基于昇思大模型的 RNN 情感分类实战:从原理到代码实现
情感分类是指将文本(如评论、推文)划分为不同情感类别的任务(常见为二分类:正面 / 负面)。循环神经网络(RNN)因能捕捉序列数据的时序依赖关系,成为处理文本这类序列数据的经典选择 —— 它可以 “记住” 前文信息,从而理解文本的语义连贯性。在昇思 MindSpore 中,我们可以通过简洁的代码实现 RNN(含 LSTM、GRU 等变体)的情感分类模型,下面从数据处理、模型构建、训练评估三个环节展
在自然语言处理领域,情感分类是一项基础且重要的任务,它能帮助我们理解文本背后的情感倾向(如正面、负面)。本文将带你走进基于昇思 MindSpore 框架的 RNN 情感分类实战,从模型原理到代码实现,一步步搭建属于你的情感分析模型。
一、情感分类与 RNN 模型概述
情感分类是指将文本(如评论、推文)划分为不同情感类别的任务(常见为二分类:正面 / 负面)。循环神经网络(RNN)因能捕捉序列数据的时序依赖关系,成为处理文本这类序列数据的经典选择 —— 它可以 “记住” 前文信息,从而理解文本的语义连贯性。
在昇思 MindSpore 中,我们可以通过简洁的代码实现 RNN(含 LSTM、GRU 等变体)的情感分类模型,下面从数据处理、模型构建、训练评估三个环节展开。
二、数据处理:文本向量化
情感分类的第一步是将文本转化为模型可理解的数值形式,通常分为分词、构建词表、文本编码、词嵌入四个步骤。
1. 分词与词表构建
以电影评论数据集为例,我们先对文本进行分词,再统计词频构建词表(包含常用词和特殊标记如<pad>填充、<unk>未知词)。

2. 文本编码与填充
将分词后的文本转换为词表对应的索引,并对长度不一的文本进行填充,保证输入维度统一。

三、模型构建:Embedding + LSTM + Dense
我们采用 “词嵌入→LSTM→全连接层” 的经典结构,其中:
- 词嵌入层:将词索引转化为低维稠密向量,捕捉词的语义信息。
- LSTM 层:捕捉文本的序列依赖关系,提取上下文特征。
- 全连接层:将 LSTM 输出的特征映射到情感类别(二分类输出维度为 1)。

四、模型训练与评估
定义损失函数、优化器后,即可开始训练模型,并通过测试集评估其情感分类效果。
-
1. 损失函数与优化器

-
2. 训练与评估流程
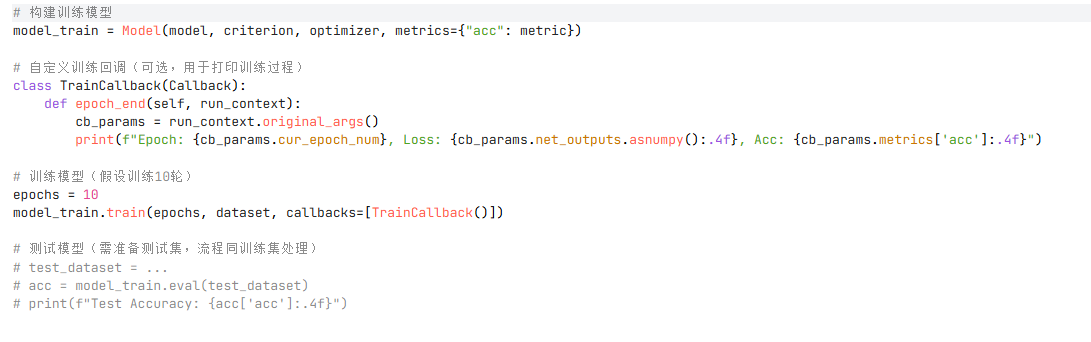
-
五、模型推理:实战情感分类
训练完成后,我们可以用新文本测试模型的情感分类能力。
-

-
六、总结与拓展
通过昇思 MindSpore 实现 RNN 情感分类,我们完成了 “数据处理→模型构建→训练评估→推理” 的全流程。若想进一步提升模型性能,可尝试以下方向:
- 优化词表与嵌入:使用预训练词向量(如 Word2Vec、GloVe)初始化嵌入层。
- 模型改进:替换为 GRU 或更深的 RNN 结构,或结合注意力机制(Attention)增强关键信息捕捉能力。
- 数据增强:通过同义替换、语序调整等方式扩充训练数据,提升模型泛化性。

开源鸿蒙跨平台开发社区汇聚开发者与厂商,共建“一次开发,多端部署”的开源生态,致力于降低跨端开发门槛,推动万物智联创新。
更多推荐
 9
9 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)