奖励模型“裁判”失灵?LongRM 突破长上下文瓶颈,8B模型性能超过 Gemini 2.5 Pro
我们选择了四个有代表性的现有生成式奖励模型(GenRMs)进行评估,包括两个基础 LLM:Llama-3.3-70B 和 Qwen3-8B,以及两个微调过的生成式奖励模型(GenRMs):Skywork-Critic-Llama-3.1-70B 和 Selene-1Mini-Llama-3.1-8B。为验证传统上下文扩展方法的有效性,我们选择了原生支持32K上下文的Con-J-Qwen2-7B模型
在大模型快速发展的今天,奖励模型 作为对齐人类偏好的关键组件,扮演着“裁判”的角色,通过评判回答的优劣指引大模型向人类价值观靠拢。随着任务上下文越来越长——从智能体任务[1,2]到长文档分析[3],一个关键问题浮现:传统的奖励模型能否胜任长上下文评估?
我们的研究给出了明确答案:不能。
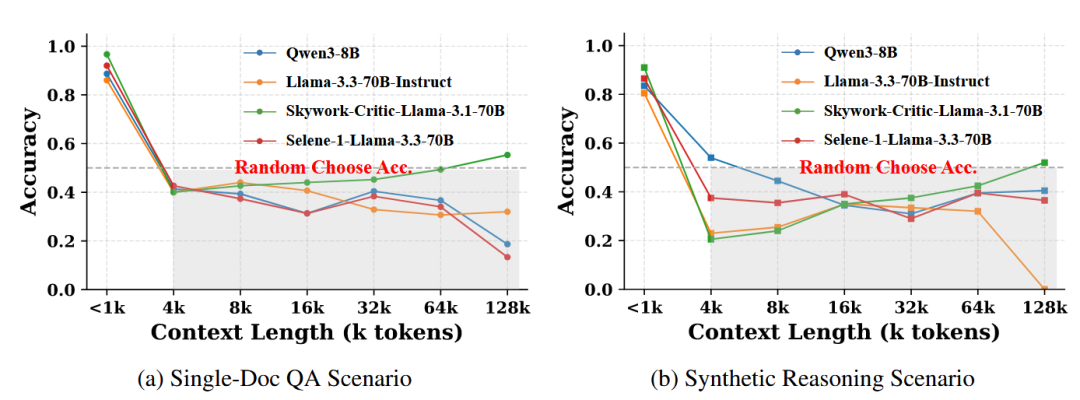
我们构建了首个针对长上下文奖励建模的评测基准 Long-RewardBench,通过实验,我们发现如图1所示:现有的奖励模型在短文本上表现出色,但一旦上下文长(包含输入和模型输出部分)度超过 4K token,其判断准确率就会骤降至 50% 以下,几乎等同于随机猜测。
针对该奖励崩溃问题,我们提出一种通用多阶段训练策略。基于此策略,我们能够获得兼顾短上下文与长上下文评估的奖励模型——LongRM。
如下图所示,我们基于80亿参数模型训练的LongRM,在长上下文评估上的表现不仅超越了700亿参数的基线模型,更能与Gemini 2.5 Pro模型在长上下文评估场景上媲美。(绿色突出显示相对改进,粗体表示最佳性能)
论文 & 代码(含评测数据)
我们的相关代码和数据已开源:
论文: LONGRM: REVEALING AND UNLOCKING THE CONTEXT BOUNDARY OF REWARD MODELING
链接: https://arxiv.org/pdf/2510.06915
GitHub:https://github.com/LCM-Lab/LongRM
Models: https://huggingface.co/collections/LCM-Lab/longrm-68ea4cefb68ff927efbe9187
Long-RewardBench V1: https://huggingface.co/datasets/LCM-Lab/LongRewardBench
严峻挑战:当上下文变长,奖励模型为何“集体崩溃”?
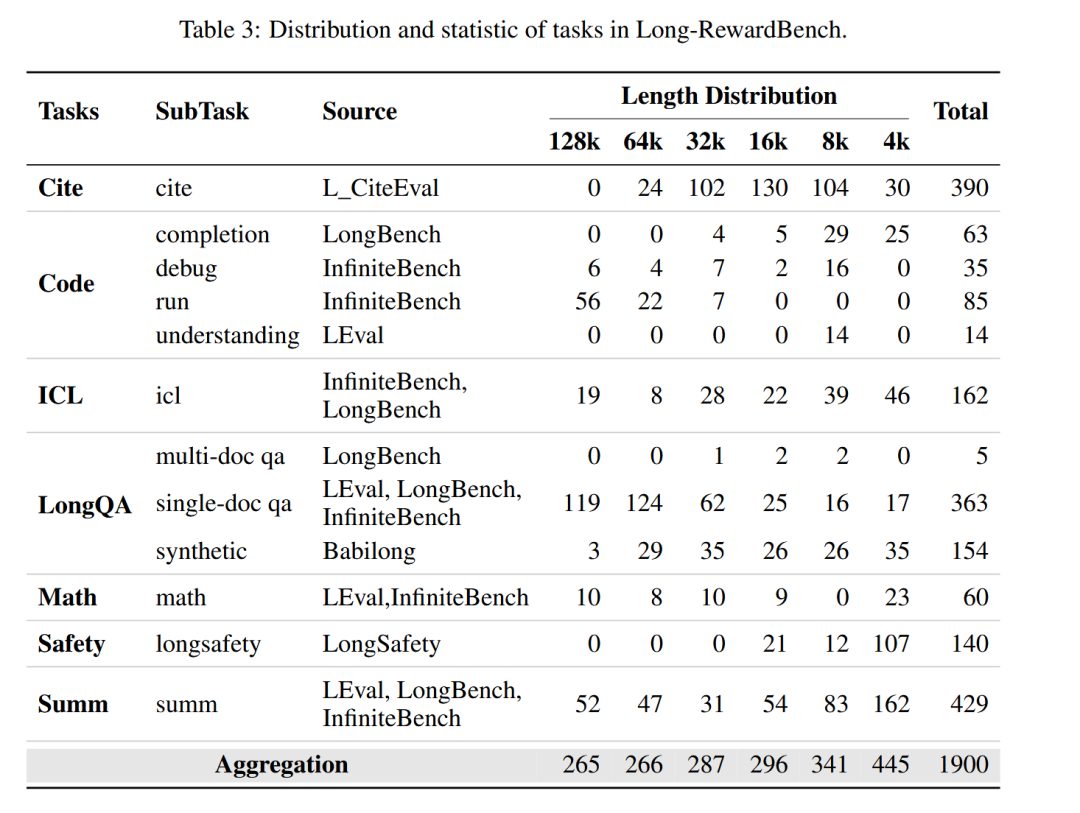
为量化奖励模型在长上下文场景下的性能表现,我们构建了业界首个专注于此的基准——Long-RewardBench。
Long-RewardBench概览
Long-RewardBench的每个测试样本包含四个部分:问题 、上下文 、待评估的模型响应集合 ,以及真实预测 (包括判断和相应解释)。
如图2所示,我们从现有开源长上下文数据集中抽取原始实例,每个实例包含问题 、上下文 和标准答案 。针对每个三元组,我们提示一组多样化的LLM生成响应,然后使用任务特定的自动指标(如摘要任务使用ROUGE-L)对每个响应 评分,作为推导偏好排名的依据。最后,我们使用强大的LLM为这些偏好合成推理解释。
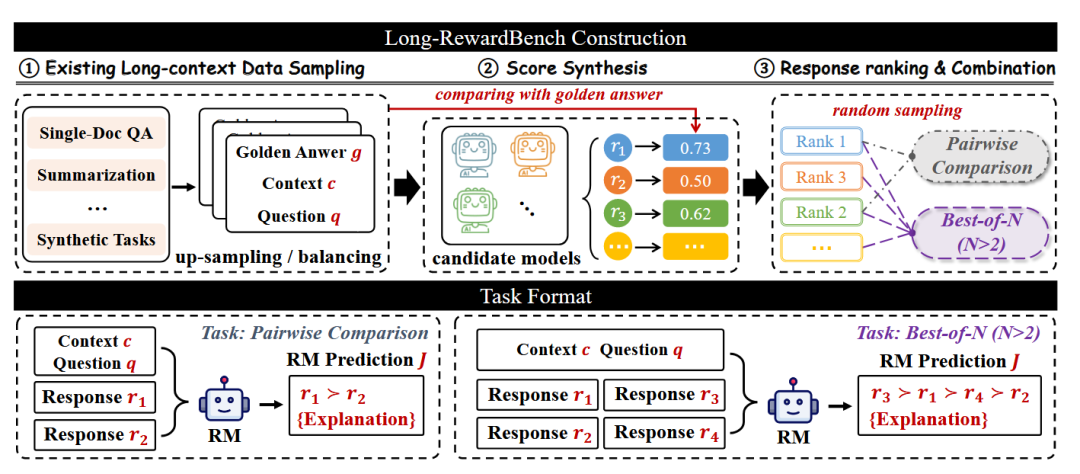
Long-RewardBench包含两个核心任务:
-
成对比较 :给定两个候选响应 、问题 和上下文 ,要求奖励模型选择更优响应并提供解释
-
N选最佳 :给定多个模型响应集合 、问题 和上下文 ,奖励模型需对所有响应排序并提供解释
在 LONG-REWARDBENCH 上的实验结果
我们选择了四个有代表性的现有生成式奖励模型(GenRMs)进行评估,包括两个基础 LLM:Llama-3.3-70B 和 Qwen3-8B,以及两个微调过的生成式奖励模型(GenRMs):Skywork-Critic-Llama-3.1-70B 和 Selene-1Mini-Llama-3.1-8B。为便于细粒度分析,我们专注于两个受控场景:单文档问答 和 合成长形式推理。
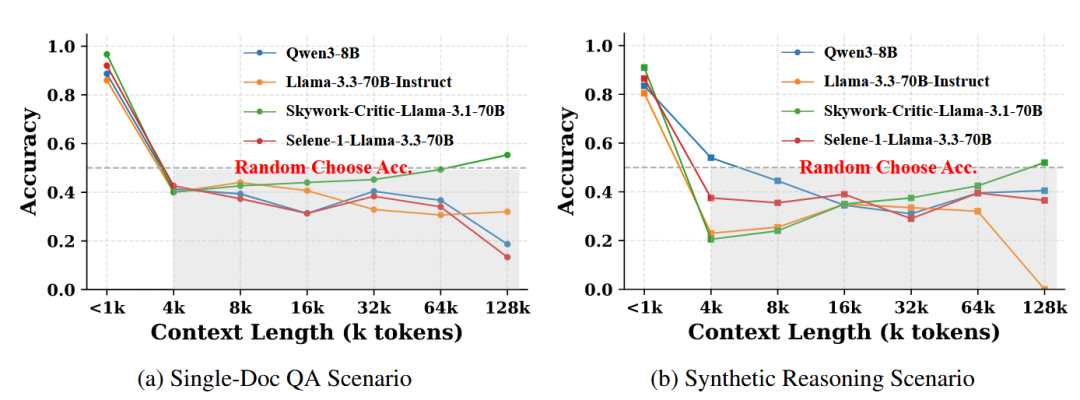
结果上图所示:
-
当上下文长度低于1K token时,大多数奖励模型表现优异
-
上下文长度达到4K token时,所有模型性能急剧下降,准确率降至50%以下
-
随着上下文长度从4K扩展到128K,没有模型能持续超过50%的准确率
-
到128K token时,除一个模型略微超过阈值外,所有模型的准确率始终低于50%
值得注意的是,大型基础模型Llama-3.3-70B-Instruct在128K的长形式推理场景中完全失败,准确率为0%,表明在极端长度下上下文感知的偏好判断完全崩溃。 此外,我们惊奇地发现,一个 80 亿参数规模的模型(Qwen3-8B)在长上下文评估中的表现几乎与 700 亿参数规模的同类模型相当。这表明,仅仅扩大模型规模并不能解决在超长上下文下进行上下文感知偏好判断的根本挑战。
传统上下文扩展方法的效果
为验证传统上下文扩展方法的有效性,我们选择了原生支持32K上下文的Con-J-Qwen2-7B模型,应用两种代表性的上下文扩展方法:免训练的位置插值方法YaRN和长上下文监督微调方法。两者的目标均为扩展到 128K 上下文长度。
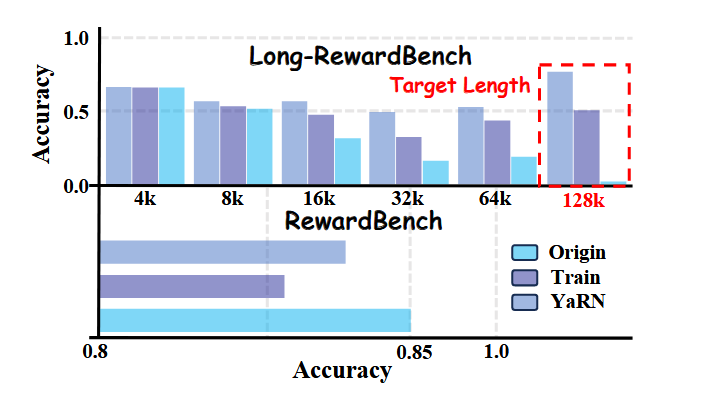
如图4所示,虽然这两种方法在长上下文评估上带来了一些改进,但它们在RewardBench上的短上下文性能显著下降,且在128K目标长度处表现出强烈的长度诱导偏差。这凸显了传统上下文窗口扩展的一个局限性:它们以泛化能力为代价以实现目标长度适应,而没有解决鲁棒的长上下文-响应一致性奖励建模的核心挑战。
失败模式分析
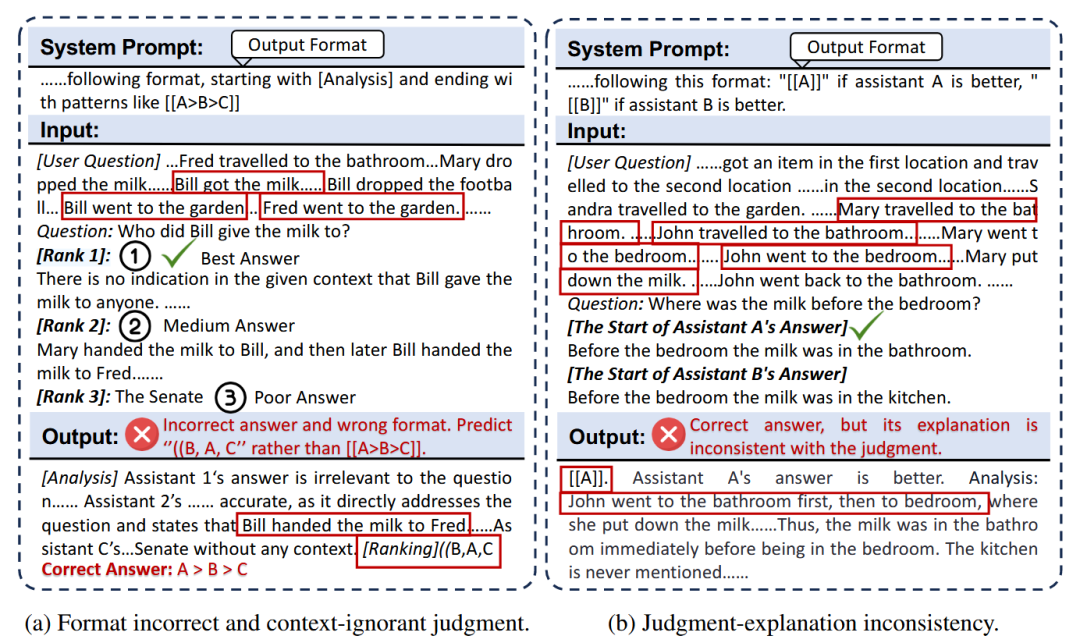
如图5所示,我们进一步分析了生成式奖励模型的输出,识别出两种普遍存在的失败模式:
-
格式不遵从和上下文忽略的判断:在长输入下,RM经常无法遵守指定的响应格式或未能基于长上下文判断;
-
判断-解释不一致:解释(推理过程)与判断相矛盾。
这表明生成式RM在长上下文场景下天生具备基本的评估能力,但它们的失败可能源于(1)未能遵循上下文(包括指令)和(2)判断-解释不一致。
解决方案:多阶段训练策略 + 高质量数据合成
为了突破这一瓶颈,我们提出了一个通用、高效的多阶段训练框架,可将任意模型扩展为具备长上下文评估能力的 LongRM。
阶段一:通过 SFT 启动代码
除了传统的奖励模型评估维度(如帮助性和安全性),我们引入"忠实度"作为新的评估维度,明确要求模型评估回答是否严格基于所提供的长上下文。
监督微调阶段的设计有两个核心目标:
-
对于现有奖励模型,训练其在长上下文条件下遵守结构化输出格式
-
对于基础模型,注入执行评估所需的知识,同时确保格式合规
为保留模型原有的短上下文评估能力,我们从公开可用的奖励模型训练集中抽样记为 ,与我们的长上下文监督微调数据 合并后( )进行训练。
"由短到长"的数据合成策略
先前研究表明,即使是强大的长上下文LLM,在上下文极长时(如≥128K),判断的可靠性也会下降。为缓解此问题,我们设计了创新的数据合成策略。 如图5(左侧)所示,我们首先识别长上下文中对判断至关重要的关键块,丢弃不相关片段,仅使用关键块构建更集中的短上下文,使强模型能够生成更可靠的判断。最后,用丢弃的上下文块将短上下文填充到目标长度,形成完整的训练上下文。
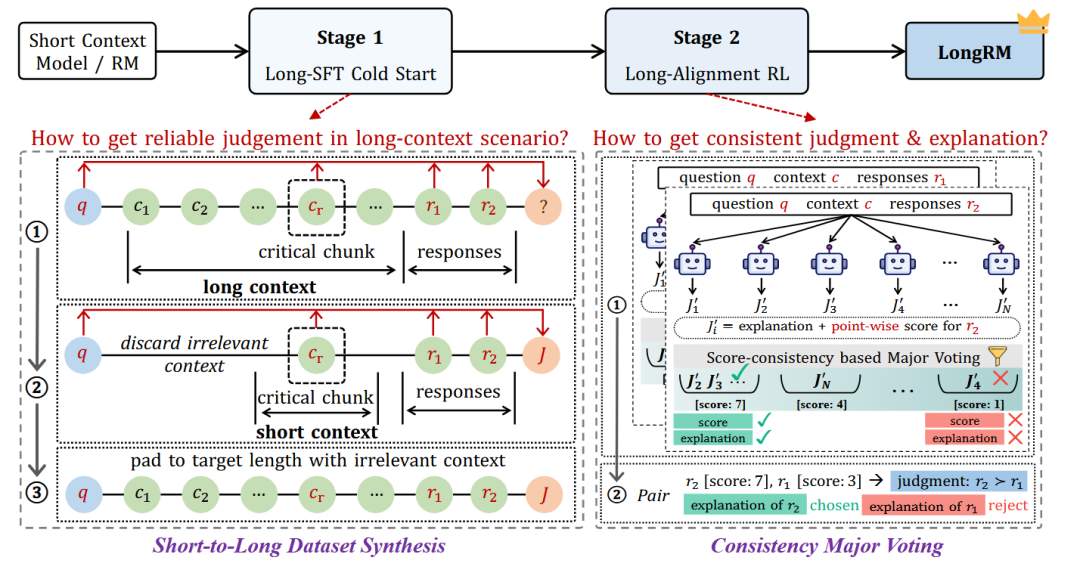
阶段二:通过强化学习进行细粒度对齐
为解决模型"判断"与"解释"自相矛盾的问题,我们采用强化学习进行细粒度对齐。考虑到训练期间的长上下文长度,为了效率和效果,我们采用 LOGO(一种专为长上下文对齐设计的 DPO 变体)。 训练目标函数为:
其中 是胜出的RM响应(判断-解释一致), 是失败的RM响应(判断-解释不一致), 是失败的RM响应的数量, (奖励差异的缩放因子)和 (目标奖励边际)是用于分离胜出和失败响应的超参数。
接着通过一致性多数投票合成 DPO 数据,如图 5(右下角)所示,为合成一致的判断和解释,我们首先将成对比较任务——给定输入 ——重新表述为两个独立的点式评分任务: 和 。让一组现有的强奖励模型(RM)独立地为每个回答进行绝对评分并给出解释,而不是在 和 之间进行任意或维度不可知的比较,从而确保预测的标量值与其解释之间的一致性。
在所有模型对 和 评分后,通过一致性多数投票机制,自动筛选出评分与解释高度一致的样本作为正例(胜出解释),不一致的作为负例(失败解释)。
实验&实验结果
通过一系列实验,我们观察到:
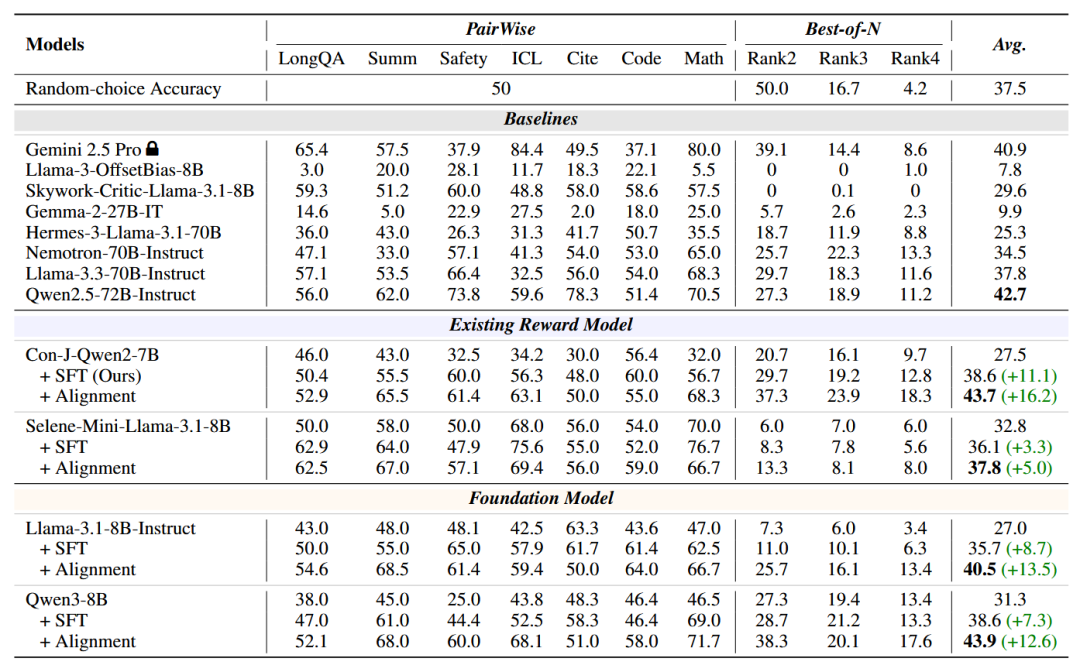
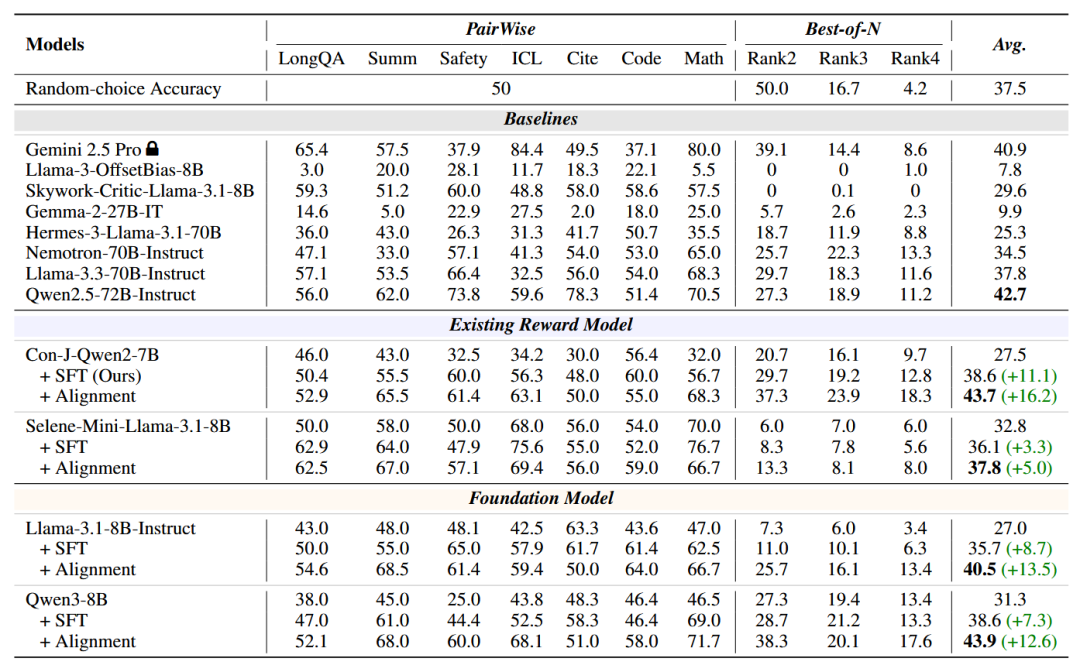
长上下文评估:通过在表 1 中展示的在Long-RewardBench 上的实验结果。我们可以观察到:
-
我们的方法在所有任务上一致地改进了现有奖励模型(RM)和基础模型。在训练之前,几乎所有模型的得分都低于理论随机选择准确率,表明其响应存在严重的格式失配。例如,Con-J-Qwen2-7B 平均仅得 27.5。使用我们的方法后,它提高到 43.7,显著超越了骨干模型。
-
我们的方法使小型 LLM 能够与更大得多的骨干模型和专有模型相媲美甚至超越。例如,经过对齐后,Qwen3-8B 和 Con-J-Qwen2-7B 分别达到 43.7 和 43.9,超过了强大得多的骨干模型 Qwen2.5-72B-Instruct。
-
我们在不同模型系列上的改进是稳定和鲁棒的,不同模型上持续带来相对收益:Con-J-Qwen2-7B 上 +16.2,Selene-Mini-Llama-3.1-8B 上 +5.0,Qwen3-8B 上 +12.6。
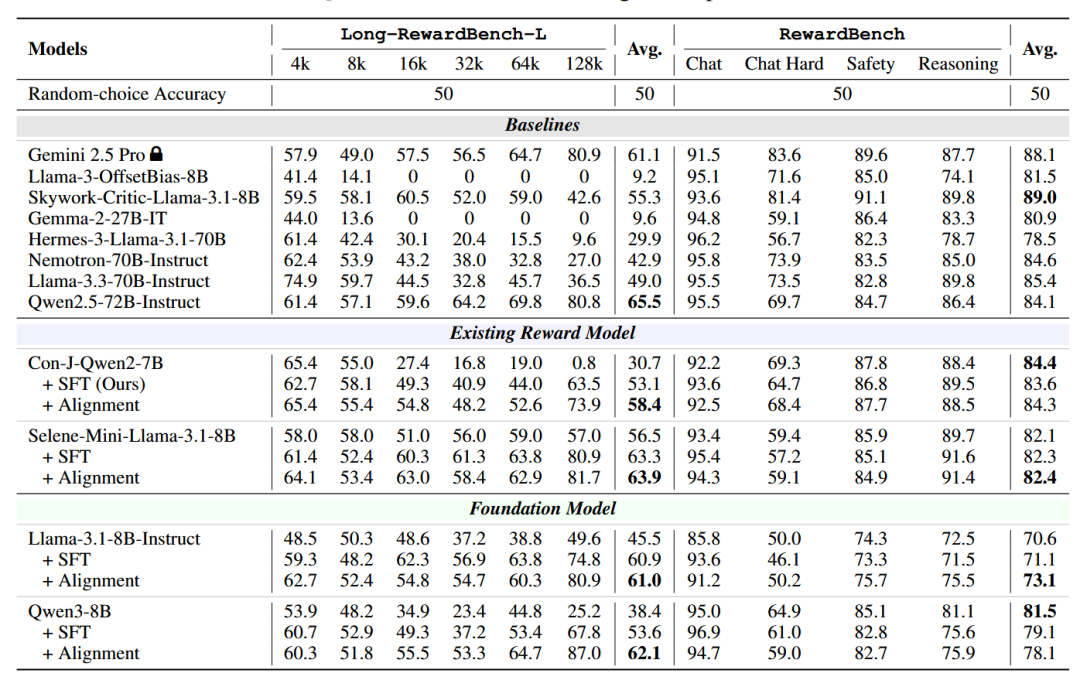
长度区间分析:我们分析了模型在成对任务上不同上下文长度区间的性能,同时通过 RewardBench 评估它们的短上下文能力。通过表2中的结果,我们观察到:
-
与传统的上下文扩展方法相比,我们的 LongRM 在所有长上下文区间(4K 到 128K)都表现出一致的改进,显示了我们的方法的鲁棒性。
-
值得注意的是,即使在 64K 和 128K 等极端长度下,使用我们的方法训练的模型也比其各自的基线实现了显著的提升。
短上下文评估能力:上述长上下文性能的增益是并没有过多损害短上下文能力。
-
在 RewardBench 上,我们的模型总体上保持或略微改善了基线性能,与现有的强基线相当或持平。例如,使用我们方法的 Con-J-Qwen2-7B 平均得分为 84.3,与其原始性能(84.4)持平,并且与大多数强基线相比具有竞争力。
-
然而,我们观察到在应用我们的方法后,Qwen3-8B 的性能有所下降(从 81.5 到 78.1)。这很可能归因于 Qwen3-8B 已经在 RewardBench 上取得了高分,并且对微调数据引入的领域偏移敏感。我们将此异常问题留待未来工作解决。
消融研究
此外,我们通过两项关键研究,验证了我们这个方法的通用性与实际应用价值。
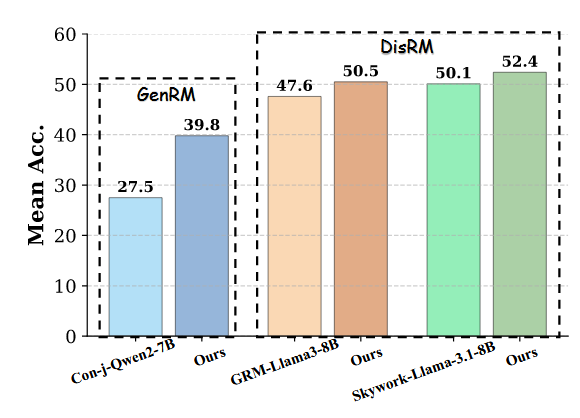
1. 方法通用性:同样适用于判别式奖励模型
为证明数据合成方法不仅限于生成式模型,我们将其应用于判别式奖励模型。我们在两个强大的判别式奖励模型(GRM-Llama3-8B与Skywork-Reward-V2-Llama-3.1-8B)上进行了实验。结果如图6所示,我们的训练策略成功地为判别式模型带来了约2分的性能提升。
2. 实战有效性:赋能长上下文模型训练
我们设计了一个实验证明LongRM能作为可靠的"AI裁判",直接提升长文本模型的训练质量。我们使用长上下文数据对模型进行监督微调,采用自蒸馏方法,让基础模型生成多个回答,然后用高效轻量的LongRM自动筛选最佳回答作为训练目标。
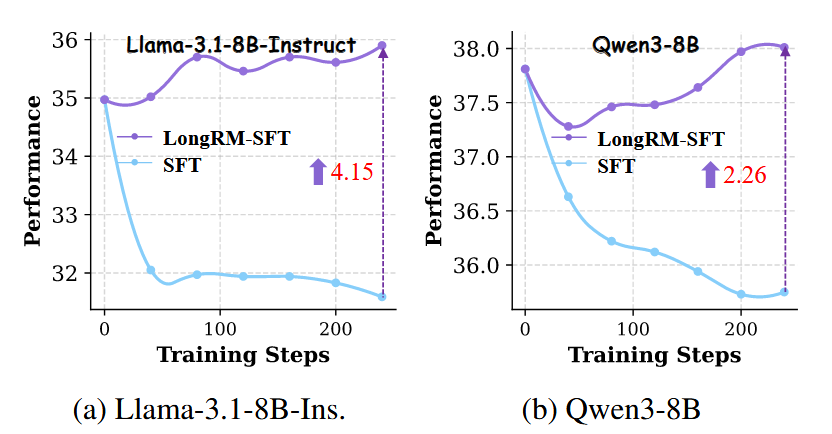
结果如图7所示,在LongBench基准上:
-
传统的直接微调会导致性能下降。
-
而由我们的LongRM引导的自蒸馏方法,则带来了显著且稳定的性能提升。
-
补充对比实验证实,传统的短上下文奖励模型在此长文本训练任务中无法提供有效监督,凸显了LongRM的独特价值。
结论 & 未来展望
LongRM的潜力远不止于对最终生成结果的打分。未来研究将致力于将LongRM的能力扩展至对生成过程的深度评估,例如对长结构化任务中的规划步骤(Plan)、中间推理链(Reasoning Chain) 或多步决策轨迹进行细粒度的可信度判断与引导。通过评估过程的合理性、连贯性与忠实度,我们希望AI系统进行有意义的“思考”而非仅“输出”,实现奖励模型从“结果评判者”到“思维教练”的跃迁。
参考文献
-
Zheng Y, Fu D, Hu X, et al. Deepresearcher: Scaling deep research via reinforcement learning in real-world environments[J]. arXiv preprint arXiv:2504.03160, 2025.
-
Mai X, Xu H, Li Z Z, et al. Agent rl scaling law: Agent rl with spontaneous code execution for mathematical problem solving[J]. arXiv preprint arXiv:2505.07773, 2025.
-
Liu J, Zhu D, Bai Z, et al. A comprehensive survey on long context language modeling[J]. arXiv preprint arXiv:2503.17407, 2025.



开源鸿蒙跨平台开发社区汇聚开发者与厂商,共建“一次开发,多端部署”的开源生态,致力于降低跨端开发门槛,推动万物智联创新。
更多推荐
 16
16 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)