OpenHarmony字符串编辑距离计算 | KMP Levenshtein算法深度解析
本文深入解析了字符串编辑距离(Levenshtein距离)的动态规划算法实现及其应用。文章首先介绍了编辑距离的定义和常见应用场景,如拼写检查、模糊匹配等。重点阐述了基于动态规划的算法原理,包括状态转移方程和边界条件处理。通过Kotlin代码示例详细解析了输入解析、边界处理、动态规划表初始化和填充等关键步骤,并展示了如何回溯编辑路径。该算法具有O(m×n)的时间复杂度,适用于多种字符串相似度计算场景
欢迎加入开源鸿蒙跨平台社区:https://openharmonycrossplatform.csdn.net
摘要
字符串编辑距离(Levenshtein距离)是计算两个字符串相似度的经典算法,广泛应用于拼写检查、模糊匹配、DNA序列比对、版本控制等场景。本文深入解析基于动态规划的编辑距离算法实现,详细解释代码的每个关键部分,并从工程化角度探讨算法的优化策略和实际应用。
1. 算法背景与问题定义
1.1 什么是编辑距离
Levenshtein距离定义为:将一个字符串转换为另一个字符串所需的最少单字符编辑操作次数。允许的编辑操作包括:
- 插入(Insert):在字符串中插入一个字符
- 删除(Delete):从字符串中删除一个字符
- 替换(Replace/Substitute):将字符串中的一个字符替换为另一个字符
1.2 应用场景
- 拼写检查器:判断用户输入的单词是否拼写错误
- 模糊匹配:搜索引擎中的近似查询
- DNA序列比对:生物信息学中的序列相似性分析
- 版本控制:代码差异分析和合并
- 自动纠错:输入法的智能纠错功能
2. 动态规划算法原理
2.1 状态转移方程
设 dp[i][j] 表示字符串 s1 的前 i 个字符转换为字符串 s2 的前 j 个字符所需的最少编辑次数。
状态转移方程:
dp[i][j] = min(
dp[i-1][j] + 1, // 删除 s1[i-1]
dp[i][j-1] + 1, // 在 s1 中插入 s2[j-1]
dp[i-1][j-1] + cost // 替换或匹配(cost = 0 if s1[i-1] == s2[j-1], else 1)
)
边界条件:
dp[0][j] = j(将空字符串转换为 s2 的前 j 个字符需要 j 次插入)dp[i][0] = i(将 s1 的前 i 个字符转换为空字符串需要 i 次删除)
2.2 算法流程
- 初始化:创建 (m+1)×(n+1) 的动态规划表
- 填充表格:按照状态转移方程填充每个
dp[i][j] - 获取结果:
dp[m][n]即为两个字符串的编辑距离 - 回溯路径:从
dp[m][n]回溯到dp[0][0],构造编辑操作序列
3. 代码实现深度解析
3.1 输入解析模块
var str1: String? = null
var str2: String? = null
val lines = payload.lines().map { it.trim() }.filter { it.isNotEmpty() }
lines.forEach { line ->
when {
line.startsWith("str1=", ignoreCase = true) -> {
str1 = line.substringAfter("=").trim()
}
line.startsWith("str2=", ignoreCase = true) -> {
str2 = line.substringAfter("=").trim()
}
}
}
// 如果没有用=格式,尝试按行解析
if (str1 == null && str2 == null && lines.size >= 2) {
str1 = lines[0]
str2 = lines[1]
}
代码解析:
这段代码实现了灵活的输入解析机制,支持两种输入格式,体现了工程实践中的容错性和用户友好性设计。
首先,使用函数式编程风格处理输入:
payload.lines()将输入按行分割map { it.trim() }去除每行的首尾空白字符filter { it.isNotEmpty() }过滤空行
然后,通过 when 表达式匹配不同的输入格式:
- 键值对格式:
str1=hello, str2=world,使用substringAfter("=")提取值 - 多行格式:第一行为
str1,第二行为str2
这种双重解析策略提高了用户体验,用户无需记忆特定的输入格式,系统会自动识别并解析。错误处理也很完善,如果两种格式都无法解析,后续会有明确的错误提示。
3.2 边界条件处理
val m = s1.length
val n = s2.length
if (m == 0) {
return "📏 编辑距离: $n (需要插入 ${n} 个字符)"
}
if (n == 0) {
return "📏 编辑距离: $m (需要删除 ${m} 个字符)"
}
代码解析:
这部分代码处理了算法的边界情况,体现了防御性编程的重要原则。边界条件处理是算法实现的关键环节,直接影响了代码的健壮性。
- 空字符串处理:如果
s1为空,编辑距离等于s2的长度(需要插入所有字符) - 提前返回优化:避免创建大型数组进行无意义的计算,提高效率
- 清晰的输出格式:不仅返回数值,还提供了语义化的说明
这种设计在处理极端情况时尤为重要,避免了后续代码中的数组越界等问题,同时提供了更好的用户体验。
3.3 动态规划表初始化
val dp = Array(m + 1) { IntArray(n + 1) }
// 初始化第一行和第一列
for (i in 0..m) {
dp[i][0] = i
}
for (j in 0..n) {
dp[0][j] = j
}
代码解析:
动态规划表的初始化是算法的基础,这里正确实现了边界条件的设置。
数组创建:
Array(m + 1)创建外层数组,大小为m+1(包含空字符串情况){ IntArray(n + 1) }为每个外层元素创建大小为n+1的内层数组- Kotlin 的数组初始化语法简洁明了
边界初始化:
dp[i][0] = i:将长度为i的字符串转换为空字符串,需要i次删除操作dp[0][j] = j:将空字符串转换为长度为j的字符串,需要j次插入操作
这种初始化方式为后续的状态转移提供了正确的基础,是动态规划算法正确性的关键保证。
3.4 核心动态规划填充逻辑
// 填充动态规划表
for (i in 1..m) {
for (j in 1..n) {
val cost = if (s1[i - 1] == s2[j - 1]) 0 else 1
dp[i][j] = minOf(
dp[i - 1][j] + 1, // 删除
dp[i][j - 1] + 1, // 插入
dp[i - 1][j - 1] + cost // 替换或匹配
)
}
}
代码解析:
这是算法的核心部分,实现了状态转移方程的代码化,体现了动态规划的精髓。
循环结构:
- 双重循环遍历所有可能的状态组合
i从 1 到m,j从 1 到n,确保所有子问题都被求解
字符匹配判断:
s1[i - 1] == s2[j - 1]:注意索引是i-1和j-1,因为dp[i][j]对应s1的前i个字符和s2的前j个字符cost = 0表示字符匹配,无需编辑操作cost = 1表示字符不匹配,需要替换操作
三种操作的最小值选择:
-
删除操作:
dp[i - 1][j] + 1- 删除
s1[i-1],然后解决s1的前i-1个字符到s2的前j个字符的子问题
- 删除
-
插入操作:
dp[i][j - 1] + 1- 在
s1中插入s2[j-1],然后解决s1的前i个字符到s2的前j-1个字符的子问题
- 在
-
替换或匹配操作:
dp[i - 1][j - 1] + cost- 如果字符匹配(cost=0),直接匹配,无需额外操作
- 如果字符不匹配(cost=1),替换
s1[i-1]为s2[j-1]
minOf 函数的使用:
- Kotlin 的
minOf函数接受多个参数,返回最小值 - 这种写法比嵌套
if-else更简洁、可读性更强
这个核心循环的时间复杂度为 O(m×n),是算法的主要计算开销。
3.5 编辑路径回溯实现
// 回溯编辑路径
val operations = mutableListOf<String>()
var i = m
var j = n
while (i > 0 || j > 0) {
if (i > 0 && j > 0 && s1[i - 1] == s2[j - 1]) {
operations.add(0, "保持 '${s1[i - 1]}' (位置 $i)")
i--
j--
} else {
val del = if (i > 0) dp[i - 1][j] else Int.MAX_VALUE
val ins = if (j > 0) dp[i][j - 1] else Int.MAX_VALUE
val rep = if (i > 0 && j > 0) dp[i - 1][j - 1] else Int.MAX_VALUE
when {
del <= ins && del <= rep -> {
operations.add(0, "删除 '${s1[i - 1]}' (位置 $i)")
i--
}
ins <= del && ins <= rep -> {
operations.add(0, "插入 '${s2[j - 1]}' (位置 ${j})")
j--
}
else -> {
operations.add(0, "替换 '${s1[i - 1]}' → '${s2[j - 1]}' (位置 $i)")
i--
j--
}
}
}
}
代码解析:
回溯算法是动态规划的重要补充,它不仅能给出编辑距离的数值,还能展示具体的编辑操作序列,这对于理解算法和实际应用都非常有价值。
回溯起点:
- 从
dp[m][n]开始,即最终结果位置 - 目标是回溯到
dp[0][0],即空字符串到空字符串(无需操作)
字符匹配处理:
- 如果当前字符匹配(
s1[i-1] == s2[j-1]),说明这部分无需编辑 - 直接向前移动,记录"保持"操作
- 这是回溯中的最优路径,因为它不需要任何编辑成本
三种操作的判断:
- 计算三种可能的前驱状态的值
- 使用
Int.MAX_VALUE处理边界情况(当i或j为 0 时,某些操作不可行) - 选择值最小的操作(即最优路径)
操作记录方式:
- 使用
operations.add(0, ...)在列表开头插入,这样最终列表是正序的 - 记录操作类型、涉及的字符和位置信息
- 格式化字符串使用 Kotlin 的字符串模板,清晰易读
回溯终止条件:
while (i > 0 || j > 0):只要还有字符未处理就继续- 当
i和j都为 0 时,回溯完成
这个回溯过程的时间复杂度为 O(m + n),因为最多回溯 m + n 步。
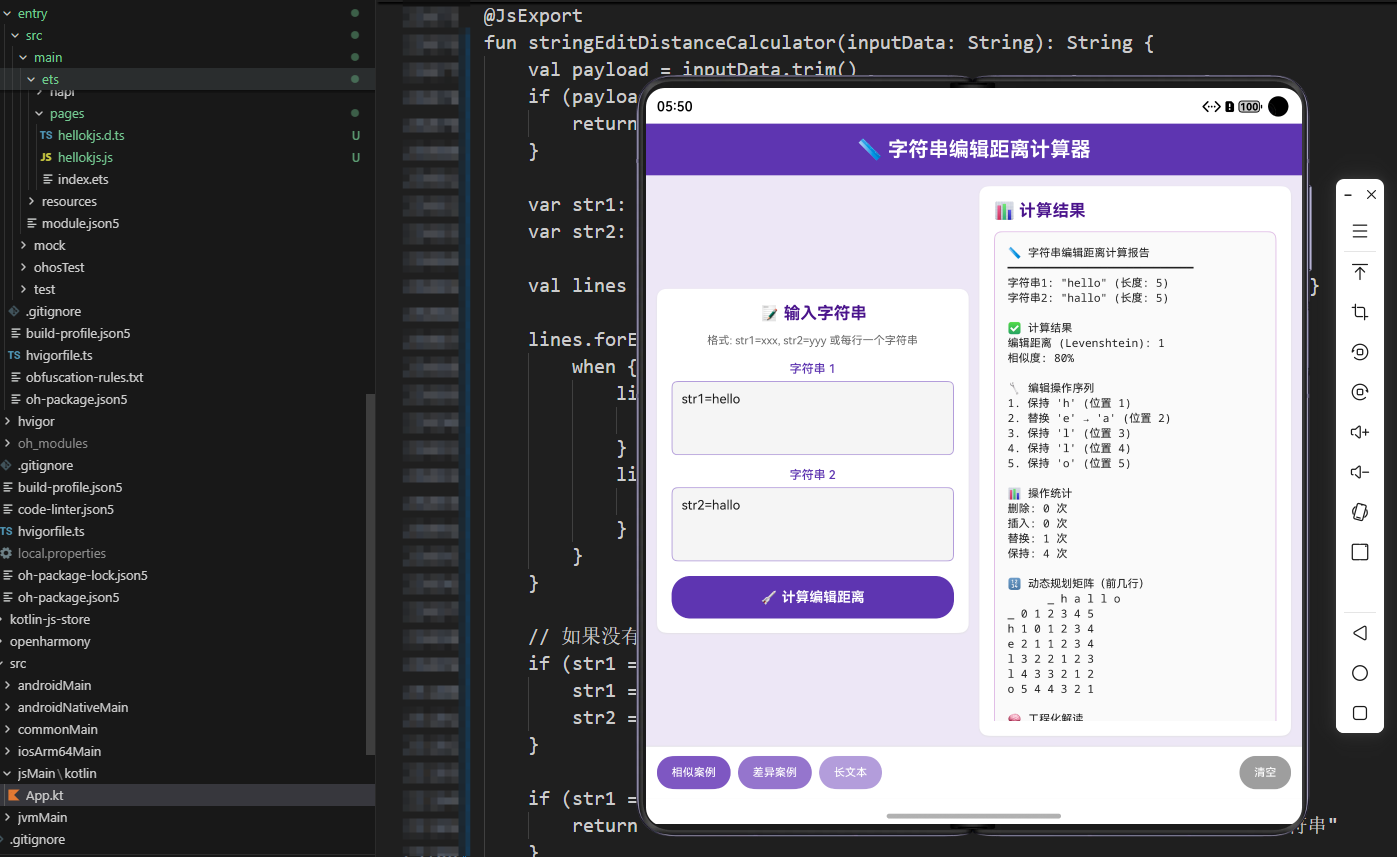
3.6 相似度计算
val maxLen = maxOf(m, n)
val similarity = if (maxLen == 0) {
1.0
} else {
(maxLen - distance).toDouble() / maxLen * 100.0
}
代码解析:
相似度计算将编辑距离转换为更直观的百分比形式,便于用户理解两个字符串的相似程度。
相似度公式:
similarity = (maxLen - distance) / maxLen * 100- 编辑距离越小,相似度越高
- 当两个字符串完全相同时,编辑距离为 0,相似度为 100%
- 当两个字符串完全不同(编辑距离等于较长字符串的长度)时,相似度为 0%
边界处理:
- 如果两个字符串都为空(
maxLen == 0),相似度为 100%(都为空字符串,视为相同) - 使用
toDouble()确保浮点数运算,避免整数除法的问题
输出格式化:
- 乘以 100.0 转换为百分比
- 后续使用
round2()函数保留两位小数,提高输出的可读性
3.7 操作统计分析
val deleteCount = operations.count { it.startsWith("删除") }
val insertCount = operations.count { it.startsWith("插入") }
val replaceCount = operations.count { it.startsWith("替换") }
val keepCount = operations.count { it.startsWith("保持") }
代码解析:
操作统计提供了编辑操作的分布情况,有助于理解两个字符串的差异特征。
统计方法:
- 使用 Kotlin 的高阶函数
count配合 lambda 表达式 startsWith()方法匹配操作类型的前缀- 这种方式简洁高效,体现了函数式编程的优势
统计意义:
- 删除操作多:说明第一个字符串包含很多第二个字符串不需要的字符
- 插入操作多:说明第一个字符串缺少很多第二个字符串需要的字符
- 替换操作多:说明两个字符串在相同位置有很多不同的字符
- 保持操作多:说明两个字符串有很多相同的部分
这些统计数据可以用于:
- 算法性能分析
- 用户界面展示
- 进一步的文本处理(如自动纠错建议)
3.8 动态规划矩阵可视化
if (m <= 10 && n <= 10) {
builder.appendLine("🔢 动态规划矩阵(前几行)")
builder.append(" ")
for (j in 0..minOf(n, 10)) {
builder.append(if (j == 0) "_ " else "${s2[j - 1]} ")
}
builder.appendLine()
for (i in 0..minOf(m, 10)) {
builder.append(if (i == 0) "_ " else "${s1[i - 1]} ")
for (j in 0..minOf(n, 10)) {
builder.append("${dp[i][j]} ")
}
builder.appendLine()
}
}
代码解析:
矩阵可视化是算法教学和调试的重要工具,可以帮助理解动态规划的工作原理。
条件限制:
- 只在字符串长度 <= 10 时显示矩阵,避免输出过长影响可读性
- 这是工程实践中常见的优化策略
表头设计:
- 第一行显示
s2的字符(列索引) - 第一列显示
s1的字符(行索引) - 使用
_表示空字符串的情况
矩阵输出格式:
- 使用
StringBuilder高效构建字符串 - 对齐输出,每列之间用空格分隔
- 清晰的布局有助于理解状态转移过程
教学价值:
- 用户可以直观看到每个子问题的解
- 可以手动验证算法的正确性
- 有助于理解动态规划的记忆化特性
4. 算法复杂度分析
4.1 时间复杂度
- 填充动态规划表:O(m × n),需要计算 (m+1) × (n+1) 个状态
- 回溯编辑路径:O(m + n),最多回溯 m + n 步
- 总体时间复杂度:O(m × n)
4.2 空间复杂度
- 动态规划表:O(m × n),存储所有子问题的解
- 操作列表:O(m + n),存储编辑操作序列
- 总体空间复杂度:O(m × n)
4.3 空间优化
可以使用滚动数组优化空间复杂度到 O(min(m, n)):
// 只保留前一行和当前行的数据
val prev = IntArray(n + 1)
val curr = IntArray(n + 1)
5. 算法优化与扩展
5.1 空间优化
对于大规模字符串,可以使用空间优化版本:
- 只存储两行数据(前一行和当前行)
- 空间复杂度从 O(m×n) 降低到 O(min(m,n))
5.2 性能优化
- 提前终止:如果只关心距离是否小于阈值,可以在计算过程中提前终止
- 并行计算:对于多个字符串对的批量计算,可以并行处理
- 缓存优化:对于重复计算的字符串对,可以使用缓存
5.3 扩展应用
- 加权编辑距离:不同操作可以有不同的成本
- Damerau-Levenshtein距离:支持相邻字符交换操作
- 最长公共子序列(LCS):只允许插入和删除操作
- 模糊匹配:在搜索和推荐系统中应用
6. 工程化实践要点
6.1 错误处理
代码实现了完善的错误处理机制:
- 输入验证:检查字符串是否为空、格式是否正确
- 边界条件:处理空字符串等特殊情况
- 异常安全:避免数组越界等运行时错误
6.2 用户体验
- 清晰的输出格式:使用分隔线和图标提高可读性
- 详细的操作序列:展示具体的编辑步骤
- 可视化矩阵:帮助理解算法过程
- 统计信息:提供操作类型分布
6.3 代码可维护性
- 函数职责清晰:每个部分功能明确
- 命名规范:变量和函数名具有描述性
- 注释完善:关键逻辑都有说明
- 模块化设计:易于扩展和修改
7. 实际应用案例
7.1 拼写检查
val userInput = "helo"
val dictionary = listOf("hello", "help", "hole")
val suggestions = dictionary.map { word ->
word to stringEditDistanceCalculator("str1=$userInput\nstr2=$word")
}.sortedBy { it.second } // 按编辑距离排序
7.2 模糊搜索
在搜索引擎中,用户输入可能有拼写错误,可以使用编辑距离找到最相似的查询结果。
7.3 DNA序列比对
在生物信息学中,编辑距离用于比较DNA序列的相似性,帮助识别基因突变。
8. 总结
字符串编辑距离算法是动态规划的经典应用,本文详细解析了算法的每个实现细节,从输入解析到结果输出,从核心算法到回溯路径,全面展示了如何实现一个高质量、易维护的编辑距离计算工具。
核心要点:
- 动态规划是解决编辑距离问题的标准方法,时间复杂度 O(m×n)
- 回溯算法可以还原具体的编辑操作序列,提高算法的实用性
- 边界条件处理是算法健壮性的关键
- 可视化输出有助于理解算法过程和调试
未来优化方向:
- 实现空间优化版本(O(min(m,n)))
- 支持加权编辑距离
- 添加批量计算功能
- 集成到实际应用系统中
通过深入理解算法原理和代码实现,我们可以更好地将编辑距离算法应用到实际项目中,解决各种字符串相似性分析的实际问题。

开源鸿蒙跨平台开发社区汇聚开发者与厂商,共建“一次开发,多端部署”的开源生态,致力于降低跨端开发门槛,推动万物智联创新。
更多推荐


 24
24 0
0- 0



 已为社区贡献17条内容
已为社区贡献17条内容

所有评论(0)