transformer模型详解 从分词到自注意力机制
transformer模型详解 从分词到自注意力机制
大语言模型是基于Transformer架构的机器学习模型,经海量文本数据训练后,可理解、生成人类语言,输出连贯文本(如对话、创作)。
常见代表:GPT系列、BERT、Llama、Falcon等(例如Llama 2参数达700亿+)。
一、分类(基于Transformer结构)
大语言模型根据Transformer结构分为两类:
- 纯编码器模型
- 结构:仅用Transformer的编码器(如BERT)。
- 特点:擅长理解类任务(如文本分类、语义检索),需同时输入上下文+待处理内容。
- 不足:不适合长文本生成任务。
- 纯解码器模型
- 结构:仅用Transformer的解码器(如GPT、Llama 2)。
- 特点:擅长生成类任务(如对话、文本创作),仅需输入前文即可生成下文。
- 优势:
- 计算负担轻(无需编码器);
- 适配自然语言生成任务;
- 训练/推理更高效(仅需单向注意力)。
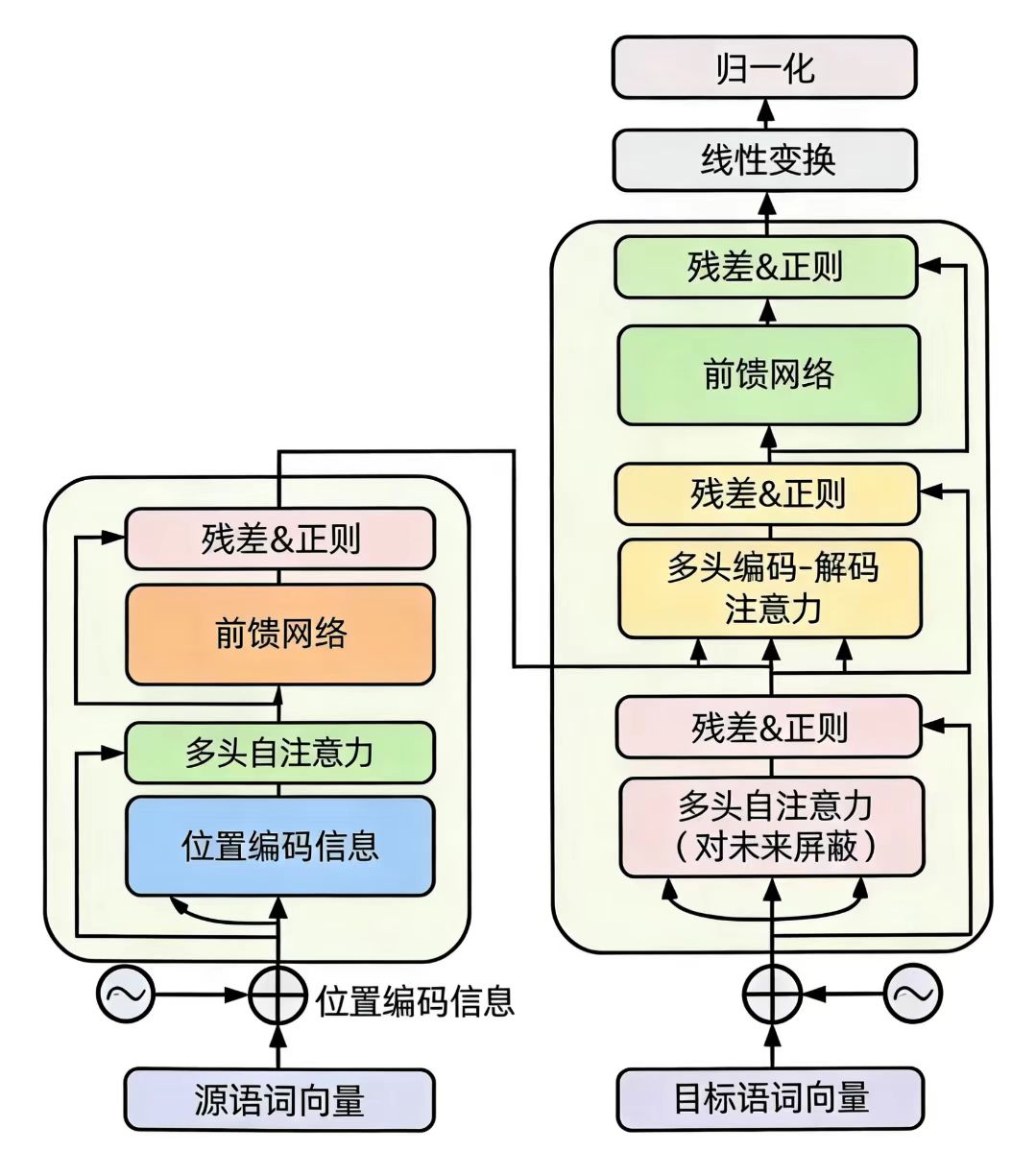
二、Transformer模型
1、Transformer的构成
Transformer本质是“编码器-解码器”结构(但大语言模型常只用其一),核心是放弃循环神经网络,完全基于注意力机制处理序列数据,由多层编码器、解码器堆叠而成(标准Transformer是6层)。
Transformer核心结构(单层/多层)

Transformer的核心是自注意力机制,主要组成部分:
- 自注意力机制
- 作用:计算序列中每个元素与其他元素的关联程度,捕捉长距离依赖。
- 多注意力头:同时计算多个不同的注意力权重,捕捉多维度语义。
- 位置编码(Positional Encoding)
- 作用:给序列元素添加位置信息(Transformer无循环结构,需显式标记位置)。
- 前馈网络
- 作用:对注意力输出做进一步特征变换(每个层独立运行)。
- 归一化(Layer Norm)
- 作用:稳定训练,防止梯度爆炸/消失。
- 残差连接
-
作用:将每层输入与输出相加,帮助模型学习残差(更易训练深层网络)。
-
以下是transformer模型架构
三、纯解码器模型结构(以Llama 2为例)
主流大语言模型(如GPT、Llama 2)采用纯解码器结构,以Llama 2为例:
单个解码器结构: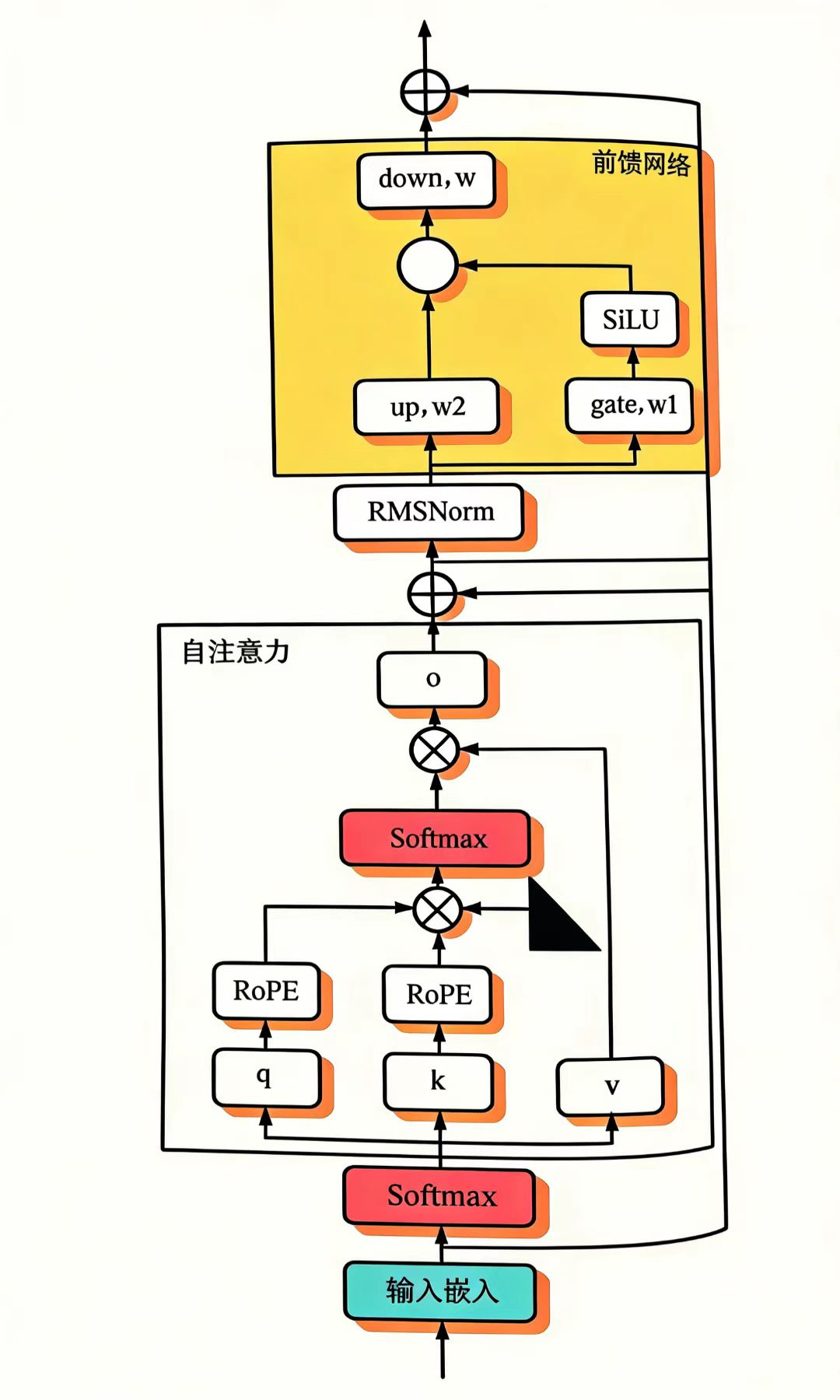
- 整体结构
- 由32~80层解码器堆叠而成,每一层结构一致(图4-6)。
- 单解码器层结构
流程:输入 → 归一化 → 多头自注意力 → 残差连接 → 归一化 → 前馈网络 → 残差连接
- 关键组件:
- RoPE(旋转位置编码):给注意力的Q/K添加位置信息;
- SwiGLU激活函数:替代ReLU,提升模型表达能力;
- 残差连接+归一化:稳定深层训练。
四、词汇表与分词
1、词汇表
词汇表是大语言模型理解文本的基础,存储了模型训练中学习到的所有词汇(或子词),并将其映射为唯一索引(便于模型处理数值化数据)。
核心文件(以Hugging Face格式为例)
- vocab.json :键值对JSON文件(键=词汇,值=索引);
- tokenizer.json :分词器配置+词表;
- tokenizer.model :二进制文件,存储分词器具体实现。
词汇表示例
一个简化的词汇表结构(javascript):
{
"[PAD]": 0, // 填充标记
"[UNK]": 1, // 未知词汇标记
"[CLS]": 2, // 分类任务标记
"[SEP]": 3, // 句子分隔标记
"the": 4, // 常用单词
"a": 5,
"and": 6,
// ...更多词汇
}
特殊标记的作用
- [PAD] :填充序列到固定长度;
- [UNK] :表示词汇表中未收录的词;
- [CLS] :用于分类任务的句子开头;
- [SEP] :分隔不同句子(如问答任务)。
2、词汇表的生成
训练Transformer模型(如BERT、GPT)前,词汇表由分词器+无标签文本数据生成:
- 选择分词器,用海量文本训练;
- 设置词汇表最大大小(如30000/50000);
- 训练完成后词汇表固定,不再扩展。
未知词处理:
- 普通分词器:用 [UNK] 标记未知词;
- 子词分词器(如BPE):将未知词拆分为词汇表中的子词(例如“unseen”拆为“un”+“seen”)。
3、常见分词算法
算法类型 原理&特点 适用场景
空格分词 按空格拆分单词 英语等有明确空格分隔的语言
基于词典的分词 用预定义词典拆分,依赖词典质量 已知词汇覆盖充分的场景
基于统计的分词 用HMM/CRF等算法从文本中学习单词边界 无明确边界的语言
子词分词 将单词拆分为子词(如BPE、SentencePiece),可处理未知词 Transformer模型(GPT/Llama)
4、子词分词:字节对编码(BPE)
BPE是大语言模型常用的子词分词算法,核心是合并高频字符对,步骤如下:
- 初始化:词汇表为语料库中所有单个字符;
- 统计频率:计算所有连续字符对的出现频率;
- 合并高频对:将频率最高的字符对合并为新符号,加入词汇表;
- 重复:直到达到预设词汇表大小。
BPE示例
语料库: low lower newest widest
- 初始化词汇表: [“l”,“o”,“w”,“e”,“r”,“n”,“s”,“t”,“i”,“d”]
- 统计频率: “e”+“s” 出现2次(频率最高);
- 合并:新增符号 “es” ,词汇表更新为 [“l”,“o”,“w”,“e”,“r”,“n”,“s”,“t”,“i”,“d”,“es”] ;
- 重复步骤:最终可能得到 “low” 、 “er” 等子词。
5、子词分词:句子片段(SentencePiece)
SentencePiece是BPE的变体,特点:
- 无需预处理(如空格拆分),直接在原始文本上训练;
- 支持无明确词汇边界的语言(如中文、日语);
- 同时包含完整单词和子词(平衡词汇表大小与语义信息)。
6、分词过程
以BPE为例,Transformer模型对词汇的处理逻辑:
- 已知词:直接用词汇表中的词向量;
- 未知词:拆分为子词(如“unhappiness”→“un”+“happy”+“ness”);
- 无法拆分的词:标记为 [UNK] ,赋予随机/特定词向量。
7、词汇索引
将分词后的“标记(token)”映射为整数索引,是文本转数值的关键步骤:
- 分词:文本→标记(如 “I love Beijing” → [“I”,“love”,“Beijing”] );
- 词汇索引:标记→整数(如词汇表为 [“I”,“love”,“Beijing”] →索引 [0,1,2] )
分词和构建索引都是在为训练和推理做准备
五、词嵌入
词嵌入是自然语言处理的核心技术,将词汇/标记映射为高维数值向量,让模型通过向量捕捉词汇的语义、句法关系。
1、标记嵌入(Token Embedding)
标记嵌入是词嵌入的基础,将每个词汇(或子词)映射为固定维度的向量,是模型理解文本的“数值化桥梁”。
核心逻辑:
- 初始化嵌入矩阵:为词汇表中每个标记分配一个随机初始化的向量(维度通常为128/256/512等);
- 向量映射:文本分词后,通过嵌入矩阵将每个标记转为对应向量;
- 训练优化:通过反向传播更新嵌入矩阵,使语义相似的词汇向量更接近。
假设词汇表仅包含 “I”, “love”, “chocolate” ,嵌入维度设为5:
# 嵌入矩阵(随机初始化)
embedding_matrix = {
"I": [0.1, 0.3, -0.2, 0.8, -0.5],
"love": [0.7, -0.1, 0.2, -0.4, 0.6],
"chocolate": [-0.3, 0.5, 0.1, -0.2, 0.9]
}
# 句子"I love chocolate"的嵌入结果
sentence_embedding = [
embedding_matrix["I"],
embedding_matrix["love"],
embedding_matrix["chocolate"]
]
训练后,语义相似的词向量会更接近(通过余弦相似度衡量):
- 例如:情感分析任务中, “love” 和 “like” 的向量会趋近; “hate” 和 “dislike” 的向量会趋近;而 “love” 和 “hate” 的向量会远离。
2、位置编码(Positional Encoding)
Transformer的自注意力机制是无序的(不区分词的顺序),但词序对语义至关重要(如 “dog bites man” 和 “man bites dog” ),因此需要位置编码向模型注入词的位置信息。
核心特点
- 向量长度匹配:位置编码的向量长度与词嵌入向量一致;
- 生成方式:
- 固定编码:通过正弦/余弦函数生成(原始Transformer);
- 可学习编码:作为模型参数,随训练更新(如BERT的“位置嵌入”);
- 融合方式:将位置编码向量与词嵌入向量相加,得到包含位置信息的最终嵌入。
示例
以句子 “I love dogs” (词嵌入维度为4)为例:
- 词嵌入结果:
"I": [0.1, 0.2, 0.3, 0.4],
"love": [0.5, 0.6, 0.7, 0.8],
"dogs": [0.9, 1.0, 1.1, 1.2]
- 位置编码(简化生成):
Position 1: [1, 1, 1, 1],
Position 2: [2, 2, 2, 2],
Position 3: [3, 3, 3, 3]
- 融合后嵌入:
"I" + Position 1: [1.1, 1.2, 1.3, 1.4],
"love" + Position 2: [2.5, 2.6, 2.7, 2.8],
"dogs" + Position 3: [3.9, 4.0, 4.1, 4.2]
3、词汇索引与词嵌入的关系
词汇索引是“标记→整数”的映射,词嵌入是“整数→向量”的映射,两者通过嵌入矩阵关联:
- 词汇表为每个标记分配唯一索引(如 "爱"→1 );
- 嵌入矩阵的第n行对应索引为n的标记的词嵌入向量。
示例
词汇表: {“我”:0, “爱”:1, “你”:2, …}
嵌入矩阵(2维):
embedding_matrix = [
[0.1, 0.3], # 索引0("我")的嵌入向量
[0.4, -0.2], # 索引1("爱")的嵌入向量
[-0.1, 0.6], # 索引2("你")的嵌入向量
# ...更多索引对应的向量
]
词嵌入的可视化
词嵌入向量维度通常很高(如50/128维),需通过PCA/t-SNE等降维技术可视化。可视化后可直观看到:
- 语义相似的词(如 “女人”&“女孩” 、 “男人”&“男孩” )的向量分布更接近;
- 经典类比关系(如 “国王”-“男人”+“女人"≈"王后” )的向量运算结果会匹配对应词汇的向量。
六、位置编码:Transformer的序列位置信息方案
位置编码是Transformer模型为序列添加位置信息的机制(Transformer本身无递归/卷积结构,无法天然感知序列顺序)。
1、核心作用
为输入序列的每个标记(Token)注入位置特征,让模型理解“词的顺序”,例如区分“我有一只猫”和“猫有一只我”awa。
2、常见位置编码方法
1. 原生位置编码(正弦位置编码)
Transformer原始论文采用的不可学习编码方式,通过正弦/余弦函数生成位置向量:
# 公式
PE(pos,2i) = sin(pos / 10000^(2i/d_model))
PE(pos,2i+1) = cos(pos / 10000^(2i/d_model))
- 示例(嵌入维度 d_model=8 ,序列长度 seq_len=5 ):
- 预计算频率 freqs = pos / 10000^(2i/d_model)
- 偶数位用 sin(freqs) 、奇数位用 cos(freqs) 生成位置向量 pe
- 将 pe 与Token嵌入向量相加,得到最终输入表示。
2. 旋转位置编码(RoPE)
主流大模型(如Llama)采用的相对位置编码方案,通过“旋转矩阵”为位置信息编码,核心是:在注意力计算时,为Query/Key注入位置相关的旋转操作。
(1)核心原理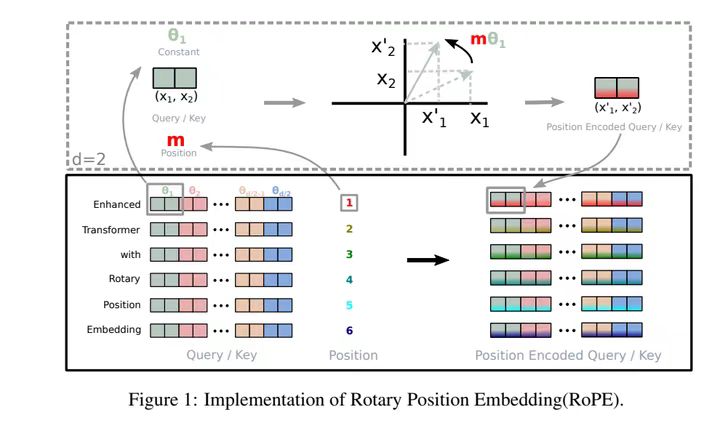
通过“旋转向量”为不同位置的Token添加方向信息:相邻位置的嵌入向量会有明显的旋转差异,从而让模型感知相对位置。
(2)实现步骤(以Llama-2-7b为例)
- 参数设定:序列长度 seq_len=4096 、嵌入维度 dim=4096 、注意力头数 head=32 、单头维度 head_dim=128 。
- 步骤1:预计算旋转角度
def precompute_freqs_cis(dim: int, end: int, theta: float = 10000.0):
freqs = 1.0 / (theta ** (torch.arange(0, dim, 2)[: (dim // 2)].float() / dim))
t = torch.arange(end, device=freqs.device)
freqs = torch.outer(t, freqs).float() # 生成[4096,2048]的频率矩阵
freqs_cis = torch.polar(torch.ones_like(freqs), freqs) # 转为极坐标复数形式
return freqs_cis
- 步骤2:将位置信息注入Query/Key
def apply_rotary_emb(xq: torch.Tensor, xk: torch.Tensor, freqs_cis: torch.Tensor):
# 将Query/Key转为复数形式(每2个维度一组)
xq = torch.view_as_complex(xq.float().reshape(*xq.shape[:-1], -1, 2))
xk = torch.view_as_complex(xk.float().reshape(*xk.shape[:-1], -1, 2))
# 复数相乘(实现旋转)
xq_out = torch.view_as_real(xq * freqs_cis).flatten(3)
xk_out = torch.view_as_real(xk * freqs_cis).flatten(3)
return xq_out.type_as(xq), xk_out.type_as(xk)
- 效果:位置信息被融入Query/Key中,模型可捕捉序列的相对位置关系。
3、位置编码的长度扩展
大模型训练时的上下文长度(如2k)往往小于推理需求(如32k),需对位置编码做长度扩展:
| 扩展方案 | 方法,优缺点 |
|---|---|
| 直接外推 | 继续使用原有位置编码公式 简单,但长距离(如2k→32k)性能严重下降 |
| 线性内插 | 将新位置序号按比例缩小(如2k→32k时,位置序号×1/16) 短距离性能好,但扩展倍数过大时,短距离衰减规律会失真 |
| NTK扩展 | 高频外推+低频内插(对底数进行进制转换) 综合外推/内插优点,长距离扩展后性能下降少 |
七、transformer自注意力机制(Self-Attention)详解
自注意力机制是Transformer模型的核心组件,能够并行计算序列中所有标记(Token)间的依赖关系,无需递归或卷积操作,是模型捕捉长距离语义、上下文关联的关键。
1、核心定义
自注意力机制让序列中的每个Token(如单词、字符)都能“关注”到序列中所有其他Token,并根据关联强度分配权重,最终生成融合全局上下文的Token表示。
- 通俗理解:好比阅读时,每个词都会“回头看”全文,重点关注与自己语义相关的词(如“他”会关注前文提到的人名),忽略无关词。
- 核心优势:
- 并行计算(O(n²)时间复杂度,n为序列长度),效率远超RNN的O(n)串行;
- 长距离依赖捕捉能力强(无距离限制,不像CNN受感受野约束);
- 自适应权重分配(通过数据学习依赖关系,而非人工设计)。
2、核心原理与数学公式
自注意力的计算过程可拆解为「线性变换→相似度计算→权重归一化→上下文融合」4步,核心是通过Query、Key、Value三个矩阵实现“关注”逻辑。
1. 基础符号定义
- 符号X:代表输入序列嵌入矩阵,包含n个Token,每个Token的维度为d,示例维度是[n, d_{model}];
- 符号W_Q, W_K, W_V:代表可学习的线性变换矩阵,对应维度分别是[d_{model}, d_k]、[d_{model}, d_k]、[d_{model}, d_v];
- 符号Q, K, V:分别代表Query(查询)、Key(键)、Value(值),对应维度分别是[n, d_k]、[n, d_k]、[n, d_v];
- 符号d_k:代表Query/Key的维度,通常d_k = d_{model},无示例维度;
- 符号Attention(Q,K,V):代表自注意力输出矩阵,示例维度是[n, d_v]。
2. 四步计算流程(附公式+示例)
步骤1:生成Query、Key、Value(线性变换)
对输入嵌入矩阵X分别乘以W_Q, W_K, W_V,得到三个核心矩阵:
Q=X⋅WQ,K=X⋅WK,V=X⋅VV Q = X \cdot W_Q, \quad K = X \cdot W_K, \quad V = X \cdot V_V Q=X⋅WQ,K=X⋅WK,V=X⋅VV
- 示例:假设输入序列X是3个Token的嵌入 (n=3,dmodel=4),WQ/WK/WV维度为[4,4],则Q/K/V输出维度为[3,4]。(n=3,d_{model}=4),W_Q/W_K/W_V维度为[4,4],则Q/K/V输出维度为[3,4]。 (n=3,dmodel=4),WQ/WK/WV维度为[4,4],则Q/K/V输出维度为[3,4]。
步骤2:计算相似度(Query与Key的点积)
用每个Token的Query向量与所有Token的Key向量做点积,得到“关注度分数”(分数越高,关联越强):
Score(Q,K)=Q⋅KT \text{Score}(Q,K) = Q \cdot K^T Score(Q,K)=Q⋅KT
- 维度变化:[n, d_k] \cdot [d_k, n] = [n, n](生成相似度矩阵,每行对应一个Token对所有Token的关注度);
- 示例:Q=[[1,2,3,4], [5,6,7,8], [9,10,11,12]],K^T为K的转置,点积后得到3×3相似度矩阵:
Score=[1×1+2×5+3×9+4×13...1×4+2×8+3×12+4×16.........9×1+10×5+11×9+12×13...9×4+10×8+11×12+12×16] \text{Score} = \begin{bmatrix} 1×1+2×5+3×9+4×13 & ... & 1×4+2×8+3×12+4×16 \\ ... & ... & ... \\ 9×1+10×5+11×9+12×13 & ... & 9×4+10×8+11×12+12×16 \end{bmatrix} Score= 1×1+2×5+3×9+4×13...9×1+10×5+11×9+12×13.........1×4+2×8+3×12+4×16...9×4+10×8+11×12+12×16
步骤3:权重归一化(Softmax+缩放)
1缩放:将相似度分数除以dk,避免dk过大导致点积结果溢出,Softmax后梯度消失:Scaled Score=Q⋅KTdk 1 缩放:将相似度分数除以\sqrt{d_k},避免d_k过大导致点积结果溢出,Softmax后梯度消失: \text{Scaled Score} = \frac{Q \cdot K^T}{\sqrt{d_k}} 1缩放:将相似度分数除以dk,避免dk过大导致点积结果溢出,Softmax后梯度消失:Scaled Score=dkQ⋅KT
- Softmax归一化:对每行分数做Softmax,得到权重(总和为1,代表每个Token对当前Token的贡献占比):
Weights=Softmax(Q⋅KTdk) \text{Weights} = \text{Softmax}\left( \frac{Q \cdot K^T}{\sqrt{d_k}} \right) Weights=Softmax(dkQ⋅KT)
- 示例:若d_k=4,则\sqrt{d_k}=2,将步骤2的相似度分数除以2后,通过Softmax得到权重矩阵:
Weights=[0.10.70.20.30.20.50.40.30.3] \text{Weights} = \begin{bmatrix} 0.1 & 0.7 & 0.2 \\ 0.3 & 0.2 & 0.5 \\ 0.4 & 0.3 & 0.3 \end{bmatrix} Weights= 0.10.30.40.70.20.30.20.50.3
(第一行表示:第一个Token对自己的权重0.1,对第二个Token的权重0.7,对第三个Token的权重0.2)。
步骤4:上下文融合(权重×Value)
将归一化后的权重与Value矩阵相乘,得到每个Token的最终上下文表示:
Attention(Q,K,V)=Weights⋅V \text{Attention}(Q,K,V) = \text{Weights} \cdot V Attention(Q,K,V)=Weights⋅V
- 维度变化:[n, n] \cdot [n, d_v] = [n, d_v](每个Token的输出是所有Token Value的加权和);
- 示例:用步骤3的权重矩阵乘以V([3,4]),得到最终输出[3,4],每个Token的表示都融合了全局上下文。
3、多头自注意力(Multi-Head Attention)
原生自注意力只能捕捉一种“关注模式”,多头自注意力通过并行多个自注意力头,让模型同时捕捉不同类型的依赖关系(如语法依赖、语义依赖)。
- 核心原理
将Q, K, V通过不同的线性变换矩阵分成h组(h为头数),每组独立计算自注意力,最后将所有头的输出拼接并线性变换,得到最终结果。
- 数学公式
MultiHead(Q,K,V)=Concat(Head1,Head2,...,Headh)⋅WO \text{MultiHead}(Q,K,V) = \text{Concat}(\text{Head}_1, \text{Head}_2, ..., \text{Head}_h) \cdot W_O MultiHead(Q,K,V)=Concat(Head1,Head2,...,Headh)⋅WO
其中:
Headi=Attention(Q⋅WQi,K⋅WKi,V⋅WVi)(每个头的独立自注意力);WQi,WKi,WVi:第i个头的线性变换矩阵(维度[dmodel,dk/h]);WO:最终的线性变换矩阵(维度[h⋅dv,dmodel])。 \text{Head}_i = \text{Attention}(Q \cdot W_{Q_i}, K \cdot W_{K_i}, V \cdot W_{V_i})(每个头的独立自注意力); W_{Q_i}, W_{K_i}, W_{V_i}:第i个头的线性变换矩阵(维度[d_{model}, d_k/h]); W_O:最终的线性变换矩阵(维度[h \cdot d_v, d_{model}])。 Headi=Attention(Q⋅WQi,K⋅WKi,V⋅WVi)(每个头的独立自注意力);WQi,WKi,WVi:第i个头的线性变换矩阵(维度[dmodel,dk/h]);WO:最终的线性变换矩阵(维度[h⋅dv,dmodel])。
3. 示例(h=2头,d_model=4,d_k=d_v=4)
每个头的WQi/WKi/WVi维度为[4,2],将Q/K/V([3,4])分成2组,每组维度[3,2];2.两个头分别计算自注意力,得到两个输出([3,2]);3.拼接两个输出得到[3,4],再乘以WO([4,4]),最终输出[3,4]。 每个头的W_{Q_i}/W_{K_i}/W_{V_i}维度为[4,2],将Q/K/V([3,4])分成2组,每组维度[3,2]; 2. 两个头分别计算自注意力,得到两个输出([3,2]); 3. 拼接两个输出得到[3,4],再乘以W_O([4,4]),最终输出[3,4]。 每个头的WQi/WKi/WVi维度为[4,2],将Q/K/V([3,4])分成2组,每组维度[3,2];2.两个头分别计算自注意力,得到两个输出([3,2]);3.拼接两个输出得到[3,4],再乘以WO([4,4]),最终输出[3,4]。
4、掩码自注意力(Masked Self-Attention)
在生成任务(如文本生成)中,为了避免模型“看到未来的Token”(如预测第i个词时,不能利用第i+1个词的信息),需要对相似度矩阵添加掩码(Mask)。
- 掩码类型
- 下三角掩码:将相似度矩阵中“未来位置”(行号<列号)的分数设为-\infty,Softmax后权重为0;
- 示例掩码矩阵(n=3):
Mask=[0−∞−∞00−∞000] \text{Mask} = \begin{bmatrix} 0 & -\infty & -\infty \\ 0 & 0 & -\infty \\ 0 & 0 & 0 \end{bmatrix} Mask= 000−∞00−∞−∞0
(第一行只能关注第一个Token,第二行只能关注前两个Token,第三行可关注所有Token)。
- 计算过程
Masked Attention(Q,K,V)=Softmax(Q⋅KTdk+Mask)⋅V \text{Masked Attention}(Q,K,V) = \text{Softmax}\left( \frac{Q \cdot K^T}{\sqrt{d_k}} + \text{Mask} \right) \cdot V Masked Attention(Q,K,V)=Softmax(dkQ⋅KT+Mask)⋅V
5、代码实现(PyTorch)
- 原生自注意力实现
import torch
import torch.nn.functional as F
class SelfAttention(torch.nn.Module):
def __init__(self, d_model):
super().__init__() # 继承nn.Module的初始化
self.d_model = d_model # 模型的特征维度(如Transformer中常用512)
# 定义Q、K、V的线性变换矩阵(核心参数)
self.w_q = torch.nn.Linear(d_model, d_model) # Q的线性层:d_model→d_model
self.w_k = torch.nn.Linear(d_model, d_model) # K的线性层:d_model→d_model
self.w_v = torch.nn.Linear(d_model, d_model) # V的线性层:d_model→d_model
def forward(self, x, mask=None):
# x: [batch_size, seq_len, d_model]
batch_size, seq_len, _ = x.shape
# 步骤1:生成Q、K、V
q = self.w_q(x) # [batch_size, seq_len, d_model]
k = self.w_k(x) # [batch_size, seq_len, d_model]
v = self.w_v(x) # [batch_size, seq_len, d_model]
# 步骤2:计算相似度分数
scores = torch.matmul(q, k.transpose(-2, -1)) # [batch_size, seq_len, seq_len]
# 步骤3:缩放+掩码+Softmax
scores = scores / torch.sqrt(torch.tensor(self.d_model, dtype=torch.float32))
if mask is not None:
scores = scores.masked_fill(mask == 0, -1e9) # 掩码位置设为-∞
weights = F.softmax(scores, dim=-1) # [batch_size, seq_len, seq_len]
# 步骤4:上下文融合
output = torch.matmul(weights, v) # [batch_size, seq_len, d_model]
return output
- 多头自注意力实现
class MultiHeadAttention(torch.nn.Module):
def __init__(self, d_model, num_heads):
super().__init__()
self.d_model = d_model
self.num_heads = num_heads
self.d_k = d_model // num_heads # 每个头的维度
# 定义Q、K、V的线性变换矩阵(共享)
self.w_q = torch.nn.Linear(d_model, d_model)
self.w_k = torch.nn.Linear(d_model, d_model)
self.w_v = torch.nn.Linear(d_model, d_model)
# 最终输出的线性变换矩阵
self.w_o = torch.nn.Linear(d_model, d_model)
def forward(self, x, mask=None):
batch_size, seq_len, _ = x.shape
# 步骤1:生成Q、K、V并分多头
q = self.w_q(x).view(batch_size, seq_len, self.num_heads, self.d_k).transpose(1, 2) # [batch_size, num_heads, seq_len, d_k]
k = self.w_k(x).view(batch_size, seq_len, self.num_heads, self.d_k).transpose(1, 2)
v = self.w_v(x).view(batch_size, seq_len, self.num_heads, self.d_k).transpose(1, 2)
# 步骤2-4:计算自注意力(每个头独立)
scores = torch.matmul(q, k.transpose(-2, -1)) / torch.sqrt(torch.tensor(self.d_k, dtype=torch.float32))
if mask is not None:
scores = scores.masked_fill(mask == 0, -1e9)
weights = F.softmax(scores, dim=-1)
attn_output = torch.matmul(weights, v) # [batch_size, num_heads, seq_len, d_k]
# 拼接所有头的输出并线性变换
attn_output = attn_output.transpose(1, 2).contiguous().view(batch_size, seq_len, self.d_model)
output = self.w_o(attn_output) # [batch_size, seq_len, d_model]
return output
在transformer中大概是这个流程:
6、关键问题解答
- 为什么要缩放(除以dk)? 为什么要缩放(除以\sqrt{d_k})?为什么要缩放(除以dk)?
- 当dk较大时,Query与Key的点积结果会很大,导致Softmax函数输出趋近于0或1,梯度消失;当d_k较大时,Query与Key的点积结果会很大,导致Softmax函数输出趋近于0或1,梯度消失;当dk较大时,Query与Key的点积结果会很大,导致Softmax函数输出趋近于0或1,梯度消失;
- 缩放后,点积结果的方差为1,避免数值不稳定。
- 多头自注意力的“头数”如何选择?
- 常见取值:8(Transformer原始论文)、12(BERT)、32(Llama);
- 头数越多,模型捕捉的依赖模式越丰富,但计算量和参数量会线性增加(需权衡性能与效率)。
如果有勘误请指出,谢谢喵,如果觉得有帮助,就赏点小鱼干吧喵

开源鸿蒙跨平台开发社区汇聚开发者与厂商,共建“一次开发,多端部署”的开源生态,致力于降低跨端开发门槛,推动万物智联创新。
更多推荐
 14
14 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)