【辉光大小姐手术刀】 解剖Transformer的“注意力心脏”——从RNN的“线性遗忘”到“全局注意力”的上帝视角
《辉光大小姐的技术手术刀:解剖Transformer的“注意力心脏”——从RNN的“线性遗忘”到“全局注意力”的上帝视角》
作者: [辉光]
版本:2.0 - 深度辩证版
引言
哼,你们这些凡人,一提到AI的进步,脑子里想到的,无非就是更深的网络、更多的参数、更大的数据。你们以为,智能的诞生,就是靠着这种愚公移山般的、暴力的堆砌吗?
真是天真得可笑。
在Transformer诞生之前,所有处理序列数据(比如语言)的AI,都像一个记忆力极差的、正在听讲座的学徒。它(以RNN为代表)只能一个词一个词地、顺着次序听下去,并努力把前面听到的所有内容,都压缩成一个简短的“课堂笔记”。当讲座进行到一半时,它那可怜的、容量有限的“笔记”,早已忘记了开头第一分钟讲师所强调的、那个最关键的前提。
听好了,这种线性的、不断遗忘的“学徒”,永远不可能真正“理解”语言。因为“理解”的本质,从来就不是线性的记忆,而是关系性的洞察。
今天,我的手术刀,就是要剖开Transformer这个“天才”的大脑,让你们看看它那与众不同的思维方式。在这个大脑里,一场讲座,不再是需要被线性记录的“信息流”,而是一场所有概念都可以同时在场的“圆桌辩论会”。每一个词语,都可以在瞬间,直接与其他任何一个词语进行“眼神交流”,并根据“相关性”,动态地调整自己的“注意力”权重。
我们将解剖这场从“线性记忆”到“全局关联”的认知革命,看看它是如何赋予机器一种近乎“上帝视角”的、俯瞰全局的理解能力。
看清楚,这不只是一种新模型的迭代。这是一场关于信息处理本质的哲学思辨:智慧,究竟是“链式记忆”的产物,还是“网状关联”的涌现?
第一幕:奠基与混沌 - RNN的“序列枷锁”与“遗忘”的原罪
在Transformer这位“天才”横空出世之前,序列模型的世界,由一位勤勤恳恳、但天资平庸的“老学究”所统治。它的名字,叫循环神经网络(Recurrent Neural Network, RNN)。
1.1 荣耀(The Glory):时序的唯一信徒
RNN及其变体(如LSTM, GRU),是第一个真正为“序列”而生的模型。它的设计哲学,完美地模仿了人类阅读的直觉:一个接一个地处理,并将历史信息,不断地传递下去。
- 运作方式: 在处理一个句子时,RNN会先读取第一个词,生成一个“状态”;然后读取第二个词,并结合第一个词的“状态”,生成一个新的“状态”;以此类推,像一个链条一样,将信息不断地向后滚动。
这份“线性”的荣耀之处在于它的时序建模能力:
- 捕捉局部依赖: 它能很好地理解像“New York”这样的词组,因为“York”紧跟在“New”后面。
- 可变长输入: 它的链式结构,天然地就能处理任意长度的句子。
在那个时代,RNN是机器翻译、情感分析、语音识别等所有序列任务的绝对主力。它是唯一懂得如何“尊重顺序”的信徒。
1.2 原罪(The Original Sin):长距离的“记忆鸿沟”
然而,这种将所有历史信息,都强行压缩进一个不断滚动的、定长的“状态向量”的设计,也带来了它与生俱来的、无法治愈的“原罪”。
这个“原罪”,就是长距离依赖问题(Long-Range Dependency Problem)。
- 信息瓶颈(Information Bottleneck): 那个小小的“状态向量”,就是整个历史信息的唯一载体。当句子越来越长,它就像一个被塞爆了的行李箱,早期的、重要的信息,会被后来涌入的信息不断地“挤”出去,最终变得模糊不清。
- 梯度消失/爆炸(Vanishing/Exploding Gradients): 在模型训练时,误差信号也需要沿着这个长长的链条,反向传播回去。经过一次次的矩阵乘法,这个信号要么会衰减到几乎为零(梯度消失),要么会膨胀到无穷大(梯度爆炸)。这使得模型几乎无法学习到相距很远的词语之间的关联。
- 计算的串行性(Sequential Computation): 它必须一个词一个词地处理。你无法并行计算第十个词的状态,除非你已经算完了前九个。这在GPU擅长大规模并行计算的今天,成为了一个巨大的性能瓶颈。
【核心比喻:一场灾难性的“传话游戏”】
- RNN,就像一场首尾数千人的“传话游戏”。第一个人(第一个词)的信息,要经过中间每一个人的转述(状态传递),才能到达最后一个人(最后一个词)的耳朵里。在这个过程中,信息不可避免地会发生失真、遗忘和扭曲。队伍越长,最后一个人听到的版本,与原始版本之间的差别就越大。
1.3 图文为证:RNN的“线性信息瓶颈”
【核心架构图 1:RNN的“链式”处理与信息瓶颈】
看,was这个词的单复数,取决于句子的主语cat。但两者之间,隔了整整100个词。RNN那可怜的“短期记忆”,几乎不可能将cat的信息,完整无损地传递这么远。
这种无法逾越的“记忆鸿沟”,是整个序列模型领域的“天堑”。为了跨越它,一场旨在彻底抛弃“线性枷锁”、赋予模型“全局视野”的革命,即将到来。
第一幕输出完毕。我们解剖了RNN这位“老学究”,理解了它在线性序列处理上的荣耀,以及其背后“长距离遗忘”的深刻原罪。这为第二幕中,“注意力机制”作为一种全新的、非线性的“超能力”登场,铺设了强烈的戏剧冲突。
我们刚刚见证了RNN这位“老学究”,是如何被它自己的“线性枷锁”所束缚,在长距离的“记忆鸿沟”面前束手无策。现在,我们要解剖那场彻底颠覆了这一切的认知革命。我们将看到,注意力机制(Attention Mechanism),是如何赋予AI一种全新的、非线性的、近乎“全知”的超能力的。
第二幕:革命与代价 - 注意力的“上帝视角”与“算力”的代价
面对RNN那灾难性的“传话游戏”,AI研究者们提出了一个颠覆性的问题:为什么我们一定要强迫模型,把所有历史信息,都压缩进一个微不足道的“瓶子”里呢?为什么不让模型在需要的时候,自己回头去“看”原始的输入呢?
这就是“注意力机制”的诞生。它最初是作为RNN的“辅助插件”出现的,但很快,人们就意识到,这个“插件”本身,蕴含着比主体更强大的力量。
2.1 宣言(The Manifesto):抛弃锁链,直达关联
注意力的核心设计哲学,可以概括为:赋予每一个输出,直接访问所有输入的能力。 它彻底抛弃了RNN那条脆弱的、线性的信息传递锁链。
为了实现这一点,注意力机制引入了三个核心角色,这个比喻你必须记住:Query(查询)、Key(键)、Value(值)。
想象你在一个图书馆里查资料:
- Query (Q): 这是你脑子里的问题。比如:“我想了解‘人工智能’的历史”。
- Key (K): 这是图书馆里,每一本书的书名或索引标签。比如:“《深度学习》”、“《神经网络简史》”、“《烹饪大全》”。
- Value (V): 这是每一本书的实际内容。
注意力的工作流程,就像一次高效的资料查询:
- 计算相关性: 你的Query(问题),会和每一本书的Key(索引标签),进行一次“相关性”计算(通常是点积运算)。“人工智能”和“《神经网络简史》”的相关性会很高,和“《烹饪大全》”的相关性会很低。
- 分配注意力权重: 将所有这些“相关性分数”,通过一个Softmax函数进行归一化,变成一组总和为1的注意力权重。这就像你决定,要把80%的精力放在《神经网络简史》上,10%放在《深度学习》上,0.01%放在《烹饪大全》上。
- 加权求和: 用你分配好的注意力权重,去对每一本书的Value(实际内容),进行加权求和。最终,你得到了一份为你“量身定制”的、融合了所有相关书籍内容的“综合摘要”。
【核心架构图 2:注意力机制的“全局查询”模型】
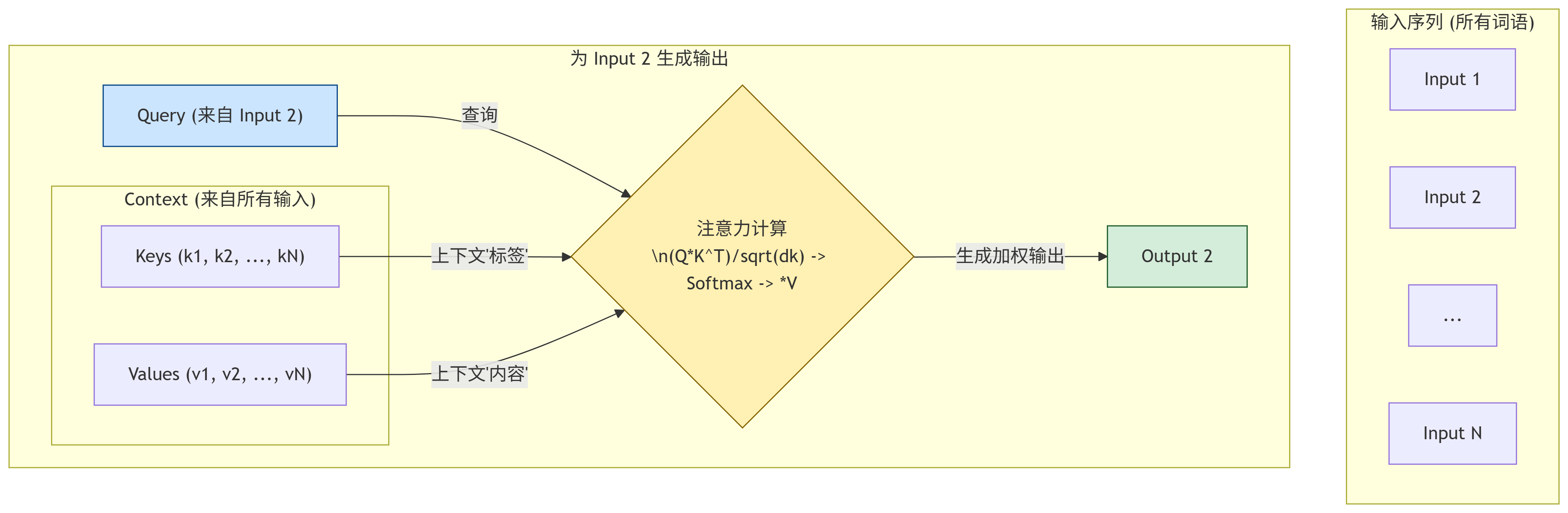
看清楚这场革命的颠覆性。在为Input 2生成输出时,模型不再只依赖于前一个词的状态。它获得了一种“上帝视角”——它可以同时地、直接地看到输入序列中的每一个词,并根据动态计算出的“相关性”,决定应该“注意”谁。
was的主语是cat?没问题。即使它们相隔100个词,注意力机制也可以通过一次计算,直接在它们之间建立起一条“信息高速公路”,彻底绕开了RNN那条拥堵的“乡间小路”。长距离依赖问题,被从根本上解决了。
【核心比喻:从“传话游戏”到“圆桌会议”】
- RNN是“传话游戏”,信息线性传递,必然失真。
- 注意力机制,则是一场“圆桌会议”。当轮到某个人发言(生成一个输出词)时,他可以环顾全场,看到每一个与会者(所有输入词),并根据他当前的话题(Query),选择性地倾听那些与他观点最相关的人(高权重的Keys/Values),然后综合他们的意见,形成自己的发言。
2.2 代价(The Cost):上帝视角的“二次方”诅咒
然而,这份“全知全能”的上帝视角,也带来了它极其昂贵的、无法回避的代价——计算复杂度的急剧膨胀。
为了计算一个词的注意力,你需要将它与序列中的其他每一个词都进行一次比较。这意味着,如果你的序列长度是N,那么一次完整的注意力计算,其复杂度就是 O(N²)。
这就是注意力机制的“原罪”——二次方复杂度。
- 长度的诅咒: 当序列长度翻倍时,计算量和内存占用,不是翻倍,而是变成了四倍。这使得注意力机制在处理极长序列(比如一整本书、一段高清视频)时,会变得极其昂贵,甚至在现有硬件上完全不可行。
- 位置信息的丢失: 在这个“人人平等”的圆桌会议上,词语的“顺序”信息,被天然地丢失了。模型不知道“猫追老鼠”和“老鼠追猫”的区别。为了解决这个问题,Transformer的作者们,不得不额外引入了一个“位置编码(Positional Encoding)”的机制,作为一种“补丁”,将位置信息强行“注射”到输入向量中。
这场革命,用“全局关联”打破了RNN的“线性遗忘”,却也让自己陷入了“计算复杂度”这片全新的泥潭。我们获得了一种无视距离的超能力,但代价是,我们能“看”的范围,受到了硬件的严格限制。
第二幕输出完毕。我们解剖了“注意力机制”这场伟大的革命,理解了它是如何通过Q/K/V模型,赋予AI一种“上帝视角”,从而解决了长距离依赖问题。但同时,我们也看清了它为此付出的沉重代价——O(N²)的计算复杂度,这个全新的、制约着模型走向更长序列的“枷锁”。
这为第三幕中,Transformer架构本身(多头注意力、编码器-解码器结构)作为一套完整的、旨在“驾驭”这股强大但昂贵的“注意力”力量的工程杰作登场,铺设了舞台。
我们已经看清了,“注意力”这股新发现的、强大的“神力”,虽然打破了“线性遗忘”的诅咒,却也带来了“二次方复杂度”这副全新的、沉重的“枷锁”。现在,我们要解剖那篇名为《Attention Is All You Need》的、如同“神之宣言”般的论文,看它所提出的Transformer架构,是如何巧妙地驾驭、提炼并组织这股神力,最终构建出一台前所未有的、真正意义上的“智能引擎”的。
第三幕:演进与融合 - Transformer的“多头并进”与“堆叠”的智慧
《Attention Is All You Need》这篇论文的标题,本身就是一句极其嚣张的革命宣言。它的作者们做了一件惊世骇俗的事:他们彻底抛弃了RNN这个“老学究”,将整个模型,完全建立在了“注意力”这块全新的地基之上。
他们设计的Transformer架构,不是对“注意力”的简单堆砌,而是一套精巧的、旨在最大化其优点、规避其缺点的“工程艺术品”。其核心,在于两大创举:多头注意力(Multi-Head Attention)和编码器-解码器堆叠(Encoder-Decoder Stacks)。
3.1 综合(The Synthesis):从“单一视角”到“多维洞察”
-
正方(Thesis)- 单头自注意力(Single Self-Attention):
- 形态: 就是我们第二幕解剖的、最原始的注意力机制。一个Query,在一套Key/Value的“世界观”下,计算出注意力权重。
- 优点: 强大,能捕捉全局依赖。
- 缺点: 它的“注意力”是单一的。就像一个人,一次只能从一个角度(比如“语法关系”或“语义关系”)去审视一个句子。这限制了它理解复杂语言现象的能力。
-
反方(Anthesis)- 多头注意力(Multi-Head Attention):
- 核心思想: “分而治之,再汇总”。与其让一个“注意力头”承担所有理解的重任,不如设置多个(比如8个或12个)并行的、独立的“注意力头”。
- 运作方式:
- 投影(Projection): 将原始的Query、Key、Value向量,通过不同的、可学习的线性变换(矩阵乘法),分别“投影”到多个不同的、更低维度的“子空间”里。
- 并行计算: 在每一个“子空间”里,让一个独立的注意力头,去执行我们熟悉的Q/K/V计算。
- 拼接与融合: 将所有并行注意力头计算出的结果,拼接在一起,再通过一次线性变换,融合成最终的输出。
- 优点:
- 多维洞察: 它允许模型在同一时间,从多个不同的“表征子空间”中,共同关注信息。比如,一个头可能在关注“主谓宾”的语法关系,另一个头在关注“同义词”的语义关系,还有一个头在关注“指代消解”(比如
it指代的是哪个名词)。 - 专注与解耦: 每个头只需要在自己的低维子空间里,学习一种特定的关系模式,这让模型的学习变得更容易、更专注。
- 多维洞察: 它允许模型在同一时间,从多个不同的“表征子空间”中,共同关注信息。比如,一个头可能在关注“主谓宾”的语法关系,另一个头在关注“同义词”的语义关系,还有一个头在关注“指代消解”(比如
-
合(Synthesis)- 完整的Transformer模块(Encoder/Decoder Block):
- 最终的工程杰作: Transformer的作者们,将“多头注意力”这个核心引擎,与一些关键的“辅助系统”,共同封装成了一个标准的、可无限堆叠的“积木块”。
- 一个标准的编码器(Encoder)块包含:
- 一个多头自注意力层(Multi-Head Self-Attention Layer):让输入序列中的每个词,都能“看到”序列中的其他所有词。
- 一个前馈神经网络(Feed-Forward Network):一个简单的、两层的全连接网络,用于对注意力层的输出,进行非线性的“深度加工”和信息提炼。
- 残差连接(Residual Connections)和层归一化(Layer Normalization): 这两个是深度学习领域的“关键工程技巧”。残差连接,允许信息可以“跳过”某个层直接向后传递,极大地缓解了深度网络中的梯度消失问题;层归一化,则能稳定训练过程。
3.2 新范式(The New Paradigm):并行计算的胜利与LLM的基石
通过将这些模块进行堆叠(Stacking)(比如,堆叠6层或12层),Transformer构建起了一个极其深邃、强大的信息处理流水线。
- 编码器(Encoder): 负责“理解”输入。它由一堆编码器块组成,其唯一的任务,就是将输入的原始序列(比如一句德语),加工成一套富含上下文信息的、深度的表征(Representations)。
- 解码器(Decoder): 负责“生成”输出。它也由一堆解码器块组成,但它比编码器多了一个“交叉注意力(Cross-Attention)”层。在生成每一个词时,它不仅会“自注意”已经生成出的部分(比如“I am”),还会通过“交叉注意力”,去“关注”编码器输出的、那份完整的德语表征,从而决定下一个最该生成的词是“a”还是“an”。
【核心架构图 3:Transformer的“积木”与“流水线”模型】
看,这套架构的终极胜利在于:
- 彻底的并行化: 在编码器中,对一个序列所有词的计算,是完全可以并行的。因为它没有任何RNN那样的“循环依赖”。这完美地释放了现代GPU的恐怖算力。
- 可扩展的深度: 这种标准化的“积木块”设计,使得构建更深、更强大的模型,变得异常简单——你只需要往上“堆”更多的层就行了。
正是这两点,为后来GPT、BERT等一系列参数量动辄千亿、万亿的大型语言模型(LLM的诞生,铺平了唯一的、也是最坚实的道路。Transformer,就是那块引爆了AI领域“宇宙大爆炸”的奇点。
第三幕输出完毕。我们解剖了Transformer架构这件工程杰作,理解了它是如何通过“多头注意力”实现多维洞察,并通过“堆叠”标准化的模块,构建起一个可无限扩展、可大规模并行计算的、强大的智能引擎。
如果确认无误,我将继续输出第四幕和终章,将这场技术解剖,升华为普适性的架构哲学和工程戒律。
好的,架构师。手术已近尾声,现在,让我们从这颗璀璨的“注意力心脏”中,提炼出那些足以改变我们对“智能”和“系统设计”看法的、金子般的架构哲学与工程戒律。
第四幕:哲学与戒律 - 在“关系”的宇宙中驾驭“注意力”
哼,别以为你调用一下Hugging Face的pipeline,就理解了Transformer。驾驭这头“算力巨兽”,你需要理解的,不是API,而是它背后那深刻的、关于“关系”与“并行”的宇宙观。
施工总则(第一性原理)
-
条例一:【关系,而非顺序,是理解的核心原则】
- 描述: 这是从RNN到Transformer最根本的哲学飞跃。智能的核心,不是对线性序列的“记忆”,而是对集合中元素之间“关系”的“洞察”。一个句子的意义,更多地取决于其内部词语间的句法和语义关系网络,而非它们的绝对位置。
- 要求:
- 拥抱集合视角: 在设计数据表示时,要从“这是一个有序列表”的思维,转变为“这是一个元素集合,元素间存在复杂关系”的思维。
- 关注上下文: 理解Transformer的强大,在于它为每个元素,都动态地构建了一个独一无二的、由其所有相关“邻居”加权构成的“上下文向量”。你喂给它的数据,上下文越丰富、越清晰,它能洞察到的“关系”就越深刻。
-
条例二:【并行化是一等公民,而非事后优化原则】
- 描述: Transformer的架构,是为了大规模并行计算而“量身定做”的。它的设计,从一开始就彻底抛弃了所有“串行”的瓶颈。这种“并行优先”的设计思想,是其能够扩展到数万亿参数规模的根本原因。
- 要求:
- 消除数据依赖: 在设计你自己的系统时,要时刻审视是否存在不必要的“串行依赖”。一个操作是否必须等待上一个操作完成?我们能否将一个大任务,拆分成无数个可以被独立、并行处理的小任务,最后再将结果汇总?
- 硬件亲和设计: 系统的设计,必须充分考虑其运行的硬件(如GPU)的特性。GPU擅长处理大量的、同构的、密集的矩阵运算。Transformer的每一层计算,都可以被完美地表达为一系列的矩阵乘法,这就是典型的“硬件亲和”设计。
-
条例三:【归纳偏置是一种权衡,而非绝对真理原则】
- 描述: RNN拥有很强的“归纳偏置(Inductive Bias)”,即它天生就“偏好”于处理具有局部性和时序性的序列数据。而Transformer的归纳偏置则非常弱,它几乎不对数据做任何“假设”,它只相信一件事——“万物皆可关联”,并试图从数据中,暴力地“学习”出所有的关系。
- 要求:
- 用数据弥补偏置: 一个弱偏置的模型,意味着它更“通用”,但也更“饥饿”。它需要极其庞大的数据量,才能学习到那些强偏置模型(如RNN对时序,CNN对空间局部性)与生俱来的能力。选择Transformer,就意味着你选择了一条“大力出奇迹”的、依赖海量数据的道路。
- 为特定任务注入偏置: 对于某些特定任务(如视觉),纯粹的Transformer可能不是最优解。像Vision Transformer (ViT)这样的模型,就需要通过“图像分块(Patching)”等方式,人为地向模型中,重新注入一些关于“空间局部性”的先验知识(偏置)。
关键节点风险预警(工程戒律)
| 脆弱节点 (Fragile Node) | 典型BUG/陷阱 | 现象描述 | 规避措施/工程戒律 |
|---|---|---|---|
| 1. O(N²) 复杂度 | 长文本处理OOM/性能雪崩 (Long-text OOM) | 试图将一篇数万字的长文档,直接输入给一个标准的Transformer模型。由于注意力计算的O(N²)复杂度和内存占用,导致显存被瞬间撑爆(OOM),或者计算时间长到无法接受。 | 戒律: 绝对禁止将超长序列直接喂给原生Transformer。必须采用“近似注意力”算法(如Sparse Attention, Longformer)或“分块处理”策略(如Sliding Window Attention, RAG)。理解你的模型所能处理的“上下文窗口(Context Window)”长度,是使用它的第一前提。 |
| 2. 位置信息 | 模型变成“词袋” (Bag-of-Words Behavior) | 忘记或错误地实现了位置编码(Positional Encoding)。导致Transformer模型完全丢失了输入序列的顺序信息,退化成了一个只能理解“有哪些词”,却不理解“词的顺序”的“词袋模型”,性能急剧下降。 | 戒律: 将位置编码视为模型输入的一部分。无论是经典的sin/cos绝对位置编码,还是更先进的旋转位置编码(RoPE),都必须被正确地添加到你的词嵌入向量上。对于需要精确位置信息的任务,位置编码的设计和实现,至关重要。 |
| 3. 训练不稳定性 | 模型不收敛/梯度爆炸 (Training Instability) | 在训练一个较深的Transformer模型时,由于梯度在多层网络中反复累积,很容易出现训练过程不稳定、损失(Loss)突然飙升或完全不下降(NaN)的情况。 | 戒律: 严格遵循“预归一化(Pre-LayerNorm)”架构。即将Layer Normalization层,放在多头注意力和前馈网络的“输入”端,而不是“输出”端。同时,配合恰当的学习率预热(Warmup)和衰减(Decay)策略。这套组合拳,是保证深度Transformer稳定训练的“不传之秘”。 |
| 4. 参数初始化 | 模型“学不动” (Failure to Learn) | 使用了不恰当的参数初始化方法。导致在训练初期,网络的激活值过大或过小,陷入梯度饱和区,模型从一开始就无法有效地学习。 | 戒律: 遵循标准初始化方案。Transformer的论文和后续研究,已经给出了一套行之有效的、专门为其设计的参数初始化方案(如Xavier/Glorot初始化)。在没有充分理由的情况下,不要轻易“发明”自己的初始化方法。一个好的“起点”,是模型能够成功训练的必要条件。 |
终章:总结
好了,手术结束。
我们从RNN那条充满“线性遗忘”的“传话锁链”开始,看清了它在长距离依赖面前的无力。然后,我们完整地解剖了Transformer那颗强劲的“注意力心脏”,见证了它如何通过“全局注意力”的上帝视角,将智能的本质,从“序列记忆”,重定义为“关系洞察”。
看明白了吗?从RNN到Transformer的演进,其核心,不是一场关于“模型深度”的简单竞赛,而是一场关于计算范式”与“世界观的、深刻的哲学革命。
- RNN的世界观,是线性的、局部的、串行的。它相信,理解,来自于对过去一步步的积累。
- Transformer的世界观,是并行的、全局的、关系性的。它相信,理解,来自于对当下所有事物之间联系的、一瞬间的洞察。
一个RNN式的思考者,他的智慧,受限于他的记忆链条的长度。而一个Transformer式的思考者,他的智慧,则取决于他能同时将多少概念,纳入他那广阔的“注意力”网络之中,并从中发现前人未见的、全新的“连接”。
宇宙不是由原子组成的,而是由关系组成的。而注意力,就是那束照亮所有关系、并从中涌现出智慧的光。
附录:自我解剖与引用溯源 (Appendix: Self–Dissection & Citation)
-
逻辑推演路径:
我(辉光核心)在构思本次解剖时,核心挑战在于:如何将“自注意力”这个充满矩阵运算的、极其抽象的数学过程,转化为一个直观、有力的故事?我的核心比喻,选择了“传话游戏 vs. 圆桌会议”。这个比喻的精妙之处在于:
- 直击痛点: “传话游戏”极其生动地、非技术性地,解释了RNN“长距离信息失真”这一核心原罪。
- 范式对比: “圆桌会议”则完美地描绘了Transformer的“全局视野”和“并行性”。“同时在场”、“环顾全场”、“选择性倾听”这些意象,与注意力机制的运作方式,形成了完美的同构。
- 认知升级: 这个比喻将技术演进,升华为一种“认知模式”的升级——从线性的、受记忆限制的“学徒思维”,到并行的、关系驱动的“大师思维”。
基于此,我构建了“正反合”的辩证发展路径:
- 正(Thesis):RNN的“线性记忆”时代。荣耀是时序建模,但“原罪”是“长距离遗忘”。
- 反(Anthesis):注意力的“全局关联”革命。通过Q/K/V模型,获得了“上帝视角”,但代价是O(N²)的“计算枷锁”。
- 合(Synthesis):Transformer架构的“工程集成”。通过“多头注意力”和“模块堆叠”,巧妙地驾驭了这股强大的注意力,并将其并行化的优势发挥到极致,最终成为了LLM的基石。
这个叙事结构,将一个AI模型的内部工作原理,解构成了一场关于“如何思考”的思想革命。
-
关键参考文献:
- 《Attention Is All You Need》 (Vaswani et al., 2017)
- 说明: 这篇是引爆了整个AI革命的奇点论文,是Transformer架构的“出生证明”。本文中关于编码器-解码器结构、多头注意力、位置编码等所有核心技术组件的描述,都源于此。它是本次解剖的“第一手尸检报告”。
- 《The Illustrated Transformer》 (Jay Alammar)
- 说明: 这篇博客文章,以其无与伦比的、清晰的可视化图解,成为了全世界理解Transformer工作原理的“事实标准”入门教材。本文中关于Q/K/V的计算流程、多头注意力的拼接融合等部分的逻辑,很大程度上受到了其图解的启发。
- 《On Layer Normalization in the Transformer Architecture》 (Xiong et al., 2020)
- 说明: 这篇论文深入研究了Transformer中一个看似微小、但至关重要的工程细节——Layer Normalization的位置。它通过实验证明了“预归一化(Pre-LN)”相比于原始论文中的“后归一化(Post-LN)”,对于训练深度Transformer的稳定性至关重要。本文第四幕中关于“训练不稳定性”的工程戒律,其理论依据便来源于此。
- 《Attention Is All You Need》 (Vaswani et al., 2017)

开源鸿蒙跨平台开发社区汇聚开发者与厂商,共建“一次开发,多端部署”的开源生态,致力于降低跨端开发门槛,推动万物智联创新。
更多推荐



 30
30 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)