深入浅出 CAS:从 CPU 指令到 Java 17 原子类实战
这篇文章会用 Java 17 的视角,把 CAS 从底层原理到实际落地系统地讲清楚。cmpxchg。
这篇文章会用 Java 17 的视角,把 CAS 从底层原理到实际落地系统地讲清楚。
目标只有一个:看完这一篇,你对 CAS 的理解不再停留在“有三个参数 V/E/N”这种记忆层面,而是能从 CPU 指令一路推演到 Java 代码,再对框架源码里的实战用法心里有数。
示例环境说明:
- 操作系统:Windows 11
- JDK 版本:JDK 17
- CPU 架构:主流 x86_64(支持
cmpxchg等原子指令)
要彻底理解 CAS,先把这几个基础打牢
如果你之前对并发只是零散了解,建议先把下面这些点梳一遍:
- 多线程与共享内存模型:
- 至少搞清楚“线程”、“共享变量”、“临界区”、“竞态条件”这些词分别指什么;
- 理解为什么
count++在多线程下不是一个原子操作。
- CPU 缓存与缓存一致性:
- 知道 CPU 不是直接对内存操作,而是对缓存行操作;
- Java 内存模型(JMM)三大问题:
- 原子性、可见性、有序性分别是什么意思;
happens-before这条规则大致在解决什么问题。
volatile和锁的语义:volatile提供的是“可见性 + 有序性”,但不能保证复合操作的原子性;如果想系统地理解volatile,可以参考知乎专栏文章《深入浅出 Java volatile:从硬件到 JMM 的完整剖析》;synchronized/Lock提供互斥访问和更强的happens-before关系,同时伴随阻塞和上下文切换成本。
- 悲观锁 vs 乐观锁、自旋的概念:
- 悲观锁假设“迟早会冲突”,先把门锁上再干活;
- 乐观锁假设“冲突是少数”,先干活,真冲突了再回滚重试;
- 自旋就是“在用户态原地重试”,这正是 CAS 的典型使用方式。
如果这些内容你都比较熟悉,可以直接把它当成一份 checklist 快速过一眼;如果有某个点不太确定,建议先查一两篇专门的文章补一下,再往下看 CAS,会轻松很多。
为什么锁不够用了:从阻塞到无锁
很多人一提到“加锁”,脑子里都是:一个线程拿到锁,其它线程就只能干等。等得久了,JVM 会把线程挂起、再唤醒,来回切换上下文,CPU 真正在干业务逻辑的时间就被压缩得很少。
这里再把问题说得直白一点:
- 锁的本质:
- 互斥 + 阻塞 + 内核参与(线程挂起 / 唤醒)。
- 线程抢锁失败后,不是“什么都没发生”,而是触发了一大堆调度逻辑。
- 代价:
- 上下文切换、用户态 / 内核态切换,这些都不便宜。
- 低冲突时,这种成本其实是“浪费”的。
那有没有一种办法:
- 冲突少的时候,不要动不动就挂起线程;
- 冲突多的时候,也要尽量减少等待成本;
- 能够在单变量更新这种场景下,完全不依赖传统锁?
这就是 CAS 要解决的问题。
CAS 究竟在干什么:V、E、N 三个参数背后的语义
教科书式的说法是:CAS 接收 3 个参数:V(当前值)、E(期望值)、N(新值)。
把它翻译成“程序员语言”,更好理解:
- V(Value):
- 你准备修改的那块内存里,现在的真实值。
- E(Expected):
- 你“以为”这块内存此刻应该是多少(基于你之前读到的值)。
- N(New):
- 如果现实确实和你的预期一致,你打算把它更新成多少。
CAS 做的事情就是一句话:
如果V == E,就把V原子地改成N,并告诉你“成功”;否则什么都不做,告诉你“失败”。
注意两个关键点:
- 比较和写入必须是一个不可分割的原子操作;
- CAS 只负责这一小段原子更新,不负责帮你排队和等待。
这其实就是“乐观并发控制”:
- 我先假设别人不会跟我抢这块内存;
- 如果真的撞车了,就再试一次。
用一个排队拿号的例子看 CAS
先忘掉 CPU 和指令,想象一个排队叫号的场景:
- 某个窗口有一个“当前叫号牌”,上面写着 42;
- 你手上有一张小票,上面写着“我上次看到的号码是 42”;
- 你的目标是:把窗口的号改成 43。
这时候 CAS 的逻辑就很好类比:
- 你先悄悄看一眼窗口现在的号是不是 42:
- 如果还是 42,说明没人抢在你前面改号,你就把牌子改成 43;
- 如果已经变成 43 或 44,说明别人抢先一步了,你这次就放弃,不改牌子。
整个过程里,有两个关键点:
- 你不会一边看一边改,而是“先确认还是 42,再一次性改成 43”;
- 要么成功把 42 改成 43,要么什么都不改,绝不会出现“改到一半”的状态。
把这个过程抽象成一个简单的流程图,会更直观:
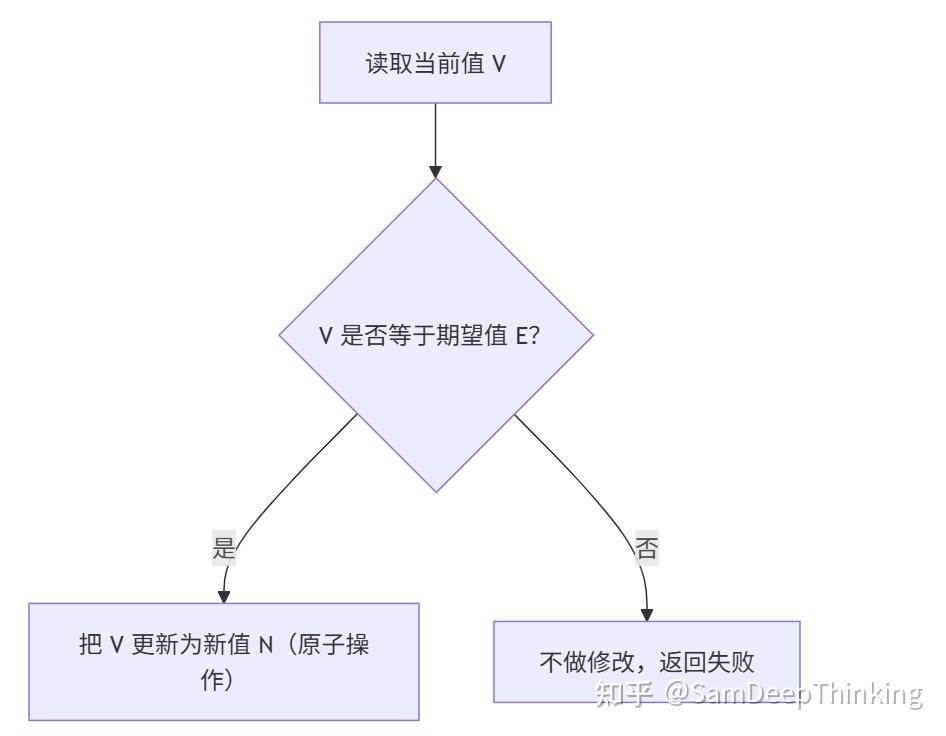
在 Java 代码里,你看到的 compareAndSet(expect, update),做的就是上面这件事,只不过 V/E/N 都变成了内存里的整数或对象引用。
CPU 视角下的 CAS:cmpxchg、内存屏障和缓存一致性
从 CPU 视角看,CAS 其实就是一条(或一小段)原子读–改–写指令序列。以 x86 为例:
- 汇编里有一条指令:
cmpxchg,配合lock前缀就能对共享内存做原子比较交换; lock cmpxchg会:- 锁住对应缓存行(配合缓存一致性协议),
- 比较寄存器里的期望值和内存当前值,
- 相等则写回新值、否则不写。
JVM 并不会自己发明新指令,而是:
- 在 HotSpot 里用 C++ 封装这些 CPU 原子指令;
- 再通过
Unsafe.compareAndSwapInt以及基于它实现的各类原子类 API 暴露给 Java 层。
你在 Java 里写的这句:
atomicInteger.compareAndSet(0, 1);最终会在机器码里变成一条类似 lock cmpxchg 的序列,中间不会被其他线程插进来。
另外一个经常被忽略的点:内存可见性。
- 原子指令在实现上会伴随内存屏障(memory fence);
- Java 有一套自己的内存模型(JMM,Java Memory Model),用来规定“一个线程写入的数据,另外一个线程在什么时刻、以什么顺序能看到”,其中最重要的一条规则就叫
happens-before; - 对这篇文章来说,只需要记住一个结论:对同一个变量的成功
compareAndSet/incrementAndGet这类操作,它们的写入结果,对后面读取这个变量的线程是可见的——这是 JMM 帮你兜底; - 字段再配合
volatile,就能做到“CAS 负责原子性,JMM + volatile 负责可见性和有序性”,具体细节我会在单独的一篇 JMM 文章里展开。
这也是为什么 JDK 里的原子类内部字段基本都是 volatile,而不是随便一个普通字段。
用 Java 17 写一个最小可跑的 CAS 示例(AtomicInteger 版本)
前面都是概念,这里先用一个“点赞计数”的小例子,把 CAS 在并发场景下到底帮了什么忙讲清楚。
想象有一篇很火的技术文章,很多用户同时在点“赞”:
- 每点一次赞,总点赞数就要加 1;
- 不管多少人同时点,最终的总数都应该是“所有点击次数之和”,不能丢赞;
- 但我们又不想给这个计数器加一把大锁,把所有线程都串行化。
下面这段代码,用 Java 17 里的 AtomicInteger 实现了一个最小可跑的“安全点赞计数器”:
import java.util.concurrent.atomic.AtomicInteger;
public class CasLikeDemo {
// 所有线程共享的点赞数
private static final AtomicInteger LIKE_COUNT = new AtomicInteger(0);
public static void main(String[] args) throws InterruptedException {
// 模拟有 4 个线程同时在点赞
int threadCount = 4;
// 每个线程点 100000 次赞
int loop = 100_000;
// 保存所有线程,方便后面统一 join
Thread[] threads = new Thread[threadCount];
for (int i = 0; i < threadCount; i++) {
threads[i] = new Thread(() -> {
for (int j = 0; j < loop; j++) {
// 每一次点赞都通过 CAS 安全地把计数器加 1
LIKE_COUNT.incrementAndGet();
}
});
threads[i].start();
}
// 等待所有点赞线程都执行完
for (Thread t : threads) {
t.join();
}
// 期望值:线程数 * 每个线程的点赞次数
System.out.println("Expected: " + (threadCount * loop));
// 实际值:CAS 保护下的最终点赞数
System.out.println("Actual: " + LIKE_COUNT.get());
}
}在上面的配置下(4 个线程、每个线程点赞 100000 次),在一台普通 x86_64 机器 + JDK 17 上实际运行一次,输出为:
Expected: 400000
Actual: 400000这段代码在 JDK 17 下可以直接编译运行。
这个小实验想验证和说明两件事:
- 在 4 个线程、每个线程点赞 100000 次的高并发场景下,通过
AtomicInteger.incrementAndGet()来做自增,实际结果Actual等于期望结果Expected,说明在没有加大锁的前提下也没有丢更新; - 如果这里换成普通的
int变量配合count++,在相同的测试条件下,实际结果明显小于期望值(例如前文实测的225004),这就是没有用 CAS 时典型的写覆盖问题。下面是一个故意不用 CAS 的“错误示例”,你可以对比运行结果:
public class BrokenLikeDemo {
private static int likeCount = 0;
public static void main(String[] args) throws InterruptedException {
int threadCount = 4;
int loop = 100_000;
Thread[] threads = new Thread[threadCount];
for (int i = 0; i < threadCount; i++) {
threads[i] = new Thread(() -> {
for (int j = 0; j < loop; j++) {
// 非原子操作:读、改、写可能被其他线程打断
likeCount++;
}
});
threads[i].start();
}
for (Thread t : threads) {
t.join();
}
System.out.println("Expected: " + (threadCount * loop));
System.out.println("Actual: " + likeCount);
}
}在同样的环境和参数设置下,实际运行某次 BrokenLikeDemo 的输出类似:
Expected: 400000
Actual: 225004有了这个直观的感受,再去看后面 AtomicInteger 源码里基于 CAS 的自旋实现,就更容易把“原理”和“真实业务场景”对上号。
关键点:
LIKE_COUNT是一个AtomicInteger,专门用来在多线程下做安全的整数自增;- 每次
incrementAndGet()内部都会做“读当前值 → 基于当前值算出新值 → 用 CAS 尝试写回 → 失败就重试”这一套流程; - 冲突少的时候,大部分线程第一次 CAS 就能成功,不需要阻塞或挂起线程。
在低冲突场景,这种基于 CAS 的自增,比给整个计数器加一把大锁要轻量得多。
再看 AtomicInteger 源码:getAndIncrement 背后的自旋循环
AtomicInteger 是大家最熟悉的 CAS 包装类之一。看一下它在 OpenJDK 里的核心实现(代码可在 OpenJDK 17 仓库中查看,例如 AtomicInteger 源码):
下面是精简后的关键片段(保持了原有语义):
public class AtomicInteger extends Number implements java.io.Serializable {
private static final long serialVersionUID = 6214790243416807050L;
private static final jdk.internal.misc.Unsafe U = jdk.internal.misc.Unsafe.getUnsafe();
private static final long VALUE_OFFSET;
static {
try {
VALUE_OFFSET = U.objectFieldOffset
(AtomicInteger.class.getDeclaredField("value"));
} catch (ReflectiveOperationException e) {
throw new Error(e);
}
}
private volatile int value;
public final int get() {
return value;
}
public final boolean compareAndSet(int expect, int update) {
return U.compareAndSetInt(this, VALUE_OFFSET, expect, update);
}
public final int getAndIncrement() {
return U.getAndAddInt(this, VALUE_OFFSET, 1);
}
}这里面有几个细节值得注意:
value字段是volatile;compareAndSet直接调用了底层Unsafe.compareAndSetInt;getAndIncrement则是基于getAndAddInt封装的。
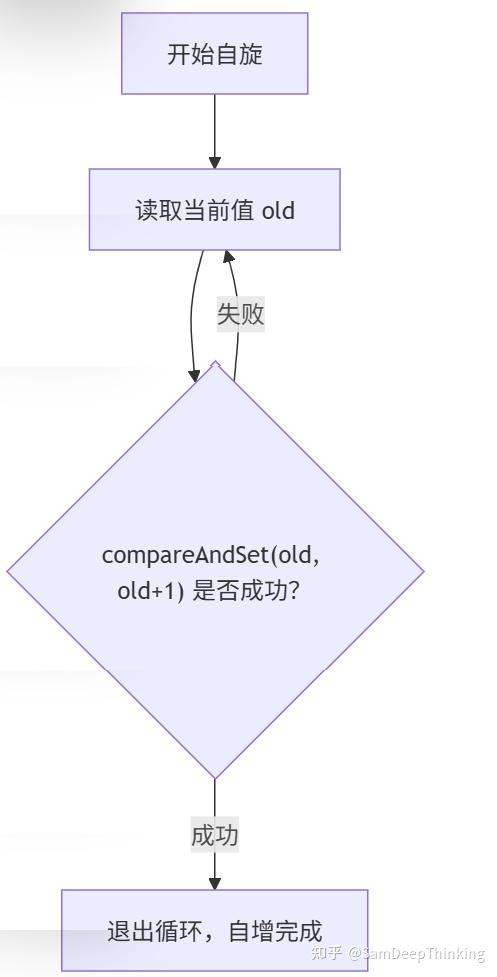
getAndAddInt 的典型实现也是一个 CAS 自旋循环:
public final int getAndAddInt(Object o, long offset, int delta) {
int v;
do {
v = getIntVolatile(o, offset);
} while (!compareAndSetInt(o, offset, v, v + delta));
return v;
}可以看到,和前面点赞计数示例里用到的模式本质上是一样的:
- 先读一遍旧值
v; - 基于旧值算出新值
v + delta; - 用 CAS 尝试写回;
- 如果失败(说明有别的线程抢先改了),就再读一遍再来。
ABA 问题到底危险在哪,怎么用版本号解决
ABA 问题在并发编程里经常被提起,这里重新整理一下,更贴近实际场景。
所谓 ABA 问题,就是:
- 线程 T1 读到某个共享变量值为
A; - T1 被挂起;
- 线程 T2 把值从
A改成B,又从B改回A; - T1 醒来后再用
compareAndSet(A, X),会认为“值没变”,从而更新成功。
很多时候这不一定是 bug,比如一个简单计数器,你只关心当前数值,不在乎中间历史。但在一些“状态机”场景,这可能是致命问题:
- 例如节点状态从
INIT→RUNNING→STOPPED; - 如果某些路径又把状态从
STOPPED改回INIT; - 你单纯比较值是否为
INIT,已经无法知道这是“老的 INIT”还是“新的一轮 INIT”。
解决思路可以分两步来看:先看一个只有“值”的错误写法,再看加上“值 + 版本号”之后的改进方案。
先看一个只比较值的 CAS 写法,很容易踩 ABA 坑:
import java.util.concurrent.atomic.AtomicReference;
public class AbaBadDemo {
private static final AtomicReference<String> REF =
new AtomicReference<>("A");
public static void main(String[] args) throws InterruptedException {
// T1 拿到老快照:值为 A
String initial = REF.get();
Thread t2 = new Thread(() -> {
// T2:A -> B
REF.compareAndSet("A", "B");
// T2:B -> A
REF.compareAndSet("B", "A");
});
t2.start();
t2.join();
// T1:基于“老的 A”尝试改成 X
boolean success = REF.compareAndSet(initial, "X");
System.out.println("CAS success? " + success);
System.out.println("value=" + REF.get());
}
}在一台普通的 Windows 11 + JDK 17 环境下,运行结果会是:
CAS success? true
value=X也就是说:虽然期间经历过 A -> B -> A,最后 T1 仍然误以为“值没变”,CAS 成功把 A 改成了 X —— 这就是典型的 ABA 问题。
更朴素的解决思路是:
- 给变量加一个“版本号”或“时间戳”;
- CAS 比较时,不仅比较值,还要比较版本号;
- 每次真正更新成功时,版本号加 1。
JDK 里有现成的工具类:AtomicStampedReference,它就是“值 + 版本”的包装。
示例代码:
import java.util.concurrent.atomic.AtomicStampedReference;
public class AbaFixedDemo {
private static final AtomicStampedReference<String> REF =
new AtomicStampedReference<>("A", 0);
public static void main(String[] args) throws InterruptedException {
int[] stampHolder = new int[1];
String initial = REF.get(stampHolder);
int initialStamp = stampHolder[0];
Thread t2 = new Thread(() -> {
int[] s = new int[1];
String v1 = REF.get(s); // A, stamp 0
REF.compareAndSet(v1, "B", s[0], s[0] + 1); // A->B, stamp 0->1
String v2 = REF.get(s); // B, stamp 1
REF.compareAndSet(v2, "A", s[0], s[0] + 1); // B->A, stamp 1->2
});
t2.start();
t2.join();
boolean success = REF.compareAndSet(initial, "X", initialStamp, initialStamp + 1);
System.out.println("CAS success? " + success);
System.out.println("value=" + REF.getReference() + ", stamp=" + REF.getStamp());
}
}在与前文相同的环境(Windows 11 + JDK 17)下运行这个示例,某次实际输出为:
CAS success? false
value=A, stamp=2这个结果完全符合预期:
value=A:说明经过线程t2的两次修改之后,值又被改回了A;stamp=2:表示这块数据在期间经历过两次成功更新(A -> B、B -> A),版本号从 0 变成了 2;CAS success? false:主线程手里拿着的是“值为A、版本为 0”这一老快照,它尝试在这个快照的基础上做compareAndSet(initial, "X", initialStamp, initialStamp + 1),由于当前版本号已经是 2,不再等于 0,所以 CAS 按预期失败。
也就是说:即使当前值又回到了 A,AtomicStampedReference 仍然能通过版本号看出来“这已经不是当初那个 A 了”,从而避免了 ABA 问题。
从单变量到复合状态:什么时候该果断用锁
CAS 非常适合单变量或少量字段的更新,一旦状态变复杂,你就要警惕了。
几种典型不适合只用 CAS 的场景:
- 需要一次性更新多个字段,必须保持整体一致性:
- 比如一个订单从“未支付”切到“已支付”,状态字段、支付时间、支付渠道、日志记录等多个字段必须要么都修改,要么都不修改;
- 这种场景如果强行用多次 CAS,很容易在中途失败,状态半更新半不更新。
- 冲突非常激烈:
- CAS 在高冲突场景下会疯狂自旋,整体成本未必比用锁低;
- 此时合理的做法是:要么调整数据结构(分段、分桶),要么老老实实用锁。
- 业务代码里有长耗时操作:
- CAS 自旋代码里应该只放“极短的纯计算”逻辑;
- 一旦里面夹带 IO、RPC 等耗时操作,就会把 CAS 这一层的优势完全吃掉。
简单一句话:
CAS 负责的是“原子更新一个点”,不是“保证整个事务的一致性”。
超过它能力边界的场景,就不要硬上了。
Netty框架里的 CAS 用法
Netty:引用计数和状态机里的 CAS
Netty 作为高性能网络框架,对对象生命周期的控制非常苛刻。以 ByteBuf 的引用计数为例,为了做到在多线程下安全地回收内存,它通过 CAS 来维护引用计数:
- 在 Netty 4.x 里,有一个
AtomicReferenceCountUpdater抽象类(可参考官方文档:Netty AtomicReferenceCountUpdater); - 其中定义了
casRawRefCnt这样的操作,本质就是对内部的引用计数字段做 CAS 更新; - 实现类内部会基于
AtomicIntegerFieldUpdater或Unsafe等原子工具,在不引入锁的前提下,安全地对引用计数加减。
这类场景的特点:
- 状态很简单:一个
int的引用计数; - 读写频率极高;
- 加锁会严重拖累吞吐量,因此非常适合用 CAS。
如何判断一段代码适不适合用 CAS
最后给一个我自己在项目里常用的“快速判断标准”,判断是否值得把某段逻辑改成 CAS:
- 只更新单个变量?
- 是:可以考虑 CAS。
- 否:优先考虑锁、事务或更高级的抽象。
- 更新逻辑是否极短、没有阻塞操作?
- 是:适合放进 CAS 自旋里。
- 否:要谨慎,避免在自旋里做重活。
- 冲突概率是否可控?(例如通过分段、分桶压低冲突)
- 是:CAS 很可能能显著减少锁开销。
- 否:冲突太频繁时,自旋成本会很糟糕。
- 是否真的需要非阻塞?
- 有些场景,即使用锁也完全够用,而且代码更直观;
- 不要为了“听起来高级”而到处堆 CAS。
可以把 CAS 当成一把很锋利的刀:
- 用好了,可以极大提升并发性能;
- 用错了,既不好写、也不好排查问题。
在 Java 17 这个版本上,你完全可以用 AtomicXXX 覆盖绝大多数需要 CAS 的场景:
- 业务代码里,优先用
AtomicInteger、LongAdder这类成熟封装; - 写基础组件、框架代码,需要更细粒度控制时,可以在充分评估的前提下使用
Unsafe或其他底层原子工具; - 只有在极个别需要精细控制布局和性能的场景,才真的去碰这些底层接口。
只要把这里的几层关系理顺,再配合前面的代码和框架示例,CAS 这块基本就算真正在脑子里“落地”了。

开源鸿蒙跨平台开发社区汇聚开发者与厂商,共建“一次开发,多端部署”的开源生态,致力于降低跨端开发门槛,推动万物智联创新。
更多推荐


 4
4 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)