安卓 文本框怎么贴近边缘_干货分享 | 用安卓APP作为边缘设备来设置基本的联邦学习环境...
Federated Learning:BringingMachineLearningtotheedgewithKotlinandAndroid选自 Medium Blog作者:Jose Corbacho编译:联邦学习训练机器学习模型需要数据。数据越多,样本特征越丰富,模型表现也会更佳。然而,数据并不便宜,更关键的是数据可能会包含个人敏感信息。随着数据隐私保护法案Gene...
Federated Learning:
Bringing Machine Learning to the edge with Kotlin and Android
选自 Medium Blog
作者:Jose Corbacho
编译:联邦学习
训练机器学习模型需要数据。数据越多,样本特征越丰富,模型表现也会更佳。然而,数据并不便宜,更关键的是数据可能会包含个人敏感信息。
随着数据隐私保护法案General Data Protection Regulation 的颁布,用户对于他们的数据价值以及隐私考虑的意识也逐渐增强。虽然匿名的技术可以极大地解决隐私安全的问题,但本质上将所有数据发送至中心处理器以训练机器学习模型的方式始终是人们担心数据安全的原因。
本文将介绍一个项目,项目将证明如何使用安卓app作为边缘设备来设置一个基本的联邦学习环境。
代码
如果你想直接跳转至代码部分,你可以在以下链接的文章回复中找到它们。
Android Application:https://github.com/mccorby/PhotoLabeller
The Server:https://github.com/mccorby/PhotoLabellerServer
组建
该项目主要由三部分组成:
-
一个服务器,由Kotlin编写(Kotlin是一种在Java虚拟机上运行的静态类型编程语言,它也可以被编译成为JavaScript源代码),并使用DL4J(https://deeplearning4j.org/)生成一个基于Cifar-10数据集的模型。
-
一个用该模型来分类照相机图像的安卓app,由Kotlin编写并且也能使用DL4J。
-
联邦学习的设置环境,能够使安卓app利用本地数据来训练模型,其服务器能够使用边缘更新来更新共享的模型。
模型
该模型是基于Cifar-10数据集,此数据集可以对十种不同类别的图像进行分类。

对模型架构进行了调整,以实现双重的目的:
A.获取有较好的性能表现
B.允许它在安卓app当中加载和训练。
所选择的架构是浅卷积神经网络,具有一个CNN层和一个密集层。证明了足以使用50个纪元和10,000个样本获得良好的性能,同时也保持模型的尺寸较小。(关于模型大小的说明:此PoC的重点在于联合学习。通过不同的技术量化或使用结构化或草图更新,可以使用更多层来训练更好的模型并缩减其大小。)在服务器端训练模型的代码位于PhotoLabellerServerproject的模型中。
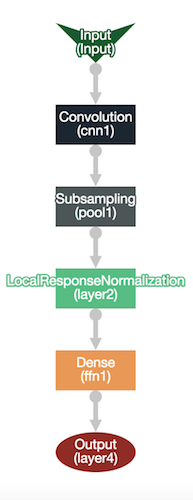
The CNN with a dense layer
用App来做预测
当连接到使用最新版本共享模型的服务器时,该app允许使用嵌入在app本身中的模型对用户使用相机拍摄的照片进行基本分类。
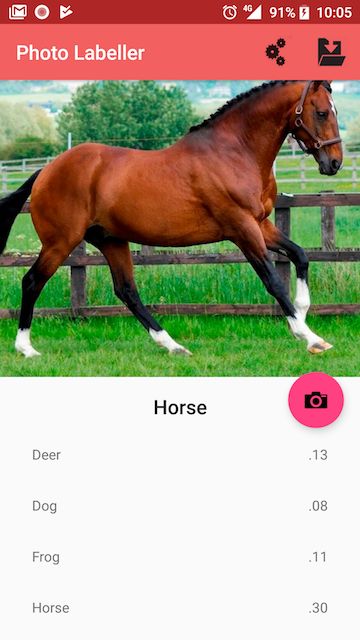
The image classifier in action
该app由模块构建,其中包括安卓特定类别和Deeplearning4j训练器相关的类别。基本模块包括了交互者和域对象。训练器应用的目的包括作预测和利用DL4J进行训练,并调用预测函数来获取图像分类。
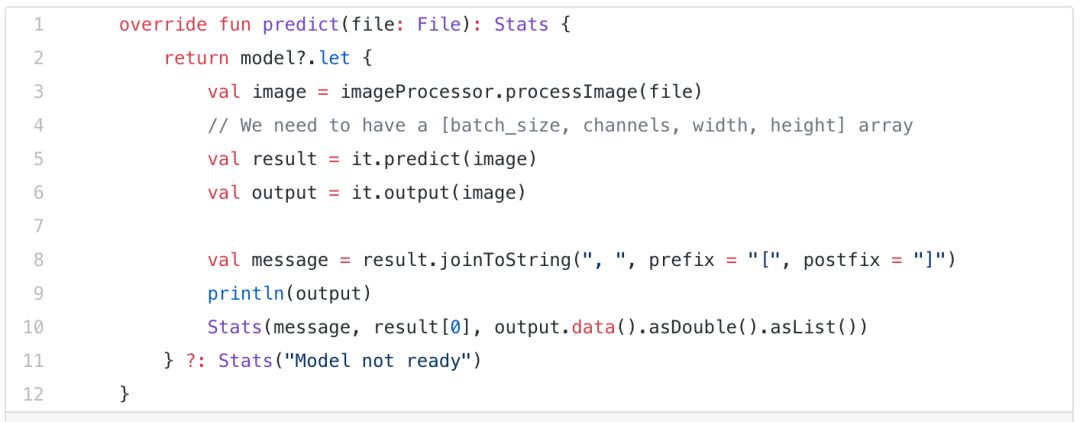
联邦学习设置
联邦学习通过允许边缘设备参与训练,将机器学习模型的更新颠倒过来。联邦学习不是将客户端中的数据发送到集中位置,而是将模型参数以加密的方式发送给参与联合的设备。然后使用本地数据重新训练模型(使用迁移学习)用户的数据不会离开设备包括手机、笔记本电脑、物联网小工具等。服务器打开“循环训练”,在此期间客户端可以将参数的更新发送至服务器。
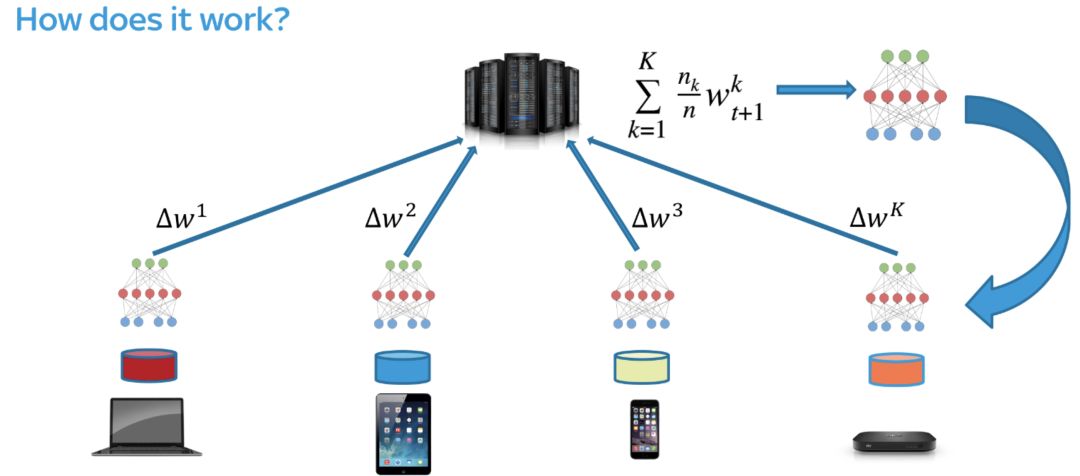
客户端—边缘训练
该安卓app会决定何时参与共享模型的训练。它使用已有的模型或服务器中的模型执行传输学习操作(在其更新的前提下)。然后将模型完成的更新参数发送至服务器。

服务器端—平均和更新模型
一旦循环训练结束时,服务器通过联邦平均算法(Federated Averaging algorithm((https://arxiv.org/abs/1602.05629))来更新共享模型,如下面的要点所示:

同时服务器还接入一个简易的REST API。该客户端也就是安卓app在应用时, 不费力就能够转移到其它的Kotlin平台上。
Notes
用安卓app做关于任何图像处理的操作时,都要求设备的计算量。用图像进行训练模型会要求其增加计算的次数。这也意味着在安卓应用程序中迁移学习的完成过程会很快:几个样本的多次迭代训练。 大部分的app都能够在内存耗尽之完成训练。参数的总量大概有450k,这对于app来说已经非常充足了。
然而,其他的模型在使用不同的数据运行时较为顺畅。例如,之前的一个联邦学习设置版本使用了糖尿病的数据集,该数据仅仅具备若干个特征。这表明了利用更多的迭代训练和更多的数据点也能完成实验。(实际上,我还未发现任何限制因素,因为在达到OOM之前,我已获取了期望的性能表现结果。)
目前该app已成功构建,大家可以尝试使用其他模型和数据集。欢迎大家将其重新用于您的研究。
--End--
🔗原文链接:https://proandroiddev.com/federated-learning-e79e054c33ef
✏️本文为联邦学习编译,转载请联系本公众号获得授权。
📧投稿或寻求报道:fedlearningai@163.com

开源鸿蒙跨平台开发社区汇聚开发者与厂商,共建“一次开发,多端部署”的开源生态,致力于降低跨端开发门槛,推动万物智联创新。
更多推荐
 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)