kmp openharmony 时间序列相关性分析与指标联动洞察
时间序列相关性分析引擎 本案例实现了一个基于Kotlin Multiplatform和OpenHarmony的时间序列相关性分析引擎,用于分析不同指标间的联动关系。核心功能包括: 输入处理:支持多条等长时间序列输入,格式为"序列名称:数值列表",可灵活使用多种分隔符 核心算法:采用皮尔逊相关系数计算任意两条序列之间的线性相关性,支持正相关、负相关和弱相关分析 输出报告:生成包含
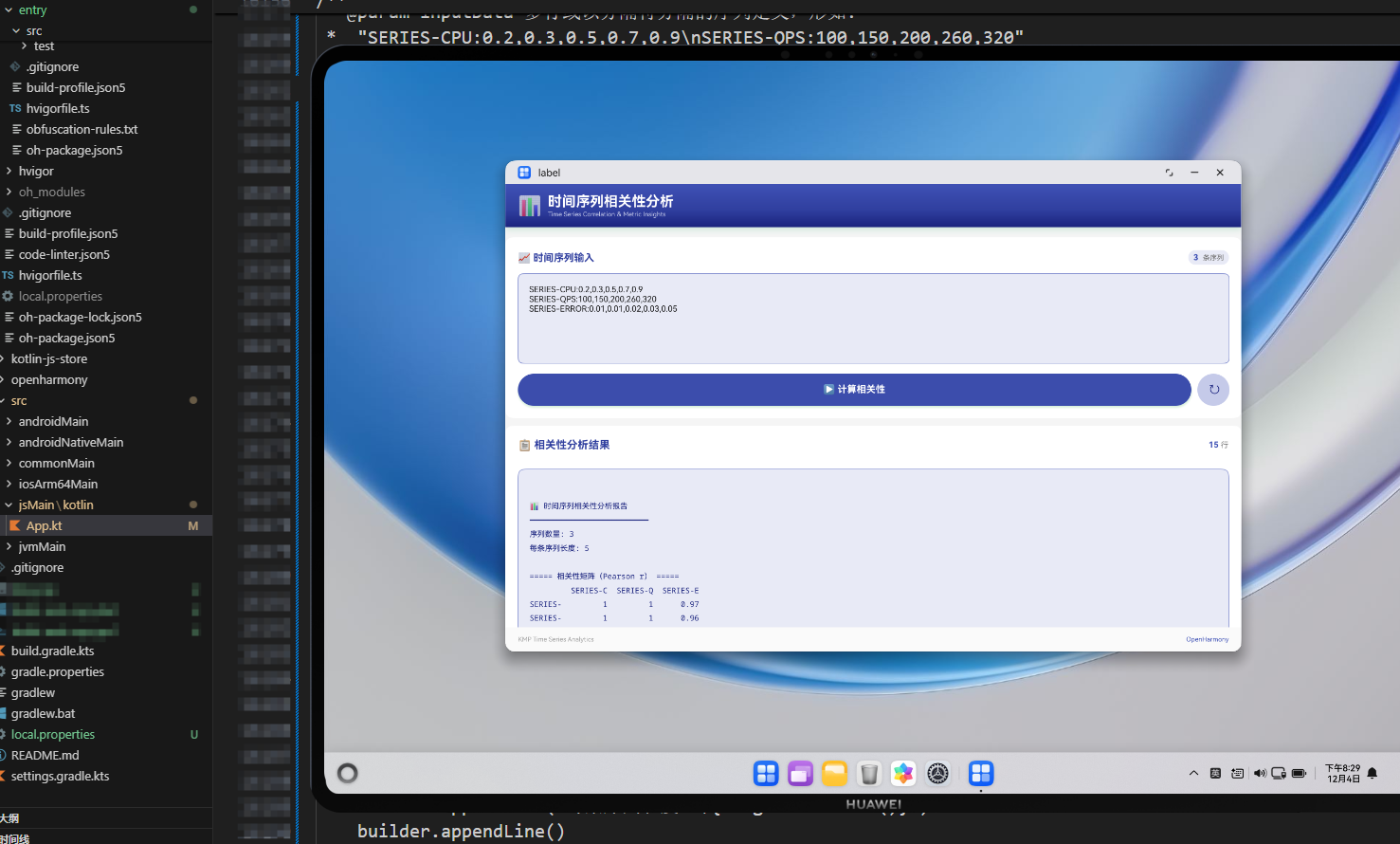
在完成「滑动窗口统计分析」之后,时间序列领域中一个非常自然的下一步问题是:不同指标之间究竟有没有联动关系?
比如 CPU 利用率上升时,请求量(QPS)是否也在上升?错误率是否跟某些波动高度相关?
基于 Kotlin Multiplatform(KMP)与 OpenHarmony,本案例实现了一个 时间序列相关性分析引擎:
- 支持多条等长时间序列输入(如 CPU、QPS、ErrorRate 等);
- 计算任意两条序列之间的 皮尔逊相关系数(Pearson r);
- 生成「相关性矩阵 + 文本解读」的分析报告;
- 通过 ArkTS 单页面板在 OpenHarmony 设备上进行可视化呈现。
本文包含 Kotlin 核心算法实现、JavaScript 桥接代码以及 ArkTS 高级 UI 面板示例。
一、时间序列相关性分析的背景
在真实的监控与运维场景中,我们经常需要回答类似问题:
- CPU 飙高时,是不是 QPS 也在同步放大?
- 错误率上升,到底是因为流量增大,还是因为后端某个服务异常?
- 某个业务指标(如转化率)与哪个底层系统指标最相关?
如果只看每条序列自身的滑动窗口统计(均值、最大值等),我们很难回答这些「联动」问题。
此时,就需要引入 相关性分析:
- 正相关:两个指标同涨同跌(如 QPS 与 CPU);
- 负相关:一个上涨时另一个下跌(如缓存命中率与后端 DB 压力);
- 相关性弱:两者几乎独立变化。
本案例使用最常见的 皮尔逊相关系数 来量化这种线性关系。
二、Kotlin 时间序列相关性分析引擎
1. 输入格式约定
为了与之前的案例风格统一,本案例采用简单、可读性强的文本输入格式。
每条时间序列一行,格式为:
序列名称:逗号分隔的数值列表
示例:
SERIES-CPU:0.2,0.3,0.5,0.7,0.9
SERIES-QPS:100,150,200,260,320
SERIES-ERROR:0.01,0.01,0.02,0.03,0.05
支持的特性:
- 多行输入,每行一条序列;
- 也可以使用
;或|作为分隔符,方便从脚本或配置中复制; - 所有序列长度必须一致,否则会返回明确的错误提示。
2. 多序列解析与数据结构设计
我们用一个简单的数据类来描述命名序列:
private data class NamedSeries(
val name: String,
val values: List<Double>
)
对应的解析函数:
private fun parseMultiSeriesInput(raw: String): List<NamedSeries> {
val result = mutableListOf<NamedSeries>()
val segments = raw.split("\n", ";", "|")
.map { it.trim() }
.filter { it.isNotEmpty() }
for (segment in segments) {
val idx = segment.indexOf(':')
if (idx <= 0) continue
val name = segment.substring(0, idx).trim()
val valuesPart = segment.substring(idx + 1).trim()
val values = valuesPart.split(",")
.mapNotNull { it.trim().toDoubleOrNull() }
if (name.isNotEmpty() && values.isNotEmpty()) {
result += NamedSeries(name = name, values = values)
}
}
return result
}
设计要点:
- 支持多种分隔符(
\n/;/|),适应不同输入来源; - 对非法行(缺少冒号、无法解析为数字)直接跳过,保证鲁棒性;
- 只保留名称非空、数值列表非空的序列,避免后续计算出错。
3. 皮尔逊相关系数算法实现
皮尔逊相关系数 ( r_{xy} ) 的定义为:
[
r_{xy} = \frac{\sum (x_i - \bar{x})(y_i - \bar{y})}{\sqrt{\sum (x_i - \bar{x})^2} \sqrt{\sum (y_i - \bar{y})^2}}
]
在 Kotlin 中对应实现如下:
private fun pearsonCorrelation(x: List<Double>, y: List<Double>): Double {
if (x.size != y.size || x.isEmpty()) return 0.0
val n = x.size
val meanX = x.average()
val meanY = y.average()
var num = 0.0
var denX = 0.0
var denY = 0.0
for (i in 0 until n) {
val dx = x[i] - meanX
val dy = y[i] - meanY
num += dx * dy
denX += dx * dx
denY += dy * dy
}
if (denX == 0.0 || denY == 0.0) return 0.0
return num / kotlin.math.sqrt(denX * denY)
}
算法说明:
- 先计算两条序列的平均值
meanX、meanY; - 遍历一次序列,累积分子(协方差)与分母(方差之积);
- 若某条序列方差为 0(全部相等),则认为相关性为 0;
- 时间复杂度为 ( O(n) ),空间复杂度 ( O(1) )。
4. 核心分析入口:timeSeriesCorrelationAnalyzer
完整的 Kotlin 核心引擎已经集成在 App.kt 中(通过 @JsExport 暴露到 JS),关键部分如下:
@JsExport
fun timeSeriesCorrelationAnalyzer(inputData: String): String {
val sanitized = inputData.trim()
if (sanitized.isEmpty()) {
return "❌ 输入为空,请按 SERIES-CPU:0.2,0.3... 格式提供多条序列"
}
val seriesList = parseMultiSeriesInput(sanitized)
if (seriesList.isEmpty()) {
return "❌ 未解析到任何序列,请检查格式是否包含 名称:数值列表"
}
val lengthSet = seriesList.map { it.values.size }.toSet()
if (lengthSet.size != 1) {
return "❌ 所有序列的长度必须一致,实际长度集合: $lengthSet"
}
val names = seriesList.map { it.name }
val n = names.size
if (n < 2) {
return "❌ 至少需要提供两条时间序列用于相关性分析,当前仅解析到 ${n} 条"
}
val builder = StringBuilder()
builder.appendLine("📊 时间序列相关性分析报告")
builder.appendLine("━━━━━━━━━━━━━━━━━━━━━━━━━━")
builder.appendLine("序列数量: $n")
builder.appendLine("每条序列长度: ${lengthSet.first()}")
builder.appendLine()
// 相关性矩阵头部
builder.appendLine("===== 相关性矩阵(Pearson r) =====")
builder.append(" ")
names.forEach { name ->
builder.append(String.format("%10s", name.take(8)))
}
builder.appendLine()
// 相关性矩阵内容
for (i in 0 until n) {
builder.append(String.format("%-7s", names[i].take(7)))
for (j in 0 until n) {
val r = if (i == j) {
1.0
} else {
pearsonCorrelation(seriesList[i].values, seriesList[j].values)
}
builder.append(String.format("%10.2f", r))
}
builder.appendLine()
}
builder.appendLine()
builder.appendLine("===== 关联关系解读 =====")
for (i in 0 until n) {
for (j in i + 1 until n) {
val r = pearsonCorrelation(seriesList[i].values, seriesList[j].values)
val level = when {
r >= 0.8 -> "高度正相关"
r >= 0.5 -> "中度正相关"
r >= 0.3 -> "低度正相关"
r <= -0.8 -> "高度负相关"
r <= -0.5 -> "中度负相关"
r <= -0.3 -> "低度负相关"
else -> "相关性较弱或接近于 0"
}
builder.appendLine("【${names[i]} vs ${names[j]}】r = ${"%.2f".format(r)},$level")
}
}
return builder.toString().trim()
}
输出结构:
- 基本信息:序列数量、每条序列长度;
- 相关性矩阵:以文本表格形式展示
r值,便于快速对比; - 关联关系解读:对每一对序列给出「高度正相关 / 中度负相关 / 相关性较弱」等中文解释。
三、JavaScript 桥接与 build-and-copy.bat 集成
通过 @JsExport 标注,timeSeriesCorrelationAnalyzer 会在 KMP JS 产物中生成对应的 JS 导出函数。
项目中的 build-and-copy.bat 脚本通常负责:
- 调用 Gradle 构建 JS 目标(生成
hellokjs.js、hellokjs.d.ts等); - 将生成的 JS 文件复制到 OpenHarmony 侧的
entry/src/main/ets/pages目录下。
桥接层示例(若你需要手动包装一层):
import { timeSeriesCorrelationAnalyzer } from './hellokjs.js';
export function runTimeSeriesCorrelation(payload) {
const normalized = typeof payload === 'string' ? payload.trim() : '';
if (!normalized) {
return '⚠️ 输入为空,请提供至少两条时间序列';
}
try {
const report = timeSeriesCorrelationAnalyzer(normalized);
console.info('[ts-correlation] success', report.split('\n')[0]);
return report;
} catch (error) {
console.error('[ts-correlation] failed', error);
return `❌ 执行失败: ${error?.message ?? error}`;
}
}
实际项目中,你只需确保:
1)Kotlin 端已经有@JsExport fun timeSeriesCorrelationAnalyzer(...);
2)执行build-and-copy.bat,刷新生成的hellokjs.js;
3)ArkTS 端从./hellokjs导入该函数即可。
四、ArkTS 高级单页面板设计(Index 页面)
由于当前工程通过 build-and-copy.bat 编译后,只能使用 Index 作为唯一入口页面,本案例将相关性分析的 UI 直接集成在 Index.ets 中。
在 kmp_ceshiapp/entry/src/main/ets/pages/Index.ets 中,我们已经替换为:
- 顶部深蓝渐变「时间序列分析」标题栏;
- 中部「时间序列输入」卡片,支持多条序列文本编辑;
- 底部「相关性分析结果」卡片,展示分析报告。
核心调用逻辑如下:
import { timeSeriesCorrelationAnalyzer } from './hellokjs'
@Entry
@Component
struct Index {
@State inputData: string = "SERIES-CPU:0.2,0.3,0.5,0.7,0.9\nSERIES-QPS:100,150,200,260,320\nSERIES-ERROR:0.01,0.01,0.02,0.03,0.05"
@State result: string = ""
@State isLoading: boolean = false
// ...
executeDemo() {
this.isLoading = true
setTimeout(() => {
try {
this.result = timeSeriesCorrelationAnalyzer(this.inputData)
} catch (e) {
this.result = "❌ 执行失败: " + e.message
}
this.isLoading = false
}, 100)
}
}
UI 风格要点:
- 顶部使用
#3F51B5 -> #1A237E渐变,营造「数据看板」质感; - 输入区采用淡紫色背景
#E8EAF6和卡片式布局,突出序列条数统计; - 结果区使用
monospace字体显示完整文本报告,方便对齐矩阵; - 空状态下展示「等待时间序列相关性分析」提示,引导用户输入多条序列。
五、与滑动窗口统计分析的协同
「滑动窗口统计分析」关注的是 单一时间序列的局部动态行为,例如:
- 每个窗口的均值、极值、趋势变化;
- 全局平均值与最大值等。
「时间序列相关性分析」则关注 多条时间序列之间的整体关系,例如:
- 某个业务 KPI 与底层资源指标之间的关联度;
- 哪些指标对同一事件最为敏感(高度正相关);
- 哪些指标具有明显的反向联动(负相关)。
两者结合,可以实现:
- 用滑动窗口定位「什么时候出问题」;
- 用相关性分析推断「问题更可能和谁有关」。
六、典型应用场景
-
系统性能诊断
- 分析 CPU / 内存 / QPS / 错误率 等序列间的相关性,识别「高危组合指标」。
-
业务转化漏斗分析
- 曝光量、点击量、加购量、下单量之间的相关性,帮助优化转化路径。
-
多维监控看板设计
- 利用相关性矩阵发现冗余指标和关键指标,精简监控面板。
-
告警规则调优
- 找出与故障最强相关的指标,缩小告警噪音,提升告警准确率。
七、KMP + OpenHarmony 集成优势
-
算法层一次实现,多端共享:
所有相关性计算逻辑由 Kotlin 实现,KMP 负责编译到 JS,未来也可复用到其他平台。 -
OpenHarmony 端原生体验:
ArkTS 提供高性能 UI 渲染能力,可以轻松打造「数据看板」式复杂面板。 -
类型安全与可维护性:
通过hellokjs.d.ts暴露类型信息,ArkTS 在编译期即可获得函数签名提示,减少运行时错误。
八、总结
本案例在「滑动窗口统计分析」的基础上,迈出了时间序列分析的第二步:
从单序列的局部统计,走向多序列之间的整体关系建模。
关键要点回顾:
- 使用
NamedSeries+ 多分隔符解析,构建稳定的多序列输入模型; - 采用皮尔逊相关系数 ( r ) 量化指标联动关系,时间复杂度线性、实现简洁;
- 通过「相关性矩阵 + 中文解读」的报告形式,兼顾工程实践与可读性;
- 借助 KMP + OpenHarmony 架构,实现算法引擎复用与原生体验的统一。
结合本案例与前一个「滑动窗口统计分析」案例,你已经拥有一套完整的 时间序列观察工具箱:
既能看「单指标在时间上的变化」,也能看「多指标之间的联动关系」,为平台稳定性与业务洞察提供坚实的数据基础。***

开源鸿蒙跨平台开发社区汇聚开发者与厂商,共建“一次开发,多端部署”的开源生态,致力于降低跨端开发门槛,推动万物智联创新
更多推荐
 8
8 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)