UniLION论文学习
本文提出UniLION自动驾驶统一模型,采用线性组RNN处理多模态长序列数据。该模型通过直接序列连接实现多种输入模式(LiDAR点云、多视图图像、时间序列)的统一处理,无需显式融合模块。UniLION生成共享BEV特征,支持并行执行3D检测、跟踪、预测和规划等任务。实验表明,该模型在多种配置下均具竞争力,为自动驾驶基础模型提供了新思路。
UniLION: Towards Unified Autonomous Driving Model with Linear Group RNNs
摘要
尽管 Transformer 在各个领域都表现出了卓越的能力,但它们的二次注意力机制在处理长序列数据时会带来巨大的计算开销。在本文中,我们提出了一种统一的自动驾驶模型 UniLION,它可以有效地处理大规模 LiDAR 点云、高分辨率多视图图像,甚至基于线性组 RNN 算子(即对分组特征执行线性 RNN)的时间序列。值得注意的是,UniLION 作为单一多功能架构,可以无缝支持多种专用变体(即仅 LiDAR、时间 LiDAR、多模态和多模态时间融合配置),而不需要显式时间或多模态融合模块。此外,UniLION 在广泛的核心任务中始终如一地提供具有竞争力甚至最先进的性能,包括 3D 感知(例如 3D 对象检测、3D 对象跟踪、3D 占用预测、BEV 地图分割)、预测(例如运动预测)和规划(例如端到端规划)。这种统一的范式自然简化了多模式和多任务自动驾驶系统的设计,同时保持卓越的性能。最终,我们希望 UniLION 为自动驾驶 3D 基础模型的开发提供全新的视角。代码见:https://github.com/happinesslz/UniLION
1. INTRODUCTION
自动驾驶技术能够跨空间和时间维度有效处理来自多视角摄像头和激光雷达传感器的海量异构传感器数据,对于在复杂驾驶场景中实现稳健的感知、预测甚至规划至关重要。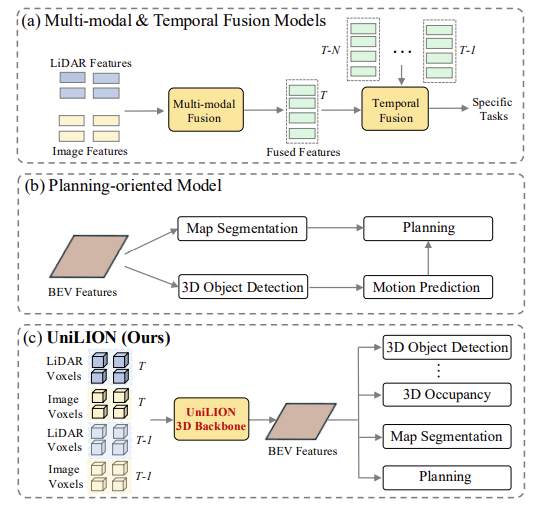
图1
(a)展示了实现多模态融合或时间融合的主流方法。
(b)展示了实现端到端自动驾驶系统的经典流程。
(c) 演示了我们的方法 UniLION,它将多种输入模式和时间序列优雅地统一到一个单一的多功能架构中。 UniLION 可以无缝支持多种专用变体(即仅 LiDAR、时间 LiDAR、多模态和多模态时间融合配置),无需显式时间或多模态融合模块。此外,UniLION 通过共享 BEV 特征表示,利用其 3D 主干的全面且卓越的特征提取功能,能够以解耦的方式并发执行多个下游任务。
如图1(a)所示,对于空间多模态融合,经典方法[1]、[2]、[3]通过逐点或体素对齐在多视图图像和LiDAR点云之间建立明确的几何对应关系,以实现有效的跨模态信息交互。最近,基于 BEV 的融合方法 [4]、[5] 采用统一的空间表示策略,将异构传感器特征转换到鸟瞰(BEV)空间,然后通过级联或注意力机制融合多模态 BEV 表示。对于时间建模,最近的方法 [6]、[7]、[8]、[9]、[10]、[11]、[12] 通过跨帧几何对齐 BEV 特征或采用基于注意力的查询融合来合并时间信息。因此,现有方法通常需要专门的多模态和时间融合模块,从而导致更复杂的系统架构。
此外,如图 1 (b) 所示,处理 3D 对象检测、运动预测和规划等不同任务通常需要复杂的模块间依赖关系才能获得更好的性能。例如,UniAD [13] 和 VAD [14] 采用具有复杂任务相互依赖关系的顺序模块连接,其中下游任务依赖于上游模块的高维潜在特征,导致潜在的错误传播和优化挑战。 FusionAD [15] 在 UniAD 的基础上,通过额外的跨模式注意机制和特征对齐模块进一步整合了相机-LiDAR 融合,但该框架仍然依赖于专门的融合架构,从而增加了系统的复杂性。为了避免顺序依赖,PARA-Drive [16] 采用了基于共享 BEV 功能的多任务并行架构,但主要侧重于面向规划的优化,导致基本 3D 感知和预测任务的性能较差。总之,这些方法要么因专门的融合模块和顺序依赖关系而遭受架构复杂性的困扰,要么牺牲不同任务之间的性能平衡。
虽然 Transformer 由于其灵活的注意力机制而有望构建统一的框架,但在处理自动驾驶场景中典型的长序列(例如具有数十万个点的密集点云、扩展的时间序列甚至多种模态)时,其二次复杂度变得令人望而却步。这就提出了一个关键问题:我们能否设计一个统一的 3D 主干网,以可接受的计算成本跨多个任务无缝处理不同的模式和时间信息,而不需要任何显式的融合模块?
线性 RNN 提供了一个引人注目的解决方案。线性 RNN 最重要的特性之一是它们相对于序列长度的线性复杂性,这与基于 Transformer 的注意力机制的二次复杂性形成鲜明对比。更重要的是,这种计算优势释放了新的可能性:线性复杂性允许将来自不同模态和时间框架的标记直接串联成单个扩展序列,促进全面的模态间和时间交互,同时自动学习互补关系,而无需手工制作的融合设计。
为了实现这一目标,我们提出了 UniLION,这是一个统一的框架,通过基于线性 RNN 的 3D 主干处理多个任务的多模态和时间信息,如图 1 (c) 所示。这种方法本质上将范式从显式多模态和时间融合转变为隐式统一表示学习,如大型语言模型(LLM)。具体来说,异构传感器流(即多视图图像、LiDAR点云和时间序列)可以通过直接令牌级(即将每个体素视为一个令牌)串联进行有效统一,并由UniLION的统一3D主干进行集中处理,从而无需专门的融合架构。
受益于我们统一的 3D 主干在远程建模方面的强大能力,UniLION 生成了紧凑但全面的 BEV 功能,通过并行多任务学习同时支持多个下游任务。这消除了顺序依赖性,同时保持了感知、预测和规划方面的竞争性能。
最后但并非最不重要的一点是,UniLION 可以作为单一多功能架构,可以无缝适应多种专用变体(即仅 LiDAR、时态 LiDAR、多模态和多模态时间设置),而不需要显式的时态/多模态融合模块。因此,一旦使用多模态时态数据进行训练,我们的 UniLION 就可以在推理阶段直接部署用于仅 LiDAR、时态 LiDAR 或多模态设置,从而实现跨不同传感器设置的稳健操作以及安全关键型应用中的容错部署。
总之,基于我们之前针对基于线性 RNN 的 3D 对象检测的会议工作 LION [17],该扩展引入了 3D 空间特征描述符来增强局部空间信息捕获和体素生成策略来致密前景特征,该扩展做出了以下新贡献:
- 统一异构输入:利用线性组 RNN 卓越的远程建模能力和线性计算复杂性,UniLION 将多视图图像、LiDAR 点云和时间信息集成到一个通过直接令牌串联统一 3D 主干,消除手工制作的融合模块并提供更优雅、可扩展的解决方案。
- 统一模型:UniLION 支持跨不同输入格式共享参数。具体来说,一旦使用多模态时态数据进行训练,相同的 UniLION 模型就可以直接部署在不同的传感器配置和时态设置(例如,仅 LiDAR、时态 LiDAR 或多模态融合)中,而无需重新训练,从而表现出对不同操作条件的卓越适应性。
- 统一输出表示:UniLION 将异构多模态和时间信息高度压缩为紧凑的 BEV 特征表示,作为共享特征,通过并行多任务学习同时支持不同的自动驾驶任务,消除顺序依赖性,同时保持跨感知、预测和规划任务的竞争性能。
- 卓越的性能:UniLION 在全面的自动驾驶任务中实现了具有竞争力和最先进的性能,包括 3D 感知(例如 3D 对象检测、跟踪、占用预测、BEV 地图分割)、运动预测和端到端规划,证明了我们统一方法的通用性和有效性。
2. RELATED WORKS
线性循环神经网络(Linear RNN):递归神经网络 (RNN) 最初是为了通过有效捕获序列数据中的时间依赖性来解决自然语言处理 (NLP) 中的序列建模问题,例如时间序列预测和语音识别。 RNN 的一个关键优势是其处理序列特征的线性计算复杂性,与基于注意力的机制相比,这在处理长序列时显着降低了计算成本。近年来,研究人员开发了先进的时间可并行的数据相关 RNN(在本文中称为线性 RNN),以克服 Transformer 架构中固有的二次计算复杂性 [18]、[19]、[20]、[21]、[22]、[23]、[24]、[25]、[26]、[27]。这些现代线性 RNN 变体保持了理想的线性复杂性,同时实现了高效的并行训练,使它们在各种任务上实现了与 Transformer 相当甚至超过 Transformer 的性能。基于这些进展,大量研究 [17]、[28]、[29]、[30]、[31] 探索了线性 RNN 算子对不同 2D 和 3D 计算机视觉应用的适应。特别是对于大规模室外 3D 场景,与基于 Transformer 的方法相比,线性 RNN 在以更低的计算开销实现远程建模方面表现出了卓越的能力,从而增强了自动驾驶感知任务的性能。
多模态时间融合(Multi-modal Temporal Fusion):多模态融合[2]、[3]、[4]、[32]、[33]、[34]、[35]和时间融合[6]、[8]、[9]、[11]、[12]、[36]、[37]是提高自动驾驶性能和鲁棒性的关键技术。对于多模态融合,现有方法可以分为两个主要范式。第一个范式 [4]、[5] 将点云和图像特征转换为统一的 BEV 表示,通过 BEV 空间中的特征级集成实现多模态融合。第二个范式[1]、[2]、[33]、[34]、[38]采用基于投影的交互机制,其中LiDAR逐点或体素特征被投影到多视图图像上以促进跨模态特征交互。此外,时间融合提供了跨时间步长的丰富上下文信息,以提高特征表示质量。早期的方法 [8]、[36] 连接历史和当前输入点云以进行时间整合。最近的方法 [6]、[9] 在特征级别执行时间融合(例如,BEV 特征和查询特征)。为了解决重复提取历史特征的计算开销,人们提出了流时间融合方法[11]、[12]、[37],以流方式对扩展序列进行有效的时间集成。相比之下,我们的 UniLION 优雅地将多种输入模式和时间序列统一到一个多功能架构中。 UniLION 无缝适应多种专用配置(即仅 LiDAR、时间 LiDAR、多模态和多模态时间融合变体),无需显式时间或多模态融合模块。
3D 感知(3D Perception): 3D 感知是后续预测和规划任务的基础。从目标的角度来看,有3D物体检测、3D多物体跟踪、BEV地图分割、3D占用预测任务。对于 3D 检测,基于点的方法将原始点 [39]、[40]、[41]、[42]、[43]、[44]、[45] 作为输入,并实现 PointNets [46]、[47] 以获得细粒度的几何信息。基于体素的方法[36]、[48]、[49]、[50]、[51]、[52]、[53]、[54]、[55]、[56]、[57]、[58]、[59]、[60]、[61]、[62]将输入不规则点云量化为规则3D体素以进行特征提取,然后将3D特征转换为BEV (鸟瞰)3D 检测功能。对于3D多目标跟踪,一些方法[36]、[63]、[64]、[65]采用检测跟踪范式来根据检测结果跟踪目标,而其他方法[66]、[67]则采用端到端范式来联合优化检测和跟踪。对于 BEV 地图分割,现有方法 [4]、[9] 使用 BEV 特征上的 2D 卷积来预测分割掩模。对于3D占用预测,一些方法[68]、[69]将多视图图像特征提升为3D体积特征,然后对3D体积特征采用3D卷积来预测每个体素的结果。
运动预测和规划(Motion Prediction and Planning):运动预测和规划任务分别涉及预测周围物体和自我车辆的未来轨迹。当前自动驾驶系统的研究可大致分为两种架构范式。第一个范例采用模块化架构[13]、[14]、[67]、[70]、[71],将自动驾驶管道分解为一系列组件,其中规划模块明确依赖于运动预测输出。第二种范式采用并行架构[16],该架构利用基于鸟瞰图(BEV)表示的并行处理架构,从而减少累积错误。
多任务学习(Multi-task Learning):许多工作一直在研究如何通过多任务学习用一种模型处理更多任务(例如,3D 对象检测、跟踪、BEV 地图分割和 3D 占用预测)。为了结合 3D 检测和 BEV 地图分割任务,BEVFusion [4] 采用单独的 BEV 主干来实现两个任务之间的平衡。当将 3D 检测与 3D 占用预测集成时,PanoOcc [69] 通过共享占用表示来统一特征学习和场景表示。对于涉及 3D 检测、BEV 地图分割和 3D 占用预测的更复杂的多任务场景,M3Net [72] 引入了一种面向任务的通道缩放机制,以减轻联合优化期间的梯度冲突。 PARA-Drive [16] 采用基于共享 BEV 功能的并行多任务架构,用于各种自动驾驶任务。然而,它主要关注面向规划的优化,导致基本感知和预测任务的性能不佳。相比之下,本文提出了 UniLION,这是一个全面的统一框架,可以同时处理完整的自动驾驶任务(即 3D 感知、预测和规划)。值得注意的是,我们的方法实现了这种统一,无需额外的特定于任务的设计,仅依赖于动态多任务损失机制(详见 3.6 节)。尽管很简单,但与所有评估任务中的专用单任务模型相比,UniLION 始终提供有竞争力且通常最先进的性能。
3. METHODS
3.1 Overview
在本文中,我们提出了一种基于线性组 RNN(即对分组特征执行线性 RNN)的简单有效的基于窗口的统一框架,名为 UniLION,它可以对数千个体素进行分组(比以前的方法 [60]、[61]、[73] 数量多几十倍)进行特征交互。此外,UniLION可以直接处理时间多模态体素,实现时间融合和多模态融合,无需任何额外的融合模块。我们的 UniLION 的流程如图 2 所示。UniLION 由 LiDAR 编码器、图像编码器、统一 3D 主干、BEV 主干以及针对不同任务的各种任务头组成。在本文中,我们的主要贡献在于基于线性群 RNN 的多模态和时间融合的统一 3D 主干。下面我们就来介绍一下UniLION的整体细节。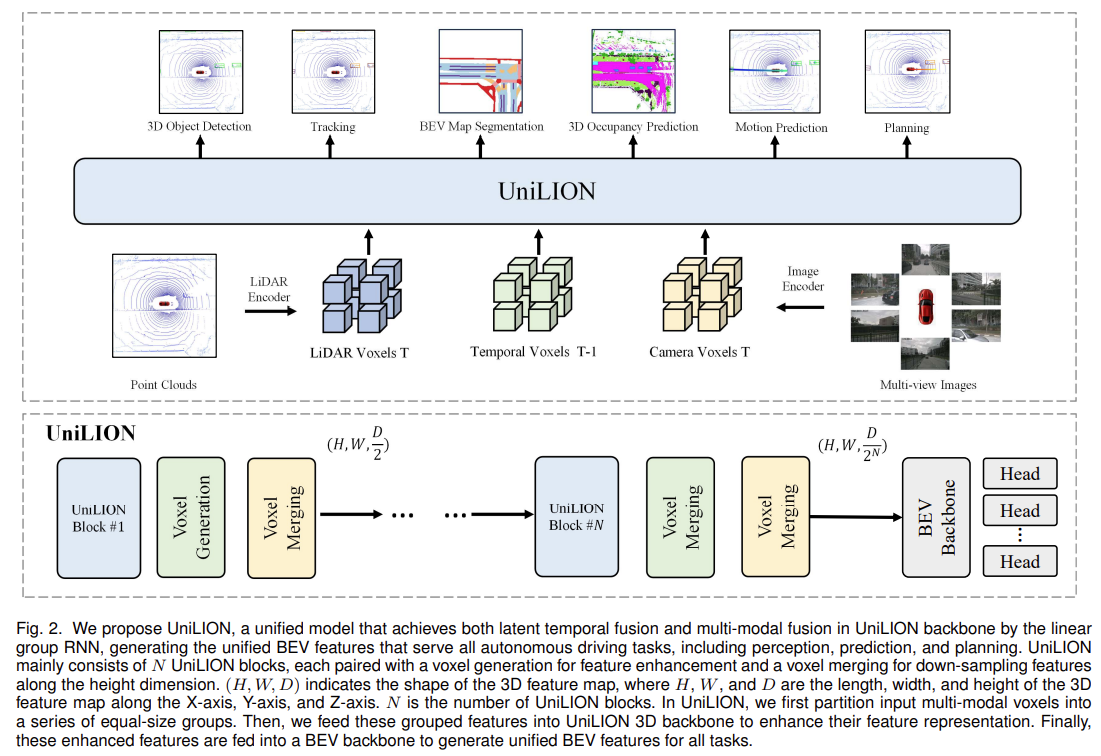
图 2.
我们提出了 UniLION,这是一个统一模型,通过线性组 RNN 在 UniLION 主干中实现潜在时间融合和多模态融合,生成服务于所有自动驾驶任务(包括感知、预测和规划)的统一 BEV 特征。 UniLION 主要由 N 个 UniLION 块组成,每个块都配有用于特征增强的体素生成和用于沿高度维度下采样特征的体素合并。 (H、W、D)表示3D特征图的形状,其中H、W和D是3D特征图沿X轴、Y轴和Z轴的长度、宽度和高度。 N 是 UniLION 块的数量。在 UniLION 中,我们首先将输入多模态体素划分为一系列大小相等的组。然后,我们将这些分组特征输入 UniLION 3D 主干以增强其特征表示。最后,这些增强的功能被输入到 BEV 主干中,为所有任务生成统一的 BEV 功能。
3.2 LiDAR and Image Encoders
UniLION 结合了 LiDAR 编码器和图像编码器,分别从点云和多视图图像中提取 LiDAR 体素和相机体素。对于 LiDAR 编码器,我们通过动态体素化将点云转换为体素,然后通过两个线性层生成 LiDAR 体素特征。对于图像编码器,我们利用已建立的视觉图像主干(例如 ResNet-50、SwinTiny)来提取多视图图像特征。为了将这些 2D 图像特征投影到 3D 空间中,我们采用由三个 2D 卷积层组成的轻量级深度估计分支来预测像素级深度值。具体来说,我们根据深度估计置信度分数选择前 K 个候选深度(默认设置 K = 4)。然后将这些候选深度与相机矩阵相结合,在统一 3D 坐标系中生成相机体素。为了解决多个相机体素占据相同 3D 位置的空间冲突,我们通过对每个空间位置的特征进行元素求和来合并重复的相机体素。最后,提取的 LiDAR 体素和相机体素沿着体素维度直接连接并输入 UniLION 3D 主干网。
3.3 3D Sparse Window Partition
UniLION 实现了 3D 稀疏窗口分区来对输入体素进行分组以进行特征交互。具体来说,我们首先将输入体素划分为形状为(Sx,Sy,Sz)的不重叠的3D窗口,其中Sx,Sy和Sz表示窗口沿X轴,Y轴和Z轴的长度,宽度和高度。接下来,我们分别沿着 X 轴(对于 X 轴窗口分区)和 Y 轴(对于 Y 轴窗口分区)对体素进行排序。最后,为了降低计算成本,我们将排序的体素划分为相同大小 G 的组,而不是相同形状的窗口以进行特征交互。由于变压器的二次计算复杂性,先前基于变压器的方法[60]、[61]、[73]只能使用较小的组大小来实现特征交互。相比之下,由于线性组 RNN 算子的线性计算复杂性,我们采用更大的组大小 G 来获得远程特征交互。
3.4 UniLION Block
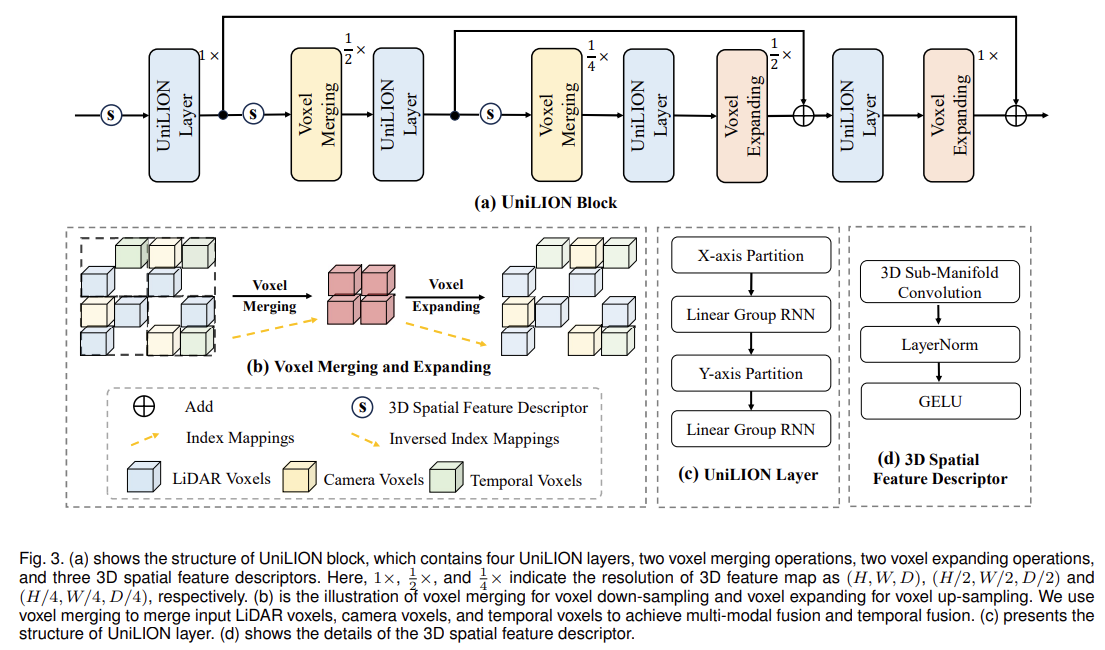
图 3.
(a) 显示了 UniLION 块的结构,其中包含四个 UniLION 层、两个体素合并操作、两个体素扩展操作和三个 3D 空间特征描述符。这里,1×、1/2 ×和1/4 ×分别表示3D特征图的分辨率为(H,W,D)、(H/2,W/2,D/2)和(H/4,W/4,D/4)。
(b)是用于体素下采样的体素合并和用于体素上采样的体素扩展的图示。我们使用体素合并来合并输入激光雷达体素、相机体素和时间体素,以实现多模态融合和时间融合。
(c) 展示了 UniLION 层的结构。
(d)显示 3D 空间特征描述符的细节。
UniLION 块是我们方法的核心组件,其中涉及用于远程特征交互的 UniLION 层、用于捕获局部 3D 空间信息的 3D 空间特征描述符、用于特征下采样的体素合并以及用于特征上采样的体素扩展,如图 3(a)所示。而且,UniLION块是分层结构,可以更好地提取多尺度特征。接下来我们介绍UniLION区块的各个部分。
- 体素合并和体素扩展(Voxel Merging and Voxel Expanding):为了使网络能够获得多尺度特征,我们的UniLION采用了分层特征提取结构。为了实现这一点,我们需要在高度稀疏的点云中执行特征下采样和上采样操作。然而,值得一提的是,我们不能像 2D 图像那样简单地应用最大或平均池化或上采样操作,因为 3D 点云具有不规则的数据格式。因此,如图3(b)所示,我们在高度稀疏的点云中采用体素合并进行特征下采样,采用体素扩展进行特征上采样。具体来说,对于体素合并,我们计算下采样索引映射以合并体素。在体素扩展中,我们通过相应的逆索引映射对下采样的体素进行上采样。
- UniLION 层(UniLION Layer):在 UniLION 块中,我们应用 UniLION 层在线性组 RNN 算子的帮助下对分组特征之间的远程关系进行建模。具体来说,如图3(c)所示,我们提供了UniLION层的结构,它由两个线性群RNN算子组成。第一个用于基于X轴窗口分区进行远程特征交互,第二个可以基于Y轴窗口分区提取远程特征信息。通过两个不同的窗口划分,UniLION层可以获得更充分的特征交互,产生更具辨别力的特征表示。
- 3D 空间特征描述符(3D Spatial Feature Descriptor):尽管线性RNN具有远程建模和低计算成本的优点,但不可忽视的是,当输入体素特征被展平为一维序列特征时,空间信息可能会丢失。例如,如图4所示,3D空间中有两个相邻的特征(即索引为01和34)。然而,当它们被展平为一维序列特征后,它们在一维空间中的距离非常远。我们将这种现象视为 3D 空间信息的丢失。为了解决这个问题,一种可用的方法是增加体素特征的扫描顺序数量,例如 VMamba [74] 和 Vim [75]。然而,扫描的顺序过于手工设计。而且,随着扫描次数的增加,相应的计算成本也显着增加。因此,在大规模稀疏3D点云中采用这种方式是不合适的。如图3(d)所示,我们引入了一个3D空间特征描述符,它由3D子流形卷积、LayerNorm层和GELU激活函数组成。当然,我们利用 3D 空间特征描述符为 UniLION 层提供丰富的 3D 局部位置感知信息。此外,我们将 3D 空间特征描述符放置在体素合并之前,以减少体素合并中的空间信息损失。
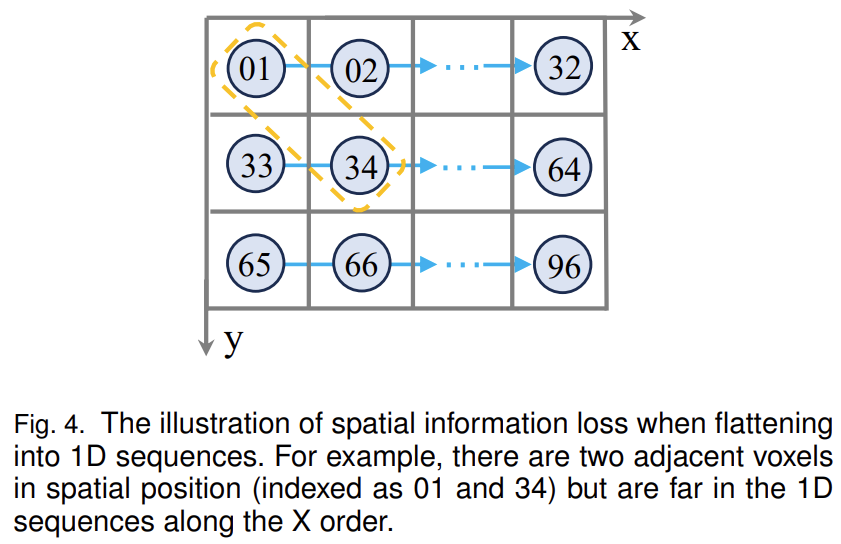
图 4. 展平为一维序列时空间信息损失的图示。例如,在空间位置上有两个相邻体素(索引为 01 和 34),但沿 X 顺序在 1D 序列中距离较远。 - 自回归体素生成(Auto-regressive Voxel Generation):尽管我们在 UniLION 主干中使用相机体素和时间体素来补偿 LiDAR 体素,但在图 3 中实现体素合并仍然存在潜在信息丢失的挑战。因此,我们提出了一种体素生成策略,借助线性群 RNN 的自回归能力来解决这些问题。具体来说,为了方便起见,我们将所选前景体素特征 F m F_m Fm的对应坐标定义为 P m P_m Pm。如图5所示,我们首先通过分别沿X轴、Y轴和Z轴以四个不同的偏移量(即[-1,-1, 0]、[1,1, 0]、[1,-1, 0]和[-1,1, 0])扩散Pm来获得扩散体素。然后,我们将扩散体素的相应特征初始化为全零。接下来,我们将第 i 个 UniLION 块的输出特征 Fi 与初始化的体素特征连接起来,并将它们输入到后续的第 (i + 1) 个 UniLION 块中。最后,由于UniLION块的自回归能力,可以基于大组中的其他体素特征有效地生成扩散体素特征。该过程表述为:
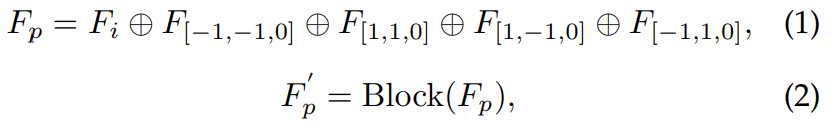
其中 F[x,y,z] 表示初始化体素特征,其中 x、y 和 z 沿 X 轴、Y 轴和 Z 轴扩散偏移。 ⊕ 和 Block 分别表示串联和 UniLION 块。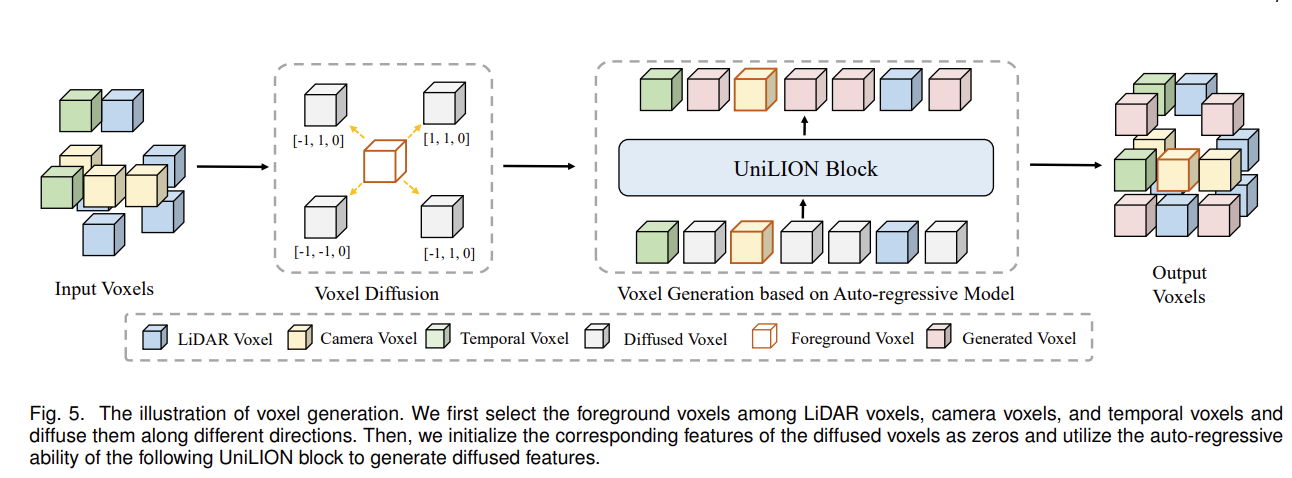
图 5. 体素生成示意图。我们首先在激光雷达体素、相机体素和时间体素中选择前景体素,并将它们沿着不同的方向扩散。然后,我们将扩散体素的相应特征初始化为零,并利用以下 UniLION 块的自回归能力来生成扩散特征。
3.5 Unified Feature Representation
以前的方法[4]、[6]、[7]、[10]通常采用额外的精心设计的模块来实现多模态或时间融合模块。相比之下,我们的目标是将所有 LiDAR 体素、相机体素甚至时间体素馈送到 UniLION 的统一 3D 主干中,而不需要额外的多模态或时间融合模块。得益于 UniLION 3D 主干在长距离建模方面的强大表示能力,我们可以自适应地对 LiDAR 体素、相机体素和时间体素的关系进行建模。
- 多模态特征学习(Multi-modal Feature Learning):在自动驾驶场景中,激光雷达点云和相机图像表现出很强的互补性,激光雷达提供精确的几何结构,而相机图像则提供丰富的语义外观信息。因此,UniLION 的目标是通过利用线性 RNN 强大的远程建模能力,将这些异构模态有效地集成到统一的 3D 主干中,从而实现相互增强。具体来说,给定输入点云和多视图图像,我们首先将点云量化为体素,并使用体素特征编码器(VFE)来提取这些体素,获得 LiDAR 体素为 V l ∈ R L l × C V_l \in \R^{L_l×C} Vl∈RLl×C 。对于多视图图像,我们首先使用图像主干来提取多视图图像特征。随后,我们采用深度网络来预测多视图深度图,并根据预测深度和数据集提供的校准矩阵将图像特征转换为相机体素 V c ∈ R L l × C Vc \in \R^{L_l×C} Vc∈RLl×C。这里, C C C、 L l L_l Ll和 L c Lc Lc 分别表示特征通道、LiDAR 体素的数量和相机体素的数量。然后,我们连接 LiDAR 体素 V l V_l Vl和相机体素 V c Vc Vc 以获得多模态体素 V m ∈ R ( L l + L c ) × C Vm ∈ \R^{ (L_l+L_c)×C} Vm∈R(Ll+Lc)×C 。值得注意的是,考虑到 3D 空间中的空间位置可能同时被 LiDAR 和相机体素占据,我们应用所提出的体素合并策略来合并重叠的多模态体素。最后,我们直接将合并的多模态体素 V m ′ ∈ R L m × C V ^′_m ∈ \R^{Lm×C} Vm′∈RLm×C 输入到 UniLION 3D 主干中,以进一步提取 3D 空间中的多模态特征,其中 Lm 表示合并的多模态体素的数量。
- 时间特征学习(Temporal Feature Learning):时间信息提取对于自动驾驶系统中准确的运动预测和轨迹规划至关重要。因此,UniLION 进一步的目标是借助线性 RNN 强大的远程建模能力,将时间信息合并到我们统一的 3D 主干中。具体来说,给定当前帧多模态体素 V T ∈ R L T × C V_T ∈ \R^{L_T ×C} VT∈RLT×C,我们从时间存储库中获取历史多模态体素 V T − 1 ∈ R L T − 1 × C V_{T −1} ∈ \R^{L_{T−1}×C} VT−1∈RLT−1×C (如果可用)。为了确保跨时间帧的空间一致性,我们使用数据集提供的转换矩阵执行空间对齐,将历史体素转换为当前帧的坐标系。随后,我们连接 V T − 1 V_{T -1} VT−1 和当前体素 V T V_T VT 以构造时间体素 V p ∈ R ( L T − 1 + L T ) × C V_p ∈ \R^{(L_{T−1}+L_T )×C} Vp∈R(LT−1+LT)×C。这里, L T − 1 L_{T -1} LT−1 和 L T L_T LT 分别表示T - 1 帧和T帧中的体素的数量。类似地,我们采用体素合并策略来合并时间体素,因为多个体素可能在时间帧中占据相同的 3D 位置。最后,我们直接将合并的体素提供给 UniLION 3D 主干以自适应地学习时间信息。
3.6 Dynamic Multi-task Loss
作为一个统一模型,UniLION 使用点云、多视图图像和历史信息来生成统一的 BEV 表示,用于自动驾驶的感知、预测和规划。基于紧凑的 BEV 功能,我们部署特定于任务的头来同时输出每个任务的结果。得益于模块化并行架构,UniLION 可以选择性地执行不同的任务,以减少推理过程中的计算开销。然而,对于多任务训练,我们需要考虑多个任务的平衡问题。为了尽可能保持每个任务的性能,我们采用动态损失平衡策略。具体来说,给定检测损失 L d e t \mathcal{L}_{det} Ldet、占用损失 L o c c \mathcal{L}_{occ} Locc、BEV图分割损失 L m a p \mathcal{L}_{map} Lmap、运动预测损失 L m o t \mathcal{L}_{mot} Lmot和规划损失 L p l a n \mathcal{L}_{plan} Lplan,我们计算动态损失权重,以将每个任务 L t a s k \mathcal{L}_{task} Ltask的损失与 L d e t \mathcal{L}_{det} Ldet对齐: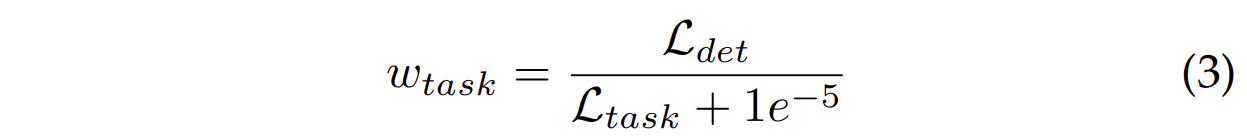
最终损失可以表示为: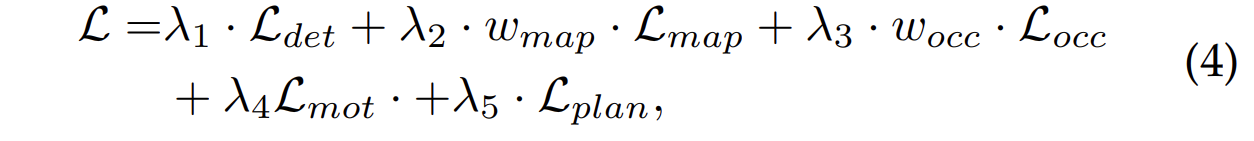
其中 λ 1 \mathcal{λ}_1 λ1、 λ 2 \mathcal{λ}_2 λ2、 λ 3 \mathcal{λ}_3 λ3、 λ 4 \mathcal{λ}_4 λ4 和 λ 5 \mathcal{λ}_5 λ5 是损失权重。
4 EXPERIMENTS
4.1 Dataset and Evaluation Metrics
数据集:我们在 nuScenes [76] 上进行了实验,nuScenes 是一种广泛认可的自动驾驶基准,其感知范围可达 50 米,并以 2 Hz 提供场景注释。该数据集包含 1,000 个场景,分为 750 个训练场景、150 个验证场景和 150 个测试场景。 nuScenes 提供全面的多模态数据,包括 LiDAR 生成的点云和来自 6 个周围摄像机的多视角图像。该数据集支持跨越感知、预测和规划领域的多种自动驾驶任务,包括 3D 对象检测、多对象跟踪、BEV 地图分割、3D 占用预测、运动预测和轨迹规划。
评估指标:我们遵循既定协议采用特定于任务的指标:用于 3D 对象检测的平均精度 (mAP) 和 NuScenes 检测分数 (NDS); AMOTA 用于跟踪绩效; BEV 地图分割的平均交集 (mIoU) [4];用于 3D 占用预测的 RayIoU [68];运动预测的最小平均位移误差(minADE)[66];和 L2 距离以及碰撞率用于规划评估[13]。
4.2 Implementation Details
网络详细信息:我们评估了 UniLION 的四种配置,以证明其多功能性:仅 LiDAR (L)、LiDAR 相机 (LC)、仅带时间融合的 LiDAR (LT) 和带时间融合的 LiDAR 相机 (LCT)。所有变体均采用能够同时处理多个任务的单一统一 3D 主干架构。我们将体素网格分辨率设置为 (0.3m, 0.3m, 0.25m) 并采用 N = 4 UniLION 块,窗口大小逐渐细化:(Sx, Sy, Sz) = (13, 13, 32),(13, 13, 16),(13, 13, 8),(13, 13, 4) 和相应的组大小 G = 4096, 2048、1024、512。在体素生成过程中,我们设置采样率r = 0.2,以实现精度和计算效率之间的最佳平衡。对于相机处理,我们采用两种主干配置:Swin-Tiny [77] 作为输入分辨率为 384 × 1056 的基础主干,ResNet-50 [78] 作为分辨率为 256 × 704 的轻量级主干。两个图像主干都在 nuImages [76] 上进行预训练。对于时间建模,我们采用流处理方式处理 4 个连续帧,将提取的特征按顺序输入到我们的 UniLION 主干中。
特定于任务的实施细节:我们使用既定的架构来实施每项任务,以确保公平评估。对于 3D 物体检测,我们采用 DSVT [61] 和 TransFusion [38] 的检测头。对于多目标跟踪,我们采用 CenterPoint [36] 的关联策略。对于 BEV 地图分割,我们利用 BEVFusion 地图头 [4]。对于 3D 占用预测,我们集成了 FlashOcc 头 [79]。对于运动预测,我们利用通过单个转换器解码器层处理的检测查询,该解码器层具有遵循 SparseDrive [67] 的六个轨迹锚点。类似地,对于轨迹规划,我们采用一个变压器解码器层来预测未来的自我车辆轨迹。为了确保所有任务的公平比较并防止信息泄漏,我们严格避免在训练和评估过程中默认使用任何自我状态信息[80]。
训练过程的细节:在训练阶段,我们采用标准的数据增强策略,包括水平翻转、旋转、平移、缩放和地面实况采样[36]、[88],以增强模型的鲁棒性并减轻过度拟合。对于训练 UniLION,我们采用多阶段训练策略和精心设计的数据增强策略。在单帧训练阶段,我们使用单帧 LiDAR 或 LiDARCamera 数据作为输入。首先,我们使用类平衡分组和采样(CBGS)[89]以及所有数据增强技术联合训练 12 个时期的检测和地图分割,以确保早期训练阶段的稳健特征学习。接下来,我们通过集成 24 个时期的检测、地图分割和占用预测任务来训练感知模型,仅进行旋转和翻转增强,因为地面真实占用注释对几何变换施加了约束。经过这些过程,我们可以获得 UniLION 的单帧感知模型(即仅 LiDAR 和 LiDAR-Camera 变体)。对于时间训练,我们加载相应的单帧预训练感知模型的权重,并以流式方式将多帧输入输入到我们的模型中,训练 24 个周期以产生时间感知模型。随后,我们加载并冻结预训练的时间感知模型权重,以训练 36 个时期的运动预测和规划任务,而无需任何数据增强,从而产生时间变体(即仅时间 LiDAR 模型和时间 LiDAR 相机模型)。 λ1、λ2、λ3、λ4和λ5分别设置为1、0.5、1、1和1。
推理过程的细节:在推理阶段,传统方法[4]、[10]需要为不同的输入模式或时态融合建立单独的模型,与之不同的是,我们的 UniLION 多帧多模态输入单一模型可无缝支持多种专用变体(即纯激光雷达模型、纯时态激光雷达模型、激光雷达-相机模型和时态激光雷达-相机模型),无需单独的模型架构或明确的时态/多模态融合模块。这种统一范式既能保持模型的优雅,又能在不同的模型设置中实现高性能。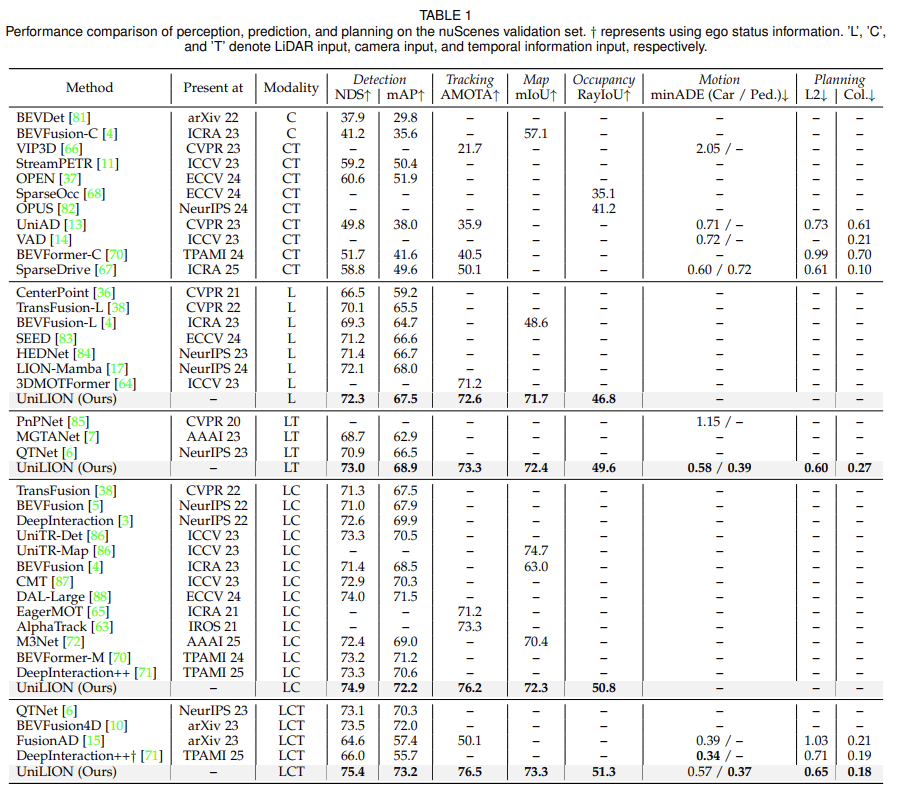
4.3 Comparisons with State-of-the-art Methods
总体结果:我们在六项自动驾驶任务中全面评估了 UniLION 的四种变体:3D 对象检测、跟踪、BEV 地图分割、3D 占用预测、运动预测和 nuScenes 数据集上的规划。请注意,我们仅在合并时间输入时评估运动预测和规划任务。如表 1 所示,UniLION 在单个统一模型中的所有任务中实现了领先的性能。对于仅 LiDAR 配置,UniLION 在 nuScenes 验证集上提供 72.3% NDS 和 67.5% mAP(用于 3D 对象检测)、72.6% AMOTA(用于跟踪)、71.7% mIoU(用于地图分割)和 46.8% RayIoU(用于占用预测)。当结合时间融合时,所有任务的性能都得到进一步增强:用于检测的 73.0% NDS 和 68.9% mAP,用于跟踪的 73.3% AMOTA,用于地图分割的 72.4% mIoU,用于占用预测的 49.6% RayIoU,用于车辆运动预测的 0.58 minADE,用于行人运动预测的 0.39 minADE,以及用于规划的碰撞率 0.27%。对于利用 LiDAR 和摄像头输入的多模态配置,UniLION 在四个核心感知任务上实现了卓越的性能:用于检测的 74.9% NDS 和 72.2% mAP、用于跟踪的 76.2% AMOTA、用于地图分割的 72.3% mIoU 以及用于占用预测的 50.8% RayIoU。时间多模态变体代表了我们最强大的配置,在所有评估的任务中实现了最先进或极具竞争力的性能:用于检测的 75.4% NDS 和 73.2% mAP、用于跟踪的 76.5% AMOTA、用于地图分割的 73.3% mIoU、用于占用预测的 51.3% RayIoU、用于车辆运动预测的 0.57 minADE、用于行人运动预测的 0.37 minADE 以及规划碰撞率极低,仅为 0.18%。请注意,我们在规划任务中不使用自我状态信息。
三维目标检测结果:表 2 列出了 UniLION 在 nuScenes 验证集上的详细 3D 物体检测结果。我们的 UniLION 在四种配置下均达到了 SOTA 性能: 这些结果验证了 UniLION 在三维物体检测方面的优越性。这些结果验证了 UniLION 作为三维物体检测统一框架的优越性,表明我们的方法可以在同时处理多个自动驾驶任务的同时,超越专门的单任务模型。
三维多目标跟踪结果:表 3 列出了 UniLION 在 nuScenes 验证集上的详细跟踪结果。在所有配置中,我们的方法都取得了具有竞争力的性能: 纯激光雷达方式的AMOTA为72.6%(比之前的SOTA方法3DMOTFormer[64]提高了1.4%),激光雷达-时间方式的AMOTA为73.3%,多模式方式的AMOTA为76.2%(比之前的SOTA方法AlphaTrack[63]提高了2.9%),时间多模式方式的AMOTA为76.5%,创造了新的SOTA结果。这些结果证明了 UniLION 在三维多目标跟踪方面的有效性。
BEV 地图分割结果:表 4 列出了 UniLION 在 nuScenes 验证集上的详细地图分割结果。在所有配置中,我们的方法都取得了具有竞争力的性能: 纯激光雷达的 mIoU 为 71.7%(与 DSVT [61] 相比提高了 3.7%),激光雷达-时态的 mIoU 为 72.4%,多模态的 mIoU 为 72.3%(与之前的 SOTA 多任务方法 M3Net [72] 相比提高了 1.9%),时态多模态的 mIoU 为 73.3%。这些结果证明了 UniLION 作为地图分割统一框架的有效性。
占用预测结果:表 5 显示了 UniLION 在 Occ3DnuScenes [100] 验证集上的占用预测性能。我们的方法在不同的设置下提供了强大的结果:仅 LiDAR 的 RayIoU 为 46.7%,LiDAR 时间的 RayIoU 为 49.6% RayIoU,多模态输入的 RayIoU 为 50.8%,时间多模态输入的 RayIoU 为 51.3%,设定了新的最先进基准。值得注意的是,UniLION 大大优于现有的 SOTA 方法,分别超过 SparseOcc [68] 和 OPUS [82] 15.2% 和 10.1% RayIoU。这些发现验证了 UniLION 占用率预测的有效性。运动预测结果。表 6 评估了 UniLION 在 nuScenes 验证集上的运动预测能力。与许多先前仅关注车辆运动的研究不同,我们将评估范围扩展到包括行人轨迹。对于仅使用 LiDAR 的配置,UniLION 为汽车实现了 0.58 minADE,为行人实现了 0.39 minADE。在多模式设置中,我们的模型为汽车实现了 0.57 minADE,为行人实现了 0.37 minADE。这些结果凸显了 UniLION 作为跨不同对象类别的运动预测集成方法的推广。
规划结果:对于规划任务,我们在 nuScenes 验证集上评估 UniLION,如表 7 所示。请注意,合并自我状态信息会导致信息泄漏 [80]。因此,UniLION 故意排除自我状态信息以缓解此问题。在LiDAR配置下,UniLION实现了0.70m的L2误差和0.27%的碰撞率。通过多模态输入,UniLION 进一步将性能提升至 0.65m L2 误差和 0.18% 碰撞率。由于 UniLION 增强的表征能力,我们的方法大大优于 BEVFormer-M,大大降低了碰撞率(从 0.68% 到 0.18%)。这些结果证实了 UniLION 规划的有效性和优越性。
One Model for All: UniLION 是一个统一的架构,通过单一模型框架支持多种模式和任务。这种设计本质上支持跨异构输入格式的参数共享。为了验证这种能力,我们在推理过程中进行了系统研究,通过有选择地禁用在多模态时间数据上训练的 UniLION 模型中的特定模态或时间输入(g 行),如表 8 所示。当单独禁用时间信息时(f 行),我们的模型保持与具有一致的训练测试输入的标准配置相当的性能(e 行)。值得注意的是,即使时间和相机输入都被禁用(b 线),我们的模型也能达到 70.6 NDS 的竞争性能,超过 TransFusion-L (70.1 NDS) 和 BEVFusion-L (69.3 NDS)。这些发现表明,单一 UniLION 模型一旦接受了多模态时态数据的训练,就可以在不同的传感器配置和时态设置(例如仅 LiDAR、时态 LiDAR 或多模态融合)中无缝部署,而无需重新训练。此功能展示了对不同操作条件的卓越适应性,同时显着增强了我们统一框架的稳健性和多功能性。
Different Image Backbones:在表9中,我们提供了一个轻量级版本UniLION,它在256×704的较小图像分辨率下采用ResNet-50[78]作为图像主干。与基础模型(Swin-tiny [77]作为图像主干,384×1056)相比,轻量级版本仍然获得了令人鼓舞的性能,NDS为73.6%,3D检测为70.8% mAP,多目标跟踪为75.0% AMOTA,地图分割为71.8% mIoU,3D占用为50.2% RayIoU。
Different Linear RNN Operators:为了验证我们框架的灵活性,我们评估了另一个代表性的线性 RNN 算子 RWKV [20],如表 9 所示。虽然 UniLION-RWKV 与 UniLION-Mamba 相比性能稍差,但它在多个自动驾驶任务中仍然取得了优异的结果,有效地证明了我们框架的灵活性。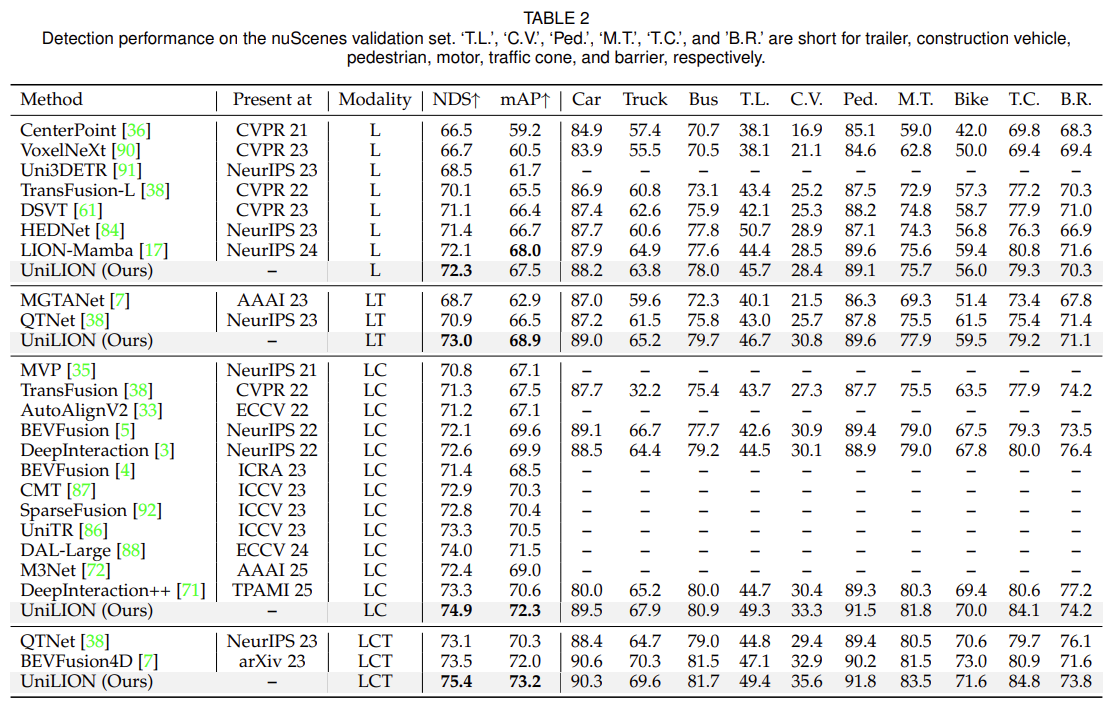
4.4 Ablation Studies
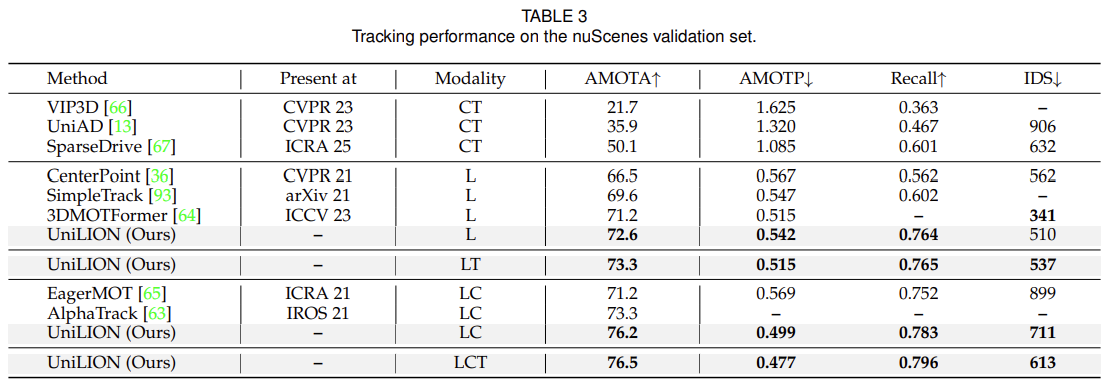
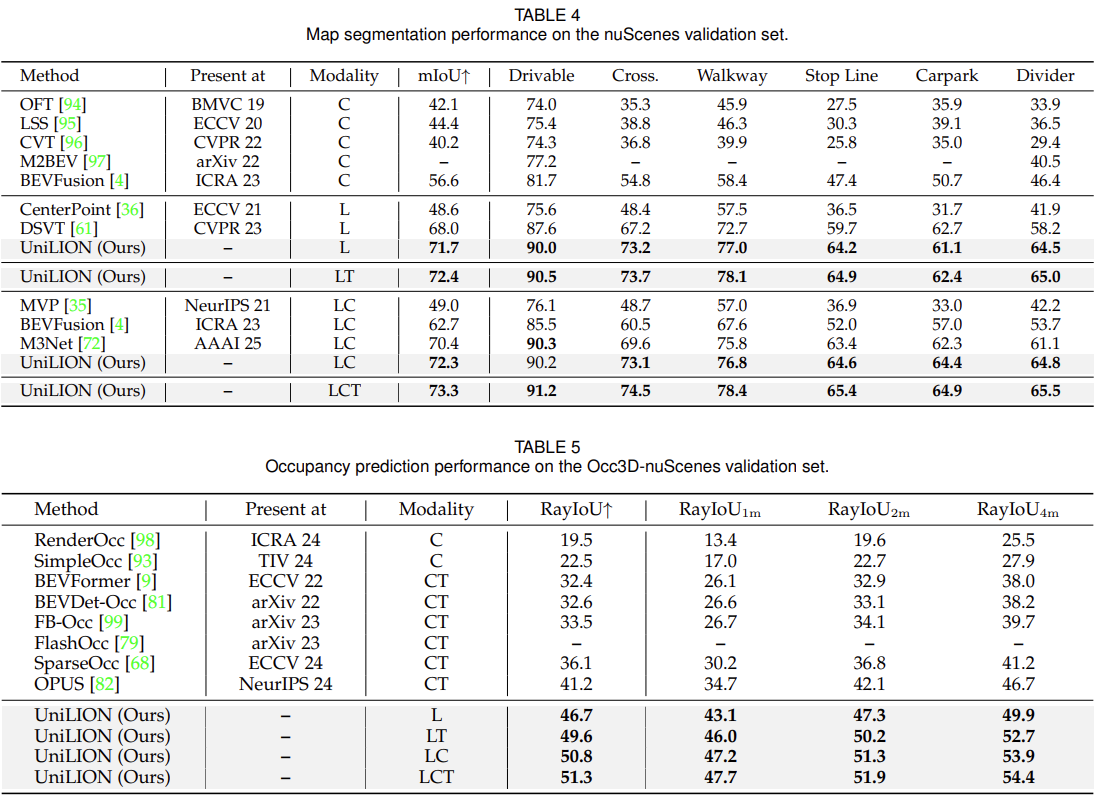
为了说明 UniLION 的有效性,我们在 nuScenes 验证集上对 UniLION 进行了消融研究。为了快速验证,我们采用具有 ResNet50 图像主干和 256×704 分辨率的单帧多模态 UniLION 作为默认模型,并评估其在 3D 感知任务(例如 3D 对象检测、跟踪、地图分割和占用)上的性能。
UniLION 的每个组件:我们验证了 UniLION 的各个组件,包括空间特征描述符和体素生成模块,如表 10 所示。将 3D 空间特征描述符集成到基线(a 行)时,此设置(b 行)有望带来 0.7% NDS、0.8% mAP、1.9% AMOTA、0.5% mIoU 和 1.1% RayIoU 的性能改进。这证明了我们提出的 3D 空间特征描述符在补偿线性 RNN 有限的空间建模能力方面的有效性。此外,体素生成模块(c 行)通过增强前景体素特征表示,使性能比基线提高了 0.6% NDS、1.1% mAP、2.7% AMOTA、0.1% mIoU 和 0.3% RayIoU。最后,当所有组件组合在一起时(第 d 行),UniLION 实现了 73.6% NDS、70.8% mAP、75.0% AMOTA、71.8% mIoU 和 50.2% RayIoU,超出基线 0.7% NDS、1.8% mAP、3.1% AMOTA、1.6% mIoU 和 1.8%瑞欧。
动态损失的有效性:在表 11 中,我们提出了验证动态损失机制有效性的实验。采用动态损失可以在大多数任务中产生一致的改进:用于检测的 0.3% NDS、用于跟踪的 0.9% AMOTA 以及用于地图分割的 0.6% mIoU。然而,我们观察到 3D 占用性能略有下降。我们将此归因于动态损失,鼓励 UniLION 优先考虑整体任务平衡,这可能会以牺牲单个任务优化为代价,特别是对于占用预测任务。
多任务学习:在表 12 中,我们研究了联合训练对不同任务表现的影响。当联合训练 3D 检测和地图分割时,我们观察到地图分割任务的性能显着提高(71.7% mIoU vs. 68.3% mIoU)。当进一步纳入占用预测任务时,我们的模型在检测方面经历了轻微的性能下降,但在占用预测方面实现了 2.7% RayIoU 的大幅改进,因为检测任务总体上可以增强 3D 占用估计。总体而言,与单任务模型相比,我们的联合训练方法实现了相当甚至更好的性能,证明了 UniLION 3D 主干提取的紧凑 BEV 特征表示的有效性。
窗口大小和组大小的稳健性: UniLION 的基本优势在于其通过集成线性 RNN 进行远程依赖建模的能力。为了评估我们方法的泛化性和参数敏感性,我们在推理过程中对不同的窗口大小和组大小进行了全面的稳健性分析,如表 13 所示。具体来说,我们评估了 UniLION(窗口大小为 {[13, 13, 32]、[13, 13, 16]、[13, 13, 8] 和 [13, 13, 4]} 和组大小为 {4096, 2048, 1024, 512}) 跨越不同的窗口大小和组大小。我们的实证研究结果表明:UniLION 在各种下游任务的不同窗口和组大小配置中表现出卓越的稳定性和一致的性能。这表明 UniLION 具有良好的外推能力,而无需强烈依赖手工设计的先验。
传感器未对准的鲁棒性:大多数自动驾驶系统中都可能出现传感器错位问题。因此,探索传感器失准的鲁棒性对于确保自动驾驶系统的安全至关重要。为了验证 UniLION 的稳健性,我们按照 FBMNet [103] 来模拟 LiDAR 和相机模式之间的传感器失准。具体来说,‘低’、‘中’和‘高’的失准水平分别表示相机外在矩阵沿垂直方向旋转1.5°、3.0°和5.0°,并分别平移0.15m、0.30m和0.50m。在低错位水平下,与对齐模型相比,UniLION 在不同任务中保持了可比较的性能。此外,我们的 UniLION 在适度退化的情况下实现了良好的性能(0.8% NDS、1.3% mAP、1.0% AMOTA、0.3% mIoU 和 1.4% RayIoU),并且即使在高水平错位下也表现出很强的鲁棒性。值得注意的是,尽管相机与 LiDAR 未对准,但多模态 UniLION 的性能始终优于仅使用 LiDAR 的同类产品。这些实验最终证明了 UniLION 对传感器错位挑战的鲁棒性。
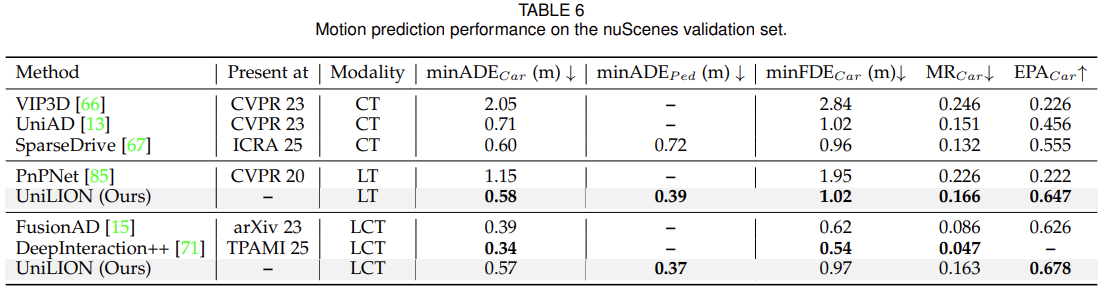
UniLION Backbone 中的 Top-K:在表 15 中,我们研究了 UniLION 3D 主干中 top-K 候选深度对生成相机体素的影响。总体而言,实验结果表明,随着 K 的增加,3D 对象检测的性能得到了一致的提高,这表明加入额外的深度候选可以增强模型的表示能力。然而,为了在计算效率和模型性能之间保持良好的权衡,我们根据经验确定 K = 4 作为我们框架的默认设置。
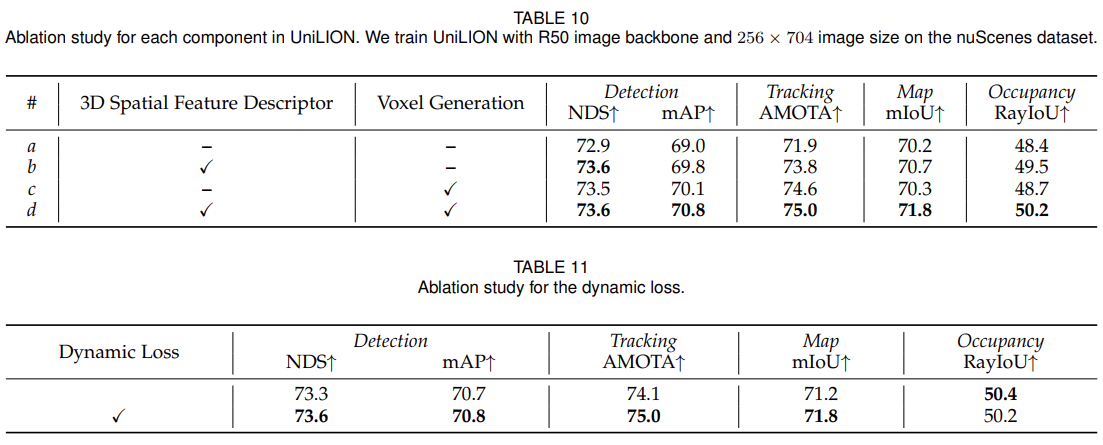
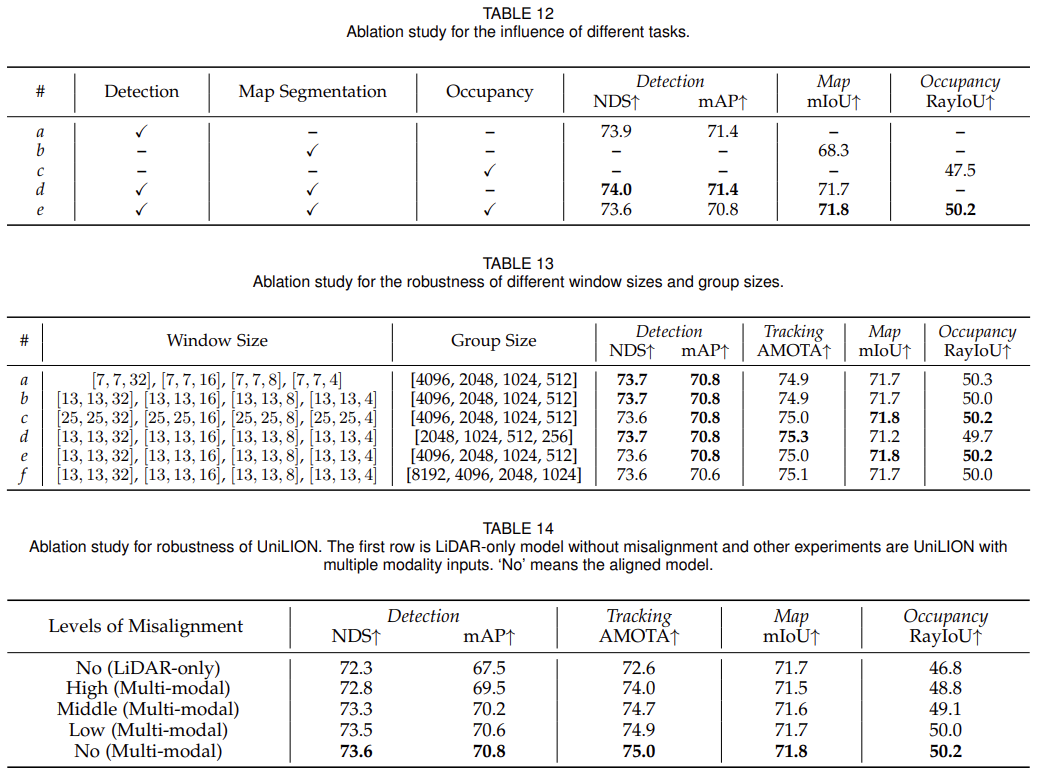
4.5 Analysis of Visualization
在本节中,我们将介绍 UniLION 在多个自动驾驶任务中的全面定性分析,包括 3D 对象检测、跟踪、地图分割、占用预测、运动预测以及 nuScenes 验证集上的规划。
1)3D对象检测:如图6(a)和(b)所示,我们分别展示了多视图图像和BEV的预测结果。得益于 UniLION 的全面特征表示,UniLION 可以成功检测难以检测的物体(例如 CAM FRONT 视图图像上的远处物体)。
2)3D对象跟踪:如图6所示,我们使用唯一的ID来区分不同的对象来可视化跟踪结果。 UniLION可以准确地关联图6(b)、图6©中的跨帧对象。
3)占用率预测:如图6(d)所示,我们将预测的占用率可视化。基于统一的BEV特性,UniLION可以实现准确的3D占用结果。
4)地图分割:如图6(e)所示。 UniLION可以准确分割地图元素(例如车道线、可行驶区域)并提供丰富的地图信息。
5)运动和规划:如图6(b)所示,我们可视化运动预测和规划的预测。对于运动预测,UniLION 可以准确地区分运动和静态物体。对于规划,UniLION 可以生成合理的轨迹以避免碰撞。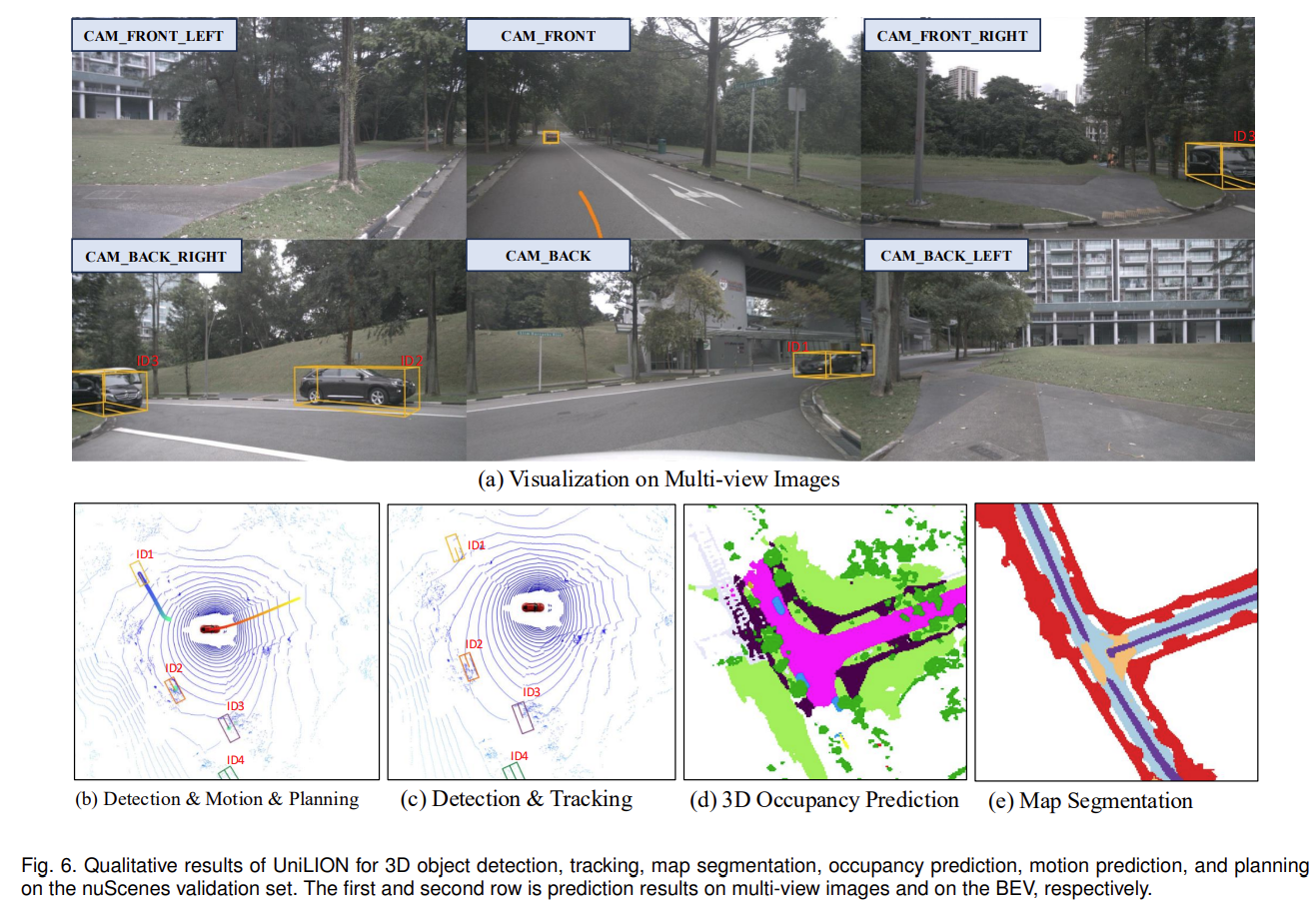
图 6.UniLION 在 nuScenes 验证集上用于 3D 对象检测、跟踪、地图分割、占用预测、运动预测和规划的定性结果。第一行和第二行分别是多视图图像和 BEV 上的预测结果。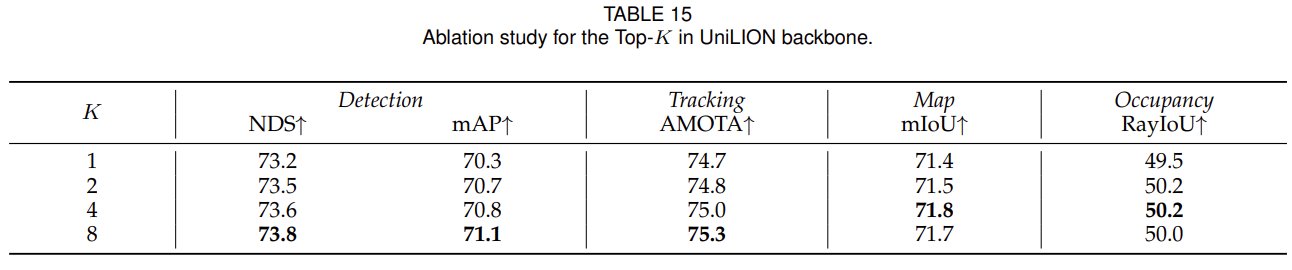
5 CONCLUSION
在本文中,我们提出了一种基于线性 RNN 的框架 UniLION,它是一个统一的 3D 主干,可以无缝处理不同的模态和时间信息,而无需任何显式的融合模块。受益于这种优雅而简单的结构,这种统一的 3D 主干可以将不同的信息压缩为紧凑且统一的 BEV 表示形式,作为共享功能,通过并行多任务学习无缝解决不同的自动驾驶任务。大量的实验验证了我们的 UniLION 在特征表示方面的优越性。最后,UniLION 在全面的自动驾驶任务中实现了具有竞争力甚至最先进的性能,包括 3D 感知(3D 对象检测、跟踪、占用预测、BEV 地图分割)、运动预测和规划,展示了我们统一方法 UniLION 的通用性和有效性。
REFERENCES
[1] T. Huang, Z. Liu, X. Chen, and X. Bai, “Epnet: Enhancing point
features with image semantics for 3d object detection,” in ECCV,
2020.
[2] Z. Liu, T. Huang, B. Li, X. Chen, X. Wang, and X. Bai, “Epnet++:
Cascade bi-directional fusion for multi-modal 3d object detection,” 2022.
[3] Z. Yang, J. Chen, Z. Miao, W. Li, X. Zhu, and L. Zhang, “Deepinteraction: 3d object detection via modality interaction,” in
NeurIPS, 2022.
15
[4] Z. Liu, H. Tang, A. Amini, X. Yang, H. Mao, D. Rus, and S. Han,
“Bevfusion: Multi-task multi-sensor fusion with unified bird’seye view representation,” in ICRA, 2023.
[5] T. Liang, H. Xie, K. Yu, Z. Xia, Z. Lin, Y. Wang, T. Tang, B. Wang,
and Z. Tang, “Bevfusion: A simple and robust lidar-camera
fusion framework,” in NeurIPS, 2022.
[6] J. Hou, Z. Liu, Z. Zou, X. Ye, X. Bai et al., “Query-based temporal
fusion with explicit motion for 3d object detection,” in NeurIPS,
2023.
[7] J. Koh, J. Lee, Y. Lee, J. Kim, and J. W. Choi, “Mgtanet: Encoding
sequential lidar points using long short-term motion-guided
temporal attention for 3d object detection,” in AAAI, 2023.
[8] X. Chen, S. Shi, B. Zhu, K. C. Cheung, H. Xu, and H. Li,
“Mppnet: Multi-frame feature intertwining with proxy points for
3d temporal object detection,” in ECCV, 2022.
[9] Z. Li, W. Wang, H. Li, E. Xie, C. Sima, T. Lu, Y. Qiao, and J. Dai,
“Bevformer: Learning bird’s-eye-view representation from multicamera images via spatiotemporal transformers,” in ECCV, 2022.
[10] H. Cai, Z. Zhang, Z. Zhou, Z. Li, W. Ding, and J. Zhao, “Bevfusion4d: Learning lidar-camera fusion under bird’s-eye-view
via cross-modality guidance and temporal aggregation,” arXiv
preprint arXiv:2303.17099, 2023.
[11] S. Wang, Y. Liu, T. Wang, Y. Li, and X. Zhang, “Exploring objectcentric temporal modeling for efficient multi-view 3d object
detection,” in ICCV, 2023.
[12] C. Han, J. Yang, J. Sun, Z. Ge, R. Dong, H. Zhou, W. Mao, Y. Peng,
and X. Zhang, “Exploring recurrent long-term temporal fusion
for multi-view 3d perception,” IEEE Robotics and Automation
Letters, 2024.
[13] Y. Hu, J. Yang, L. Chen, K. Li, C. Sima, X. Zhu, S. Chai, S. Du,
T. Lin, W. Wang et al., “Planning-oriented autonomous driving,”
in CVPR, 2023.
[14] B. Jiang, S. Chen, Q. Xu, B. Liao, J. Chen, H. Zhou, Q. Zhang,
W. Liu, C. Huang, and X. Wang, “Vad: Vectorized scene representation for efficient autonomous driving,” in ICCV, 2023.
[15] T. Ye, W. Jing, C. Hu, S. Huang, L. Gao, F. Li, J. Wang, K. Guo,
W. Xiao, W. Mao et al., “Fusionad: Multi-modality fusion for
prediction and planning tasks of autonomous driving,” arXiv
preprint arXiv:2308.01006, 2023.
[16] X. Weng, B. Ivanovic, Y. Wang, Y. Wang, and M. Pavone, “Paradrive: Parallelized architecture for real-time autonomous driving,” in CVPR, 2024.
[17] Z. Liu, J. Hou, X. Wang, X. Ye, J. Wang, H. Zhao, and X. Bai,
“Lion: Linear group rnn for 3d object detection in point clouds,”
NeurIPS, 2024.
[18] Z. Qin, S. Yang, and Y. Zhong, “Hierarchically gated recurrent
neural network for sequence modeling,” in NeurIPS, 2023.
[19] A. Orvieto, S. L. Smith, A. Gu, A. Fernando, C. Gulcehre, R. Pascanu, and S. De, “Resurrecting recurrent neural networks for long
sequences,” in ICML, 2023.
[20] B. Peng, E. Alcaide, Q. G. Anthony, A. Albalak, S. Arcadinho,
S. Biderman, H. Cao, X. Cheng, M. N. Chung, L. Derczynski et al.,
“Rwkv: Reinventing rnns for the transformer era,” in EMNLP,
2023.
[21] B. Peng, D. Goldstein, Q. Anthony, A. Albalak, E. Alcaide, S. Biderman, E. Cheah, X. Du, T. Ferdinan, H. Hou, P. Kazienko, K. K.
GV, J. Kocon, B. Koptyra, S. Krishna, R. M. J. au2, N. Muen- ´
nighoff, F. Obeid, A. Saito, G. Song, H. Tu, S. Wozniak, R. Zhang, ´
B. Zhao, Q. Zhao, P. Zhou, J. Zhu, and R.-J. Zhu, “Eagle and
finch: Rwkv with matrix-valued states and dynamic recurrence,”
arXiv:2404.05892, 2024.
[22] Y. Sun, L. Dong, S. Huang, S. Ma, Y. Xia, J. Xue, J. Wang, and
F. Wei, “Retentive network: A successor to transformer for large
language models,” arXiv:2307.08621, 2023.
[23] S. De, S. L. Smith, A. Fernando, A. Botev, G. Cristian-Muraru,
A. Gu, R. Haroun, L. Berrada, Y. Chen, S. Srinivasan, G. Desjardins, A. Doucet, D. Budden, Y. W. Teh, R. Pascanu, N. D.
Freitas, and C. Gulcehre, “Griffin: Mixing gated linear recurrences with local attention for efficient language models,”
arXiv:2402.19427, 2024.
[24] S. Yang, B. Wang, Y. Shen, R. Panda, and Y. Kim, “Gated
linear attention transformers with hardware-efficient training,”
arXiv:2312.06635, 2023.
[25] A. Gu and T. Dao, “Mamba: Linear-time sequence modeling with
selective state spaces,” arXiv:2312.00752, 2023.
[26] Y. Sun, X. Li, K. Dalal, J. Xu, A. Vikram, G. Zhang, Y. Dubois,
X. Chen, X. Wang, S. Koyejo et al., “Learning to (learn at test time):
Rnns with expressive hidden states,” arXiv:2407.04620, 2024.
[27] M. Beck, K. Poppel, M. Spanring, A. Auer, O. Prudnikova, ¨
M. Kopp, G. Klambauer, J. Brandstetter, and S. Hochreiter, “xlstm:
Extended long short-term memory,” arXiv:2405.04517, 2024.
[28] B. Alkin, M. Beck, K. Poppel, S. Hochreiter, and J. Brand- ¨
stetter, “Vision-lstm: xlstm as generic vision backbone,”
arXiv:2406.04303, 2024.
[29] Y. Duan, W. Wang, Z. Chen, X. Zhu, L. Lu, T. Lu, Y. Qiao, H. Li,
J. Dai, and W. Wang, “Vision-rwkv: Efficient and scalable visual
perception with rwkv-like architectures,” arXiv:2403.02308, 2024.
[30] D. Liang, X. Zhou, X. Wang, X. Zhu, W. Xu, Z. Zou, X. Ye, and
X. Bai, “Pointmamba: A simple state space model for point cloud
analysis,” arXiv:2402.10739, 2024.
[31] G. Zhang, L. Fan, C. He, Z. Lei, Z. Zhang, and L. Zhang, “Voxel
mamba: Group-free state space models for point cloud based 3d
object detection,” arXiv preprint arXiv:2406.10700, 2024.
[32] Y. Jiao, Z. Jie, S. Chen, J. Chen, X. Wei, L. Ma, and Y.-G. Jiang,
“Msmdfusion: Fusing lidar and camera at multiple scales with
multi-depth seeds for 3d object detection,” in CVPR, 2023.
[33] Z. Chen, Z. Li, S. Zhang, L. Fang, Q. Jiang, and F. Zhao, “Autoalignv2: Deformable feature aggregation for dynamic multimodal 3d object detection,” in ECCV, 2022.
[34] Y. Chen, Z. Yu, Y. Chen, S. Lan, A. Anandkumar, J. Jia, and J. M.
Alvarez, “Focalformer3d: Focusing on hard instance for 3d object
detection,” in ICCV, 2023.
[35] T. Yin, X. Zhou, and P. Krahenb ¨ uhl, “Multimodal virtual point 3d ¨
detection,” in NeurIPS, 2021.
[36] T. Yin, X. Zhou, and P. Krahenbuhl, “Center-based 3d object
detection and tracking,” in CVPR, 2021.
[37] J. Hou, T. Wang, X. Ye, Z. Liu, S. Gong, X. Tan, E. Ding, J. Wang,
and X. Bai, “Open: Object-wise position embedding for multiview 3d object detection,” in ECCV, 2024.
[38] X. Bai, Z. Hu, X. Zhu, Q. Huang, Y. Chen, H. Fu, and C.-L. Tai,
“Transfusion: Robust lidar-camera fusion for 3d object detection
with transformers,” in CVPR, 2022.
[39] S. Shi, X. Wang, and H. Li, “Pointrcnn: 3d object proposal generation and detection from point cloud,” in CVPR, 2019.
[40] Z. Yang, Y. Sun, S. Liu, X. Shen, and J. Jia, “Std: Sparse-to-dense
3d object detector for point cloud,” in CVPR, 2019.
[41] C. R. Qi, W. Liu, C. Wu, H. Su, and L. J. Guibas, “Frustum
pointnets for 3d object detection from rgb-d data,” in CVPR, 2018.
[42] C. R. Qi, O. Litany, K. He, and L. J. Guibas, “Deep hough voting
for 3d object detection in point clouds,” in ICCV, 2019.
[43] Y. Zhang, Q. Hu, G. Xu, Y. Ma, J. Wan, and Y. Guo, “Not all points
are equal: Learning highly efficient point-based detectors for 3d
lidar point clouds,” in CVPR, 2022.
[44] C. Chen, Z. Chen, J. Zhang, and D. Tao, “Sasa: Semanticsaugmented set abstraction for point-based 3d object detection,”
in AAAI, 2022.
[45] Z. Yang, Y. Sun, S. Liu, and J. Jia, “3dssd: Point-based 3d single
stage object detector,” in CVPR, 2020.
[46] C. R. Qi, H. Su, K. Mo, and L. J. Guibas, “Pointnet: Deep learning
on point sets for 3d classification and segmentation,” in CVPR,
2017.
[47] C. R. Qi, L. Yi, H. Su, and L. J. Guibas, “Pointnet++: Deep
hierarchical feature learning on point sets in a metric space,” in
NeurIPS, 2017.
[48] Y. Yan, Y. Mao, and B. Li, “Second: Sparsely embedded convolutional detection,” Sensors, 2018.
[49] S. Shi, Z. Wang, J. Shi, X. Wang, and H. Li, “From points to parts:
3d object detection from point cloud with part-aware and partaggregation network,” IEEE TPAMI, 2020.
[50] S. Dong, L. Ding, H. Wang, T. Xu, X. Xu, J. Wang, Z. Bian, Y. Wang,
and J. Li, “Mssvt: Mixed-scale sparse voxel transformer for 3d
object detection on point clouds,” in NeurIPS, 2022.
[51] Z. Liu, X. Zhao, T. Huang, R. Hu, Y. Zhou, and X. Bai, “Tanet: Robust 3d object detection from point clouds with triple attention,”
in AAAI, 2020.
[52] J. Deng, S. Shi, P. Li, W. Zhou, Y. Zhang, and H. Li, “Voxel r-cnn:
Towards high performance voxel-based 3d object detection,” in
AAAI, 2021.
[53] T. Guan, J. Wang, S. Lan, R. Chandra, Z. Wu, L. Davis, and
D. Manocha, “M3detr: Multi-representation, multi-scale, mutualrelation 3d object detection with transformers,” in WACV, 2022.
16
[54] S. Shi, C. Guo, L. Jiang, Z. Wang, J. Shi, X. Wang, and H. Li, “Pvrcnn: Point-voxel feature set abstraction for 3d object detection,”
in CVPR, 2020.
[55] S. Shi, L. Jiang, J. Deng, Z. Wang, C. Guo, J. Shi, X. Wang, and
H. Li, “Pv-rcnn++: Point-voxel feature set abstraction with local
vector representation for 3d object detection,” IJCV, 2021.
[56] H. Yang, W. Wang, M. Chen, B. Lin, T. He, H. Chen, X. He, and
W. Ouyang, “Pvt-ssd: Single-stage 3d object detector with pointvoxel transformer,” in CVPR, 2023.
[57] G. Zhang, J. Chen, G. Gao, J. Li, S. Liu, and X. Hu, “Safdnet: A
simple and effective network for fully sparse 3d object detection,”
in CVPR, 2024.
[58] L. Fan, Z. Pang, T. Zhang, Y.-X. Wang, H. Zhao, F. Wang, N. Wang,
and Z. Zhang, “Embracing single stride 3d object detector with
sparse transformer,” in CVPR, 2022.
[59] P. Sun, M. Tan, W. Wang, C. Liu, F. Xia, Z. Leng, and D. Anguelov,
“Swformer: Sparse window transformer for 3d object detection in
point clouds,” in ECCV, 2022.
[60] Z. Liu, X. Yang, H. Tang, S. Yang, and S. Han, “Flatformer: Flattened window attention for efficient point cloud transformer,” in
CVPR, 2023.
[61] H. Wang, C. Shi, S. Shi, M. Lei, S. Wang, D. He, B. Schiele, and
L. Wang, “Dsvt: Dynamic sparse voxel transformer with rotated
sets,” in CVPR, 2023.
[62] H. Wang, L. Ding, S. Dong, S. Shi, A. Li, J. Li, Z. Li, and L. Wang,
“Cagroup3d: Class-aware grouping for 3d object detection on
point clouds,” in NeurIPS, 2022.
[63] Y. Zeng, C. Ma, M. Zhu, Z. Fan, and X. Yang, “Cross-modal 3d
object detection and tracking for auto-driving,” in NeurIPS, 2021.
[64] S. Ding, E. Rehder, L. Schneider, M. Cordts, and J. Gall, “3dmotformer: Graph transformer for online 3d multi-object tracking,”
in CVPR, 2023.
[65] A. Kim, A. Osep, and L. Leal-Taix ˇ e, “Eagermot: 3d multi-object ´
tracking via sensor fusion,” in ICRA, 2021.
[66] J. Gu, C. Hu, T. Zhang, X. Chen, Y. Wang, Y. Wang, and H. Zhao,
“Vip3d: End-to-end visual trajectory prediction via 3d agent
queries,” in CVPR, 2023.
[67] W. Sun, X. Lin, Y. Shi, C. Zhang, H. Wu, and S. Zheng,
“Sparsedrive: End-to-end autonomous driving via sparse scene
representation,” in ICRA, 2025.
[68] H. Liu, Y. Chen, H. Wang, Z. Yang, T. Li, J. Zeng, L. Chen, H. Li,
and L. Wang, “Fully sparse 3d occupancy prediction,” in ECCV,
2024.
[69] Y. Wang, Y. Chen, X. Liao, L. Fan, and Z. Zhang, “Panoocc:
Unified occupancy representation for camera-based 3d panoptic
segmentation,” in CVPR, 2024.
[70] Z. Li, W. Wang, H. Li, E. Xie, C. Sima, T. Lu, Q. Yu, and J. Dai,
“Bevformer: learning bird’s-eye-view representation from lidarcamera via spatiotemporal transformers,” IEEE TPAMI, 2024.
[71] Z. Yang, N. Song, W. Li, X. Zhu, L. Zhang, and P. H. Torr,
“Deepinteraction++: Multi-modality interaction for autonomous
driving,” IEEE TPAMI, 2025.
[72] X. Chen, S. Shi, T. Ma, J. Zhou, S. See, K. C. Cheung, and H. Li,
“M3net: Multimodal multi-task learning for 3d detection, segmentation, and occupancy prediction in autonomous driving,”
in AAAI, 2025.
[73] L. Fan, Z. Pang, T. Zhang, Y.-X. Wang, H. Zhao, F. Wang, N. Wang,
and Z. Zhang, “Embracing single stride 3d object detector with
sparse transformer,” in CVPR, 2022.
[74] Y. Liu, Y. Tian, Y. Zhao, H. Yu, L. Xie, Y. Wang, Q. Ye, and Y. Liu,
“Vmamba: Visual state space model,” arXiv:2401.10166, 2024.
[75] L. Zhu, B. Liao, Q. Zhang, X. Wang, W. Liu, and X. Wang,
“Vision mamba: Efficient visual representation learning with
bidirectional state space model,” in ICML, 2024.
[76] H. Caesar, V. Bankiti, A. H. Lang, S. Vora, V. E. Liong, Q. Xu,
A. Krishnan, Y. Pan, G. Baldan, and O. Beijbom, “nuscenes: A
multimodal dataset for autonomous driving,” in CVPR, 2020.
[77] Z. Liu, Y. Lin, Y. Cao, H. Hu, Y. Wei, Z. Zhang, S. Lin, and B. Guo,
“Swin transformer: Hierarchical vision transformer using shifted
windows,” in ICCV, 2021.
[78] K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for
image recognition,” in CVPR, 2016.
[79] Z. Yu, C. Shu, J. Deng, K. Lu, Z. Liu, J. Yu, D. Yang,
H. Li, and Y. Chen, “Flashocc: Fast and memory-efficient occupancy prediction via channel-to-height plugin,” arXiv preprint
arXiv:2311.12058, 2023.
[80] Z. Li, Z. Yu, S. Lan, J. Li, J. Kautz, T. Lu, and J. M. Alvarez, “Is
ego status all you need for open-loop end-to-end autonomous
driving?” in CVPR, 2024.
[81] J. Huang, G. Huang, Z. Zhu, Y. Ye, and D. Du, “Bevdet: Highperformance multi-camera 3d object detection in bird-eye-view,”
2021.
[82] J. Wang, Z. Liu, Q. Meng, L. Yan, K. Wang, J. Yang, W. Liu,
Q. Hou, and M.-M. Cheng, “Opus: occupancy prediction using
a sparse set,” in NeurIPS, 2024.
[83] Z. Liu, J. Hou, X. Ye, T. Wang, J. Wang, and X. Bai, “Seed: A
simple and effective 3d detr in point clouds,” in ECCV, 2024.
[84] G. Zhang, C. Junnan, G. Gao, J. Li, and X. Hu, “HEDNet: A
hierarchical encoder-decoder network for 3d object detection in
point clouds,” in NeurIPS, 2023.
[85] M. Liang, B. Yang, W. Zeng, Y. Chen, R. Hu, S. Casas, and
R. Urtasun, “Pnpnet: End-to-end perception and prediction with
tracking in the loop,” in CVPR, 2020.
[86] H. Wang, H. Tang, S. Shi, A. Li, Z. Li, B. Schiele, and L. Wang,
“Unitr: A unified and efficient multi-modal transformer for
bird’s-eye-view representation,” in ICCV, 2023.
[87] J. Yan, Y. Liu, J. Sun, F. Jia, S. Li, T. Wang, and X. Zhang, “Cross
modal transformer: Towards fast and robust 3d object detection,”
in CVPR, 2023.
[88] J. Huang, Y. Ye, Z. Liang, Y. Shan, and D. Du, “Detecting as
labeling: Rethinking lidar-camera fusion in 3d object detection,”
in ECCV, 2024.
[89] B. Zhu, Z. Jiang, X. Zhou, Z. Li, and G. Yu, “Class-balanced
grouping and sampling for point cloud 3d object detection,”
arXiv:1908.09492, 2019.
[90] Y. Chen, J. Liu, X. Zhang, X. Qi, and J. Jia, “Voxelnext: Fully sparse
voxelnet for 3d object detection and tracking,” in CVPR, 2023.
[91] Z. Wang, Y.-L. Li, X. Chen, H. Zhao, and S. Wang, “Uni3detr:
Unified 3d detection transformer,” in NeurIPS, 2024.
[92] Y. Xie, C. Xu, M.-J. Rakotosaona, P. Rim, F. Tombari, K. Keutzer,
M. Tomizuka, and W. Zhan, “Sparsefusion: Fusing multi-modal
sparse representations for multi-sensor 3d object detection,” in
ICCV, 2023.
[93] W. Gan, N. Mo, H. Xu, and N. Yokoya, “A simple attempt for
3d occupancy estimation in autonomous driving,” arXiv preprint
arXiv:2303.10076, 2023.
[94] T. Roddick, A. Kendall, and R. Cipolla, “Orthographic feature
transform for monocular 3d object detection,” in BMVC, 2019.
[95] J. Philion and S. Fidler, “Lift, splat, shoot: Encoding images from
arbitrary camera rigs by implicitly unprojecting to 3d,” in ECCV,
2020.
[96] B. Zhou and P. Krahenb ¨ uhl, “Cross-view transformers for real- ¨
time map-view semantic segmentation,” in CVPR, 2022.
[97] E. Xie, Z. Yu, D. Zhou, J. Philion, A. Anandkumar, S. Fidler,
P. Luo, and J. Alvarez, “M2bev: Multi-camera joint 3d detection
and segmentation with unified birds-eye view representation.
arxiv 2022,” arXiv preprint arXiv:2204.05088, 2022.
[98] M. Pan, J. Liu, R. Zhang, P. Huang, X. Li, H. Xie, B. Wang,
L. Liu, and S. Zhang, “Renderocc: Vision-centric 3d occupancy
prediction with 2d rendering supervision,” in ICRA, 2024.
[99] Z. Li, Z. Yu, D. Austin, M. Fang, S. Lan, J. Kautz, and J. M.
Alvarez, “Fb-occ: 3d occupancy prediction based on forwardbackward view transformation,” arXiv preprint arXiv:2307.01492,
2023.
[100] X. Tian, T. Jiang, L. Yun, Y. Mao, H. Yang, Y. Wang, Y. Wang,
and H. Zhao, “Occ3d: A large-scale 3d occupancy prediction
benchmark for autonomous driving,” in NeurIPS, 2023.
[101] P. Hu, A. Huang, J. Dolan, D. Held, and D. Ramanan, “Safe local
motion planning with self-supervised freespace forecasting,” in
CVPR, 2021.
[102] T. Khurana, P. Hu, A. Dave, J. Ziglar, D. Held, and D. Ramanan,
“Differentiable raycasting for self-supervised occupancy forecasting,” in ECCV, 2022.
[103] Z. Liu, X. Ye, Z. Zou, X. He, X. Tan, E. Ding, J. Wang, and
X. Bai, “Multi-modal 3d object detection by box matching,” IEEE
Transactions on Intelligent Transportation Systems, 2024.

开源鸿蒙跨平台开发社区汇聚开发者与厂商,共建“一次开发,多端部署”的开源生态,致力于降低跨端开发门槛,推动万物智联创新。
更多推荐


 11
11 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)