Python中常用的数据可视化方法
本文介绍了Python中常用的数据可视化方法,包括直方图、密度图、箱型图、相关矩阵图和散点矩阵图。以乳腺癌和鸢尾花数据集为例,详细展示了如何使用Matplotlib和Seaborn库实现这些可视化工具。直方图和密度图用于展示数据分布特征,箱型图显示数据五数概括,相关矩阵图分析变量间相关性,散点矩阵图则展示多变量关系。这些可视化方法能有效帮助数据分析人员识别数据模式、异常值和变量间关系,为机器学习任
摘要:本文介绍了Python中常用的数据可视化方法,包括直方图、密度图、箱型图、相关矩阵图和散点矩阵图。以乳腺癌和鸢尾花数据集为例,详细展示了如何使用Matplotlib和Seaborn库实现这些可视化工具。直方图和密度图用于展示数据分布特征,箱型图显示数据五数概括,相关矩阵图分析变量间相关性,散点矩阵图则展示多变量关系。这些可视化方法能有效帮助数据分析人员识别数据模式、异常值和变量间关系,为机器学习任务提供直观的数据探索手段。
目录
直方图是一种条形图状的变量分布表示。它显示了该变量每个值出现的频率。横轴表示变量值的范围,纵轴表示每个值的频率或计数。每条条的高度代表落在该值范围内的数据点数量。
直方图有助于识别数据中的模式,如偏态、模态和离群值。偏态指的是变量分布的不对称程度。模态指的是分布中峰的数量。离群值是指超出该变量典型值范围的数据点。
Python 直方图的实现
Python 提供了多个用于数据可视化的库,如 Matplotlib、Seaborn、Plotly 和 Bokeh。以下示例中,我们将使用 Matplotlib 实现直方图。
我们将使用Sklearn库中的乳腺癌数据集作为示例。乳腺癌数据集包含乳腺癌细胞的特征信息,以及它们是恶性还是良性。该数据集包含30个特征和569个样本。
示例
我们先导入必要的库并加载数据集 −
import matplotlib.pyplot as plt
from sklearn.datasets import load_breast_cancer
data = load_breast_cancer()接下来,我们将创建数据集平均半径特征的直方图 −
plt.figure(figsize=(7.2, 3.5))
plt.hist(data.data[:,0], bins=20)
plt.xlabel('Mean Radius')
plt.ylabel('Frequency')
plt.show()在本代码中,我们使用 Matplotlib 中的 hist() 函数创建了数据集平均半径特征的直方图。我们已将箱数设置为20,以将数据范围划分为20个区间。我们还通过 xlabel() 和 ylabel() 函数在 x 轴和 y 轴上添加了标签。
输出
所得直方图显示了数据集中平均半径值的分布。我们可以看到数据大致呈正态分布,峰值大约在12-14之间。
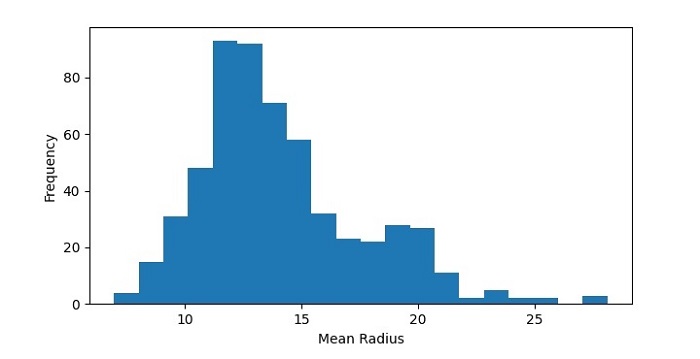
多数据集直方图
我们还可以创建一个包含多个数据集的直方图,以比较它们的分布。我们为恶性和良性样本创建平均半径特征的直方图 −
示例
plt.figure(figsize=(7.2, 3.5))
plt.hist(data.data[data.target==0,0], bins=20, alpha=0.5, label='Malignant')
plt.hist(data.data[data.target==1,0], bins=20, alpha=0.5, label='Benign')
plt.xlabel('Mean Radius')
plt.ylabel('Frequency')
plt.legend()
plt.show()在本代码中,我们两次使用hist()函数创建了平均半径特征的两个直方图,一个针对恶性样本,一个针对良性样本。我们用alpha参数将条形的透明度设置为0.5,这样它们不会完全重叠。我们还用legend()函数为图例添加了图例。
输出
执行该代码后,输出为如下图 −
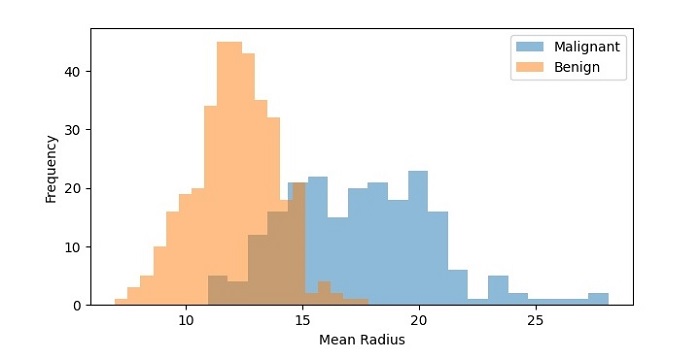
所得直方图显示了恶性和良性样本的平均半径分布。我们可以看到分布不同,恶性样本的频率更高,平均半径也更高。
密度图是一种显示连续变量概率密度函数的图。它类似于直方图,但不是用条表示每个值的频率,而是用平滑曲线表示概率密度函数。x轴表示变量的值范围,y轴表示概率密度。
密度图有助于识别数据中的模式,如偏态、模态和异常值。偏态指的是变量分布的不对称程度。模态指的是分布中峰的数量。离群值是指超出该变量典型值范围的数据点。
Python密度图的实现
Python 提供了多个用于数据可视化的库,如 Matplotlib、Seaborn、Plotly 和 Bokeh。在下面的示例中,我们将使用 Seaborn 来实现密度图。
我们将使用Sklearn库中的乳腺癌数据集作为示例。乳腺癌数据集包含乳腺癌细胞的特征信息,以及它们是恶性还是良性。该数据集包含30个特征和569个样本。
示例
我们先导入必要的库并加载数据集 −
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.datasets import load_breast_cancer
data = load_breast_cancer()接下来,我们将绘制数据集平均半径特征的密度图 −
plt.figure(figsize=(7.2, 3.5))
sns.kdeplot(data.data[:,0], shade=True)
plt.xlabel('Mean Radius')
plt.ylabel('Density')
plt.show()在本代码中,我们使用Seaborn的kdeplot()函数创建了数据集平均半径特征的密度图。我们已将shade参数设置为True,以对曲线下方的区域进行阴影。我们还通过 xlabel() 和 ylabel() 函数在 x 轴和 y 轴上添加了标签。
输出
所得密度图显示了数据集中平均半径值的概率密度函数。我们可以看到数据大致呈正态分布,峰值大约在12-14之间。
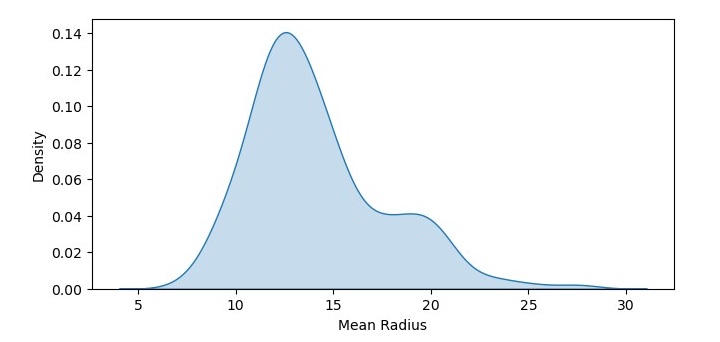
多数据集密度图
我们也可以用多个数据集绘制密度图,比较它们的概率密度函数。我们为恶性和良性样本均绘制平均半径特征的密度图 −
示例
plt.figure(figsize=(7.5, 3.5))
sns.kdeplot(data.data[data.target==0,0], shade=True, label='Malignant')
sns.kdeplot(data.data[data.target==1,0], shade=True, label='Benign')
plt.xlabel('Mean Radius')
plt.ylabel('Density')
plt.legend()
plt.show()在本代码中,我们两次使用kdeplot()函数创建了平均半径特征的两个密度图,一个为恶性样本,一个为良性样本。我们已将shade参数设置为True,以对曲线下方区域进行阴影,并且使用label参数在图上添加了标签。我们还用legend()函数为图例添加了图例。
输出
执行该代码后,输出为如下图 −
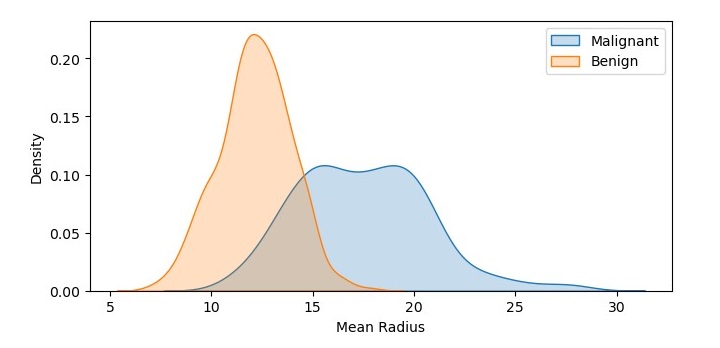
所得密度图显示了恶性和良性样本平均半径值的概率密度函数。我们可以看到恶性样本的概率密度函数向右移动,表明平均半径值更高。
箱型图是一种数据集的图形表示,显示数据的五个数字汇总——最小值、第一四分位数、中位数、第三四分位数和最大值。
盒图由一个盒子组成,盒子上下都有胡须。
该框代表数据的四分位数间距(IQR),即第一四分位数与第三四分位数之间的区间。
胡须从盒子的上下延伸到最大和最低的数值,这些数值在1.5倍的IQR范围内。
任何超出该范围的值被视为离群值,并表示为胡须之外的点。
Python 实现的方框图和胡须图
既然我们对箱型图有了基本了解,接下来用 Python 实现它们。以我们的例子为例,我们将使用Sklearn的鸢尾数据集,其中包含了150朵鸢尾花的萼片长度、宽度、花瓣长度和花瓣宽度,这些花属于三种不同物种——Setosa、Versicolor和Virginica。
首先,我们需要导入必要的库并加载数据集。
示例
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.datasets import load_iris
iris = load_iris()
data = iris.data
target = iris.target接下来,我们可以利用Seaborn库为三种鸢尾花种种绘制萼片长度的箱形图。
plt.figure(figsize=(7.5, 3.5))
sns.boxplot(x=target, y=data[:, 0])
plt.xlabel('Species')
plt.ylabel('Sepal Length (cm)')
plt.show()输出
该编码将生成三种鸢尾花种种的萼片长度箱形图,x轴表示物种,y轴代表萼片长度(厘米)。
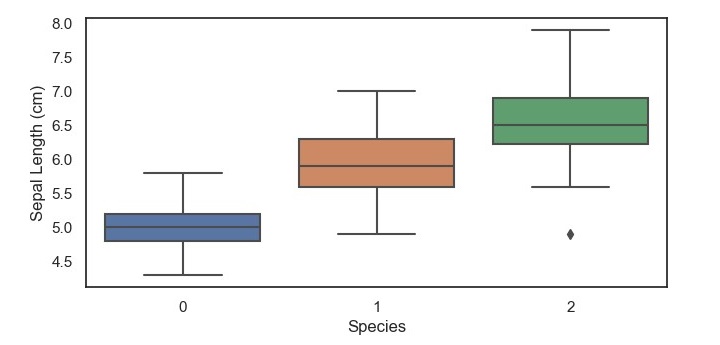
从这张箱形图中,我们可以看到,setosa属的萼片长度比versicolor和virginica属短,后者在萼片长度的中位数和范围上都相似。此外,我们可以看到setosa物种中没有异常值,但在versicolor和virginica物种中有一些例外。
相关矩阵图是数据集中变量间两两相关性的图形表示。该图由散点图和相关系数矩阵组成,每个散点图代表两个变量之间的关系,相关系数表示关系的强度。矩阵的对角线通常显示每个变量的分布。
相关系数是两个变量之间的线性关系度量,范围为-1到1。系数为1表示完全正相关,其中一个变量的增加与另一个变量的增加相关。系数为-1表示完全负相关,其中一个变量的增加与另一个变量的下降相关。系数为0表示变量之间无相关性。
Python 相关矩阵图的实现
现在我们对相关矩阵图有了基本的理解,接下来用Python实现它们。在我们的例子中,我们将使用Sklearn的鸢尾花数据集,其中包含了150朵鸢尾花的长度、宽度、花瓣长度和花瓣宽度,这些花属于三种不同物种——Setosa、Versicolor和Virginica。
示例
import numpy as np
import pandas as pd
import seaborn as sns
from sklearn.datasets import load_iris
iris = load_iris()
data = pd.DataFrame(iris.data, columns=iris.feature_names)
target = iris.target
plt.figure(figsize=(7.5, 3.5))
corr = data.corr()
sns.set(style='white')
mask = np.zeros_like(corr, dtype=np.bool)
mask[np.triu_indices_from(mask)] = True
f, ax = plt.subplots(figsize=(11, 9))
cmap = sns.diverging_palette(220, 10, as_cmap=True)
sns.heatmap(corr, mask=mask, cmap=cmap, vmax=.3, center=0,
square=True, linewidths=.5, cbar_kws={"shrink": .5})
plt.show()输出
该代码将生成 Iris 数据集的相关系数矩阵图,每个方格代表两个变量之间的相关系数。
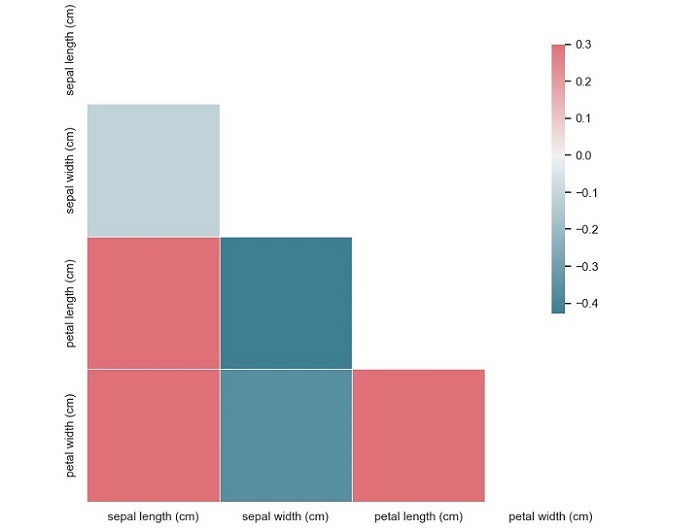
从图中可见,“萼片宽度(cm)”和“花瓣长度(cm)”的负相关性为中等(-0.37),而“花瓣长度(cm)”和“花瓣宽度(cm)”则呈强正相关(0.96)。我们还可以看到变量“萼片长度(cm)”与变量“花瓣长度(cm)”有弱正相关(0.87)。
散点矩阵图是一种多变量关系的图形表示。它是机器学习中可视化数据集中特征相关性的有用工具。该图也称为配对图,用于识别数据集中两个或多个变量之间的相关性。
散点矩阵图显示数据集中每对特征的散点图。每个散点图代表两个变量之间的关系。也可以在图中添加一条斜线,显示每个变量的分布。
Python散点矩阵图的实现
在这里,我们将用 Python 实现散点矩阵图。在下面的示例中,我们将使用Sklearn的Iris数据集。
Iris数据集是机器学习中的经典数据集。它包含四个特征:萼片长度、萼片宽度、花瓣长度和花瓣宽度。该数据集包含150个样本,每个样本被标记为三种物种之一:Setosa、Versicolor或Virginica。
我们将使用 Seaborn 库来实现散点矩阵图。Seaborn 是一个基于 Matplotlib 库构建的 Python 数据可视化库。
示例
以下是实现散射矩阵图的Python代码 −
import seaborn as sns
import pandas as pd
# load iris dataset
iris = sns.load_dataset('iris')
# create scatter matrix plot
sns.pairplot(iris, hue='species')
# show plot
plt.show()在这段代码中,我们首先导入必要的库,Seaborn 和 Pandas。然后,我们使用 sns.load_dataset() 函数加载 Iris 数据集。该函数从Seaborn库加载Iris数据集。
接下来,我们使用 sns.pairplot() 函数创建散点矩阵图。色相参数用于指定数据集中应用于色彩编码的列。在这种情况下,我们使用物种列根据每个样本的物种来给点着色。
最后,我们使用 plt.show() 函数来显示该图。
输出
该代码的输出将是一个散布矩阵图,显示Iris数据集中每对特征的散点图。
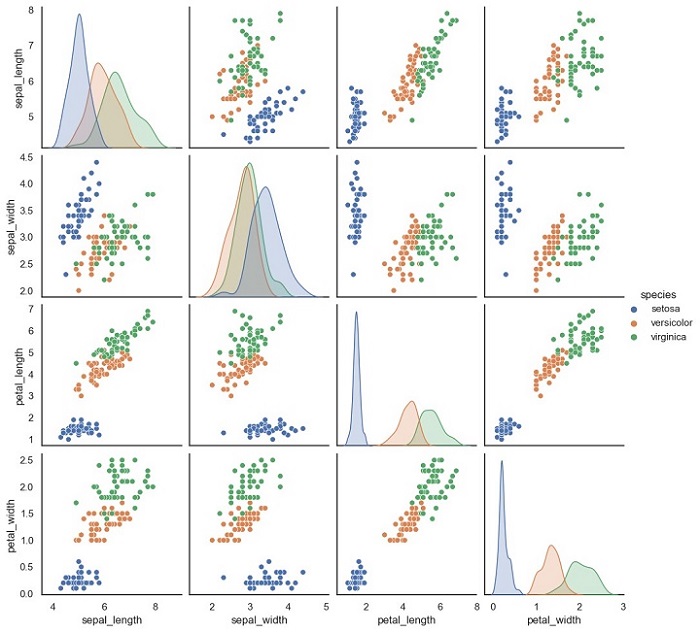
注意每个散点图根据每个样本的物种进行颜色编码。

开源鸿蒙跨平台开发社区汇聚开发者与厂商,共建“一次开发,多端部署”的开源生态,致力于降低跨端开发门槛,推动万物智联创新。
更多推荐
 15
15 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)