NLP自然语言处理之RNN
RNN(Recurrent Neural Network)循环神经网络,LSTM
一、传统序列模型之RNN
1、RNN基本概念和基础结构
RNN(Recurrent Neural Network)循环神经网络,是一种序列模型,RNN 会逐个读取句子中的词
语,并在每一步结合当前词和前面的上下文信息,不断更新对句子的理解。
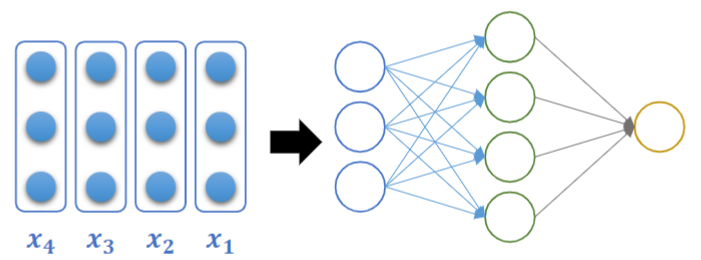
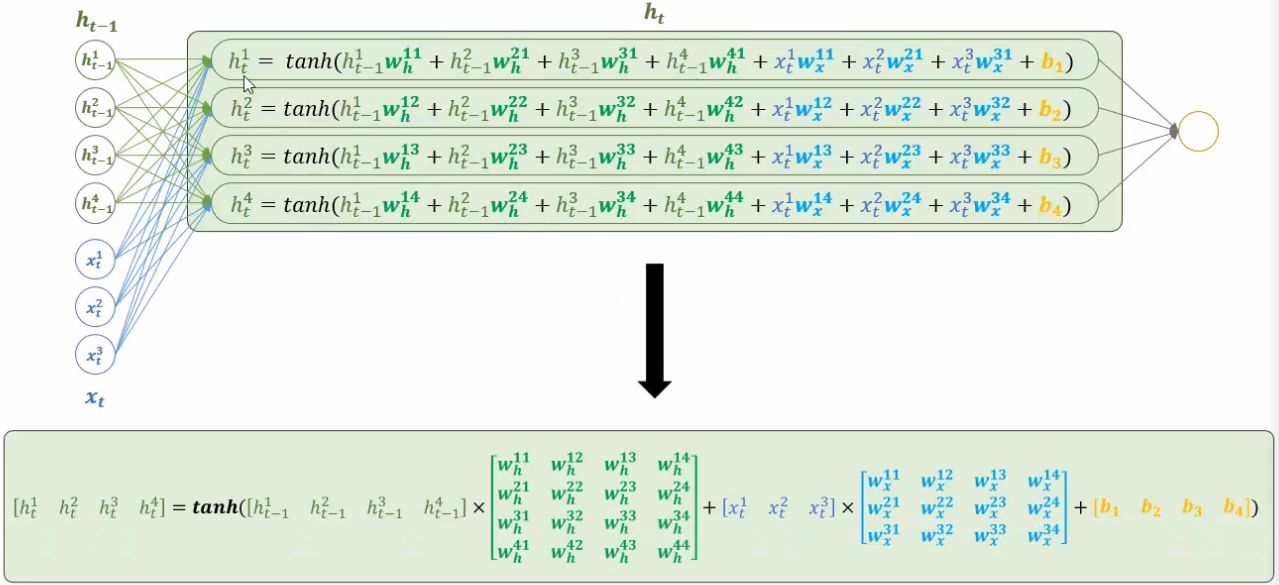
隐藏层公式,可以看到Wh一定是正方形,Wx不一定是正方形
![]()
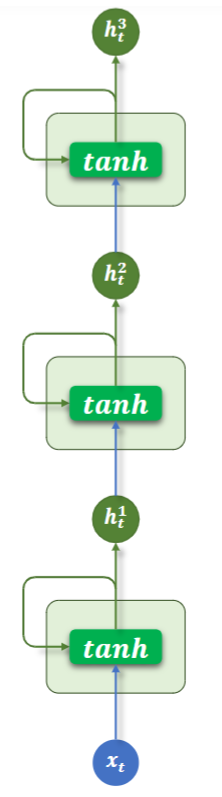
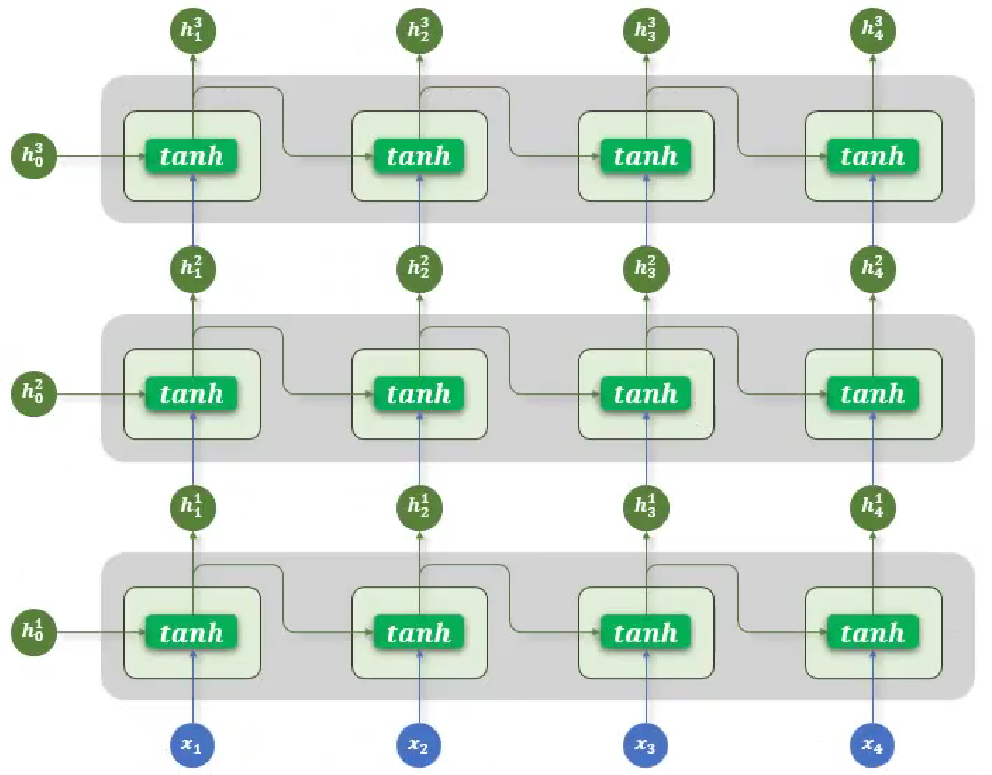
2、多层结构
纵向是神经网络传播方向,横向是时间步方向
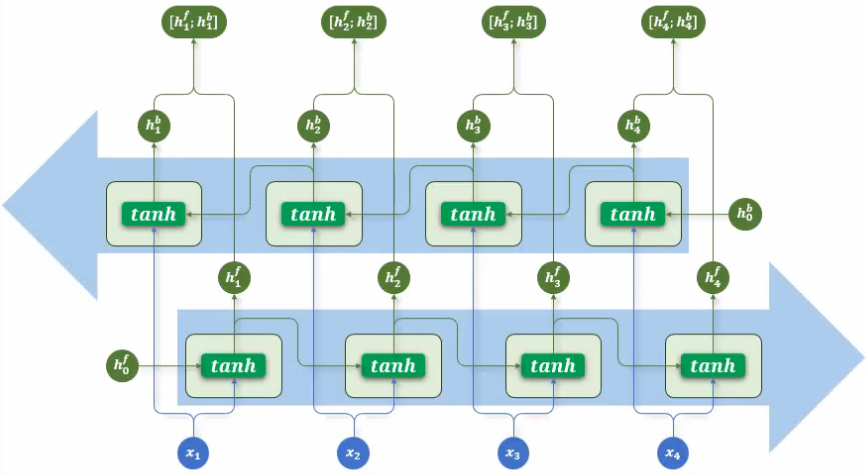
3、双向结构
双向结构的核心就是反向遍历 token 序列,两层 RNN 并行,上面一排是反向遍历RNN,可以看到
是x4作为起点
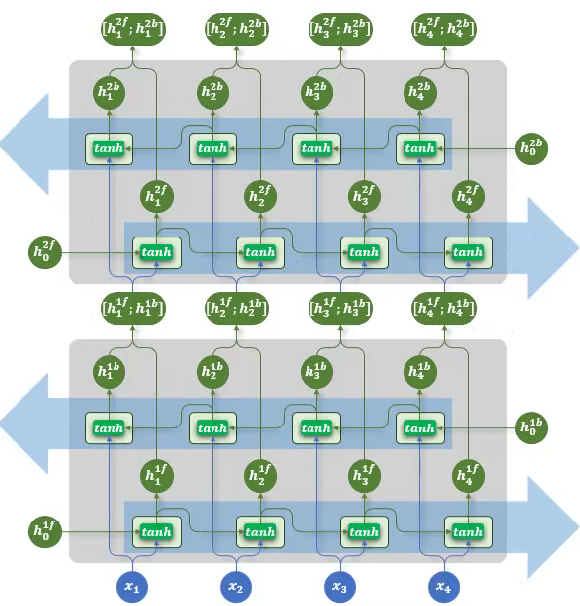
3、多层双向结构
4、API参数说明
input词向量的维度,hidden隐状态维度,nlayersRNN层数,bidirectional是否双向,nonlinearity激
活函数默认tanh可以改成relu,bias是否启用偏置项。
batch_first默认false(seq_len一个序列有几个token, batch_size一批有多少序列, input_size每个
token的词向量),所以推荐设置成True这样更符合直观判断。

5、代码测试
得到输出序列和最后一个时间步所有层上的输出隐状态
import torch
import torch.nn as nn
input = torch.randn(2,4,3)
print(input.shape)
rnn = nn.RNN(input_size = 3,hidden_size = 4,num_layers = 2,bidirectional = True,batch_first = True)
h0 = torch.randn(4,2,4)
output,hn = rnn(input,h0)
print(output.shape) #(N, L, 2*hidden_size) 2是因为双向
print(hn.shape)
torch.Size([2, 4, 3])
torch.Size([2, 4, 8])
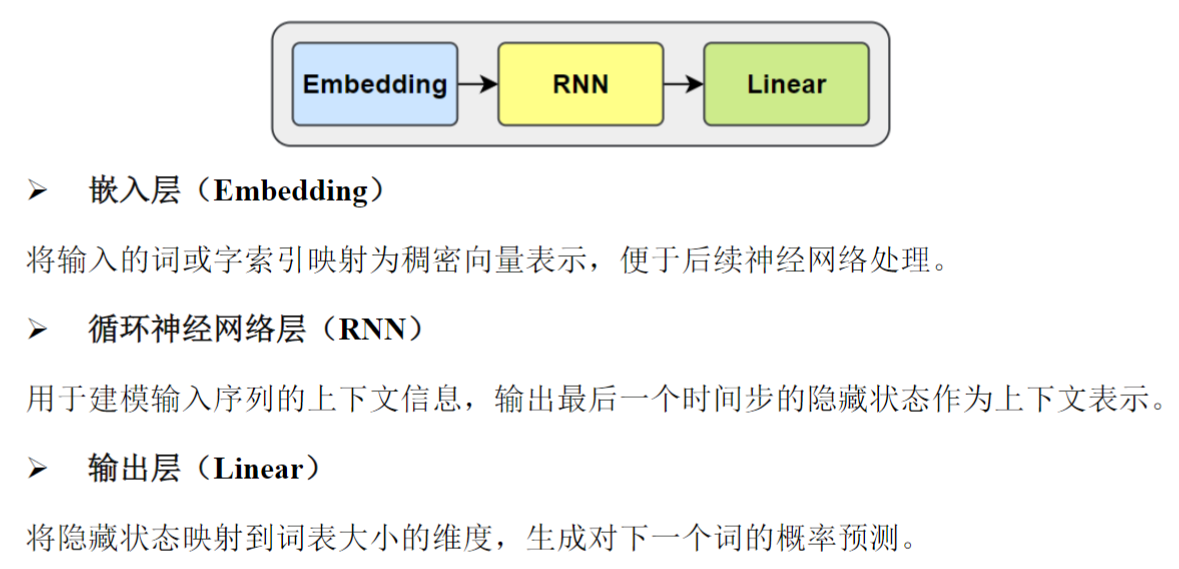
torch.Size([4, 2, 4])6、RNN案例之智能输入法
根据用户当前已输入的文本内容,预测下一个可能输入的词语,要求返回概率最高的 5 个候选词供
用户选择。
数据集:https://huggingface.co/datasets/Jax-dan/HundredCV-Chat
config
from pathlib import Path # 路径定义
# 定义项目根目录
ROOT_DIR = Path(__file__).parent.parent
# 数据目录
RAW_DATA_DIR = ROOT_DIR / "data" / "raw"
PROCESSED_DATA_DIR = ROOT_DIR / "data" / "processed"
# 模型目录
MODEL_DIR = ROOT_DIR / "models"
LOG_DIR = ROOT_DIR / "logs"
RAW_DATA_FILE = "synthesized_.jsonl"
TRAIN_DATA_FILE = "train.jsonl"
TEST_DATA_FILE = "test.jsonl"
VOCAB_FILE = "vocab.txt"
BEST_MODEL = "best.model.pt"
UNK_TOKEN = '<unk>'
SEQ_LEN = 5
BATCH_SIZE = 64
EMBEDDING_SIZE = 128
HIDDEN_SIZE = 256
LEARNING_RATE = 1e-3
EPOCHS = 10preprocess
import pandas as pd
import jieba
from sklearn.model_selection import train_test_split
from config import *
from tokenizer import JiebaTokenizer
# 构建数据集的函数,传入原始语料和词表word2id,返回{'input':[ids],'target':id}
def build_dataset(sentences,tokenizer):
sentences_id = [ tokenizer.encode(sentence) for sentence in sentences]
# def build_dataset(sentences,word2id):
# sentences_id = [[word2id.get(token,0) for token in jieba.lcut(sentence)] for sentence in sentences]
dataset = []
for sentence_id_list in sentences_id:
# 遍历每个id
for i in range(len(sentence_id_list) - SEQ_LEN):
# 每5个构成一个input,后面的是target
input = sentence_id_list[i:i+SEQ_LEN]
target = sentence_id_list[i+SEQ_LEN]
dataset.append({'input': input, 'target': target})
return dataset
def preprocess(text):
print("--------开始数据预处理--------")
df = pd.read_json(RAW_DATA_DIR / RAW_DATA_FILE,lines=True,orient='records' ).sample(frac = 0.1)
# 提取所有对话句子,并做清洗
sentences = []
# 遍历所有组对话
for dialog in df['dialog']:
for sentence in dialog:
sentences.append(sentence.split(':')[1])
print(sentences[0])
print(len(sentences))
train_sentences, test_sentences = train_test_split(sentences, test_size = 0.2)
JiebaTokenizer.build_vocab(train_sentences,MODEL_DIR/VOCAB_FILE)
tokenizer = JiebaTokenizer.from_vocab(MODEL_DIR/VOCAB_FILE)
# vocab_set = set()
# for sentence in train_sentences:
# vocab_set.update(jieba.lcut(sentence))
# # 转换成列表(词表,id2word),并处理未登录词
# vocab_list = [UNK_TOKEN] + list(vocab_set)
# word2id = {word:id for id, word in enumerate(vocab_list)}
#
# print("词表大小:",len(vocab_list))
#
# with open(MODEL_DIR/VOCAB_FILE, 'w',encoding = 'utf-8') as f:
# f.write('\n'.join(vocab_list))
# train_dataset = build_dataset(train_sentences, word2id)
# test_dataset = build_dataset(test_sentences, word2id)
train_dataset = build_dataset(train_sentences, tokenizer)
test_dataset = build_dataset(test_sentences, tokenizer)
pd.DataFrame(train_dataset).to_json(PROCESSED_DATA_DIR/TRAIN_DATA_FILE, lines=True, orient='records')
pd.DataFrame(test_dataset).to_json(PROCESSED_DATA_DIR/TEST_DATA_FILE, lines=True, orient='records')
print("--------数据预处理完成--------")
if __name__ == '__main__':
preprocess(())dataset
import pandas as pd
import torch
from torch.utils.data import DataLoader,Dataset
from config import *
class InputMethodDataset(Dataset):
def __init__(self,path):
self.data = pd.read_json(path,lines=True,orient='records').to_dict(orient='records')
def __len__(self):
return len(self.data)
def __getitem__(self,index):
input = torch.tensor(self.data[index]['input'],dtype = torch.long)
target = torch.tensor(self.data[index]['target'],dtype = torch.long)
return input,target
def get_dataloader(train = True):
path = PROCESSED_DATA_DIR / (TRAIN_DATA_FILE if train else TEST_DATA_FILE)
dataset = InputMethodDataset(path)
dataloader = DataLoader(dataset,batch_size=BATCH_SIZE,shuffle=True)
return dataloader
if __name__ == "__main__":
train_dataloader = get_dataloader(train = True)
test_dataloader = get_dataloader(train = False)
for input,target in train_dataloader:
print(input.shape,target.shape)
breakmodel
在model的前向传播定义中,看上去没有激活函数,其实不是的,rnn自带了一个tanh双曲正切,然
后softmax自动包在损失函数里了,所以才会这样。
import torch
import torch.nn as nn
from config import *
class InputMethodModel(nn.Module):
def __init__(self,vocab_size):
super().__init__()
self.embedding = nn.Embedding(num_embeddings=vocab_size, embedding_dim=EMBEDDING_SIZE)
self.rnn = nn.RNN(input_size = EMBEDDING_SIZE,hidden_size = HIDDEN_SIZE, batch_first=True)
self.linear = nn.Linear(in_features=HIDDEN_SIZE,out_features=vocab_size)
def forward(self,x):
embed = self.embedding(x)
# RNN前向传播,得到输出(N,L,hidden_size)
output,_ = self.rnn(embed)
# 取最后一个时间步的隐状态,作为上下文特征向量
feature = output[:,-1,:]
result = self.linear(feature)
return result
if __name__ == "__main__":
vocab_size = 1000
input = torch.randint(vocab_size,size = (64,5))
model = InputMethodModel(vocab_size)
output = model(input)
print(output.shape)train
import torch
from torch import nn, optim
from config import *
from dataset import get_dataloader
from model import InputMethodModel
from tqdm import tqdm
from torch.utils.tensorboard import SummaryWriter # 日志写入器
import time # 时间库
from tokenizer import JiebaTokenizer
# 定义训练引擎函数,训练一个epoch,返回平均损失
def train_one_epoch(model, train_loader, loss,optimizer,device):
model.train()
total_loss = 0
for input, target in tqdm(train_loader,desc='训练:'):
input, target = input.to(device), target.to(device)
output = model(input)
loss_value = loss(output, target)
loss_value.backward()
optimizer.step()
optimizer.zero_grad()
total_loss += loss_value.item()
return total_loss / len(train_loader)
def train():
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
train_loader = get_dataloader(train = True)
tokenizer = JiebaTokenizer.from_vocab(MODEL_DIR / VOCAB_FILE)
model = InputMethodModel(vocab_size=tokenizer.vocab_size).to(device)
# with open(MODEL_DIR/VOCAB_FILE,'r',encoding='utf-8') as f:
# vocab_list = [token.strip() for token in f.readlines()]
#
# model = InputMethodModel(vocab_size = len(vocab_list)).to(device)
loss = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(),lr = LEARNING_RATE)
writer = SummaryWriter(log_dir=LOG_DIR / time.strftime("%Y-%m-%d_%H-%M-%S"))
min_loss = float('inf')
for epoch in range(EPOCHS):
print('='*10,f'EPOCH:{epoch+1}','='*10)
this_loss = train_one_epoch(model, train_loader, loss,optimizer,device)
print("本轮训练损失:",this_loss)
writer.add_scalar('loss',this_loss,epoch+1)
if this_loss < min_loss:
min_loss = this_loss
torch.save(model.state_dict(),MODEL_DIR/BEST_MODEL)
print('模型保存成功!')
writer.close()
if __name__ == '__main__':
train()
========== EPOCH:1 ==========
训练:: 100%|██████████| 5332/5332 [02:11<00:00, 40.50it/s]
本轮训练损失: 4.642174700284845
训练:: 0%| | 0/5332 [00:00<?, ?it/s]模型保存成功!
========== EPOCH:2 ==========
训练:: 100%|██████████| 5332/5332 [02:28<00:00, 36.00it/s]
本轮训练损失: 3.7933898876237406
训练:: 0%| | 0/5332 [00:00<?, ?it/s]模型保存成功!
========== EPOCH:3 ==========
训练:: 100%|██████████| 5332/5332 [02:20<00:00, 38.01it/s]
本轮训练损失: 3.4373765425492477
训练:: 0%| | 0/5332 [00:00<?, ?it/s]模型保存成功!
========== EPOCH:4 ==========
训练:: 100%|██████████| 5332/5332 [02:20<00:00, 37.95it/s]
训练:: 0%| | 0/5332 [00:00<?, ?it/s]本轮训练损失: 3.1928433156603724
模型保存成功!
========== EPOCH:5 ==========
训练:: 100%|██████████| 5332/5332 [02:19<00:00, 38.25it/s]
本轮训练损失: 3.009689052303483
模型保存成功!
========== EPOCH:6 ==========
训练:: 100%|██████████| 5332/5332 [02:18<00:00, 38.44it/s]
本轮训练损失: 2.860410354589933
训练:: 0%| | 0/5332 [00:00<?, ?it/s]模型保存成功!
========== EPOCH:7 ==========
训练:: 100%|██████████| 5332/5332 [02:18<00:00, 38.39it/s]
本轮训练损失: 2.7379631528886565
模型保存成功!
========== EPOCH:8 ==========
训练:: 100%|██████████| 5332/5332 [02:04<00:00, 42.92it/s]
本轮训练损失: 2.6363531857930176
训练:: 0%| | 0/5332 [00:00<?, ?it/s]模型保存成功!
========== EPOCH:9 ==========
训练:: 100%|██████████| 5332/5332 [02:06<00:00, 42.00it/s]
本轮训练损失: 2.548899033824394
训练:: 0%| | 0/5332 [00:00<?, ?it/s]模型保存成功!
========== EPOCH:10 ==========
训练:: 100%|██████████| 5332/5332 [02:08<00:00, 41.65it/s]
本轮训练损失: 2.473966639469373
模型保存成功!拓展:Tensorboard
在终端运行tensorboard --logdir .\input_method_rnn\logs\,关键代码如下

from torch.utils.tensorboard import SummaryWriter # 日志写入器
import time # 时间库
writer = SummaryWriter(log_dir=LOG_DIR / time.strftime("%Y-%m-%d_%H-%M-%S"))
writer.add_scalar('loss',this_loss,epoch+1)
writer.close()
predict
import torch
import jieba
from config import *
from model import InputMethodModel
from tokenizer import JiebaTokenizer
def predict_topk(model,input,k = 5):
model.eval()
with torch.no_grad():
output = model(input)
# 取输出的topk
top_indices = torch.topk(output,k).indices
return top_indices.tolist() # 转换成列表返回
# def predict(text,model,id2word,word2id,k,device):
# tokens = jieba.cut(text)
# ids = [word2id.get(token, word2id.get(UNK_TOKEN)) for token in tokens]
def predict(text, model, tokenizer, k, device):
ids = tokenizer.encode(text)
input = torch.tensor([ids], dtype=torch.long).to(device)
# 核心预测逻辑
top_indices_list = predict_topk(model, input, k=k)
# 将id列表转换成token列表
top_tokens = [tokenizer.id2word[id] for id in top_indices_list[0]]
# top_tokens = [id2word[id] for id in top_indices_list[0]]
return top_tokens
def run_predict():
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
tokenizer = JiebaTokenizer.from_vocab(MODEL_DIR/VOCAB_FILE)
# with open(MODEL_DIR/VOCAB_FILE,'r',encoding='utf-8') as f:
# vocab_list = [token.strip() for token in f.readlines()]
# id2word = {id:word for id,word in enumerate(vocab_list)}
# word2id = {word:id for id,word in enumerate(vocab_list)}
print("词表加载成功!")
model = InputMethodModel(vocab_size=tokenizer.vocab_size).to(device)
# model = InputMethodModel(vocab_size = len(id2word)).to(device)
model.load_state_dict(torch.load(MODEL_DIR/BEST_MODEL))
print("模型加载成功!")
print('欢迎使用智能输入法模型!输入q或者quit退出...')
input_history = '' # 保存历史输入序列
while True: # 核心,一个死循环
user_input = input('> ')
# 判断如果是q或quit直接退出
if user_input.strip() in['q','quit']:
print('欢迎下次再来!')
break
# 判断如果是空白,提示信息后继续循环
if user_input.strip() == '':
print('请输入有效内容!')
continue
# 将当前输入添加到历史输入中,作为input
input_history += user_input
top_indices = predict(input_history, model, tokenizer, 5, device)
# top_indices = predict(input_history,model,id2word,word2id,5,device)
print('预测结果:',top_indices)
if __name__ == '__main__':
# text = "我们公司"
# top5_tokens = predict(text)
# print(top5_tokens)
run_predict()
['的', '最近', '在', '也', '做']交互式程序运行效果
这里把原来的程序中的predict包装成一个无限循环的交互式问答程序
import torch
import jieba
from config import *
from model import InputMethodModel
def predict_topk(model,input,k = 5):
model.eval()
with torch.no_grad():
output = model(input)
# 取输出的topk
top_indices = torch.topk(output,k).indices
return top_indices.tolist() # 转换成列表返回
def predict(text,model,id2word,word2id,k,device):
tokens = jieba.cut(text)
ids = [word2id.get(token, word2id.get(UNK_TOKEN)) for token in tokens]
input = torch.tensor([ids], dtype=torch.long).to(device)
# 核心预测逻辑
top_indices_list = predict_topk(model, input, k=k)
# 将id列表转换成token列表
top_tokens = [id2word[id] for id in top_indices_list[0]]
return top_tokens
def run_predict():
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
with open(MODEL_DIR/VOCAB_FILE,'r',encoding='utf-8') as f:
vocab_list = [token.strip() for token in f.readlines()]
id2word = {id:word for id,word in enumerate(vocab_list)}
word2id = {word:id for id,word in enumerate(vocab_list)}
print("词表加载成功!")
model = InputMethodModel(vocab_size = len(id2word)).to(device)
model.load_state_dict(torch.load(MODEL_DIR/BEST_MODEL))
print("模型加载成功!")
print('欢迎使用智能输入法模型!输入q或者quit退出...')
input_history = '' # 保存历史输入序列
while True: # 核心,一个死循环
user_input = input('> ')
# 判断如果是q或quit直接退出
if user_input.strip() in['q','quit']:
print('欢迎下次再来!')
break
# 判断如果是空白,提示信息后继续循环
if user_input.strip() == '':
print('请输入有效内容!')
continue
# 将当前输入添加到历史输入中,作为input
input_history += user_input
top_indices = predict(input_history,model,id2word,word2id,5,device)
print('预测结果:',top_indices)
if __name__ == '__main__':
# text = "我们公司"
# top5_tokens = predict(text)
# print(top5_tokens)
run_predict()
> 我们公司
预测结果: ['的', '最近', '在', '也', '做']
> 的
预测结果: ['研究', '产品', '项目', '家庭', '在线教育']
> 研究
预测结果: ['报告', '项目', '历史', '机器', '方向']
> 报告
预测结果: [',', '。', '《', '是', '也']
> 在
预测结果: ['市场调研', '原型', '团队', '项目', '比赛']
> 接收
预测结果: ['的', ',', '?', '。', '工作']
> 审批
预测结果: ['?', '中', '里', '下', ',']
> 中
预测结果: ['取得', '遇到', '最', '最大', '效果']
> q
欢迎下次再来!evaluate
import torch
from config import *
from model import InputMethodModel
from dataset import get_dataloader
from predict import predict_topk
from tokenizer import JiebaTokenizer
# 验证逻辑,返回评价指标top1和top5准确率
def evaluate(model, dataloader, device):
top1_acc_count,top5_acc_count = 0,0
total_count = 0
with torch.no_grad():
for inputs,targets in dataloader:
inputs, targets = inputs.to(device), targets.to(device)
# 前向传播,得到5个预测id
top5_indices_list = predict_topk(model, inputs)
for target,top5_indices in zip(targets,top5_indices_list):
total_count += 1
# 判断预测第一个id是否是target
if target == top5_indices[0]:
top1_acc_count += 1
# 判断target是否在预测列表中
if target in top5_indices:
top5_acc_count += 1
top1_acc = top1_acc_count / total_count
top5_acc = top5_acc_count / total_count
return top1_acc, top5_acc
# 评估主流程
def run_evaluate():
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
tokenizer = JiebaTokenizer.from_vocab(MODEL_DIR/VOCAB_FILE)
# with open(MODEL_DIR/VOCAB_FILE,'r',encoding='utf-8') as f:
# vocab_list = [token.strip() for token in f.readlines()]
print("词表加载成功!")
model = InputMethodModel(vocab_size = tokenizer.vocab_size).to(device)
model.load_state_dict(torch.load(MODEL_DIR/BEST_MODEL))
print("模型加载成功!")
test_dataloader = get_dataloader(train = False)
top1_acc, top5_acc = evaluate(model, test_dataloader, device)
print("评估结果:")
print('top1_acc:', top1_acc)
print('top5_acc:', top5_acc)
if __name__ == '__main__':
run_evaluate()
词表加载成功!
模型加载成功!
评估结果:
top1_acc: 0.28823343071345603
top5_acc: 0.5277416024309833项目改进tokenizer
import jieba
from config import *
class JiebaTokenizer(object):
unk_token = UNK_TOKEN # 类属性
def __init__(self,vocab_list):
self.vocab_list = vocab_list
self.vocab_size = len(vocab_list)
self.word2id = {word: id for id, word in enumerate(vocab_list)}
self.id2word = {id: word for id, word in enumerate(vocab_list)}
# self.unk_token = UNK_TOKEN
self.unk_id = self.word2id[self.unk_token]
# 分词静态方法
@staticmethod
def tokenize(text):
return jieba.lcut(text)
# 编码(id化)
def encode(self,text):
# 分词
tokens = self.tokenize(text)
# id化
ids = [self.word2id.get(token, self.unk_id) for token in tokens]
return ids
# 创建词表,并保存到文件
@classmethod
def build_vocab(cls,sentences,vocab_file_path):
vocab_set = set()
for sentence in sentences:
vocab_set.update(jieba.lcut(sentence))
# 转换成列表(词表,id2word),并处理未登录词
vocab_list = [cls.unk_token] + list(vocab_set)
print("词表大小:", len(vocab_list))
with open(vocab_file_path, 'w', encoding='utf-8') as f:
f.write('\n'.join(vocab_list))
# 从文件加载词表,并创建分词器对象实例
@classmethod
def from_vocab(cls,vocab_file_path):
with open(vocab_file_path, 'r', encoding='utf-8') as f:
vocab_list = [token.strip() for token in f.readlines()]
# 构建分词器对象
tokenizer = cls(vocab_list)
return tokenizer
if __name__ == '__main__':
tokenizer = JiebaTokenizer.from_vocab(MODEL_DIR/VOCAB_FILE)
print("词表大小:",tokenizer.vocab_size)
print("特殊符号UNK:",tokenizer.unk_token)
print(tokenizer.encode('自然语言处理'))
词表大小: 9285
特殊符号UNK: <unk>
[6332, 6519]7、RNN存在问题
在训练RNN时,采用的是时间反向传播(Backpropagation Through Time, BPTT)方法,在反向
传播过程中,梯度需要在每个时间步上不断链式传递,存在的梯度消失或梯度爆炸问题。当输入序
列很长时,模型难以有效学习早期输入对最终输出的影响。

开源鸿蒙跨平台开发社区汇聚开发者与厂商,共建“一次开发,多端部署”的开源生态,致力于降低跨端开发门槛,推动万物智联创新。
更多推荐
 2
2 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)