标签Labels、Scheduler、Pod亲和性与反亲和性
·
标签Labels
Labels是用于标识和选择K8S资源的键值对。
可以对Pod、Node、Service、Deployment、Namespace等资源使用标签。
用途:
- 分类和组织
- 筛选和管理
- 自动化操作
使用方法:
1.创建资源时,添加标签
apiVersion: v1
kind: Pod
metadata:
name: my-pod
labels:
app: my-app
environment: production
spec:
containers:
- name: my-container
image: nginx:1.26# 通过标签名筛选pod
kubectl get pod -l app=pod-1
kubectl get pod -l app
2.在资源运行时,添加或修改标签
kubectl label 资源类型 资源名 标签键=值 --overwrite
# 添加标签
kubectl label pod my-pod owner=john
# 删除标签
kubectl label pod my-pod owner-
# 重新添加标签
kubectl label pod my-pod environment=test --overwrite
使用标签的方式:
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-deployment
spec:
replicas: 3
selector: # 标签选择器
matchLabels: # 通过键值对绑定标签
app: my-app # 需要管理Pod的标签
template: # 创建Pod的模板,通过Deployment自动创建Pod
metadata:
labels:
app: my-app # Pod的标签,用于被筛选和管理
spec:
containers:
- name: my-container
image: nginx
标签选择器是用于根据标签筛选对象的机制。以下是几种常见的标签选择器示例:
- 等式选择器:选择与指定标签键值对匹配的对象。
kubectl get pods -l app=my-app
这条命令选择所有带有 app=my-app 标签的 Pod。参数 -l, --selector= 用于指定标签。
- 集合选择器:选择标签值在指定集合中的对象。
kubectl get pods -l environment in (production, staging)
这条命令选择所有带有 environment 标签,且值为 production 或 staging 的 Pod。
- 存在性选择器:选择具有指定标签键的对象。
kubectl get pods -l owner
这条命令选择所有带有 owner 标签的 Pod,不论其值是什么。
案例:
labels标签,在kubernetes我们会经常见到,它的功能非常关键,就相关于服务pod的身份证信息,如果我们创建一个deployment资源,它之所有能守护下面启动的N个pod以达到期望的数据,service之所以能把流量准确无误的转发到指定的pod上去,归根结底都是labels在这里起作用,下面我们来实际操作下,相信大家跟着操作完成后,就会理解labels的功效了
# 我们先来创建一个nginx的deployment资源
kubectl create deployment nginx --image=nginx:1.21.6 --replicas=3
# 等服务pod都运行好,这时候按我们期待的状态就是3个pod,没问题
kubectl get pod -w
# 我们现在来修改其中一个pod的label,你会发现这个pod会被deployment抛弃,因为失去了labels这个标签,deployment已经不认识这个pod了,它就成了无主的pod,这时我们直接删除这个pod,它就会直接消失,就和我们用kubectl run 一个独立的pod资源一样
kubectl label pod nginx-69747f9bdb-tb27v app=web01 --overwrite=True
# 查看所有的pod标签,会发现修改后的pod标签已变
kubectl get pod --show-labels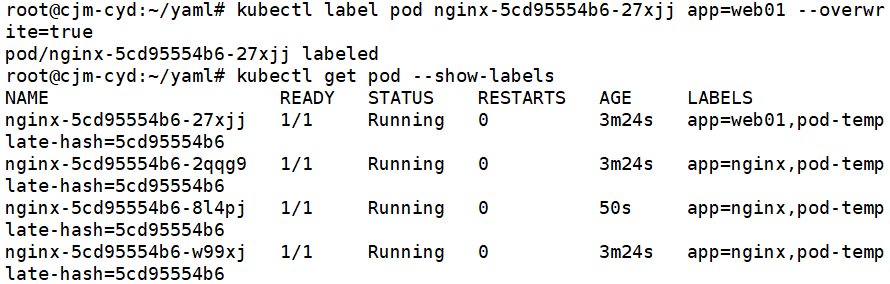
# 删除修改过标签的pod,不会重启,它已经不受deployment的控制了。
kubectl delete pod nginx-69747f9bdb-tb27v# 我们再来基于这个nginx的deployment来创建一个service服务
kubectl expose deployment nginx --port=80 --target-port=80 --name=nginx
# 直接利用svc的ip来请求下,发现都是正常的对吧
kubectl get svc nginx
# 这个时候我来来修改下svc资源的选择labels,看看会出现什么情况
kubectl patch services nginx -p '{"spec":{"selector":{"app": "nginxaaa"}}}'
# 这时再请求这个svc的ip,你会发现已经请求不通了,这也证明了它已经关联不到后面对应label的pod了
# 我们修改回来后,会发现一切恢复正常了
kubectl patch services nginx -p '{"spec":{"selector":{"app": "nginx"}}}'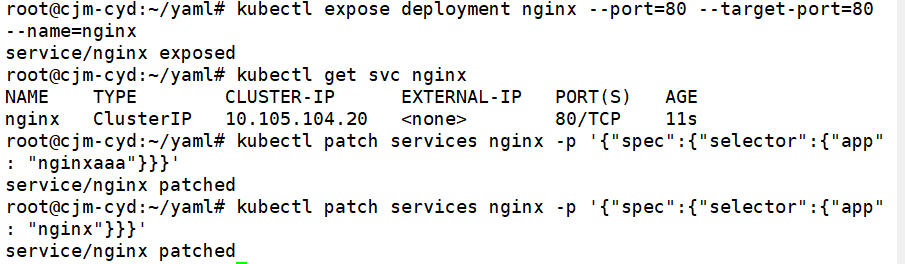
labels受namespace管控,在同一个namespace下面的服务labels,如果只有一个,就需要注意其唯一性,不要有重复的存在,不然服务就会跑串,出现一些奇怪的现象,我们在资源中可以配置多个lables来一起组合使用,这样就会大大降低重复的情况了。
多deployment混合运行模式
# 首先导出多服务配置
kubectl get deployments.apps nginx -o yaml > nginx-other.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
annotations:
deployment.kubernetes.io/revision: "1"
creationTimestamp: "2026-02-21T16:14:56Z"
generation: 1
labels:
app: nginx
name: nginx
namespace: default
resourceVersion: "11284"
uid: e6ab3af4-9c4a-47a1-a52c-0df4aa7f8e0f
spec:
progressDeadlineSeconds: 600
replicas: 3
revisionHistoryLimit: 10
selector:
matchLabels:
app: nginx
strategy:
rollingUpdate:
maxSurge: 25%
maxUnavailable: 25%
type: RollingUpdate
template:
metadata:
creationTimestamp: null
labels:
app: nginx
spec:
containers:
- image: nginx:1.21.6
imagePullPolicy: IfNotPresent
name: nginx
resources: {}
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
dnsPolicy: ClusterFirst
restartPolicy: Always
schedulerName: default-scheduler
securityContext: {}
terminationGracePeriodSeconds: 30
status:
availableReplicas: 3
conditions:
- lastTransitionTime: "2026-02-21T16:14:57Z"
lastUpdateTime: "2026-02-21T16:15:38Z"
message: ReplicaSet "nginx-5cd95554b6" has successfully progressed.
reason: NewReplicaSetAvailable
status: "True"
type: Progressing
- lastTransitionTime: "2026-02-21T16:17:33Z"
lastUpdateTime: "2026-02-21T16:17:33Z"
message: Deployment has minimum availability.
reason: MinimumReplicasAvailable
status: "True"
type: Available
observedGeneration: 1
readyReplicas: 3
replicas: 3
updatedReplicas: 3kubectl describe svc nginx
kubectl apply -f nginx-other.yaml
kubectl get deployments.apps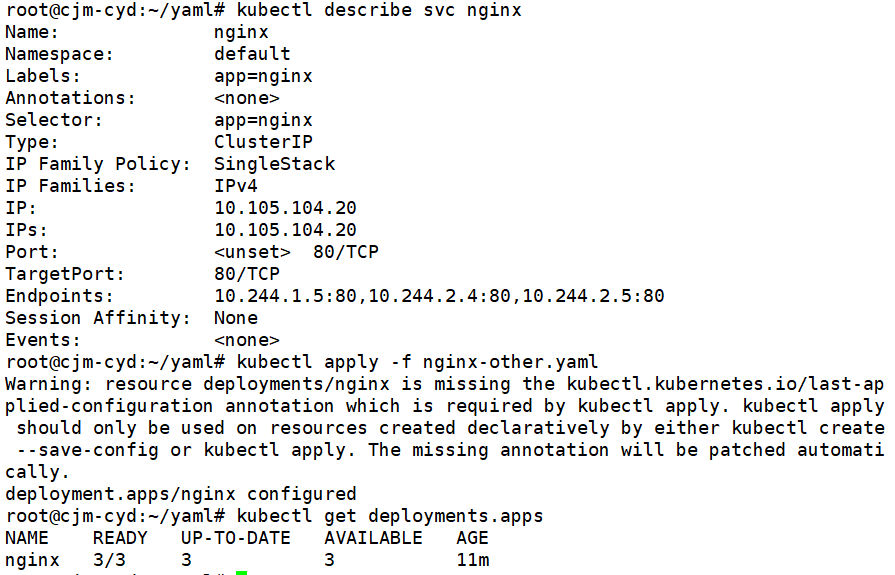
Scheduler:调度器
在创建运行Pod时,用于将Pod的创建请求绑定到Node节点上;
可以满足调度的公平、高效、灵活。
调度过程:
1.过滤掉不满足条件的节点,预选(predicate);
2.按照节点优先级排序,这个是优选(ptiority);
3.选择优先级最高的node节点。
调度方法:
1.自动调度:Scheduler经过一系列的算法计算得出最优节点;
2.定向调度:
- NodeName:指定Node名称进行调度;
- NodeSelector:通过Node标签进行选择调度。
3.亲和性调度:
- NodeAffinity 节点亲和的
- PodAffinity Pod亲和度
- PodAntiAffinity Pod反亲和性
4.污点与容忍度:
- Taints 给Node节点打上污点,需要容忍的才能调度;
- Toleration 在Pod上设置容忍度,才能运行在有污点的Node上。
污点与容忍度
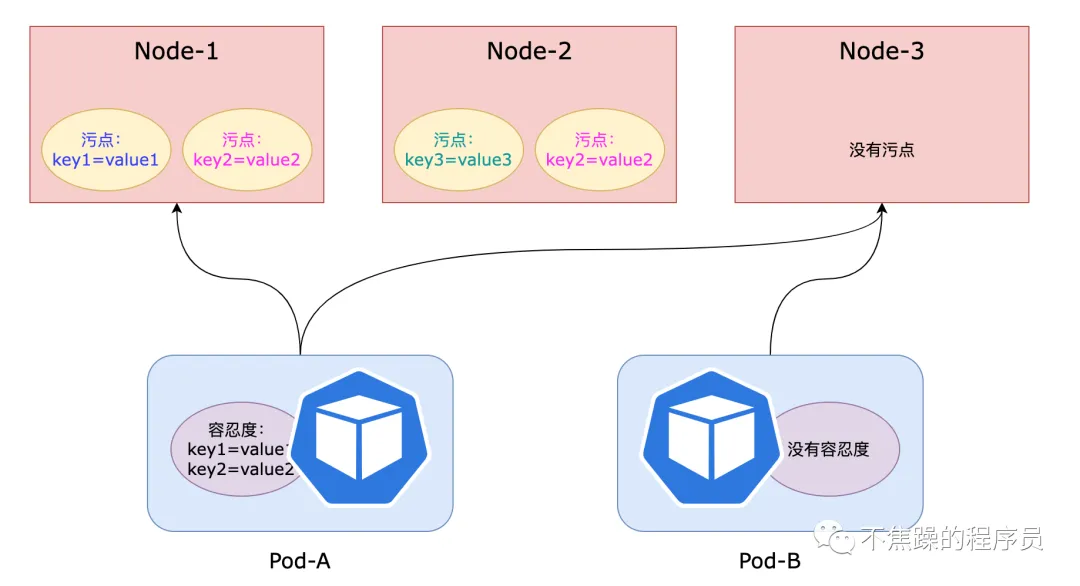
如果Node节点上有污点,需要Pod有容忍度才能调度运行。
污点的三种排斥级别:
- NoSchedule:没有容忍度的Pod不能新建,已经运行的Pod不受影响;
- PreferNoSchedule:没有容忍度的Pod尽量不要创建,如果没有其它节点可以选择,也能创建;
- NoExecute:驱逐所有Pod应用。
给Node打污点:
- node.kubernetes.io/not-ready:节点未就绪
- node.kubernetes.io/unreachable:节点不可触达
- node.kubernetes.io/memory-pressure:节点内存空间已满。
- node.kubernetes.io/disk-pressure:节点磁盘空间已满。
- node.kubernetes.io/network-unavailable:节点网络不可用。
创建污点
kubectl taint nodes node1 aihao=shuijiao:NoSchedule
给node1添加另一个污点
kubectl taint nodes node1 exi=dubo:NoExecute
删除污点
kubectl taint nodes node1 aihao-
kubectl taint nodes node1 exi-
给Pod添加容忍度:
创建配置文件
vim toleration-demo.yaml
# toleration-demo.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-toleration
spec:
replicas: 2
selector:
matchLabels:
app: nginx-toleration
template:
metadata:
labels:
app: nginx-toleration
spec:
tolerations:
# 容忍第一个污点:aihao=shuijiao:NoSchedule(删除 tolerationSeconds)
- key: "aihao"
operator: "Equal"
value: "shuijiao"
effect: "NoSchedule" # NoSchedule 不支持 tolerationSeconds
# 容忍第二个污点:exi=dubo:NoExecute(tolerationSeconds 只加在这里)
- key: "exi"
operator: "Equal"
value: "dubo"
effect: "NoExecute"
tolerationSeconds: 3600 # 仅 NoExecute 生效:Pod 被驱逐前容忍3600秒
# 可选:指定只调度到 node1
nodeSelector:
kubernetes.io/hostname: node1
containers:
- name: nginx
image: nginx:1.26
ports:
- containerPort: 80
应用配置
kubectl apply -f toleration-demo.yaml
验证Pod调度结果
kubectl get pods -o wide | grep nginx-toleration
亲和性和反亲和性
亲和性调度是指通过配置的形式,实现优先选择满足条件的Node进行调度,如果没有,也可以调度到不满足条件的节点上,使调度更加灵活
亲和性(Affinity)主要分为三类:
- 节点亲和性(nodeAffinity):以node为目标,解决pod可以调度到哪些node的问题
- pod亲和性(podAffinity):以pod为目标,解决pod可以和哪些已经存在pod部署到同一个拓扑域中的问题
- pod反亲和性(podAntiAffinity):以pod为目标,解决pod不能和哪些已存在的pod部署在统一个拓扑域中的问题。
亲和性调度是指通过配置的形式,实现优先选择满足条件的Node进行调度,如果没有,也可以调度到不满足条件的节点上,使调度更加灵活
亲和性(Affinity)主要分为三类:
- 节点亲和性(nodeAffinity):以node为目标,解决pod可以调度到哪些node的问题
- pod亲和性(podAffinity):以pod为目标,解决pod可以和哪些已经存在pod部署到同一个拓扑域中的问题
- pod反亲和性(podAntiAffinity):以pod为目标,解决pod不能和哪些已存在的pod部署在统一个拓扑域中的问题。
RequiredDuringSchedulingIgnoredDuringExecution:硬亲和,硬性,强制
apiVersion: apps/v1
kind: Deployment
metadata:
creationTimestamp: null
labels:
app: nginx
name: nginx
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
creationTimestamp: null
labels:
app: nginx
spec:
containers:
- image: nginx:1.26
name: nginx
affinity:
podAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- nginx
topologyKey: test1
#topologyKey:指定拓扑域的关键字段
#表示我正在使用test1作为拓扑域的关键字
#这个test1一般是节点标签。
#表示希望把pod调度到包含有app标签的pod。他的值为nginx在test1的拓扑域上的节点
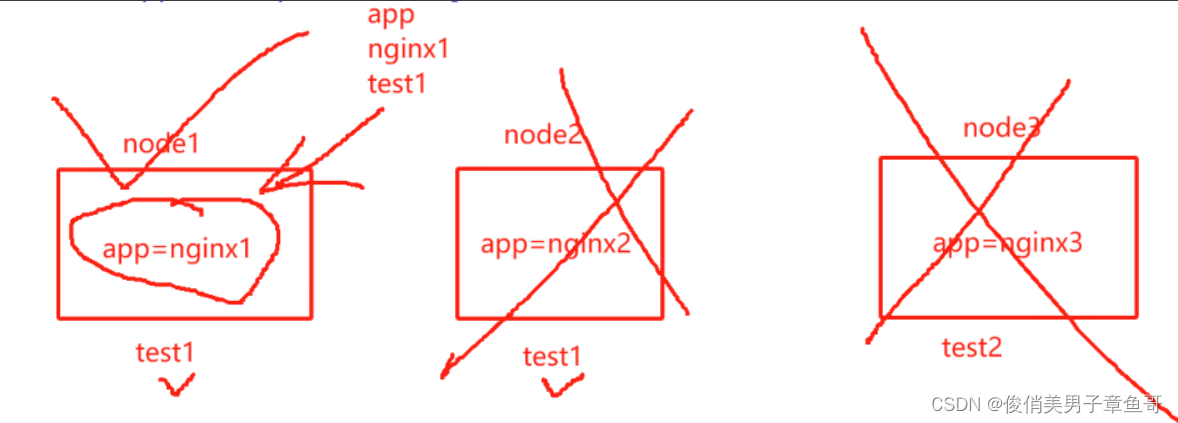
PreferredDuringSchedulingIgnoredDuringExecution:软亲和,优先
apiVersion: apps/v1
kind: Deployment
metadata:
creationTimestamp: null
labels:
test: nginx2
name: nginx2
spec:
replicas: 3
selector:
matchLabels:
test: nginx2
template:
metadata:
creationTimestamp: null
labels:
test: nginx2
spec:
containers:
- image: nginx:1.22
name: nginx2
affinity:
podAntiAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 1
podAffinityTerm:
labelSelector:
matchExpressions:
- key: app
operator: In
values:
- nginx1
topologyKey: test1
特点:
- pod的亲和性策略。在配置时,必须要加上拓扑域的关键字topologkey指向的是节点标签
- pod亲和性的策略也分为硬策略和软策略
- pod亲和性的notin可以替代反亲和性
- pod亲和性主要是为了把相关联的pod组件部署在同一节点上。例如:LNMP

开源鸿蒙跨平台开发社区汇聚开发者与厂商,共建“一次开发,多端部署”的开源生态,致力于降低跨端开发门槛,推动万物智联创新。
更多推荐
 6
6 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)