【经典】Between MDPs and semi-MDPs: A framework for temporal abstraction in reinforcement learning
本文提出了一种在强化学习中实现时间抽象的方法,通过引入"选项"(Options)概念来扩展马尔可夫决策过程(MDP)框架。选项是包含策略、终止条件和启动集的三要素封装,能够表示持续一段时间的行动序列。研究发现,定义在MDP上的选项集合构成半马尔科夫决策过程(SMDP),但最有趣的问题在于底层MDP与SMDP的交互。论文展示了三个关键应用:通过中断选项改进规划效果,开发从执行片段
Between MDPs and semi-MDPs:A framework for temporal abstraction in reinforcement learning

文章目录
摘要
学习、规划和在多个时间抽象层次上表示知识是AI的关键、长期挑战。
在这篇论文中,我们考虑如何在**强化学习和马尔可夫决策过程(MDPs)**的数学框架内解决这些挑战。
我们在这一框架中扩展了通常的动作概念,以包括选项(option)——用于在一段时间内采取行动的封闭循环策略。选项的例子包括拿起一个物体、去吃午饭和前往遥远的城市,以及诸如肌肉抽搐和关节扭矩等基本动作。总体而言,我们展示了选项使时间抽象的知识和动作能够以自然且通用的方式包含在强化学习框架中。特别是,我们展示了选项可以与规划方法中的原语动作以及学习方法中的Q-学习等可互换使用。形式上,在MDP上定义的一组选项构成一个半马尔可夫决策过程(SMDP),而SMDP理论为选项理论提供了基础。然而,最有趣的问题涉及底层MDP和SMDP之间的相互作用,因此超出了SMDP理论的范围。我们展示了三种情况下的结果:
(1)我们证明了在执行过程中可以使用带有选项的规划结果来中断选项,从而比计划得更好,
(2)我们引入了一种新的选项内方法,该方法能够从其执行片段中学习关于一个选项的信息,以及
(3)我们提出了一个子目标的概念,可以用来改进选项本身。
所有这些结果在现有文献中都有先例;本文的贡献在于在一个更简单、更通用的设置中建立它们,同时对现有的强化学习框架进行较少的更改。特别是,我们展示了这些结果可以在不承诺(或排除)任何特定的状态抽象、层次结构、函数逼近或宏观效用问题的方法的情况下获得。
从MDP到SMDP:时间抽象的框架
- 核心挑战: 如何在强化学习中处理多时间尺度的决策和行动?
- 传统MDP局限: 仅关注单步动作,无法有效利用高层抽象知识。(MDP的基本单元是单步动作)
- 本文贡献: 提出"选项"(Options)概念,扩展MDP框架,实现时间抽象。(选项,允许把一系列动作打包成一个动作,从而在MDP框架上实现时间上的抽象)
- 关键思想: 选项是持续一段时间的闭环策略,可与原始动作互换使用。
一、MDP的基础
强化学习 (MDP) 框架
-
核心要素: 状态 (State)、动作 (Action)、奖励 (Reward)、转移概率 (Transition Probability)。
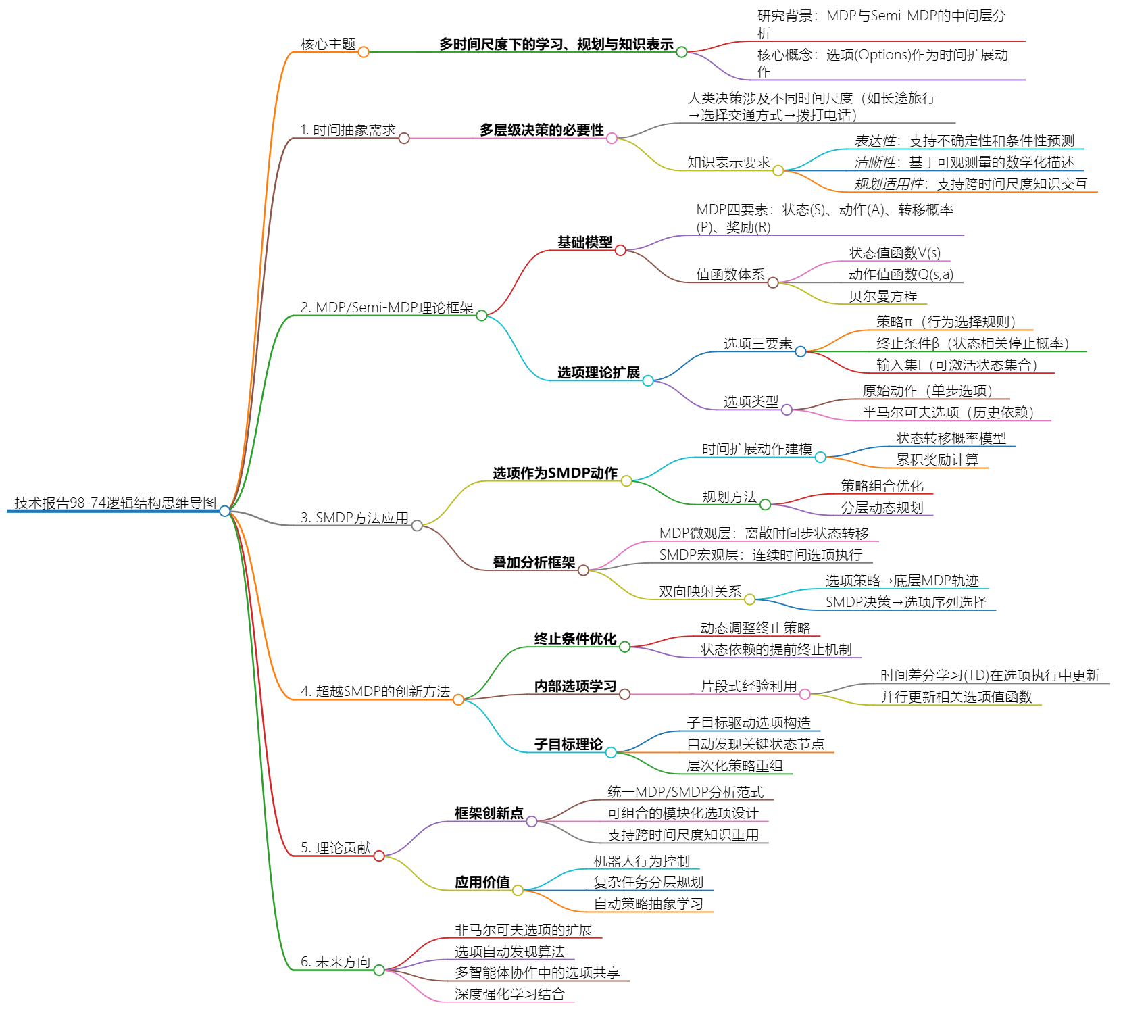
即使奖励:
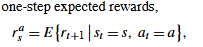
-
目标: 学习最优策略,最大化累积折扣奖励。
-
价值函数 (Value Function): 衡量状态或状态-动作对的价值。
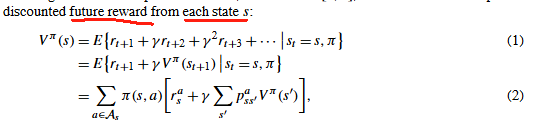
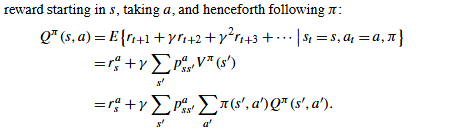
-
贝尔曼方程 (Bellman Equation): 价值函数的递归关系,用于规划和学习。
-
局限性: 仅适用于单步动作,难以处理复杂、长期任务。
标准的MDP模型,其动作都是瞬时的,一步到位,这在处理像导航、执行复杂任务这类要持续行动的场景时,效率就可能不高
二、 选项option
2 1. 定义
三要素:
- 策略 (Policy, π): 在特定状态下执行的一系列动作。S×A→[0,1]
- 终止条件 (Termination Condition, β): 决定选项何时结束。(比如到达某个目标点或者经过一段时间)S+→[0,1]
- 启动集 (Initiation Set, I): 选项可用的状态集合。I⊆S
本质:一个可执行的、有明确开始和结束的"宏动作"。
栗子:
- “拿起物体”:包含移动物体、抓取物体、确认主权成果的策略,以及当物体拿起或者发生意外的时的终止条件。此外,机器人看见物体且手是空闲的状态下才能启动。
- “去午餐”,“到达城市”
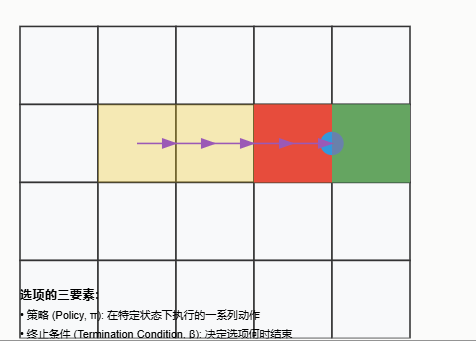
2.2 选项的执行
- An option 〈I, π, β〉 is available in state st if and only if st ∈ I. If the option is taken, then actions are selected according to π until the option terminates stochastically according to β. (如果状态st属于选项〈I,π,β〉,则该选项在该状态下可用;如果选择了该选项,则根据π选择动作,直到根据β随机终止)
- 根据概率分布 π ( s t , ⋅ ) π(s_t,·) π(st,⋅)选择下一个动作 a t a_t at。然后环境转移到状态 s t + 1 s_{t+1} st+1,其中选项要么以概率 β ( s t + 1 ) β(s_{t+1}) β(st+1)终止,要么继续,根据 π ( s t + 1 , ⋅ ) π(s_{t+1},·) π(st+1,⋅)确定 a ( t + 1 ) a(t+1) a(t+1),可能在 s t + 2 s_{t+2} st+2中根据 β ( s t + 2 ) β(s_{t+2}) β(st+2)终止,依此类推。
- 当选项终止时,代理有机会选择另一个选项。
2.3 选项的执行范围
选项的启动集和终止条件共同限制了其应用范围,以一种可能有用的方式。特别是,它们限定了需要定义该选项策略的范围
这个意思是?:根据当前的状态,随机选择一个动作,该动作隶属于某个选项,然后以该选项的终止条件为依据,继续选择选项中的动作与环境交互,直到选项结束。然后选择另一个选项!(猜测的不一定准)
在半马尔可夫选项中,策略和终止条件是可能历史的函数,即它们是π:Ω×A→[0,1]和β:Ω→[0,1]
启动
自然假设所有选项可能继续的状态也是选项可能被采取的状态(即,{s: β(s) < 1} ⊆ I)
猜测:所以选项的策略就是对于不同的选项启动的条件不一样?
终止
有时,选项“超时”是有用的,即使它们未能达到任何特定状态,在经过一段时间后也会终止。
过程
一般来说,一个选项在某个时间点t启动,确定了为数步k所选择的动作,然后终止于 s t + k s_{t +k} st+k。在每个中间时间 τ , t ≤ τ < t + k \tau,t \leq τ<t+k τ,t≤τ<t+k,马尔可夫选项的决策可能仅取决于 s τ s_{\tau} sτ,而半马尔可夫选项的决策可能取决于整个先前序列 s t , a t r t + 1 , s t + 1 , a t + 1 , . . . , r τ , s τ s_t,a_tr_{t+1},s_{t+1},a_{t+1},...,r_τ,s_τ st,atrt+1,st+1,at+1,...,rτ,sτ,但不取决于 s t s_t st之前的事件(或之后的 s τ s_τ sτ)。
我们称这个序列为从t到 τ τ τ的历史,并用 h t τ h_{tτ} htτ表示它。
即:半MDP的单步是MDP。
2.4 选项的类型
选项根据其决策机制,可以分为两种主要类型:马尔可夫选项和半马尔可夫选项。
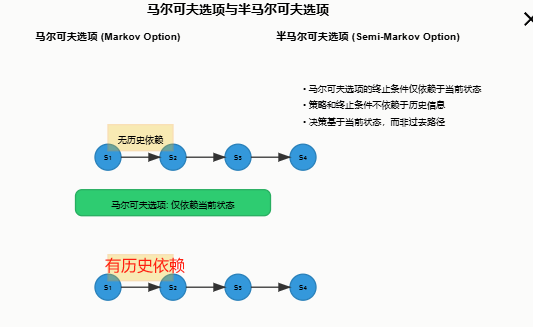
- 马尔可夫选项 (Markov Option)
- 终止条件仅依赖于当前状态
- 策略和终止条件不依赖于历史信息。
- 半马尔可夫选项 (Semi-Markov Option)
- 终止条件和策略可以依赖于历史信息。
- 更灵活,能处理更复杂的场景,如超时终止。
✋统一性: 原始动作可以视为单步选项。
动作a对应于当a可用时可用的选项( I = s : a ∈ A s I = {s: a ∈ A_s} I=s:a∈As),该选项总是持续直到步骤( β ( s ) = 1 , ∀ s ∈ S β(s) = 1, ∀s ∈ S β(s)=1,∀s∈S),并且在所有地方都选择a( π ( s , a ) = 1 , ∀ s ∈ I π(s, a) = 1, ∀s ∈ I π(s,a)=1,∀s∈I).因此,我们可以认为代理在每个时间点的选择完全是选项中的一个,其中一些选项仅持续一个时间步长,而其他选项则具有时间扩展。前者我们称为单步或原始选项,后者称为多步选项。
我们令 O = ∪ s ∈ S O s \mathscr{O}=\cup _{s\in S} \mathscr{O}_s O=∪s∈SOs表示可用的选项集合。
❓选项如何设置呢?
我们对选项的定义旨在使它们尽可能像动作,同时增加它们在时间上扩展的可能性。
由于选项以明确的方式终止,我们可以以与考虑动作序列非常相似的方式考虑它们的序列。
我们还可以考虑选择选项而不是动作的策略,并且可以像模拟动作结果一样模拟选择选项的后果。
2.5 选项的扩展
给定任意两个选项a和b,我们可以考虑按顺序执行它们,即可以先执行a直到它终止,然后执行b直到它终止(如果a在b的启动集之外终止,则省略b)。两个选项组合成一个新的选项,记为ab,对应于这种行为方式。
两个马尔可夫选项的组合通常将是半马尔可夫的,而不是马尔可夫的,因为第一个选项终止前后的动作选择不同。
两个半马尔可夫期权的组合总是另一个半马尔可夫期权。
因为动作是选项的特殊情况,我们也可以将它们组合起来产生一个确定的动作序列,换句话说,是一个经典的宏操作符。
2.6 选项上的策略
当在状态 s t s_t st启动时,选项上的马尔可夫策略 µ : S × O → [ 0 , 1 ] µ: S × O → [0, 1] µ:S×O→[0,1]根据概率分布 µ ( s t , ⋅ ) µ(s_t, ·) µ(st,⋅)选择一个选项 o ∈ O s t o ∈ O_{s_t} o∈Ost。 o o o是基于 s t s_t st的选项,确定动作,一直到状态 s t + k s_{t+k} st+k终止。在此时间点根据 µ ( s t + k , ⋅ ) µ(s_{t +k}, ·) µ(st+k,⋅)选择新的选项,并如此继续。这样,选项上的策略µ决定了常规的动作策略,或称为平滑策略(flat policy) π = f l a t ( µ ) π = flat(µ) π=flat(µ)。
平滑策略在状态 s τ s_τ sτ 时选择的动作不仅取决于 s τ s_τ sτ,还取决于当时正在跟踪的选项,并且这随机地取决于自策略启动以来的整个历史 h t τ h_{t τ} htτ.
2.7 选项的使用-python
设计有一个5*5的gridwold ,在(0,0) ,(1,4), (2,3),(4,3) 处有3,-2,3,-4的请求。(即3拿走3个物品,-2放下2个物品)。基础动作有上,下,左,右,拾取1个,放下1个。 我们如何设置一些选项(启动集合,策略,终止条件)。 我们的最终目的是(0,0) ,(1,4), (2,3),(4,3) 的状态为0.
- 选项1:
- 启动条件为:位置约束为(0,0)和(2,3) ,数量约束为>0.
- 策略:0.6的概率为拾取,位移动作上下左右的概率分别为0.1 。
- 终止策略: 位置变化 或者 数量为0, 或者执行了3步。
- 选项2:
- 启动条件为:位置约束为(1,4)和(4,3) ,数量约束为<0.
- 策略:0.6的概率为拾取,位移动作上下左右的概率分别为0.1 。
- 终止策略: 位置变化 或者 数量为0 ,或者执行了3步。
- 选项3:
- 启动条件:任意位置
- 策略:位移动作上下左右的概率均等,没有拾取和放下动作。
- 终止条件:当前位置状态改变。
定义选项
import numpy as np
class Option:
def __init__(self, name, initiation_set, policy, termination_condition):
self.name = name
self.initiation_set = initiation_set
self.policy = policy
self.termination_condition = termination_condition
self.step_count = 0 # 用于记录执行的步数
def reset_step_count(self):
self.step_count = 0
def can_initiate(self, state, items):
return self.initiation_set(state, items)
def choose_action(self, state, items):
return self.policy(state, items)
def is_terminated(self, state, items, prev_state):
self.step_count += 1
return self.termination_condition(state, items, prev_state, self.step_count)
# 定义启动集合函数
def initiation_set_option1(state, items):
return state in [(0, 0), (2, 3)] and items[state] > 0
def initiation_set_option2(state, items):
return state in [(1, 4), (4, 3)] and items[state] < 0
def initiation_set_option3(state, items):
return True # 任意位置都可以启动
# 定义策略函数
def policy_option1(state, items):
actions = ["pick", "up", "down", "left", "right"]
probabilities = [0.6, 0.1, 0.1, 0.1, 0.1]
return np.random.choice(actions, p=probabilities)
def policy_option2(state, items):
actions = ["pick", "up", "down", "left", "right"]
probabilities = [0.6, 0.1, 0.1, 0.1, 0.1]
return np.random.choice(actions, p=probabilities)
def policy_option3(state, items):
actions = ["up", "down", "left", "right"]
probabilities = [0.25, 0.25, 0.25, 0.25]
return np.random.choice(actions, p=probabilities)
# 定义终止条件函数
def termination_condition_option1(state, items, prev_state, step_count):
return state != prev_state or items[state] == 0 or step_count >= 3
def termination_condition_option2(state, items, prev_state, step_count):
return state != prev_state or items[state] == 0 or step_count >= 3
def termination_condition_option3(state, items, prev_state, step_count):
return state != prev_state
# 创建选项
options = [
Option(name="Option_1", initiation_set=initiation_set_option1, policy=policy_option1, termination_condition=termination_condition_option1),
Option(name="Option_2", initiation_set=initiation_set_option2, policy=policy_option2, termination_condition=termination_condition_option2),
Option(name="Option_3", initiation_set=initiation_set_option3, policy=policy_option3, termination_condition=termination_condition_option3)
]
选项使用
# 环境模拟
def move(state, action):
x, y = state
if action == "up":
return (x, y - 1)
elif action == "down":
return (x, y + 1)
elif action == "left":
return (x - 1, y)
elif action == "right":
return (x + 1, y)
return state
# 示例运行
state = (0, 0) # 初始状态
items = {(0, 0): 3, (1, 4): -2, (2, 3): 3, (4, 3): -4} # 初始物品数量
prev_state = state
while any(items.values()):
# 选择可以启动的选项
available_options = [opt for opt in options if opt.can_initiate(state, items)]
if not available_options:
print("没有可用的选项")
break
current_option = np.random.choice(available_options) ###随机选择一个选项~~~
print(f"选择了选项:{current_option.name}")
while not current_option.is_terminated(state, items, prev_state):
action = current_option.choose_action(state, items)
print(f"当前状态:{state},选择的动作:{action}")
if action == "pick":
if items[state] > 0:
items[state] -= 1
elif items[state] < 0:
items[state] += 1
else:
prev_state = state
state = move(state, action)
print(f"新状态:{state},物品数量:{items[state]}")
print("任务完成!")
2.8. 状态价值函数 (State-Value Function)
V μ ( s ) V^μ(s) Vμ(s) - 在状态 s 下,遵循策略 μ 的期望回报。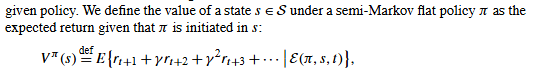
E ( π , s , t ) \mathscr{ E}(π, s, t) E(π,s,t) denotes the event of π being initiated in s at time t.
2.9 选项价值函数 (Option-Value Function)
Q μ ( s , o ) Q^μ(s,o) Qμ(s,o) - 在状态 s 下,选择选项 o 并遵循策略 μ 的期望回报。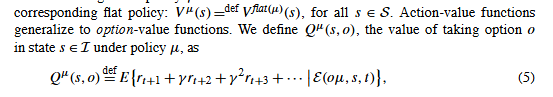
其中, o μ oμ oμ是 o o o和 μ μ μ的组合,表示半马尔可夫策略,该策略首先遵循o直到终止,然后开始根据结果状态中的μ进行选择。对于半马尔可夫期权,定义 E ( o , h , t ) E(o,h,t) E(o,h,t)是有用的,即o在时间t从h继续的事件,其中h是以 s t s_t st结束的历史。在继续时,如果历史记录在 s t s_t st之前,actions被选择。也就是说,根据 o ( h , ⋅ ) o(h,·) o(h,⋅)选择一个 a t a_t at,o在t+1处以概率为 β ( h a t r t + 1 s t + 1 ) β(ha_t r_{t+1} s_{t+1}) β(hatrt+1st+1)终止;如果o不终止,则根据 o ( h a t r t + 1 s t + 1 , ⋅ ) o(ha_t r_{t+1} s_{t+1},·) o(hatrt+1st+1,⋅)选择 a t + 1 a_{t+1} at+1,以此类推。根据这个定义,(5)也适用,其中s是历史而不是状态。
2.9贝尔曼方程的扩展
适用于选项的价值函数,形式与MDP类似。
2.10最优价值函数
三、 SMDP (option-to-option) methods
 定理: MDP + 选项 = SMDP
定理: MDP + 选项 = SMDP
- SMDP特点: 动作持续时间可变,适用于连续时间离散事件系统。
- 选项作为SMDP中的"动作": 选项本身构成了一个SMDP。
- 理论基础:SMDP理论为选项方法提供了理论支撑
3.1 奖励
使用选项进行规划需要一个关于其后果的模型。幸运的是,从现有的SMDP理论中可以知道用于选项的适当形式的模型,类似于前面定义的动作的 r s a r_s^a rsa和 p s s ′ a p^a_{ss'} pss′a。对于每个可能开始执行选项的状态,这种类型的模型预测该选项将终止的状态以及途中获得的总奖励。这些量以特定方式被折现。
对于任何选项o,设 E ( o , s , t ) E(o, s, t) E(o,s,t)表示在时间t从状态s启动o的事件。那么o对任意状态s ∈ S的奖励部分为 对于所有 s ′ ∈ S s' ∈ S s′∈S,其中 p ( s ′ , k ) p(s', k) p(s′,k) 是选项在 k 步后终止于 s’ 的概率。因此, p s s ′ o p^o_{ss'} pss′o 是 s’ 是选项终止状态的可能性与该结果相对于 γ 滞后的度量的组合。我们称这种模型为多时间模型[54,55],因为它描述了选项的结果不是在单一时间点而是可能在许多不同时间点上适当组合的情况
对于所有 s ′ ∈ S s' ∈ S s′∈S,其中 p ( s ′ , k ) p(s', k) p(s′,k) 是选项在 k 步后终止于 s’ 的概率。因此, p s s ′ o p^o_{ss'} pss′o 是 s’ 是选项终止状态的可能性与该结果相对于 γ 滞后的度量的组合。我们称这种模型为多时间模型[54,55],因为它描述了选项的结果不是在单一时间点而是可能在许多不同时间点上适当组合的情况
3.2 贝尔曼方程
状态价值函数
使用多时间模型,我们可以为一般策略和选项编写贝尔曼方程。
对于任何马尔可夫策略( Markov polic) µ µ µ,状态值函数可以写成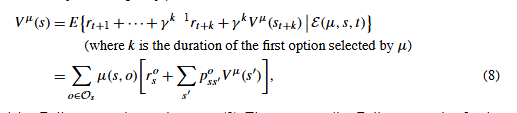 这是个贝尔曼方程,类似于公式(2).
这是个贝尔曼方程,类似于公式(2).
选项价值函数
在状态 s ∈ I s∈I s∈I中,期权o的价值对应的贝尔曼方程为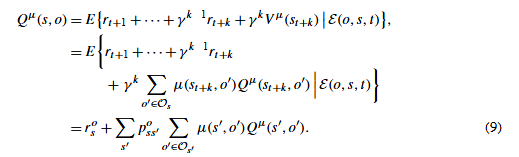
注意,所有这些方程在特殊情况下专门化为前面给出的那些,在这种情况下 µ 是常规策略,o 是常规动作。
还请注意 Q µ ( s , o ) = V o µ ( s ) Q^µ (s, o) = V^{oµ} (s) Qµ(s,o)=Voµ(s)
3.3 最优价值函数
最后,最优值函数和最优贝尔曼方程的推广适用于选项及其上的策略。当然,传统的最优价值函数 V ∗ V^∗ V∗和 Q ∗ Q^∗ Q∗不会因引入选项而受到影响;最终,使用原生动作与使用选项一样好。然而,了解在不包括所有动作的情况下,用有限的选项集可以做到多好是有趣的。
例如,在规划中,我们可能首先只考虑高级别选项以快速找到近似计划。让我们用O表示受限选项集,用 Π ( O ) Π(\mathscr{O}) Π(O)表示仅从 O \mathscr{O} O中的选项中选择的所有策略的集合。
那么给定我们只能从 O \mathscr{O} O中选择时的最优值函数是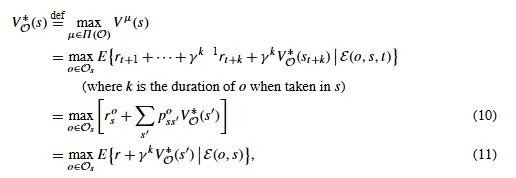 其中 E ( o , s ) E(o, s) E(o,s)表示在状态s下启动选项o。
其中 E ( o , s ) E(o, s) E(o,s)表示在状态s下启动选项o。
在此事件的条件下,通常的随机变量包括:s′是选项o终止的状态,r是途中累积的折扣奖励,k是在s和s′之间流逝的时间步数。
最优选项的价值函数和贝尔曼方程为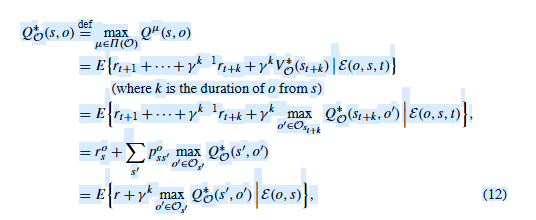
where r, k, and s ′ are again the reward, number of steps, and next state due to taking o ∈ O s o ∈ \mathscr{O}_s o∈Os .
给定一组选项, O \mathscr{O} O,相应的最优策略 optimal policy,记为 µ O ∗ µ^∗_{\mathscr{O}} µO∗ ,是实现KaTeX parse error: Expected '}', got 'EOF' at end of input: …^∗_{\mathscr{O} 的任何策略,即在所有状态 s ∈ S s ∈ S s∈S中,有KaTeX parse error: Expected '}', got 'EOF' at end of input: …\mathscr{O} (s)。如果知道 V ∗ O V^∗O V∗O 和选项的模型,则可以通过选择(10)或(11)中的最大化选项中的任意命题来形成最优策略。
或者,如果 Q O ∗ Q^∗_{\mathscr{O}} QO∗ 已知,则可以在没有模型的情况下通过在每个状态s中以任意比例选择选项 o o o(对于这些选项 Q O ∗ ( s , o ) = m a x o ′ Q O ∗ ( s , o ′ ) ) Q^∗_O (s, o) = max_{o ′} Q^∗_O (s, o ′ )) QO∗(s,o)=maxo′QO∗(s,o′))来找到最优策略。
这样,计算 V O ∗ V^∗_{ \mathscr{O} } VO∗或 Q O ∗ Q^∗_{\mathscr{O}} QO∗的近似值就成为具有选择性的规划和学习方法的关键目标。
V O ∗ ( s ) V_O^∗(s) VO∗(s) 和 Q O ∗ ( s , o ) Q_O^∗(s,o) QO∗(s,o) - 在给定选项集合 O 下,能达到的最大价值
四 、SMDP 规划方法
同步价值迭代 (SVI)M: 一种基于动态规划的规划方法。
选项-SVI: 将选项纳入SVI算法,更新状态价值函数 V O ∗ ( s ) VO∗(s) VO∗(s) 或选项价值函数 Q O ∗ ( s , o ) QO∗(s,o) QO∗(s,o)。
- 优势:
利用选项的高层抽象,加速价值函数的收敛。
由是选项本身就代表了更高级别的行为,规划过程可以从更宏观的层面进行,从而大大加速价值函数的收敛速度. - 价值实现性 (Value Achievement):
如果模型正确,规划结果能达到 V O ∗ V_{\mathscr{O}}^∗ VO∗
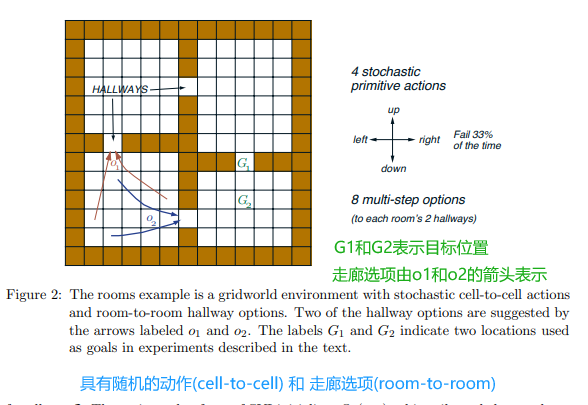
4.1 Hallways gridworld environment
1 .实验环境
-
房间与走廊结构:
实验包含四个房间,每个房间通过走廊(hallway)(如图2所示)。每个房间内有两个内置走廊选项(hallway options),用于将智能体从房间内任何状态引导至两个出口走廊之一。 -
智能体初始位置位于左上角房间的左上角单元格(upper leftcorner)
-
动作与转移: A ∪ H A \cup H A∪H:A (primitive actions) ,H(hallway options)
- 基础动作: 智能体可执行随机等概率动作(如上下左右移动),动作转移具有随机性。
- 选项(Options):每个房间内预设两个“走廊选项”(hallway options),用于从房间内任意状态转移到目标走廊。
-
观察空间:多步选项(H,A∪H)从一开始就明显优于原始动作(A)。
-
探索:通过选项减少所需的探索
2. 参数设置
- 折扣因子(γ):0.9
- 学习率(α):0.1
- 终止条件(β(s)):每个走廊选项的终止条件在目标走廊状态下为1,其他状态为0,即选项执行至目标走廊时终止。
- 奖励机制:所有状态转移的即时奖励为0,仅通过子目标值引导策略学习。 (⭐️好特殊的设计啊~)
- 子目标设定:每个走廊选项的子目标值(subgoal values)为+1(目标走廊),房间外状态(包括非目标走廊)的子目标值为0。
- 策略探索:动作选择采用随机均匀概率,即无探索策略(如 ε-greedy),完全随机执行基础动作
3. 实验步骤与策略【Q-learning】
1)选项策略(π)设计:
👉每个走廊选项的策略遵循房间内的最短路径到达目标走廊,同时最小化误入其他走廊的概率。
👉例如,一个走廊选项的策略如图3所示(原文未直接提供,但通过描述可推断为路径规划示意图)。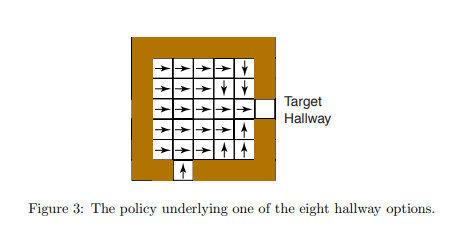
策略可视化:展示了单一走廊选项的策略 π,显示智能体在房间内沿最短路径移动,避开非目标走廊
2)学习过程:
- 通过随机行为(随机动作选择)初始化,逐步学习子目标值函数。
- 使用时序差分(TD)学习方法更新Q值,公式为:
Q t + 1 ( s , a ) = Q t ( s , a ) + α [ γ n Q t ( s ′ , a ′ ) − Q t ( s , a ) ] Q_{t+1}(s,a)=Q_t(s,a)+α[γ^nQ_t(s′,a′)−Q_t(s,a)] Qt+1(s,a)=Qt(s,a)+α[γnQt(s′,a′)−Qt(s,a)]
其中,n为选项执行的步数[13]。 - 允许在选项执行中中断选项(interrupting options),即不强制执行至终止,以测试时间抽象的灵活性。结论:选项的中断机制(interruptibility)显著提升策略灵活性,避免因强制执行完整选项导致的低效
3)迭代优化:
👉图5展示了在不同迭代阶段(Iteration #1至#5)中,子目标值的收敛过程。初始值误差较大,但随时间步数增加逐渐接近真实值。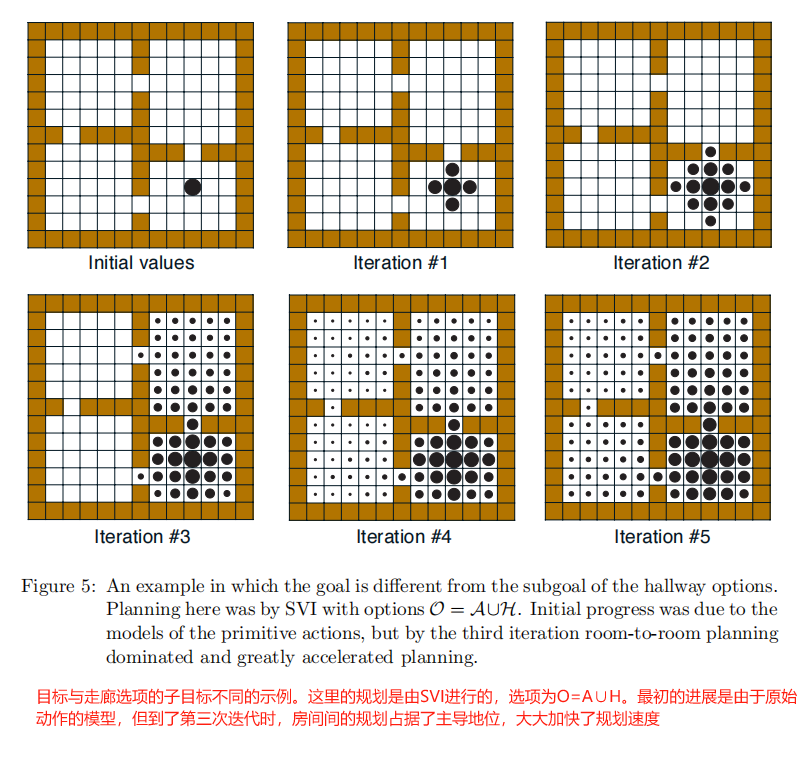
4) 评估指标
- 计算均方根误差(RMS Error):对比学习值 Q_g(s, a)与真实值 Q_g*(s, a)的差异,评估收敛性
- 跟踪不同任务(如上下走廊任务)中目标状态 G 的值函数变化,验证跨任务泛化能力
4.实验数据
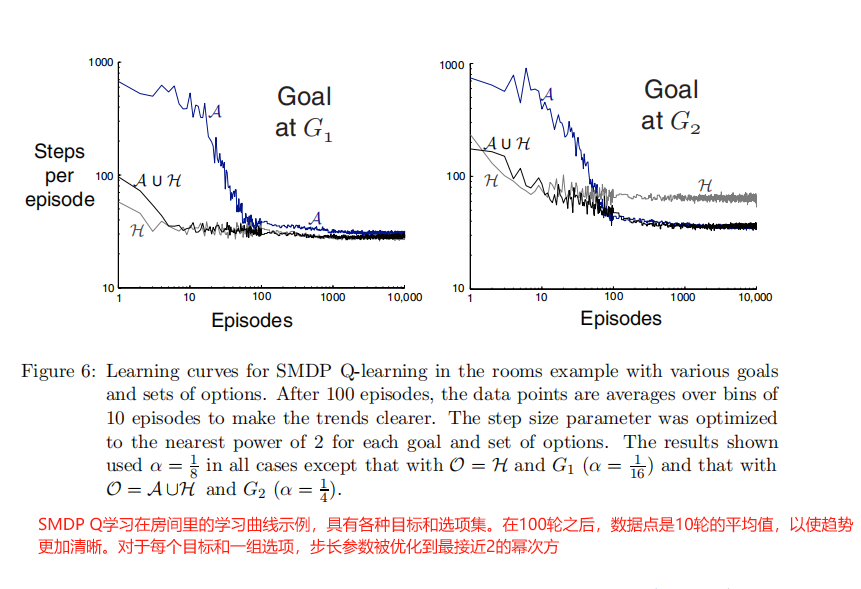
图解释:有左右两个图(任务目标分别为G1和G2),每个图各3条曲线(其动作空间分别为:A ,H , A ∪ H A \cup H A∪H).在总体趋势中,即前100轮次的时候,H和 A ∪ H A \cup H A∪H的方法都比原始动作 A A A更快的达到目标,甚至在第一次尝试的时候就表现的更好。
- G1目标:选项在整个过程中都比Q学习保持优势。减少勘探可能会有所贡献。
- G2目标:类似的趋势,但仅走廊(H)方法长期表现较差。
- 原因:最佳路径需要混合原始操作(例如,走廊选项有时会偶然发现G2)。
- 组合组(A∪H):由于同样的原因,相对于A的优势降低。
5 中断选项(Interrupting options)
-
SMDP的局限性:
把选项看作黑盒子,一旦选中就必须执行到底。这其实有点浪费。如果我们能深入到选项内部,或者调整它们的结构,是不是能获得更强大的能力呢?这就引出了关键思想:我们需要在MDP和SMDP之间灵活切换。
-
Potential: 通过查看内部选项或改变其内部结构来获得更多权力。
-
key insight:同时在MDP和SMDP中工作至关重要。
🔍使用SMDP框架分析选项。
🔧根据MDP解释修改它们。
🚀生成一个新的、可能更好的SMDP我们可以用SMDP的视角来分析选项,然后利用他们的MDP的解释来修改它们,从而产生一个新的、可能更优的SMDP。
why 需要中断?
中断的核心思想 :在选项自然终止之前中断它们。
想象一下,你正在开车,导航告诉你走这条路到目的地,但开到一半发现前面堵车了,或者有更快捷的路线. 你会怎么做?你会继续傻乎乎地按原计划走,还是果断掉头? 显然,后者更明智。类似地,当我们执行一个选项 o o o时,如果中途发现继续执行下去不如立刻切换到另一个选项 q q q更有价值, 那我们为什么不中断呢?

How 中断?
📝 Formalization :定义一个新的策略 μ ′ \mu' μ′,是基于原来的策略 μ \mu μ,且针对的是新的选项集 O ′ \mathscr{O'} O′
🔄 Mapping: 每一个选项 o ∈ o o \in \mathscr{o} o∈o,对应生成一个新选项 o ′ ∈ O ′ o' \in \mathscr{O'} o′∈O′
📋 Policy:这个新策略在每个状态s对选项的选择概率与原策略相同。
🛑 Termination Condition Change:关键在于修改了选项的终止条件 β ′ \beta' β′
β ′ ( h ) = β ( h ) , u n l e s s Q μ ( h , o ) < V μ ( s ) , t h e n β ( h ) = 1 \beta'(h) =\beta(h) ,unless \ Q^{\mu}(h,o) <V^{\mu}(s) ,then \ \beta(h)=1 β′(h)=β(h),unless Qμ(h,o)<Vμ(s),then β(h)=1
✅ Result:终止选项 o o o.
解析:历史时间h,当前状态为s ,要判断是否提前在h的位置终止
在策略 μ \mu μ下,在历史h的时候,继续执行选项 o o o,其价值 Q μ ( h , o ) Q^{\mu}(h,o) Qμ(h,o)小于当前状态下根据策略 μ \mu μ选择所有选项的最大价值 V μ ( s ) V^{\mu}(s) Vμ(s) ,那么就提前终止选项 o o o.
Theo 2中断保证
为什么中断策略有用,theo2 可以保证。
定理2:对于任意一个马尔可夫决策过程(MDP),任意一组选项(options) O \mathscr{O} O,以及任意一个马尔可夫策略 μ : S × O → [ 0 , 1 ] \mu:S \times \mathscr{O} \to [0,1] μ:S×O→[0,1],我们定义一个新的选项集合 O ′ \mathscr{O'} O′ ,使得每个旧选项 o = < I , π , β > ∈ O o=<I,\pi, \beta> \in \mathscr{O} o=<I,π,β>∈O 对应一个新的选项 o ′ = < I , π , β ′ > ∈ O ′ o'=<I,\pi,\beta'> \in \mathscr{O'} o′=<I,π,β′>∈O′ 。其中, β ′ \beta' β′ 是 β \beta β 的修改版本,具体规则是:
- 如果某个历史 h h h 结束于状态 s s s,并且在该历史中执行选项 o o o 时的选项价值函数 Q μ ( h , o ) Q^{\mu}(h,o) Qμ(h,o) 小于状态 s s s 的价值函数 V μ ( s ) V^{\mu}(s) Vμ(s) ,那么我们可以选择将 β ′ ( h ) = 1 \beta'(h) =1 β′(h)=1 ,即强制终止该历史。
这种修改后的终止条件被称为“中断历史”(interrupted histories)。新的策略 μ ′ \mu' μ′ 是基于 O ′ \mathscr{O'} O′ 的策略,其定义为:对于所有状态 s ∈ S s\in S s∈S 和所有选项 o ′ ∈ O ′ o' \in \mathscr{O'} o′∈O′ ,其中 o o o 是与 o ′ o' o′ 对应的旧选项。
定理的两个主要结论是:
-
价值函数的非劣性:对于所有状态 s ∈ S s\in S s∈S,新的策略 μ ′ \mu' μ′ 的价值函数 V μ ′ ( s ) V^{\mu'}(s) Vμ′(s) 至少不小于原策略 的价值函数 V μ ( s ) V^{\mu}(s) Vμ(s)。即:
V μ ′ ( s ) ≥ V μ ( s ) V^{\mu'}(s) \geq V^{\mu}(s) Vμ′(s)≥Vμ(s)
这是因为中断策略 μ ′ \mu' μ′在某些情况下可以提前终止当前选项并选择更优的选项,从而获得更高的期望回报。 -
价值函数的严格改进:如果存在某个状态 s s s,使得在启动 μ ′ \mu' μ′ 后,存在非零概率遇到中断历史(即提前终止当前选项并选择更优选项),那么 V μ ′ ( s ) > V μ ( s ) V^{\mu'}(s) > V^{\mu}(s) Vμ′(s)>Vμ(s) 。即:
如果 P r ( 在 s 启动 μ ′ 后遇到中断历史 ) > 0 , 则 V μ ′ ( s ) > V μ ( s ) 如果Pr(在s启动 \mu' 后遇到中断历史) >0,则V^{\mu'}(s) > V^{\mu}(s) 如果Pr(在s启动μ′后遇到中断历史)>0,则Vμ′(s)>Vμ(s)
这是因为在这种情况下,中断策略 μ ′ \mu' μ′ 会显著提高期望回报.如果存在任何可能中断的情况,那么中断策略的价值就会严格大于原来的策略。
Proof 思路:
定理的证明主要依赖于期望回报的比较。具体来说,证明中考虑了两种情况下的期望回报:
- 未中断的情况:继续执行当前选项,直到其自然终止。
- 中断的情况:在某些历史中提前终止当前选项,并选择更优的选项。
通过比较这两种情况下的期望回报,可以证明中断策略 μ ′ \mu' μ′ 的期望回报至少不小于原策略 μ \mu μ 的期望回报。在某些情况下,中断策略 μ ′ \mu' μ′ 的期望回报会更高,因为提前终止当前选项并选择更优的选项可以带来更高的奖励
定理应用
改进已经找到的SMDP的最优策略 μ O \mu_{\mathscr{O}} μO 。 μ O \mu_{\mathscr{O}} μO是在给定的选项集合 O \mathscr{O} O下达到的最好结果,但它通常不是全局最优的,因为全局最优可能需要使用更细粒度的原始动作。

How比较?
状态s ,选项0 ,其状态选项价值为Q(s, 0)
- 在Q-learning方法中: 建立一个Q表格[状态/选项–价值]
状态-选项价值
Q_values = {
((0, 0), "Option_1"): 0.9,
((0, 0), "Option_2"): 0.7,
((0, 0), "Option_3"): 0.5,
((1, 4), "Option_1"): 0.6,
((1, 4), "Option_2"): 0.8,
((1, 4), "Option_3"): 0.4,
# 其他状态和选项的价值
}
# 当前状态为(0,0) ,当前选项为"Option_2"
# 比较
V((0,0))=max[0.9,0.7,0.5]=0.9
0.7 <0.9 ##中断
- 在DQN方法中:建立一个Q函数,从而得到 V s V_s Vs
Why省力?
- 局部性:比较 Q(s,o) 和 V(s) 只需要关注当前状态 s,而不需要考虑其他状态。
- 稀疏性:选项数量通常较少,因此计算 V(s) 的成本很低。
- 增量性:价值函数的更新是基于当前状态和动作的奖励信号,而不是对整个状态空间进行重新评估。
极限情况
我们可以做到每一步都中断,每次都切换到当前状态下价值最高的那个选项,也就是所谓的贪婪执行。在这种情况下,每个选项实际上只执行了一步就被打断了。
6. 中断选项–python示例
选项的设置如上
# 环境模拟
def move(state, action):
x, y = state
if action == "up":
return (x, y - 1)
elif action == "down":
return (x, y + 1)
elif action == "left":
return (x - 1, y)
elif action == "right":
return (x + 1, y)
return state
Inter-option Policy
# 高级策略(选择选项的策略)
def choose_option(state, items, options):
available_options = [opt for opt in options if opt.can_initiate(state, items)]
if not available_options:
return None
return np.random.choice(available_options)
判断是否中止选项
# 选项中断机制
def should_interrupt(current_option, state, items, options):
current_value = Q_values[(state, current_option.name)] # 当前选项的价值
max_value = max(Q_values[(state, opt.name)] for opt in options if opt.can_initiate(state, items))
# 其他选项的最大价值
return current_value < max_value
示例运行
# 示例运行
state = (0, 0) # 初始状态
items = {(0, 0): 3, (1, 4): -2, (2, 3): 3, (4, 3): -4} # 初始物品数量
prev_state = state
# 假设的价值函数
Q_values = {
((0, 0), "Option_1"): 0.9,
((0, 0), "Option_2"): 0.7,
((0, 0), "Option_3"): 0.5,
((1, 4), "Option_1"): 0.6,
((1, 4), "Option_2"): 0.8,
((1, 4), "Option_3"): 0.4,
# 其他状态和选项的价值
}
while any(items.values()):
current_option = choose_option(state, items, options)
if current_option is None:
print("没有可用的选项")
break
print(f"选择了选项:{current_option.name}")
current_option.reset_step_count()
while not current_option.is_terminated(state, items, prev_state):
if should_interrupt(current_option, state, items, options):
print(f"中断选项:{current_option.name}")
break
action = current_option.choose_action(state, items)
print(f"当前状态:{state},选择的动作:{action}")
if action == "pick":
if items[state] > 0:
items[state] -= 1
elif items[state] < 0:
items[state] += 1
else:
prev_state = state
state = move(state, action)
print(f"新状态:{state},物品数量:{items[state]}")
print("任务完成!")
7 实验结论
1)学习误差
- 图 11 显示,随着学习步数增加(最高 100,000 步),子目标价值函数(Qg)与真实值(Q*)的均方根误差(RMS Error)逐渐降低,从初始值 0.5 降至约 0.15, 表明选项策略有效收敛(即算法有效性)
- 上层走廊任务与下层走廊任务的误差曲线表明,学习过程能有效区分不同子目标的值函数
2)任务泛化
实验对比了两个子任务(上走廊与下走廊)的学习效果,结果显示选项策略在不同目标(G1/G2)下均能快速适应
G1 和 G2 的值函数在两个任务中呈现差异性收敛,验证了选项策略对子目标的敏感性
3)选项中断分析
若允许在选项执行中途切换动作(非完全终止),可进一步提升灵活性,但实验中默认遵循选项至终止。
4)策略优化
通过调整选项内部策略(如路径选择),实验验证了 MDP与 SMDP 接口的灵活性,支持多时间尺度的规划
4.2 Navigation with Landmark Controllers
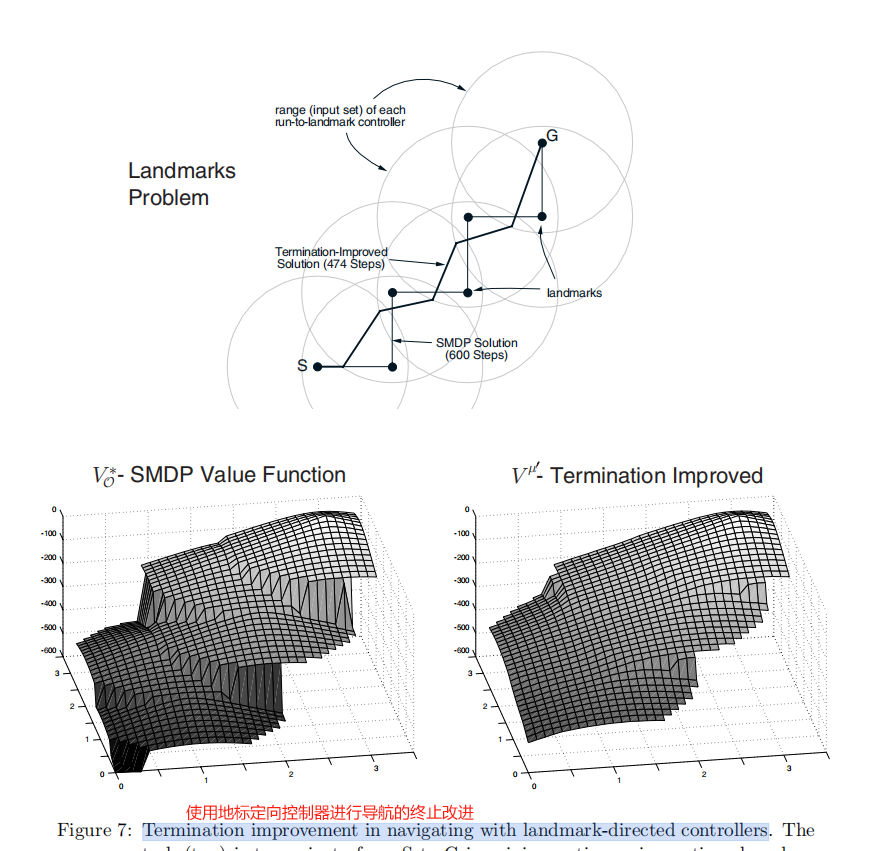
使用地标定向控制器进行导航的终止改进。任务(顶部)是使用基于控制器的选项在最短的时间内从S导航到G,控制器运行到七个地标(黑点)中的每一个。圆圈显示了控制器操作的每个地标周围的区域。细线显示了SMDP解决方案,即仅使用这些控制器而不中断它们的最佳行为,粗线显示了相应的终止改进解决方案,该解决方案减少了拐角。下面的两个面板显示了SMDP和终端改进解决方案的状态值函数。
- options说明:使用地标选项(landmark options)的概念,用于简化连续状态空间中的导航任务。具体来舒,作者将任务分解为7个坐标,每个坐标对应一个控制器,该控制器负责将智能体从当前位置引导到该地标。每个控制器的初始化集合是一个圆形区域,策略是直接移动到该地标,而终止调价是到达该地标时结束。这种设计使得智能体可以利用预定义的控制器来完成复杂的导航任务,而无需为每个可能的路径单独设计策略。


4.3 Dynamic System control
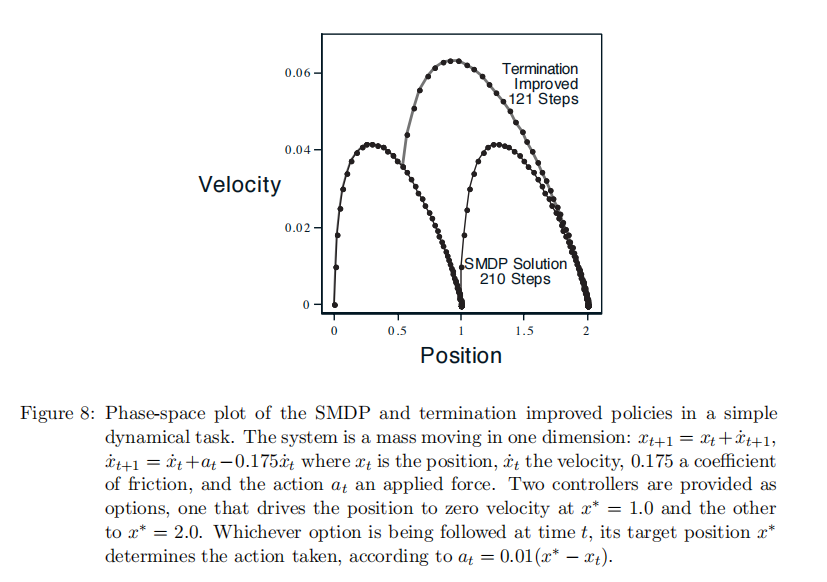
动态系统控制。这是个一维质量块,有摩擦力,目标是从静止状态0到达静止状态2,同样追求时间最短。
Fig.8解析。图中有两个策略。
- 第一个是SMDP solution ,即下面那“两个独立的山”曲线的组合。先使用选项1(从rest 0开始加速到最高速度0.04然后再减速到达 rest 1停止) ,再使用选项2(从rest 1开始加速到最高速度然后减速到达rest 2 停止。)
- 第二个是interrupted solution.即上面“山连着山”的曲线组合。先使用选项1,然后使用中止策略(在0.5的位置),最后使用选项2。


五、Intra-option Model Learning:Motivation
5.1 更新规则
如何学习 选项本身的模型。即,若想知道一个选项 o o o在某个状态s下,执行它会带来多少累积奖励 r s o r_s^o rso,以及转移到下一个状态 s ′ s' s′的概率 p s s ′ o p_{ss'}^o pss′o.
传统的SMDP模型学习方法很简单:等选项执行完毕,记录下结果,然后更新模型估计。例如,用TD学习规则更新 r s o r_s^o rso和 p s s ′ o p_{ss'}^o pss′o。其局限在于,只能在选项终止时才更新,对于非终止选项无效,而且一次只能学习一个选项模型。
How在选项执行过程中学习其模型?
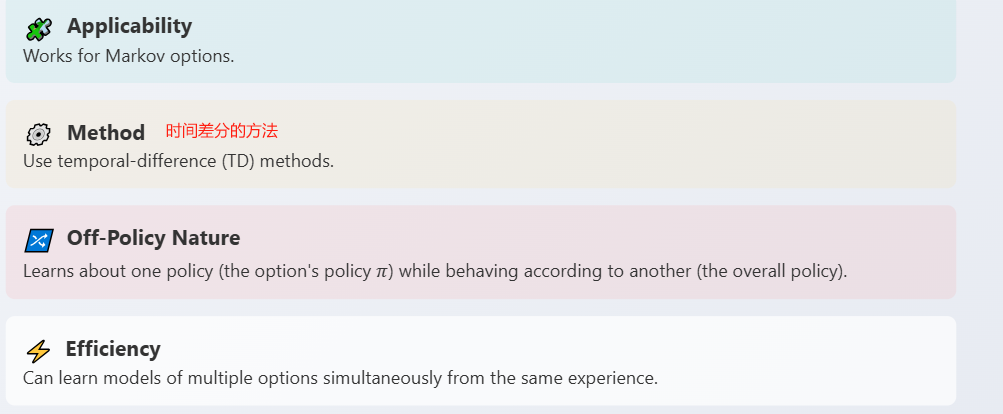
对于马尔可夫选项,可以使用特殊的时差方法来在选项终止前有用地学习关于选项模型。我们称这些为选项内方法,因为它们从“选项内部”的经验片段中学习有关选项的信息。
核心思想是利用时间差分方法,在选项执行的每一步都进行更新。这种方法非常高效,因为它可以从同一段经验中同时学习多个选项的模型。而且,它本质上是一种离策略学习,因为它可以在遵循某个策略的同时,学习关于另一个选项的模型.
贝尔曼方程
建立选项模型的贝尔曼方程。这些方程描述了正确的模型参数如何与自身相关联。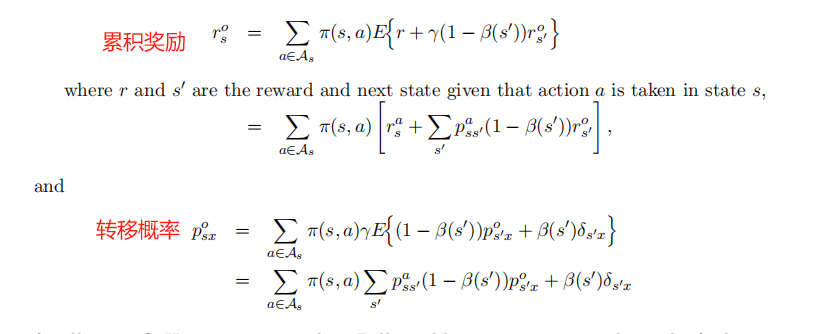
TD更新规则
假设在状态 s t s_t st执行了动作 a t a_t at,这个动作与选项 o o o的策略 π \pi π是一致的。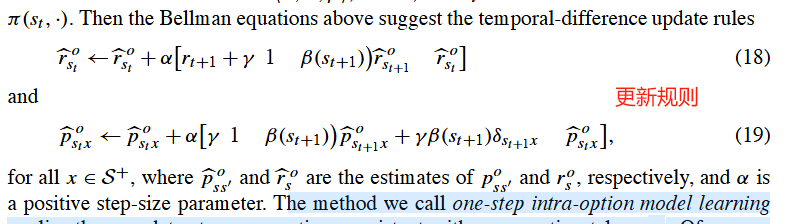
这些更新是在每一步执行的,并且应用于所有与当前动作一致的选项。
5.2 Hallways 案例验证
假设 走廊选项是已知的,但他们的模型是未知的,需要学习。

结果表示:选项内方法学习速度明显更快,误差更低。(下图中,左侧是选项的学习,右侧是选项内部的学习。看纵轴,左图明显高于右图)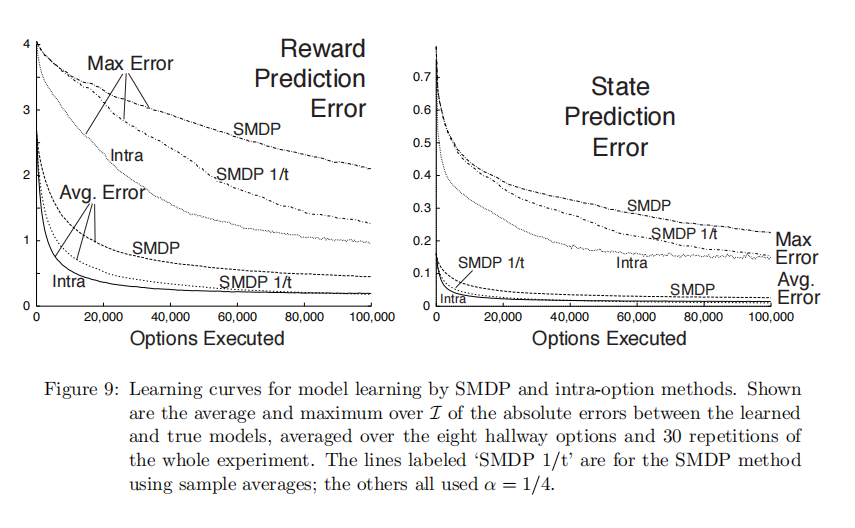
这证实了我们的想法:在选项过执行过程中进行学习,确实能更高效的掌握选项内部的运作机制。
六、Intra-option value learning
目标是找到最优的选项策略,即 Q O ∗ Q_O^* QO∗.传统的SMDP价值学习方法,是在选项执行完毕后才评估其价值,每次执行只能提供一个训练样本。若我们能相学些模型那样更,在选项执行过程中就学习其价值呢?可以的。因为对马尔科夫选项,它在每个中间步骤都可以被视为重新启动了一次。
从状态 s t s_t st到 s t + k s_{t+k} st+k的跳跃,本身就是关于 Q O ∗ ( s t , o ) Q^*_O(s_t, o) QO∗(st,o)的一个有效经验。
在强化学习中,当我们学习近似最优值函数 Q O ∗ ( s , o ) Q^*_{\mathscr{O}}(s,o) QO∗(s,o)时,假设选项 o o o是马尔科夫的,那么从时间t到t+k执行 o o o的过程中,SMDP方法会提取一个训练样本来更新 Q O ∗ ( s , o ) Q^*_{\mathscr{O}}(s,o) QO∗(s,o) 。然而,由于 o o o 是马尔可夫的,这意味着在每个时间步 t,t+1,……,t+k-1, o o o, 也可以被看作是“启动”的。因此,从中间状态 s i s_i si 到终止状态 s t + k s_{t+k} st+k 的所有跳跃(即从 s i s_i si 到 s t + k s_{t+k} st+k 的所有中间状态)都可以被视为有效的经验,用于改进对 Q O ∗ ( s , o ) Q^*_{\mathscr{O}}(s,o) QO∗(s,o) 的估计.
这种现象被称为intra-option learning(选项内学习),它允许我们从同一个经验中提取多个训练样例,从而更高效地学习选项值。例如,考虑一个与 o o o非常相似的选项 o ′ o' o′ ,它在执行过程中选择了相同的操作,但会在 t+k+1 时终止,而不是在
时t+k。虽然 o ′ o' o′ 与 o o o 是不同的选项,但所有在 执行过程中获得的经验都可以用于学习 o ′ o' o′ 的值.这种思想被称为off-policy training(非策略训练),其目的是充分利用所有可能的经验,以尽可能多地了解所有选项,无论这些选项在生成经验中的作用如何。通过这种方式,我们可以更有效地利用经验,从而提高学习效率。例如,intra-option Q-learning(选项内Q学习)是一种方法,它允许在选项执行过程中,对每个动作进行更新,并将更新规则应用于所有与该动作一致的选项。这种方法可以更早地利用经验,从而提高学习效率
引入一种新的符号表示状态-期权对的价值,给定该期权是马尔可夫的并且在到达该状态时执行:

这个方程将当前选项的价值和下一步的U值联系起来。
TD更新规则
在马尔可夫选项中,由于其终止决策仅依赖于当前状态,而不是执行时间的长短,因此可以使用intra-option Q-learning 来学习选项值。这种方法通过贝尔曼方程推导出更新规则,并证明了在确定性策略下,该方法可以收敛到最优的 Q 值。具体来说,更新规则如下:
其中, α \alpha α 是学习率, r t + 1 r_{t+1} rt+1 是即时奖励, γ \gamma γ是折扣因子, U ( s , o ) U(s,o) U(s,o)是下一个状态的期望值。这种方法允许在选项执行过程中,对每个动作进行更新,并将更新规则应用于所有与该动作一致的选项。这种方法可以更早地利用经验,从而提高学习效率.
Room 案例验证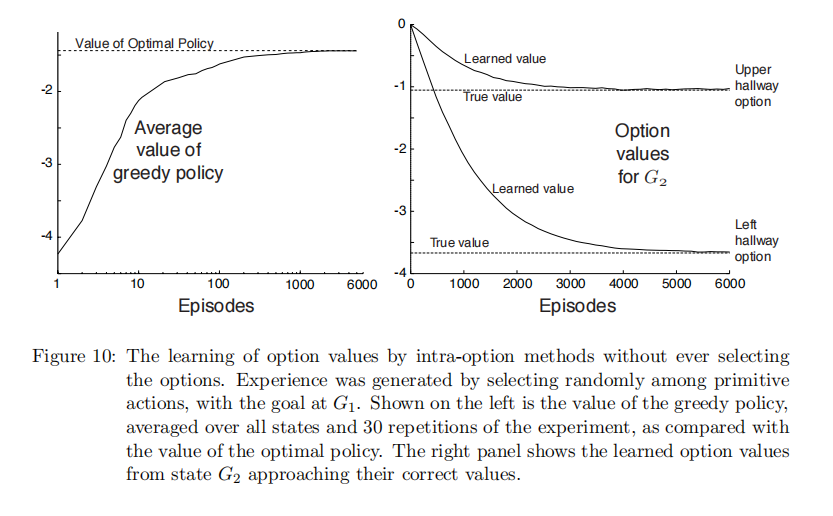
左图显示,基于学习到的选项价值构建的贪婪策略,其价值逐渐接近最优策略。
右图则展示了G2状态,学习到走廊选项价值也逐渐接近其真实值。
这充分证明了选项内的学习方法的强大能力,即没有直接执行某个选项,也能对齐价值进行有效的学习。

七、 Subgoals for learning options
讨论如何爱根本上改变选项的策略,也就是让选项更好的服务其子目标。自然想到,每个选项都应该实现某个特定的子目标。比如,开门选项,目标为打开门。

有了子目标价值函数,可以定义针对子目标g的最优价值函数 V g ∗ ( s ) V_g^*(s) Vg∗(s)

开源鸿蒙跨平台开发社区汇聚开发者与厂商,共建“一次开发,多端部署”的开源生态,致力于降低跨端开发门槛,推动万物智联创新。
更多推荐
 7
7 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)