GWO-GRNN 广义神经网络 灰狼优化算法 WOA-GRNN PSO-GRNN 回归预测
GWO-GRNN 广义神经网络 灰狼优化算法 WOA-GRNN PSO-GRNN 回归预测 基于鲸鱼算法优化的广义神经网络(GRNN)预测 基于麻雀算法优化的广义神经网络(GRNN)预测 更多优化算法可加好友 Matlab 代码注释详细,可正常运行。
搞预测模型的老司机们应该都懂,调参数这事儿有多玄学。特别是像GRNN(广义回归神经网络)这种对平滑因子极其敏感的主儿,手动调参分分钟让人崩溃。不过这两年有个新玩法挺有意思——拿优化算法自动调教GRNN的超参数,今天咱们就扒一扒这个套路。
先看GRNN的结构,它的核心就藏在隐含层的平滑因子σ里。这个σ值要是选不好,预测结果可能比股市还刺激。传统网格搜索太费时间,这时候进化算法就派上用场了。比如用灰狼优化(GWO)来找最优σ值,这货模仿狼群捕猎的等级制度和包围策略,在参数空间里嗅探最佳位置。

来个Matlab代码片段感受下:
% 灰狼参数初始化
alpha_pos = zeros(1, dim);
beta_pos = zeros(1, dim);
delta_pos = zeros(1, dim);
for t=1:Max_iter
a = 2 - t*(2/Max_iter); % 收敛因子递减
for i=1:SearchAgents_no
% 计算适应度(预测误差)
fitness = fitness_function(positions(i,:), train_data, test_data);
% 更新alpha、beta、delta狼位置
if fitness < alpha_score
alpha_score = fitness;
alpha_pos = positions(i,:);
elseif fitness > alpha_score && fitness < beta_score
beta_score = fitness;
beta_pos = positions(i,:);
elseif fitness > alpha_score && fitness < delta_score
delta_score = fitness;
delta_pos = positions(i,:);
end
end
% 位置更新公式(核心操作)
for i=1:SearchAgents_no
r1=rand();
r2=rand();
A1=2*a*r1-a; % 探索系数
C1=2*r2; % 开发系数
D_alpha=abs(C1*alpha_pos-position(i,:));
X1=alpha_pos-A1*D_alpha;
% 类似操作更新beta和delta的位置...
position(i,:)=(X1+X2+X3)/3; % 三狼位置加权平均
end
end这段代码的关键在于动态平衡探索与开发——参数a从2线性递减到0,前期允许大范围跳跃防止陷入局部最优,后期逐渐收窄搜索范围精准打击。适应度函数里藏着GRNN的训练过程,每次用当前σ值构建网络计算预测误差。
GWO-GRNN 广义神经网络 灰狼优化算法 WOA-GRNN PSO-GRNN 回归预测 基于鲸鱼算法优化的广义神经网络(GRNN)预测 基于麻雀算法优化的广义神经网络(GRNN)预测 更多优化算法可加好友 Matlab 代码注释详细,可正常运行。
鲸鱼算法(WOA)的玩法更骚,它模仿座头鲸的螺旋泡网捕食:
% 鲸鱼位置更新核心代码
p = rand();
if p<0.5
if abs(A)<1
D = abs(C*X_rand - X(i,:));
X(i,:) = X_rand - A*D; % 收缩包围
else
X_rand = X(randi(nPop),:); % 随机选个体
D = abs(C*X_rand - X(i,:));
X(i,:) = X_rand - A*D; % 全局探索
end
else
D_leader = abs(X_best - X(i,:));
X(i,:) = D_leader*exp(b.*l).*cos(2*pi*l) + X_best; % 螺旋更新
end这里的螺旋方程让参数在最优解周围做螺旋运动,特别适合GRNN这种可能存在多个局部最优的情况。b控制螺旋形状,l是[-1,1]的随机数,这种机制比单纯的直线搜索更容易绕过障碍。

至于粒子群(PSO),它的社会行为特性在参数优化中表现稳定:
% PSO速度更新
v = w*v + c1*rand().*(pbest_pos - pos) + c2*rand().*(gbest_pos - pos);
pos = pos + v;
% 惯性权重动态调整
w = w_max - (w_max-w_min)*iter/Max_iter; 惯性权重w从0.9线性降到0.4,前期保持高速探索,后期低速精细搜索。粒子不仅追随全局最优,还保留自身历史最优经验,这种记忆特性对GRNN的参数空间地形适应性强。
实际跑代码时要注意数据预处理——建议把输入输出归一化到[-1,1]区间,否则不同量纲的特征会把优化算法带沟里。另外适应度函数建议用MAE而不是MSE,因为绝对误差对异常值不敏感,优化过程更稳定。
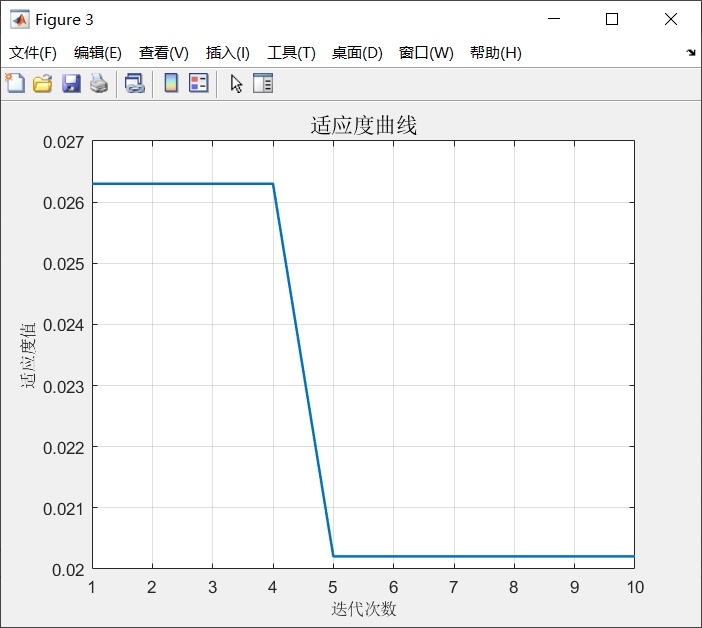
最后给个暴论:别指望某个算法通吃所有数据集。试过UCI的混凝土强度数据集,GWO-GRNN的R²能到0.92,但在股票预测里WOA反而更稳。建议在同一个数据上跑不同算法,观察收敛曲线——如果前20代就快速收敛,可能陷入局部最优;如果后期还在剧烈震荡,可能需要调整参数范围。

开源鸿蒙跨平台开发社区汇聚开发者与厂商,共建“一次开发,多端部署”的开源生态,致力于降低跨端开发门槛,推动万物智联创新。
更多推荐



 3
3 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)