新一代ORM框架——Jimmer
Jimmer是JVM最先进ORM,同时支持Java & Kotlin1.Jimmer核心功能:便捷的查询API,健全的Java DSL,优美的Kotlin DSL自动去除无用的表连接自动合并逻辑等价的表连接自动合并逻辑等价的隐式子查询分页查询可自动生成并优化count查询动态查询为多表查询设计DSL支持混入原生SQL表达式以使用非标准的数据库特有能力拓展SQL的能力,轻松支持原生SQL实现成本高昂
新一代ORM框架——Jimmer
相信各位读者平时工作中用的不是JPA(hibernate)就是Mybaties plus,可能从各位读者上学的时候听到的就是这两种orm框架了(jdbc template不算),那么我们除了这两个ORM还有其他选择吗?
以前可能没有,但是现在有了,最先进的ORM框架:Jimmer(鸡门儿) 他来了
1、什么是Jimmer
Jimmer是JVM最先进ORM,同时支持Java & Kotlin
1.Jimmer核心功能:
-
便捷的查询API,健全的Java DSL,优美的Kotlin DSL
-
自动去除无用的表连接
-
自动合并逻辑等价的表连接
-
自动合并逻辑等价的隐式子查询
-
分页查询可自动生成并优化count查询
-
动态查询为多表查询设计
-
DSL支持混入原生SQL表达式以使用非标准的数据库特有能力
-
拓展SQL的能力,轻松支持原生SQL实现成本高昂的高级功能
-
高级的SQL优化能力
-
-
强大的缓存
-
多级缓存,每一级缓存都可以做自由技术选型
-
不仅仅是对象缓存 (关联、计算值、多视图)
-
自动维持缓存一致性
-
-
对GraphQL的快速支持
-
基于文档注释客户端契约 (OpenAPI、TypeScript)
2.Jimmer的核心理念:
任意形状的的数据结构作为一个整体进行读写操作,而非简单的处理实体对象。
-
Jimmer实体对象并非POJO,表达任意形状的数据结构。
-
任意形状的数据结构,都可以作为一个整体进行
-
读:Jimmer创建这种无限灵活的数据结构,传递给你
-
写:你创建这种无限灵活的数据结构,传递给Jimmer
-
3.Jimmer卓越的性能:
Jimmer和其他ORM框架的性能对比:
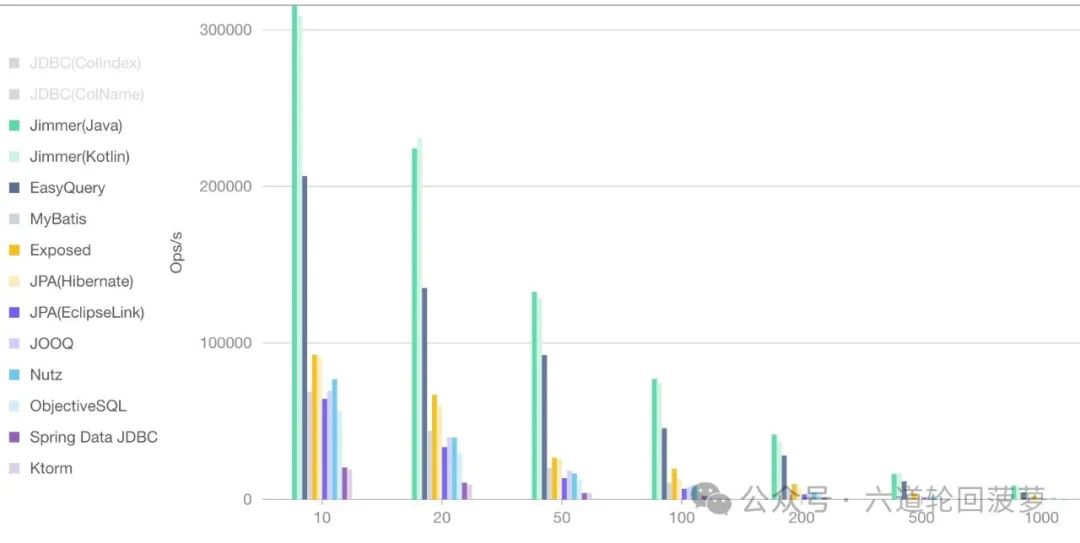
总之jimmer也是一个面向对象的ORM框架,同时他的性能也远远优于现有的ORM框架
请注意jimmer是基于APT即Annotation Processor Tool,也就是和lombok是一样的,都是在编译时期生成代码
2、初试Jimmer
说这么多,我们直接来看看在代码里我们如何使用Jimmer
首先我们在我们的数据库中新建一张表,基于这张表我们来看看Jimmer是如何实现crud的
DDL语句:
create table book(
idbigintunsignednotnull auto_increment primary key,
namevarchar(50) notnull,
editionintegernotnull,
price numeric(10, 2) notnull
) engine=innodb;
然后我们新建一个springboot应用,这里笔者用的是jdk11+springboot2.7.18,请注意jimmer对jdk版本没有太大的要求,jdk8也支持的(但是最低就应该是jdk8了,如果你还在使用jdk8以下,那笔者认为你更应该考虑跳槽)
然后我添加jimmer的依赖:
<dependency>
<groupId>org.babyfish.jimmer</groupId>
<artifactId>jimmer-spring-boot-starter</artifactId>
<version>${jimmer.version}</version>
</dependency>
<dependency>
<groupId>org.babyfish.jimmer</groupId>
<artifactId>jimmer-core</artifactId>
<version>${jimmer.version}</version>
</dependency>
<dependency>
<groupId>org.babyfish.jimmer</groupId>
<artifactId>jimmer-sql</artifactId>
<version>${jimmer.version}</version>
<scope>provided</scope>
</dependency>
jimmer的最新版本可以在如下页面找到:https://github.com/babyfish-ct/jimmer/releases
笔者用的时候最新的版本是:0.9.76
然后由于jimmer是基于APT的,所以我们需要添加maven的构建插件:
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.10.1</version>
<configuration>
<annotationProcessorPaths>
<path>
<groupId>org.babyfish.jimmer</groupId>
<artifactId>jimmer-apt</artifactId>
<version>${jimmer.version}</version>
</path>
<path>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>${lombok.version}</version>
</path>
</annotationProcessorPaths>
</configuration>
</plugin>
请注意,如果你的项目里使用了lombok,请在path里也写上lombok,否则lombok会失效
我们接着配置我们的配置文件,由我们使用了Jimmer的starter所以Jimmer的数据源也是直接使用spring的数据源:
spring:
datasource:
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://xx.xx.xx.xxx:3306/jimmer?serverTimezone=GMT%2B8&characterEncoding=utf8&useSSL=false
username: your username
password: your password
Jimmer还有几个独有的配置,这里简单介绍几个有用的:
|
属性名 |
类型 |
默认值 |
描述 |
|---|---|---|---|
|
jimmer.dialect |
string |
org.babyfish.jimmer.sql.dialect.DefaultDialect |
数据库方言类名 |
|
jimmer.show-sql |
boolean |
false |
如果为true,自动打印被执行的SQL |
|
jimmer.pretty-sql |
boolean |
false |
E确保打印的sql是格式良好的 (默认是紧凑的) |
|
jimmer.database-validation-mode |
NONE|WARNING|ERROR |
NONE |
如果非NONE,验证数据库结构和代码实体类型结构的一致性,如果不一致,WARNING导致日志告警,ERROR导致报错 |
我们可以这样配置在我们的Application.yml中:
jimmer:
dialect: org.babyfish.jimmer.sql.dialect.MySqlDialect
show-sql: true
pretty-sql: true
database-validation-mode: ERROR
下一步就是新建我们表对应的实体,这里就是Book,注意在Jimmer中我们的entity实体不是一个class而是一个接口Interface:
@Entity
@Table(name = "book")
publicinterface Book {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
long id();
@Key
String name();
@Key
Integer edition();
BigDecimal price();
}
请注意这里把属性写成方法是因为Jimmer的实体是不可变对象,因此,接口中指存在getter,不存在setter
这里除开接口,常用的注解和jpa和Mybaties plus差不多
然后我们写完实体之后,我们需要编译一次我们的代码,来让apt生成代码,生成的代码就是这样子:

可以看到根据我们的Book生成了很多衍生类,这些类我们后面都会用到的。
新建实体之后我们就可以开始增删改查了,Jimmer的curd都是基于底层api——JSqlClient来的,我们上面使用了Jimmer的spring starter的话这个client可以自动注入的:
private final JSqlClient sqlClient;
不过不用这个也行,后面会讲到,因为Jimmer完全兼容Spring Data
然后我们新增一个Repository——BookRepository来承载我们的Book类的增删改查操作:
@Repository
@RequiredArgsConstructor
public class BookRepository {
private final JSqlClient sqlClient;
private static final BookTable T = BookTable.$;
}
注意这里BookTable就是我们自动生成的
2.1、查询
我们查询分为分页查询、查询全部、查询单个
分页查询:
public Page<Book> findBooks(int pageIndex, int pageSize, @Nullable Fetcher<Book> fetcher,
// 例如: "name asc, edition desc"
@Nullable String sortCode, @Nullable String name, @Nullable BigDecimal minPrice, @Nullable BigDecimal maxPrice) {
return sqlClient.createQuery(T).where(T.name().ilikeIf(name)).where(T.price().betweenIf(minPrice, maxPrice))
.orderBy(Order.makeOrders(T, sortCode != null ? sortCode : "name asc, edition desc")).select(T.fetch(fetcher))
.fetchPage(pageIndex, pageSize);
}
我们可以加一点可以为空的过滤条件来模拟我们列表的条件查询,这里Fetcher是指你想返回那些字段,我们在外面如此定义一个Fetcher:
BookFetcher fetcher = Fetchers.BOOK_FETCHER.name().edition().price();
表示我们这次查询只需要返回name、edition、price字段,如果为null则说明返回所有字段,是不是很方便!
然后条件查询的可读性也非常强,和JPA和Mybaties plus差不多
分页的话也只需要在末尾新增一个fetchPage方法传入我们的分页参数即可,非常的方便
查询全部:
public List<Book> findAllBooks(@Nullable Fetcher<Book> fetcher,
// 例如: "name asc, edition desc"
@Nullable String sortCode, @Nullable String name, @Nullable BigDecimal minPrice, @Nullable BigDecimal maxPrice) {
return sqlClient.createQuery(T).where(T.name().ilikeIf(name)).where(T.price().betweenIf(minPrice, maxPrice))
.orderBy(Order.makeOrders(T, sortCode != null ? sortCode : "name asc, edition desc")).select(T.fetch(fetcher)).execute();
}
比起分页来只是少了一个fetchPage
查询单个:
public Book findBookById(long id, @Nullable Fetcher<Book> fetcher) {
return sqlClient.createQuery(T).where(T.id().eq(id)).select(T.fetch(fetcher)).fetchFirst();
}
这里我们以根据ID查询为例,也是非常简洁
2.2、插入
插入之前我们需要创建一个对外的插入对象,因为我们的Book是不可变的接口,没有提供set方法,所以我们需要构造一个插入的实体:
@Data
publicclass BookInput implements Input<Book> {
@Nullable
private Long id;
private String name;
private Integer edition;
private BigDecimal price;
@Override
public Book toEntity() {
return BookDraft.$.produce(draft -> {
if (this.getId() != null) {
draft.setId(this.getId());
}
if (this.getName() != null) {
draft.setName(this.getName());
}
if (this.getEdition() != null) {
draft.setEdition(this.getEdition());
}
if (this.getPrice() != null) {
draft.setPrice(this.getPrice());
}
});
}
}
这里需要实现jimmer的input接口,然后实现toEntity方法,让这个输入能够转换为实体,由于我们的实体是一个接口,所以我们这里需要用到我们自动生成的衍生类:BookDraft来为我们生成一个Book对象
然后我们用这个input对象来做插入:
public long saveBook(BookInput input) {
return sqlClient.getEntities().save(input.toEntity()).getModifiedEntity().id();
}
有了单个插入我们还有批量插入:
public void batchInsertBooks(List<BookInput> bookInputs) { sqlClient.getEntities().saveEntities(bookInputs.stream().map(BookInput::toEntity).collect(Collectors.toList()));
}
不过这里批量插入和jpa和mybaties plus一样也是for循环里insert,我们看日志可以看出来:
INFO 19823 --- [nio-8085-exec-1] o.b.jimmer.sql.runtime.ExecutorForLog : Execute SQL===>
Purpose: MUTATE
SQL: insertinto book(NAME, EDITION, PRICE) values(? /* batch_test_Name_7 */, ? /* 5 */, ? /* 2 */)
Affected rowcount: 1
JDBC response status: success
Timecost: 4ms
<===ExecuteSQL
INFO 19823--- [nio-8085-exec-1] o.b.jimmer.sql.runtime.ExecutorForLog : Execute SQL===>
Purpose: MUTATE
SQL: insertinto book(NAME, EDITION, PRICE) values(? /* batch_test_Name_9 */, ? /* 1 */, ? /* 10 */)
Affected rowcount: 1
JDBC response status: success
Timecost: 3ms
<===ExecuteSQL
INFO 19823--- [nio-8085-exec-1] o.b.jimmer.sql.runtime.ExecutorForLog : Execute SQL===>
Purpose: MUTATE
SQL: insertinto book(NAME, EDITION, PRICE) values(? /* batch_test_Name_10 */, ? /* 6 */, ? /* 6 */)
Affected rowcount: 1
JDBC response status: success
Timecost: 2ms
<===ExecuteSQL
2.3、更新
jimmer支持单独的更新操作:
public int update(BookInput input) {
BookTable bookTable = Tables.BOOK_TABLE;
final MutableUpdate update = sqlClient.createUpdate(bookTable);
if (input.getName() != null) {
update.set(bookTable.name(), input.getName());
}
if (input.getEdition() != null) {
update.set(bookTable.edition(), input.getEdition());
}
if (input.getPrice() != null) {
update.set(bookTable.price(), input.getPrice());
}
return update.where(bookTable.id().eq(input.getId())).execute();
}
可以根据入参的不为null来设置更新的值,如果为null则不更新,非常的丝滑,就像写sql一样,通俗易懂简洁明了
2.4、删除
删除也很简单:
public int deleteBook(long id) {
return sqlClient.deleteById(Book.class, id).getTotalAffectedRowCount();
}
当然了你如果想不根据ID删除也可以:
public int deleteBook(BookInput input) {
BookTable bookTable = Tables.BOOK_TABLE;
return sqlClient.createDelete(bookTable).where(bookTable.name().eq(input.getName())).execute();
}
类似于update自己创建一个delete语句
2.5、联表Join操作
jimmer是支持join的,只需要在实体里加上对应的关联的表实体然后根据一对多、多对多,多对一等关系加上ManyToOne、OneToMany等注解就行了,然后如果需要联表的话只需要在fetcher里添加对应的属性就行了,这个其他ORM框架一致,只不过笔者日常使用的比较少这里就不再赘述了
2.6、枚举映射
Jimmer还支持把数据库的字段映射为特征,比如我们有一个字段Gender表示性别,在数据库中用0和1表示,我们可以把他映射为枚举直接放到我们实体中:
Gender gender();
那么枚举就是:
@EnumType(EnumType.Strategy.ORDINAL)
public enum Gender {
MALE,
FEMALE
}
如果不是0和1这种,而是100和200的话也可以:
@EnumType(EnumType.Strategy.ORDINAL)
public enum Gender {
@EnumItem(ordinal = 100)
MALE,
@EnumItem(ordinal = 200)
FEMALE
}
2.7、支持Spring Data
Jimmer整合了spring data,为Java提供了一个Repository基接口:JRepository
意味着我们只需要继承这个接口之后,就和springdata Jpa一样的使用我们的jimmer了!
public interface BookJRepository extends JRepository<Book, Long> {
Book findBookByEdition(Integer edition);
}
也许意味着如果你现在正在使用JPA,那么可以用最小代价来转换为jimmer
2.8、构建GraphQL服务
Jimmer支持Spring GraphQL,可以直接构建一个Spring GraphQL服务,只需要添加如下依赖性:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-graphql</artifactId>
<version>${spring.boot.version}</version>
</dependency>
然后依照spring graphQL的要求来就行了,具体的spring graphQL可以参考:https://spring.io/projects/spring-graphql
3、总结
上文中笔者简单介绍了一下jimmer的几种常规用法以及特性,感兴趣的读者可以自行去jimmer官网上深入探索更高级的用法:https://babyfish-ct.github.io/jimmer-doc/zh/docs/quick-view/
笔者用下来的感受就是一个升级版的JPA,是面向对象的但是功能和写法更高级,特别是写法更能适应现代语言了。

开源鸿蒙跨平台开发社区汇聚开发者与厂商,共建“一次开发,多端部署”的开源生态,致力于降低跨端开发门槛,推动万物智联创新。
更多推荐

 20
20 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)