自监督和有监督下的单/双塔模型
1. 自监督1.1.PCL: Peer-Contrastive Learning with Diverse Augmentations for Unsupervised Sentence Embeddings1.2.TRANS-ENCODER 自监督的Sentence Bi & Cross Encoder1.3.Mirror-Bert1.3.1.相关背景1.3.2.方法介绍1.4.Self-gui
文章目录
- 1. 自监督
-
- 1.1.PCL: Peer-Contrastive Learning with Diverse Augmentations for Unsupervised Sentence Embeddings
- 1.2.TRANS-ENCODER 自监督的Sentence Bi & Cross Encoder
- 1.3.Mirror-Bert
- 1.4.Self-guided contrastive learning for BERT sentence representations
- 1.5.CLEAR: Contrastive Learning for Sentence Representation
- 1.6.ESimCSE
- 1.7.RankCSE
- 2.有监督双塔
- 3.有监督单塔
- 3. 数据噪声
又是一篇从草稿箱里面翻出来的笔记,还是bert时代的产物,跟目前的LLM多少有点不在一个频道上,但是有些思想还是比较有意思甚至是post-training以及对齐阶段可以参考的~
1. 自监督
1.1.PCL: Peer-Contrastive Learning with Diverse Augmentations for Unsupervised Sentence Embeddings
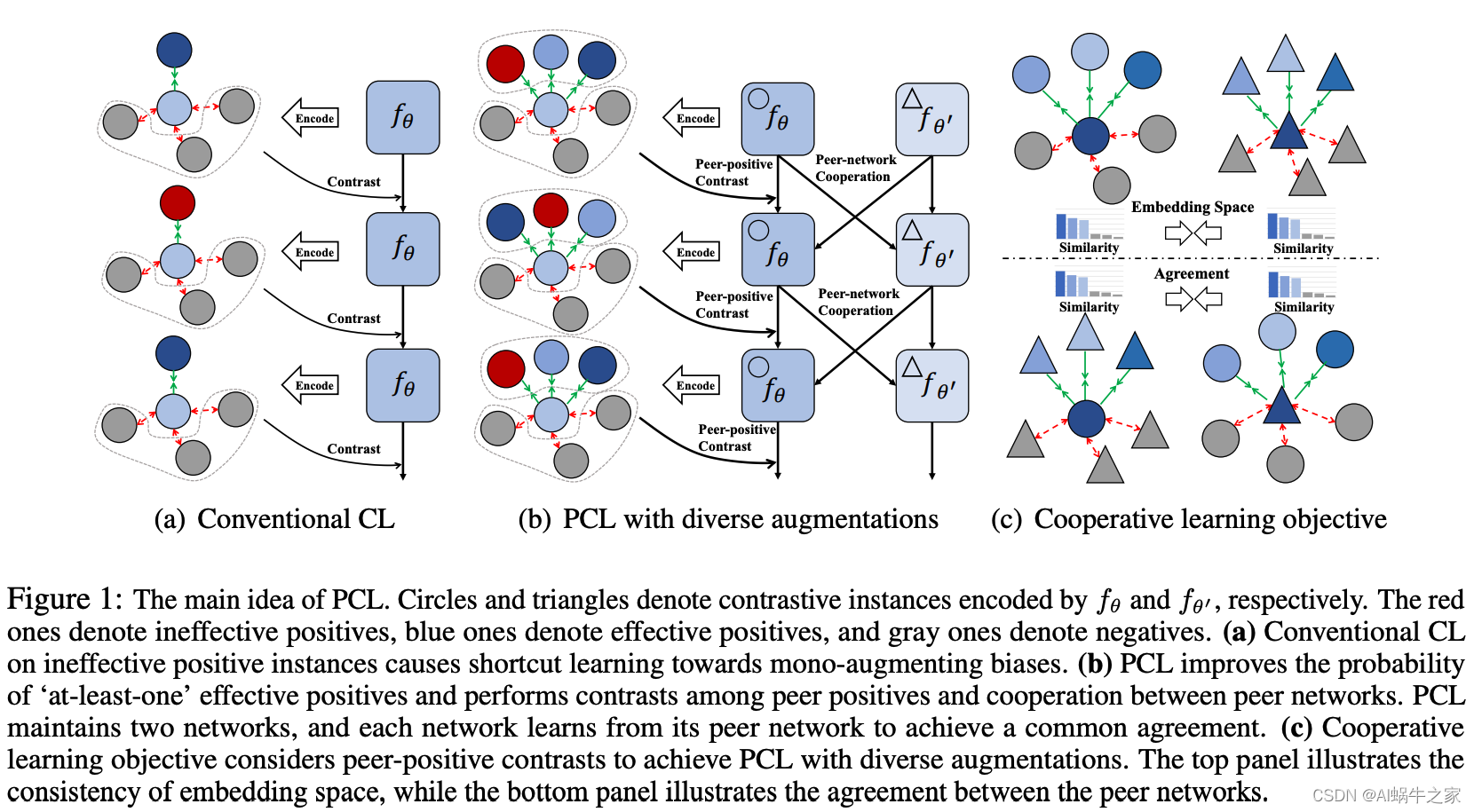
两种对比学习找正样本的方法——离散(Discrete augmentation format)和连续(Continuous augmentation format):
- Discrete augmentation format:直接通过字符或者n-gram的方式修改正样本,比如同义词替换、字词shuffing、字词删减、回译;
- Continuous augmentation format:通过隐变量的方式,比如SimCSE中两次dropout
motivation:
目前模型要么采用离散的方式,要么采用连续方式,但是都用的是单一的增强方式(mono-augmenting format)并且增强策略有限,这导致上述方法都存在“学习捷径”。例如依赖两次dropout的正样本训练出来的模型倾向于通过句子长度判断。
知识点小百科:
- Shortcut Learning:
预训练语言模型如BERT在许多NLU任务上展现出了出色的性能,但最近的研究表明,这类模型倾向于利用数据集的bias,尝试利用“捷径(shortcuts)”去获得较高的评测性能,而不是真正地理解语言。这往往会导致模型在OOD样本上较差的泛化性能,以及面对对抗攻击时较差的鲁棒性。
具体的考虑分类任务:给定样本 x x x,模型需要学习一个映射 f ( x ) f(x) f(x) 去预测标签 y y y。在训练过程中,如果一些词或短语与某个标签 y y y 共现的次数高于其他词,模型就会捕获这类特征用于预测。根据独立同分布的假设,训练、验证和测试集均采样自同一个数据分布,因此即使模型捕获了这类捷径特征用于预测,在测试集中指标也不会很差。然而,当暴露于分布外数据(OOD samples)和对抗样本(adversarial samples)的时候,模型就会表现出较差的泛化性和鲁棒性,因为他们不一定和训练集的数据具有相同的shortcuts。
method
同时采用多种增强正样例的方法(离散+连续),但是采用多种增强方式也有双刃剑(double-edged sword)——多种增强方式可能导致无法保证样本质量。我们提出了一个brand-new peer-contrastive learning framework,它不仅可以执行普通的正反对比,还可以执行正反对比。
we propose a brand-new peer-contrastive learning framework that not only performs the vanilla positive-negative contrast but a positive-positive contrast.
1.2.TRANS-ENCODER 自监督的Sentence Bi & Cross Encoder
动机:
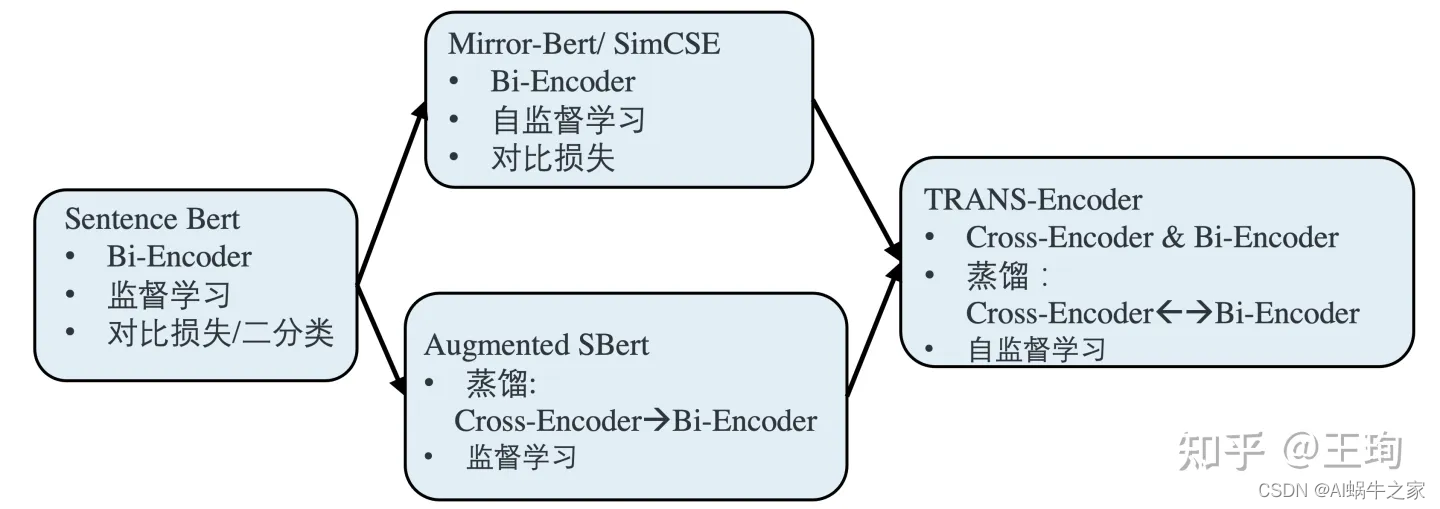
既然自监督效果卓越,已经在Bi-Encoder上打平甚至超越了监督学习了,而Cross-Encoder一般来说,其效果又是强于Bi-Encoder,那么不禁想,为什么不强强联合,自监督学习一个Cross-Encoder出来呢。
问题:
那么难点来了,自监督的学习一个Cross-Encoder是没有现成的自监督框架的,如果我们硬是要照搬SimCSE/Mirror-Bert, 将一个句子,和其augmentaion拼接起来输入Cross-Encoder,让模型判断是否相似,这个正例对于模型有点过于简单了,负例也是同理。模型很难在这样的自监督任务设计上学到有效信息;Bi-encoder之所以可以是因为两个句子是分别过模型的,在最后的输出才计算相似度,这个任务对Bi-encoder是有一定的难度的。
方案:
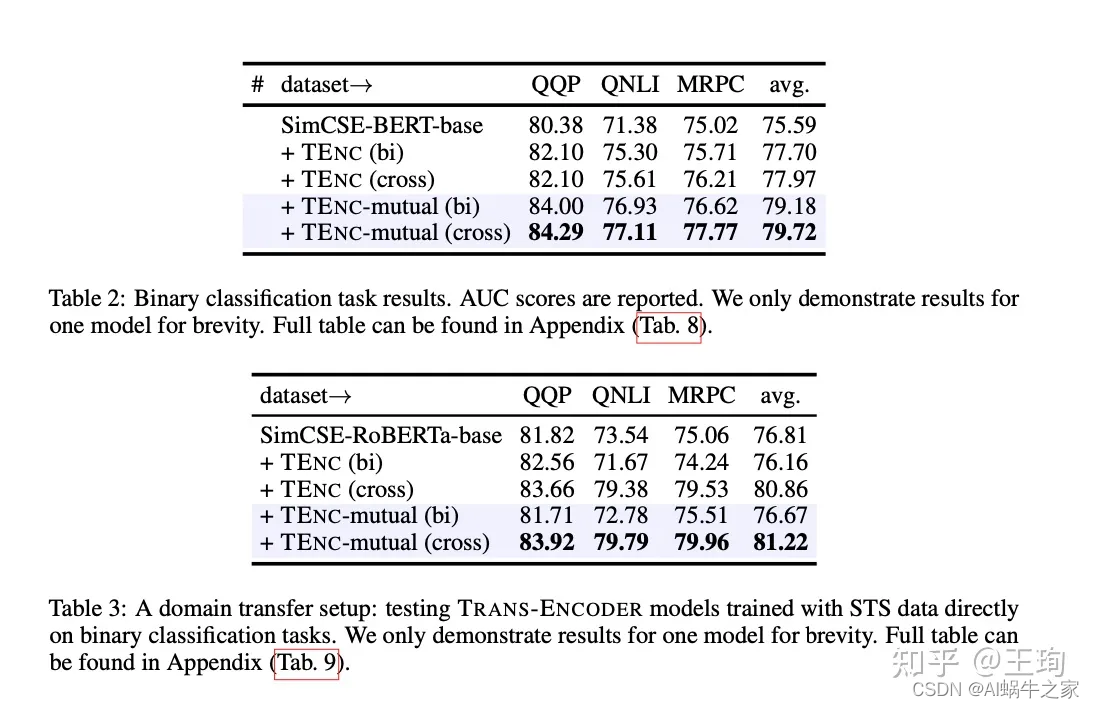
解决问题的办法,在于结合知识蒸馏和自监督学习,按照上图,我们首先按照自监督学习训练一个强力的Bi-Encoder 模型,然后,以该Bi-Encoder模型为师,知识蒸馏去训练一个Cross-Encoder,值得注意的是,虽然Cross-Encoder是学生,但是其本身模型架构的能力上限是强于其老师Bi-Encoder,因此可以做到青出于蓝而胜于蓝,在知识蒸馏之后,其模型效果优于Bi-Encoder。这个就是模型的第一步:Bi-Encoder —> Cross-Encoder。
那么,接下来第二步就简单了,我们有了一个强于Bi-Encoder的Cross-Encoder 语义相似性模型,那么和Augmented SBert类似,可以以Cross-Encoder为师,知识蒸馏增强Bi-Encoder 。至此康庄大道已在眼前,以上两个步骤,可以循环往复,迭代进行;两个模型,互为老师,教学相长,一起变强。
若干小细节:
该文章构思巧妙而又简单: 在损失函数上,Bi-Encoder -> Cross-Encoder的损失函数为二元交叉熵损失BCE;Cross-Encoder -> Bi-Encoder的损失函数为均方误差损失MSE。同时,在网络设计上,也很优雅,其中Bi-Encoder和Cross-Encoder共享网络结构,其区别仅仅在于Bi-Encoder输入为单个句子, 而Cross-Encoder的输入为[CLS] sent1 [SEP] sent2 [SEP]。文章的方法在各个benchmark上取得了很大的效果提升。
参考:
TRANS-ENCODER:自蒸馏和互蒸馏的无监督句对模型
论文分享-自监督的Sentence Bi & Cross Encoder
1.3.Mirror-Bert
1.3.1.相关背景
对比学习训练,使用InfoNCE[1]损失函数作为训练目标,旨在一个batch内拉近和当前句子相似句子的表示,推开不相似句子的表示,由余弦相似度来度量句子表示之间的距离。在对比学习中,构造出多样且高质量的正例对是关键,这里列出了图一中近期各对比学习方法使用的正例构造方法,主要分为2个层面:
- 文本输入层面的修改
随机删除词(ConSERT[2],CLEAR[3])
随机删除连续词(ConSERT,CLEAR,Mirror-BERT)
打乱输入顺序(ConSERT,CLEAR)
同义词替换(CLEAR) - 特征层面构造不同视角
随机掩盖某一维特征(ConSERT)
两次不同的Dropout结果(ConSERT,SimCSE,Mirror-BERT)
增加噪声扰动(ConSERT)
由2个不同模型提供不同视角的特征(Self-Guide Contrastive Learning[4],CT[5])
1.3.2.方法介绍
本文Mirror-BERT主要使用了随机删除连续词和dropout策略来构造正例,dropout也被其他工作证明为简单有效的对比学习正例构造方式。从近期对比学习的相关工作来看,不对原句做过多的破坏能保证构造正例的质量,在不考虑训练效率的情况下,额外训练一个模型提供另一视角下的句子表示也被证明有效。
比较关注STS的结果,与SimCSE相比,平均结果没有SimCSE好,部分任务略优。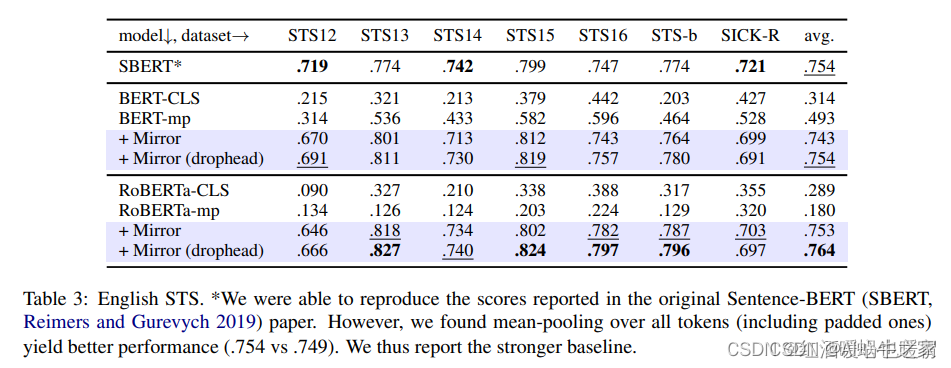
Mirror各个不同的任务中都用了10k的数据,我印象中SimCSE用的数据较多,经过查验:We randomly sample 1 0 6 10^610
6
sentences from English Wikipedia and fine-tune BERT base with learning rate = 3e-5, N = 64. In all our experiments, no STS training sets are used。但是看下图,Mirror-Bert 在10k-20k的时候大部分任务都能取到最好的结果
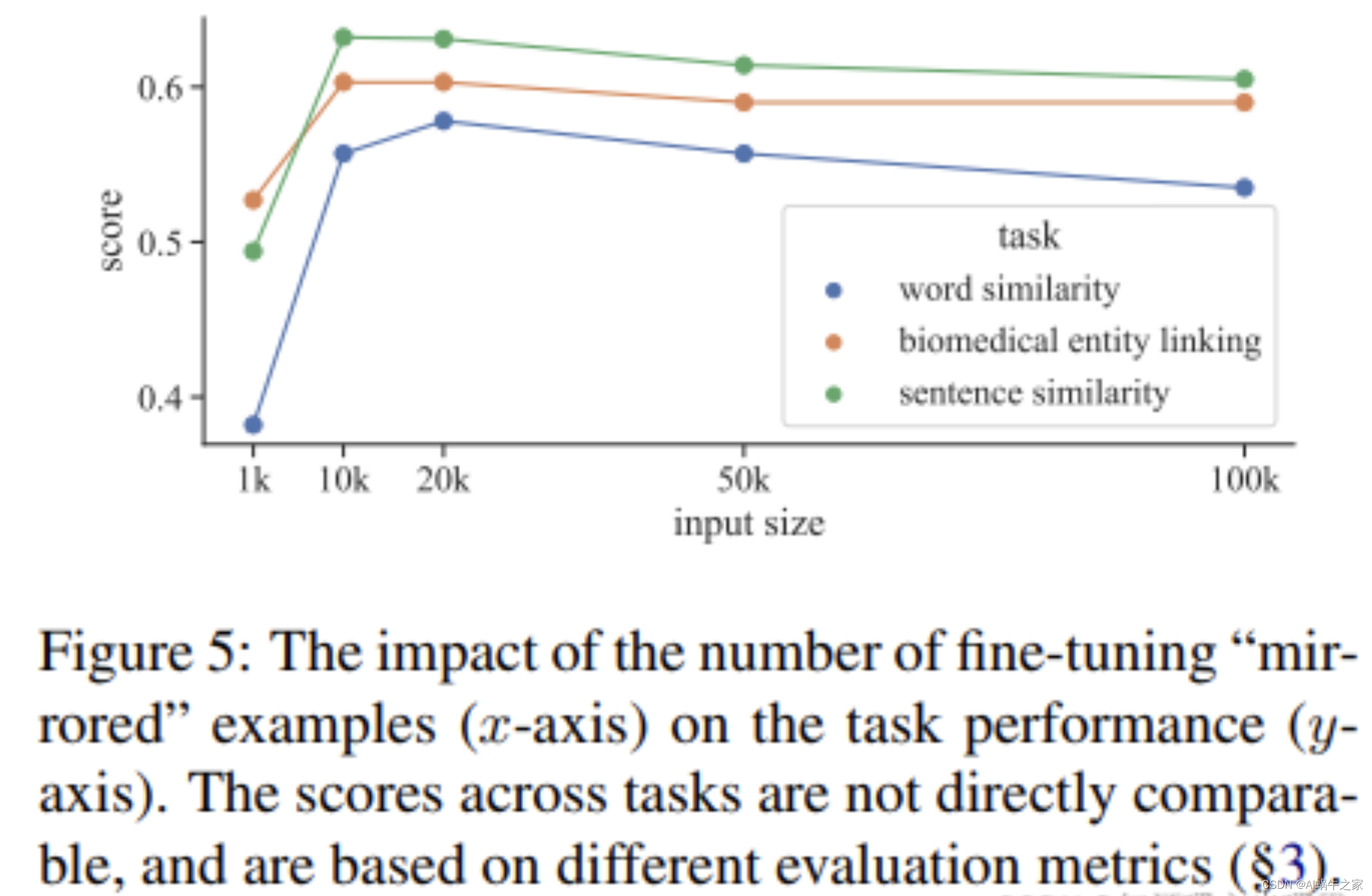
在STS任务上做的消融试验,span mask起的作用更大一些,但是两者一起用的时候效果最好。其中drophead method: it randomly prunes attention heads at MLM training as a regularisation step
Mirror-BERT Improves Isotropy?看样子是的
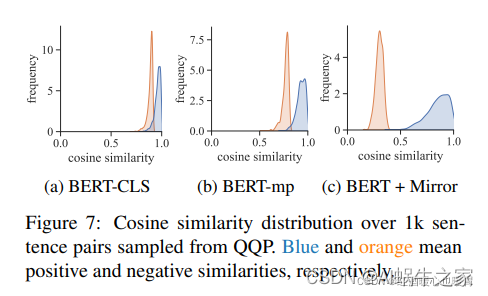
从数据增强的角度看,SimCSE的确是它的一个特例,但是SimCSE将对比方法延伸到有监督和无监督两种,且效果的确比Mirror-Bert好,还是danqi女神的作品,如果只想读一篇,我更推荐看SimCSE。
参考链接:
Fast, Effective, and Self-Supervised:Mirror-BERT
1.4.Self-guided contrastive learning for BERT sentence representations
来自首尔大学,讨论的问题是如何在不引入外部资源或者显示的数据增强的情况下,利用BERT自身的信息去进行对比,从而获得更高质量的句子表示?
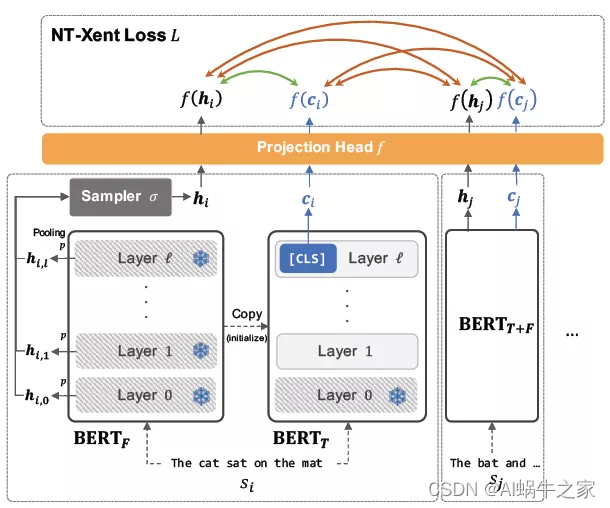
文中对比的是:BERT的中间层表示和最后的CLS的表示。模型包含两个BERT,一个BERT的参数是固定的,用于计算中间层的表示,其计算分两步:(1) 使用MAX-pooling获取每一层的句子向量表示 (2)使用均匀采样的方式从N层中采样一个表示;另一个BERT是要fine-tune的,用于计算句子CLS的表示。同一个句子的通过两个BERT获得两个表示,从而形成正例,负例则是另一个句子的中间层的表示或者最后的CLS的表示。
1.5.CLEAR: Contrastive Learning for Sentence Representation
CLEAR设计了mask language modal去表征词级别的特征,用对比学习表征句子级别的特征。对比学习将相同句子数据增强以后的结果拉近(作为正例),将不同句子以及不同句子的数据增强拉远(作为负例)。通过将句意相似的句子彼此拉近的方式,更好的学习句子级别的语义信息。
该文章的贡献如下:
1,设计了四种数据增强的方式random-words-deletion随机词语删除,spans-deletion随机连续token删除, synonym-substitution同义词替换, reordering重新排序。
2,设计了对比学习的思路更好的对句子级别的语义进行表征。
3,在很多下游任务上取得了很好的效果。
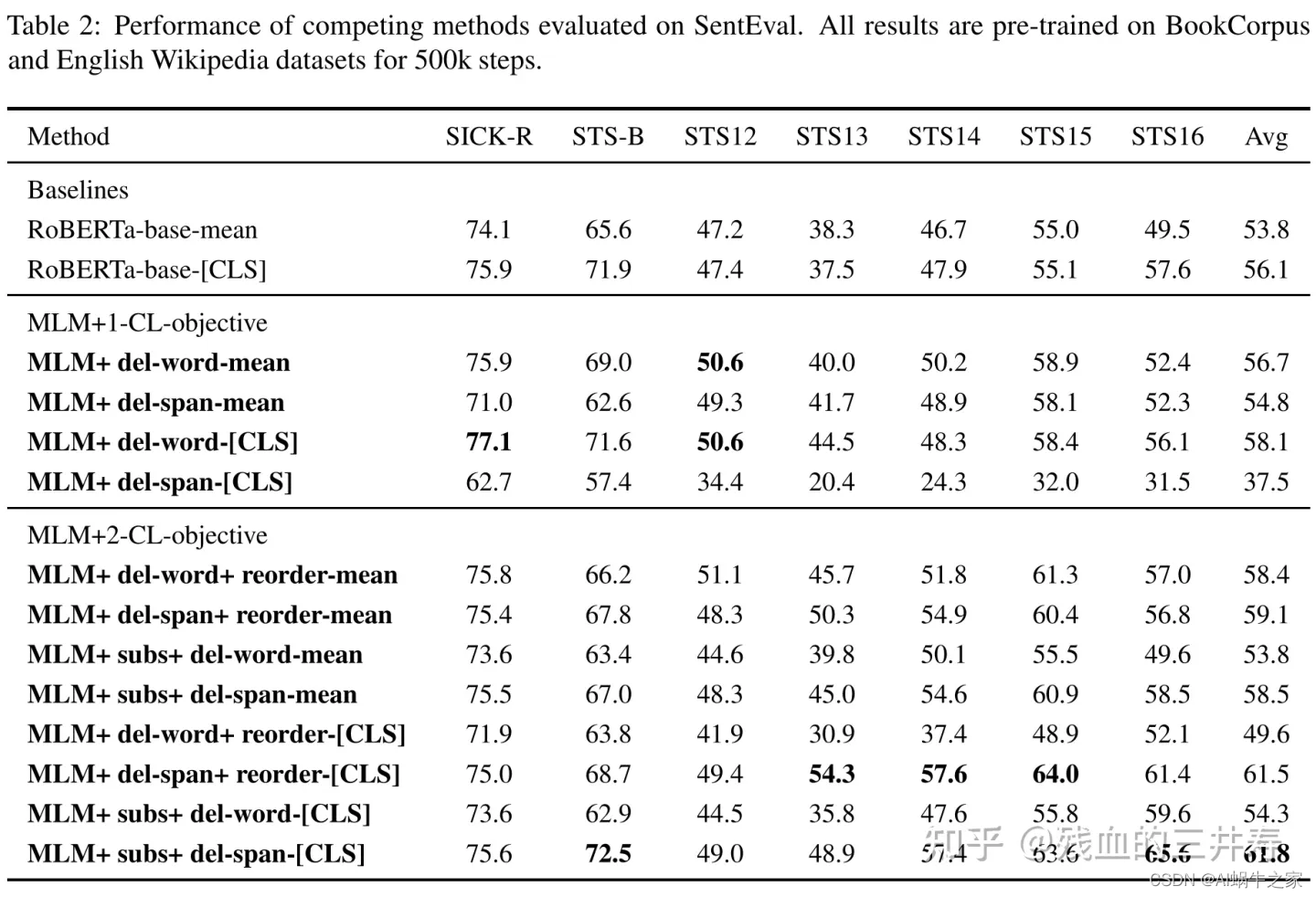
效果其实跟最新的比起来效果一般:
1.6.ESimCSE
通过对比学习,进行自监督的方法,使用计算交叉熵为loss通过softmax分类来学习正负样本相似度。ESimCSE是SimCSE升级版。SimCSE是通过dropout两个句子产生两个相似的正负样本进行对比学习,来学习到文本匹配之间的关系。ESimCSE解决了SimCSE遗留的两个问题:
1、SimCSE通过dropout构建的正例对包含相同长度的信息(原因:Transformer的Position Embedding),会使模型倾向于认为相同或相似长度的句子在语义上更相似;
2、更大的batch size会导致SimCSE性能下降;
ESimCSE构建正例对的方法:**Word Repetition(单词重复)**和 **Momentum Contrast(动量对比学习)**扩展负样本对。
1.7.RankCSE
非官方代码实现:https://github.com/perceptiveshawty/RankCSE
对比学习不仅需要考虑样本之间是否为正负对,还需要思考更加细粒度的相似程度关系。锚点对正负样本的打分不能仅仅通过 InfoNCE 去拉开正样本和所有负样本的表示,还需要加入排序信息。
(1) standard contrastive learning objective (§4.2);
(2) ranking consistency loss which ensures ranking consistency between two representations with different dropout masks (§4.3);
(3) ranking distillation loss which distills listwise ranking knowledge from the teacher
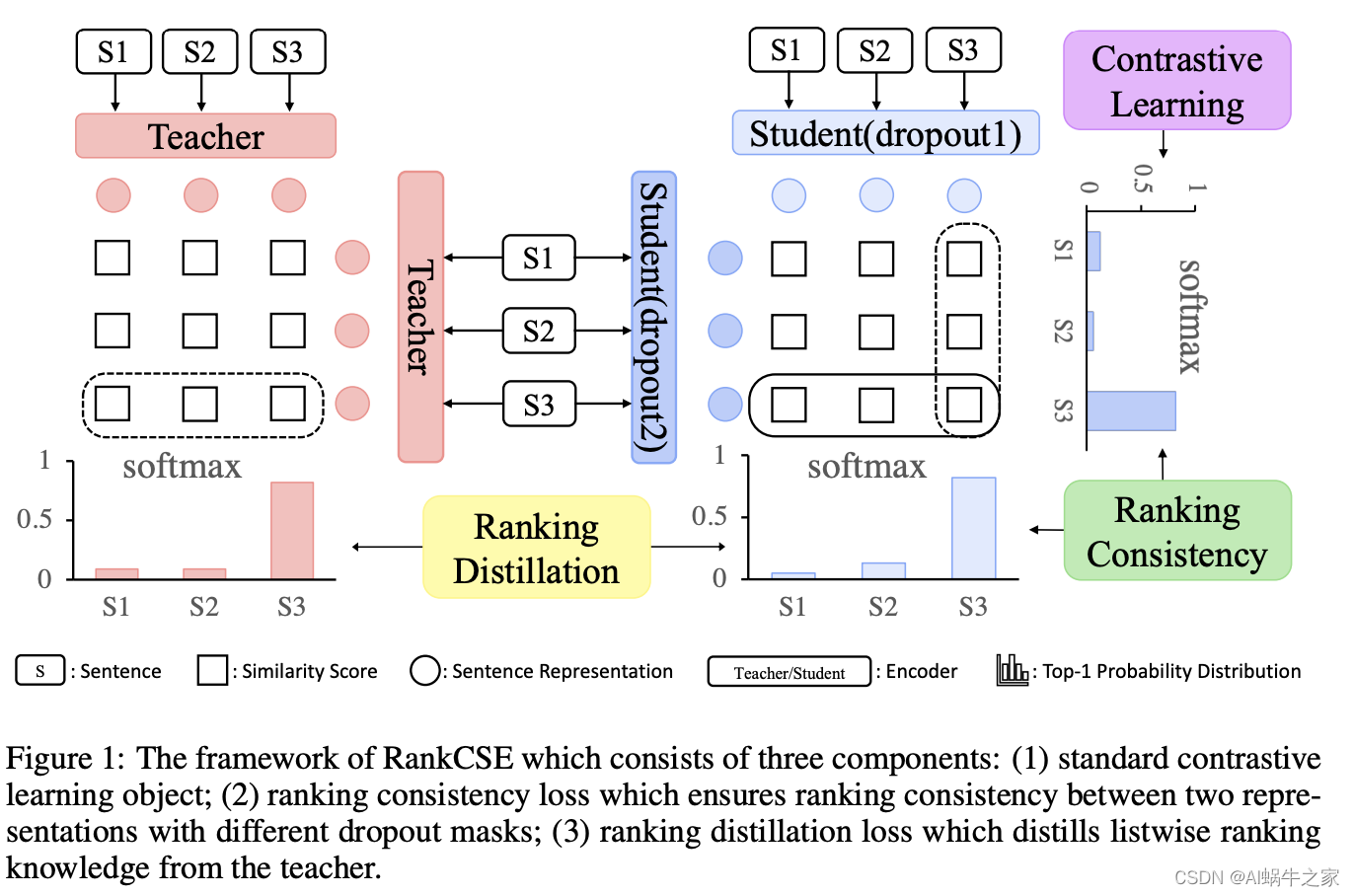
两种排序:保证两次 dropout 排序的一致性;用教师模型将样本间排序信息蒸馏给学生模型;
-
常规对比学习损失:
ζ i n f o N C E = − ∑ i = 1 N l o g e x p ( d ( f ( x i ) , f ( x i ) ′ ) / τ 1 ∑ j = 1 N e x p ( d ( f ( x i ) , f ( x j ) ′ ) / τ 1 ) \zeta_{infoNCE} = -\sum_{i=1}^N log\frac{exp(d(f(x_i),f(x_i)')/\tau_1}{\sum_{j=1}^N exp(d(f(x_i),f(x_j)')/\tau_1)} ζinfoNCE=−i=1∑Nlog∑j=1Nexp(d(f(xi),f(xj)′)/τ1)exp(d(f(xi),f(xi)′)/τ1 -
一致性排序: 对齐两次 forward 的 infoNCE 分母,具体而言,对于一个样本,对齐的两个排序分布为该样本第一次前向传播的 emb 和所有 inbatch 样本第二次前向传播的 emb 计算的排序分布和反转后的排序分布。将这两个分布计算 JS 散度。
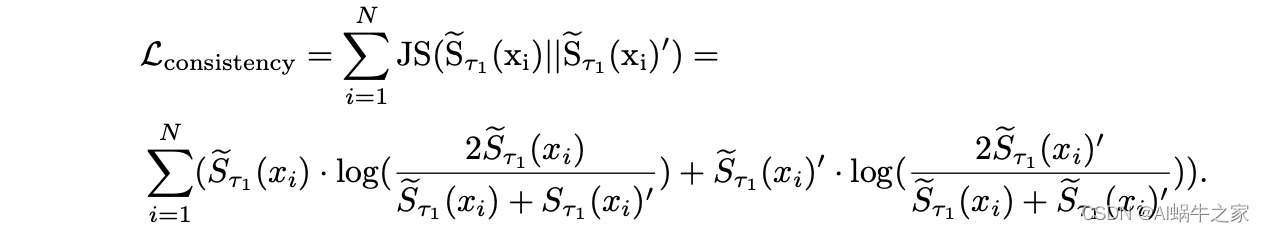
-
教师排序蒸馏: 使用训练好的 simcse 作为教师,得到每个样本第一次前向传播的 emb 和所有 inbatch 样本第二次前向传播的 emb 计算的排序分布作为软标签,使用 list-wise 的方法蒸馏。 注意由于锚点和正样本分数太高,丢弃这部分分数。 蒸馏时,使用两个教师模型的标签按照权重混合。排序的loss可以表示如下:
ζ r a n k = ∑ i = 1 N r a n k ( S ( x i ) , S T ( x i ) ) \zeta_{rank} = \sum_{i=1}^Nrank(S(x_i),S^T(x_i)) ζrank=i=1∑Nrank(S(xi),ST(xi))
其中,N表示的是batch内的样本数,注意不是某个query对应的doc数量
具体的,蒸馏损失可以使用 ListNet 或者 ListMLE:- 其中ListNet用的是Top1的简化版本 :
ζ L i s t N e t = − ∑ i = 1 N s o f t m a x ( S T ( x i ) / τ 3 ∗ l o g ( s o f t m a x ( S ( x i ) / τ 2 ) ) \zeta_{ListNet} = - \sum_{i=1}^Nsoftmax(S^T(x_i)/\tau_3 * log(softmax(S(x_i)/\tau_2)) ζListNet=−i=1∑Nsoftmax(ST(xi)/τ3∗log(softmax(S(xi)/τ2)) - ListMLE直接根据groundtruth的顺序最大化最大似然估计,所以只是用到了teacher模型打分之后得出来的排名,没有直接用模型打分。
ζ L i s t M L E = − ∑ i = 1 N l o g ( π i T ∣ S ( x i ) , τ 2 ) ) \zeta_{ListMLE} = -\sum_{i=1}^N log(\pi_i^T|S(x_i),\tau_2)) ζListMLE=−i=1∑Nlog(πiT∣S(xi),τ2))
π i T \pi_i^T πiT表示老师模型的排序情况,具体详见下面定义部分。另外注意这里模型预测分数并没有softmax做归一化。
其中,部分定义如下:

- 其中ListNet用的是Top1的简化版本 :
最终的损失为 :
ζ f i n a l = ζ i n f o N C E + β ζ c o n s i s t e n c y + γ ζ r a n k \zeta_{final} = \zeta_{infoNCE}+\beta\zeta_{consistency}+\gamma\zeta_{rank} ζfinal=ζinfoNCE+βζconsistency+γζrank
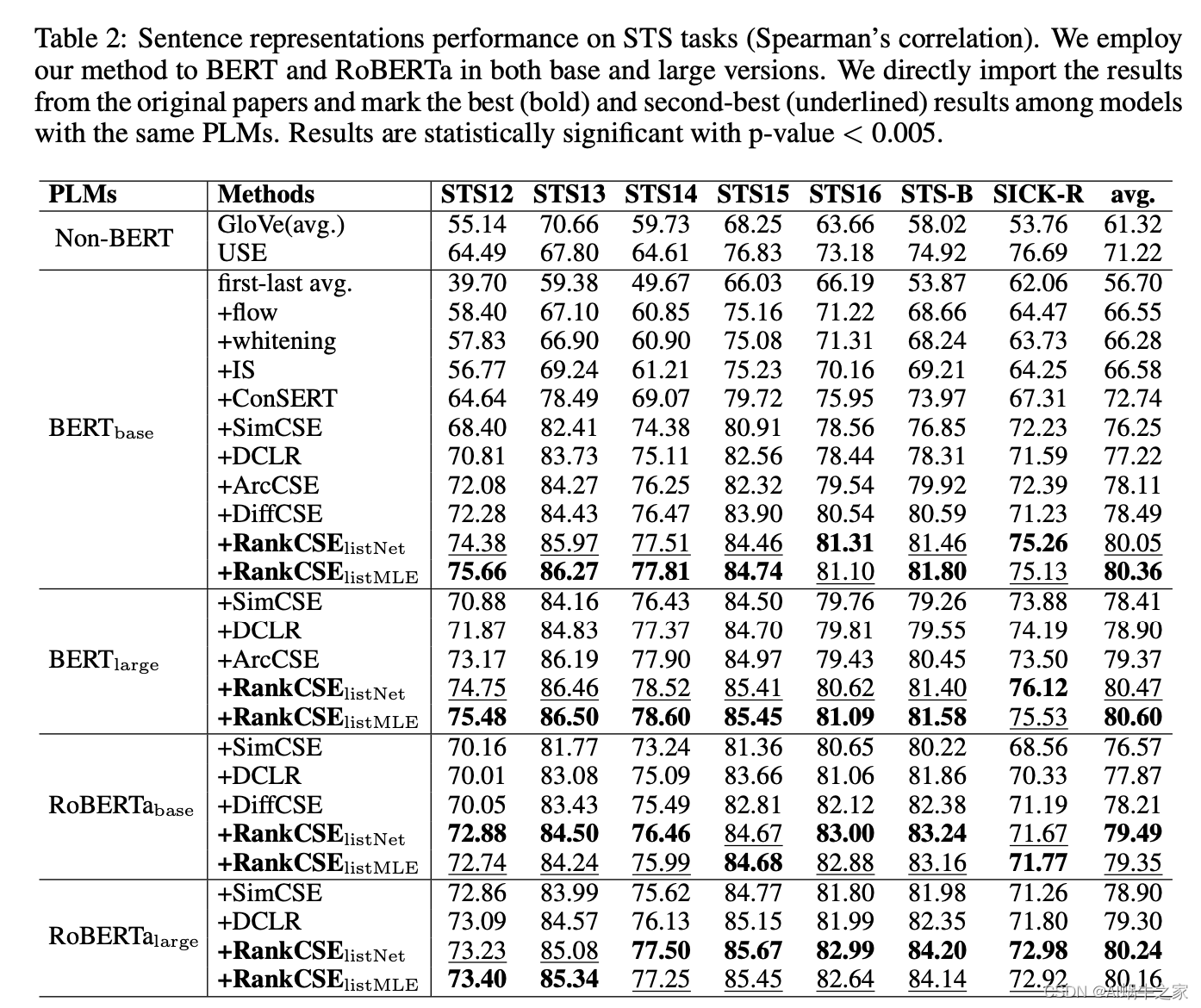
最终结果
2.有监督双塔
2.1.Augmented SBERT
采用cross-encoder弱标注所有可能的句子对组合会导致巨大的开销,甚至可能导致模型表现力下降。所以我们需要合适的采样策略,减少弱标注的句子对,提升模型表现力。
(1) Random Sampling (RS)
(2) Kernel Density Estimation (KDE):目的是保证silver 数据和gold数据的分布保持一致。为此,我们弱标注大量随机的句子对后,但只保留一定的组合。如对于分类任务,只保留positive的句子对;对于回归任务,使用 kernel density estimation (KDE)来估计连续的对于分数s的密度函数Fgold(s) and Fsilver(s)。
不过,KDE采样策略计算效率不好,需要大量随机的采样。我们后面没有采用该方法。
(3) BM25 Sampling (BM25):采用Okapi BM25算法。我们利用ElasticSearch。对每个句子提取最相似的k个句子。然后这些句子对使用cross-encoder弱标注,并都被当做silver数据使用。该方法运行效率很高。本文推荐此方法。
(4) Semantic Search Sampling (SS):BM25的一个缺点是只能找到词汇重叠的句子,所以同义词,其没有或者只有很少重叠的句子不会被选择。该方法,我们使用cosine-similarity选择最相似的k个语句。也可以采用Faiss。
(5) BM25 + Semantic Search Sampling (BM25- S.S.)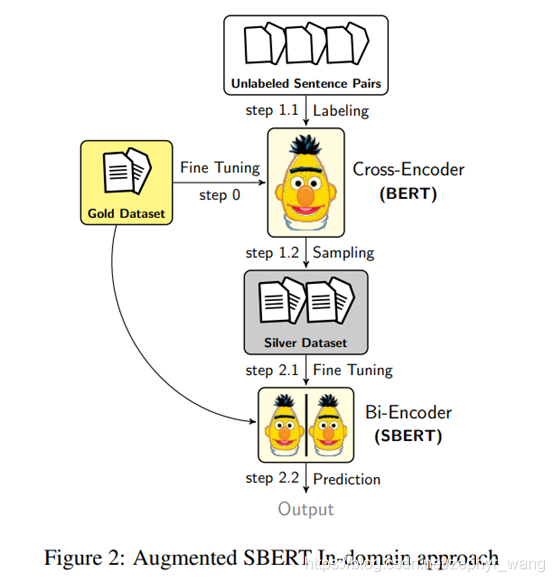
https://blog.csdn.net/zephyr_wang/article/details/119581505
3.有监督单塔
3.1.DABERT: Dual Attention Enhanced BERT for Semantic Matching
这里用了一个减的操作,跟以前feature融合不同的是,这个是两两向量相减之后,最终结果向量再sum表征差异,多少有点奇怪,但是从paper结果上看有效,paper没有代码
关于特征融合部分,有点意思,看起来像是多模态里面的双线性特征融合。细节没太看懂。。。
3. 数据噪声
2.1.Label Denoise论文总结——Co-training系列
在标签去噪的研究中,有一类希望通过选择clean instances/clean sets去更新网络参数的方法。一般认为loss比较小的数据比较可靠,可以认为是clean sets。
参考链接:
Label Denoise论文总结——Co-training系列

开源鸿蒙跨平台开发社区汇聚开发者与厂商,共建“一次开发,多端部署”的开源生态,致力于降低跨端开发门槛,推动万物智联创新。
更多推荐

 18
18 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)