VXLAN 学习
VXLAN技术解析:构建云时代的虚拟网络 VXLAN(Virtual Extensible LAN)是为解决传统VLAN在云环境中的局限性而设计的网络虚拟化技术。相比VLAN仅支持4094个网络ID的限制,VXLAN采用24位VNI标识,可支持约1600万个虚拟网络,完美适应多租户需求。 关键技术特点: 两层网络架构:Underlay提供物理IP网络基础,Overlay构建虚拟二层网络 报文封装:
一.为什么需要VXLAN
传统 VLAN 的封装位置和局限性
1. VLAN 封装在哪里?
传统 VLAN 的标签是在二层以太网帧的头部进行封装的,具体位置如下:
text
【传统以太网帧(无VLAN)】 | 目标MAC (6) | 源MAC (6) | 类型 (2) | 数据 | FCS |
text
【802.1Q VLAN 帧】 | 目标MAC (6) | 源MAC (6) | **0x8100 (2)** | **PCP(3)+DEI(1)+VID(12)** | 类型 (2) | 数据 | FCS |
-
关键字段:
-
TPID:固定为
0x8100,标识这是一个带 802.1Q 标签的帧。 -
TCI:包含:
-
VLAN ID:12位,这就是问题的核心。它最大值为
2^12 - 2 = 4094(0 和 4095 保留)。
-
-
VLAN 标签是由交换机添加和移除的,只在同一个二层广播域内有效。 一旦数据包需要通过路由器进行三层路由,VLAN 标签通常就会被剥离。
2. 为什么传统 VLAN 在云时代不够用了?
VLAN 的 4094 个限制在传统企业网中可能足够,但在云计算和多租户数据中心中带来了严重问题:
-
数量限制:一个大型云提供商可能有成千上万个租户(客户),4094 个完全不够用。
-
隔离性弱:VLAN 的隔离依赖于 MAC 地址表。在大规模网络中,MAC 地址表可能被攻破或配置错误,导致"VLAN 跳跃"攻击。
-
网络范围受限:VLAN 本质上是一个二层概念。它无法跨越一个三层的 IP 网络。这意味着虚拟机被限制在同一个物理数据中心、同一个子网内,无法自由迁移。
3.为什么需要 VXLAN?
VXLAN 就是为了解决上述所有问题而设计的。
1. 巨大的扩展性
-
VXLAN 使用 24 位的 VNI 来标识虚拟网络。
-
最大数量为
2^24 = 16,777,216(约 1600 万)个。 -
这足以让每个云租户都有自己的逻辑网络,甚至一个租户可以有多个。
2. 克服物理位置限制
这是 VXLAN 最核心的价值之一。
-
场景:公司A在北京和上海都有数据中心。他们希望两个数据中心的服务器属于同一个子网(例如
10.1.1.0/24),以便应用能够无缝通信或进行虚拟机热迁移。 -
传统 VLAN 无法实现:因为北京和上海的数据中心之间是通过三层 IP 网络互联的,VLAN 标签无法穿越。
-
VXLAN 解决方案:
-
VXLAN 将虚拟机发出的原始以太网帧(包括它的 VLAN 标签,如果有的话)整个封装在一个 UDP/IP 包中。
-
这个 UDP/IP 包可以通过任何 IP 网络进行路由,就像普通的网页流量一样,从北京到达上海。
-
目的地的 VTEP 解封装后,将原始帧交给目标虚拟机。
-
-
效果:VXLAN 在三层 IP 网络之上,构建了一个庞大的、虚拟的"二层 overlay 网络"。
3. 更好的隔离性
-
VXLAN 的隔离基于 VNI。
-
通信的建立依赖于控制平面(如 EVPN),更加安全和可控。
-
一个 VNI 中的 MAC 地址不会泄漏到另一个 VNI 中。
二. underlay 和overlay
1. Underlay 网络
这是传统的物理IP网络,是所有流量的承载基础。
-
角色:为 VXLAN 的封装包提供IP可达的传输路径。
-
技术:就是你现在已经很熟悉的三层路由协议(如 OSPF, IS-IS, BGP)和二层交换技术。目标非常简单:让网络中的任何两台物理交换机(特别是担任VTEP角色的交换机)之间都能够通过IP地址相互访问。
-
关注点:
-
可达性:确保网络中没有路由黑洞。
-
可靠性:使用快速收敛协议,确保链路或设备故障时能快速切换。
-
性能:保证足够的带宽和低延迟,因为Underlay的性能直接影响Overlay的质量。
-
-
简单来说:Underlay 就是让 VTEP 之间能够通过 IP 互相 Ping 通 的那个网络。
2. Overlay 网络
这是建立在 Underlay 之上的虚拟化、逻辑的网络。
-
角色:实现虚拟机/容器之间的逻辑二层或三层互联,不受物理网络位置的限制。
-
技术核心 - VXLAN:
-
封装:Overlay 将虚拟机发出的原始数据帧(比如一个以太网帧),整个封装在一个新的 UDP 数据包中。
-
VXLAN 头部:这个新的UDP包有一个 VXLAN 头部,里面最重要的字段是 VNI,这是一个 24-bit 的标识符,类似于 VLAN ID,但规模大得多(1600万 vs 4094),用于隔离不同的虚拟网络(租户)。
-
IP 头部:在 VXLAN/UDP 头部外面,再封装一个新的 IP 头部。这个IP头部的源IP是源VTEP的IP,目的IP是目的VTEP的IP。这个IP地址是在 Underlay 网络中路由的。
-
-
关键组件 - VTEP:
-
VXLAN 隧道端点 是 Overlay 和 Underlay 的边界和桥梁。它通常是物理交换机(硬件VTEP)或虚拟交换机(如vSphere的vDS,Linux bridge,软件VTEP)。
-
职责:执行“封装”和“解封装”操作。它就像是物流系统中的“本地转运中心”。
-
-
简单来说:Overlay 就是通过 VTEP 的封装技术,在 Underlay 的 IP 网络上“模拟”出一个庞大的、虚拟的二层广播域。
三.VXLAN 报文整体结构
一个完整的 VXLAN 报文就像是一个“俄罗斯套娃”,从外到内依次是:
外层 Ethernet 头 -> 外层 IP 头 -> 外层 UDP 头 -> VXLAN 头 -> 原始的内层以太网帧
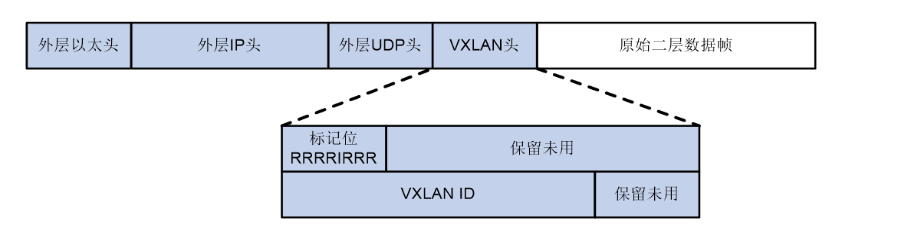
-
两层封装:VXLAN 创建了两套独立的寻址系统。
-
外层头:用于在 Underlay(物理网络)中路由,使用 VTEP 的 IP。
-
内层头:用于在 Overlay(虚拟网络)中通信,使用 虚拟机的 MAC/IP。
-
-
VNI 是关键:VNI 提供了网络隔离,类似于 VLAN ID,但规模巨大。只有拥有相同 VNI 的虚拟机才能相互通信。
-
负载均衡:UDP 源端口由哈希计算得出,这使得网络设备可以将不同的 VXLAN 流映射到不同的物理路径上,充分利用所有可用链路。
-
对中间网络透明:Underlay 网络中的路由器和交换机完全不需要理解 VXLAN 头或内层帧的内容。它们只根据最外层的 IP 和 MAC 地址进行转发,就像处理任何一个普通的 IP 数据包一样。
VXLAN 在技术上利用 UDP 作为其传输层协议,但它本质上是一个服务于网络虚拟化的隧道协议,而非一个面向最终用户的应用层协议。
四. 报文封装解析
假设我们有一个数据中心,里面运行着两个虚拟机:
-
VM-A
-
MAC 地址:
00:11:22:33:44:AA -
IP 地址:
192.168.10.10 -
所在物理服务器上的 VTEP-1 的 IP 是
10.1.1.100
-
-
VM-B
-
MAC 地址:
00:11:22:33:44:BB -
IP 地址:
192.168.10.20 -
所在物理服务器上的 VTEP-2 的 IP 是
10.1.2.200
-
-
VXLAN 网络标识符:
VNI = 5000
现在,VM-A 要 Ping VM-B。
第1步:原始以太网帧(Overlay 网络流量)
在 VTEP-1 进行封装之前,VM-A 发出的原始 ICMP 请求帧是这样的:
text
【 原始以太网帧 - 由 VM-A 发出 】 ------------------------------------------------------------------- | 字段 | 值 | ------------------------------------------------------------------- | 目的 MAC地址 | 00:11:22:33:44:BB (VM-B的MAC) | | 源 MAC地址 | 00:11:22:33:44:AA (VM-A的MAC) | | Ethertype | 0x0800 (表示载荷是IPv4) | | ----------------------------------------------------------------- | | 【内层IP头】 | | 源IP地址 | 192.168.10.10 (VM-A) | | 目的IP地址 | 192.168.10.20 (VM-B) | | 协议 | 1 (ICMP) | | ----------------------------------------------------------------- | | 【内层ICMP数据】 | | Type/Code | 8/0 (Echo Request) | | 校验和 | ... (计算得出) | | 数据 | "Ping Data" | -------------------------------------------------------------------
这个帧就是需要被运送的“货物”。
第2步:VTEP-1 进行 VXLAN 封装
VTEP-1 收到这个原始帧后,会执行以下操作:
-
识别出目标 VM-B 位于另一个 VTEP(VTEP-2)后面。
-
决定将这个原始帧封装到一个 VXLAN 包中,发往
10.1.2.200。 -
开始“打包”,添加各层头部。
封装后的完整 VXLAN 报文如下:
text
【 完整的 VXLAN 封装报文 】 =================================================================== 【外层以太网头 - 用于物理网络第一跳】 ------------------------------------------------------------------- | 目的 MAC地址 | (例如: 00:50:56:XX:XX:XX) // 去往10.1.2.200的下一跳路由器MAC | | 源 MAC地址 | (例如: 00:50:56:YY:YY:YY) // VTEP-1的物理MAC | | Ethertype | 0x0800 (表示外层载荷是IPv4) | ------------------------------------------------------------------- 【外层IP头 - Underlay网络路由的依据】 ------------------------------------------------------------------- | 版本/IHL | 4 | | 服务类型 | ... | | 总长度 | (原始帧长 + 50字节左右的VXLAN开销) | | 标识符 | ... | | 标志/片偏移 | ... | | TTL | 64 | | 协议 | 17 (表示后面是UDP) | | 头部校验和 | ... | | 源IP地址 | 10.1.1.100 (VTEP-1的IP) | | 目的IP地址 | 10.1.2.200 (VTEP-2的IP) | ------------------------------------------------------------------- 【外层UDP头 - VXLAN的传输载体】 ------------------------------------------------------------------- | 源端口 | 54321 // VTEP-1动态计算生成,用于负载均衡 | | 目的端口 | 4789 // VXLAN标准端口号 | | UDP长度 | (原始帧长 + 8字节VXLAN头 + 8字节UDP头) | | UDP校验和 | 0x0000 (可能被禁用) 或 ... | ------------------------------------------------------------------- 【VXLAN头 - Overlay网络的标识】 ------------------------------------------------------------------- | Flags | 0x08 (二进制: 00001000, 第5位'I'位=1,有效) | | Reserved | 0x000000 (24位保留) | | VNI | 0x01388 (24位, 十进制5000) // 关键!标识租户 | | Reserved | 0x00 (8位保留) | ------------------------------------------------------------------- 【原始以太网帧 - 作为载荷被完整封装】 ------------------------------------------------------------------- | 目的 MAC地址 | 00:11:22:33:44:BB (VM-B的MAC) // 内层帧开始 | | 源 MAC地址 | 00:11:22:33:44:AA (VM-A的MAC) | | Ethertype | 0x0800 | | ----------------------------------------------------------------- | | 【内层IP头】 | | 源IP地址 | 192.168.10.10 (VM-A) | | 目的IP地址 | 192.168.10.20 (VM-B) | | 协议 | 1 (ICMP) | | ----------------------------------------------------------------- | | 【内层ICMP数据】 | | Type/Code | 8/0 (Echo Request) | | 校验和 | ... | | 数据 | "Ping Data" | ------------------------------------------------------------------- ===================================================================
关键点解析
-
两层寻址:
-
外层头:
源IP: 10.1.1.100->目的IP: 10.1.2.200。Underlay 网络的路由器只关心这个,它们把整个包当作一个普通的 UDP 数据包来路由。 -
内层头:
源IP: 192.168.10.10->目的IP: 192.168.10.20。Overlay 网络中的 VM-A 和 VM-B 只关心这个。它们完全不知道自己的数据包被封装了。
-
-
VNI 的作用:VTEP-2 收到包后,通过查看 VNI=5000,就知道这个包属于哪个逻辑网络,然后只将其转发给同样属于 VNI 5000 的虚拟机。
-
负载均衡:UDP 源端口
54321是计算出来的。如果 VM-A 同时有多个流发往 VM-B,每个流的源端口可能不同,这样 Underlay 网络就可以将这些流分散到不同的链路上。
总结
通过这个例子,你可以清晰地看到 VXLAN 如何将一个 二层以太网帧 “装进” 一个 四层 UDP 包 里,然后利用三层的 IP 网络进行传输。这正是“Overlay over Underlay”思想的完美体现:在基础的 IP 网络(Underlay)之上,构建一个虚拟的二层网络(Overlay)。
五、UDP 的源端口是随机的,可用于多路径负载分担?怎么理解,负载分担的几要素,五元组:源ip,目的ip,协议号,源端口,目的端口,一定要一个不同的,保证哈希均匀,做哈希的时候。ecmp ,代价,芯片有算法。
为什么需要不同的五元组?
ECMP(等价多路径路由)的核心思想是:通过网络设备(通常是交换机或路由器)上的硬件芯片,将不同的“数据流”分散到多条并行的物理链路上,以充分利用带宽。
这个“区分数据流”的依据,就是您提到的 五元组:
-
源 IP
-
目的 IP
-
协议号
-
源端口
-
目的端口
芯片会对这五个字段进行一个哈希运算,得到一个数值。然后根据这个哈希值,从可用的路径中选择一条(例如,哈希值 % 路径数)。
关键在于:如果两个数据包的五元组完全相同,它们的哈希结果也必然相同,从而会被始终分配到同一条路径上。 这就无法实现负载分担。
一个具体的例子
假设 VTEP-1 (10.1.1.100) 和 VTEP-2 (10.1.2.200) 之间有 4 条物理链路做 ECMP。
场景 1:没有动态源端口(所有流量哈希结果相同)
-
VM1 (
192.168.10.10) 向 VM2 (192.168.10.20) 传输一个大文件。 -
VM1 又向 VM2 发起一个视频会议流。
-
如果没有动态源端口,假设 VTEP-1 使用固定源端口
12345。 -
那么这两个应用流量的外层五元组完全一样,哈希结果一样,两条流量会被压到同一条物理链路上,而其他3条链路空闲。负载分担失败。
场景 2:有动态源端口(不同流量哈希结果不同)
-
文件传输流:内层字段是
(Src=192.168.10.10, Dst=192.168.10.20, Proto=TCP, SrcPort=12345, DstPort=22)。哈希后,VTEP-1 为其分配 UDP 源端口34567。 -
视频会议流:内层字段是
(Src=192.168.10.10, Dst=192.168.10.20, Proto=UDP, SrcPort=54321, DstPort=5000)。哈希后,VTEP-1 为其分配 UDP 源端口45678。
现在,两个 VXLAN 包的外层头部分别是:
-
文件传输包:
(SrcIP=10.1.1.100, DstIP=10.1.2.200, Proto=UDP, SrcPort=34567, DstPort=4789) -
视频会议包:
(SrcIP=10.1.1.100, DstIP=10.1.2.200, Proto=UDP, SrcPort=45678, DstPort=4789)
对于 Underlay 网络的 ECMP 交换机来说:
-
它看到的是两个五元组不同的普通 UDP 数据包。
-
它对这两个包计算哈希,结果很可能不同。
-
于是,它可能将文件传输流分配到 路径1,将视频会议流分配到 路径2。
-
成功实现了负载分担!
关于“代价”和“芯片”
您提到的“代价”和“芯片有算法”也非常到位。
-
代价:
-
计算开销:VTEP 需要对每个流的第一个包进行内层字段的哈希计算以确定源端口。这是一个轻微的性能代价,但通常由专用硬件或优化的软件实现,影响很小。
-
状态跟踪:为了确保同一个“流”(如一个TCP连接)的所有包使用相同的源端口(避免乱序),VTEP 需要维护一个流表,记录内层流到外层UDP端口的映射。
-
-
芯片有算法:
-
现代交换机和路由器的转发 ASIC 就是为了高速处理这类任务而生的。
-
哈希算法:芯片内置了高效的哈希算法(如 CRC32, XOR),可以在纳秒级别完成五元组的哈希计算。
-
ECMP 表:芯片维护一个 ECMP 组表,里面包含了多条下一跳的路径。哈希计算的结果直接作为索引,从这个表中选取一条路径,整个过程在硬件流水线中一气呵成,几乎没有延迟。
-
总结
VXLAN 使用动态的 UDP 源端口,是一个为了解决 Underlay 网络 ECMP 负载分担 而精心设计的机制。
-
目的:为固定的 VTEP 对之间的流量创造差异性。
-
方法:通过对内层流量的多个字段进行哈希,将结果映射到 UDP 源端口上。
-
效果:使得 Underlay 网络设备能够基于完整且多变的外层五元组进行高效的哈希计算,将不同的 Overlay 流量流分散到不同的物理路径上,从而充分利用网络带宽,避免拥塞。
这是一个完美结合了四层协议特性和三层路由技术的经典设计。
六.水平分割
水平分割的核心原则非常简单直接:
从一个接口学到的路由信息,不再从同一个接口发送出去。
这是一种用于防止路由环路和广播风暴的基本机制。
1. 三层网络中的水平分割
这主要应用于运行距离矢量路由协议的网络中,如 RIP 和 EIGRP。
-
工作原理:路由器认为,如果它从某个邻居路由器那里学到了一条去往网络 A 的路由,那么它就不应该再把这个路由信息回传给同一个邻居。因为那个邻居本来就知道这条路,再告诉它纯属多余,更糟糕的是,在拓扑变化时这可能形成环路。
举个例子:
假设有三台路由器连接成一个环:
text
[Router A] --- [Router B] --- [Router C]
| |
--------------[----------------
-
没有水平分割时(可能产生环路):
-
C 连接网络 10.1.1.0/24。它告诉 B:“我能到达 10.1.1.0/24”。
-
B 学习到这条路由,然后告诉 A:“我能到达 10.1.1.0/24”。
-
A 学习到这条路由,然后告诉 C:“我能到达 10.1.1.0/24”。
-
此时,如果 C 到 10.1.1.0/24 的链路故障,但 C 还没来得及通知所有人,它可能会错误地从 A 那里学到一条去往自己直连网络的路由,从而形成环路:C -> A -> B -> C。
-
-
有水平分割时(避免环路):
-
C 告诉 B:“我能到达 10.1.1.0/24”。
-
B 从与 C 相连的接口学到了这条路由。根据水平分割原则,B 不会再从这个相同的接口发消息告诉 C “我能到达 10.1.1.0/24”。
-
B 会从其他接口(比如朝向 A 的接口)告诉 A。
-
A 学到后,也不会把它发回给 B。
-
这样就从根源上切断了环路的可能性。
-
在三层网络中,水平分割通常是默认启用的。
2. 二层网络中的水平分割
这主要应用于传统的 二层交换网络 和 帧中继 等环境中。
-
工作原理:交换机从一个端口收到广播、组播或未知单播帧时,会将其从所有其他端口泛洪出去。但如果启用了水平分割,交换机不会将这个帧再发回它接收到的那个端口。
举个例子:
假设一个简单的 Hub-and-Spoke 拓扑:
text
[Server A]
|
[Switch S]
/ \
[PC B] [PC C]
-
没有水平分割时(产生不必要的流量):
-
PC B 发送一个广播帧(例如 ARP 请求)。
-
交换机 S 从连接 B 的端口收到该帧。
-
交换机 S 将其泛洪到所有其他端口,即发往 Server A 和 PC C。
-
同时,它也可能愚蠢地将其发回给 PC B(虽然 PC B 会丢弃自己发出的帧,但这仍然浪费了带宽和设备的处理能力)。
-
-
有水平分割时(优化流量):
-
PC B 发送广播帧。
-
交换机 S 从连接 B 的端口收到该帧。
-
根据水平分割,交换机 S 绝不会再将这个帧从端口 B 发回去。它只泛洪到其他端口(A 和 C)。
-
这减少了网络上的冗余流量。
-
在复杂的二层网络(尤其是存在多条路径时),仅仅依靠水平分割不足以防止环路,因此需要 STP 来阻塞冗余路径。
水平分割与 VXLAN
在 VXLAN 环境中,情况变得有些特殊:
-
逻辑上的二层网络,物理上的三层网络:
-
在 Overlay 层面,它是一个大的二层广播域。
-
在 Underlay 层面,它是一个三层 IP 网络。
-
-
水平分割的应用:
-
在 Underlay 中:Underlay 通常运行 OSPF 或 BGP 等链路状态或路径矢量协议。水平分割不用于 OSPF。对于 BGP,则有自己更复杂的环路防止机制(如 AS_PATH)。
-
在 Overlay 中:VTEP 之间建立了全互联的 VXLAN 隧道。对于一个 VTEP 来说,它从某个 VXLAN 隧道口(这是一个逻辑接口)收到 BUM(广播、未知单播、组播)流量后,不应该再将其从同一个隧道口发回去。这本质上也是一种水平分割思想。
然而,VXLAN 控制平面(如 EVPN)通过 BGP 分发 MAC/IP 路由信息,其环路防止依赖于 BGP 本身的机制,而不是简单的接口级水平分割。
-
总结
| 特性 | 三层网络(RIP/EIGRP) | 二层网络(传统交换) | VXLAN Overlay |
|---|---|---|---|
| 目的 | 防止路由环路 | 防止广播风暴和优化流量 | 防止在逻辑隧道间形成环路 |
| 实现方式 | 不从接收接口回传路由更新 | 不从接收端口回泛洪帧 | 控制平面通过 BGP 规则,数据平面逻辑上不向入隧道回传 BUM 流量 |
| 关键点 | 距离矢量协议的基本特性 | STP 的补充 | 由更复杂的控制平面协议(如 EVPN)保障 |
简单来说,水平分割是一种“知恩不图报”的智慧:“你告诉我的路,我绝不会再原路指回给你,因为这既没必要,又很危险。”
七.VXLAN VTEP ARP/ND
在 VXLAN 环境中,ARP(IPv4) 和 ND(Neighbor Discovery,IPv6 的等效协议) 的行为与传统二层网络有显著不同。VTEP 在其中扮演着至关重要的角色。
核心问题:广播域的延伸与限制
在传统局域网中,ARP 依靠广播来工作。但在 VXLAN 中:
-
Overlay 是一个巨大的逻辑二层广播域。
-
Underlay 是一个三层 IP 网络,默认不转发二层广播。
那么,当一个虚拟机发出一个 ARP 请求(广播帧)时,它如何穿越 Underlay 网络到达另一台主机上的目标虚拟机呢?
VTEP 通过两种主要机制来解决这个问题:
机制一:多播泛洪与学习(传统方式,Flood-and-Learn)
这是 VXLAN 最初定义的基础工作方式。
1. ARP 请求的处理(BUM 流量)
-
场景:VM1 (
192.168.10.10) 想知道 VM2 (192.168.10.20) 的 MAC 地址。 -
过程:
-
VM1 发出一个广播 ARP 请求:"谁是
192.168.10.20?" -
源 VTEP-1 收到这个广播帧。它识别出这是 BUM(广播、未知单播、组播)流量。
-
VTEP-1 将这个原始 ARP 请求帧进行 VXLAN 封装。关键点在于:
-
外层目的 IP 地址:不再是一个单播 IP,而是一个预配置的 Underlay 多播组地址(例如
239.1.1.100)。 -
VNI 被设置在 VXLAN 头中。
-
-
这个多播包在 Underlay 网络中被路由。所有加入了该多播组的 VTEP(即所有属于同一 VXLAN 段的 VTEP)都会收到这个包。
-
这些 VTEP(包括 VTEP-2)解封装报文,还原出原始的 ARP 广播帧。
-
VTEP-2 将这个帧发送给其本地的 VM2。
-
-
结果:一次 ARP 请求,通过 Underlay 的多播,被泛洪到了所有相关的 VTEP 和虚拟机。
2. ARP 回复的处理(单播流量)
-
过程:
-
VM2 收到 ARP 请求,并发送一个单播 ARP 回复:"我是
192.168.10.20,我的 MAC 是BB:BB:BB:BB:BB:BB"。 -
VTEP-2 收到这个回复。此时,它已经知道了 VM1 的 MAC 地址(从收到的 ARP 请求中学习到)。
-
VTEP-2 进行 VXLAN 封装,但这次外层目的 IP 是 VTEP-1 的单播 IP 地址 (
10.1.1.100)。 -
这个单播包通过 Underlay 网络直接发送给 VTEP-1。
-
VTEP-1 解封装后,将 ARP 回复交给 VM1。
-
-
同时,VTEP 会学习:在这个过程里,VTEP-1 和 VTEP-2 都学习到了
VM1 MAC <-> VTEP-1 IP和VM2 MAC <-> VTEP-2 IP的映射关系,并存入本地表项。
缺点:这种方式会产生大量 BUM 流量,效率较低。
机制二:控制平面学习(现代方式,常与 EVPN 结合)
这是现代数据中心更高效、更常用的方式。它避免了泛洪 ARP 请求。
GARP 的用途
-
核心思想:使用一个控制协议(如 EVPN)在 VTEP 之间同步和分发 MAC 和 IP 的映射关系。
-
过程:
-
当 VM2 第一次启动并获得 IP 地址时,它可能会发送一个 GARP(无偿 ARP) 包宣告自己的存在。
-
VTEP-2 收到这个包,它不仅学习到 VM2 的 MAC 地址,还会通过 EVPN 控制平面 向其他所有 VTEP 发送一条路由信息,内容大致是:"主机
BB:BB:BB:BB:BB:BB(IP192.168.10.20) 在我这里(VTEP-210.1.2.200),属于 VNI 5000"。 -
VTEP-1 通过控制平面提前学习到了这条信息,并保存在它的 ARP 抑制表 或 代理 ARP 表 中。
-
当 VM1 后来发送查询
192.168.10.20的 ARP 请求时:-
请求到达 VTEP-1。
-
VTEP-1 检查本地表项,发现它已经知道答案。
-
VTEP-1 直接代答!它代替 VM2 发送一个 ARP 回复给 VM1:"我是
192.168.10.20,我的 MAC 是BB:BB:BB:BB:BB:BB"。 -
这个 ARP 请求永远不会被泛洪到 Underlay 网络。
-
-
-
关键结论
-
VTEP 是 ARP/ND 的智能网关:在 VXLAN 网络中,VTEP 不再是一个简单的二层交换机。它积极参与到 ARP/ND 过程中,要么负责泛洪,要么直接代理应答。
-
目标是减少泛洪:现代 VXLAN 设计的核心趋势是尽可能使用控制平面来分发主机信息,从而最大限度地减少对数据平面泛洪的依赖。这大大提升了网络的效率和可扩展性。
-
对虚拟机透明:无论 VTEP 采用哪种机制,对于虚拟机 VM1 和 VM2 来说,它们感知到的仍然是一个普通的二层网络。ARP 请求和回复的过程在它们看来与传统网络毫无二致。
-
-
GARP 是什么报文?
GARP 的全称是 Gratuitous ARP,中文常翻译为"无偿 ARP"或"** gratuitous ARP**"。
核心概念
GARP 是一个主机主动、未经请求地发送的 ARP 报文,其目的是宣告或更新自己的 IP-MAC 映射关系,而不是为了查询某个 IP 对应的 MAC 地址。
报文特点
一个典型的 GARP 报文有以下关键特征:
-
操作类型:仍然是 ARP 请求。
-
源 IP 和 源 MAC:发送方自己的 IP 和 MAC 地址。
-
IP 地址冲突检测:
-
当一台主机配置了一个 IP 地址后,它会发送一个 GARP 来询问:"有没有人的 IP 地址是 X.X.X.X?"
-
如果收到回应,说明这个 IP 已经被使用,就会报告地址冲突。
-
-
主动更新邻居的 ARP 缓存(这是 VXLAN 场景下最重要的用途):
-
主机通过 GARP 宣告:"大家好!我是 IP 地址 X.X.X.X,我的 MAC 地址是 YY:YY:YY:YY:YY:YY。请更新你们的 ARP 表!"
-
收到这个广播的所有主机,都会用这个新的信息更新它们自己的 ARP 表。
-
-
高可用性(HA)场景:
-
当备用服务器接管了主服务器的服务 IP 时,它会发送 GARP,通知网络上的交换机和其他主机:"这个 IP 现在对应的 MAC 地址是我了!" 从而将流量引导到新的设备。
-
目标 IP 和 目标 MAC:
-
目标 IP 地址:也是发送方自己的 IP 地址(这是与普通 ARP 请求最根本的区别)。
-
目标 MAC 地址:通常是全零 (
00:00:00:00:00:00) 或广播地址 (FF:FF:FF:FF:FF:FF),具体实现可能不同。
-
-
发送方式:广播,让整个广播域内的所有主机都能听到。
-
八.Multi-homing - 多宿(您所说的“双规”)
这指的是一个网络(例如用户站点CE)通过多条链路连接到同一个或不同的服务提供商,以实现冗余和负载分担。这正是您描述的“多PE双规”场景。
核心特点:
关注点:一个站点 的 入网方式。
目的:提供冗余、负载均衡、提高可靠性。
在MPLS VPN中的典型Multi-homing架构:
如图所示,一个CE设备通过两条链路分别连接到两个不同的PE路由器,这就是典型的Multi-homing
-
-
场景:一个公司的总部通过两条不同的运营商线路(或者同一运营商的两个不同接入点)接入互联网或MPLS VPN。
-
DF 选举的设计目标和用武之地。
定义:一台 CE 设备或一个站点,通过多条链路连接到多个 PE 设备。这种连接方式在 EVPN 中称为 Ethernet Segment。
text
[PE1]
|
(链路1)
|
[CE] - (链路2) <- 这个逻辑组就是一个 Ethernet Segment (ES)
|
[PE2]
问题:当网络中有广播、未知单播或组播流量需要从 VXLAN 网络发往这个 CE 时,应该由 PE1 还是 PE2 来发送?
-
如果 PE1 和 PE2 都发送,CE 会收到两份完全相同的数据帧,造成重复流量。
-
这不仅是浪费,还可能给终端设备造成问题。
解决方案:DF 选举
-
EVPN 为每个 Ethernet Segment 设计了一个选举机制。
-
所有连接到同一个 ES 的 PE 之间会通过交换 EVPN 路由(包含 ESI 和 DF 选举社区属性)来进行选举。
-
选举出的 DF 负责:
-
将网络侧的 BUM 流量转发给 CE。
-
处理来自 CE 的 ARP 请求并将其广播到 VXLAN 网络中。
-
-
非 DF 则在这些方面保持沉默,避免重复流量。
结果:对于一个特定的 ES,在任一时刻,有且只有一个 PE 被选举为 DF。
DF 选举的过程简介
选举通常基于以下因素(不同厂商实现可能有细微差别):
-
Ethernet Segment Identifier:选举在每个独立的 ES 内进行。
-
VTEP IP 地址:最常用的算法是取所有候选 PE 的 IP 地址,按一定规则排序,并基于一个 Modulo 运算来选出 DF。
-
可配置的优先级:允许管理员干预选举结果,指定优先的 PE 作为 DF。
Ethernet Segment Identifier:选举在每个独立的 ES 内进行。
VTEP IP 地址:最常用的算法是取所有候选 PE 的 IP 地址,按一定规则排序,并基于一个 Modulo 运算来选出 DF。
结果:对于一个特定的 ES,在任一时刻,有且只有一个 PE 被选举为 DF
-
-
可配置的优先级:允许管理员干预选举结果,指定优先的 PE 作为 DF。
-
Single-Homing 场景
-
定义:一台 CE 设备(服务器、交换机)或一个站点,只通过一条链路连接到一个 PE 设备。
text
[CE] --- (单条链路) --- [PE]
-
DF 选举情况:
-
不需要选举:因为只有一个 PE,这个 PE 理所当然地就是转发流量的唯一出口和入口。
-
即使有选举机制运行,结果也是确定的,只有它自己,所以它永远是 DF。
-
在这个场景下,讨论 DF 选举是多余的。 所有 BUM 流量都由这个唯一的 PE 负责转发给 CE,不存在冲突或重复。
-

开源鸿蒙跨平台开发社区汇聚开发者与厂商,共建“一次开发,多端部署”的开源生态,致力于降低跨端开发门槛,推动万物智联创新。
更多推荐

 11
11 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)