2025ICCV--Interpretable Zero-Shot Learning with Locally-Aligned Vision-Language Model
大规模视觉-语言模型(VLMs),例如 CLIP,通过利用大规模的视觉-文本配对数据,在零样本学习(ZSL)中取得了显著成功。然而,这些方法通常缺乏可解释性,因为它们计算的是整张查询图像与类别词嵌入之间的相似度,难以解释其预测结果。为了解决这一问题,一种可行的方法是开发具有可解释性的模型,为此,我们提出了 LaZSL,一种用于可解释零样本学习的局部对齐视觉-语言模型。。大量实验表明,我们的方法在可
Abstract
大规模视觉-语言模型(VLMs),例如 CLIP,通过利用大规模的视觉-文本配对数据,在零样本学习(ZSL)中取得了显著成功。然而,这些方法通常缺乏可解释性,因为它们计算的是整张查询图像与类别词嵌入之间的相似度,难以解释其预测结果。为了解决这一问题,一种可行的方法是开发具有可解释性的模型,通过引入语言信息,使用离散的属性构建分类器,类似于人类的感知方式。这带来了一个新的挑战:如何基于预训练的视觉-语言模型,有效地将局部视觉特征与对应的属性进行对齐。为此,我们提出了 LaZSL,一种用于可解释零样本学习的局部对齐视觉-语言模型。LaZSL 通过最优传输实现局部视觉-语义对齐,使视觉区域与其相关属性之间进行交互,从而实现有效的对齐,并在无需额外训练的情况下提供可解释的相似性度量。大量实验表明,我们的方法在可解释性、准确性和领域泛化能力方面均具有显著优势。
1. Introduction
尽管 CLIP 取得了显著的成果,但其性能在推理阶段所使用的文本提示词以及特定领域的数据集上表现出明显的敏感性。因此,许多研究工作主要聚焦于以下两个方面:i) 提示词学习(prompt learning)[44, 55, 56] 和 ii) 适配器学习(adapter learning)[18, 24, 31]。提示词学习旨在从下游数据中发现领域知识,以提高 CLIP 的泛化能力。例如,Zhou 等人提出了利用下游数据进行提示词学习,以在文本提示中引入领域知识 [55, 56]。Shu [44] 和 Feng [17] 则进一步探索了从测试样本本身获取额外信息,以增强提示词的领域知识。适配器学习则遵循微调的思想,通过额外的视觉-语义交互来学习轻量级的参数 [24]。
然而,这些方法仍然遵循标准 CLIP 的方式,计算整张查询图像与每个类别提示词嵌入向量之间的相似度,如图 1(a) 所示,因此其可解释性仍然有限。这是因为它们无法根据目标类别的对应因素(例如属性或语义)来识别类别。同时,这些方法也难以捕捉视觉信息的细粒度特征,从而限制了它们的泛化能力。因此,一些研究工作 [12, 16, 30, 37, 42, 46] 尝试通过引入语言信息来构建具有可解释性的模型,其中分类器是基于离散的属性构建的。具体而言,这些方法利用大型语言模型(LLMs)为每个类别生成多个更精细的文本描述,这些描述包含大量的属性信息,并将这些文本作为提示词,与图像计算相似度,如图 1(b) 所示。这样,它们能够根据与目标类别对应的关键属性来进行分类,因此其分类器具有一定的可解释性,类似于人类的感知方式,即人类通过明显的因素(例如属性)来识别物体。然而,这些可解释的相似度计算仍然是基于整张图像与属性之间的相似度,无法直接捕捉细粒度视觉信息与其对应属性之间的关系,这不可避免地会导致视觉-语义对齐错误,从而限制了视觉-语言模型的泛化能力。
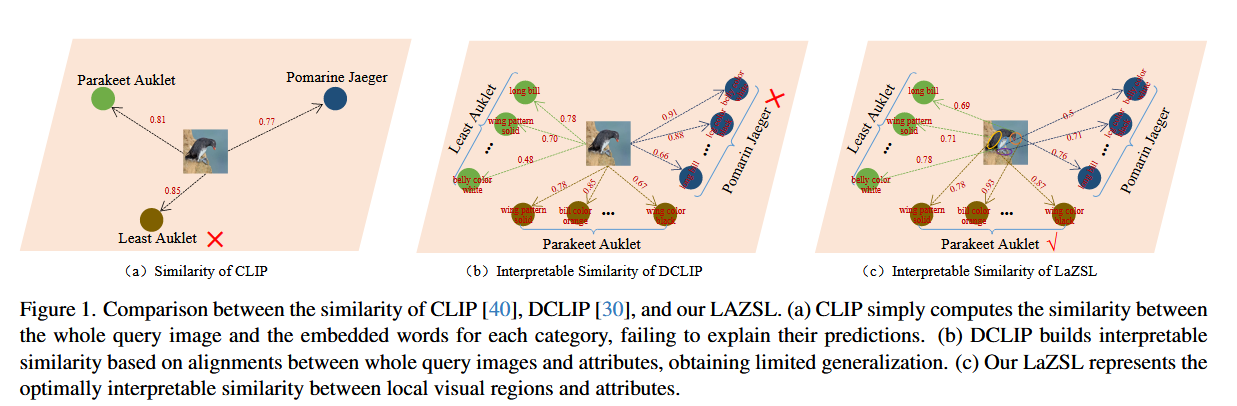
自然地,可解释的零样本学习(interpretable ZSL)带来了一个新的挑战:如何在预训练的视觉-语言模型(VLMs)基础上,实现局部视觉信息与属性之间的有效对齐。与经典的零样本学习方法 [6, 7, 29, 33] 不同,这些方法可以在网络主干中使用注意力机制来学习属性定位,从而实现视觉区域与人工标注属性之间的局部对齐;而视觉-语言模型的网络通常是冻结的,且由于缺乏足够的训练数据,难以重新设计用于训练。受最优传输(Optimal Transport, OT)理论 [28, 36, 47] 的启发,我们可以将每张图像划分为视觉空间中的一组局部图像块(patches),并将每个类别的属性集合视为语义空间中的一个离散分布。通过这样的建模方式,分类任务就转化为衡量视觉空间分布与语义空间分布之间的距离,如图 1(c) 所示。然后,通过计算局部视觉特征与属性特征之间的最优传输方案,实现局部视觉与语义之间的对齐。由此,我们可以基于具体的属性特征和图像块特征进行标签预测,从而实现更有效的对齐并提升分类准确率。
在本文中,我们提出了一种用于可解释零样本学习(interpretable ZSL)的局部对齐视觉-语言模型,称为 LaZSL。LaZSL 首先通过随机裁剪图像和大型语言模型(LLM)分别构建视觉集合和语义集合。然后,LaZSL 采用基于最优传输(OT)的局部视觉-语义对齐方法,构建视觉集合与语义集合之间的交互关系,通过优化 OT 方案实现有效的对齐。值得注意的是,我们还将全局视觉信息引入到混合代价矩阵中,以避免预训练视觉-语言模型中的知识遗忘问题。最终,我们可以通过将混合相似度矩阵与 OT 方案进行对齐,来预测输入图像的类别。在九个广泛使用的数据集上进行的大量实验表明,我们的方法在可解释性、准确率提升以及良好的领域泛化能力等方面均具有显著优势。
我们的主要贡献总结如下:
- 我们提出 LaZSL,以在预训练的视觉-语言模型(如 CLIP)基础上,实现局部视觉与属性之间的有效对齐,从而用于可解释的零样本学习(interpretable ZSL)。与大多数 CLIP 的变体不同,这些方法通常需要额外的模型训练,而我们的 LaZSL 是完全无需训练的。
- 我们引入基于最优传输的局部视觉-语义对齐,以构建视觉区域和属性之间的交互,从而实现有效的对齐,并获得可解释的相似度,用于ZSL预测。
- 我们在9个广泛使用的数据集上进行了广泛的实验,以评估我们的方法,结果表明我们的La ZSL取得了优于基线的性能。
2. Related Works
经典的零样本学习:
早期的零样本学习(ZSL)方法利用人工标注的属性作为辅助信息,以实现从可见类别到不可见类别的知识迁移 [34, 51]。这些方法的核心目标是如何实现有效的视觉-语义交互,以完成知识迁移。通常,这类方法可以分为三种类型:基于嵌入的方法、生成式方法以及公共空间学习方法。
基于嵌入的方法:将视觉特征映射到语义空间,并通过搜索最近的语义原型来完成分类 [1, 7, 9, 21]。
假设我们有一个“斑马”的图像,但我们没见过斑马。
我们知道斑马的语义属性是:“有条纹”、“像马”、“黑白”。
我们把图像特征映射到语义空间,然后找到最接近“斑马”属性的类别,就认为是斑马。
生成式方法:学习一个以语义为条件的生成器,用于合成不可见类别的图像或特征样本,从而将 ZSL 任务转化为监督分类问题 [8, 10, 11, 52]。
我们知道“斑马”的属性描述。
我们训练一个生成器,输入“斑马的属性”,输出“斑马的图像特征”。
然后我们就可以用这些生成的“斑马特征”来训练一个分类器。
公共空间学习方法:将视觉特征和语义特征映射到一个共同的特征空间,并通过最近邻搜索进行分类 [5, 43, 49]。
图像特征 → 映射到公共空间
类别语义(如属性)→ 也映射到同一个空间
然后看谁更近,就分类为哪个类别
尽管这些方法通过人工标注的属性具有一定的可解释性,但收集这些属性信息耗时且费力,尤其是在面对多样化的场景时。因此,这些方法难以在大规模数据集(如 ImageNet)上取得良好的效果。
基于视觉-语言模型(VLM)的零样本学习:视觉-语言模型通过大规模的视觉-文本配对数据进行训练,具备强大的知识迁移能力 [22, 40]。例如,CLIP 在零样本学习任务中引领了新的研究趋势 [40]。尽管取得了显著进展,CLIP 仍然严重依赖于提示词的设计,并且在特定领域的数据集上表现有限 [27, 55]。为此,许多研究工作尝试通过提示词学习 [24, 53, 55] 和适配器学习 [24, 31] 等方法来改进 CLIP。然而,这些方法仍然是通过计算整张查询图像与类别名称的词嵌入向量之间的相似度来进行分类,缺乏可解释性。最近,一些研究工作 [12, 16, 30, 37, 42, 46] 尝试通过引入由大型语言模型(LLMs)生成的语言信息,构建具有可解释性的模型。在这些模型中,分类器可以根据目标对象是否具备对应的关键属性来识别目标类别,类似于人类的认知方式。然而,这些方法仍然难以有效地捕捉局部视觉信息与对应属性之间的关系,导致视觉空间与语义空间之间的错误对齐,从而限制了视觉-语言模型的泛化能力。为了解决这一挑战,我们设计了一种局部对齐的视觉-语言模型,在预训练的视觉-语言模型基础上,实现局部视觉信息与属性之间的有效对齐。
最优传输在视觉中的应用:最优传输(Optimal Transport, OT)理论最初被引入是为了解决如何以最小成本同时运输多个物品的问题 [36]。由于其具备分布匹配的特性,OT 已被广泛应用于多种计算机视觉任务中 [2, 25, 26]。与我们的工作更为相关的是,一些研究 [4, 28, 47] 将 OT 用于提示词调优(prompt tuning)。例如,Chen 等人 [4] 和 Li 等人 [28] 利用 OT 同时学习单模态或多模态的提示词,以优化文本提示。与这些方法不同的是,我们使用 OT 来在局部视觉集合与属性集合之间寻找更好的对齐方式,通过局部对齐获得更准确的相似度,从而提升分类性能。
3. Locally-Aligned Vision-Language Model
在本节中,我们介绍了一种用于可解释零样本学习的局部对齐视觉-语言模型(称为 LaZSL)。该模型通过最优传输(OT)优化语义特征与视觉特征之间的交互,实现局部视觉信息与属性之间的有效对齐。LaZSL 能够根据其对应的属性准确捕捉局部的细粒度视觉信息,从而进行类别预测。因此,该方法在可解释性、准确率提升以及良好的领域泛化能力方面均表现出色。
如图 2 所示,LaZSL 主要由三个部分组成:语义集合与视觉集合的构建、基于最优传输的属性级视觉-语义交互,以及零样本预测。我们将在接下来的小节中详细介绍这些部分的具体内容。
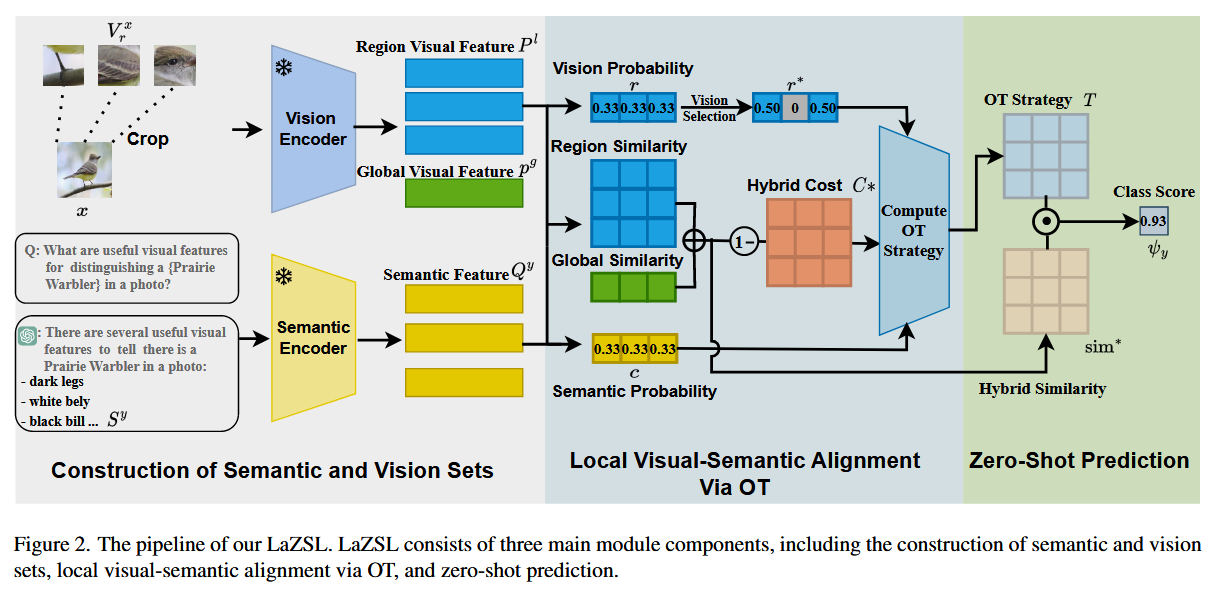
3.1. Construction of Semantic and Vision Sets
尽管基于全局特征的 CLIP 变体在零样本学习任务中表现出色,但它们在处理细粒度分类任务或语义信息较为稀疏的类别时往往表现不佳。因此,有必要通过引入局部属性来增强 CLIP 模型,以捕捉更细粒度的视觉信息。此外,构建属性分类器还具有可解释性的优势 [30]。为了实现这一目标,我们首先构建了语义集合和视觉集合。
语义集合的构建。为了在属性级别引入语义信息,我们参考 [30] 的方法,借助大型语言模型(LLM)为每个类别构建语义集合。具体而言,给定一个类别标签 y,可以通过以下方式生成语义集合:
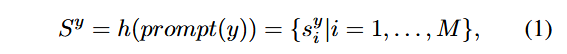
其中,h(⋅) 表示大型语言模型(例如 GPT-3),而 prompt(⋅) 是一个模板函数,通过使用固定的提示词模板来生成针对 LLM 的查询语句。
实际上,在为每个类别获得语义集合之后,大多数可解释的零样本学习(ZSL)方法通常通过计算全局视觉特征与语义集合中各个属性之间的相似度,并对这些相似度取平均,来得到该类别的得分 [30, 37, 42]。虽然这种方法在一定程度上能够缓解由于属性语义缺失所带来的不足,但其本质上仍然是利用属性信息进行全局对齐,而非真正实现属性级别的视觉-语义交互。为了解决这一问题,我们进一步构建了一个视觉集合,用于捕捉局部的视觉信息,并将其用于实现局部的视觉-语义交互。
视觉集合的构建。具体而言,我们尝试通过对原始图像进行随机多尺度裁剪,来捕捉与语义集合相对应的视觉区域。给定一张图像 x∈,其中 H 和 W 分别表示图像的高度和宽度,我们提出使用函数 Pr(⋅,⋅) 来构建区域视觉集合:
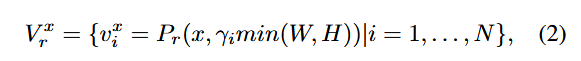

3.2. Local Visual-Semantic Alignment Via OT
在构建视觉和语义集合之后,我们使用CLIP编码器来获得它们的潜在空间表示
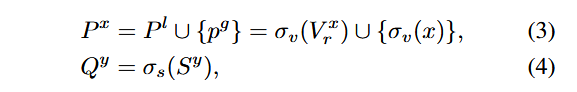
其中,和
分别是CLIP的视觉编码器和语义编码器。我们得到的
包括局部视觉特和全局视觉特征
与现有的可解释零样本学习方法 [30, 37, 42] 不同,这些方法使用全局特征进行视觉-语义对齐(即一对一的匹配),我们的方法构建了局部的视觉集合和语义集合(即多对多的匹配)。在这种情况下,简单地平均多个相似度无法充分估计两个集合之间的相似性。因此,我们提出了一种基于最优传输(OT)的匹配方法。
最优传输问题可以被视为寻找将一种概率分布转换为另一种概率分布所需的最小代价。由于这一代价可以作为衡量两个概率分布之间距离的指标,我们利用最优传输(OT)理论来实现视觉集合与语义集合之间的匹配。最优传输的计算过程可以表示为:
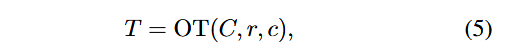
其中,T 表示最优传输(OT)方案,r 和 c 分别表示视觉集合和语义集合的离散概率向量,通常初始化为均匀分布。C 是区域视觉集合与语义集合之间的代价矩阵,矩阵中的每个元素 Ci,j 的计算方式为:
![]()

可以看出,通过使用最优传输(OT),我们找到了一种有效的方法来评估视觉集合与语义集合之间的相似性。然而,该算法仍存在两个局限性:i)随机获得的区域视觉特征中包含一定的噪声;
ii)这些区域视觉特征可能导致 CLIP 视觉编码器的知识遗忘,无法很好地捕捉其对应的类别信息。为了解决这些问题,我们提出了一种视觉选择机制以及一种区域-全局混合代价(region-global hybrid cost)方法。
Vision Selection.具体而言,原始的区域视觉特征根据一个阈值 δ 被划分为相关区域集合和不相关区域集合,其中阈值 δ 是根据所有区域视觉特征与全局图像之间的平均相似度计算得到的。随后,我们通过修改与 δ 相关的概率向量 r 的初始化方式,来去除不相关的噪声。该过程可以表示为:
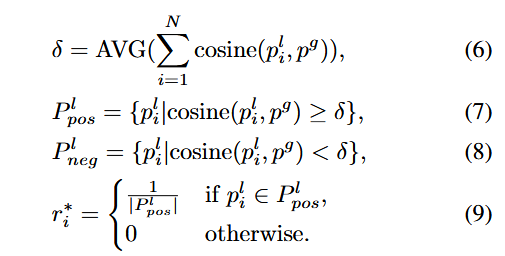
因此,视觉概率 r 根据公式(9)更新为 r∗。随后,正样本区域视觉集合 pil∈Ppos 被用于通过最优传输(OT)进行视觉-语义交互。
视觉概率 r 是一个权重向量,用于表示图像中各个局部区域的重要性,在最优传输中作为源分布,帮助模型聚焦于更有意义的视觉区域,从而提升分类准确性和可解释性。
Region-Global Hybrid Cost.在最优传输(OT)中,代价矩阵是一个至关重要的先验知识来源。在基于 OT 的视觉-语义交互中,我们观察到,当前的代价仅由随机裁剪得到的区域视觉集合与语义集合之间的相似度构成。这种做法不可避免地使得从该代价计算出的 OT 策略 T 对裁剪过程引入的噪声过于敏感,从而导致 CLIP 视觉编码器的知识遗忘。为了解决这一问题,我们选择将额外的全局先验信息引入到代价矩阵中:
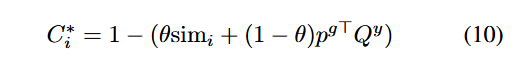
其中, 表示混合代价矩阵 C∗ 的第 i 行,θ∈(0,1) 是一个超参数,可视为区域特征与全局特征之间的混合置信度。
Compute OT Strategy. 在获得混合代价矩阵 C∗ 之后,我们就可以计算最优传输方案T。具体而言,我们选择使用 Sinkhorn 算法 [13] 来求解最优传输距离,该算法通过引入熵正则项实现快速优化。通过迭代更新区域视觉集合与语义集合之间的策略矩阵,公式(5)具体表示为:
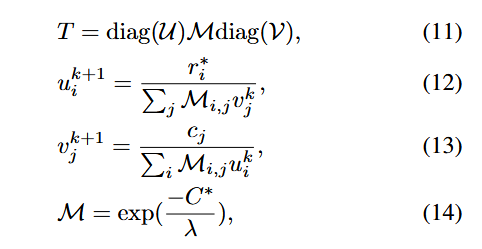
3.3. Zero-Shot Prediction
在视觉-语义交互之后,我们得到OT计划T。同样,为了与成本矩阵对齐,我们使用混合相似度方法计算类别得分:
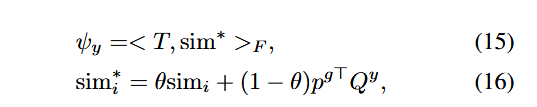
其中,表示混合相似度矩阵
的第i行,
表示两个矩阵之间的 Frobenius 内积。可以观察到,对于每个类别y,我们都可以获得其对应的类别得分。接下来,我们使用该得分进行零样本预测:
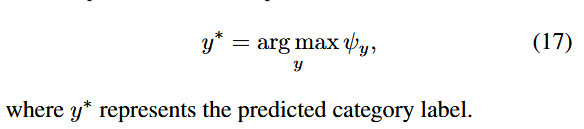

开源鸿蒙跨平台开发社区汇聚开发者与厂商,共建“一次开发,多端部署”的开源生态,致力于降低跨端开发门槛,推动万物智联创新。
更多推荐

 26
26 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)