基于CRNN的音频分类项目实战源码包
在PyTorch中,可以通过继承nn.Module类来自定义CRNN模型。以下是一个完整的CRNN模型实现示例:return x参数说明:: CNN输入通道数。: RNN输入维度,通常等于CNN输出通道数乘以高度。: LSTM隐藏层维度。: 分类任务的类别总数。在PyTorch中,可以使用nn.LSTM模块来定义LSTM层。其参数包括输入维度、隐藏层大小、层数、是否双向等。

简介:”torchaudio-contrib-master.zip” 是一个基于 PyTorch 和 torchaudio 的音频处理开源项目资源包,来源于 GitHub 上的 CRNN 音频分类项目。该项目结合卷积神经网络(CNN)与循环神经网络(RNN),实现对音频数据的智能分类,如人声、乐器声、动物声音等。项目涵盖完整的音频预处理、特征提取、模型构建、训练优化与评估流程,使用了 MFCC、LSTM、数据增强等关键技术,适合音频处理与深度学习方向的研究和实践。 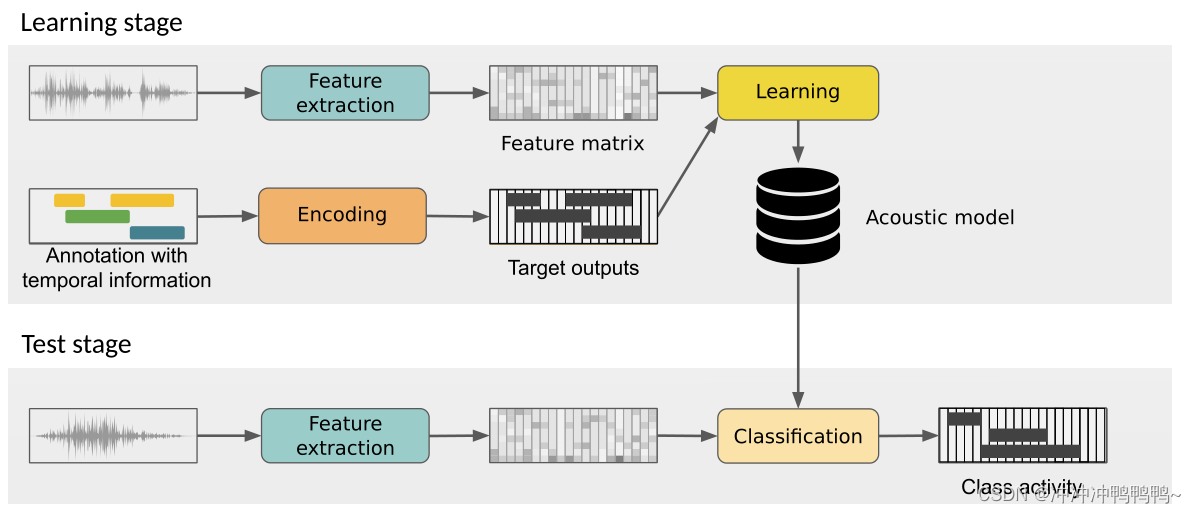
1. Torchaudio音频处理库应用
音频数据的高效处理是构建现代语音与音频系统的基础。Torchaudio 作为 PyTorch 生态中专门处理音频的库,提供了从音频加载、变换、特征提取到格式转换的一整套工具链,极大简化了深度学习在音频领域的应用开发流程。
本章将从音频数据的加载与保存入手,介绍如何使用 torchaudio.load 和 torchaudio.save 函数处理常见音频格式(如 WAV、MP3),并通过示例展示如何读取音频张量和采样率。随后,我们将讲解音频信号的基本操作,如声道转换、重采样、音量归一化等,并演示如何将音频数据转换为模型可接受的张量格式。
此外,还将介绍如何借助 Torchaudio 实现音频信号的可视化(如波形图与频谱图绘制)以及特征的初步提取(如梅尔频谱、MFCC 等),为后续章节中构建音频分类和识别模型奠定基础。
2. CRNN模型结构原理与实现
2.1 CRNN模型的基本构成
2.1.1 卷积层与特征提取
卷积神经网络(CNN)在图像识别和语音处理领域表现出色,其核心在于通过卷积操作提取局部特征。在CRNN(Convolutional Recurrent Neural Network)结构中,CNN层通常位于模型的前端,用于从原始输入数据(如音频频谱图或图像序列)中提取高维特征。这些特征通常以二维或三维张量的形式输出,作为RNN层的输入。
例如,对于音频分类任务,输入通常是一个频谱图(如梅尔频谱图),CNN层会逐层提取出频率和时间维度上的局部模式。以下是一个典型的CNN层实现代码:
import torch
import torch.nn as nn
class CNNBlock(nn.Module):
def __init__(self, in_channels, out_channels):
super(CNNBlock, self).__init__()
self.conv = nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=1, padding=1)
self.bn = nn.BatchNorm2d(out_channels)
self.relu = nn.ReLU()
def forward(self, x):
x = self.conv(x)
x = self.bn(x)
x = self.relu(x)
return x
代码逻辑分析:
nn.Conv2d是二维卷积层,输入通道in_channels,输出通道out_channels,卷积核大小为3x3,padding=1 保证输出尺寸与输入一致。nn.BatchNorm2d对卷积输出进行批量归一化,有助于加快训练速度并提高泛化能力。nn.ReLU是非线性激活函数,使得模型能够学习更复杂的特征表示。
参数说明:
in_channels: 输入通道数,如对于RGB图像为3,对于单通道频谱图为1。out_channels: 输出通道数,通常随着网络深度增加而增加,如从32逐步增加到128。kernel_size: 卷积核大小,决定感受野范围。stride: 步长,控制卷积滑动的间隔。padding: 填充,防止特征图尺寸缩小。
2.1.2 循环层与序列建模
在CNN层之后,CRNN模型通常会使用一个或多个RNN层来处理时间序列数据。与CNN不同,RNN能够捕捉序列中元素之间的依赖关系,特别适合处理语音、文本等时序数据。
在PyTorch中,可以使用 nn.LSTM 或 nn.GRU 来实现循环层。下面是一个使用LSTM的示例:
class RNNBlock(nn.Module):
def __init__(self, input_size, hidden_size, num_layers=1):
super(RNNBlock, self).__init__()
self.lstm = nn.LSTM(input_size, hidden_size, num_layers=num_layers, bidirectional=True)
def forward(self, x):
# x shape: (seq_len, batch_size, input_size)
x, _ = self.lstm(x)
return x
代码逻辑分析:
input_size是输入特征的维度,通常来自CNN层的输出通道数。hidden_size是LSTM隐藏层的维度,决定了模型记忆容量。bidirectional=True表示使用双向LSTM,能够同时考虑过去和未来的上下文信息。- 输出
x的形状为(seq_len, batch_size, hidden_size * 2)(双向)。
参数说明:
input_size: 每个时间步输入的特征维度。hidden_size: LSTM隐藏层单元数。num_layers: LSTM层数,堆叠多个LSTM可增强模型的表达能力。bidirectional: 是否使用双向LSTM。
2.1.3 全连接层与输出预测
在CNN和RNN之后,通常会接一个全连接层(Fully Connected Layer)进行最终的分类或回归任务。全连接层将RNN输出的序列信息映射到最终的输出空间(如类别数)。
class FCBlock(nn.Module):
def __init__(self, input_size, output_size):
super(FCBlock, self).__init__()
self.fc = nn.Linear(input_size, output_size)
def forward(self, x):
# x shape: (seq_len, batch_size, input_size)
batch_size, seq_len, _ = x.size()
x = x.view(-1, x.size(2)) # (batch_size * seq_len, input_size)
x = self.fc(x)
x = x.view(batch_size, seq_len, -1) # (batch_size, seq_len, output_size)
return x
代码逻辑分析:
x.view(-1, x.size(2))将输入展平为二维张量,以便输入到线性层。self.fc是全连接层,将输入特征映射到输出类别数。- 最终结果重新恢复为三维张量,便于后续处理(如CTC损失)。
参数说明:
input_size: 来自RNN层的输出维度。output_size: 最终输出的类别数或目标维度。
2.2 CRNN的数学原理与前向传播
2.2.1 CNN与RNN的融合机制
CRNN模型的精髓在于CNN与RNN的有机融合。CNN负责提取空间特征,RNN负责建模时间依赖关系,二者结合可以有效处理具有时空结构的数据。例如,在语音识别中,CNN可以提取频谱图中的频率特征,而RNN则建模音素之间的时序关系。
数学上,CNN的输出可以视为一个时间序列的特征表示。设输入为 $X \in \mathbb{R}^{T \times D}$,其中 $T$ 是时间步数,$D$ 是每个时间步的特征维度。CNN对 $X$ 进行卷积操作后得到:
H^{CNN} = f_{CNN}(X)
随后,RNN层对 $H^{CNN}$ 进行建模:
H^{RNN} = f_{RNN}(H^{CNN})
其中 $f_{CNN}$ 和 $f_{RNN}$ 分别表示CNN和RNN的映射函数。
2.2.2 时间序列特征的整合方式
CRNN中时间序列的整合主要依赖RNN结构。以LSTM为例,其核心是门控机制,包括输入门、遗忘门和输出门,能够控制信息的流动和记忆。
LSTM在每个时间步 $t$ 的计算公式如下:
\begin{aligned}
i_t &= \sigma(W_i \cdot [h_{t-1}, x_t] + b_i) \
f_t &= \sigma(W_f \cdot [h_{t-1}, x_t] + b_f) \
o_t &= \sigma(W_o \cdot [h_{t-1}, x_t] + b_o) \
\tilde{C} t &= \tanh(W_C \cdot [h {t-1}, x_t] + b_C) \
C_t &= f_t \odot C_{t-1} + i_t \odot \tilde{C}_t \
h_t &= o_t \odot \tanh(C_t)
\end{aligned}
其中 $\sigma$ 是sigmoid函数,$\odot$ 是逐元素乘法。
2.2.3 损失函数与梯度传播路径
CRNN模型的训练通常采用交叉熵损失函数(Cross-Entropy Loss),用于分类任务。损失函数定义为:
L = -\sum_{i=1}^N y_i \log(\hat{y}_i)
其中 $y_i$ 是真实标签,$\hat{y}_i$ 是模型预测的概率。
在反向传播过程中,梯度从损失函数逐层回传至CNN和RNN层。由于RNN存在梯度消失问题,通常采用梯度裁剪(Gradient Clipping)技术防止梯度爆炸。
2.3 PyTorch中CRNN模型的实现步骤
2.3.1 模型定义与参数配置
在PyTorch中,可以通过继承 nn.Module 类来自定义CRNN模型。以下是一个完整的CRNN模型实现示例:
class CRNNModel(nn.Module):
def __init__(self, cnn_input_channels, rnn_input_size, hidden_size, num_classes):
super(CRNNModel, self).__init__()
self.cnn = nn.Sequential(
CNNBlock(cnn_input_channels, 32),
nn.MaxPool2d(2, 2),
CNNBlock(32, 64),
nn.MaxPool2d(2, 2)
)
self.rnn = RNNBlock(rnn_input_size, hidden_size)
self.fc = FCBlock(hidden_size * 2, num_classes)
def forward(self, x):
# x shape: (batch_size, channels, height, width)
x = self.cnn(x) # (batch_size, out_channels, new_height, new_width)
batch_size, c, h, w = x.size()
x = x.view(batch_size, c * h, w) # (batch_size, feature_dim, time_steps)
x = x.permute(2, 0, 1) # (time_steps, batch_size, feature_dim)
x = self.rnn(x)
x = self.fc(x)
return x
参数说明:
cnn_input_channels: CNN输入通道数。rnn_input_size: RNN输入维度,通常等于CNN输出通道数乘以高度。hidden_size: LSTM隐藏层维度。num_classes: 分类任务的类别总数。
2.3.2 数据输入与模型训练流程
CRNN模型的训练流程包括数据预处理、模型前向传播、损失计算、反向传播和参数更新。以下是训练流程的伪代码:
for epoch in range(num_epochs):
for batch in train_loader:
inputs, targets = batch
inputs = inputs.to(device)
targets = targets.to(device)
outputs = model(inputs)
loss = criterion(outputs, targets)
optimizer.zero_grad()
loss.backward()
optimizer.step()
其中 criterion 通常是 nn.CrossEntropyLoss() , optimizer 可以是 torch.optim.Adam() 。
2.3.3 模型验证与保存策略
在训练过程中,每经过一定轮次(epoch)后,应进行模型验证以评估其性能。验证集上的准确率和损失可以帮助判断模型是否过拟合或欠拟合。
以下是一个简单的模型保存策略:
best_loss = float('inf')
for epoch in range(num_epochs):
# Training
model.train()
for inputs, targets in train_loader:
...
# Validation
model.eval()
with torch.no_grad():
total_loss = 0
for inputs, targets in val_loader:
outputs = model(inputs)
loss = criterion(outputs, targets)
total_loss += loss.item()
avg_loss = total_loss / len(val_loader)
if avg_loss < best_loss:
best_loss = avg_loss
torch.save(model.state_dict(), 'best_model.pth')
该策略会保存验证损失最小的模型权重,避免模型过拟合训练数据。
本章内容深入剖析了CRNN模型的结构原理与实现方式,涵盖CNN特征提取、RNN序列建模以及PyTorch中的具体实现细节。通过本章学习,读者将掌握构建和训练CRNN模型的核心方法,并为后续音频分类任务打下坚实基础。
3. 卷积神经网络(CNN)音频特征提取
卷积神经网络(Convolutional Neural Network, CNN)在图像识别领域取得了巨大成功,近年来也被广泛应用于音频处理任务中。通过将音频信号转化为图像形式的二维表示(如频谱图、梅尔频谱图),CNN可以高效地提取局部特征,并通过多层堆叠构建层次化特征表达。本章将深入探讨CNN在音频处理中的核心原理、音频信号的二维表示方法,以及基于CNN的音频特征提取实战技巧。
3.1 卷积神经网络的基本原理
CNN的核心在于其局部感知和参数共享机制,使其能够高效地提取图像或图像化信号中的局部特征。
3.1.1 卷积核与特征图的生成
卷积操作是CNN中最基础的操作,它通过一个可学习的小型滤波器(即卷积核)在输入信号上滑动,计算局部区域的加权和,从而生成特征图(Feature Map)。在音频处理中,卷积核通常在频谱图的二维空间上滑动,提取频域和时间域的局部特征。
import torch
import torch.nn as nn
# 定义一个简单的卷积层
conv_layer = nn.Conv2d(in_channels=1, out_channels=16, kernel_size=(3, 3), stride=1, padding=1)
# 输入是一个模拟的梅尔频谱图(batch_size=1, channel=1, height=128, width=256)
input_spectrogram = torch.randn(1, 1, 128, 256)
# 执行卷积操作
output_features = conv_layer(input_spectrogram)
print(output_features.shape) # 输出:torch.Size([1, 16, 128, 256])
逐行分析:
- 第1~2行:导入必要的PyTorch模块。
- 第5行:定义一个二维卷积层,输入通道为1(单通道频谱图),输出通道为16(即生成16张特征图),卷积核大小为3x3,填充为1,确保输出尺寸与输入一致。
- 第8行:构造一个模拟输入张量,表示一个梅尔频谱图。
- 第11行:执行卷积操作,输出形状为 (batch_size, out_channels, height, width) ,即每个通道代表一个特征图。
3.1.2 激活函数与池化操作
在卷积之后通常接一个非线性激活函数(如ReLU)以增强模型的非线性表达能力,随后使用池化层(如最大池化)来压缩特征图的尺寸,减少计算量并提升平移不变性。
# 添加ReLU激活函数与最大池化层
relu = nn.ReLU()
max_pool = nn.MaxPool2d(kernel_size=(2, 2), stride=2)
# 应用激活与池化
activated_features = relu(output_features)
pooled_features = max_pool(activated_features)
print(pooled_features.shape) # 输出:torch.Size([1, 16, 64, 128])
逐行分析:
- 第4行:应用ReLU激活函数,保留正数部分,增强非线性。
- 第5行:使用最大池化层,将特征图尺寸缩小为原来的一半。
- 第7行:输出结果的尺寸为 (1, 16, 64, 128) ,其中高度和宽度均被压缩。
3.1.3 多层卷积堆叠的优势
通过堆叠多个卷积层,CNN可以构建深层网络结构,从而学习更抽象的高阶特征。例如,浅层卷积可能检测边缘和局部频率特征,而深层卷积则可以捕捉更复杂的语义特征。
# 构建多层卷积模块
class MultiConvBlock(nn.Module):
def __init__(self):
super(MultiConvBlock, self).__init__()
self.conv1 = nn.Conv2d(1, 16, kernel_size=(3,3), padding=1)
self.conv2 = nn.Conv2d(16, 32, kernel_size=(3,3), padding=1)
self.relu = nn.ReLU()
self.pool = nn.MaxPool2d(2, 2)
def forward(self, x):
x = self.pool(self.relu(self.conv1(x)))
x = self.pool(self.relu(self.conv2(x)))
return x
model = MultiConvBlock()
output = model(input_spectrogram)
print(output.shape) # 输出:torch.Size([1, 32, 32, 64])
逐行分析:
- 第5~11行:定义了一个包含两个卷积层的模块,每层后接ReLU激活和最大池化。
- 第14行:输入通过该模块后,最终输出的特征图数量为32,尺寸为32x64。
- 优势说明: 每层提取不同级别的特征,形成层次化表示,提升模型对复杂音频结构的建模能力。
3.2 音频信号的二维表示方法
音频信号本质上是一维的时间序列,但在CNN处理中,通常将其转化为二维图像形式,以便更好地利用CNN的局部感受野和空间特征提取能力。
3.2.1 频谱图与梅尔频谱图
频谱图(Spectrogram) 是将音频信号通过短时傅里叶变换(STFT)转换为时间和频率两个维度的图像表示。
import torchaudio
# 加载音频文件
waveform, sample_rate = torchaudio.load("example_audio.wav")
# 生成频谱图
spectrogram_transform = torchaudio.transforms.Spectrogram(n_fft=512, hop_length=256)
spectrogram = spectrogram_transform(waveform)
print(spectrogram.shape) # 输出:(1, 257, time_steps)
逐行分析:
- 第4行:加载一个音频文件,得到波形和采样率。
- 第7行:使用 Spectrogram 变换生成频谱图, n_fft=512 表示使用512点FFT。
- 第9行:输出张量形状为 (channel, frequency_bins, time_steps) ,表示频谱图。
梅尔频谱图(Mel Spectrogram) 是一种更接近人耳听觉感知的频谱表示方式,通过将频谱映射到梅尔刻度上,减少高频部分的分辨率。
# 生成梅尔频谱图
mel_spectrogram_transform = torchaudio.transforms.MelSpectrogram(
sample_rate=sample_rate, n_fft=512, hop_length=256, n_mels=128
)
mel_spectrogram = mel_spectrogram_transform(waveform)
print(mel_spectrogram.shape) # 输出:(1, 128, time_steps)
参数说明:
- n_mels=128 :梅尔滤波器组数量,控制频谱图的频率分辨率。
- 优势: 更符合人耳感知,适合用于语音识别和音频分类任务。
3.2.2 时频分析的实现方式
时频分析是将音频信号从时间域转换为时间-频率域的过程,常用方法包括短时傅里叶变换(STFT)、梅尔频谱变换、CQT(恒Q变换)等。
| 方法 | 特点描述 | 适用场景 |
|---|---|---|
| STFT | 固定窗口大小,适用于平稳信号 | 通用音频分析 |
| 梅尔频谱变换 | 映射到人耳感知频段,降低高频分辨率 | 语音识别、音乐分类 |
| CQT | 可变窗口大小,适合非平稳信号 | 乐器识别、音频事件检测 |
流程图:
graph TD
A[原始音频信号] --> B[短时傅里叶变换]
B --> C[生成频谱图]
C --> D{是否映射到梅尔刻度?}
D -->|是| E[梅尔频谱图]
D -->|否| F[普通频谱图]
E --> G[用于CNN特征提取]
F --> G
3.2.3 特征图的归一化与增强
为了提高模型泛化能力,通常对生成的频谱图进行归一化处理,如对数变换和标准化:
# 对数变换与标准化
log_mel = torch.log(mel_spectrogram + 1e-6)
mean = log_mel.mean()
std = log_mel.std()
normalized_mel = (log_mel - mean) / (std + 1e-6)
逐行分析:
- 第2行:对梅尔频谱图取对数,增强低能量区域的可见性。
- 第3~4行:计算均值与标准差。
- 第5行:进行标准化处理,使得输入数据分布更加稳定。
3.3 基于CNN的音频特征提取实战
在本节中,我们将结合PyTorch与Torchaudio,构建一个完整的CNN模型,用于音频特征提取,并可视化提取的特征。
3.3.1 构建CNN模型架构
我们构建一个轻量级CNN模型,包含卷积层、池化层和全连接层,用于音频特征提取。
import torch.nn as nn
class AudioCNN(nn.Module):
def __init__(self, num_classes=10):
super(AudioCNN, self).__init__()
self.features = nn.Sequential(
nn.Conv2d(1, 16, kernel_size=(3,3), padding=1),
nn.ReLU(),
nn.MaxPool2d(2, 2),
nn.Conv2d(16, 32, kernel_size=(3,3), padding=1),
nn.ReLU(),
nn.MaxPool2d(2, 2),
nn.Conv2d(32, 64, kernel_size=(3,3), padding=1),
nn.ReLU(),
nn.MaxPool2d(2, 2)
)
self.classifier = nn.Sequential(
nn.AdaptiveAvgPool2d((1,1)),
nn.Flatten(),
nn.Linear(64, num_classes)
)
def forward(self, x):
features = self.features(x)
output = self.classifier(features)
return output, features
逐行分析:
- 第5~14行:构建特征提取层,包含三层卷积+ReLU+池化。
- 第15~19行:分类层,使用自适应平均池化将特征图压缩为1x1,然后全连接层输出分类结果。
- 功能扩展: 模型返回两个值:分类输出与中间特征图,可用于特征可视化。
3.3.2 输入数据的预处理与封装
使用Torchaudio进行数据预处理,包括加载音频、转换为梅尔频谱图、归一化等。
from torch.utils.data import Dataset, DataLoader
import torchaudio
class AudioDataset(Dataset):
def __init__(self, file_paths, labels, sample_rate=16000, n_mels=128):
self.file_paths = file_paths
self.labels = labels
self.sample_rate = sample_rate
self.transform = torchaudio.transforms.MelSpectrogram(
sample_rate=sample_rate, n_fft=512, hop_length=256, n_mels=n_mels
)
def __len__(self):
return len(self.file_paths)
def __getitem__(self, idx):
waveform, sr = torchaudio.load(self.file_paths[idx])
if sr != self.sample_rate:
waveform = torchaudio.transforms.Resample(orig_freq=sr, new_freq=self.sample_rate)(waveform)
mel = self.transform(waveform)
mel = torch.log(mel + 1e-6)
return mel, self.labels[idx]
逐行分析:
- 第5~11行:定义一个自定义音频数据集类,继承 Dataset 。
- 第13~18行:实现 __getitem__ 方法,加载音频并转换为梅尔频谱图,进行对数变换。
- 优势: 数据封装后可直接用于PyTorch DataLoader,实现批量训练。
3.3.3 特征向量的提取与可视化
训练模型后,我们可以提取中间特征图并进行可视化。
import matplotlib.pyplot as plt
# 假设模型已训练并传入一个测试样本
model.eval()
with torch.no_grad():
input_mel = normalized_mel.unsqueeze(0) # 增加batch维度
output, features = model(input_mel)
# 可视化第一个特征图
feature_map = features[0, 0].cpu().numpy()
plt.imshow(feature_map, cmap='viridis', aspect='auto')
plt.colorbar()
plt.title("Feature Map Visualization")
plt.show()
逐行分析:
- 第5行:将输入张量增加batch维度。
- 第7行:获取模型输出及中间特征。
- 第10~14行:使用Matplotlib将第一个通道的特征图可视化。
- 结果说明: 不同颜色表示不同强度的激活区域,可帮助理解CNN在音频频谱图上关注的局部特征。
本章系统介绍了卷积神经网络在音频处理中的基本原理、音频信号的二维表示方法以及基于CNN的音频特征提取实战技巧。通过构建完整的音频特征提取流程,我们不仅掌握了CNN模型的搭建与训练方法,还实现了音频特征的可视化分析,为后续音频分类任务奠定了坚实基础。
4. 循环神经网络(RNN/LSTM)序列建模
在音频处理领域,尤其是语音识别、音频分类和多模态建模任务中,音频信号本质上是一种时间序列数据。为了有效捕捉音频数据中的时序依赖关系,RNN(Recurrent Neural Network)和LSTM(Long Short-Term Memory)成为关键建模工具。本章将深入解析RNN与LSTM的基本原理,分析其在音频序列建模中的典型应用场景,并通过PyTorch框架展示其具体实现技巧。
4.1 RNN与LSTM的基本原理
4.1.1 RNN的结构与局限性
RNN 是最早用于处理序列数据的神经网络结构。其核心思想是引入循环结构,使得当前时刻的隐藏状态(hidden state)不仅依赖于当前输入,还依赖于前一时刻的隐藏状态。这种设计允许模型在处理序列数据时保持“记忆”,从而捕捉时间依赖关系。
标准RNN的数学表示如下:
h_t = \tanh(W_{hh} h_{t-1} + W_{xh} x_t)
其中:
- $ h_t $:第 t 个时间步的隐藏状态;
- $ x_t $:第 t 个时间步的输入;
- $ W_{hh} $:隐藏层到隐藏层的权重矩阵;
- $ W_{xh} $:输入到隐藏层的权重矩阵。
虽然RNN理论上可以处理任意长度的序列,但其存在 梯度消失 和 梯度爆炸 的问题,导致难以学习长期依赖关系。这在音频处理任务中尤为明显,例如语音识别中需要识别整句话的上下文信息。
4.1.2 LSTM的门控机制与长期记忆
LSTM 是对RNN结构的改进版本,引入了 门控机制 来控制信息的流动,从而缓解梯度消失问题。LSTM的核心组件包括三个门控单元:输入门(input gate)、遗忘门(forget gate)和输出门(output gate),以及一个 记忆单元 (cell state)。
LSTM的计算公式如下:
\begin{align }
f_t &= \sigma(W_f \cdot [h_{t-1}, x_t] + b_f) \
i_t &= \sigma(W_i \cdot [h_{t-1}, x_t] + b_i) \
\tilde{C} t &= \tanh(W_C \cdot [h {t-1}, x_t] + b_C) \
C_t &= f_t \odot C_{t-1} + i_t \odot \tilde{C} t \
o_t &= \sigma(W_o \cdot [h {t-1}, x_t] + b_o) \
h_t &= o_t \odot \tanh(C_t)
\end{align }
其中:
- $ f_t $:遗忘门,决定哪些信息被遗忘;
- $ i_t $:输入门,决定哪些新信息被存储;
- $ C_t $:记忆单元;
- $ o_t $:输出门,决定输出哪些信息;
- $ \sigma $:Sigmoid激活函数;
- $ \odot $:逐元素乘法。
通过这种结构,LSTM能够有效地学习长期依赖关系,使其在音频序列建模任务中表现出色。
4.1.3 GRU与LSTM的对比分析
GRU(Gated Recurrent Unit)是LSTM的简化版本,将输入门和遗忘门合并为一个更新门(update gate),并引入一个重置门(reset gate)来控制信息的传递。其数学公式如下:
\begin{align }
z_t &= \sigma(W_z \cdot [h_{t-1}, x_t]) \
r_t &= \sigma(W_r \cdot [h_{t-1}, x_t]) \
\tilde{h} t &= \tanh(W \cdot [r_t \odot h {t-1}, x_t]) \
h_t &= (1 - z_t) \odot h_{t-1} + z_t \odot \tilde{h}_t
\end{align }
| 特性 | LSTM | GRU |
|---|---|---|
| 记忆单元 | 有 | 无 |
| 门控数量 | 3个 | 2个 |
| 参数数量 | 较多 | 较少 |
| 计算复杂度 | 高 | 低 |
| 适用场景 | 长期依赖 | 中短期依赖 |
GRU在模型复杂度和训练效率方面具有优势,而LSTM更适合需要长期记忆的音频建模任务。在实际应用中,需根据任务特性选择合适的模型。
4.2 音频序列建模的典型应用
4.2.1 语音识别中的序列建模
在语音识别任务中,音频信号通常被转换为文本序列。RNN/LSTM可以用于建模音频特征序列(如MFCC、梅尔频谱图等)与文本之间的对齐关系。例如,CTC(Connectionist Temporal Classification)损失函数与LSTM结合,可有效处理输入输出序列长度不一致的问题。
4.2.2 音频分类中的时序信息建模
音频分类任务中,如音乐流派识别、语音情绪分析等,需要模型捕捉音频信号的时序特征。LSTM能够从音频特征序列中提取动态特征,提升分类性能。例如,在处理音频频谱图时,将每一帧频谱作为时间步输入LSTM,从而建模整个音频的语义信息。
4.2.3 多模态音频序列建模方法
在多模态任务中,如视频语音识别或音频-文本联合理解,音频与文本、图像等其他模态的信息需要联合建模。RNN/LSTM可以作为序列建模模块,与CNN、Transformer等结构结合,实现跨模态信息融合。例如,使用CNN提取音频特征,再由LSTM进行时序建模,最终与其他模态的信息进行融合预测。
4.3 RNN/LSTM在PyTorch中的实现技巧
4.3.1 数据的序列化与批处理
在PyTorch中,音频数据通常以张量形式表示。为了适配RNN/LSTM的输入格式,需将音频特征数据组织为时间序列格式,即 (sequence_length, batch_size, input_size) 。
import torch
from torch.utils.data import DataLoader, Dataset
class AudioDataset(Dataset):
def __init__(self, features, labels):
self.features = features # shape: [num_samples, sequence_length, feature_dim]
self.labels = labels
def __len__(self):
return len(self.features)
def __getitem__(self, idx):
return self.features[idx], self.labels[idx]
# 假设特征为 shape: [N, T, F]
features = torch.randn(1000, 100, 40) # N: 样本数, T: 时间步数, F: 特征维度
labels = torch.randint(0, 10, (1000,))
dataset = AudioDataset(features, labels)
dataloader = DataLoader(dataset, batch_size=32, shuffle=True)
逐行解释:
- features :音频特征张量,形状为 [样本数, 时间步数, 特征维度] 。
- __getitem__ :返回一个样本的特征和标签。
- DataLoader :自动进行批处理,支持并行加载。
4.3.2 LSTM层的定义与参数设置
在PyTorch中,可以使用 nn.LSTM 模块来定义LSTM层。其参数包括输入维度、隐藏层大小、层数、是否双向等。
import torch.nn as nn
class AudioLSTM(nn.Module):
def __init__(self, input_dim, hidden_dim, num_layers, num_classes, bidirectional=False):
super(AudioLSTM, self).__init__()
self.lstm = nn.LSTM(input_dim, hidden_dim, num_layers,
bidirectional=bidirectional,
batch_first=False) # 输入格式为 (seq_len, batch, input_size)
self.fc = nn.Linear(hidden_dim * (2 if bidirectional else 1), num_classes)
def forward(self, x):
# x shape: (seq_len, batch_size, input_dim)
out, _ = self.lstm(x)
# 取最后一个时间步的输出
out = self.fc(out[-1])
return out
# 实例化模型
model = AudioLSTM(input_dim=40, hidden_dim=128, num_layers=2, num_classes=10, bidirectional=True)
逐行解释:
- input_dim=40 :输入特征维度(如MFCC维数)。
- hidden_dim=128 :LSTM隐藏层大小。
- num_layers=2 :LSTM堆叠层数。
- bidirectional=True :是否使用双向LSTM。
- out[-1] :取最后一个时间步的输出作为最终表示。
4.3.3 训练过程中的优化与监控
在训练过程中,可使用交叉熵损失函数与Adam优化器,并结合学习率调度器进行动态调整。同时,建议使用TensorBoard或Wandb进行训练监控。
import torch.optim as optim
from torch.utils.tensorboard import SummaryWriter
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
scheduler = optim.lr_scheduler.ReduceLROnPlateau(optimizer, 'min', patience=3)
writer = SummaryWriter('runs/audio_lstm')
for epoch in range(10):
model.train()
for i, (inputs, labels) in enumerate(dataloader):
inputs = inputs.transpose(0, 1) # 转换为 (seq_len, batch_size, input_dim)
outputs = model(inputs)
loss = criterion(outputs, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
writer.add_scalar('training loss', loss.item(), epoch * len(dataloader) + i)
# 验证集评估
model.eval()
with torch.no_grad():
val_loss = ...
scheduler.step(val_loss)
逐行解释:
- inputs.transpose(0, 1) :将输入张量从 (batch_size, seq_len, input_dim) 转换为 (seq_len, batch_size, input_dim) ,以适配LSTM的输入格式。
- writer.add_scalar :记录训练损失到TensorBoard,便于可视化分析。
- scheduler.step(val_loss) :根据验证损失调整学习率,防止过拟合。
示例:LSTM音频分类训练流程图
graph TD
A[加载音频数据] --> B[提取特征如MFCC]
B --> C[构建Dataset和DataLoader]
C --> D[定义LSTM模型]
D --> E[定义损失函数和优化器]
E --> F[训练循环]
F --> G{是否完成训练}
G -->|是| H[保存模型]
G -->|否| I[继续训练]
I --> F
该流程图展示了从数据准备到模型训练的完整流程,清晰地体现了LSTM在音频分类任务中的实施路径。
通过本章的深入解析与实战示例,我们系统地了解了RNN/LSTM的原理、应用场景及其在PyTorch中的实现方式。在后续章节中,将进一步结合CRNN模型,探讨CNN与RNN的融合在音频建模中的协同优势。
5. 音频分类任务实战流程
在本章中,我们将围绕音频分类任务的完整实战流程进行深入剖析。音频分类广泛应用于语音识别、音乐流派识别、环境声音分类等场景,其核心在于从原始音频信号中提取有效特征,并通过机器学习模型完成分类任务。本章将结合Torchaudio、PyTorch以及CRNN等技术栈,系统性地展示从数据准备到模型部署的全过程。
5.1 音频分类的整体流程概述
音频分类任务的基本流程包括数据准备、特征提取、模型选择、训练与评估、部署上线等多个环节。每个环节紧密衔接,共同影响最终模型的性能表现。
5.1.1 任务定义与数据准备
音频分类任务通常基于一个已标注的音频数据集,例如UrbanSound8K、ESC-50或Google的Speech Commands Dataset。任务目标是根据音频内容将其划分到预定义的类别中。
数据准备流程包括:
- 数据加载与格式转换(如wav、mp3转为统一格式)
- 标签映射(label mapping)
- 划分训练集、验证集和测试集
- 音频长度统一(如截断或填充)
import torchaudio
import os
def load_audio_files(data_dir):
audio_files = []
labels = []
for label, folder in enumerate(os.listdir(data_dir)):
folder_path = os.path.join(data_dir, folder)
for file in os.listdir(folder_path):
file_path = os.path.join(folder_path, file)
waveform, sample_rate = torchaudio.load(file_path)
audio_files.append(waveform)
labels.append(label)
return audio_files, labels
上述代码展示了如何使用
torchaudio.load()读取音频文件,并将其与对应的标签组合成训练数据。
5.1.2 特征提取与模型选择
音频特征提取是音频分类的关键步骤,常用的特征包括MFCC、梅尔频谱图、过零率等。特征提取后,选择适合的模型结构进行训练。常见的模型包括CNN、RNN、CRNN等。
5.1.3 模型评估与部署流程
训练完成后,使用验证集进行调参,测试集评估性能。最终模型可通过PyTorch的 torch.save() 保存,并部署至生产环境,如Web服务、边缘设备等。
5.2 梅尔频率倒谱系数(MFCC)提取与应用
MFCC(Mel Frequency Cepstral Coefficients)是音频分类中最常用的特征之一,因其能有效模拟人类听觉系统对声音的感知方式。
5.2.1 MFCC的基本原理与计算流程
MFCC的计算流程如下:
- 预加重(Pre-emphasis) :增强高频部分,改善信噪比。
- 分帧与加窗(Framing & Windowing) :将音频切分为短帧并加窗。
- 傅里叶变换(FFT) :将时域信号转为频域。
- 梅尔滤波器组(Mel Filter Banks) :将频谱映射到梅尔尺度。
- 离散余弦变换(DCT) :压缩系数,去除相关性。
- 提取MFCC系数 :通常取前12~13个系数。
5.2.2 MFCC在音频分类中的优势
- 对声音变化的鲁棒性 :能够抵抗音量、语速等变化。
- 特征维度低 :相比原始波形或频谱图,MFCC特征维度更低,便于建模。
- 与人耳感知一致 :更符合人类听觉感知特性。
5.2.3 使用Torchaudio提取MFCC特征
Torchaudio 提供了 torchaudio.transforms.MFCC() 接口用于提取MFCC特征。
import torchaudio.transforms as T
# 假设已加载waveform和sample_rate
mfcc_transform = T.MFCC(
sample_rate=sample_rate,
n_mfcc=40,
melkwargs={"n_fft": 400, "hop_length": 160, "n_mels": 80}
)
mfcc_features = mfcc_transform(waveform)
print(mfcc_features.shape) # 输出:[1, 40, T]
说明:
n_mfcc=40表示提取40个MFCC系数,T表示时间帧数。输出形状为[通道数, MFCC维度, 时间帧数]。
5.3 数据增强与训练优化策略
数据增强是提升模型泛化能力的重要手段,尤其在音频分类任务中,由于数据采集环境多样,增强策略尤为重要。
5.3.1 音频裁剪与变速变调技术
- 裁剪(Trimming) :截取音频片段以统一长度。
- 变速(Speed Perturbation) :改变播放速度以生成不同变体。
- 变调(Pitch Shifting) :改变音频的音调。
import torchaudio.functional as F
# 变速变调示例
new_sample_rate = int(sample_rate * 1.1) # 加快10%
resampled_waveform = F.resample(waveform, sample_rate, new_sample_rate)
5.3.2 噪声注入与频谱掩码增强
- 噪声注入(Noise Injection) :在音频中添加背景噪声。
- 频谱掩码(SpecAugment) :对频谱图进行时间或频率掩码。
# 添加白噪声
noise = torch.randn_like(waveform) * 0.005
noisy_waveform = waveform + noise
5.3.3 学习率调整与正则化方法
- 学习率调度器(Learning Rate Scheduler) :如
StepLR、ReduceLROnPlateau。 - 正则化方法 :Dropout、L2正则化、权重初始化。
from torch.optim.lr_scheduler import ReduceLROnPlateau
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
scheduler = ReduceLROnPlateau(optimizer, 'min', patience=3)
5.4 模型评估与性能分析
模型评估是确保模型性能的关键环节。在音频分类任务中,常用的评估指标包括准确率、召回率、F1分数等。
5.4.1 准确率、召回率与F1分数
- 准确率(Accuracy) :预测正确的样本比例。
- 召回率(Recall) :实际正样本中被正确预测的比例。
- F1分数 :准确率与召回率的调和平均,适用于类别不平衡场景。
from sklearn.metrics import classification_report
# 假设 y_true 是真实标签, y_pred 是模型预测结果
print(classification_report(y_true, y_pred))
5.4.2 混淆矩阵与类别不平衡问题
混淆矩阵可以直观展示分类器在各个类别上的表现,帮助识别模型的误分类情况。
from sklearn.metrics import confusion_matrix
import seaborn as sns
import matplotlib.pyplot as plt
cm = confusion_matrix(y_true, y_pred)
sns.heatmap(cm, annot=True, fmt='d', cmap='Blues')
plt.xlabel('Predicted')
plt.ylabel('True')
plt.show()
5.4.3 可视化分析与模型调优建议
通过可视化模型的注意力权重、特征热力图等,可以辅助分析模型关注的区域,从而进行针对性优化。
例如,使用Grad-CAM可视化CNN关注的频谱区域,或分析RNN/LSTM的隐藏状态变化趋势。
graph TD
A[原始音频] --> B[特征提取]
B --> C{模型选择}
C -->|CNN| D[卷积特征提取]
C -->|RNN| E[序列建模]
C -->|CRNN| F[结合CNN+RNN]
D --> G[模型训练]
E --> G
F --> G
G --> H[模型评估]
H --> I{是否满足要求}
I -->|是| J[部署上线]
I -->|否| K[调整参数]
K --> G
上图展示了音频分类任务的整体建模流程与反馈机制。
简介:”torchaudio-contrib-master.zip” 是一个基于 PyTorch 和 torchaudio 的音频处理开源项目资源包,来源于 GitHub 上的 CRNN 音频分类项目。该项目结合卷积神经网络(CNN)与循环神经网络(RNN),实现对音频数据的智能分类,如人声、乐器声、动物声音等。项目涵盖完整的音频预处理、特征提取、模型构建、训练优化与评估流程,使用了 MFCC、LSTM、数据增强等关键技术,适合音频处理与深度学习方向的研究和实践。

开源鸿蒙跨平台开发社区汇聚开发者与厂商,共建“一次开发,多端部署”的开源生态,致力于降低跨端开发门槛,推动万物智联创新。
更多推荐
 9
9 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)