基于Java Web的问答系统构建指南
SSH框架是Java社区中最受欢迎的企业级Web应用框架之一。其设计目标是通过整合Spring的业务层、Struts的控制层和Hibernate的数据访问层,为Java开发者提供一站式解决方案。Spring框架的核心理念是基于轻量级的控制反转(IoC)和面向切面编程(AOP)为应用程序提供全面的基础结构支持。它简化了Java企业级应用的开发,并降低了复杂性,使得开发者能够专注于业务逻辑的实现。Sp

简介:本文介绍了如何利用Java技术栈构建一个问答系统,重点在于后端架构和前端开发模式的应用。通过结合Spring、Struts和Hibernate框架,采用JSON数据交互和Nginx服务器,实现了一个高效可扩展的问答系统。文章详细阐述了SSH框架的组件功能,Spring的核心作用,Struts的MVC处理方式,Hibernate的ORM机制,组件化前端开发的优势,以及JSON在前后端分离架构中的重要性。 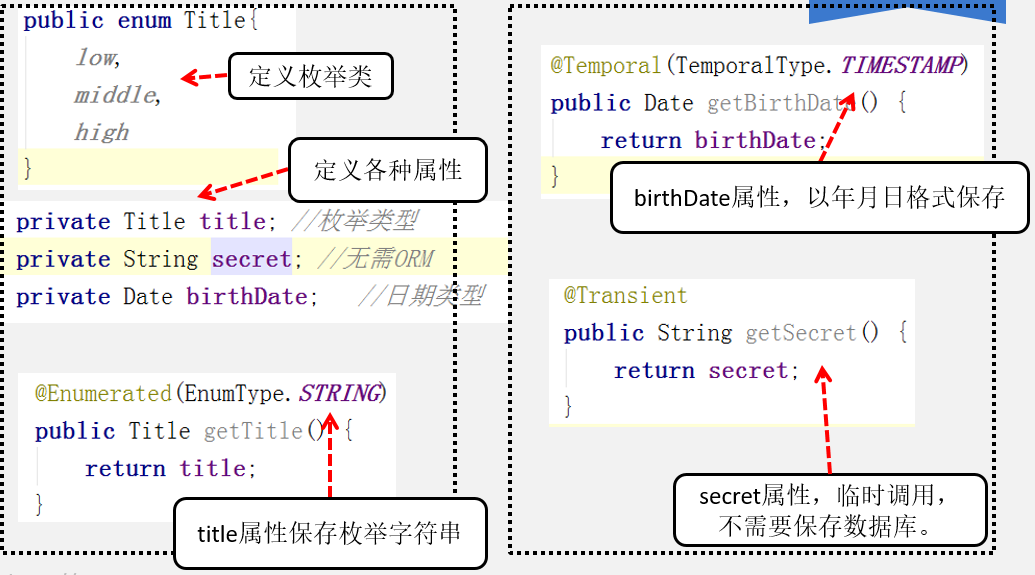
1. SSH框架构建后端逻辑
在当今的Web应用开发中,后端逻辑的构建是至关重要的环节,它不仅需要处理数据,还要管理业务流程并确保安全性和性能。本章将聚焦于如何利用SSH框架(Spring, Struts, Hibernate)构建稳定而高效的后端逻辑。
1.1 SSH框架简介
SSH框架是Java社区中最受欢迎的企业级Web应用框架之一。其设计目标是通过整合Spring的业务层、Struts的控制层和Hibernate的数据访问层,为Java开发者提供一站式解决方案。
1.2 开发环境搭建
在开始构建SSH框架之前,首先需要确保开发环境已经准备妥当。具体包括Java开发工具包(JDK)、集成开发环境(IDE)、数据库系统(如MySQL),以及Spring、Struts和Hibernate框架本身的正确安装和配置。
1.3 框架集成步骤
接下来,开发者将按照以下步骤集成SSH框架: - 配置Spring框架来管理业务逻辑和事务; - 集成Struts框架以处理用户请求和业务流程调度; - 将Hibernate框架嵌入以简化数据库操作; - 通过Spring IoC容器整合以上三者,形成一个连贯的整体。
通过SSH框架,开发者可以专注于业务逻辑的实现,而将底层的重复工作交给框架来处理,从而提高开发效率和应用质量。在后续章节中,我们将深入探讨Spring、Struts和Hibernate的内部机制和高级特性,让读者能够更加得心应手地使用这些工具。
2. 深入理解Spring框架核心功能
2.1 Spring框架基础介绍
2.1.1 Spring框架的核心理念
Spring框架的核心理念是基于轻量级的控制反转(IoC)和面向切面编程(AOP)为应用程序提供全面的基础结构支持。它简化了Java企业级应用的开发,并降低了复杂性,使得开发者能够专注于业务逻辑的实现。
Spring框架的设计目标是帮助开发者快速搭建高质量的应用程序。它通过提供一系列层次化的模块,覆盖了从企业级应用开发、测试、部署到运维的各个阶段。Spring框架的设计也强调了非侵入性和轻量级,允许开发者在选择使用它的特定部分时拥有灵活性。
Spring在设计上还遵循了最小入侵原则,这意味着应用程序的业务逻辑可以独立于Spring框架存在,减少框架自身对业务逻辑的影响。这一点通过Spring的依赖注入(DI)机制得到了实现,它支持松耦合的组件设计,有助于提高代码的可复用性和可测试性。
2.1.2 Spring框架的主要模块解析
Spring框架由众多模块组成,每个模块都针对特定的应用开发需求提供了支持。以下是一些主要模块的简要介绍:
-
Spring Core Container :核心容器包括了Spring的基本模块,例如Core, Beans, Context, 和 Expression Language模块。它提供了IoC容器的实现,用于管理对象的创建和依赖注入。
-
Spring AOP :提供了面向切面编程的实现,允许开发者定义方法拦截器和切点,用于在不修改源码的情况下实现额外的功能。
-
Spring MVC :模型-视图-控制器(MVC)实现,用于构建Web应用程序,提供了灵活的请求映射、数据绑定、验证以及格式化等功能。
-
Spring Data Access/Integration :提供对数据访问的支持,包括JDBC、ORM、OXM、JMS 和 Transactions模块,简化数据访问代码,并支持多种数据库操作技术。
-
Spring Web :包含了支持构建Web应用程序所需的所有工具,如Spring Web MVC、Spring WebFlux以及内嵌服务器支持。
-
Spring Test :提供对JUnit或TestNG测试框架的集成,支持测试Spring组件,包括IoC容器和Web应用程序。
Spring框架的模块化设计使其成为一个高度可扩展的平台,开发者可以根据具体的应用需求选择需要的模块使用。
2.2 Spring的依赖注入与AOP
2.2.1 依赖注入的原理与应用
依赖注入(Dependency Injection, DI)是Spring框架的一个核心功能,通过它可以实现组件之间的松耦合。依赖注入允许一个对象定义依赖关系,而不是自己创建依赖对象,这样的好处是可以使代码更加灵活和易于测试。
依赖注入的原理主要是通过容器在运行时,将依赖对象注入到使用它们的对象中。在Spring中,这种依赖注入通常是通过配置文件或者注解实现的。以下是依赖注入的几种类型:
- 构造器注入 :通过构造函数提供依赖关系。
- setter注入 :通过setter方法提供依赖关系。
- 字段注入 :通过字段直接赋值依赖关系,通常通过注解实现。
Spring容器根据定义好的配置,会创建对象,并在创建对象的过程中注入所需的依赖。例如,如果我们有一个接口 MessageService 和实现类 EmailService ,我们可以这样使用构造器注入:
@Component
public class MessageService {
private final EmailService emailService;
@Autowired
public MessageService(EmailService emailService) {
this.emailService = emailService;
}
// ...
}
在上述代码中, MessageService 的构造器通过 @Autowired 注解声明了对 EmailService 的依赖。Spring容器会自动创建 EmailService 的实例,并在创建 MessageService 时将其实例注入其中。
依赖注入的应用场景非常广泛,它不仅能用于服务组件的注入,还可以用于其他资源的注入,如数据库连接、事务管理器等。
2.2.2 面向切面编程(AOP)的实践
面向切面编程(Aspect-Oriented Programming, AOP)是Spring框架中另一个重要的特性,它允许开发者将横切关注点(cross-cutting concerns)从业务逻辑中分离出来。横切关注点是一些散布在多个类中的功能,如日志、安全检查、事务管理等。
在Spring AOP中,开发者可以通过定义切面(aspect)来实现AOP。切面是一个可以包含多个通知(advice)和切点(pointcut)的模块。通知定义了在特定连接点(如方法执行前后)要执行的动作。切点则定义了哪些连接点将被通知应用。
下面是一个简单的Spring AOP应用实例:
@Aspect
@Component
public class MyLoggingAspect {
@Before("execution(* com.example.service.*.*(..))")
public void logBefore(JoinPoint joinPoint) {
System.out.println("Before method: " + joinPoint.getSignature().getName());
}
}
在这个例子中, MyLoggingAspect 类被标记为一个切面,其中包含了一个前置通知( @Before ),它会在 com.example.service 包下的任意方法执行前打印一条日志信息。 execution(* com.example.service.*.*(..)) 是切点表达式,它定义了通知应用的范围。
使用AOP可以显著提高代码的可读性和可维护性,因为横切关注点被集中管理,而不是散布在业务逻辑代码中。
2.3 Spring中的事务管理
2.3.1 事务管理的概念与机制
在企业级应用开发中,事务管理是一个关键的概念,它确保了数据的一致性和完整性。事务是一系列的操作,这些操作作为一个整体工作单元,要么全部成功,要么全部失败。事务管理提供了对事务行为的控制和配置,包括事务的边界定义、传播行为以及事务的隔离级别。
Spring框架提供了全面的事务管理支持,它不仅支持声明式事务,还支持编程式事务管理。声明式事务通过配置实现事务的边界和行为定义,而不需要在业务逻辑代码中显式控制事务。这使得事务管理代码与业务逻辑代码分离,从而使得代码更加简洁和易于维护。
Spring的声明式事务管理机制基于AOP,事务的配置和管理在XML配置文件或注解中定义。例如,通过使用 @Transactional 注解,开发者可以轻松地将事务管理应用于服务层的方法上:
@Transactional
public void performTransaction() {
// Some business logic that should run within a transaction
}
在这个例子中, performTransaction 方法被标记为事务性的。Spring容器在运行时会自动为其创建和管理事务。
2.3.2 在Java Web项目中实现声明式事务
在Java Web项目中,实现声明式事务通常涉及以下几个步骤:
-
引入依赖 :确保Spring框架相关的依赖已经在项目中配置,特别是事务管理模块。
-
配置事务管理器 :通常在Spring的配置文件中定义一个事务管理器bean。对于基于JDBC或JPA的项目,可以分别使用
DataSourceTransactionManager或JpaTransactionManager。 -
启用注解驱动的事务管理 :通过在配置类中使用
@EnableTransactionManagement注解或在XML配置文件中添加相应的命名空间和标签来启用注解驱动的事务管理。 -
应用事务注解 :在需要事务管理的业务逻辑方法上使用
@Transactional注解。
下面是一个简单的Spring配置类示例,展示了如何设置事务管理器:
@Configuration
@EnableTransactionManagement
public class TransactionConfig {
@Bean
public PlatformTransactionManager transactionManager(EntityManagerFactory entityManagerFactory) {
return new JpaTransactionManager(entityManagerFactory);
}
}
在这个配置类中, JpaTransactionManager 被定义为bean,并通过 @Bean 注解注入到Spring容器中。 @EnableTransactionManagement 注解启用了注解驱动的事务管理。
使用声明式事务管理之后,开发者不需要在代码中显式控制事务的开始和结束,大大简化了事务操作的代码复杂度。同时,声明式事务管理使得事务的行为配置更加集中和灵活,便于管理。
在企业级应用中,合理使用Spring的事务管理特性能够极大地提升应用的健壮性和效率。通过灵活的事务管理机制,可以确保关键业务操作的安全性和一致性。
3. Struts MVC动作调度与业务逻辑实现
在本章中,我们将深入探讨Struts框架如何利用MVC设计模式来实现动作调度和业务逻辑处理。Struts作为Java Web开发的一个流行框架,其通过成熟的MVC模式将视图层、控制器层和模型层分离,使得开发者能够更加专注于业务逻辑的实现,同时提高了代码的可维护性和可扩展性。
3.1 Struts框架的工作原理
3.1.1 MVC设计模式简介
MVC(Model-View-Controller)是一种将应用程序分为三个核心组件的设计模式,旨在实现对业务逻辑、用户界面和输入数据处理的分离。
- Model(模型) :处理业务逻辑和与数据库等数据源交互的组件。
- View(视图) :显示数据的组件,是用户界面的一部分。
- Controller(控制器) :接收用户输入,调用模型和视图去完成用户的请求。
MVC模式通过分离关注点来简化应用程序的结构,使得代码更加模块化,便于修改和维护。
3.1.2 Struts工作流程解析
Struts框架通过一系列配置文件和类实现了MVC设计模式。其工作流程通常如下:
- 接收用户请求 :Web层接收到用户的HTTP请求。
- 分发请求 :Struts的
ActionServlet根据配置文件中的映射信息将请求分发给对应的Action对象处理。 - 处理业务逻辑 :Action对象调用业务逻辑组件(即Model)进行业务处理,并可返回不同类型的
ActionForward对象,指定视图组件。 - 返回结果 :根据Action处理的结果,ActionServlet再将请求转发至相应的视图组件。
- 生成响应 :视图组件接收到业务逻辑处理结果后,生成最终的响应返回给用户。
Struts框架的这种流程设计极大地提高了Web应用的可管理性和可维护性。
3.2 Struts的动作类与表单处理
3.2.1 动作类的编写与执行流程
Struts中的Action类是其MVC模式中控制器的核心。开发者需要编写Action类来处理来自用户的请求,并与模型层交互。执行流程如下:
- Action类的编写 :继承自
Action接口或ActionSupport类,并覆盖execute方法来执行业务逻辑。 - 执行流程 :
- 用户请求触发一个Action。
- Struts框架拦截请求,并调用对应的Action实例的
execute方法。 execute方法中根据业务逻辑进行处理,如访问数据库、校验数据等。- 返回一个
ActionForward对象,该对象定义了下一步操作的逻辑,如转发到另一个页面或重新指向当前页面的另一个Action。 这里是一个简单的Action类示例:
public class LoginAction extends ActionSupport {
private String username;
private String password;
// Getters and setters...
@Override
public ActionForward execute(ActionMapping mapping, ActionForm form,
HttpServletRequest request, HttpServletResponse response)
throws Exception {
// 业务逻辑处理
boolean isValidUser = validateUser(request.getParameter("username"), request.getParameter("password"));
if (isValidUser) {
// 认证成功后,转发到主页面
return mapping.findForward("success");
} else {
// 认证失败后,转发回登录页面
return mapping.findForward("input");
}
}
private boolean validateUser(String username, String password) {
// 这里应该调用服务层代码进行验证
return "admin".equals(username) && "password".equals(password);
}
}
3.2.2 表单验证与数据绑定
Struts利用ActionForm来实现请求参数与表单数据的绑定。ActionForm类是模型组件与视图组件之间的桥梁,它不仅可以封装数据,还可以进行数据验证。
- 表单验证 :Struts的验证框架允许在ActionForm中声明验证规则,或者通过配置文件(如
validation.xml)来定义验证规则。 - 数据绑定 :通过表单标签(如
<html:text>)将HTML表单字段绑定到ActionForm对象的属性上,使得Action类能够通过属性访问表单数据。
3.3 Struts 2的高级特性应用
3.3.1 拦截器的使用与自定义
Struts 2引入了拦截器(Interceptor)机制,它是一种可以拦截请求并进行预处理或后处理的组件,类似于AOP中的切面。
- 拦截器的作用 :拦截器可以在Action执行前后执行代码,用于执行日志记录、权限检查、数据校验等操作。
- 自定义拦截器 :通过实现
Interceptor接口或继承AbstractInterceptor类创建自定义拦截器。
public class MyInterceptor extends AbstractInterceptor {
public String intercept(ActionInvocation invocation) throws Exception {
HttpServletRequest request = (HttpServletRequest) invocation.getInvocationContext().get(ServletActionContext.HTTP_REQUEST);
HttpServletResponse response = (HttpServletResponse) invocation.getInvocationContext().get(ServletActionContext.HTTP_RESPONSE);
// 自定义的预处理逻辑
// 调用下一个拦截器或Action
String result = invocation.invoke();
// 自定义的后处理逻辑
return result;
}
}
3.3.2 结果类型与类型转换器的高级运用
Struts 2中的结果类型(Result Type)定义了返回给客户端的响应类型,如直接输出、转发、重定向等。
- 定义结果类型 :在struts.xml中配置不同的结果类型。
- 类型转换器 :用于将ActionForm中的数据转换成适合视图层展示的格式,Struts 2提供了强大的默认类型转换器,并支持自定义转换器。
自定义类型转换器示例:
public class DateConverter extends TypeConverter {
public Object convertFromString(Map context, String[] values, Class toClass) {
if (toClass != Date.class) {
throw new TypeConversionException("Converter DateConverter only supports java.util.Date class");
}
if (values == null || values.length == 0 || values[0] == null || values[0].trim().equals("")) {
return null;
}
try {
SimpleDateFormat format = new SimpleDateFormat("yyyy-MM-dd");
return format.parse(values[0]);
} catch (ParseException e) {
throw new TypeConversionException(e);
}
}
public String convertToString(Map context, Object o) {
SimpleDateFormat format = new SimpleDateFormat("yyyy-MM-dd");
return format.format(o);
}
}
Struts 2的这些高级特性使得Web应用的开发更加灵活和高效。通过本章的学习,读者应能理解并掌握Struts框架在Web应用开发中的作用,并能应用到实际的项目中去。
4. Hibernate ORM简化数据库操作
4.1 ORM基本概念与Hibernate框架概述
4.1.1 对象关系映射(ORM)原理
对象关系映射(Object Relational Mapping,简称ORM)是一种编程技术,用于实现面向对象编程语言里不同类型系统的数据之间的转换。在ORM框架中,对象模型和关系模型之间的映射关系会被自动处理,从而让开发者能够用面向对象的方式去操作数据库中的数据。
ORM的原理是通过反射机制和动态代理,在运行时创建类的实例、属性和方法,这些实例和方法与数据库中的表、字段和SQL语句一一对应。在ORM框架中,开发人员通过操作这些实例和方法,就能完成数据的增删改查操作。
4.1.2 Hibernate框架特点与架构
Hibernate是一个开源的对象关系映射(ORM)框架,它提供了一种面向Java对象的方式来查询和更新数据库中的数据。Hibernate不仅支持数据库中的基本CRUD操作,而且提供了查询语言(HQL)和延迟加载等高级特性。
Hibernate的架构可以分为以下几个核心组件: - Session:代表应用程序和数据库之间的持久化管理会话。 - SessionFactory:负责Hibernate配置信息的读取,并生成Session实例。 - Transaction:管理事务的行为,可以进行事务的提交或回滚。 - Configuration:负责读取hibernate.cfg.xml配置文件。 - Query:用于执行HQL语句以及Critera查询。
4.2 Hibernate的持久化操作
4.2.1 Session与Transaction管理
在Hibernate中,Session是操作数据的主接口,它对数据库进行持久化操作的实例。Session实例持有与数据库的连接,并且维护着一个持久化对象的缓存。
以下是一个简单的Session操作示例代码:
Session session = sessionFactory.openSession(); // 打开Session
Transaction transaction = session.beginTransaction(); // 开始事务
try {
// 假设User是一个实体类,user1是User的实例
User user1 = new User("user1", "password1");
session.save(user1); // 保存用户信息到数据库
transaction.commit(); // 提交事务
} catch (Exception e) {
transaction.rollback(); // 发生异常时回滚事务
throw e;
} finally {
session.close(); // 关闭Session
}
4.2.2 HQL与Criteria查询方式
HQL(Hibernate Query Language)是一种面向对象的查询语言,用于检索和操作持久化对象。它与SQL类似,但HQL是面向对象的,可以操作类和类的属性。
Session session = sessionFactory.openSession();
String hql = "FROM User WHERE username = :username";
Query query = session.createQuery(hql);
query.setParameter("username", "user1"); // 设置查询参数
List<User> users = query.list(); // 执行查询并返回结果列表
Criteria接口提供了另一种创建查询的方式,是类型安全的,并且可以动态构建查询。
Session session = sessionFactory.openSession();
Criteria criteria = session.createCriteria(User.class);
criteria.add(Restrictions.eq("username", "user1")); // 添加查询条件
List<User> users = criteria.list(); // 执行查询并返回结果列表
4.3 Hibernate高级特性与性能优化
4.3.1 缓存策略与配置
Hibernate提供两种类型的缓存:一级缓存(Session级别)和二级缓存(SessionFactory级别)。一级缓存是隐式的,自动处理;二级缓存则是可配置的,可以由多个Session共享。
二级缓存的配置示例:
<hibernate-configuration>
<session-factory>
<!-- 其他配置 -->
<property name="cache.provider_class">org.hibernate.cache.EhCacheProvider</property>
<property name="cache.use_query_cache">true</property>
<property name="cache.region.factory_class">org.hibernate.cache.ehcache.EhCacheRegionFactory</property>
<!-- EhCache的具体配置文件 -->
<property name="cache.ehcache.config_file">/path/to/ehcache.xml</property>
</session-factory>
</hibernate-configuration>
4.3.2 性能调优与SQL优化技巧
Hibernate性能调优涉及多个层面,包括查询优化、二级缓存使用、懒加载策略等。在查询时,应尽量减少数据库访问次数,使用HQL和Criteria等高级查询技术来实现。同时,合理配置二级缓存,可以有效减少数据库的访问压力。
SQL优化技巧可以从以下几个方面进行: - 确保建立适当的索引,以加快查询速度。 - 对复杂的查询进行分析,拆分成简单的子查询。 - 使用HQL和Criteria API来减少生成的SQL数量,并利用其特性如批量抓取和查询缓存。 - 使用Hibernate的懒加载策略来减少不需要立即加载的数据,从而减少数据库负载。
Hibernate的SQL日志输出有助于开发者分析和优化生成的SQL语句,可以进行如下的配置:
<property name="show_sql">true</property>
<property name="format_sql">true</property>
Hibernate是一个强大的ORM框架,通过合理的配置和优化,可以大幅提高数据操作的效率和系统的性能。在实际开发中,开发者应根据具体需求,灵活运用Hibernate提供的特性,并结合性能调优技巧,以达到最佳的开发和运行效果。
5. 前端与后端的交互及服务器部署
5.1 JSON数据交互格式解析
5.1.1 JSON格式的定义与优势
JSON(JavaScript Object Notation)是一种轻量级的数据交换格式,易于人阅读和编写,同时也易于机器解析和生成。它的设计基于JavaScript的一个子集,因此继承了JavaScript对象字面量语法,但JSON是一个独立于语言的文本格式,它被所有的现代编程语言支持。
JSON的优势在于:
- 轻量级 :与XML相比,JSON结构更为简单,通常在数据传输中占用更少的带宽。
- 易于阅读和编写 :JSON格式简单,可以很直观地表达复杂的数据结构。
- 易于机器解析和生成 :大多数编程语言提供了用于处理JSON的库,使得数据处理变得简单高效。
- 跨平台和语言 :JSON是一种语言无关的格式,因此可以在不同的平台和语言之间轻松交换数据。
5.1.2 在Java Web项目中处理JSON数据
在Java Web项目中处理JSON数据,通常会用到一些流行的库,如Jackson或Gson。以下是一个使用Jackson库处理JSON数据的简单示例:
import com.fasterxml.jackson.databind.ObjectMapper;
import java.util.HashMap;
import java.util.Map;
public class JsonExample {
public static void main(String[] args) {
try {
ObjectMapper mapper = new ObjectMapper();
Map<String, String> data = new HashMap<>();
data.put("name", "John Doe");
data.put("age", "30");
// 将Java对象转换为JSON字符串
String json = mapper.writeValueAsString(data);
System.out.println(json);
// 将JSON字符串解析为Java对象
Map<String, String> newData = mapper.readValue(json, Map.class);
System.out.println(newData.get("name"));
} catch (Exception e) {
e.printStackTrace();
}
}
}
以上代码中, ObjectMapper 类是Jackson库中处理JSON的核心类。首先,我们创建了一个 Map 对象并用数据填充。然后,使用 writeValueAsString 方法将Map对象转换成JSON字符串。相反地, readValue 方法可以将JSON字符串解析回Java对象。
5.2 前后端分离架构下的数据交互
5.2.1 RESTful API设计原则
RESTful API是一种创建Web服务的架构风格和方法,它遵循REST(Representational State Transfer)原则。REST不是标准,而是一系列设计原则的集合,其核心思想是使用HTTP协议提供的方法(GET, POST, PUT, DELETE等)来处理资源。
RESTful API设计原则包括:
- 资源的URL表示 :每个URL代表一个资源或资源的集合。
- 使用HTTP方法 :根据操作类型选择合适的HTTP方法。
- 无状态通信 :服务器不应保存客户端的状态。
- 响应式设计 :应该使用HTTP状态码来表达操作的成功或失败。
- 统一接口 :客户端与服务端之间的交互应通过统一接口进行。
5.2.2 前后端分离的数据交互实践
在前后端分离的架构中,前端和后端通过API接口进行通信。前端负责用户界面和用户体验,后端负责逻辑处理和数据存储。以下是一个简单的前后端分离交互实践示例:
sequenceDiagram
participant F as 前端
participant B as 后端
F ->> B: GET /api/users
B -->> F: 返回用户列表
F ->> B: POST /api/users {name: "John", age: 30}
B -->> F: 用户添加成功
在上述流程中,前端发送一个GET请求到后端获取用户列表,后端处理请求后将数据返回给前端。接着,前端发送一个POST请求添加新用户,后端接收到请求并处理后,返回成功信息给前端。
5.3 Nginx服务器的部署与配置
5.3.1 Nginx的基本使用与安装
Nginx(发音为“engine-x”)是一个高性能的HTTP和反向代理服务器,也是一个IMAP/POP3/SMTP服务器。Nginx以其高稳定性和丰富的功能集而广受欢迎,非常适合于负载均衡、静态资源服务、反向代理等场景。
安装Nginx通常很简单,可以在大多数Linux发行版中使用包管理器进行安装,例如在Ubuntu上可以使用以下命令:
sudo apt update
sudo apt install nginx
安装完成后,Nginx默认配置文件通常位于 /etc/nginx/nginx.conf 。
5.3.2 Nginx作为反向代理服务器的配置与优化
Nginx可以作为反向代理服务器来优化应用性能和安全。以下是一个Nginx配置文件的简单例子:
http {
server {
listen 80;
location / {
proxy_pass http://localhost:8080; # 假设后端服务监听在8080端口
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
}
}
}
在该配置中,Nginx监听80端口,接收到请求后转发到后端服务(监听在8080端口)。 proxy_set_header 指令用于设置传递给后端的头信息。
Nginx的优化通常包括:
- 开启Gzip压缩 :减少传输数据量。
- 调整工作进程数量 :根据CPU核心数调整。
- 调整连接超时设置 :提高系统的响应能力。
- 使用缓存 :减少后端服务的负载。
5.4 前端组件化开发模式
5.4.1 组件化开发的优势与实现方式
组件化开发是一种前端开发模式,它将用户界面分割为独立、可复用的组件,每个组件拥有自己的视图、逻辑和样式。组件化开发的优势包括:
- 代码复用性高 :相同的组件可以在不同的地方复用。
- 降低复杂性 :通过模块化的方式使复杂的系统更易于理解和管理。
- 提高开发效率 :组件化可以使得团队协作更高效。
- 提高产品质量 :组件化通过单元测试、功能隔离使得代码质量更高。
实现前端组件化的框架有很多,如React、Vue和Angular等。
5.4.2 前端工程化工具与流程
前端工程化是指使用工具或流程自动化处理重复性工作,以提高开发效率和软件质量。常用的前端工程化工具包括:
- 构建工具 :如Webpack、Rollup等,用于模块打包和代码转换。
- 包管理器 :如npm、Yarn,用于管理依赖。
- 版本控制 :如Git,用于代码版本控制。
- 自动化测试工具 :如Jest、Mocha等,用于自动化测试。
- 代码格式化工具 :如ESLint、Prettier,用于保持代码风格的一致性。
前端工程化流程通常包含以下步骤:
- 初始化项目 :通过脚手架工具(如Create React App、Vue CLI)快速搭建项目结构。
- 代码编写 :按照组件化的方式编写代码。
- 代码检查与格式化 :确保代码风格统一和无语法错误。
- 构建与打包 :使用构建工具将代码打包为生产环境的文件。
- 部署 :将构建好的文件部署到服务器或CDN。
以上内容介绍了在前后端交互中,JSON数据交互格式的重要性及应用方式,RESTful API的设计原则和实践,以及Nginx服务器的部署和配置技巧。还讨论了前端组件化开发的优势和实现方式,以及前端工程化工具与流程。这些知识点能够帮助IT行业从业者更深入地理解和应用前端与后端的交互技术,以及部署与优化Web应用的能力。
简介:本文介绍了如何利用Java技术栈构建一个问答系统,重点在于后端架构和前端开发模式的应用。通过结合Spring、Struts和Hibernate框架,采用JSON数据交互和Nginx服务器,实现了一个高效可扩展的问答系统。文章详细阐述了SSH框架的组件功能,Spring的核心作用,Struts的MVC处理方式,Hibernate的ORM机制,组件化前端开发的优势,以及JSON在前后端分离架构中的重要性。

开源鸿蒙跨平台开发社区汇聚开发者与厂商,共建“一次开发,多端部署”的开源生态,致力于降低跨端开发门槛,推动万物智联创新。
更多推荐

 15
15 0
0- 0



 已为社区贡献18条内容
已为社区贡献18条内容

所有评论(0)