TTRL: Test-Time Reinforcement Learning
本文研究了在缺乏显式标签的数据上,对大型语言模型(LLMs)进行推理任务的强化学习(RL)。该问题的核心挑战在于:在推理阶段无法访问真实标签(ground truth)的情况下,如何进行奖励估计。尽管这一设定看似难以实现,我们发现,测试时扩展(Test-Time Scaling, TTS)中的常见做法(如多数投票),能够产生出乎意料地有效的奖励信号,足以驱动强化学习训练。在此基础上,本文提出了测试
NeurIPS 2025 字节的论文,上班需要用到这个方法因此潦草读一下
Abstract
本文研究了在缺乏显式标签的数据上,对大型语言模型(LLMs)进行推理任务的强化学习(RL)。该问题的核心挑战在于:在推理阶段无法访问真实标签(ground truth)的情况下,如何进行奖励估计。尽管这一设定看似难以实现,我们发现,测试时扩展(Test-Time Scaling, TTS)中的常见做法(如多数投票),能够产生出乎意料地有效的奖励信号,足以驱动强化学习训练。
在此基础上,本文提出了测试时强化学习(Test-Time Reinforcement Learning, TTRL),一种在无标签数据上训练 LLM 的新方法。TTRL 通过利用预训练模型中蕴含的先验知识,使 LLM 能够实现自我演化(self-evolution)。
实验结果表明,TTRL 在多种任务和模型上均能稳定提升性能。值得注意的是,在仅使用无标签测试数据的情况下,TTRL 使 Qwen-2.5-Math-7B 在 AIME 2024 上的 pass@1 指标提升了约 211%。此外,尽管 TTRL 仅由 maj@n 指标进行监督,其性能却持续超过初始模型 maj@n 的上限,并接近直接使用带有真实标签的测试数据进行训练的模型。
实验结果验证了 TTRL 在多种任务上的普适有效性,并展示了其在更广泛任务和领域中的潜力。
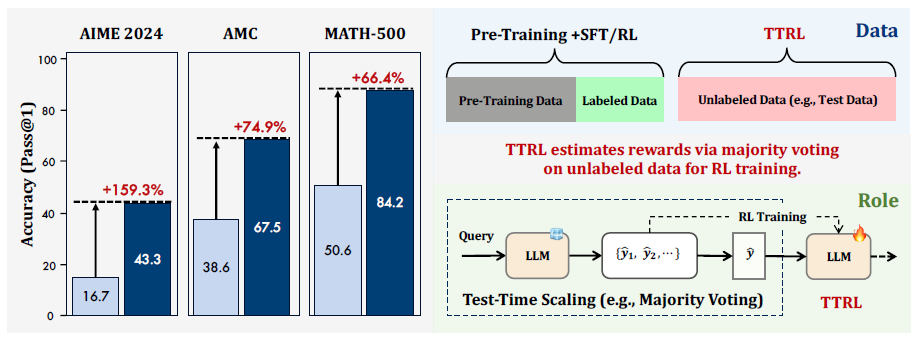
Figure 1: Performance and Position of TTRL.
Contribution
We introduce Test-Time Reinforcement Learning (TTRL), which performs test-time training
through RL. TTRL employs repeated sampling strategies in the rollout phase to accurately
estimate the label and compute rule-based rewards, thereby enabling RL on unlabeled data.
By incorporating effective majority voting rewards, TTRL facilitates efficient and stable RL
in the absence of ground truth labels. TTRL directly addresses the problem of training models via RL without explicit supervision, investigating a model’s ability to explore and learn in this challenging yet critical setting. Essentially, TTRL enables the model to generate its own experiences, estimate rewards, and improve its performance over time.
1. Majority voting provides effective reward estimation for TTRL (§ 3).
2. TTRL can exceed its training signal and upper limit maj@n, and closely mirrors the performance of direct training on the test data with ground-truth (§ 4.1).
3. It is possible to achieve efficient and stable RL in an unsupervised manner (§ 4.2).
Related Works
Such self-evolvement can be broadly categorized into two modes:
1) adaptation to test-time data, which enables models to tackle harder benchmarks such as ARC-AGI-2
2) training on external unlabeled data, which unlocks more training data beyond labeled corpora. This work focuses on the adaptation to testtime
data, which has been extensively studied under the paradigm of Test-Time Training
(TTT) (Sun et al., 2019; 2024; Behrouz et al., 2024; Aky¨ urek et al., 2024). TTT has received
increasing attention recently. These approaches adapt model parameters at test time by
exploiting the structure and distributional properties of incoming test data.
Method
We study the problem of training a pre-trained model during test time using RL without ground-truth labels. We call this setting Test-Time Reinforcement Learning.
同一问题 → 多次推理(TTS) → 统计一致性(maj@n) → reward → 立刻更新
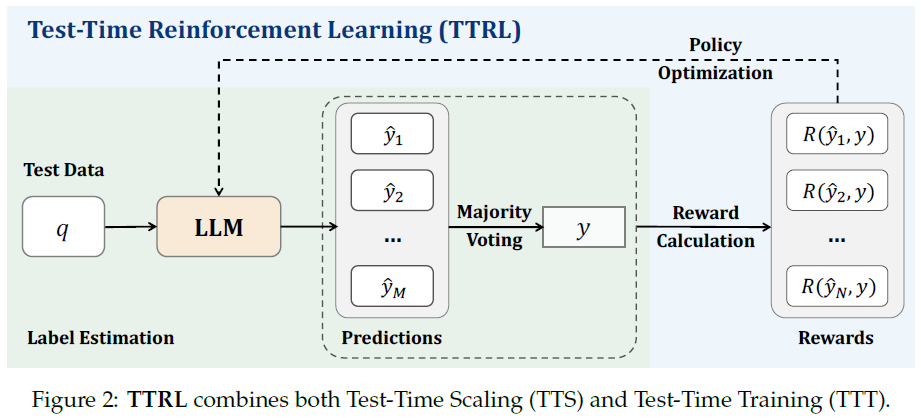
Given a state represented by the prompt x, the model acts by producing an output y sampled from a policy πθ (y | x) parameterized by θ.
To construct a reward signal without ground-truth labels, we generate multiple candidate outputs {y1, y2, . . . , yN} from the model through repeated sampling.
A consensus output y∗ is derived, for instance, by majority voting or another aggregation method, serving as a proxy for the optimal action.
The environment then provides a reward r(y, y∗) based on the alignment between the sampled action y and the consensus action y∗. The RL objective is thus to maximize the expected reward:

and parameters θ are updated through gradient ascent:
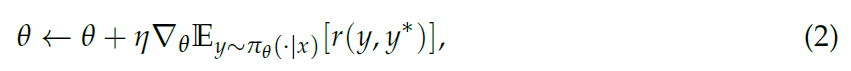
where η denotes the learning rate. This approach enables the model to adapt during inference, effectively improving its performance on distribution-shifted inputs without the need for labeled data.
Majority Voting Reward Function
The majority voting reward is determined by first estimating a label through majority voting. This estimated label is then used to calculate rule-based rewards, which serve as the final rewards. Given a question x, we first input x into the LLM to generate a set of outputs. An answer extractor then processes these outputs to obtain the corresponding predicted
answers, denoted as P = {yˆi}iN=1. We first follow Equation 4 over P to estimate a label, with majority voting as the scoring function s(y, x) to get y, the most frequently occurring prediction in P. The majority-voted prediction y is then used as the estimated label to compute rule-based rewards (Guo et al., 2025). The reward function is:

Evaluation
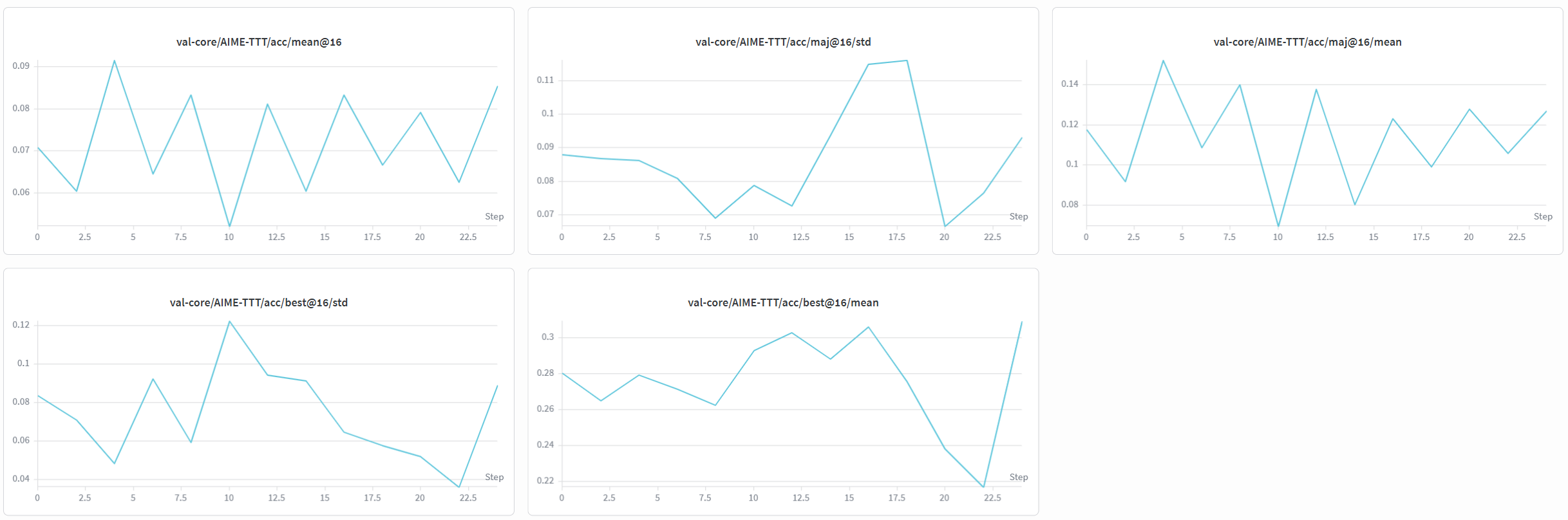
这里重点注意一下, 就是这个计算指标是这样的:

然后各种指标如下(这个是我复现的)
-
acc:accuracy(准确率)
-
@16:每道题采样 16 次(通常是 16 个 reasoning path / 16 次生成)
-
mean / std:均值 or 标准差
best@16 = oracle best-of-16
16 次生成里,只要有一次是对的,就算这题做对
判断框架
| 情况 | 含义 |
|---|---|
| best ↑,maj 不变 | 有能力但不稳定 |
| mean ↑,maj ↑ | 真实能力增强 |
| std ↑ | 不稳定 |
| best 很高,maj 很低 | 搜索有效,但推理不一致 |
Code
PPO 训练主流程(ray_trainer)
| 位置 | 改动 |
|---|---|
| 生成阶段(约 1137–1148) | config.ttrl.enable 为 True 时:用 n_votes_per_prompt 做多票采样;apply_ttrl_gt 用多数投票更新 batch 的 ground truth;select_top_k_per_prompt 从每 prompt 的 n 条里选前 k 条用于训练 |
| 更新阶段(约 1311–1319) | TTRL 开启时:apply_original_gt 恢复原始 GT;用 reward_fn 再算一遍得到 token_level_scores_original;compute_ttrl_metrics 算 TTRL 指标并写入 metrics(如 train/label_accuracy、train/reward_accuracy、train/majority_ratio 等) |
TTRL 工具与数学库
| 文件 | 作用 |
|---|---|
| verl/verl/trainer/ppo/ttrl_utils.py | select_top_k_per_prompt、apply_ttrl_gt、apply_original_gt、compute_ttrl_metrics,以及内部多数投票、指标计算 |
| verl/verl/utils/reward_score/ttrl_math/ | TTRL 用的数学判分:extract_answer、simplify_expression_string、grade、reward_func 等;被 ttrl_utils 和 custom_reward_function.path 使用 |
ttrl_math
数学答案评分和奖励计算的模块,用于评估模型解答是否正确并给出可用的 reward 信号。下面是各部分的作用概览:
- 数学答案自动评判:判断模型给出的数学答案是否与标准答案等价
- 高召回率设计:结合多种比较方式(数值、符号、LaTeX),尽量不误判正确答案
- 奖励函数接口:为强化学习(如 PPO)提供标量 reward 和结构化评分
__init__.py(主入口)
- extract_answer():从模型输出里提取 \boxed{...} 中的答案
- grade():用多种方式比较「模型答案 vs 标准答案」
- compute_score():计算最终分数,返回例如:
- score:是否答对(0/1)
- format_score:是否能正确解析 \boxed{}(1.0 表示格式正确)
- acc:是否判为正确
- pred / extracted_gt:提取出的预测与标准答案
- reward_func():供 RL 训练调用的 reward 接口
math_utils.py
- 答案提取:extract_boxed_answer 解析 \boxed{}
- 评判逻辑:
- grade_answer_mathd:MathQA 风格(含单位、数值等)
- grade_answer_sympy:基于 SymPy 的符号比较
- is_latex_equal:基于 math_verify 的 LaTeX 等价性判断
- 工具:timeout_ours 做超时保护,mathd_normalize_answer 做规范化
math_normalize.py
- 对答案做标准化(借鉴 Hendrycks 的 MATH / math_equivalence)
- 统一分数、单位、LaTeX 等格式,便于等价比较
cluster.py
- TTRLClusterCounter:按等价关系对答案聚类
- 将数学上等价的多种写法归为一类,用于统计或聚合不同形式的正确解
grader.py
- 封装具体的评分与比较逻辑,供上层调用
3. 在项目中的角色
从路径 verl/utils/reward_score/ttrl_math 可以看出,这个模块作为 reward/score 计算 的一部分,在数学题上的用途是:
- 从模型完整解答中抽取出最终答案
- 用多种等价性判断方式(数值、符号、LaTeX)给分
- 为 PPO 等 RL 训练提供 0/1 或标量 reward,并支持多选题/多答案格式(如 gt_answer 为列表)
- 在 reward_func 中统一处理异常并返回可用的 reward 值
| Role | 干嘛 |
|---|---|
| ActorRollout | 用当前 policy 生成 response |
| Critic | 估 value / advantage |
| RewardModel | 算 reward |
| RefPolicy | 算 KL reference |
ray_trainer.py
RayPPOTrainer.fit()
PPO/TTRL 的主循环, 你会看到:rollout → reward → advantage → update
-
谁来生成(Actor / Rollout)
-
谁来打分(Reward / Critic)
-
谁来约束(Ref policy + KL)
-
谁在哪块 GPU 上跑(Ray Resource Pool)
| Role | 干嘛的 |
|---|---|
| Actor | 被训练的策略(policy),要更新参数 |
| Rollout | 只负责生成(高吞吐,vLLM 风格) |
| ActorRollout | 👉 Actor + Rollout 合体版(最常用) |
| Critic | 价值函数 V(s),算 advantage(GAE 用) |
| RefPolicy | 冻结的参考模型,用来算 KL |
| RewardModel | 学习型 RM(不是 rule-based) |
ResourcePoolManager: GPU 分配
(1)Rollout / Generate
self.actor_rollout_wg.generate_sequences(...)
-
vLLM 生成 response
-
同时保留 logprob
(2)Reward / KL
compute_reward(...) apply_kl_penalty(...)
-
reward_fn 或 reward model 打分
-
ref_policy 算 KL
-
KL 被直接加进 token-level reward
👉 这是 TTRL / RLHF 防 collapse 的关键
(3)Advantage
compute_advantage(...)
-
GAE → 用 Critic
-
GRPO / RLOO → 不用 Critic
你看到这句就能判断是不是 actor-critic
| ttrl_utils.py 中的函数 | 在 ray_trainer.py 中的使用 |
|---|---|
| select_top_k_per_prompt | 第 1146 行:gen_batch_output = select_top_k_per_prompt(...) |
| apply_ttrl_gt | 第 1145 行:batch = apply_ttrl_gt(...) |
| apply_original_gt | 第 1313 行:batch = apply_original_gt(batch) |
| compute_ttrl_metrics | 第 1317 行:ttrl_metrics = compute_ttrl_metrics(...) |
🔥 第二优先(真正的梯度)
-
ActorRolloutRefWorker-
forward
-
loss 构造
-
optimizer.step
-
LoRA / policy 参数更新就在这里
-
🔥 第三优先(稳定性相关)
-
CriticWorker-
value loss
-
advantage 怎么算
-
collapse 是怎么被抑制的
-

开源鸿蒙跨平台开发社区汇聚开发者与厂商,共建“一次开发,多端部署”的开源生态,致力于降低跨端开发门槛,推动万物智联创新。
更多推荐
 18
18 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)