残差突破的机缘巧合(三)
简单残差实现包括两部分:forward和backward,我们,前两节理论讲完,记录完成!关于程序中实现:参考
lenet改vgg成功后,我们再改为最简单的resnet-CSDN博客
另外残差实现部分容易,因为:16*16*16到最后也是16*16*16;
而虚线残差让人感觉12*16*16到最后是16*16*16,反向后16-》12,不好对付,实际,程序中,这个count不用考虑,因为有一个函数化解了,他非常妙:
for (int i = 0; i < pre_layer->map_count; i++)//12*16*16
{
for (int j = 0; j < cur_layer->map_count; j++)//24*16*16
{
connected_index = i * cur_layer->map_count + j;
convolution_calcuVggBPplus1(
pre_layer->map[i].data, pre_layer->map_width, pre_layer->map_height,//16 16*12
cur_layer->map[j].error, cur_layer->map_width, cur_layer->map_height,//16 16*16
cur_layer->kernel[connected_index].delta_weight, cur_layer->kernel_width, cur_layer->kernel_height,//3 3
c31_备用_layer.map[j].error,//16 16*16
buffer2[i]//16*16 *12
);
}
}
————————————————
就是这个函数!可惜cudnn中没有,耽搁了我好几个月,才完成了cudnn的残差,用了半个月以来,发现没什么问题,突然发现grad_output这个到底是什么?我竟然没搞清楚,吓出我一身冷汗!那我的cudnn 残差网络实现不是扯淡吗?
那么这个grad_output到底是什么?是何方神圣?在我们数学推导中是哪一部分,在cpu残差程序中又指什么?
我cudnn残差实现,受到pytorch残差的影响,看上去好简单!但是pytorch没有反向梯度推导(他是自动求梯度的),等于什么也没说!
因为cpu残差的实现,所以有一种直觉,直接就拥上去了,两天来核查了,放下心了!
所以,得到一个经验,就是直觉对了,还是要核实!现在好像有两次想当然对了,吓出自己两身冷汗!但直觉不一定对!
还是古人说的好,慎独,谨慎点好,数学的特长就在这里,使你变得严谨!
void convolution_calcuVggBPplus1(double* input_map_data, int input_map_width, int input_map_height, double* kernel_data, int kernel_width,
int kernel_height, double* result_map_data, int result_map_width, int result_map_height,double* c33备用,double* c31备用)//c33备用=error,c31备用=buffer
{
// log_exec("convolution_calcu");
double sum = 0.0;
for (int i = 0; i < result_map_height; i++)//3
{
for (int j = 0; j < result_map_width; j++)//3
{
sum = 0.0;
for (int n = 1; n < kernel_height-1; n++)//14
{
for (int m = 1; m < kernel_width-1; m++)//14
{
int index_input_reshuffle = (i-1 + n) * input_map_width + j-1 + m;//
int index_kernel_reshuffle = n * kernel_width + m;//14*14
sum += input_map_data[index_input_reshuffle] * (kernel_data[index_kernel_reshuffle]
+c33备用[index_input_reshuffle] *c31备用[index_input_reshuffle]) ;//16*16
}////c33备用*c31备用==error*buffer
}
int index_result_reshuffle = (i) * result_map_width + j;//3*3
result_map_data[index_result_reshuffle] += sum;
}
}
}
————————————————
这个从vgg改过来适应残差的函数,很妙!前向卷积可以,反向传播当作卷积继续用!
其实cudnn中的grad_output就是kernel_data[index_kernel_reshuffle]
在这幅图中:
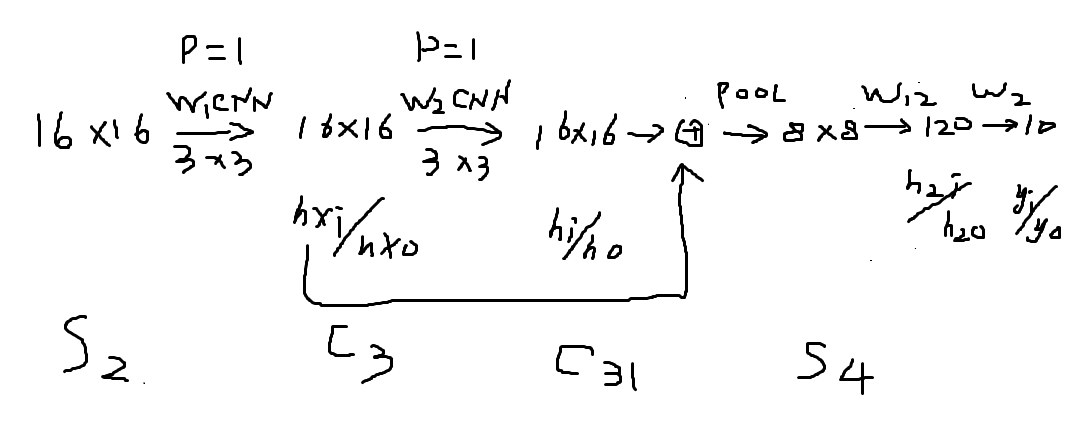
input_map_data[index_input_reshuffle] * (kernel_data[index_kernel_reshuffle]
+c33备用[index_input_reshuffle] *c31备用[index_input_reshuffle]) ;//16*16
程序中这句话就是:
s2.data(c3.error+c31.error*ds(s2.data))
所以,grad_output就是kernel_data[index_kernel_reshuffle]=c3.error
c3.error的nchw与grad_output一样
好,记录完毕!
粗枝大叶已经对上,cudnn中少了ds(s2.data)这个动作,而是直接用了s2.data,需要再核实验证!
ds()函数是leaky relu激活函数反向传播时的求导动作,差别已经不大,但还是应谨慎求之!
cudnn残差实现的时实线部分,虚线看上去也有戏了!

开源鸿蒙跨平台开发社区汇聚开发者与厂商,共建“一次开发,多端部署”的开源生态,致力于降低跨端开发门槛,推动万物智联创新。
更多推荐


 7
7 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)