【深度好文】Agentic Tool Use RL 原生多轮工具调用训练范式
本文聚焦于单智能体式的**工具使用学习(Agentic Tool Use Learning)**,特别是以强化学习(RL)为核心的端到端范式。我们将系统剖析几项代表性工作,辨其思想,明其得失。我们的讨论**区别于主流基于提示词和软件工程构建的AI Agent**——其依赖大量人工设计的模块,而我们关注的是如何让模型通过与环境交互,**从经验中内生出规划与行动的能力**。
大语言模型(LLM)的本质,是其在海量文本上预训练后形成的“知识库”。然而,一个真正的智能体不应止步于“知”,更要力于“行”。它需要与环境交互,使用工具,在试错中积累具身经验(Embodied Experience)。这标志着我们对LLM角色的重新定位:从一个无所不知的“智者”,转变为一个能够解决实际问题的“行动者”。
本文聚焦于单智能体式的工具使用学习(Agentic Tool Use Learning),特别是以强化学习(RL)为核心的端到端范式。我们将系统剖析几项代表性工作,辨其思想,明其得失。
我们的讨论区别于主流基于提示词和软件工程构建的AI Agent——其依赖大量人工设计的模块,而我们关注的是如何让模型通过与环境交互,从经验中内生出规划与行动的能力。
监督下的工具模拟
早期的工作,核心思想是“模仿”。它们通过监督微调(SFT)或巧妙的提示工程,让LLM学会“在什么情况下,该调用什么API”。这为工具使用奠定了基础,但模型只是在复现数据中的行为,而非真正理解任务。
Toolformer: 让语言模型自学调用API
https://arxiv.org/abs/2302.04761
Toolformer 是这一时期的开创性工作。它构想了一种精巧的自监督方法,让LLM自行决定在文本的何处插入API调用,以更好地预测未来文本。
其核心思想可以概括为一个 “事后归因” 的过滤机制。对于一段文本 x = ( x 1 , . . . , x n ) x = (x_1, ..., x_n) x=(x1,...,xn),模型会尝试在不同位置 i i i生成候选的API调用 c c c。在执行并获得结果 r r r后,关键一步是判断这个调用是否有价值。
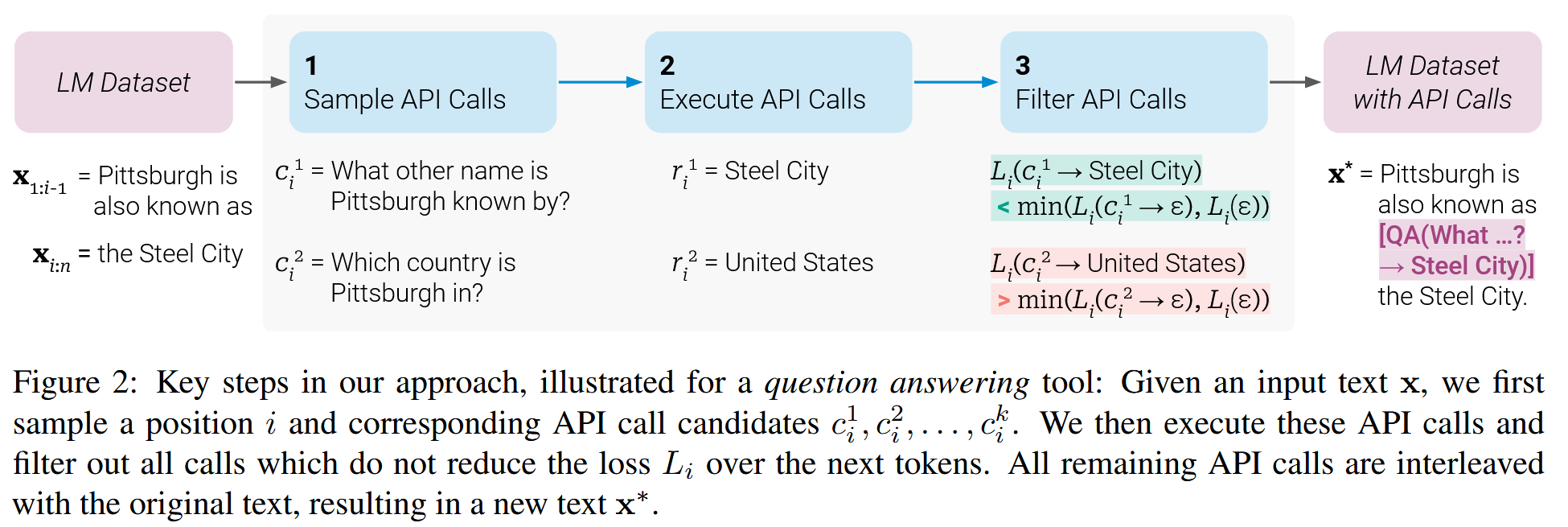
Toolformer的判断标准非常直接:插入API调用及其结果,是否显著降低了模型预测后续文本的困惑度?
我们可以用一个简化的损失函数来描述这个逻辑。假设 L ( z ) L(z) L(z)是模型在给定前缀 z z z后,预测后续文本 x i : n x_{i:n} xi:n的损失(例如交叉熵)。我们比较两种情况下的损失:
- L i + L_i^+ Li+: 在位置 i i i插入了API调用 c c c及其结果 r r r时的损失。
- L i − L_i^- Li−: 不插入任何调用,或者只插入了调用本身(没有结果)时的损失。
只有当收益足够大时,这个API调用才会被保留下来,用于微调模型:
( L i − − L i + ) > τ (L_i^- - L_i^+) > \tau (Li−−Li+)>τ
其中 τ \tau τ是一个预设的阈值。这个不等式精准地刻画了Toolformer自监督学习的精髓:一个好的工具调用,必须能让世界(后续文本)变得更加“可预测”。
Toolformer的巧妙之处在于,它将“学习使用工具”这个问题,转化为了一个“学习扩充文本以降低信息熵”的自监督任务,从而为模型生成了大量(输入, API调用, 输出)形式的训练数据。但其局限也同样明显:它只能模仿,无法在没有见过类似样本的情况下,进行多步、复杂的工具调用。
Search-o1: 免训练的智能体式检索
https://arxiv.org/abs/2501.05366
Search-o1 将这一思路推向了极致,把传统的检索增强生成(RAG)范式,升级为一种 “智能体式检索” 。其核心在于,模型不再被动地接收检索结果,而是主动决定 “何时搜、搜什么、搜几次” 。

这一切完全无需训练,仅依赖于LLM强大的上下文理解和推理能力。模型在生成推理步骤时,可以自主生成一个特殊的<query>标签和搜索查询。 这一过程可以形式化地理解为,在生成每个词元时,模型都在计算生成一个“搜索动作”的概率。
给定任务指令 I I I和问题 q q q,模型生成推理过程 R R R和最终答案 a a a的概率可以表示为:
P ( R , a ∣ I , q ) = ∏ t P ( token t ∣ I , q , context < t ) P(R, a | I, q) = \prod_{t} P(\text{token}_t | I, q, \text{context}_{<t}) P(R,a∣I,q)=t∏P(tokent∣I,q,context<t)Search-o1的精髓在于, context < t \text{context}_{<t} context<t是动态变化的。当模型在第 t t t步生成了<query>...<query/>,外部系统会执行搜索,并将结果 r final r_{\text{final}} rfinal注入到后续的上下文中。因此,后续的词元生成 P ( token t ′ ∣ . . . ) P(\text{token}_{t'} | ...) P(tokent′∣...)将以这个新知识为条件。
此外,它还设计了一个 “文档内推理” 模块,用LLM自身对检索回来的冗长文档进行“预处理”和“精炼”,提取核心信息后再注入主推理链,避免了信息过载。
Search-o1代表了 免训练(Training-free) 的顶峰,它巧妙地利用了LLM的现有能力。然而,其天花板也因此被基础模型的能力牢牢锁定,难以通过学习获得超越基础模型的新技能。
作为策略模型的语言模型
SFT和提示工程的本质是行为克隆,模型学习的是“在特定状态下执行特定动作的概率”,而非“为了达成某个目标应该执行什么动作序列”。要实现真正的目标导向,必须引入强化学习(RL)。
在RL范式中,LLM不再是文本生成器,而是一个策略模型(Policy Model) π θ \pi_{\theta} πθ。它与环境交互,通过获得的奖励(Reward)来更新自身参数 θ \theta θ,从而学习到最优的行为策略。
Search-R1: 将搜索视为与环境的交互
https://arxiv.org/abs/2503.09516
Search-R1 明确地将“使用搜索引擎”这一行为定义为一个RL问题。在这里:
- 智能体 (Agent): 语言模型 π θ \pi_{\theta} πθ。
- 环境 (Environment): 由用户问题 x x x、搜索引擎 R R R以及整个交互历史构成。
- 动作空间 (Action Space): 模型可以生成的特殊指令,如
<think>(思考)、<search>(搜索)、<answer>(回答)。 - 状态 (State): 包含了原始问题、历史思考链和所有搜索结果。
Search-R1为了引导初始 LLM 遵循预期的多轮交互格式,使用了一个简单的结构化模板prompt。这个模板仅规定了输出的基本结构 (思考-搜索-整合-回答的循环),而没有对内容本身做过多限制,以保证 LLM 在 RL 训练中能够自由探索和学习其内在的决策逻辑。

其优化目标是一个经典的策略梯度目标函数,并加入了KL散度正则项以防止策略漂移:
max θ E y ∼ π θ [ R ( y ) ] − β ⋅ D K L ( π θ ∣ ∣ π r e f ) \max_{\theta} \mathbb{E}_{y \sim \pi_{\theta}} [R(y)] - \beta \cdot D_{KL}(\pi_{\theta} || \pi_{ref}) θmaxEy∼πθ[R(y)]−β⋅DKL(πθ∣∣πref)
这个公式的含义是:我们希望最大化在当前策略 π θ \pi_{\theta} πθ下产生的行为轨迹 y y y所能获得的期望奖励 R ( y ) R(y) R(y),同时约束新的策略 π θ \pi_{\theta} πθ不要与原始的参考策略 π r e f \pi_{ref} πref偏离太远。
一个关键细节是检索内容损失掩码(Retrieved Token Masking)。在计算损失时,只计算模型自身生成内容(思考和最终答案)的损失,而忽略从搜索引擎返回内容的损失。 这一点至关重要,它确保了模型学习的是 “如何使用工具” 这一策略,而不是去记忆 “工具返回了什么知识” 。这也是RL阶段的训练思想,我们假设模型已经在预训练阶段习得了良好的语言理解和基本常识,所以只需要在RL阶段教会模型如何更好与环境交互。
ReSearch & R1-Searcher++: 奖励函数与课程学习的艺术
https://arxiv.org/abs/2503.19470
https://arxiv.org/abs/2505.17005
如果说Search-R1搭建了RL框架,那么同期的ReSearch 和R1-Searcher++ 则在“如何让RL更有效”上进行了深入探索,其核心在于奖励函数设计和课程学习。
ReSearch 设计了一个分层的奖励函数:
r = { F1 ( a p r e d , a g t ) , 若答案正确 (F1 > 0) 0.1 , 若答案错误但格式正确 0 , 若格式也错误 r = \begin{cases} \text{F1}(a_{pred}, a_{gt}), & \text{若答案正确 (F1 > 0)} \\ 0.1, & \text{若答案错误但格式正确} \\ 0, & \text{若格式也错误} \end{cases} r=⎩
⎨
⎧F1(apred,agt),0.1,0,若答案正确 (F1 > 0)若答案错误但格式正确若格式也错误
这种设计非常巧妙。在训练初期,模型很难直接输出正确答案,奖励信号会非常稀疏。通过给予“格式正确”一个小的正向奖励,它鼓励模型先学会“说人话”(遵循交互格式),再逐步学会“说对话”。
R1-Searcher++则将这一思想发展为分阶段学习:
- 行为塑形阶段: 只奖励“正确使用工具”和“遵循格式”,不关心答案对错。这类似于热身,让模型先掌握基本动作。
- 答案优化阶段: 引入答案准确性(如F1分数)作为主要奖励,引导模型利用已经掌握的工具技能去解决实际问题。
挑战与未来方向
尽管RL范式潜力巨大,同时一个客观事实是,目前这类端到端智能体在实用性上与精心设计的AI Agent仍有差距,但这恰恰是未来研究的广阔空间。
1. 学习的起点:如何迈出第一步?
RL的冷启动问题在LLM Agent中尤为突出。Search-R1依赖单样本示例模板,R1-Searcher采用SFT预热。一个良好的开端可能决定了RL训练的稳定性和上限,未来,是否有更高效更通用的预训练和启动方式是一个重要问题。
2. 奖励函数, 如何定义“好”的行为?
奖励函数的设计是RL的灵魂。目前多采用基于最终结果的稀疏奖励,但“过程”同样重要。如何设计更稠密的过程奖励(Process Reward),甚至引入LLM-as-a-Judge作为奖励模型,为轨迹的“质量”而非仅“结果”打分,同时如何缓解Reward hacking? 这是提升学习效率的关键。
3. 优化方法
传统的RL优化算法(REINFORCE, PPO, GRPO)在LLM Agent训练中面临稳定性、收敛效率等挑战。GiGPO旨在让LLM Agent实现细粒度信用分配。但未来还需要设计更符合Agent特性的RL优化算法。
4. 思考还是行动, 如何平衡?
如何让Agent在“内部思考”和“外部行动”(调用工具)间取得平衡是一大难题。简单地将工具调用次数作为优化目标并不能完美平衡,未来可能要探索例如"元学习"等,让Agent动态调整其思考-行动策略。
5. 样本与计算的效率
RL的“样本效率低下”是老生常谈。SkyRL-v0 聚焦于通过高效的异步架构和分布式环境来加速在真实软件环境中的 Rollout 过程。 而ZeroSearch尝试通过构建模拟环境来完全消除API调用成本,为解决数据获取昂贵的问题提供了新思路。 在优化算法层面。
6. 记忆与长序列的挑战
随着交互轮次增多,轨迹长度迅速膨胀,这不仅给有限的上下文窗口带来压力,也使得从冗长的历史中提取有效信息变得困难。
7. 微调的成本:如何让研究走向应用?
全参数RL训练成本高昂。Tina 的研究表明,利用LoRA这类 参数高效微调(PEFT) 技术,仅用极低的成本(如9美元)就能在小型模型上训练出强大的推理能力,这为RL Agent的普及提供了可能。
应用领域
目前Agentic Tool Use Learning的应用领域主要在搜索与代码执行和游戏等复杂度较低且可快速验证的领域:
RAG增强
Search-o1,Search-R1,ReSearch,R1-Searcher++,s3,ZeroSearch等工作专注于将工具使用能力融入到RAG中,提升知识获取和推理能力。
sunnynexus/Search-o1: Search-o1: Agentic Search-Enhanced Large Reasoning Models
[2503.19470] ReSearch: Learning to Reason with Search for LLMs via Reinforcement Learning
Web搜索
WebDancer和WebThinker则让LLM学会自主“上网冲浪”,进行深度和广度的信息搜索。
[2507.02592] WebSailor: Navigating Super-human Reasoning for Web Agent
WebDancer: Towards Autonomous Information Seeking Agency
数学推理与代码执行
ARTIST,START,ToRL,ReTool, 等工作推动了LLM在数学推理、代码执行领域的应用。
[2505.01441] Agentic Reasoning and Tool Integration for LLMs via Reinforcement Learning
[2503.04625] START: Self-taught Reasoner with Tools
[2503.23383] ToRL: Scaling Tool-Integrated RL
[2504.11536] ReTool: Reinforcement Learning for Strategic Tool Use in LLMs
游戏
RAGEN探索了LLM智能体在游戏环境中的自进化理解。
[2504.20073] RAGEN: Understanding Self-Evolution in LLM Agents via Multi-Turn Reinforcement Learning
Coumputer-using
SkyRL-v0,GUI-Actor,UI-R1则致力于让LLM学会计算机操作(Computer-using),包括命令行和图形用户界面(GUI)的交互。
[2503.21620] UI-R1: Enhancing Efficient Action Prediction of GUI Agents by Reinforcement Learning
[2506.03143] GUI-Actor: Coordinate-Free Visual Grounding for GUI Agents
训练框架
为了支持复杂Agent的训练,需要更成熟的训练框架。出了相关论文开源的训练框架,也出现了一些专用的Agentic RL训练和微调框架。
Simple-Efficient/RL-Factory: Train your Agent model via our easy and efficient framework
GitHub - inclusionAI/AReaL: Distributed RL System for LLM Reasoning
GitHub - hiyouga/LLaMA-Factory: Unified Efficient Fine-Tuning of 100+ LLMs & VLMs (ACL 2024)
GitHub - NovaSky-AI/SkyRL: SkyRL: A Modular Full-stack RL Library for LLMs
结语
从Toolformer的模仿学习,到Search-R1的策略学习,我们看到了一条清晰的演进路径:智能体正从一个被动的“知识库”和“模仿者”,逐渐成长为一个主动的、有目标的“行动者”。尽管挑战重重,但将LLM作为策略模型,通过与环境的真实交互来学习如何行动,无疑是通往更通用人工智能的必由之路。

开源鸿蒙跨平台开发社区汇聚开发者与厂商,共建“一次开发,多端部署”的开源生态,致力于降低跨端开发门槛,推动万物智联创新。
更多推荐
 28
28 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)