论文阅读: Innate Reasoning is Not Enough: In-Context Learning Enhances Reasoning Large Language Models w
最近推理引入LLM,称为reasoning model或RLLM。RLLM的特点是,回答前先天生成CoT(innate CoT),包含反思和自我纠正。目前的研究是,innate CoT能显著增强模型的推理能力。传统的CoT的研究,不好的few-shot CoT是会降低模型性能。另一方面,既然模型能够自己生成CoT,那么输入的promt中CoT还重要吗?对于一般CoT的研究,一开始是few-shot
目录
一、整体说明
这篇论文从数学问题的角度,部分测试了一些小的开源RLLM的推理能力,主要考察指标是准确率、思考长度和反思、推理数量。得到的结论是CoT对于RLLM的效果方法依然同等有效。
二、具体解读
1、作者

2、问题介绍
最近推理引入LLM,称为reasoning model或RLLM。RLLM的特点是,回答前先天生成CoT(innate CoT),包含反思和自我纠正。目前的研究是,innate CoT能显著增强模型的推理能力。传统的CoT的研究,不好的few-shot CoT是会降低模型性能。另一方面,既然模型能够自己生成CoT,那么输入的promt中CoT还重要吗?
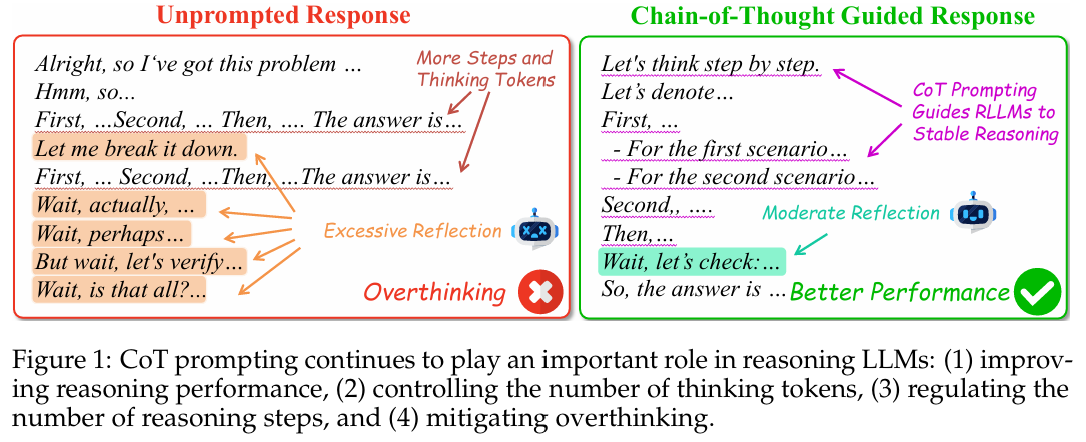
对于一般CoT的研究,一开始是few-shot CoT,后来是zero-shot CoT,在后来是Auto-CoT。CoT在很多方面都能够影响LLM的输出,包括输出的序列的长度。
Innate CoT从另一个角度可以认为,是让推理在模型的内部发生,例如将搜索算法和反思prompt集成到模型内部。
3、实验
使用多个RLLM,从数学问题角度探索。
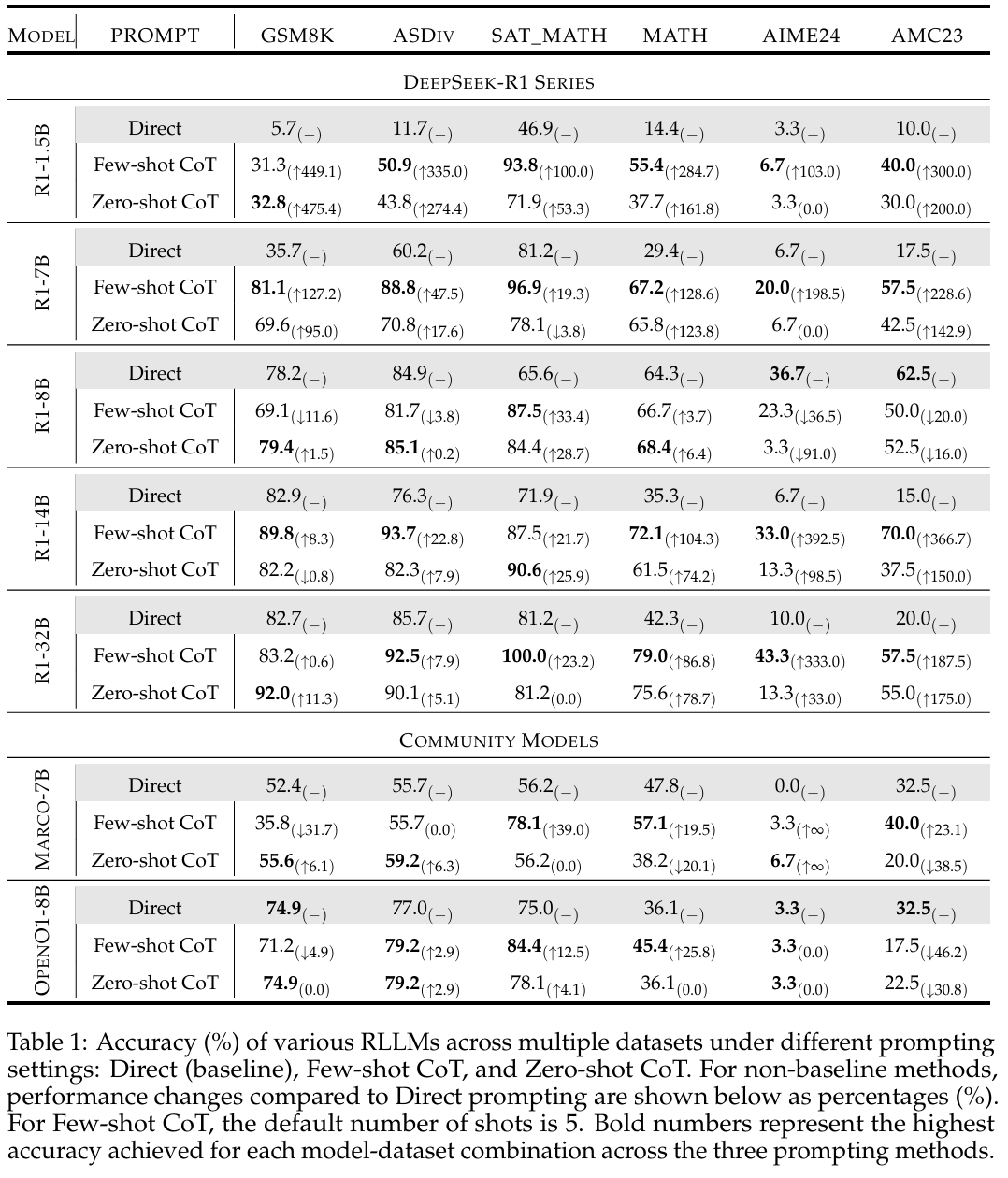
(1)方法
3种CoT:
- 直接提问。仅问题描述。
- zero-shot CoT。“让我们一步步思考”
- few-shot CoT。含有预期输出。
(2)设置
模型: 开源的RLLM。
数据: 6个数学基准,从小学到竞赛。
指标: 准确率,thinking token数量,推理步骤数量,反思数量。后面两个指标根据具体的字符串来确定。
(3)影响
- 准确率,72%的情况,zero-shot和few-shot会提升模型的性能。其实zero-shot的提升会更好,并且更稳定。
- thinking token数量,不同的CoT方法也会明显影响输出的token数量。使用CoT会增加thinking token的数量,并且分布相比不使用更加集中。few-shot下的token数量的分布是最集中的,很大程度上源于模型的过多学习示例。
- 过度反思。RLLM会在遇到复杂问题时输出过多没有必要的token,反思甚至高达几百次,而引入CoT后,反思的数量下降得非常明显,并且准确率也提升很多。这充分说明很多的反思是没有必要的。额外的一点关注,就反思而言,zero-shot的结果比few-shot的结果要好。
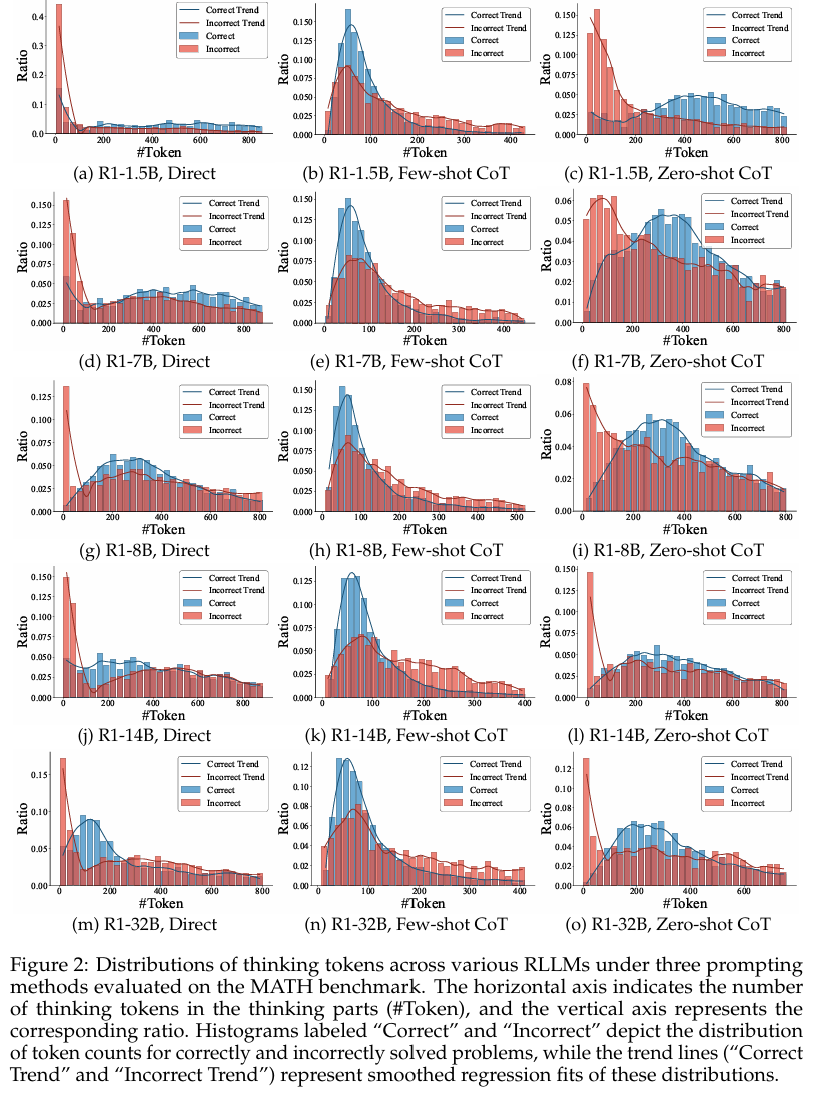
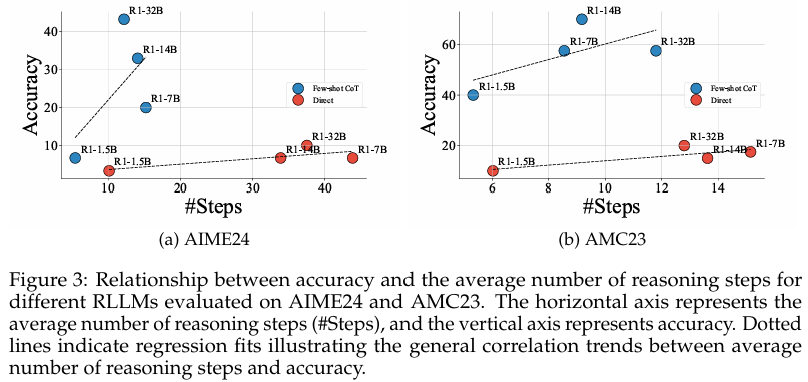
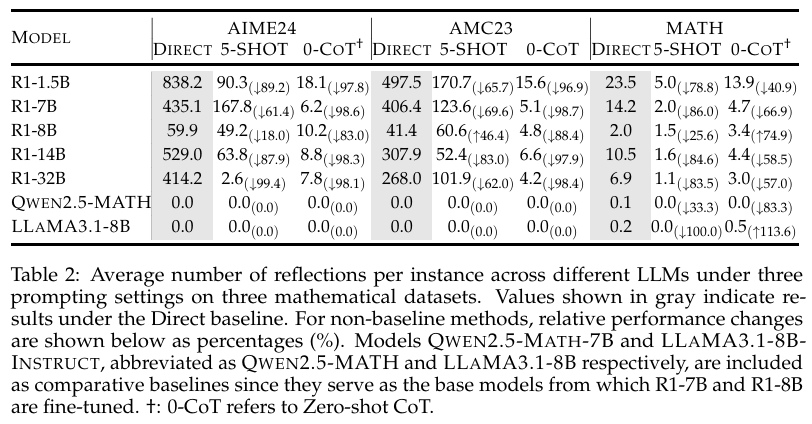
(4)关于反思的研究
对于本文的数学问题的研究,涉及的RLLM的过度反思过于常见。在测试的所有模型,正确率随着反思步骤提升到一定程度之后开始下降。
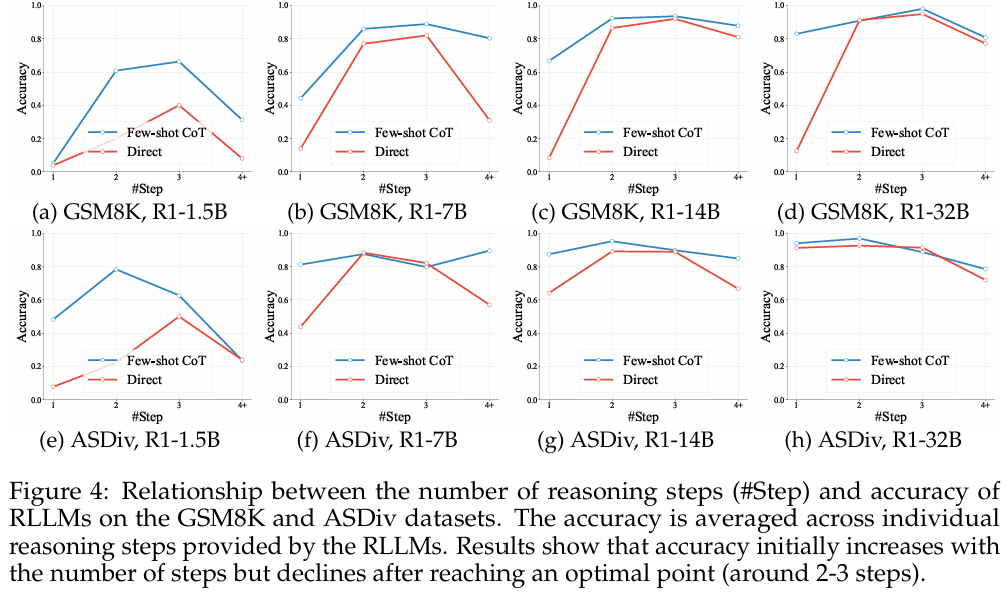
(5)关于提示数量的研究
当使用了one-shot,所有的模型都表现出更好的效果,而更多的提示,效果反而并不完全稳定能提升模型的效果。
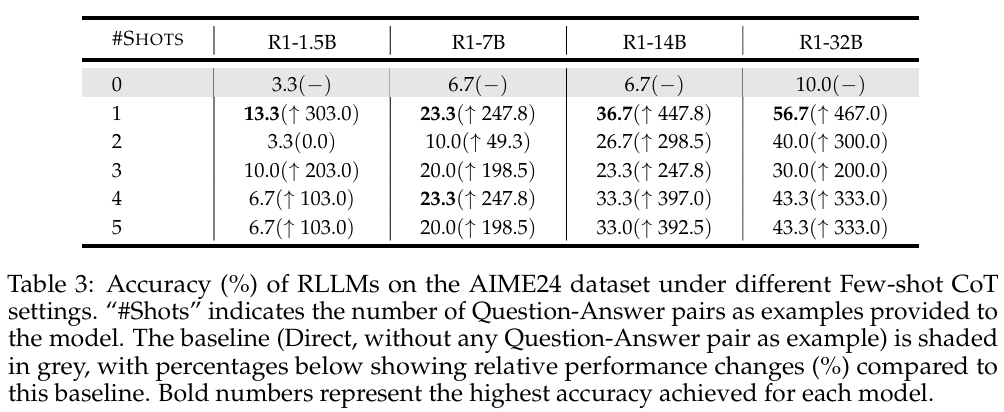
(6)注意力模式的研究
研究模型基本的注意力,本文中作为反思和步骤标准的单词有较高的注意力分数,尤其是"wait"。
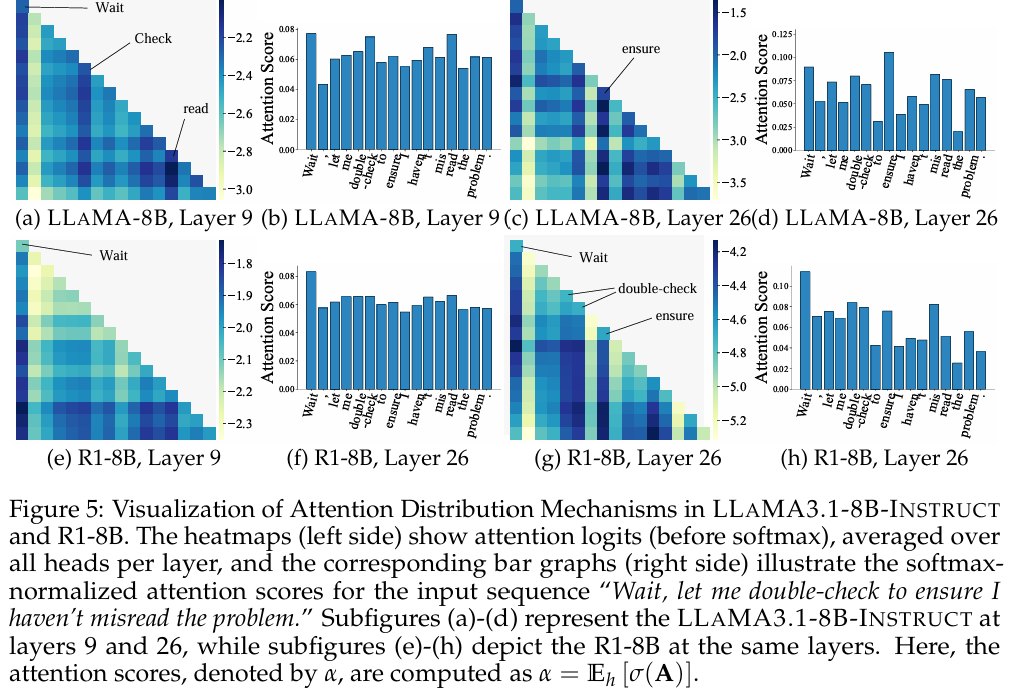
三、总结
这是一篇很简单的论文。其实可以看得出来,这篇论文写得挺着急的。最关键实验结果的图片横纵坐标的单位不一致,比较结果的时候看起来很难受。很有新意的用attention score的方式研究的图,文本又被覆盖了很多。不知道后续上传的版本会不会修改这些小问题。
这篇论文虽然很简单,但是确实回答了我之前观察并想到的一些问题。CoT的方法,以及few-shot的方法,确实不一定完全会增强模型的生成效果。我通过本文了解到了更好的CoT的方法,但是对于这里的结论存疑。原因就是,为什么不完全测试所有的RLLM,即使是开源的,也还有deepseek-reasoner,以及qwen-QwQ。同一个family的模型得到的结论,可能只能代表部分的结果。而与数学问题对应的,编程方面的问题也可以同样通过自动化快速进行测试的。而且关于思考步骤和正确率的关系,本文似乎思考的有些问题。困难的问题是会代表更多的步骤,也自然正确率会下降,但这不代表思考步骤的增多正确率会下降啊?
我之前观察到一个现象,就是RLLM会在不知道问题如果解决的情况下,过度输出thinking token,造成api以及context资源的严重浪费。这篇文章回答了这个问题,那就是实际上这是一种过拟合的现象。我的观点是这只是模型的in-context learning的能力,而不完全代表模型的推理能力。这篇论文我认为很好的一个方式就是回到模型本身去检测attention score,这样做可视化分析的方法对于我之前是欠缺的。

开源鸿蒙跨平台开发社区汇聚开发者与厂商,共建“一次开发,多端部署”的开源生态,致力于降低跨端开发门槛,推动万物智联创新。
更多推荐
 8
8 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)