麻雀搜索算法:在多种预测任务中的神奇应用
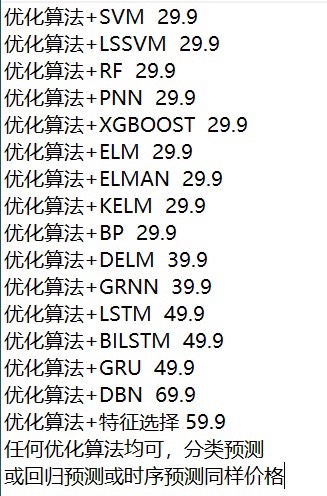
麻雀搜索算法优化用于分类 回归 时序预测 麻雀优化支持向量机SVM,最小二乘支持向量机LSSVM,随机森林RF,极限学习机ELM,核极限学习机KELM,深度极限学习机DELM,BP神经网络,长短时记忆网络 LSTM,Bilstm,GRU,深度置信网络 DBN,概率神经网络PNN,广义神经网络GRNN,Xgboost ..... 以上有分类预测回归预测时序预测 matlab代码,可直接替换数据使用,简单操作易上手。

嘿,各位数据科学和机器学习爱好者们!今天咱来聊聊麻雀搜索算法在分类、回归及时序预测中的精彩表现。
麻雀搜索算法优化与多种模型结合
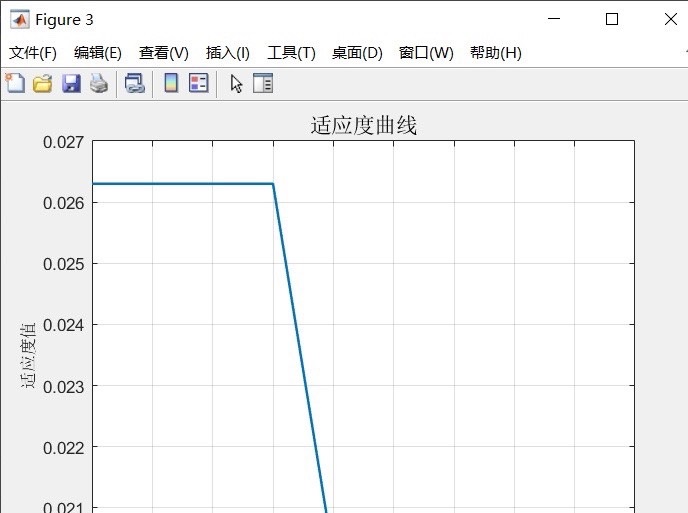
麻雀搜索算法(SSA)是一种新兴的群体智能优化算法,灵感来源于麻雀觅食和反捕食行为。它在优化机器学习模型上有着独特的优势。咱们看看它是怎么和各种预测模型合作的。
与支持向量机(SVM)结合
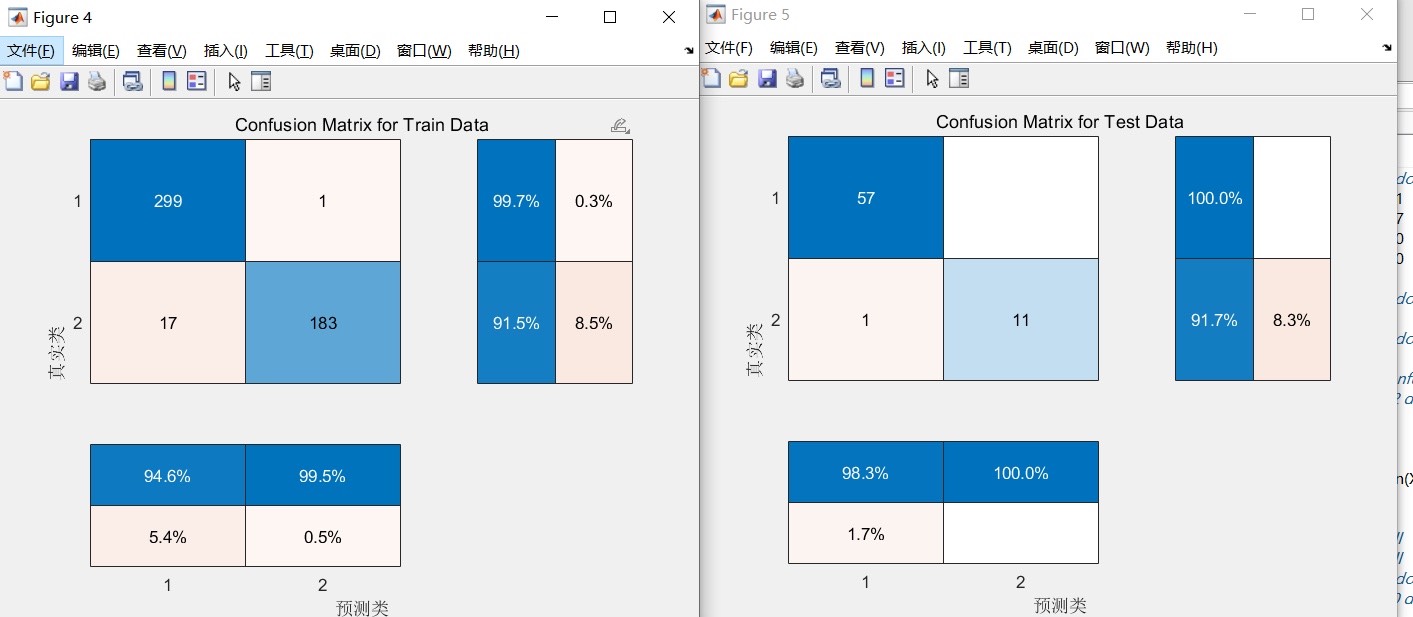
支持向量机(SVM)是一种经典的分类和回归模型。而麻雀优化的支持向量机(SSA - SVM)能通过调整SVM的参数,找到最优的超平面。比如在分类任务中,我们要最大化分类间隔,麻雀搜索算法就可以帮忙找到最合适的惩罚因子C和核函数参数gamma。

麻雀搜索算法优化用于分类 回归 时序预测 麻雀优化支持向量机SVM,最小二乘支持向量机LSSVM,随机森林RF,极限学习机ELM,核极限学习机KELM,深度极限学习机DELM,BP神经网络,长短时记忆网络 LSTM,Bilstm,GRU,深度置信网络 DBN,概率神经网络PNN,广义神经网络GRNN,Xgboost ..... 以上有分类预测回归预测时序预测 matlab代码,可直接替换数据使用,简单操作易上手。
下面是一段简单的Matlab代码示例(假设已经加载数据data和标签label):
% 划分训练集和测试集
cv = cvpartition(label,'HoldOut',0.3);
idxTrain = training(cv);
idxTest = test(cv);
trainData = data(idxTrain,:);
trainLabel = label(idxTrain);
testData = data(idxTest,:);
testLabel = label(idxTest);
% 定义SVM模型参数范围
c_range = logspace(-2, 2, 5);
g_range = logspace(-2, 2, 5);
param_grid = combvec(c_range, g_range);
% 利用麻雀搜索算法优化SVM参数
[best_c, best_g] = ssa_svm_param_selection(trainData, trainLabel, param_grid);
% 构建并训练优化后的SVM模型
model = fitcsvm(trainData, trainLabel, 'KernelFunction', 'rbf', 'BoxConstraint', best_c, 'KernelScale', best_g);
% 预测
predLabel = predict(model, testData);
accuracy = sum(predLabel == testLabel) / numel(testLabel);
disp(['测试集准确率:', num2str(accuracy)]);在这段代码里,我们先划分了数据集,然后定义了SVM参数的范围。接着通过自定义的ssasvmparam_selection函数(这里未详细展开麻雀搜索算法实现部分)来寻找最优参数,最后构建并评估模型。
与最小二乘支持向量机(LSSVM)结合
最小二乘支持向量机(LSSVM)相比传统SVM,把不等式约束转化为等式约束,求解更高效。麻雀搜索算法可以优化LSSVM的正则化参数γ和核函数参数σ。
与其他模型结合
- 随机森林(RF):麻雀搜索算法能优化随机森林中树的数量、特征选择数量等参数,提升模型的泛化能力和预测精度。
- 极限学习机(ELM)及其变种:像核极限学习机(KELM)、深度极限学习机(DELM),通过麻雀搜索算法优化输入权重和隐含层偏置等,让模型更快收敛到更好的解。
- 神经网络家族:对于BP神经网络、长短时记忆网络(LSTM、BiLSTM)、门控循环单元(GRU)、深度置信网络(DBN)、概率神经网络(PNN)、广义神经网络(GRNN)以及Xgboost,麻雀搜索算法都能在参数调优上发挥作用。比如在LSTM中,调整学习率、隐藏层神经元数量等参数,找到最佳的网络结构。
实际操作便利性
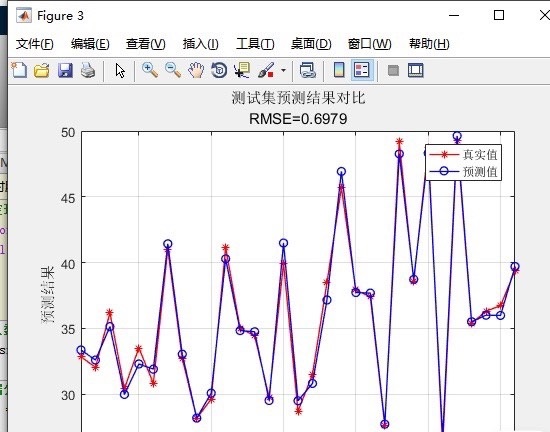
这些Matlab代码最大的优点就是简单操作易上手。只需要把自己的数据按照格式替换进去,就能运行。无论是分类预测、回归预测还是时序预测任务,都能适用。比如在时序预测中,把时间序列数据整理好,按照训练集和测试集的划分方式替换到代码对应位置,就能借助麻雀优化的模型进行预测了。
总之,麻雀搜索算法为多种预测模型带来了新的活力,让我们在处理分类、回归和时序预测任务时,有了更强大的工具。各位不妨亲自试试,感受它的魅力!


开源鸿蒙跨平台开发社区汇聚开发者与厂商,共建“一次开发,多端部署”的开源生态,致力于降低跨端开发门槛,推动万物智联创新。
更多推荐


 6
6 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)