【线粒体基因组分析】02.tRNA二级结构美化与组图脚本(MITOS与RNAplot绘图适用)
·
一、概述
本教程提供了原创的tRNA二级结构美化脚本,用于美化由MITOS或者使用RNAplot程序构建出的tRNA二级结构图SVG文件,并且按照用户指定的排布进行组图。
二、视频教学
02.tRNA二级结构美化与组图脚本(MITOS与RNAplot绘图适用)![]() http://www.bilibili.com/video/BV1FzbRzjERa
http://www.bilibili.com/video/BV1FzbRzjERa
三、代码获取
3.1 方法一:复制代码文本
可以自行复制以下代码,并粘贴到文本文件中,将文本文件命名为TrnaStructureBeautifier.py
#!/usr/bin/env python
# _*_ coding:utf-8 _*_
#
# @Version : 1.1
# @Project : https://github.com/shueho/BioDataTools
# @Time : 2025/7/23 20:00
# @Update : 2025/8/13 14:00
# @Author : Hao Xue
# @E-mail : studid@163.com
# @File : TrnaStructureBeautifier.py
#
# Enhancement of tRNA secondary structure diagrams generated using the RNAplot function from the ViennaRNA package.
import os
import re
import argparse
#old = sys.argv[1]
def parse_arguments():
parser = argparse.ArgumentParser(description="RNA结构图美化参数配置")
# === 输入控制 ===
parser.add_argument(
"-i", "--input",
type=str,
required=True,
help="SVG文件或者SVG文件存放的文件夹路径"
)
# === 基础布局 ===
parser.add_argument(
"-s", "--size-weight",
type=float,
default=1.4,
help="图形缩放比例(默认 1.4)"
)
parser.add_argument(
"-p", "--per-row",
type=int,
default=4,
help="每行图片数量(默认 4)"
)
parser.add_argument(
"-hg", "--horizontal-gap",
type=int,
default=8,
help="图片水平间隔(默认 8)"
)
parser.add_argument(
"-vg", "--vertical-gap",
type=int,
default=5,
help="图片垂直间隔(默认 5)"
)
# === 碱基连线颜色 ===
parser.add_argument(
"-ac", "--adjacent-color",
type=str,
default="blue",
help='相邻碱基连线颜色(支持名称或 HEX,如 "blue" 或 "#00FF00",默认 "blue")'
)
parser.add_argument(
"-pc", "--pair-color",
type=str,
default="red",
help='配对碱基连线颜色(支持名称或 HEX,如 "red" 或 "#FF0000",默认 "red")'
)
# === 碱基圆圈样式 ===
parser.add_argument(
"-bf", "--base-fill",
type=str,
default="white",
help='碱基圆圈填充色(默认 "white")'
)
parser.add_argument(
"-bs", "--base-stroke",
type=str,
default="black",
help='碱基圆圈轮廓色(默认 "black")'
)
# === 碱基美化图 ===
parser.add_argument(
"-A", "--base-a",
type=str,
default="red",
help='美化A碱基圆圈填充色(默认 "red")'
)
parser.add_argument(
"-U", "--base-u",
type=str,
default="blue",
help='美化U/T碱基圆圈填充色(默认 "blue")'
)
parser.add_argument(
"-G", "--base-g",
type=str,
default="green",
help='美化G碱基圆圈填充色(默认 "green")'
)
parser.add_argument(
"-C", "--base-c",
type=str,
default="yellow",
help='美化C碱基圆圈填充色(默认 "yellow")'
)
# === 反密码子控制 ===
#parser.add_argument(
# "-af", "--anticodon-file",
# type=str,
# default=None,
# help="反密码子位点文件路径(文本文件,每行一个位置)"
#)
#parser.add_argument(
# "-aF", "--anti-fill",
# type=str,
# default="red",
# help='反密码子圆圈填充色(默认 "red")'
#)
#parser.add_argument(
# "-aS", "--anti-stroke",
# type=str,
# default="black",
# help='反密码子圆圈轮廓色(默认 "black")'
#)
args = parser.parse_args()
return args
args = parse_arguments()
base_color = {"A":args.base_a,"U":args.base_u,"G":args.base_g,"C":args.base_c,}
# 设置目标文件夹名称
modified_folder = "modified"
# 创建文件夹(如果已存在则忽略)
os.makedirs(modified_folder, exist_ok=True)
print("已创建文件夹: modified")
def read_svg(spath):
with open(spath) as f:
return f.read()
def set_new_text(x_y_char,fill_=args.base_fill,stroke_=args.base_stroke):
x = x_y_char[0]
y = x_y_char[1]
t = x_y_char[2].upper().replace("T","U")
return '<circle cx="{}" cy="{}" r="5" fill="{}" stroke="{}" />\n <text x="{}" y="{}" text-anchor="middle" dy="3.33333"\n font-size="10" fill="black">{}</text>\n'.format(x,y,fill_,stroke_,x,y,t)
def set_new_lines(x_y_char_1, x_y_char_2,stroke_):
x1, y1, _ = x_y_char_1
x2, y2, _ = x_y_char_2
xy = (x1, y1, x2, y2)
return '<line x1="{}" y1="{}" x2="{}" y2="{}" stroke="{}" stroke-width="1"/>\n'.format(*xy,stroke_)
def get_add_line(svg_text):
#pattern = r'<line.*?x1="([^"]+)"[^>]*?y1="([^"]+)"[^>]*?x2="([^"]+)"[^>]*?y2="([^"]+)"'
pattern = r'<line\b[^>]*\s*x1="([^"]+)"[^>]*\s*y1="([^"]+)"[^>]*\s*x2="([^"]+)"[^>]*\s*y2="([^"]+)"'
matches = re.findall(pattern, svg_text)
result = []
for x1_str, y1_str, x2_str, y2_str in matches:
try:
x1 = float(x1_str)
y1 = float(y1_str)
x2 = float(x2_str)
y2 = float(y2_str)
result.append(set_new_lines((x1, y1, ""), (x2, y2, ""),args.pair_color))
except ValueError:
# 如果坐标无法转换为 float,跳过该元素
continue
return "".join(result)
def extract_text_info(svg_text):
# 正则表达式匹配 <text> 标签中的 x、y 和字符内容
#pattern = r'<text\s+x="([^"]+)"\s+y="([^"]+)"[^>]*>([^<]+)</text>'
pattern = r'<text\b[^>]*\s*x="([^"]+)"[^>]*\s*y="([^"]+)"[^>]*>(.*?)<\/text>'
matches = re.findall(pattern, svg_text)
result = []
for x_str, y_str, char in matches:
try:
x = float(x_str)
y = float(y_str)
result.append((x, y, char))
except ValueError:
# 如果 x 或 y 无法转换为 float,跳过该元素
continue
content = '<g style="font-family: Times New Roman" transform="translate(-4.6, 4)" id="seq">\n'
content += get_add_line(svg_text)
for i in range(1,len(result)):
#content += set_new_text(result[i])
content += set_new_lines(result[i-1],result[i],args.adjacent_color)
content += set_new_text(result[i-1])
content += set_new_text(result[len(result)-1]) + '</g>\n'
return content
def save_svg(content, outpath):
with open(outpath,"w") as f:
f.write(content)
def modi_svg(path):
t = read_svg(path)
name_ = os.path.basename(path)
if "-" in name_:
name_ = name_.split("-")[0]
else:
name_ = name_.split(".")[0]
head_ = '''<?xml version="1.0" encoding="UTF-8" standalone="yes"?>
<svg xmlns="http://www.w3.org/2000/svg" height="452" width="452">
<rect style="stroke: none; fill: none" height="452" x="0" y="0" width="452" onclick="click(evt)" />
<g transform="scale({},{}) translate(45,45)">
<g style="font-family: Times New Roman" id="name">
<text font-size="20" x="1" y="10">{}</text>
</g>
'''.format(args.size_weight,args.size_weight,name_)
mid_ = extract_text_info(t)
tail_ = ' </g>\n</svg>'
save_svg(head_ + mid_ + tail_, "modified/modified_"+name_+".svg")
return name_
#save_svg(modi_svg(old), "new.svg")
def remove_xml_declaration(content):
"""Remove XML declaration from SVG content."""
return re.sub(r'<\?xml[^>]*\?>\s*', '', content)
def extract_dimensions(svg_content):
"""Extract width and height from SVG content."""
width_match = re.search(r'width="([^"]+)"', svg_content)
height_match = re.search(r'height="([^"]+)"', svg_content)
if not width_match or not height_match:
raise ValueError("Could not extract width or height")
return width_match.group(1), height_match.group(1)
def merge_horizontal_group(svg_files, output_file):
"""Merge SVGs in a group horizontally."""
svgs = []
total_width = 0
max_height = 0
gap = args.horizontal_gap
for filename in svg_files:
with open(filename, 'r') as f:
content = f.read()
content = remove_xml_declaration(content)
width, height = extract_dimensions(content)
try:
width_px = float(width.strip('px'))
height_px = float(height.strip('px'))
except ValueError:
raise ValueError(f"Invalid unit in file {filename}")
svgs.append({
'filename': filename,
'content': content,
'width': width,
'height': height,
'width_px': width_px,
'height_px': height_px
})
total_width += sum(svg_info['width_px'] for svg_info in svgs) + gap * (len(svgs) - 1)
max_height = max(max_height, height_px)
new_svg = [
'<?xml version="1.0" encoding="UTF-8" standalone="no"?>',
'<svg xmlns="http://www.w3.org/2000/svg" width="{}" height="{}">'.format(total_width, max_height)
]
current_x = 0.0
for svg_info in svgs:
inner_content = re.sub(r'<svg[^>]*>', '', svg_info['content'])
inner_content = re.sub(r'</svg>', '', inner_content)
new_svg.append('<g transform="translate({:.2f}, 0)">'.format(current_x))
new_svg.append(inner_content)
new_svg.append('</g>')
current_x += svg_info['width_px'] +gap
new_svg.append('</svg>')
with open(output_file, 'w') as f:
f.write('\n'.join(new_svg))
def merge_vertical_groups(group_files, output_file):
"""Merge all horizontal groups vertically."""
svgs = []
max_width = 0
total_height = 0
gap = args.vertical_gap
for filename in group_files:
with open(filename, 'r') as f:
content = f.read()
content = remove_xml_declaration(content)
width, height = extract_dimensions(content)
try:
width_px = float(width.strip('px'))
height_px = float(height.strip('px'))
except ValueError:
raise ValueError(f"Invalid unit in file {filename}")
svgs.append({
'filename': filename,
'content': content,
'width': width,
'height': height,
'width_px': width_px,
'height_px': height_px
})
max_width = max(max_width, width_px)
total_height += sum(svg_info['height_px'] for svg_info in svgs) + gap * (len(svgs) - 1)
new_svg = [
'<?xml version="1.0" encoding="UTF-8" standalone="no"?>',
'<svg xmlns="http://www.w3.org/2000/svg" width="{}" height="{}">'.format(max_width, total_height)
]
current_y = 0.0
for svg_info in svgs:
inner_content = re.sub(r'<svg[^>]*>', '', svg_info['content'])
inner_content = re.sub(r'</svg>', '', inner_content)
new_svg.append('<g transform="translate(0, {:.2f})">'.format(current_y))
new_svg.append(inner_content)
new_svg.append('</g>')
current_y += svg_info['height_px'] + gap
new_svg.append('</svg>')
with open(output_file, 'w') as f:
f.write('\n'.join(new_svg))
def update_circle_colors(svg_content, base_color_map):
new_ = ""
ls = svg_content.split("\n")
for i in range(len(ls)):
if "<circle cx" in ls[i]:
flag = re.findall(r'(?<=>)[A-Z](?=<\/text>)',ls[i+2])[0]
if flag not in base_color_map:
new_ += ls[i]+"\n"
continue
new_ += ls[i].replace(args.base_fill,base_color_map[flag])+"\n"
else:
new_ += ls[i]+"\n"
return new_
if __name__ == "__main__":
# 示例调用
print("参数解析结果:")
#print(f"主数据文件: {args.input}")
print(f"大小权重: {args.size_weight}")
print(f"每行图片数量: {args.per_row}")
print(f"图片水平间隔: {args.horizontal_gap}")
print(f"图片垂直间隔: {args.vertical_gap}")
print(f"相邻碱基连线颜色: {args.adjacent_color}")
print(f"配对碱基连线颜色: {args.pair_color}")
print(f"碱基填充色: {args.base_fill}")
print(f"碱基轮廓色: {args.base_stroke}")
#print(f"反密码子文件: {args.anticodon_file}")
#print(f"反密码子填充色: {args.anti_fill}")
#print(f"反密码子轮廓色: {args.anti_stroke}")
#如果是文件,直接添加到列表
file_list = []
group_size = args.per_row
if os.path.isfile(args.input):
file_list.append(args.input)
print(f"已添加文件: {args.input}")
# 如果是文件夹,添加文件夹内所有文件(不递归子文件夹)
elif os.path.isdir(args.input):
for filename in os.listdir(args.input):
file_path = os.path.join(args.input, filename)
if os.path.isfile(file_path) and "modified_" not in file_path and ".svg" == file_path[-4:]: # 只处理文件
file_list.append(file_path)
file_list.sort()
print(f"已添加文件夹内所有文件: {args.input}")
modi_files = []
for i in file_list:
n = modi_svg(i)
modi_files.append("modified/modified_"+n+".svg")
# Step 2: Merge into horizontal groups
group_index = 0
group_files = []
for i in range(0, len(modi_files), group_size):
group = modi_files[i:i+group_size]
if not group:
break
group_output = f"modified/group_{group_index}.svg"
merge_horizontal_group(group, str(group_output))
group_files.append(group_output)
group_index += 1
# Step 3: Merge all groups vertically
final_output = "modified/final.svg"
merge_vertical_groups(group_files, str(final_output))
print(f"未上色SVG保存到: {final_output}")
print(f"美化A碱基填充色: {args.base_a}")
print(f"美化U碱基填充色: {args.base_u}")
print(f"美化G碱基填充色: {args.base_g}")
print(f"美化C碱基填充色: {args.base_c}")
fisvg = read_svg(str(final_output))
cosvg = update_circle_colors(fisvg,base_color)
save_svg(cosvg,"modified/final_color.svg")
print(f"上色SVG保存到: modified/final.svg")
#print(modi_files)3.2 方法二:从Github下载
四、使用方法
4.1 配置Python环境
参考教程:
【生信分析前置】02.Python的下载安装流程![]() http://www.bilibili.com/video/BV1orbXzKEU1
http://www.bilibili.com/video/BV1orbXzKEU1
4.2 tRNA二级结构原图
将由MITOS或者RNAplot导出的tRNA二级结构SVG文件,存放至一个文件夹中。
如果不知道怎么获得这些文件,可以参考图文:
4.3 运行脚本
假设我们将所有SVG存放到example/mitos_RNA_plot文件夹中,可以在终端中运行以下命令:
# 使用默认参数美化图片
python TrnaStructureBeautifier.py -i example/mitos_RNA_plot #指定一个文件夹
python TrnaStructureBeautifier.py -i example/trnG.svg #指定一个文件
# 使用全部配置参数
python TrnaStructureBeautifier.py -i example/mitos_RNA_plot -s 1.8 -p 6 -hg 12 -vg 7 -ac "red" -pc "#FF0000" -bf "#FFFF00" -bs "#000000" -A "#FF0000" -U "#0000FF" -G "#00FF00" -C "#FFFF00" 如果想要知道详细的脚本使用方法可以参考图文:
五、运行结果
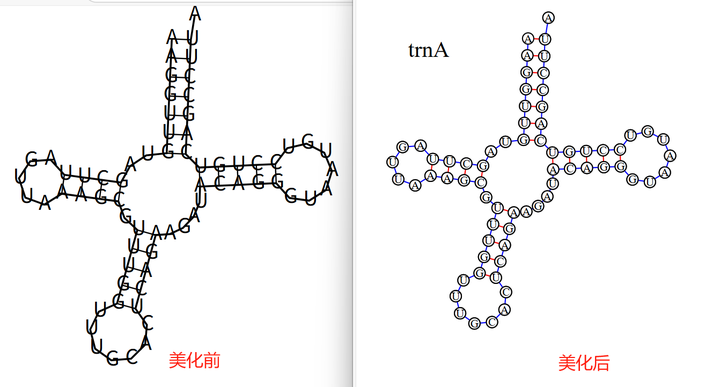
5.1 单图美化效果
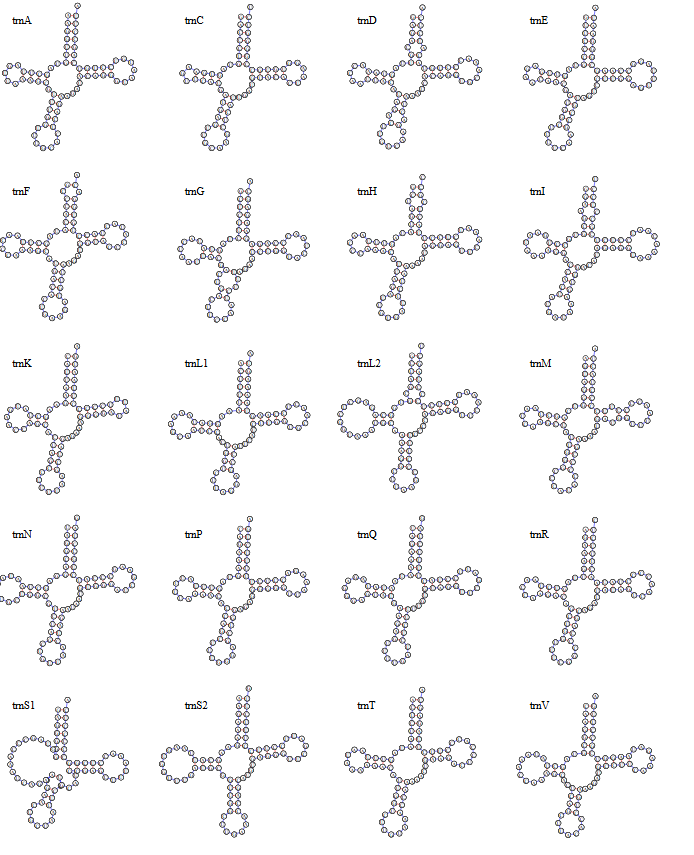
5.2 不上色组图
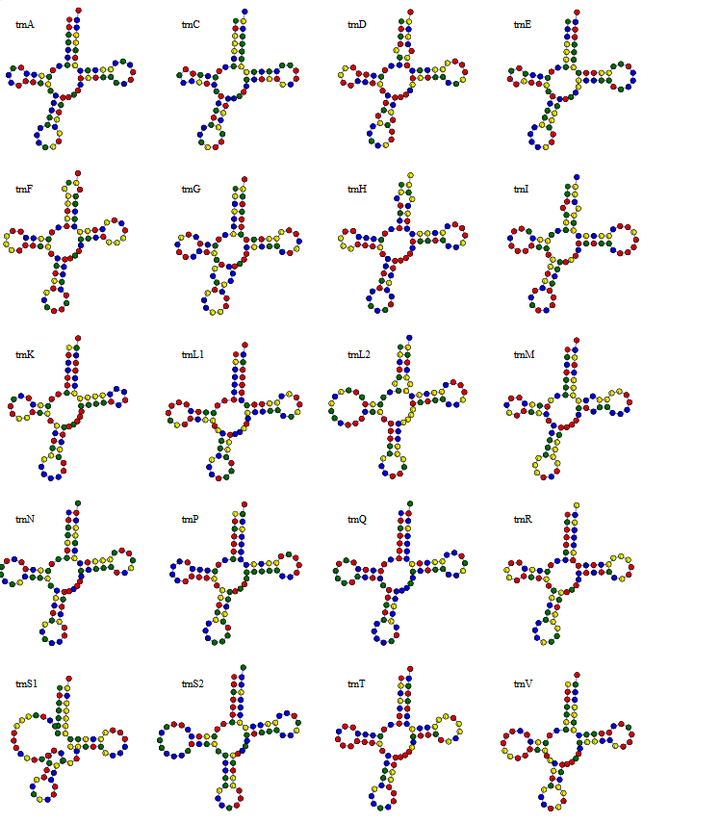
5.3 上色组图

开源鸿蒙跨平台开发社区汇聚开发者与厂商,共建“一次开发,多端部署”的开源生态,致力于降低跨端开发门槛,推动万物智联创新。
更多推荐
 12
12 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)