实验一:统计字符个数
HDFS NameNode内部通常端口HDFS NameNode对用户的查询端口9870Yarn查看任务进行情况的端口8088历史服务器查询端口19888。
集群测试
1.
cd ~
vim data.txt
2.编辑data.txt
3.在HDFS创建datainput文件夹
hdfs dfs -mkdir /datainput
4.将data.txt上传到HDFS
hdfs dfs -put data.txt /datainput
^^
hdfs dfs:这是 HDFS 命令行工具的前缀,用于与 HDFS 进行交互。借助它可以在命令行里对 HDFS 执行各种操作,像文件的创建、删除、上传、下载等。-put:这是hdfs dfs命令的一个子命令,作用是把本地文件系统里的文件上传到 HDFS 中。data.txt:指的是本地文件系统中的文件路径,这里表明要上传的文件名为data.txt。你可以根据实际情况将其替换成其他文件的路径。/datainput:代表 HDFS 上的目标路径,意味着要把本地的data.txt文件上传到 HDFS 的/datainput目录下。要是/datainput目录不存在,命令会执行失败;若省略/datainput后面的文件名,上传后的文件名会和本地文件名保持一致。
^^
hdfs dfs 命令的子命令
文件和目录操作
- 创建目录
hdfs dfs -mkdir <路径>:用于在 HDFS 中创建新的目录。例如,hdfs dfs -mkdir /new_dir会在 HDFS 根目录下创建一个名为new_dir的目录。
- 查看文件和目录
hdfs dfs -ls <路径>:列出指定路径下的文件和目录。例如,hdfs dfs -ls /会列出 HDFS 根目录下的所有文件和目录。hdfs dfs -cat <文件路径>:显示指定文件的内容。例如,hdfs dfs -cat /user/hadoop/test.txt会显示/user/hadoop目录下test.txt文件的内容。
- 复制和移动文件
hdfs dfs -cp <源路径> <目标路径>:将文件或目录从源路径复制到目标路径。例如,hdfs dfs -cp /source/file.txt /destination/会将/source目录下的file.txt文件复制到/destination目录下。hdfs dfs -mv <源路径> <目标路径>:将文件或目录从源路径移动到目标路径。例如,hdfs dfs -mv /source/file.txt /destination/会将/source目录下的file.txt文件移动到/destination目录下。
- 删除文件和目录
hdfs dfs -rm <文件路径>:删除指定的文件。例如,hdfs dfs -rm /user/hadoop/test.txt会删除/user/hadoop目录下的test.txt文件。hdfs dfs -rm -r <目录路径>:递归删除指定的目录及其所有子目录和文件。例如,hdfs dfs -rm -r /user/hadoop/dir会删除/user/hadoop目录下的dir目录及其所有内容。
文件上传和下载
- 上传文件
hdfs dfs -put <本地路径> <HDFS路径>:将本地文件系统中的文件上传到 HDFS。例如,hdfs dfs -put /local/file.txt /hdfs/dir/会将本地/local目录下的file.txt文件上传到 HDFS 的/hdfs/dir目录下。
- 下载文件
hdfs dfs -get <HDFS路径> <本地路径>:将 HDFS 中的文件下载到本地文件系统。例如,hdfs dfs -get /hdfs/file.txt /local/会将 HDFS 中的/hdfs/file.txt文件下载到本地的/local目录下。
查看文件系统信息
hdfs dfs -df <路径>:显示指定路径所在文件系统的使用情况,包括总容量、已使用容量和可用容量等信息。例如,hdfs dfs -df /会显示 HDFS 根目录所在文件系统的使用情况。hdfs dfs -du <路径>:显示指定路径下所有文件和目录的磁盘使用情况。例如,hdfs dfs -du /user/hadoop会显示/user/hadoop目录下所有文件和子目录的磁盘使用情况。
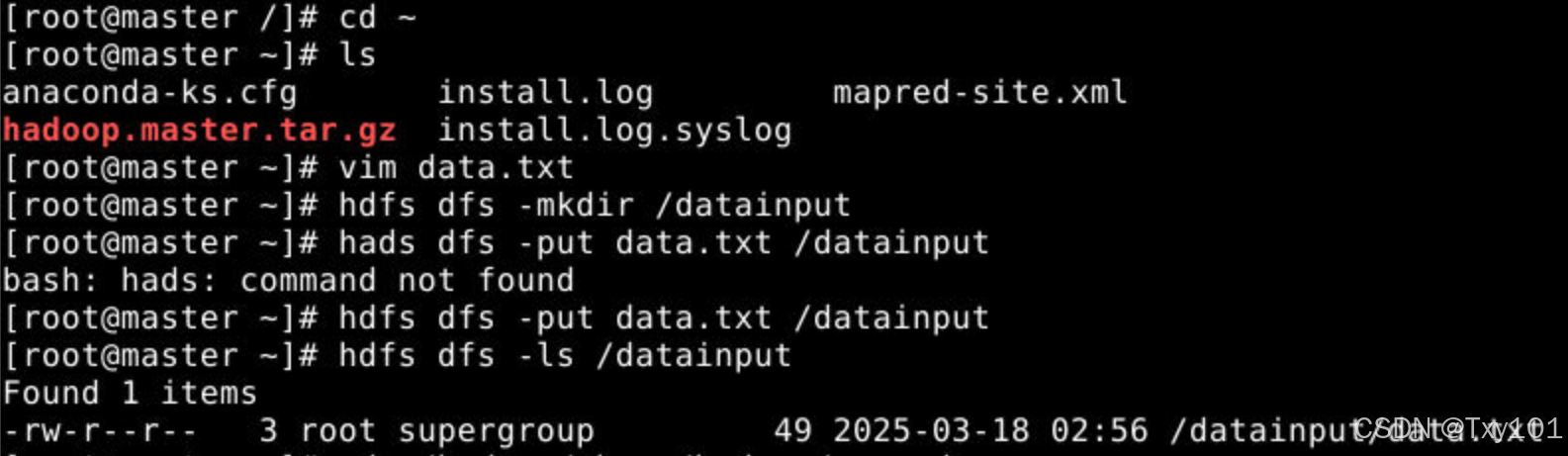
5..查看是否上传成功
hdfs dfs -ls /datainput
执行结果如下:
6.运行MapReduce WordCount例子
cd /usr/local/hadoop/share/hadoop/mapreduce/
hadoop jar hadoop-mapreduce-examples-3.4.0.jar wordcount /datainput/data.txt /dataoutput
hadoop jar:这是一个 Hadoop 命令,用于执行一个 Java 归档文件(JAR 文件)中的 MapReduce 作业。jar子命令表明你要运行一个打包成 JAR 文件的 Java 程序。hadoop-mapreduce-examples-3.4.0.jar:这是 Hadoop 自带的示例 JAR 文件,版本号为 3.4.0。该文件包含了多个 MapReduce 示例程序,像 WordCount、Sort 等。wordcount:指定要运行的具体示例程序名称。wordcount程序的功能是统计输入文本中每个单词的出现次数。/datainput/data.txt:这是输入文件的路径,也就是要进行单词统计的文件。此路径为 HDFS(Hadoop 分布式文件系统)中的路径,意味着data.txt文件必须存在于 HDFS 的/datainput目录下。/dataoutput:这是输出结果的路径,同样是 HDFS 路径。wordcount程序会把统计结果存储在该目录下。需要注意的是,在运行程序之前,这个输出目录不能存在,否则程序会报错。
7.查看结果
# 列出 /dataoutput 目录下的文件和子目录
hdfs dfs -ls /dataoutput
# 查看 /dataoutput/part-r-00000 文件的内容
hdfs dfs -cat /dataoutput/part-r-00000
^^
1. hdfs dfs -cat /dataoutput/part-r-00000
此命令的作用是在 HDFS 里查看指定文件的内容
hdfs dfs:这是用于与 HDFS 交互的命令行工具。-cat:这是hdfs dfs的一个操作选项,其功能是将文件内容输出到标准输出。/dataoutput/part-r-00000:这是 HDFS 中的文件路径。在 Hadoop 的 MapReduce 作业里,通常会把最终的输出结果拆分成多个文件,文件名的格式一般为part-r-xxxx,其中r代表reduce阶段的输出,xxxx是一个数字序号,从00000开始。所以,/dataoutput/part-r-00000指的是/dataoutput目录下序号为00000的reduce输出文件
2. hdfs dfs -ls /dataoutput
该命令的用途是列出 HDFS 中指定目录下的文件和子目录
hdfs dfs:同样是用于与 HDFS 交互的命令行工具。-ls:这是hdfs dfs的一个操作选项,其功能是列出指定目录下的文件和子目录。/dataoutput:这是 HDFS 中的目录路径。
执行结果如下:

可以在端口查看(这只是一个方便查看的页面,这里存储的可以理解为指针。)
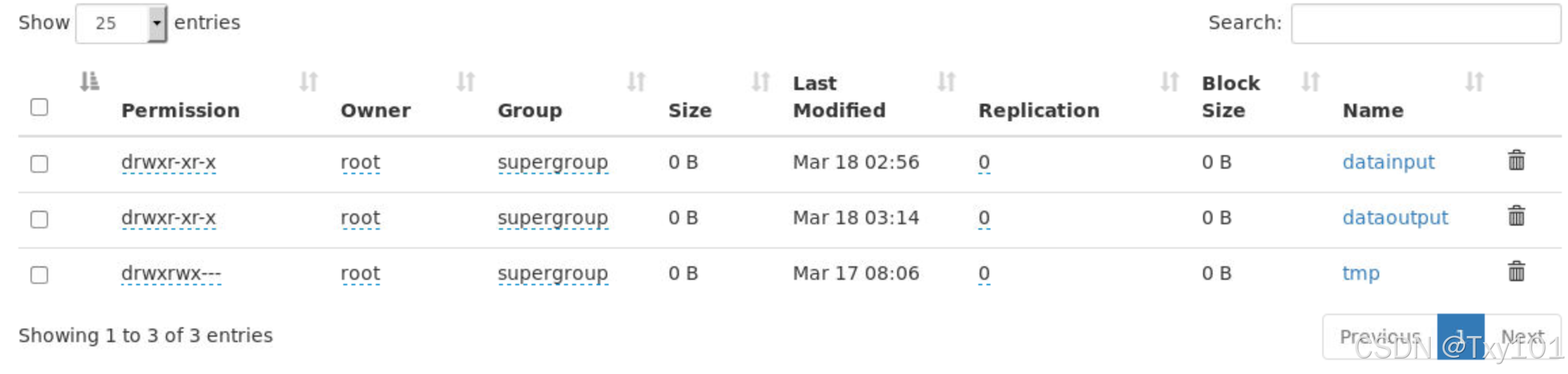

_SUCCESS:成功的标志,输出成功
Couldn't preview the file. :网不好

注意:这个网站是方便展示的,但并没有实际存储。文件按实际存储在data node里面,查看具体data node的位置在配置文件中的hadoop.tmp.dir配置的地址中。例如:我name node存放在master的/usr/local/hadoop/tmp/dfs文件中 ,data node存放在slave的/usr/local/hadoop/tmp/dfs文件中
实际的文件namenode地址看下列操作
- 查看
core-site.xml文件

文件内容如下:
[root@master hadoop]# cat core-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
</property>
</configuration>
^^
1)hdfs://master:9000
9000报错:整个core-site.xml(hdfs)上传都错误;找hdfs-site.xml文件,看是否有问题
9000是内部通信的接口
9870是外部(客户端)访问hdfs的端口
2)hadoop.tmp.dir
临时工作目录,一般需要改
3)file:/usr/local/hadoop/tmp
文件所在地址
- 查看 hdfs-site.xml 文件
# datanode在这里的hdfs-site.xml 文件

文件内容如下:
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master:50090</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/data</value>
</property>
</configuration>
^^
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/name</value>
是namenode 主要文件的存储地址
file是相应的协议,代表本地文件
对 Hadoop 临时目录下与 HDFS 相关的文件和目录进行查看和访问
1)在master节点上
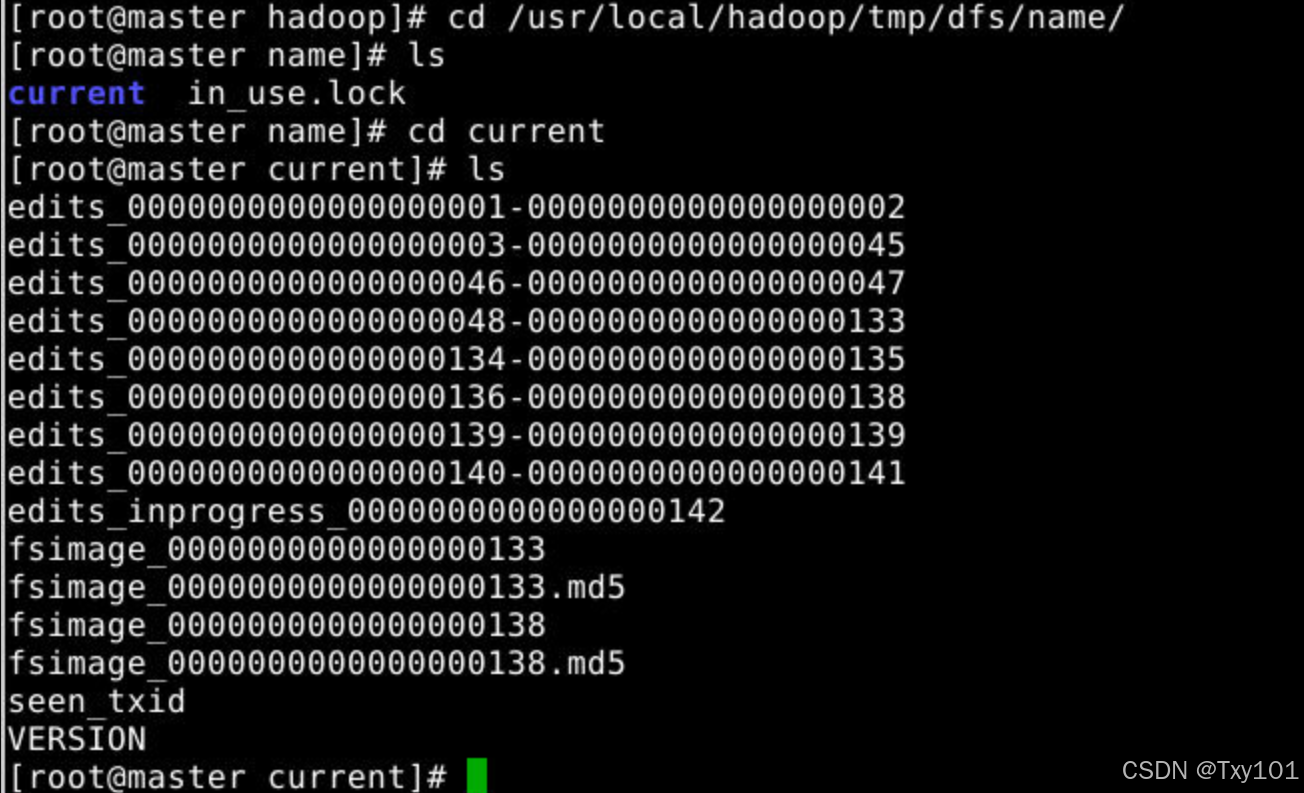
# cd /usr/local/hadoop/tmp/dfs/name/:进入 Hadoop 临时目录下dfs目录中的name目录,name目录用于存储 HDFS 的名称节点(NameNode)相关的数据和元数据
# 列出name目录下的文件和子目录,显示有current目录和in_use.lock文件,in_use.lock文件用于确保同一时间只有一个 NameNode 进程可以访问这些数据,防止数据冲突
# 进入current子目录,该目录存储着 NameNode 的当前状态数据,包括编辑日志(edits)和命名空间镜像(fsimage)等重要文件
# 列出current目录下的文件,其中edits文件记录了对 HDFS 文件系统的所有写操作,fsimage文件是 HDFS 文件系统在某个时间点的完整快照,seen_txid记录了已经处理过的事务 ID,VERSION文件包含了 HDFS 的版本信息
返回上一级目录,回到dfs目录

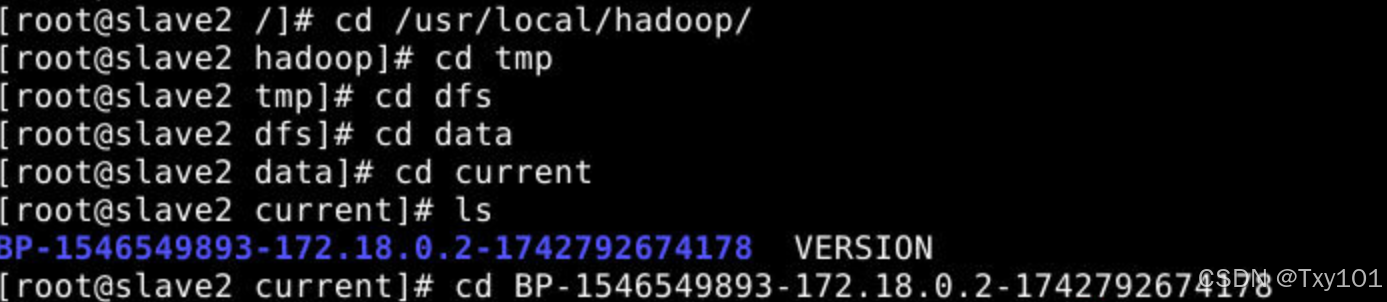
2)在slave节点上
-
进入 HDFS 数据存储根目录

-
进入
data目录 -
进入
current目录
-
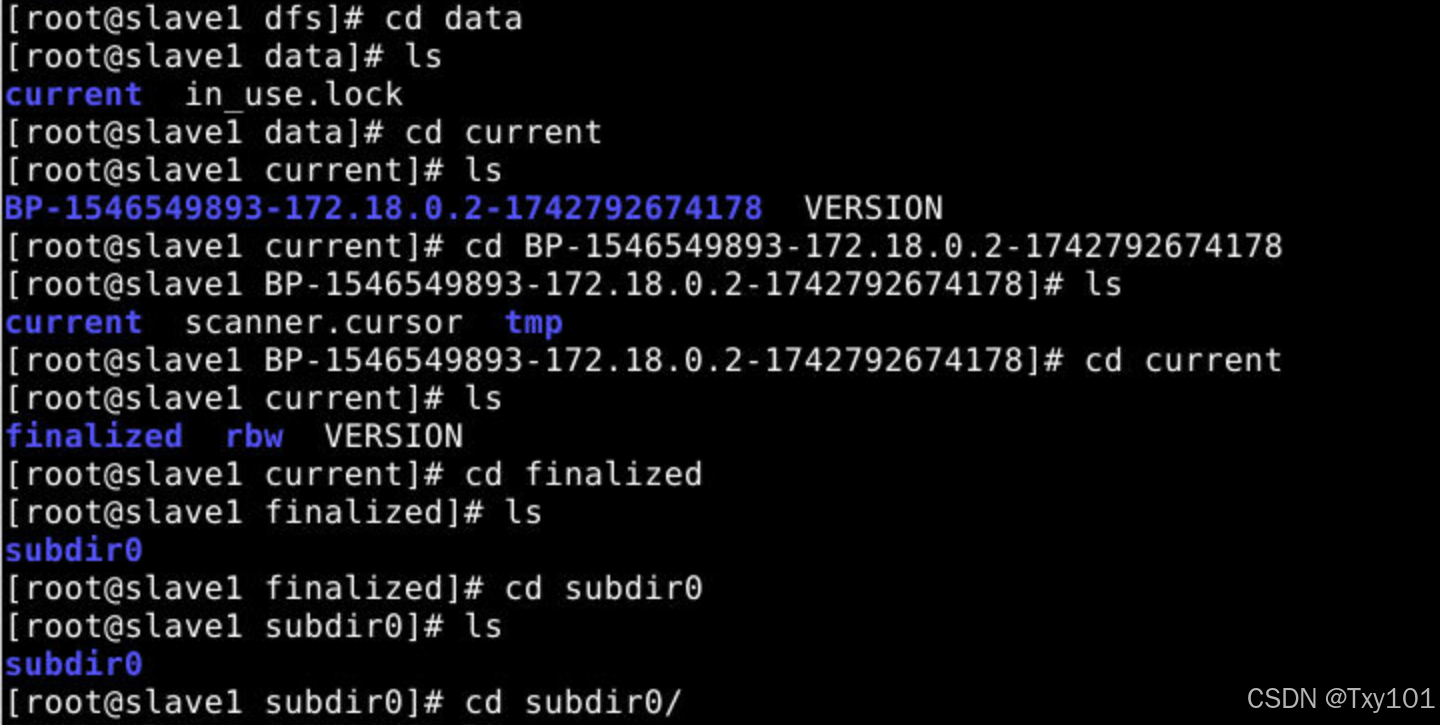
VERSION文件包含了 HDFS 的版本信息以及其他与 DataNode 相关的配置信息。 BP-1546549893-172.18.0.2-1742792674178是一个块池(Block Pool)目录,块池是 HDFS 中管理数据块的一种机制,用于隔离不同命名空间下的数据块。
-
进入块池目录
-
再次进入
current目录
finalized目录存储已经完成写入并经过验证的数据块。rbw(Replica Being Written)目录存储正在写入的数据块,即尚未完成写入操作的数据块。VERSION文件同样包含了该块池的版本信息。
-
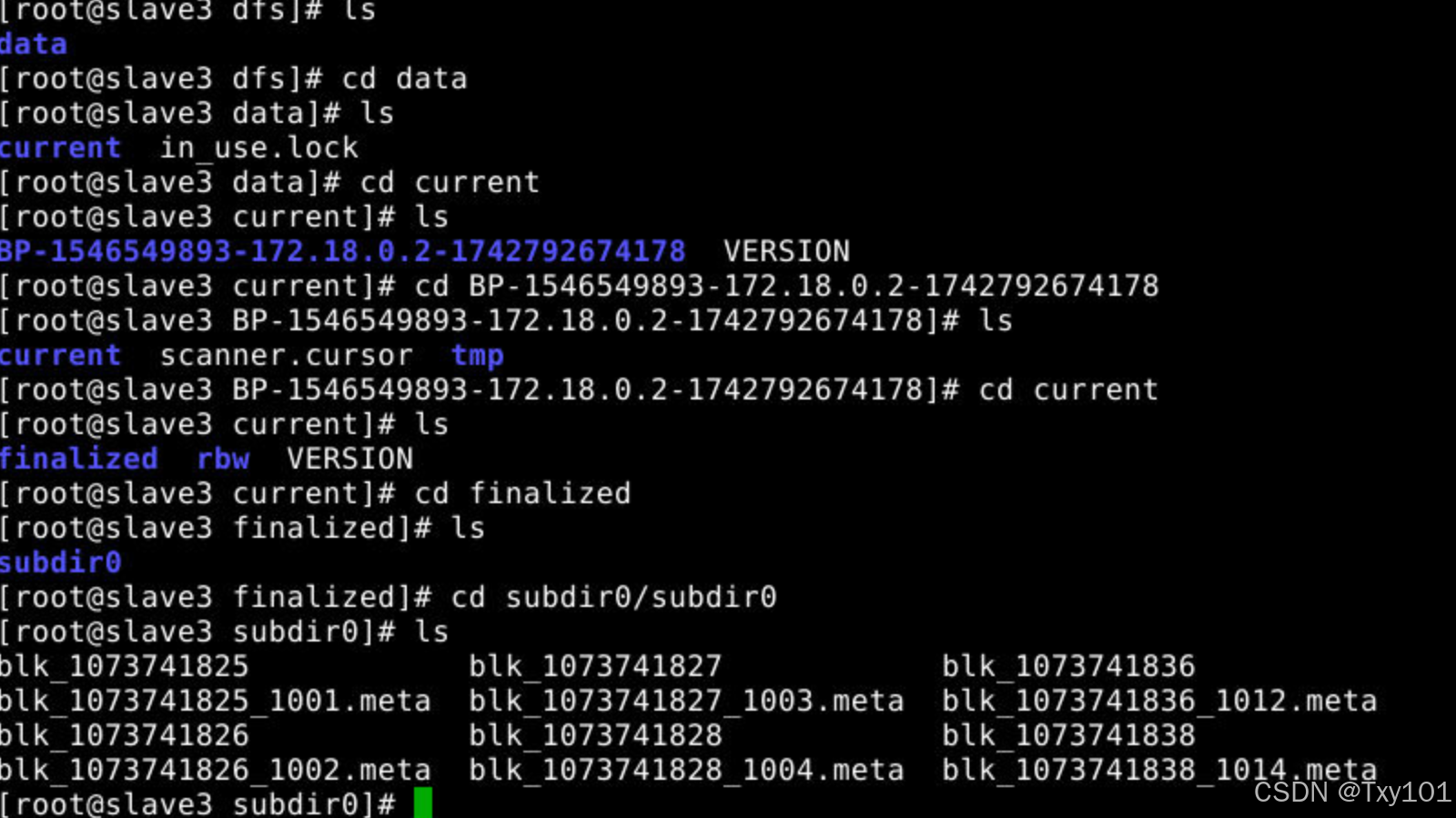
进入
finalized目录 -
逐级进入子目录
- 逐级进入子目录,最终看到了实际的数据块文件和元数据文件。
- 以
blk_开头的文件是实际的数据块文件,存储着 HDFS 中文件的具体数据。 - 以
blk_xxx.meta结尾的文件是对应数据块的元数据文件,包含了数据块的校验和、数据块长度等信息,用于数据的完整性检查和恢复。

^^
在 Hadoop 集群中,/usr/local/hadoop/tmp/dfs 目录下 ,在 Master 节点和 Slave 节点上存在差异(Master节点没有data目录;Slave节点没有Name目录)
主要有以下原因:
- Hadoop 分布式文件系统(HDFS)采用主从架构,Master 节点主要运行 NameNode 进程,负责管理文件系统的命名空间、元数据信息,以及协调客户端对文件的访问等。它并不负责实际数据的存储,因此在 Master 节点的
hadoop.tmp.dir指定目录(/usr/local/hadoop/tmp/dfs)下通常没有data目录来存储数据块。Master节点没有DataNode 进程 - Slave 节点上运行 DataNode 进程,其主要职责是存储和管理 HDFS 中的数据块。当 HDFS 进行数据写入时,NameNode 会根据一定的策略将数据块分配到各个 DataNode 节点上进行存储,所以在 Slave 节点的
hadoop.tmp.dir目录下会有data目录,用于存放实际的数据块文件。 - workers文件里有localhost ,master ,slave1 ,slave2 ,slave3 4个节点(在进行集群配置时,可以保留localhost,让master节点同时充当名称节点和数据节点,也可以删除localhost这行,让master节点仅作为名称节点使用。)

^^
/usr/local/hadoop/tmp/dfs/data/current/BP-1546549893-172.18.0.2-1742792674178/current/finalized/subdir0/subdir0
Browse Directory的数据全存储在该路径下注意:这里有三台服务器都有这个文件,因为我们的配置文件里面复印的分数是3份。如果我的集群存储datanode的机器有4台,那么只有三台服务器有。
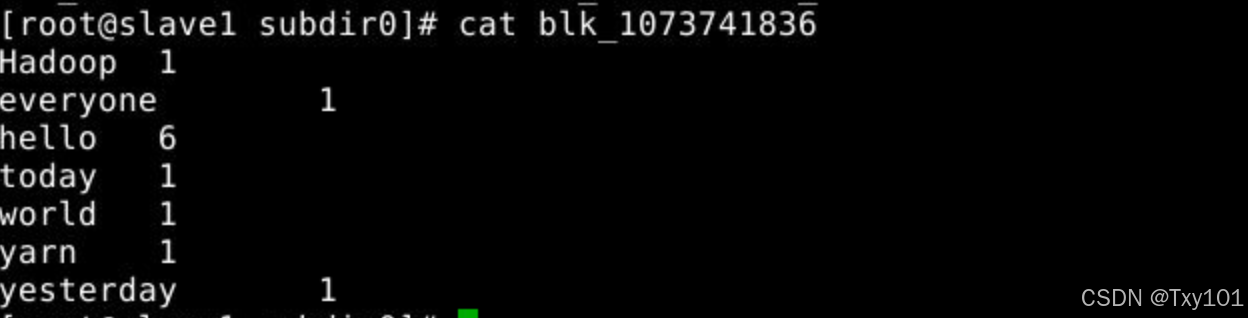
在master节点上:

^^
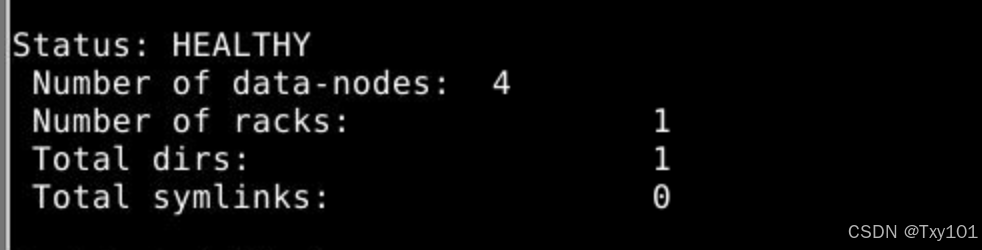
使用hdfs fsck命令查看文件的块信息
hdfs fsck /dataoutput -files -blocks -locations
检查 HDFS 中
/dataoutput路径下文件只能在master节点上(NameNode的存储)执行
输出示例:
/dataoutput/part-r-00000 63 bytes, replicated: replication=3, 1 block(s): OK
0. BP-1546549893-172.18.0.2-1742792674178:blk_1073741836_1012 len=63 Live_repl=3 [DatanodeInfoWithStorage[172.18.0.5:9866,DS-cc005683-c046-494f-9a78-899bfd5469ea,DISK], DatanodeInfoWithStorage[172.18.0.4:9866,DS-f1020da9-5f3a-4dcc-b3b0-8e8268dba16f,DISK], DatanodeInfoWithStorage[172.18.0.3:9866,DS-03247bab-3ca9-4022-bb69-8851d958f095,DISK]]
# blk_1073741836:实际的块存储的名字# DatanodeInfoWithStorage:实际的块存储的位置
# 172.18.0.5(0.4/0.3):机器所在的IP地址
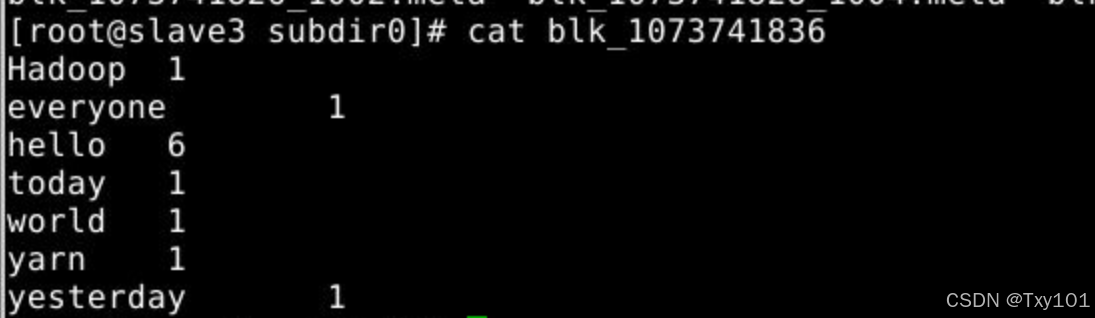
- 分别去slave1、slave2、slave3文件存储位置执行文件位置查找blk_1073741836_1012,名字为blk_1073741836的
<property>
<name>dfs.replication</name>
<value>3</value>
</property>设定 HDFS 存储文件时的数据块副本数量
dfs.replication:这是 HDFS 的一个关键配置参数,用于明确每个数据块在 HDFS 集群里要存储的副本数量。3:代表每个数据块会被复制 3 份,存储于不同的 DataNode 节点。- 有多少台机器最多存储多少台
在slave2节点上,BP号与在master节点上查询的一样
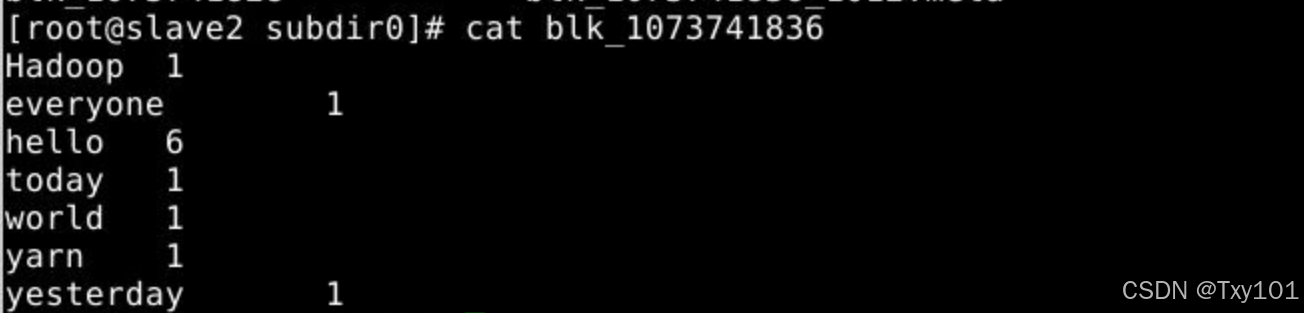
在slave3节点同上
大文件测试
切换到/usr/local/java目录
cd /usr/local/java
ls
将位于 /cgsrc/ 目录下的 jdk-8u171-linux-x64.tar.gz 压缩包复制到根目录 /
[注]tar.gz 文件名和 /之间有一个空格
cp /csgsrc/jdk-8u171-linux-x64.tar.gz /
ls
将本地文件系统中的 jdk-8u171-linux-x64.tar.gz 文件上传到 HDFS 的根目录下
hadoop fs -put -f /jdk-8u171-linux-x64.tar.gz /
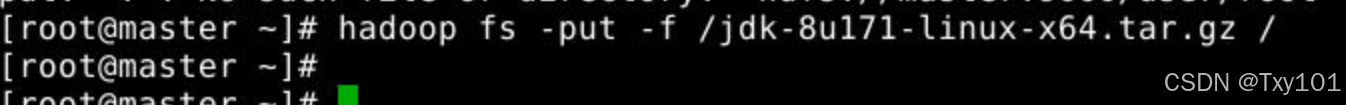
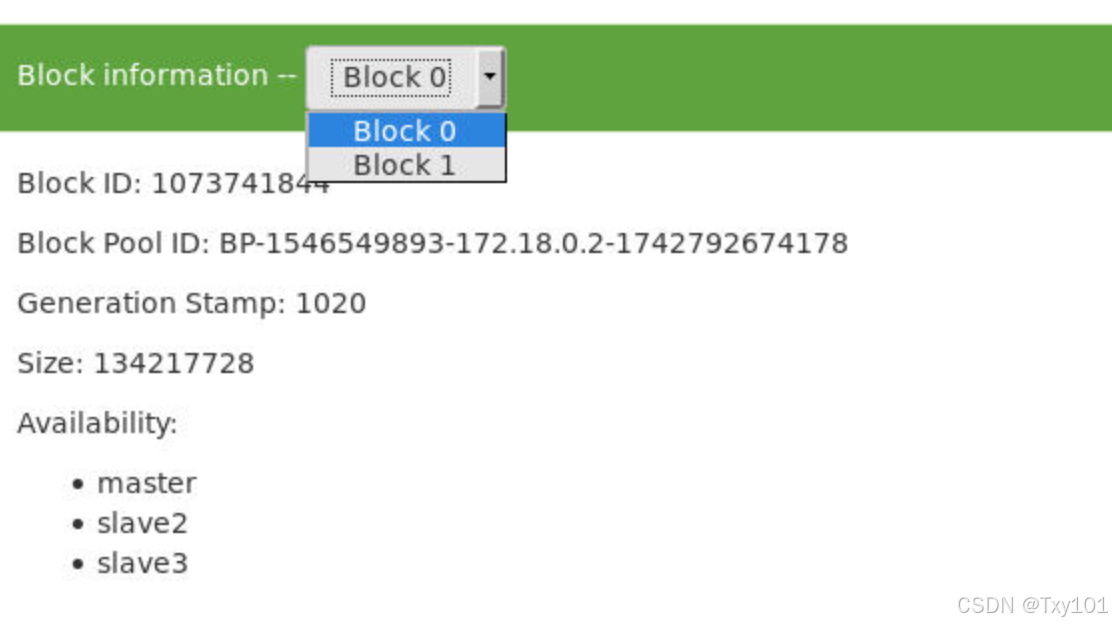
可以在端口查看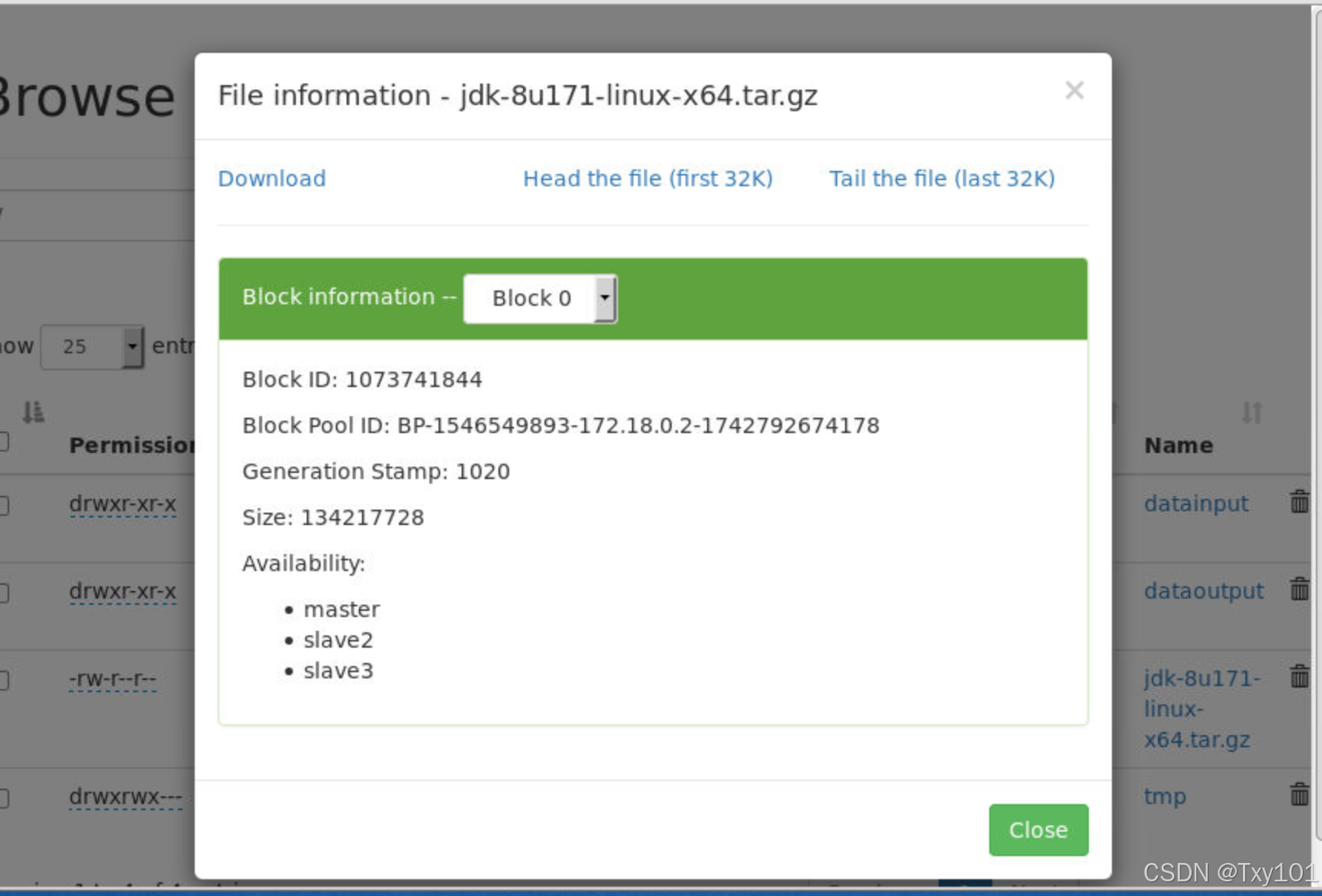
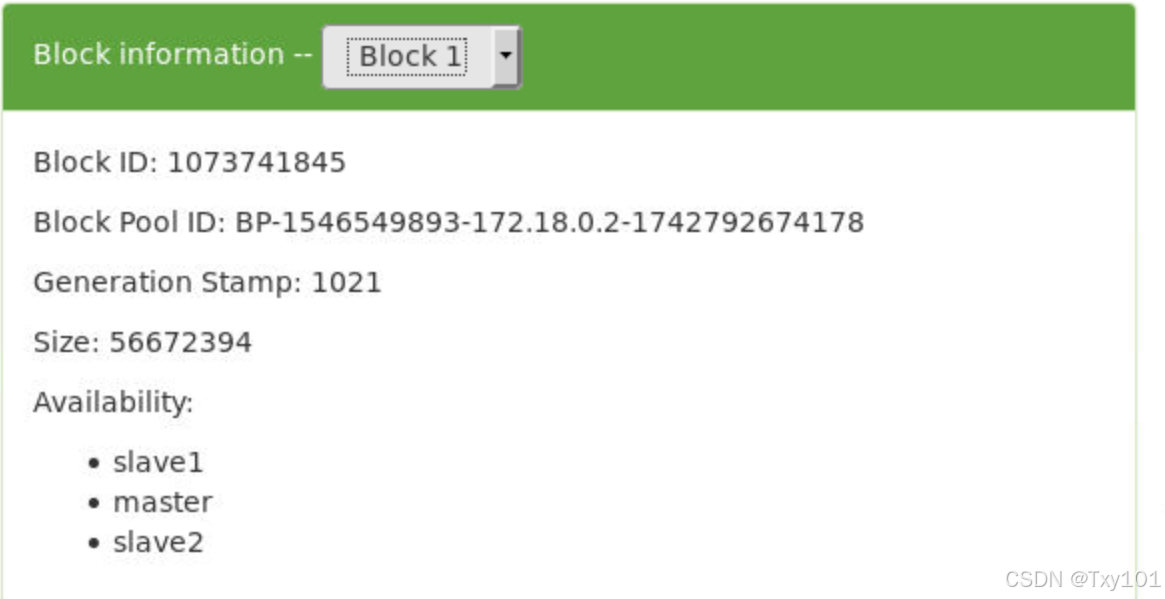
表示该数据块存储在 slave3 、 master 、 slave2 这些节点上
hdfs fsck /jdk-8u171-linux-x64.tar.gz -files -blocks -locations
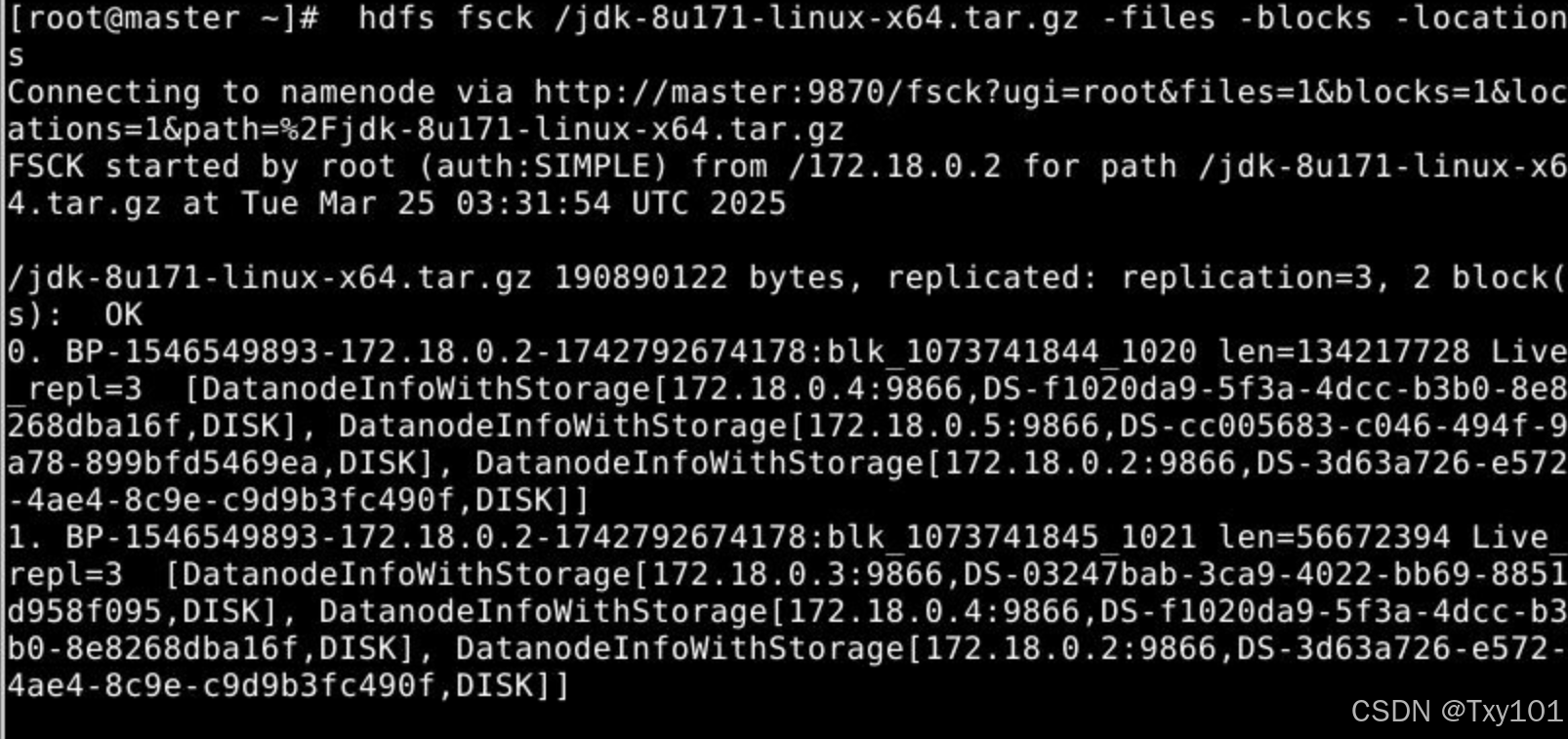
文件内容如下:
/jdk-8u171-linux-x64.tar.gz 190890122 bytes, replicated: replication=3, 2 block(s): OK
0. BP-1546549893-172.18.0.2-1742792674178:blk_1073741844_1020 len=134217728 Live_repl=3 [DatanodeInfoWithStorage[172.18.0.4:9866,DS-f1020da9-5f3a-4dcc-b3b0-8e8268dba16f,DISK], DatanodeInfoWithStorage[172.18.0.5:9866,DS-cc005683-c046-494f-9a78-899bfd5469ea,DISK], DatanodeInfoWithStorage[172.18.0.2:9866,DS-3d63a726-e572-4ae4-8c9e-c9d9b3fc490f,DISK]]
1. BP-1546549893-172.18.0.2-1742792674178:blk_1073741845_1021 len=56672394 Live_repl=3 [DatanodeInfoWithStorage[172.18.0.3:9866,DS-03247bab-3ca9-4022-bb69-8851d958f095,DISK], DatanodeInfoWithStorage[172.18.0.4:9866,DS-f1020da9-5f3a-4dcc-b3b0-8e8268dba16f,DISK], DatanodeInfoWithStorage[172.18.0.2:9866,DS-3d63a726-e572-4ae4-8c9e-c9d9b3fc490f,DISK]]
^^
切分成2个模块,并且每个块的名字不一样
文件过大,切分成小块
1)在master节点上
查看文件位置
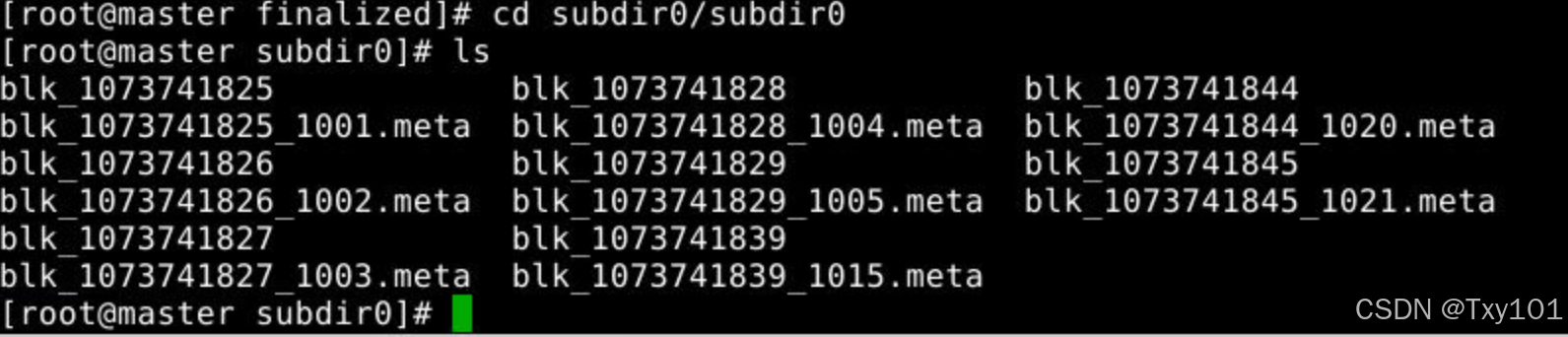
^^
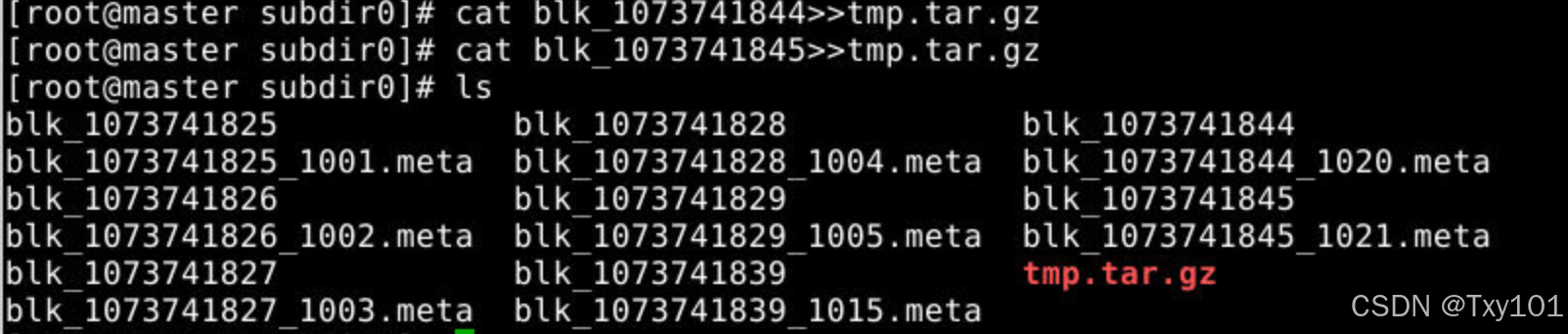
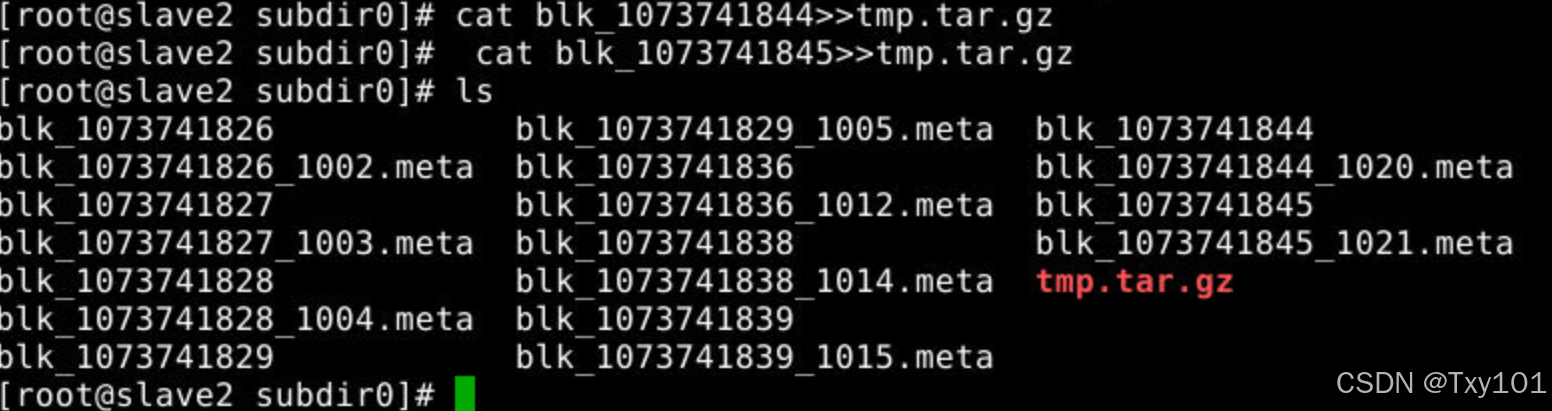
cat命令用于查看文件内容,这里结合>>操作符,>>表示追加内容。
将名为blk_1073741844的文件内容追加到tmp.tar.gz文件中;
将blk_1073741845文件的内容追加到tmp.tar.gz文件中;
cat blk_1073741844>>tmp.tar.gz
cat blk_1073741845>>tmp.tar.gz
解压文件
tar -zxvf tmp.tar.gz

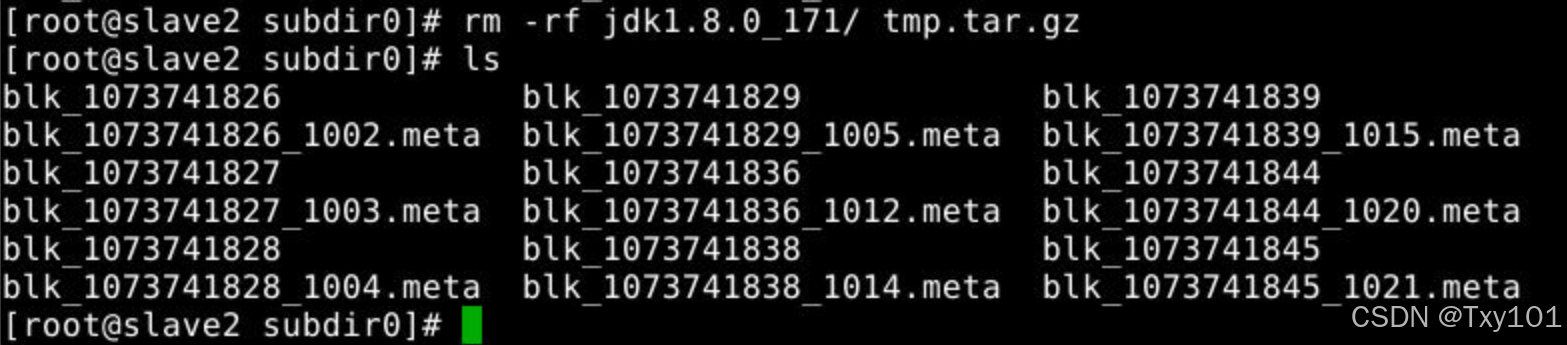
删除,目录回到只有数据块和元数据文件的状态
rm -rf jdk1.8.0_171
rm -rf tmp.tar.gz
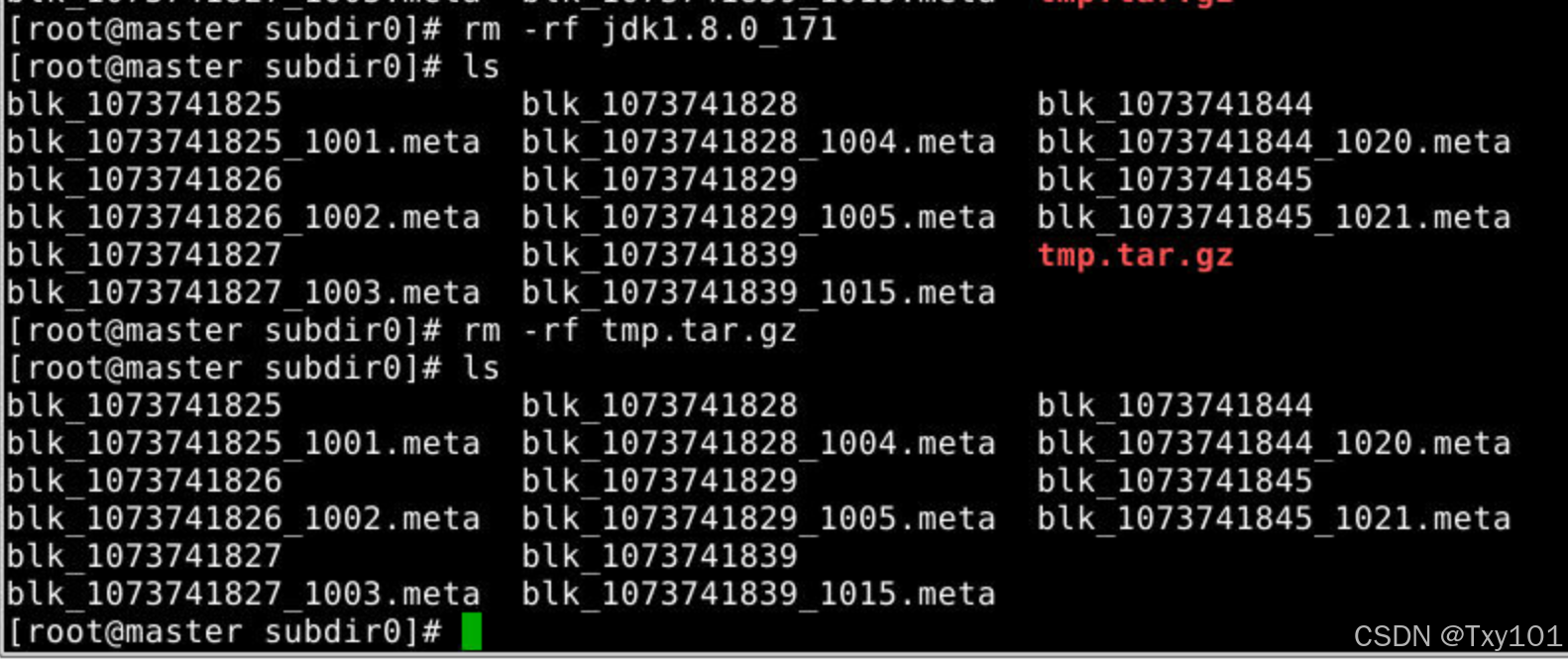
2)在slave节点上同上


可以在端口查看
总结
一、常用端口号
-
hadoop3 X(目前的版本)
HDFS NameNode内部通常端口 8020/9000/9820 HDFS NameNode对用户的查询端口 9870 Yarn查看任务进行情况的端口 8088 历史服务器查询端口 19888 -
hadoop2 X(HBase)
HDFS NameNode内部通常端口 8020/9820 HDFS NameNode对用户的查询端口 50070 Yarn查看任务进行情况的端口 8088 历史服务器查询端口 19888
二、常用的配置文件
3 X core-site.xml 、hdfs-site.xml 、yarn-site.xml 、mapred-site.xml 、workers
2 X core-site.xml 、hdfs-site.xml 、yarn-site.xml 、mapred-site.xml 、slaves
^ core-default.xml(默认配置文件):当 Hadoop 启动时,会首先加载core - default.xml中的配置信息,然后再加载core - site.xml等自定义配置文件,后者可以覆盖core - default.xml中的默认值
^core-site.xml 的优先级 高于 hdfs-default.xml

开源鸿蒙跨平台开发社区汇聚开发者与厂商,共建“一次开发,多端部署”的开源生态,致力于降低跨端开发门槛,推动万物智联创新。
更多推荐
 11
11 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)