Kubernetes Pod 深度解析
目录
2:编写 Pod 配置文件 frontend-localredis-pod.yaml
一:什么是 Pod
Pod 是一个或多个容器的组合。这些容器共享存储、网络和命名空间,以及运行规范。在 Pod 中,所有容器都被统一安排和调度。对于具体应用而言,Pod 是它们的逻辑主机,Pod 包含业务相关的多个应用容器。所以,Pod 是一组具有共享命名空间、IP地址和端口的容器的集合。
1:从使用的角度来看
在实际的使用时,单个容器是无法单独来支撑我们的应用的,往往需要很多微服务才能组成一个系统,并且还会存在A服务依赖B服务,B服务需要和C服务共用某个目录。另外,在使用裸容器时,很难实现对容器内进行健康检査以及横向扩容等操作,而Pod 可以轻松解决这些问题。
2:从 Kubernetes 的角度来看
Docker 只是容器 Runtime(运行时)的一种们还有很多容器 Runtime,比如 Rkt、CRI-0等,而
Kubernetes 作为目前最流行的容器编排工具,需要支持各个 Runtime 并且不依赖于底层 Runtime 的实现技术,于是就抽象出了 Pod 这个概念,用于管理多个紧密相连的符合 CRI 标准的容器。
Pod 可以简单的理解为一组、一个或多个容器,每个 Pod 还包含一个 Pause 容器,Pause 容器是 Pod的父容器,主要负责僵尸进程的回收管理。同时,通过 Pause 容器可以使同一个 Pod 里面的不同容器共享存储、网络、PID、IPC(进程间通信)等,容器之间可以使用 Localhost:Port 的方式相互访问,可以使用 volume 实现数据共享。根据 Docker 的构造,Pod 可以被创建为一组具有共享命名空间、IP 地址和端口的容器。
Pod 有两个必须知道的特点:
网络:每一个 Pod 都会被指派一个唯一的 Ip 地址,在 Pod 中的每一个容器共享网络命名空间,包括Ip 地址和网络端口。在同一个 Pod 中的容器可以同 1ocalhost 进行互相通信。当 Pod 中的容器需要与Pod 外的实体进行通信时,则需要通过端口等共享的网络资源。
存储:Pod 能够被指定共享存储卷的集合,在 Pod 中所有的容器能够访问共享存储卷,允许这些容器共享数据。存储卷也允许在一个 Pod 持久化数据,以防止其中的容器需要被重启。
3:Pod 的状态
(1)kubectl 命令创建 pod

(2)查看 pod

(3)显示 Pod 的更多信息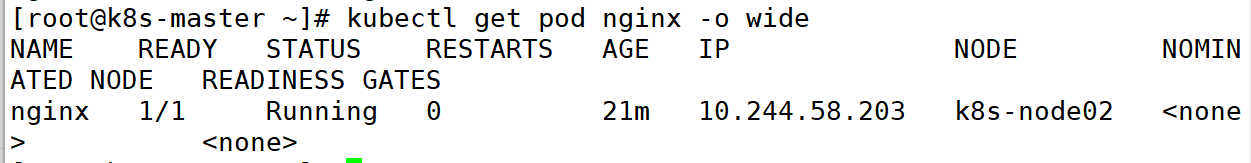
(4)查看 pod 日志

(5)以yaml 格式显示 Pod 详细信息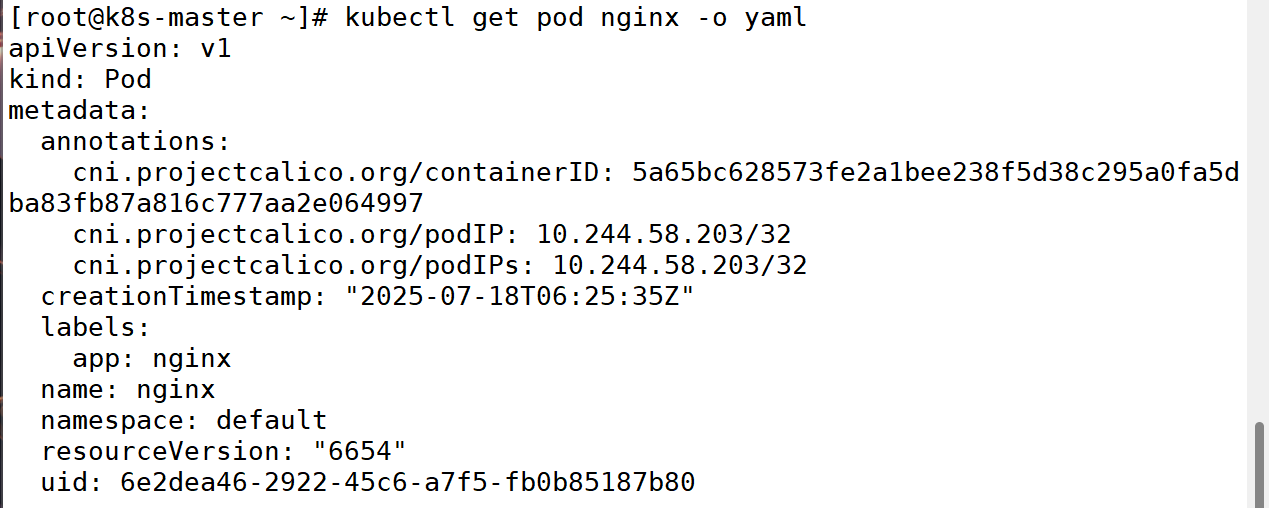
(6)显示资源的详细描述信息
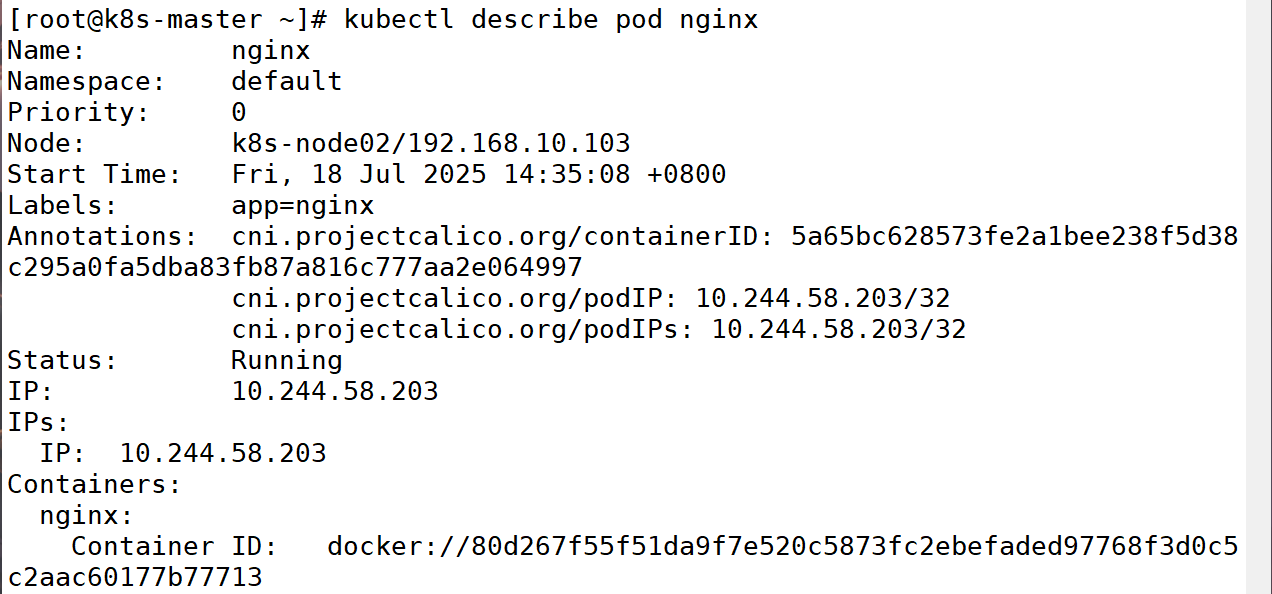
备注:
kubectl get:常用于査看同一资源类型的一个或多个资源对象,可以使用-0参数自定义输出格式kubectl describe:侧重于描述指定资源的各方面的详细信息,不仅会返回节点信息,还会返回在其上运行的 Pod 的摘要、节点事件等信息。
(7)在Pod 的容器中执行命令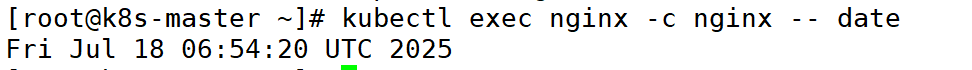
备注:
-c:指定 Pod 中容器的名字
(8)登录到 Pod 中的容器中
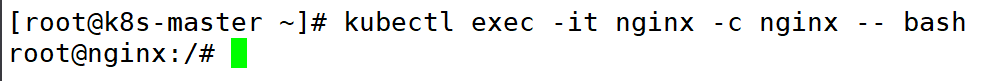
kubectl exec -it nginx -- bash
如果登录的时候不指定容器,就登录到Pod 中的第一个容器中。
(9)在线编辑运行中的资源对象
![]()
(10)将 pod 的端口映射到宿主机

其他主机访问测试:
curl 192.168.10.101:8080
注意:
此命令会在前台运行,此时就可以在其他客户端用该k8s 主机的 IP 地址和 8080 的端口号进行访问了Ctrl+c停止,但停止后就没有这个映射了。
(11)在宿主机和 Pod 的容器之间拷贝文件

(12)Pod 的状态

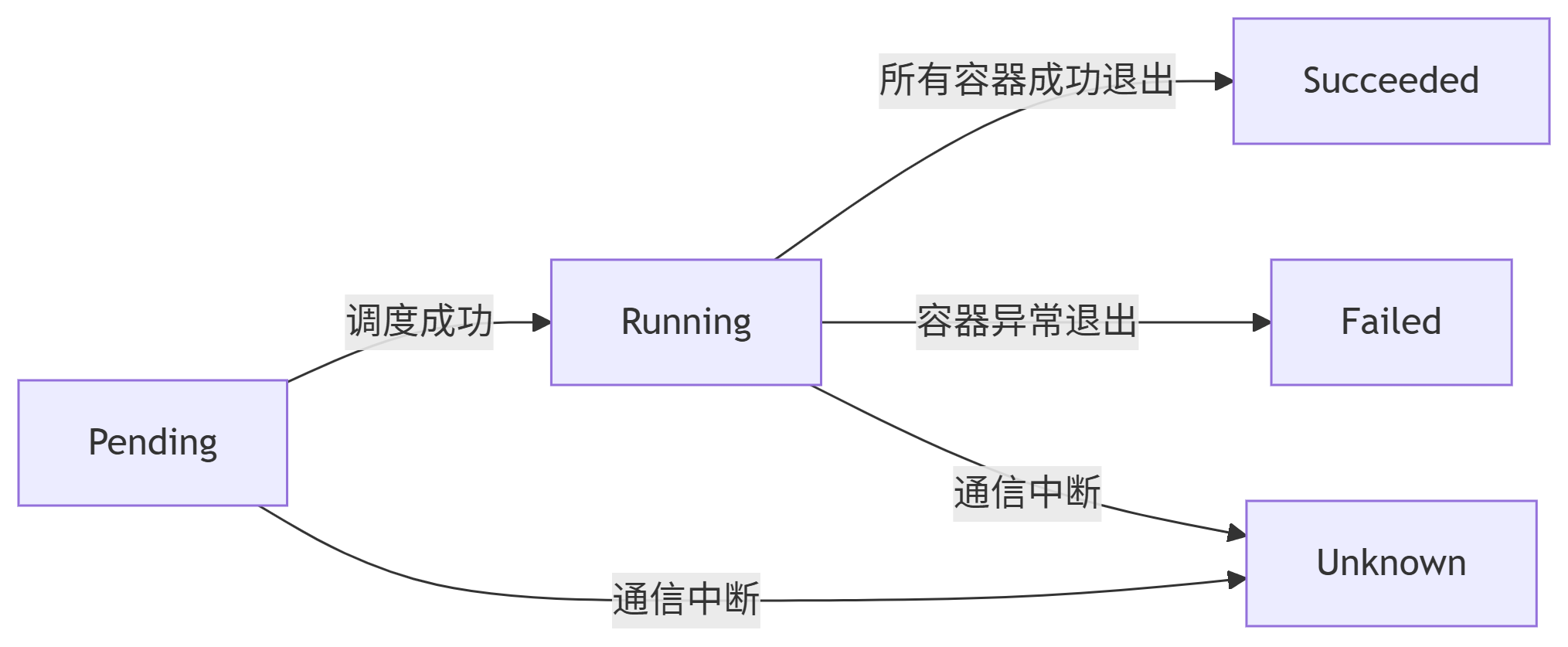
可以看到此时的 Pod 的状态是 Running,Pod 的状态不仅仅只有 Running,常见的其他状态如表1所示:
表1:Pod 状态字段 Phase(阶段)的不同取值
| 状态 | 说明 |
|---|---|
| Pending(挂起) | Pod 已被 Kubernetes 系统接收,但一个或多个容器未被创建。可通过 kubectl describe 查看原因。 |
| Running(运行中) | Pod 已绑定到节点,所有容器已创建,且至少有一个容器在运行、启动或重启。可通过 kubectl logs 查看日志。 |
| Succeeded | 所有容器成功终止且不会重启。可通过 kubectl logs 查看日志。 |
| Failed(失败) | 所有容器已终止,且至少一个容器以失败状态终止(非零退出码或被系统终止)。可通过 logs 和 describe 检查。 |
| Unknown(未知) | 通常因通信问题无法获取 Pod 状态。 |
| ImagePullBackOff | 镜像拉取失败(镜像不存在、网络问题或需登录认证)。通过 describe 查看具体原因。 |
| ErrImagePull | 镜像拉取失败(通常与 ImagePullBackOff 原因类似,但为短暂状态)。 |
| CrashLoopBackOff | 容器启动失败(启动命令错误、健康检查不通过等)。通过 logs 查看具体原因。 |
| OOMKilled | 容器内存溢出(内存限制过小或程序内存泄漏)。通过 logs 检查程序日志。 |
| Terminating | Pod 正在被删除。通过 describe 查看状态。 |
| SysctlForbiden | Pod 自定义了不支持的内核参数。通过 describe 查看具体原因。 |
| Completed | 容器主进程退出(常见于计划任务结束)。通过 logs 查看容器日志。 |
| ContainerCreating | Pod 正在创建(通常为下载镜像或配置问题)。通过 describe 查看具体原因。 |
(13)删除pod

二:Pod 探针
在生产环境中,进程正常启动并不代表应用能正常处理请求,所以合理的设计应用的健康检査尤其重要。在使用裸机或裸容器部署时,一般很难对应用做很完善的健康检査,而 Pod 提供的探针可以很方便的用来检测容器的应用是否正常。
1:Pod 探针的实现方式
目前探针有3种检测方式,可以根据不同的场景选择合适的健康检查方式,分别是ExecAction、TCPSocketAction 和 HTTPGetAction。具体实现方式如表 2所示。
表 2:Pod 探针的实现方式
| 实现方式 | 说明 |
|---|---|
| ExecAction | 在容器内执行指定的命令。如果命令返回值为 0,则认为容器健康。适用于自定义脚本或二进制检查场景。 |
| TCPSocketAction | 尝试与容器指定的端口建立 TCP 连接。如果端口开放,则认为容器健康。适用于检查服务是否监听端口的场景。 |
| HTTPGetAction | 向容器内指定的 URL 发起 HTTP GET 请求。如果响应状态码在 200-400 之间,则认为容器健康。适用于 Web 服务检查。 |
2:容器状态
上述的检查方式可以被周期性的执行,每次检查容器后可能得到的容器状态如表3所示。
表 3:Pod 探针检查容器后可能得到的状态
| 状态 | 说明 |
| Success(成功) | 容器通过检查 |
| Failure(失败) | 容器检查失败 |
| Unknown(未知) | 诊断失败,因此不采取任何措施 |
3:Pod 探针类型
Pod 探针有三类,分别是:livenessProbe(存活探针)、readinessProbe(就绪探针)、startupProbe(启动探针)。
| 探针类型 | 作用 | 检测失败后果 | 支持的检测方法 | 适用场景 |
|---|---|---|---|---|
| livenessProbe(存活探针) | 检测容器是否正常运行。 | 自动重启容器(根据重启策略)。 | - HTTP GET 请求 - Exec 执行命令 - TCP Socket |
处理死锁、长时间阻塞等容器内部故障,确保服务可用性。 |
| readinessProbe(就绪探针) | 检测容器是否准备好接收流量。 | 从 Service 的 Endpoints 中移除该 Pod,停止向其路由流量。 | - HTTP GET 请求 - Exec 执行命令 - TCP Socket |
服务启动依赖(如数据库初始化)、高负载时暂时不可用,或滚动更新时新版本预热。 |
| startupProbe(启动探针) | 检测容器是否完成启动。在成功前,其他探针不生效。 | 若持续失败,会重启容器(类似 livenessProbe)。 |
- HTTP GET 请求 - Exec 执行命令 - TCP Socket |
启动缓慢的应用(如 Java 应用初始化),避免被 livenessProbe 误杀。 |
- 存活探针:确保容器崩溃时自动恢复。
- 就绪探针:确保流量只路由到准备好的实例。
- 启动探针:保护启动慢的应用,避免被过早重启。
三者配合可显著提升应用在 Kubernetes 中的稳定性和可用性。
三:Pod 镜像拉取策略和重启策略
1:镜像拉取策略
在发布应用或者更改控制器配置时,会触发 Pod 的滚动更新,此时针对容器的镜像有不同的拉取方式。如表 4 所示。
表 4:镜像拉取策略
-
存活探针:确保容器崩溃时自动恢复。
-
就绪探针:确保流量只路由到准备好的实例。
-
启动探针:保护启动慢的应用,避免被过早重启。
三者配合可显著提升应用在 Kubernetes 中的稳定性和可用性。
三:Pod 镜像拉取策略和重启策略
1:镜像拉取策略
在发布应用或者更改控制器配置时,会触发 Pod 的滚动更新,此时针对容器的镜像有不同的拉取方式。如表 4 所示。
表 4:镜像拉取策略
| 操作方式 | 说明 | 使用场景 |
|---|---|---|
| Always | 总是从镜像仓库拉取最新镜像(无论本地是否存在)。 | 需要确保始终使用最新镜像的场景(如开发环境或 CI/CD 流水线)。 |
| IfNotPresent | 仅当本地不存在该镜像时才会拉取。注意:如果镜像标签为 latest,则行为与 Always 相同。 |
生产环境推荐策略(避免频繁拉取镜像,提升启动速度)。 |
| Never | 仅使用本地镜像,绝不从仓库拉取。若本地不存在,则容器启动失败。 | 离线环境或强制使用本地预加载镜像的场景。 |
指定拉取策略:
2:Pod 重启策略
在 Kubernetes 中,Pod 的重启策略(Restart Policy)定义了当容器退出或失败时,kubelet 如何处理容器。重启策略是 Pod 级别的配置,适用于Pod 中的所有容器。
在 Always 策略中,只要容器退出(无论退出码是什么),kubelet 都会自动重启容器。适用于需要持续运行的服务(如 web 服务器、数据库等)。在 onFailure 策略中,只有当容器以非零退出码退出时,kubelet 才会重启容器,如果容器正常退出(退出码为 ),则不会重启。适用于任务型Pod(如批处理任务),任务完成后不需要重启。
在 Never 策略中,无论容器以何种方式退出,kubelet 都不会重启容器。适用于一次性任务,任务完成后不需要重启。
各个策略的简要说明如表 5。
表 5:Pod 重启策略
| 操作方式 | 说明 | 适用场景 |
|---|---|---|
| Always | 容器退出后立即自动重启(无论退出码是 0 还是非 0)。 | 长期运行的服务(如 Web 服务器、数据库等)。 |
| OnFailure | 仅在容器非正常退出时重启(退出码非 0)。 | 任务型工作负载(如批处理作业、定时任务),需重试失败任务。 |
| Never | 容器退出后不重启,直接标记为终止状态。 | 一次性任务(如数据迁移、测试任务),无需重复执行。 |
使用场景对比:
| 场景 | 推荐策略 | 原因 |
|---|---|---|
| 持续运行的 Web 服务 | Always |
确保服务中断后自动恢复。 |
| 每日数据备份任务 | OnFailure |
任务失败时重试,成功则无需重启。 |
| 一次性测试容器 | Never |
测试完成后无需保留容器。 |
指定重启策略:

四:创建一个简单的 Pod
1:编写一个简单的 Pod
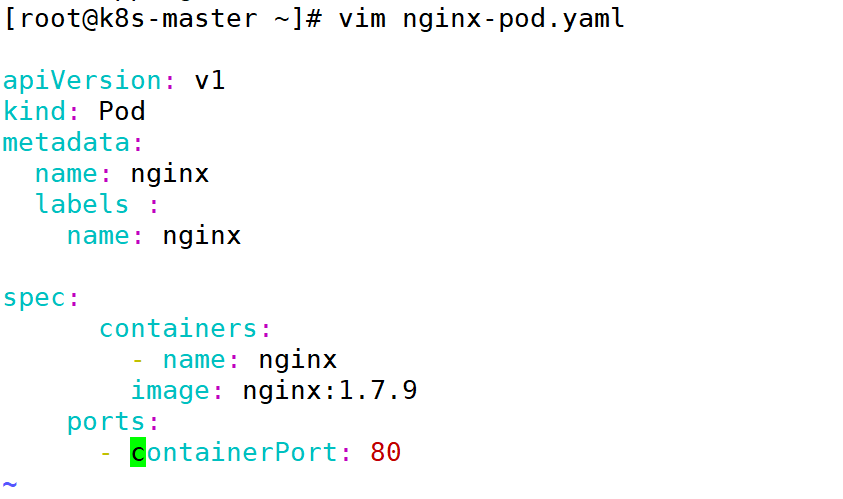
2:编写 Pod 配置文件 frontend-localredis-pod.yaml
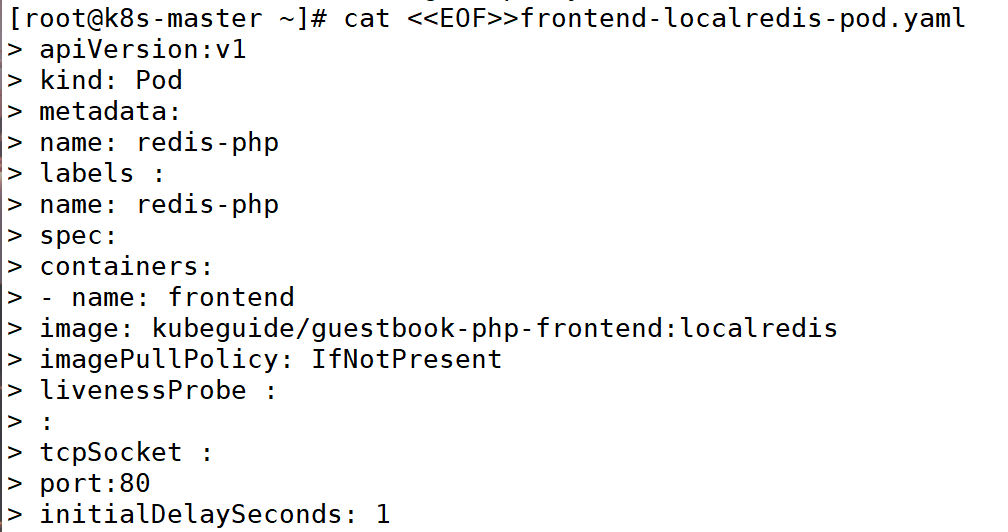
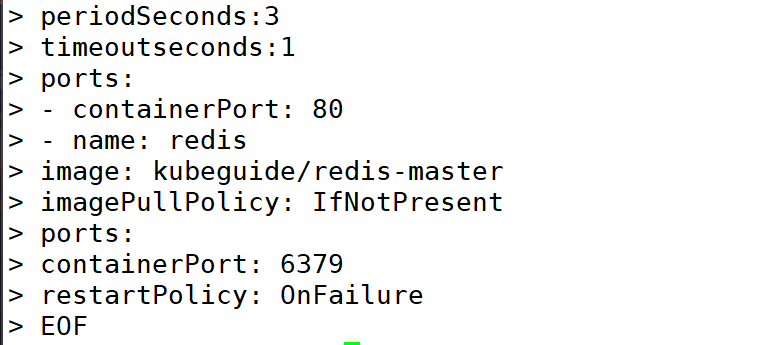
备注:
| 配置项 | 值/类型 | 说明 |
|---|---|---|
| apiVersion | v1 |
必选,Kubernetes API 版本(核心资源使用 v1)。 |
| kind | Pod |
必选,资源类型为 Pod。 |
| metadata.name | redis.php |
必选,Pod 名称(集群内唯一)。 |
| metadata.labels.name | redis.php |
自定义标签,可用于服务选择器或资源分组。 |
| spec.containers | 列表(多个容器) | 必选,定义 Pod 中的容器列表。 |
| containers[0].name | frontend |
第一个容器的名称。 |
| containers[0].image | kubeguide/guestbook.php-frontend |
容器镜像地址。 |
| imagePullPolicy | IfNotPresent |
镜像拉取策略:仅当本地不存在时拉取(latest 标签除外)。 |
| livenessProbe | tcpSocket: port 80 |
存活探针:通过 TCP 检查 80 端口是否开放。 |
| initialDelaySeconds | 1 |
容器启动后等待 1 秒开始探测(避免误判启动慢的服务)。 |
| periodSeconds | 3 |
每 3 秒执行一次存活探测(默认 10 秒)。 |
| timeoutSeconds | 1 |
探测超时时间(默认 3 秒),超时视为失败。 |
| ports | containerPort: 80 |
暴露容器的 80 端口(仅声明作用,实际暴露需配合 Service)。 |
| containers[1].name | redis |
第二个容器的名称。 |
| containers[1].image | kubeguide/redis-master |
Redis 主节点镜像。 |
| containers[1].ports | containerPort: 6379 |
暴露 Redis 默认端口 6379。 |
| restartPolicy | OnFailure |
容器非正常退出时重启(适合任务型负载)。 |
3:Pod 文件语法
| 属性 | 类型 | 必填 | 说明 |
|---|---|---|---|
apiVersion |
<string> |
是 | Kubernetes API 版本(如 v1),必须通过 kubectl api-versions 查询到。 |
kind |
<string> |
是 | 资源类型(如 Pod),必须通过 kubectl api-resources 查询到。 |
metadata |
<Object> |
是 | 元数据,包含资源标识和说明: • name:Pod 名称。• namespace:命名空间。• labels:标签(键值对)。 |
spec |
<Object> |
是 | 核心配置,定义 Pod 的详细规格(如容器、调度、存储等)。 |
status |
<Object> |
否 | 状态信息(由 Kubernetes 自动生成,无需手动配置)。 |
(2)spec(规格)属性
| 属性 | 类型 | 必填 | 说明 |
|---|---|---|---|
containers |
<[]Object> |
是 | 容器列表,定义 Pod 中的容器配置(如名称、镜像、端口等)。 |
nodeName |
<String> |
否 | 强制将 Pod 调度到指定名称的 Node 节点(绕过调度器)。 |
nodeSelector |
<map[]> |
否 | 通过 Node 的标签选择调度目标(如 {"disktype": "ssd"})。 |
hostNetwork |
<boolean> |
否 | 是否使用主机网络模式(默认 false,设为 true 时容器直接使用宿主机网络)。 |
volumes |
<[]Object> |
否 | 存储卷定义,用于挂载到容器(如 ConfigMap、PVC、HostPath 等)。 |
restartPolicy |
<string> |
否 | 容器重启策略: • Always(默认)• OnFailure• Never。 |
imagePullSecrets |
<[]Object> |
否 | 私有镜像仓库的认证信息(如 name: regcred)。 |
affinity |
<Object> |
否 | 高级调度策略(如节点亲和性、Pod 亲和性/反亲和性)。 |
tolerations |
<[]Object> |
否 | 允许 Pod 调度到带有指定污点(Taints)的节点。 |
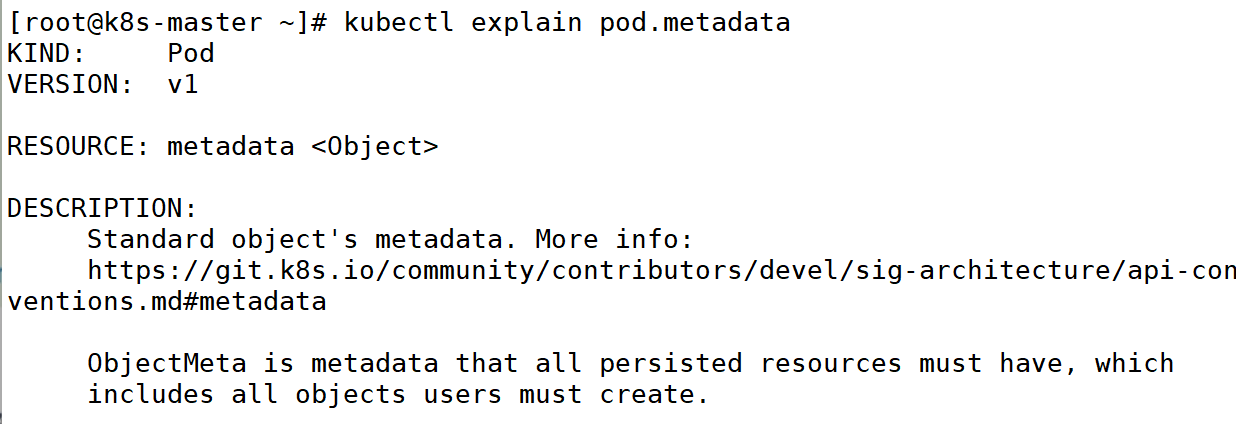
(3)通过 kubectl explain 命令来查看每种资源的可配置项


4:运行 kubectl create 命令创建此 Pod

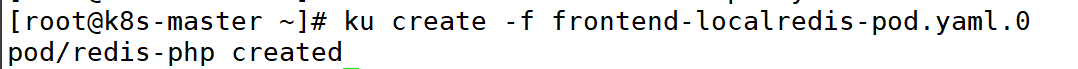
5:查看已经创建的 Pod

6:查看 pod 详细创建信息
7:删除 pod

五:Pod 的基本用法
1:编写 pod 文件,将两个容器放在同一个 pod中
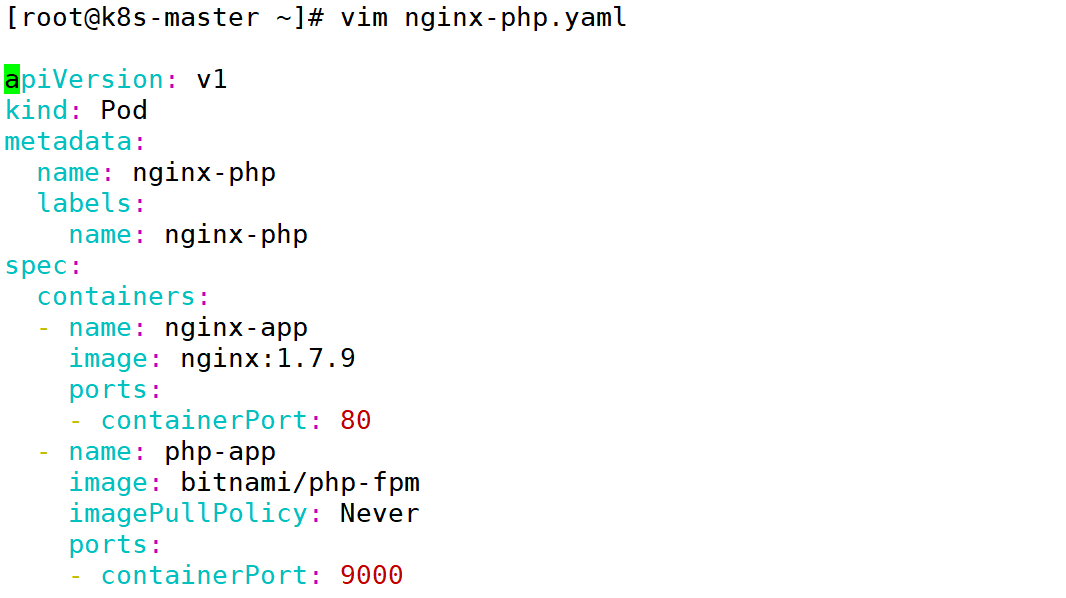
2:部署nginx的 pod 文件

备注:
此时可以看到 pod 中有两个容器处于 running 状态中
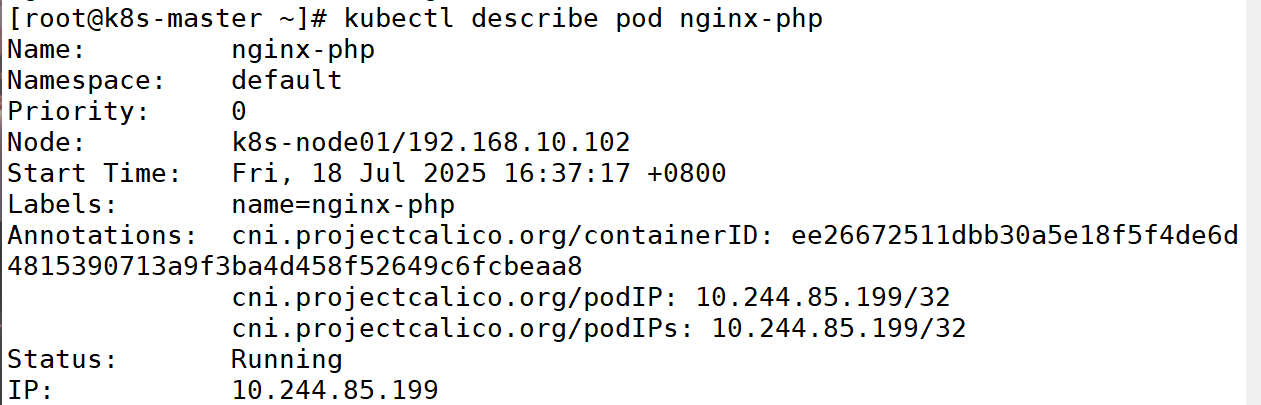
3:查看 pod 的详细信息
4:暴露端口

5:查看端口映射
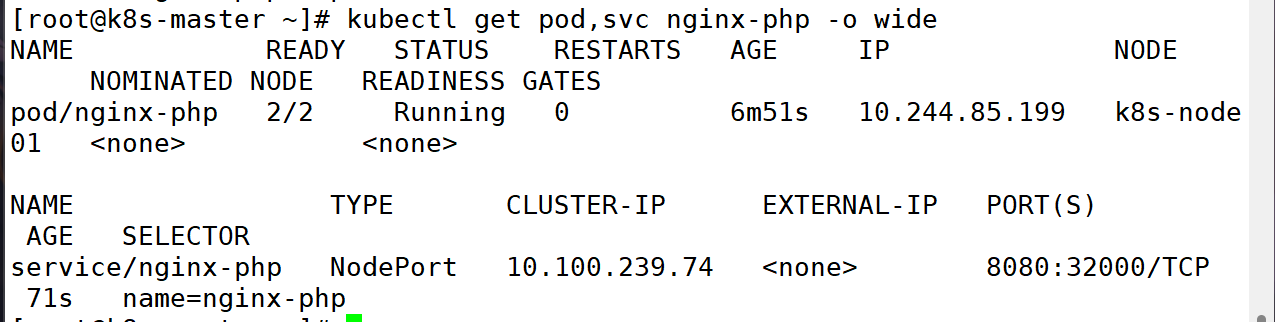
6:测试访问
用外部主机,访问 master 的 ip 地址:映射的端口
http://192.168.10.101:32000/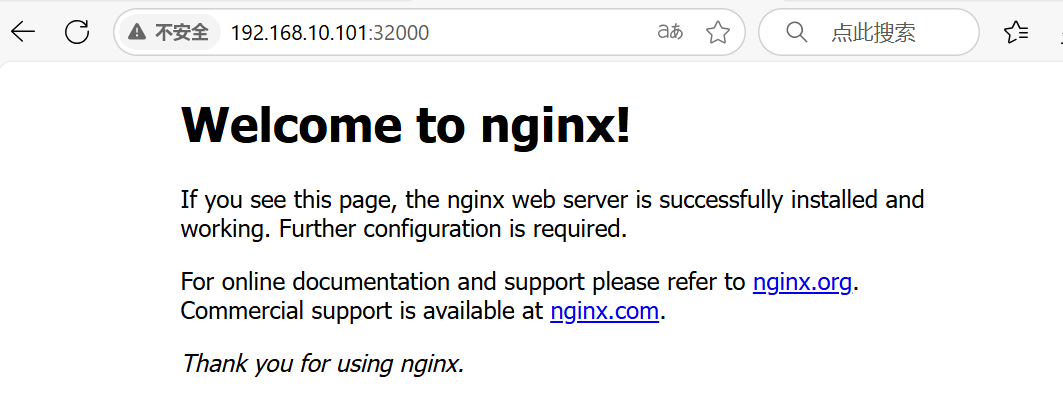
7:删除 pod

六:静态 pod
静态 Pod 是由 kubelet 进行管理的仅存在于各个 Node 上的 Pod。他们不能通过 API Server 进行管理,无法于 Replicationcontroller、Deployment 或者 Daemonset 进行关联,并且 kubelet 无法对他们进行健康检査。静态 Pod 总是由 kubelet 创建的,并且总在 kubelet 所在的 Node 上运行。
1:编写 yamal 文件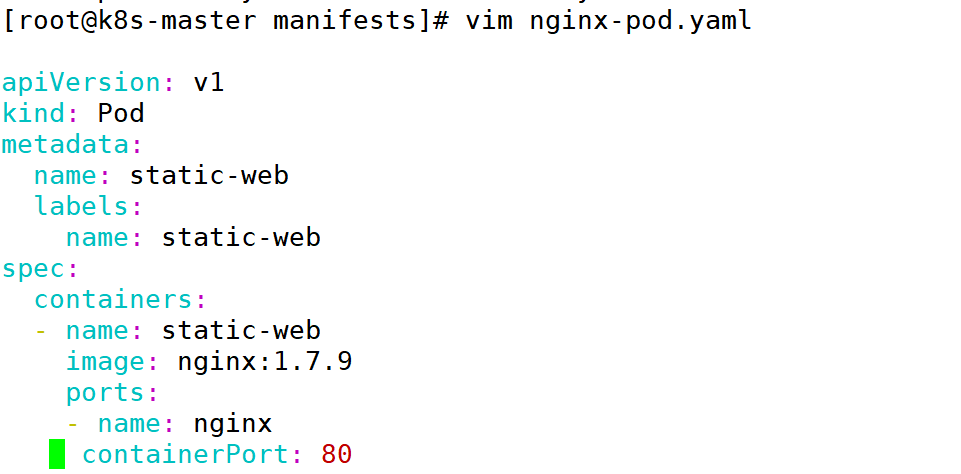
2:不需执行部署命令,过一会,查看 pod
kubectl get pod
NAME READY STATUS RESTARTS AGE
nginx-php 2/2 Running 4(18m ago) 20m
static-web-k8s-master01 1/1 Running 0 20s
kubectl get pod
NAME READY STATUS RESTARTS AGE
nginx-php 2/2 Running 4(18m ago) 20m
static-web-k8s-master01 1/1 Running 0 20s
3:删除静态 pod 的方法
![]()
备注:
不能用如下语句删除
kubectl delete pod static-web-k8s-master01
这样删除,会让 pod 处于 pending 状态,但无法删除
七:Pod 启动过程与运行状态
Pod 创建完之后,一直到持久运行起来,中间有很多步骤,也就有很多出错的可能,因此会有很多不同的状态。
在 Pod 的启动过程中,会涉及到多个关键组件,保证 Pod 能够顺利的启动完成,这些关键组件和作用如下所示:
API Server:接收和处理 Pod 创建请求。
etcd:存储集群状态和 Pod 定义。
Scheduler:将 Pod 调度到合适的节点。
kubelet:在节点上管理 Pod 的生命周期。
容器运行时:负责容器的创建和运行。
通过这些步骤,Kubernetes 确保 Pod 能够按照预期启动并运行。
1:pod 的启动过程包含的步骤
Pod 的启动过程是 Kubernetes 中一个关键的操作,涉及多个步骤和组件协同工作。以下是 Pod 启动的主要过程:
| 阶段 | 执行组件 | 关键操作 | 输出/结果 |
|---|---|---|---|
| 1. 用户提交定义 | 用户/kubectl | 提交 Pod 的 YAML/JSON 文件到 API Server。 | 请求进入 Kubernetes 系统。 |
| 2. API Server 处理 | API Server | 1. 身份验证与授权。 2. 存储定义到 etcd。 |
Pod 定义持久化,等待调度。 |
| 3. 调度 Pod | Scheduler | 1. 监控未调度的 Pod。 2. 根据资源、亲和性等选择节点。 3. 绑定节点并更新 etcd。 |
Pod 与目标节点绑定。 |
| 4. kubelet 创建 | kubelet(目标节点) | 1. 监控到新 Pod。 2. 调用容器运行时(Docker/containerd)。 3. 设置网络和存储。 |
容器开始启动,Pod 状态为 ContainerCreating。 |
| 5. 启动容器 | 容器运行时 | 1. 拉取镜像(如需要)。 2. 启动容器进程。 |
容器运行,kubelet 报告状态。 |
| 6. 状态更新 | kubelet → API Server | 持续监控容器状态,更新至 API Server 和 etcd。 | Pod 状态可能为 Pending、Running 或 Error。 |
| 7. 运行状态判定 | kubelet | 检查所有容器状态: - 全部成功 → Running。- 失败 → 按 restartPolicy 处理。 |
Pod 进入稳定状态(如 Running)或循环重启(CrashLoopBackOff)。 |
| 8. 探针检查(可选) | kubelet | 定期执行 livenessProbe/readinessProbe:- 失败时重启或移除流量。 |
确保服务健康(存活探针)或就绪(就绪探针)。 |
| 9. Pod 可用 | kubelet/Service | 通过就绪探针的 Pod 被加入 Service 的 Endpoints。 | 流量可路由到 Pod(如 ClusterIP 或 Ingress)。 |
| 10. 持续监控 | kubelet | 监控容器状态,处理异常(如 OOMKilled、进程退出)。 | 自动恢复(如重启)或标记为 Failed。 |
关键组件与职责
| 组件 | 核心职责 |
|---|---|
| API Server | 接收请求、验证权限、持久化数据到 etcd,作为集群的“网关”。 |
| Scheduler | 根据资源需求和策略分配节点,确保负载均衡。 |
| kubelet | 节点代理,管理容器生命周期、监控状态、执行探针。 |
| 容器运行时 | 实际运行容器(如 Docker),负责镜像拉取和进程管理。 |
| etcd | 存储集群所有状态数据(如 Pod 定义、节点绑定)。 |
2:pod的运行状态
| 状态 | 触发条件 | 常见原因 | 后续操作建议 |
|---|---|---|---|
| Pending | - Pod 已被 APIServer 创建并存入 etcd。 - 未完成调度或正在下载镜像。 |
- 资源不足导致无法调度。 - 镜像拉取慢或失败(如 ImagePullBackOff)。 |
检查 kubectl describe pod <name>:- 调度问题 → 调整资源请求或节点标签。 - 镜像问题 → 检查镜像名称或仓库权限。 |
| Running | - Pod 已调度到节点。 - 所有容器已被创建,且至少一个在运行或重启中。 |
- 容器启动中(ContainerCreating)。- 部分容器崩溃但未全部终止。 |
检查 kubectl logs <pod> 或 kubectl exec 进入容器调试。 |
| Succeeded | - Pod 中所有容器成功退出(退出码 0)。 - 适用于 Job/CronJob 等任务型负载。 |
- 一次性任务(如批处理作业)正常完成。 | 无需干预,任务已完成。可通过 kubectl logs 查看输出结果。 |
| Failed | - 所有容器已终止,且至少一个容器非正常退出(退出码非 0 或被系统终止)。 | - 容器启动命令错误(如 command not found)。- 资源不足(如 OOMKilled)。 |
检查 kubectl describe pod 和 kubectl logs:- 修正命令或资源配置。 - 调整 restartPolicy。 |
| Unknown | - 无法读取 Pod 状态(通常因通信故障)。 | - 节点失联(如 kubelet 崩溃)。 - 网络分区。 |
检查节点状态 kubectl get nodes:- 重启节点 kubelet。 - 修复网络问题。 |
八:故障排除步骤
当一个 Pod 无法正常启动时,可能是由于多种原因导致的。以下是故障排除的详细步骤,帮助你定位和解决问题。
| 状态 | 可能原因 | 排查命令/方法 | 解决方案 |
|---|---|---|---|
| Pending | - 资源不足(CPU/内存)。 - 节点亲和性/污点不匹配。 - PVC 未绑定。 |
kubectl describe pod <name>kubectl describe node <node>kubectl get pvc |
- 调整资源请求。 - 检查节点标签/污点。 - 确保 PVC 已绑定。 |
| ImagePullBackOff | - 镜像名称错误或不存在。 - 私有镜像未配置 imagePullSecrets。- 仓库不可访问。 |
kubectl describe pod <name>docker pull <image> 手动测试 |
- 修正镜像名称。 - 添加 imagePullSecrets。- 检查网络或仓库权限。 |
| CrashLoopBackOff | - 应用启动错误(如配置错误)。 - 资源不足(OOM)。 - 依赖服务未就绪。 |
kubectl logs <pod> --previouskubectl describe pod <name> |
- 检查应用日志和配置。 - 增加资源限制。 - 确保依赖服务可用。 |
| ErrImagePull | - 镜像拉取失败(权限/网络问题)。 | kubectl describe pod <name>kubectl get events |
- 检查镜像权限和名称。 - 配置正确的 imagePullSecrets。 |
| ContainerCreating | - 镜像下载慢。 - CNI 插件问题。 - 存储卷未就绪。 |
kubectl get eventskubectl get pvckubectl -n kube-system logs <cni-pod> |
- 检查网络插件日志。 - 等待 PVC 绑定。 - 优化镜像大小。 |
| Running(但不可用) | - 就绪探针失败。 - 应用内部错误(如端口未监听)。 |
kubectl logs <pod>kubectl exec -it <pod> -- curl localhost:<port> |
- 调整就绪探针配置。 - 检查应用服务状态。 |
| Unknown | - 节点失联(kubelet 崩溃)。 - 网络分区。 |
kubectl get nodessystemctl status kubelet |
- 重启节点 kubelet。 - 修复节点网络。 |
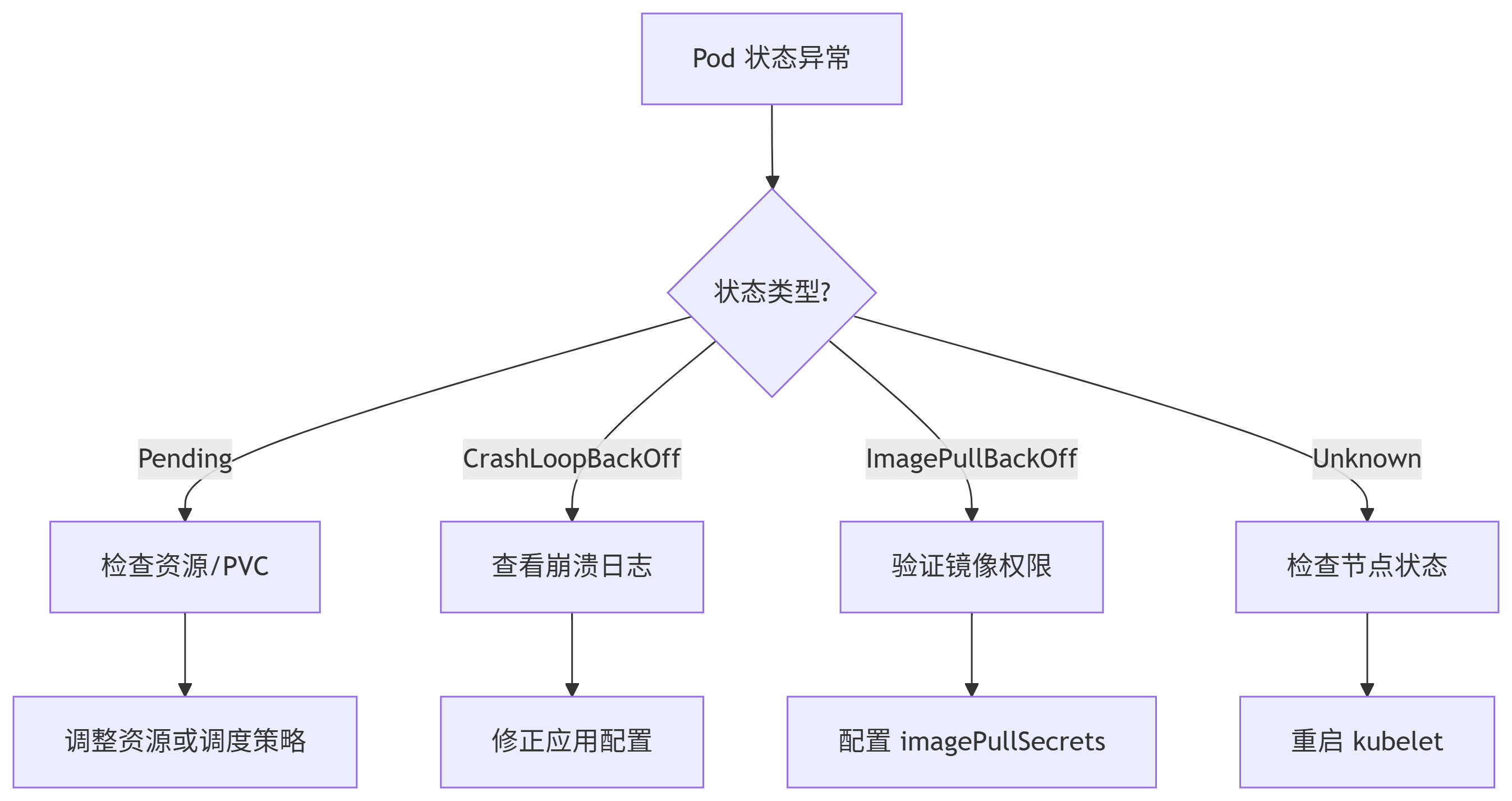
通过以上步骤,可以逐步定位 Pod 无法启动的原因。常见问题包括镜像拉取失败、资源不足、配置错误、网络或存储问题等。根据具体错误信息,结合日志和事件描述,可以快速解决问题。

开源鸿蒙跨平台开发社区汇聚开发者与厂商,共建“一次开发,多端部署”的开源生态,致力于降低跨端开发门槛,推动万物智联创新。
更多推荐

 15
15 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)