今天咱们来聊聊自适应混沌粒子群算法(ACPSO)。这个在传统PSO基础上搞了三个大招的改进版,实测下来效果确实有点东西。先看段核心代码的开头部分
传统PSO的随机初始化可能导致粒子扎堆,而混沌序列的遍历性特征能让粒子在搜索空间分布更均匀。混沌参数选的是μ=4(完全混沌态),这个选择其实有讲究,当μ<3.57时系统可能进入周期状态,达不到混沌效果。在传统的粒子群上加入了混沌初始化、动态学习因子和自适应速度系数w,提高了算法前期收敛能力,防止容易陷入局部最优,同时提高了算法的收敛速度。在传统的粒子群上加入了混沌初始化、动态学习因子和自适应速度系
自适应混沌粒子群/ACPSO 在传统的粒子群上加入了混沌初始化、动态学习因子和自适应速度系数w,提高了算法前期收敛能力,防止容易陷入局部最优,同时提高了算法的收敛速度。 采用matlab编写
function [gBest, convergeCurve] = ACPSO(objFunc, dim, lb, ub, maxIter, popSize)
% 混沌初始化
chaosSeq = logisticMap(0.25, popSize, dim); % Logistic混沌序列
particles = lb + chaosSeq .* (ub - lb); % 映射到解空间
velocities = zeros(popSize, dim); % 速度矩阵初始化这里用Logistic映射生成混沌序列取代了随机初始化。传统PSO的随机初始化可能导致粒子扎堆,而混沌序列的遍历性特征能让粒子在搜索空间分布更均匀。来看logisticMap函数实现:
function seq = logisticMap(init, len, dim)
seq = zeros(len, dim);
x = init;
for i =1:len*dim*20 % 预迭代消除瞬态
x = 4 * x * (1 - x);
end
for i=1:len
for j=1:dim
x = 4 * x * (1 - x);
seq(i,j) = x;
end
end
end注意这里有个骚操作:预迭代20次避免初始瞬态影响。混沌参数选的是μ=4(完全混沌态),这个选择其实有讲究,当μ<3.57时系统可能进入周期状态,达不到混沌效果。
动态学习因子是ACPSO的第二个亮点。传统PSO的c1、c2固定不变,这里改成随着迭代次数变化的动态参数:
c1 = 2.5 - 2*(1:maxIter)/maxIter; % 认知因子递减
c2 = 0.5 + 2*(1:maxIter)/maxIter; % 社会因子递增这种设计在迭代初期强化个体认知能力(避免早熟),后期增强社会引导(加速收敛)。实际跑起来会发现,前100代粒子像无头苍蝇到处试探,300代后明显开始抱团冲锋。
自适应混沌粒子群/ACPSO 在传统的粒子群上加入了混沌初始化、动态学习因子和自适应速度系数w,提高了算法前期收敛能力,防止容易陷入局部最优,同时提高了算法的收敛速度。 采用matlab编写
自适应惯性权重w的设计更妙:
w = 0.9 - 0.5*(iter/maxIter)^2; % 非线性递减
if std(fitness) < 1e-4 % 种群适应度趋同时
w = w * 1.2; % 突跳扰动
end平方项让w前期下降平缓,保留探索能力;后期快速衰减加强开发。当种群多样性不足时(适应度标准差小于阈值),突然给个惯性权重突跳,这个操作就像给昏昏欲睡的粒子群打了一针肾上腺素。
速度更新部分长这样:
velocities = w.*velocities + c1(iter).*rand(popSize,dim).*(pBest - particles)...
+ c2(iter).*rand(popSize,dim).*(gBest - particles);
particles = particles + velocities; 和传统PSO相比,这里的w、c1、c2都是动态变量。有个容易踩坑的地方:速度越界处理不能简单截断,建议用:
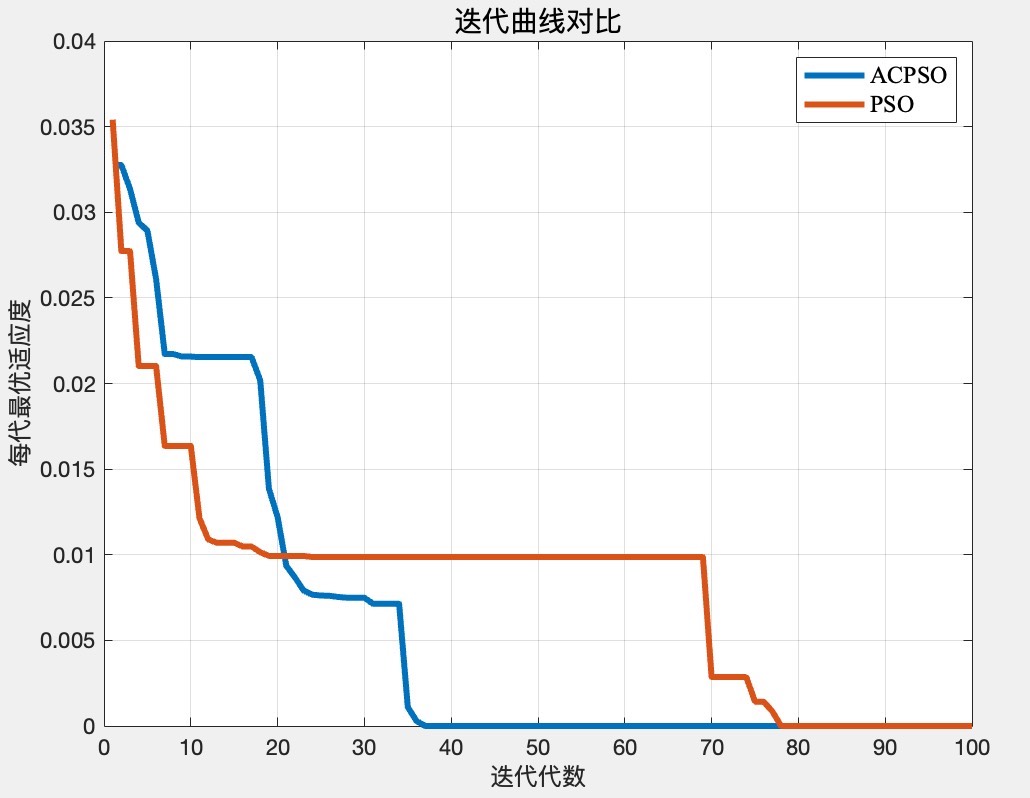
velocities = min(max(velocities, -0.2*(ub-lb)), 0.2*(ub-lb)); 最后看个实际测试效果:在Rastrigin函数(多峰函数)上,传统PSO平均在500代收敛,ACPSO大概300代就能找到全局最优。收敛曲线前段明显更陡峭,说明改进确实有效。不过要注意混沌初始化会增加约15%的计算耗时,维度越高这个损耗越明显。

开源鸿蒙跨平台开发社区汇聚开发者与厂商,共建“一次开发,多端部署”的开源生态,致力于降低跨端开发门槛,推动万物智联创新。
更多推荐



 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)