【chap6-字符串】用Python3刷《代码随想录》
字符串是由若干字符组成的有限序列,也可以理解为一个字符数组
目录
344. 反转字符串
思路:双指针法。定义两个指针(即索引下标),一个从字符串前面,一个从字符串后面,两个指针同时向中间移动,并交换元素
- 反转链表和反转字符串都是双指针法,但字符串也是一种数组,故元素在内存中是连续分布的(跟链表不同)
class Solution:
def reverseString(self, s: List[str]) -> None:
"""
Do not return anything, modify s in-place instead.
"""
i, j = 0, len(s)-1
for i in range(len(s)):
if i < j:
s[i], s[j] = s[j], s[i]
i += 1
j -= 1
return s541. 反转字符串II
题意简单概括:对于字符串s,每次遍历其2k的长度,反转2k长度里的前k个;若最后一组的长度不足2k但大于k,只反转这k个;若不足k,全部反转
首先,这题可以调用 344题反转字符串 中的函数,但要注意的是,344题的输入是一个字符组成的列表,而这题是字符串
- 对字符串str 转 字符列表 list,用 list() 即可
- 字符列表res 拼接回 字符串,用 "".join(res)
其次,分析本题哪些部分需要反转。注意,对于字符串s,是2k个长度去遍历的。对于2k个长度中的前k个进行反转
- 使用 range(start, end, step) 来确定需要调换的初始位置
- 对于字符串s = 'abc',如果使用s[0:999] ===> 'abc'。字符串末尾如果超过最大长度,则会返回至字符串最后一个值,这个特性可以避免一些边界条件的处理
- 用切片整体替换,而不是一个个替换
class Solution:
def reverseStr(self, s: str, k: int) -> str:
# 先定义一个反转函数
def reverse(s): # List[str]
i, j = 0, len(s)-1
for i in range(len(s)):
if i < j:
s[i], s[j] = s[j], s[i]
i += 1
j -= 1
return s
res = list(s) # str —> list
for i in range(0, len(s), 2*k): # 每次跳2k步
res[i: i+k] = reverse(res[i: i+k]) # 切片是左闭右开
return ''.join(res)剑指offer 05. 替换空格
力扣已经将剑指offer题目下架,原题意为:
- 请实现一个函数,把字符串s中的每个空格替换成%20
- 示例:输入:s = "We are happy." 输出:"We%20are%20happy."
因为Python中字符串是不可变类型,所以操作字符串需要将其转换为列表,因此空间复杂度不可能为O(1)
法1:比较直观的一种方法。添加空列表,添加匹配的结果
class Solution:
def replaceSpace(self, s: str) -> str:
res = []
for i in range(len(s)):
if s[i] != ' ': # 注意引号中间要打一个空格
res.append(s[i])
else:
res.append('%20')
return "".join(res)法2:双指针。首先扩充数组到每个空格替换成 %20 之后的大小,然后从后向前替换空格(为什么是从后向前?因为从前向后填充的话,每次添加元素都要将添加元素之后的所有元素向后移动)
很多数组填充类的问题,都可以预先给数组扩容成填充后的大小,然后再从后向前进行操作
class Solution:
def replaceSpace(self, s: str) -> str:
cnt = s.count(' ') # 统计字符串s里有多少个空格
res = list(s) # str —> list
res.extend([' ']*2*cnt) # 每个空格都要换成%20,长度+2
# left遍历s,若遇到空格,则替换为%20;否则直接赋给right
left, right = len(s)-1, len(res)-1 # 从后向前遍历
while left >= 0:
if res[left] != ' ':
res[right] = res[left]
right -= 1
else:
res[right-2: right+1] = '%20' # 左闭右开 [right-2, right]
right -= 3
left -= 1
return "".join(res)LCR 122.路径加密
class Solution:
def pathEncryption(self, path: str) -> str:
path = list(path)
for i in range(len(path)):
if path[i] == '.':
path[i] = ' '
return "".join(path)151. 反转字符串中的单词
思路:移除多余空格(双指针法) —> 将整个字符串反转 —> 将每个单词反转(即字符串中用空格隔出来的部分)。先整体反转再局部反转
- 移除空格,跟 27. 移除元素 思路一样,都是快慢指针(快指针指向想要获取的元素,慢指针表示获取快指针指向的元素后应该更新在哪里)。空间复杂度是 O(1),时间复杂度是 O(n)
class Solution:
# 反转字符串
def reverse(self, s: str) -> str:
s = list(s)
left, right = 0, len(s)-1
while left < right:
s[left], s[right] = s[right], s[left]
left += 1
right -= 1
return "".join(s)
# 移除多余空格
def removeSpace(self, s: str) -> str:
s = list(s)
slow, fast = 0, 0 # fast来获取非空格的字母,slow为获取fast字母之后更新的位置
while fast < len(s):
if s[fast] != " ":
# 每个单词的前面要留一个空格
if slow != 0: # 首个单词前面不需要留空格
s[slow] = ' '
slow += 1
while fast < len(s) and s[fast] != " ":
s[slow] = s[fast] # slow是用来收集fast指向的字母
fast += 1
slow += 1
fast += 1
return "".join(s[:slow]) # 注意截取到slow。因为是原地修改
def reverseWords(self, s: str) -> str:
s = self.removeSpace(s) # 去除多余空格
s = self.reverse(s) # 整个字符串全部反转
# 再对每个单词进行局部反转
start = 0
s = list(s)
for i in range(len(s)):
if s[i] == " ":
s[start: i] = self.reverse(s[start: i])
start = i+1
if i == len(s)-1: # 最后一个单词
s[start:] = self.reverse(s[start:])
return "".join(s)若借助库函数:
class Solution:
def reverseWords(self, s: str) -> str:
s = s.strip() # 先去除字符串前后的空格
s = s[::-1] # 反转整个字符串
# 将每个单词反转
s = ' '.join(word[::-1] for word in s.split()) # split()默认的分隔符是任意空白字符
return s若不借助 strip() 和 split() 函数,另一写法的代码如下:
class Solution:
# 反转s[i: j]
def reverse(self, s, i, j): # s是一个list
while i < j:
s[i], s[j] = s[j], s[i]
i += 1
j -= 1
def reverseWords(self, s: str) -> str:
s = list(s)
# strip()
start, end = 0, len(s) - 1
n = len(s)
while start < n and s[start] == ' ':
start += 1
while end >= 0 and s[end] == ' ':
end -= 1
if start > end:
return ''
# 去除中间多余的空格, 并且把字符串挪到最前面
i, j = 0, start
while j <= end:
if s[j] == ' ':
if s[j - 1] == ' ': # 多个空格
j += 1
else:
s[i] = s[j] # 只有1个空格
i += 1
j += 1
else: # 字母
s[i] = s[j]
i += 1
j += 1
n = i # 有效字符串的长度
self.reverse(s, 0, n - 1)
i = 0
while i < n:
j = i # 找到i开始的整个单词
while j < n and s[j] != ' ':
j += 1
# 此时, j指向单词的最后一个字母后的空格或者字符串结束处
self.reverse(s, i, j - 1)
i = j + 1 # 跳到下个单词的第一个
return ''.join(s[:n]) # n是有效字符串的长度剑指Offer58-II.左旋转字符串
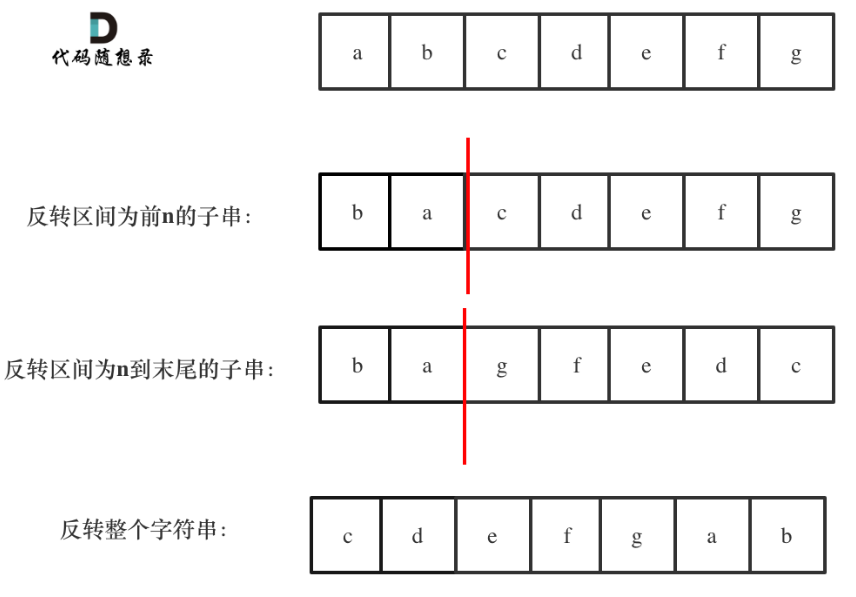
力扣已经将剑指offer题目下架,原题意为:
字符串的左旋转操作是把字符串前面的若干个字符转移到字符串的尾部。请定义一个函数实现字符串左旋转操作的功能。比如,输入字符串"abcdefg"和数字2,该函数将返回左旋转两位得到的结果"cdefgab"
示例 1:
输入: s = "abcdefg", k = 2
输出: "cdefgab"
示例 2:
输入: s = "lrloseumgh", k = 6
输出: "umghlrlose"
限制:
1 <= k < s.length <= 10000
使用整体反转+局部反转就可以实现反转单词顺序的目的
思路:先局部反转再整体反转
class Solution:
def reverse(self, s: list, start, end):
while start < end:
s[start], s[end] = s[end], s[start]
start += 1
end -= 1
def reverseLeftWords(self, s: str, n: int) -> str:
# 先反转前n个
res = list(s)
self.reverse(res, 0, n-1)
# 再反转n+1到末尾
self.reverse(res, n, len(res)-1)
# 再整个反转
self.reverse(res, 0, len(res)-1)
return "".join(res) LCR 182. 动态口令
class Solution:
def dynamicPassword(self, password: str, target: int) -> str:
password = list(password)
for i in range(len(password)):
password.append(password[i])
if i == target-1:
password[:i+1] = ""
break
return "".join(password)28. 找出字符串中第一个匹配项的下标
(一)KMP理论
KMP主要应用在字符串匹配的场景中,其思想是当出现字符串不匹配的情况时,可以知道一部分之前已经匹配的文本内容,利用这些信息避免从头再去做匹配
如:文本串aabaabaaf(长度为n),模式串aabaaf(长度为m),要在文本串里匹配模式串
- 暴力:两层for循环遍历两个字符串,挨个匹配;若不匹配,把模式串整体往后移一位,继续匹配。时间复杂度O(m*n)
- KMP:匹配过程O(n),单独生成next数组是O(m)。时间复杂度O(m+n)
- 该案例中模式串的前缀表是 010120
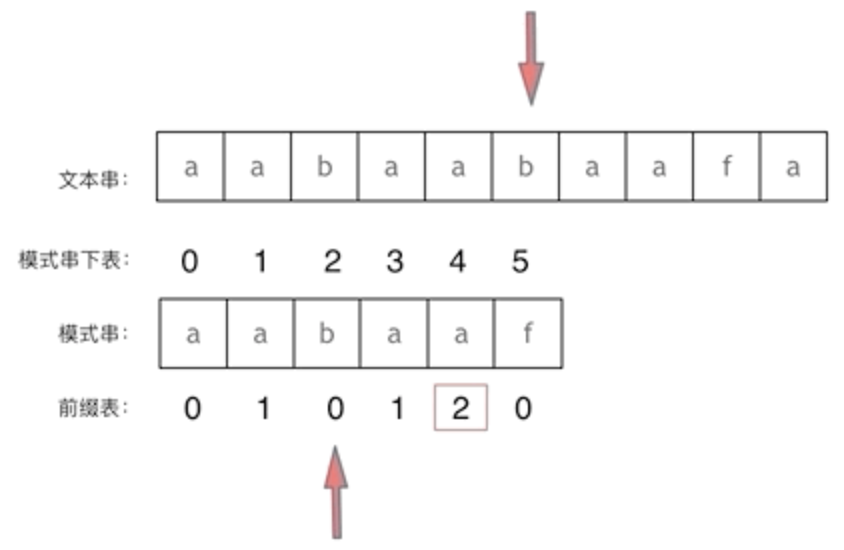
next数组是一个前缀表,用来回退,记录了模式串与文本串不匹配时,模式串应该从哪里开始重新匹配。定义前缀表为:记录下标i(包括i)之前的字符串中有多长的相同前后缀
- 前缀:包含首字母,不包含尾字母的所有连续子串
- 后缀:包含尾字母,不包含首字母的所有连续子串
求得最长相同前后缀的长度就是对应前缀表的元素。找到了最长相等的前后缀,匹配失败的位置是后缀子字符串的后一个字符,找到与其相同的前缀,从后面重新匹配即可
关键:寻找匹配失败位置的前一位在前缀表中的元素,即为要跳转到的重新匹配的下标位置
(二)求next数组代码
什么是前缀表?前缀表是用来回退的,它记录了模式串与主串(文本串)不匹配的时候,模式串应该从哪里开始重新匹配
- 记录下标i之前(包括i)的字符串中,有多大长度的相同前后缀
- 以下图为例,下标5之前的这部分字符串(aabaa)的最长相等的前缀和后缀字符串都是aa,因为找到了最长相等的前后缀,匹配失败的位置是后缀子串的后面,那么找到与其相同的前缀的后面重新匹配就可以了
下实现思路为直接拿 next 数组作为前缀表(遇见冲突看前一位的下标,就是要回退到的位置)
构造 next数组 其实就是计算 模式串s 前缀表的过程。求 next 数组有几个步骤:
- 初始化:i 为后缀末尾的位置(遍历模式串s的循环下标 i 要从1开始),j 为前缀末尾的位置(同时 j 也代表 i 包括 i 在内的之前这个子串的最长相等前后缀的长度)
- 处理前后缀末尾不相同的情况:此时需要向前回退,要找 j 前一个元素在next数组里的值,即next[j-1]
- 处理前后缀相同的情况:找到了相同的前后缀,同时向后移动 i 和 j,并将 j(前缀的长度)赋给 next[i],因为 next[i] 要记录相同前后缀的长度
- 更新 next 数组的值:next[i] 表示i(包括i)之前最长相等的前后缀长度(其实就是j)
# 构造next数组,即前缀表(将前缀表直接作为next数组)
def getNext(self, next: List[int], s: str): # s为模式串
# step1:初始化next数组
j = 0 # j为前缀末尾位置
next[0] = 0 # 只有一个字符的字符串相同前后缀的最大长度是0
for i in range(1, len(s)): # i为后缀末尾位置,从1开始初始化
# step2:若前缀和后缀对应的字符不相同
while s[i] != s[j] and j>0: # 是while而不是if,因为若不相同要连续回退
j = next[j-1] # j要回退到前一位next数组的值的下标位置
# step3:若前缀和后缀对应的字符相同
if s[i] == s[j]:
j += 1 # j还代表着i包括i之前子串的最长相等前后缀长度
next[i] = j
# 另一种写法
def getNext(self, needle: str) -> List[int]:
next = [0] * len(needle)
j = 0 # 前缀末尾
for i in range(1, len(needle)): # 后缀末尾
while j>0 and needle[i] != needle[j]:
j = next[j-1]
if needle[i] == needle[j]:
j += 1
next[i] = j
return next(三)本题题解
特殊情况:当 needle 是空字符串时,应当返回0
28. 实现 strStr() - 代码随想录 - 算法公开课
在文本串s里找是否出现过模式串t,其实就是先构造next数组,然后利用next数组做匹配
- 定义两个下标 j 指向模式串起始位置,i 指向文本串起始位置(从0开始遍历文本串)
- 比较 s[i] 和 t[j]:
- 如果不相同,j 就要从next数组里寻找下一个匹配的位置
- 如果相同,那么 i 和 j 同时向后移动
- 如果判断在 文本串s 里出现了 模式串t 呢?如果j指向了模式串t的末尾,就说明模式串t完全匹配文本串s里的某个子串了
- 本题要在文本串中找出模式串出现的第一个位置(从0开始),所以返回当前在文本串中匹配模式串的位置i,减去模式串的长度,再加1,就是结果
class Solution:
# 构造next数组,即前缀表(将前缀表直接作为next数组)
def getNext(self, next: List[int], s: str): # s为模式串
# step1:初始化next数组
j = 0 # j为前缀末尾位置
next[0] = 0 # 只有一个字符的字符串相同前后缀的最大长度是0
for i in range(1, len(s)): # i为后缀末尾位置,从1开始初始化
# step2:若前缀和后缀对应的字符不相同
while s[i] != s[j] and j>0: # 是while而不是if,因为若不相同要连续回退
j = next[j-1] # j要回退到前一位next数组的值的下标位置
# step3:若前缀和后缀对应的字符相同
if s[i] == s[j]:
j += 1 # j还代表着i包括i之前子串的最长相等前后缀长度
next[i] = j
# 在 haystack(文本串) 里匹配 needle(模式串)
def strStr(self, haystack: str, needle: str) -> int:
next = [0]*len(needle)
self.getNext(next, needle)
j = 0 # j为模式串起始位置
for i in range(len(haystack)): # i为文本串起始位置
while haystack[i] != needle[j] and j>0:
j = next[j-1] # j就要从next数组中寻找下一个匹配的位置
if haystack[i] == needle[j]:
j += 1 # 若相同, i和j同时向后移动
if j == len(needle): # 若j指向了模式串的末尾,说明模式串完全匹配文本串的某个子串了
return i-len(needle)+1 # 返回模式串在文本串中匹配时的第一个字符的位置
return -1- 时间复杂度:O(n + m)
- 空间复杂度:O(m), 只需要保存字符串needle的前缀表
459. 重复的子字符串
1、暴力解法:一个for循环获取子串的结束位置(子串的开头位置一定是从0开始的),另一个for循环匹配子串和主串,检查主串能否由子串重复多次构成。时间复杂度为O(n^2)
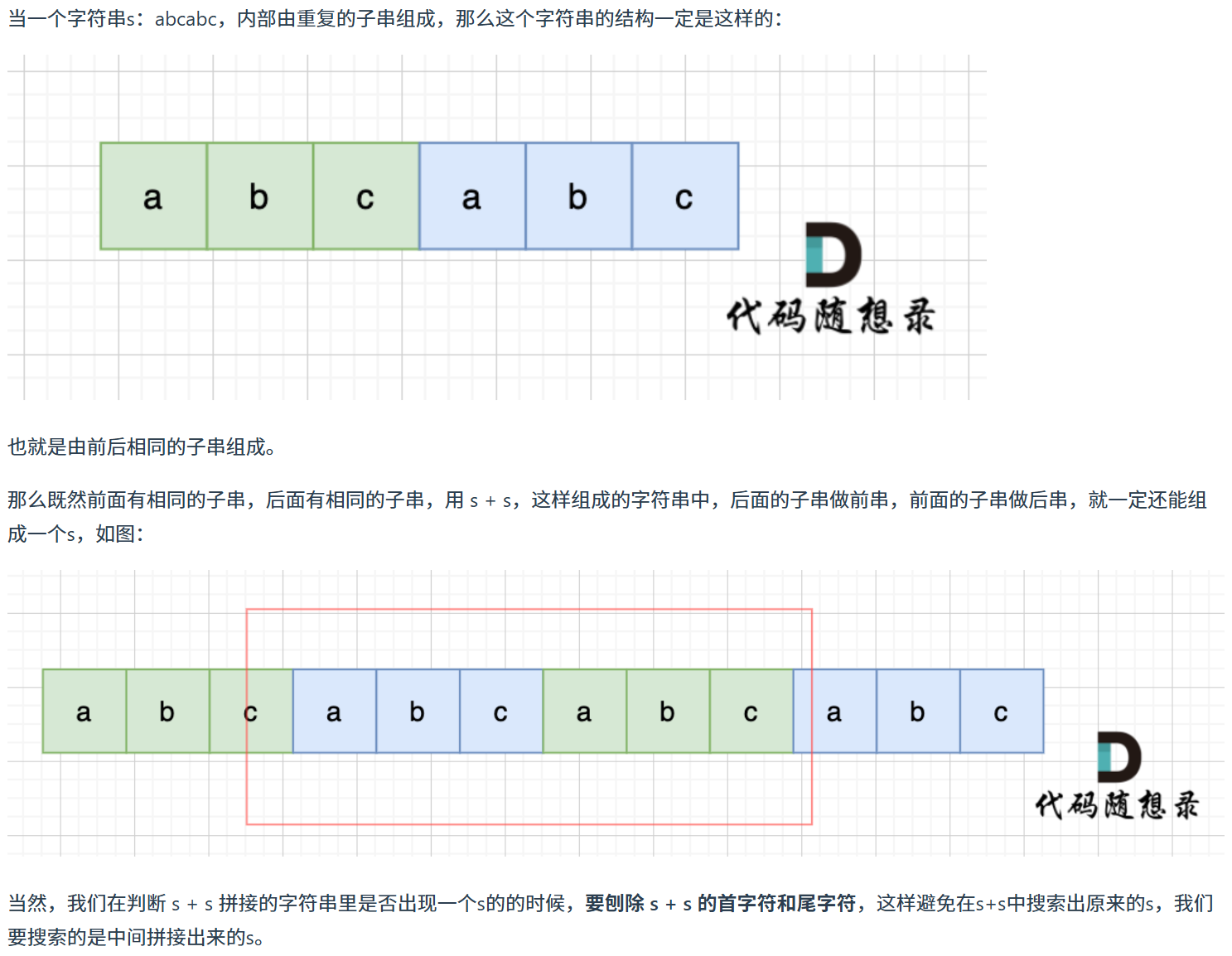
2、移动匹配法:让 s + s 得到一个新的字符串,同时要删去这个新字符串的首字母和尾字母,再去这个新字符串中看看有没有包含 s 字符串。如果包含了,说明 s 是由重复的子串组成的
class Solution:
def repeatedSubstringPattern(self, s: str) -> bool:
new_s = s + s
new_s = new_s[1:-1] # 切片str[start:stop:step],包含start,不包含stop
if s in new_s:
return True
return False3、KMP法
复习KMP:
- 适用场景:给一个字符串,判断另一个字符串是不是在这个字符串里出现过
- KMP算法在查找过程中遇到不匹配的地方,直接跳到上一次匹配的地方继续匹配(因为有计算好的next数组)
- next数组:以各个字符串为结尾的子串的最长相等前后缀的集合
若一个字符串是由重复子串组成的,那么它的最小重复单位就是它的最长相等前后缀不包含的那个子串。如:字符串 abababab,最长相等前后缀为 ababab,不包含的就是ab(即最小重复单元)
数组长度 减去 最长相等前后缀的长度,相当于第一个重复子串的长度,也就是一个重复周期的长度。如果这个周期可以被数组长度整除,说明整个数组就是这个周期的循环
- next数组记录的就是最长相同前后缀,如果 next[-1] != 0 则说明字符串有最长相同的前后缀(就是字符串里前缀子串和后缀子串相同的最长长度)
class Solution:
# KMP求next数组(记录的就是最长相等前后缀的长度)
def getNext(self, next: List[int], s: str):
j = 0
next[0] = 0
for i in range(1, len(s)):
while s[i] != s[j] and j>0:
j = next[j-1]
if s[i] == s[j]:
j += 1
next[i] = j
def repeatedSubstringPattern(self, s: str) -> bool:
next = [0]*len(s)
self.getNext(next, s) # "ababab" [0,0,1,2,3,4]
# next[-1] != 0说明字符串有相同的前后缀
# next[-1] 就是最长相等前后缀的长度
# len(s)-next[-1] 就是重复子串的长度
if next[-1] != 0 and len(s) % (len(s)-next[-1]) == 0:
return True
else:
return False- 时间复杂度: O(n)
- 空间复杂度: O(n)
总结:使用KMP可以解决两类经典问题,匹配问题(28题)和重复子串问题(459题)

开源鸿蒙跨平台开发社区汇聚开发者与厂商,共建“一次开发,多端部署”的开源生态,致力于降低跨端开发门槛,推动万物智联创新。
更多推荐


 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)