 2 W 3 ] ( ℓ ) x j S + [ b 2 b 3 ] . \begin{aligned} \mathbf{q}_{i} & =\mathbf{W}_{1}{ }^{(\ell)} \mathbf{x}_{i}^{Q}+\mathbf{b}_{1} \\ {\left[\begin{array}{l} \mathbf{k}_{j} \\ \mathbf{v}_{j} \end{array}\right] } & =\left[\begin{array}{l} \mathbf{W}_{2} \\ \mathbf{W}_{3} \end{array}\right]{ }^{(\ell)} \mathbf{x}_{j}^{S}+\left[\begin{array}{l} \mathbf{b}_{2} \\ \mathbf{b}_{3} \end{array}\right] . \end{aligned} qi[kjvj]=W1(ℓ)xiQ+b1=[W2W3](ℓ)xjS+[b2b3].
每层ℓ 具有针对两个图像的所有关键点学习和共享的自己的投影参数。在实践中,我们通过多头注意力来提高表现力.
SuperGlue可以根据外观和关键点位置进行检索或参与,因为它们被编码在表示Xi中。
我们的公式提供了最大的灵活性,因为网络可以学习基于特定属性的关键点子集(见图4)。SuperGlue可以根据外观和关键点位置来检索或参与,因为它们在表示xi中编码。这包括关注附近的关键点并检索相关相似或显著关键点的位置。这样可以表示几何变换和赋值。最终的匹配描述符是线性投影:
f i A = W ⋅ ( L ) x i A + b , ∀ i ∈ A , \mathbf{f}_{i}^{A}=\mathbf{W} \cdot{ }^{(L)} \mathbf{x}_{i}^{A}+\mathbf{b}, \quad \forall i \in \mathcal{A}, fiA=W⋅(L)xiA+b,∀i∈A,
对于B来说也是同理的。
Optimal matching layer-最佳匹配层
SuperGlue的第二个主要模块是最优匹配层,它产生一个部分分配矩阵。
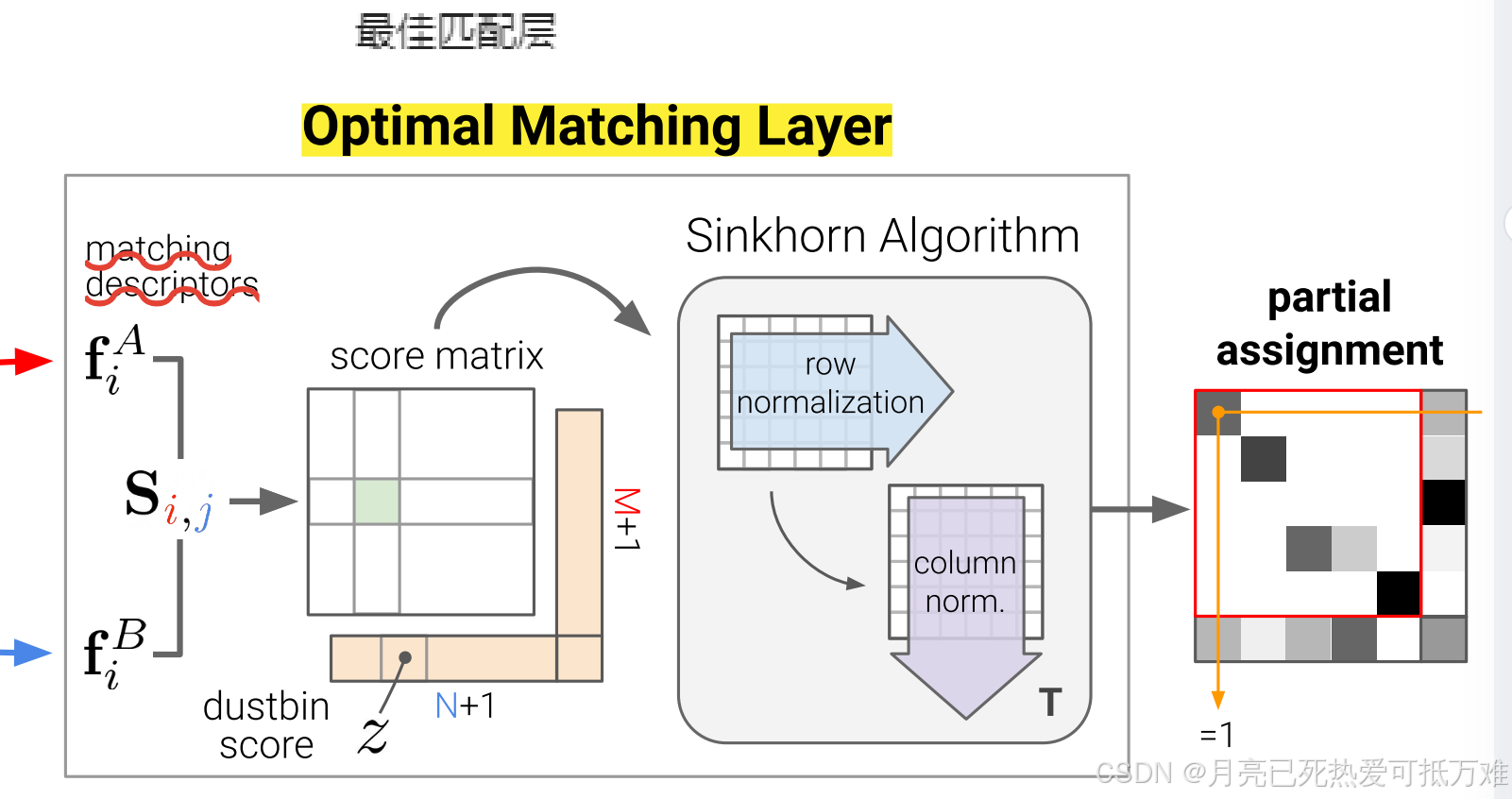
如在标准图匹配公式中,分配P可以通过计算得分矩阵来获得
S ∈ R M × N \mathbf{S} \in \mathbb{R}^{M \times N} S∈RM×N
并在等式1的约束下最大化总分:
∑ i , j S i , j P i , j \sum_{i, j} \mathbf{S}_{i, j} \mathbf{P}_{i, j} i,j∑Si,jPi,j
来获得。这相当于求解线性分配问题。
Score Prediction
为所有M×N个潜在匹配构建单独的表示将是禁止的。相反,我们将成对得分表示为匹配描述符的相似性:
S i , j = < f i A , f j B > , ∀ ( i , j ) ∈ A × B \mathbf{S}_{i, j}=<\mathbf{f}_{i}^{A}, \mathbf{f}_{j}^{B}>, \forall(i, j) \in \mathcal{A} \times \mathcal{B} Si,j=<fiA,fjB>,∀(i,j)∈A×B
其中<·,·>是内积。与学习的视觉描述符相反,匹配描述符不是归一化的,并且它们的幅度可以在每个特征和训练期间变化,以反映预测置信度。
Occlusion and Visibility: 遮挡和可见性
为了让网络抑制一些关键点,我们用一个垃圾箱来增加每个集合,以便将不匹配的关键点显式分配给它。这种技术在图匹配中很常见,SuperPoint也使用垃圾箱来解释可能没有检测到的图像单元。我们通过添加一个新行和列,即点到bin和bin到bin的分数,将分数S增加到S-,并填充一个可学习的参数:
S ‾ i , N + 1 = S ‾ M + 1 , j = S ‾ M + 1 , N + 1 = z ∈ R \overline{\mathbf{S}}_{i, N+1}=\overline{\mathbf{S}}_{M+1, j}=\overline{\mathbf{S}}_{M+1, N+1}=z \in \mathbb{R} Si,N+1=SM+1,j=SM+1,N+1=z∈R
虽然A中的关键点将被分配给B或垃圾箱中的单个关键点,但每个垃圾箱具有与另一组中的关键点一样多的匹配:N、M分别用于A、B中的垃圾箱。
a = [ 1 M ⊤ N ] ⊤ b = [ 1 N ⊤ M ] ⊤ \mathbf{a}=\left[\begin{array}{ll} \mathbf{1}_{M}^{\top} & N \end{array}\right]^{\top} \mathbf{b}=\left[\begin{array}{ll} \mathbf{1}_{N}^{\top} & M \end{array}\right]^{\top} a=[1M⊤N]⊤b=[1N⊤M]⊤
A和B中每个关键点和垃圾箱的预期匹配数。增广赋值<$P现在具有约束:
P ‾ 1 N + 1 = a and P ‾ ⊤ 1 M + 1 = b . \overline{\mathbf{P}} \mathbf{1}_{N+1}=\mathbf{a} \quad \text { and } \quad \overline{\mathbf{P}}^{\top} \mathbf{1}_{M+1}=\mathbf{b} . P1N+1=a and P⊤1M+1=b.

开源鸿蒙跨平台开发社区汇聚开发者与厂商,共建“一次开发,多端部署”的开源生态,致力于降低跨端开发门槛,推动万物智联创新。
更多推荐

 9
9 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)