【自动驾驶】《FLAD: Federated Learning for LLM-based Autonomous Driving in Vehicle-Edge-Cloud Networks》
论文《FLAD: Federated Learning for LLM-based Autonomous Driving in Vehicle-Edge-Cloud Networks》提出了一种基于联邦学习(FL)的自动驾驶框架,旨在通过分布式多模态数据训练提升大型语言模型(LLM)在自动驾驶中的性能,同时解决数据隐私和计算资源限制问题。FLAD采用云-边缘-车辆协作架构,结合智能并行训练和知识蒸
1.参考
论文
https://arxiv.org/pdf/2511.09025
kimi.ai
2.总结
来自:kimi.ai
论文《FLAD: Federated Learning for LLM-based Autonomous Driving in Vehicle-Edge-Cloud Networks》提出了一种名为FLAD(Federated Learning for LLM-based Autonomous Driving)的框架,旨在通过联邦学习(Federated Learning, FL)技术,利用车辆边缘云网络中的分布式多模态传感器数据,提升基于大型语言模型(LLM)的自动驾驶系统的性能,同时解决数据隐私和计算资源限制的问题。以下是论文的详细总结:
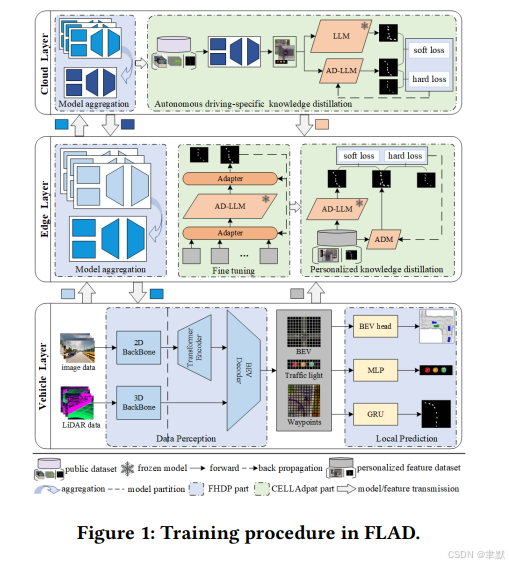
研究背景
-
LLM在自动驾驶中的潜力:LLM在数据融合、推理和决策方面表现出色,是自动驾驶(AD)的有力候选技术。然而,当前基于LLM的AD系统依赖于集中式数据中心和大规模特定领域数据集,这引发了数据隐私、通信开销和实时性能的担忧。
-
联邦学习(FL)的优势:FL允许车辆在不共享原始数据的情况下协作训练模型,从而保护数据隐私。此外,FL能够利用车辆边缘的分布式计算潜力,解决车载硬件资源有限的问题。
FLAD框架
FLAD框架通过云-边缘-车辆协作架构,实现分布式模型训练,同时确保数据隐私和计算资源的有效利用。框架包含三个关键创新:
-
云-边缘-车辆协作架构:通过减少通信延迟和保护数据隐私,提高模型训练效率。
-
智能并行协作训练:通过通信调度机制优化训练效率,利用资源受限的终端设备进行模型训练。
-
知识蒸馏方法:根据异构边缘数据个性化LLM,提高模型适应性。
FLAD的关键技术
-
Federated Hybrid Data Parallelism (FHDP):
-
结合FL和流水线并行技术,最大化资源利用,同时保护数据隐私。
-
通过智能聚类和资源调度,优化模型训练过程,减少通信开销。
-
提出SWIFT(Speedy Weight-based Intelligent Fast Two-phase scheduler)调度器,结合稳定性排序和DQN优化,生成适应动态和异构车辆环境的流水线配置。
-
-
Cloud-Edge LLM Adaptation (CELLAdapt):
-
结合微调(fine-tuning)和知识蒸馏技术,将云中的通用LLM适应到边缘服务器的特定AD任务。
-
通过知识蒸馏,将云中的LLM压缩为更紧凑的AD模型,提高推理速度。
-
实验评估
-
实验设置:使用CARLA模拟器生成的合成驾驶数据,模拟50辆虚拟车辆的联邦学习环境。
-
性能评估:
-
系统效率:FHDP在内存使用和吞吐量方面表现出色,平均内存占用为3.1GB,吞吐量达到单机解决方案的75%。
-
驾驶性能:FLAD训练的视觉编码器在交通灯识别准确率上从79.9%提升到92.66%。在CARLA测试中,FLAD在路线完成率、违规分数和驾驶分数上均优于基线方法。
-
结论
FLAD框架通过云-边缘-车辆协作架构和智能资源管理,显著提高了基于LLM的自动驾驶系统的性能,同时保护了数据隐私并高效利用了分布式计算资源。该框架为未来自动驾驶系统的协作训练和知识共享提供了新的可能性。
未来工作
-
设计更高效的模型以降低训练成本。
-
优化数据加载过程,减少无线网络开销。
-
进一步提高训练效率,扩展FLAD在更多自动驾驶任务中的应用。
3.解决什么问题,属于什么范畴
FLAD(Federated Learning for LLM-based Autonomous Driving in Vehicle-Edge-Cloud Networks) 主要旨在解决以下几类关键问题:
1. 数据隐私和安全问题
-
背景:自动驾驶系统(AD)依赖于大量的驾驶数据进行训练,这些数据通常包含敏感信息(如车辆位置、驾驶行为等)。传统的集中式训练方法需要将数据上传到云端,这可能引发隐私泄露风险。
-
FLAD的解决方案:通过联邦学习(FL)技术,FLAD允许车辆在本地训练模型,仅共享模型更新而不是原始数据,从而保护数据隐私。
2. 计算资源限制问题
-
背景:自动驾驶系统需要处理复杂的多模态传感器数据(如摄像头图像、激光雷达点云等),这要求强大的计算能力。然而,车辆的车载硬件资源有限,难以独立完成复杂的模型训练。
-
FLAD的解决方案:FLAD利用云-边缘-车辆的分布式架构,将计算任务分配到车辆、边缘服务器和云端,通过智能调度和流水线并行技术,优化资源利用。
3. 通信效率和实时性问题
-
背景:在车辆网络中,通信带宽有限且不稳定,尤其是在高速移动的车辆环境中。传统的分布式训练方法可能会因通信延迟而降低训练效率。
-
FLAD的解决方案:通过设计高效的通信调度机制和快速恢复机制,FLAD能够减少通信开销,提高训练过程的实时性和稳定性。
4. 模型适应性和个性化问题
-
背景:不同地区的驾驶环境和交通规则存在差异,自动驾驶模型需要针对特定区域进行个性化调整。传统的集中式训练方法难以实现这种区域特定的模型优化。
-
FLAD的解决方案:通过知识蒸馏技术,FLAD能够将云中的通用LLM(Large Language Model)适应到边缘服务器的特定AD任务,生成个性化的自动驾驶模型。
FLAD 属于的研究范畴
FLAD 的研究内容涉及多个学科领域,主要包括以下几个方面:
1. 自动驾驶技术
-
研究范畴:FLAD属于自动驾驶技术的研究范畴,特别是端到端自动驾驶系统(End-to-End Autonomous Driving, E2E-AD)的优化。
-
具体贡献:通过联邦学习和分布式计算,FLAD提高了自动驾驶系统的适应性和实时性,使其能够更好地处理复杂的驾驶场景。
2. 联邦学习(Federated Learning, FL)
-
研究范畴:FLAD是联邦学习在自动驾驶领域的应用,属于分布式机器学习的研究范畴。
-
具体贡献:FLAD提出了一种新的联邦学习框架,通过云-边缘-车辆协作,解决了数据隐私和计算资源限制的问题。
3. 边缘计算(Edge Computing)
-
研究范畴:FLAD利用边缘计算技术,将部分计算任务从云端转移到边缘服务器和车辆,属于边缘计算的研究范畴。
-
具体贡献:通过边缘计算,FLAD减少了通信延迟,提高了系统的实时性和可靠性。
4. 多模态数据融合
-
研究范畴:FLAD处理多模态传感器数据(如摄像头图像、激光雷达点云等),属于多模态数据融合的研究范畴。
-
具体贡献:通过智能调度和流水线并行技术,FLAD优化了多模态数据的处理效率,提高了自动驾驶系统的感知和决策能力。
5. 知识蒸馏(Knowledge Distillation)
-
研究范畴:FLAD利用知识蒸馏技术将大型语言模型(LLM)适应到边缘设备,属于模型压缩和知识转移的研究范畴。
-
具体贡献:通过知识蒸馏,FLAD生成了更紧凑的自动驾驶模型,提高了模型的推理速度和适应性。
总结
FLAD 是一个跨学科的研究项目,主要解决自动驾驶系统中的数据隐私、计算资源限制、通信效率和模型个性化问题。它属于自动驾驶技术、联邦学习、边缘计算、多模态数据融合和知识蒸馏等研究范畴,通过创新的云-边缘-车辆协作架构和智能资源管理技术,显著提高了自动驾驶系统的性能和可靠性。
4.性能与效果
FLAD(Federated Learning for LLM-based Autonomous Driving in Vehicle-Edge-Cloud Networks)框架通过一系列创新技术,显著提升了基于大型语言模型(LLM)的自动驾驶系统的性能和可靠性。以下是FLAD框架达到的主要效果:
1. 提升自动驾驶性能
-
更高的准确性:通过联邦学习和分布式训练,FLAD能够利用更多的数据进行模型训练,从而提高自动驾驶系统的感知和决策准确性。例如,FLAD训练的视觉编码器在交通灯识别的准确率上从79.9%提升到92.66%。
-
更好的适应性:通过知识蒸馏技术,FLAD能够将云中的通用LLM适应到边缘服务器的特定自动驾驶任务,生成个性化的自动驾驶模型。这使得模型能够更好地适应不同地区的驾驶环境和交通规则。
2. 保护数据隐私
-
数据本地化:FLAD采用联邦学习技术,允许车辆在本地训练模型,仅共享模型更新而不是原始数据。这种方式有效保护了驾驶数据的隐私。
-
减少数据泄露风险:通过避免将原始数据上传到云端,FLAD显著降低了数据泄露的风险。
3. 优化计算资源利用
-
分布式计算:FLAD利用云-边缘-车辆的分布式架构,将计算任务分配到车辆、边缘服务器和云端。通过智能调度和流水线并行技术,优化了资源利用。
-
资源受限设备的支持:FLAD通过动态模型分区和智能调度,使得资源受限的车辆也能参与模型训练,提高了系统的整体效率。
4. 提高通信效率
-
减少通信开销:通过设计高效的通信调度机制和快速恢复机制,FLAD能够减少通信开销,提高训练过程的实时性和稳定性。
-
快速恢复能力:FLAD的快速恢复机制能够在网络故障或车辆离开网络覆盖时,快速恢复训练过程,减少中断时间。
5. 增强系统的实时性和可靠性
-
实时性:FLAD通过边缘计算和分布式训练,减少了通信延迟,提高了系统的实时性。
-
可靠性:FLAD的快速恢复机制和边缘辅助备份策略,确保了训练过程的连续性和稳定性。
6. 实验验证
-
系统效率:在内存使用和吞吐量方面,FLAD表现出色。实验结果显示,FLAD的平均内存占用为3.1GB,吞吐量达到单机解决方案的75%。
-
驾驶性能:在CARLA测试中,FLAD在路线完成率、违规分数和驾驶分数上均优于基线方法。
总结
FLAD框架通过云-边缘-车辆协作架构和智能资源管理技术,显著提高了基于LLM的自动驾驶系统的性能和可靠性。它不仅保护了数据隐私,还优化了计算资源利用,提高了通信效率,增强了系统的实时性和可靠性。这些效果使得FLAD成为未来自动驾驶系统中一个极具潜力的解决方案。

开源鸿蒙跨平台开发社区汇聚开发者与厂商,共建“一次开发,多端部署”的开源生态,致力于降低跨端开发门槛,推动万物智联创新。
更多推荐
 27
27 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)