训练数据集加速方案
·
需要加速什么
- netdisk 存储受网络印象,频繁的交互会拉低速率
- nvme 等本地存储设备顺序读取可稳定 3.5GB/s+, 但随机读取 仅有 40M/s+
- nvme 上大量小文件读取,速率将降至更低 16M/s。
因此参考上面的问题,需要通过以下方式加速
- 冷热数据转化,数据存储在netdisk上,当使用时拉取到nvme上转化为热数据。
- 随机读取优化,通过算法将顺序读转化为伪随机读,支持随机读取。
- 在使用时小文件也保持打包状态,不进行完全展开。
- 额外可补充缓存机制,使用内存进一步提高速度
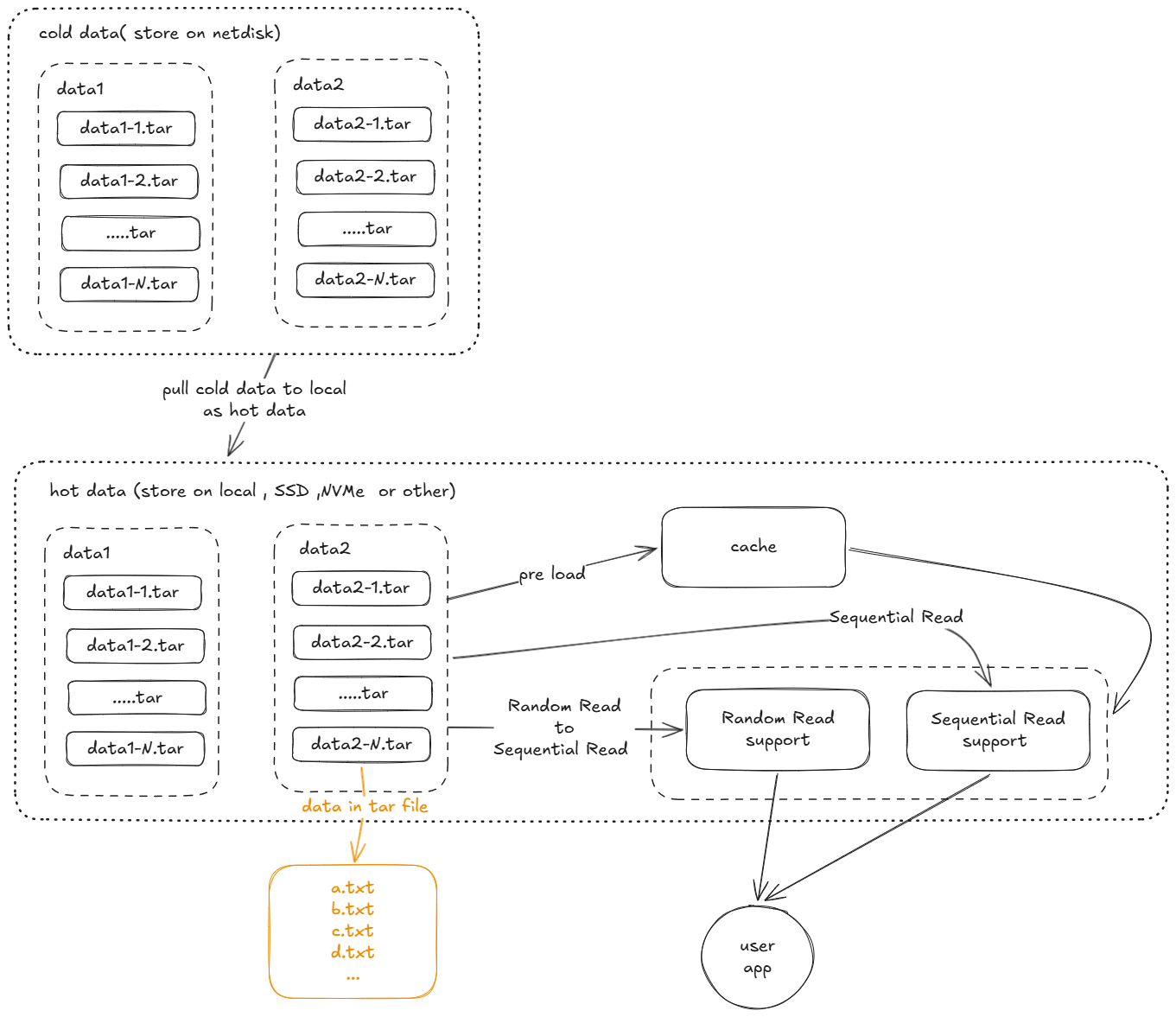
具体设计
如下所示
- cold data 数据存放在网盘中,当需要使用时将拉取到nvme本地存储上
- 大量的数据集文件被分割打包为一个个tar包
- 当顺序读取时将先读取tar包,再从tar包中读取小文件内容(注:读取小文件并不直接解压tar)
- 随机读取时将通过算法,使用顺序读取支持随机获取数据
- 可使用额外缓存预加载数据,进一步加速。
注:其中热数据使用部分可参考webdatas
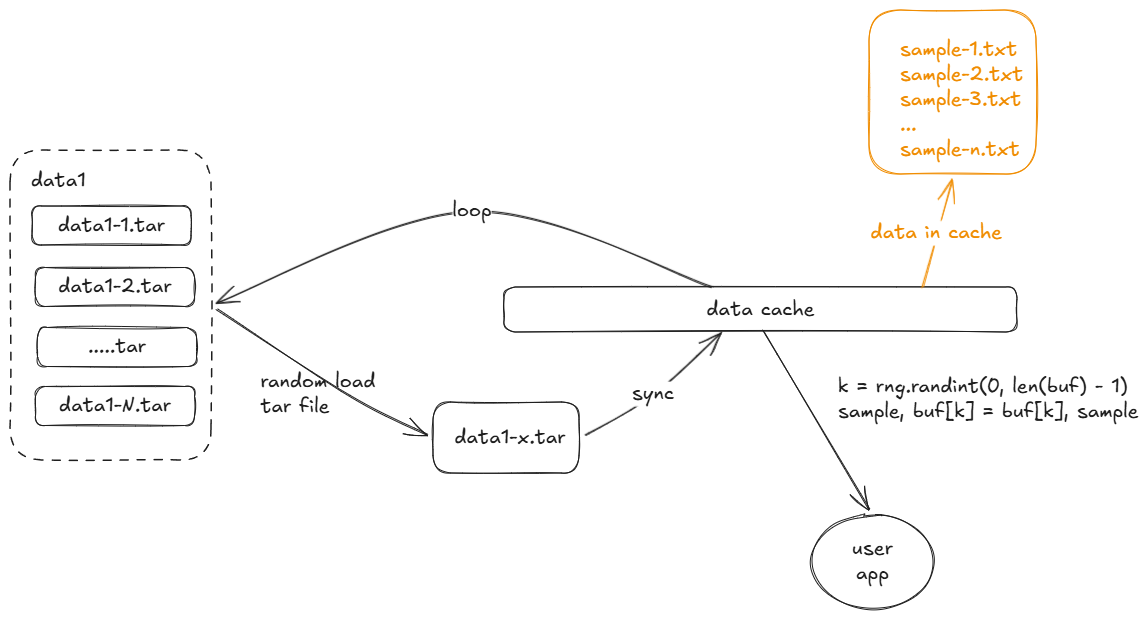
如何用顺序读支持随机读
如下所示
- 读取时将从数据集的tar包中随机选取一个进行顺序读取。
- 将会从tar包中直接顺序读取数据,不解压展开数据包。
- 随着用户的读取不断循环上面步骤
- 用户应用随机读取数据时将从缓存从随机获取一个数据,并从当前处理的tar包中读取一个数据填充已读取数据的位置。

开源鸿蒙跨平台开发社区汇聚开发者与厂商,共建“一次开发,多端部署”的开源生态,致力于降低跨端开发门槛,推动万物智联创新。
更多推荐
 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)