Kubernetes中Pod资源进阶底层讲解
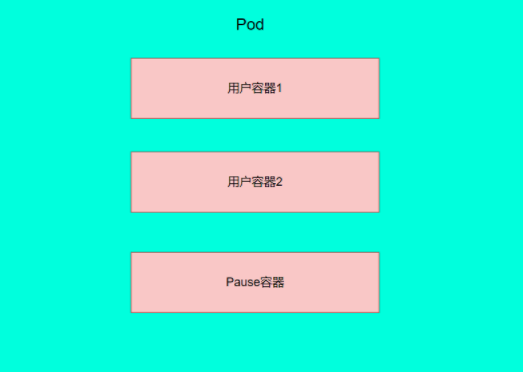
每个Pod中都可以包含一个或者多个容器,这些容器可以分为两类。
·
1. Pod底层原型
分类
每个Pod中都可以包含一个或者多个容器,这些容器可以分为两类
- 用户程序所在的容器,数量可多可少
- Pause容器,这是每个Pod都会有的一个根容器,它的作用有两个:
-
- 可以以它为依据,评估整个Pod的健康状态
- 可以在根容器上设置Ip地址,其它容器都以此Ip(Pod IP),以实现Pod内部的网路通信
实现原理
- 共享网络
-
- 通过pause容器,把其他业务容器加入到pause容器里面,让所有业务容器在同一个namespace中,可以实现网络共享
- 共享存储
-
- 引入数据卷volume的概念,使用数据卷进行持久化存储
2. pod镜像拉取策略imagesPullPolicy
- IfNotPresent:默认值,镜像在宿主机上不存在时才拉取
- Always:每次创建pod都会重新拉取一次镜像
- Never:pod永远不会主动拉取这个镜像

3. pod资源限制
- 说明:
-
- requests: 资源请求量,当容器运行时,向Node申请的最少保障资源
- limits: 资源上限,容器在Node上所能消耗的最高上限
resources:
requests:
memory:"内存大小"
cpu:"cpu占用大小"
limits:
memory:"内存占用大小"
cpu:"cpu占用大小"
——————————————————————————————————————————————
CPU 资源以 CPU 单位度量。Kubernetes 中的一个 CPU 等同于:
1 个 AWS vCPU
1 个 Azure vCore
例如 100m CPU、100 milliCPU 和 0.1 CPU 都相同
文档地址:
https://kubernetes.io/zh-cn/docs/tasks/configure-pod-container/assign-cpu-resource/
4. pod的创建流程
- 通过kubectl apply -f xxx.yaml 创建pod
- 创建pod的时候:
- kubectl向apiserver发送创建pod的请求
- apiserver把pod的创建信息存储到etcd进行保存
- scheduler监听到未绑定node的pod资源,通过调度算法对该pod资源选定一个合适的node进行绑定,然后响应给apiserver,更新pod状态并存储到etcd中
- 在绑定的node中,Controller-Manager通知kubelet收到分配到自身节点上的pod,调用容器引擎api创建容器,并把容器状态响应给apiserver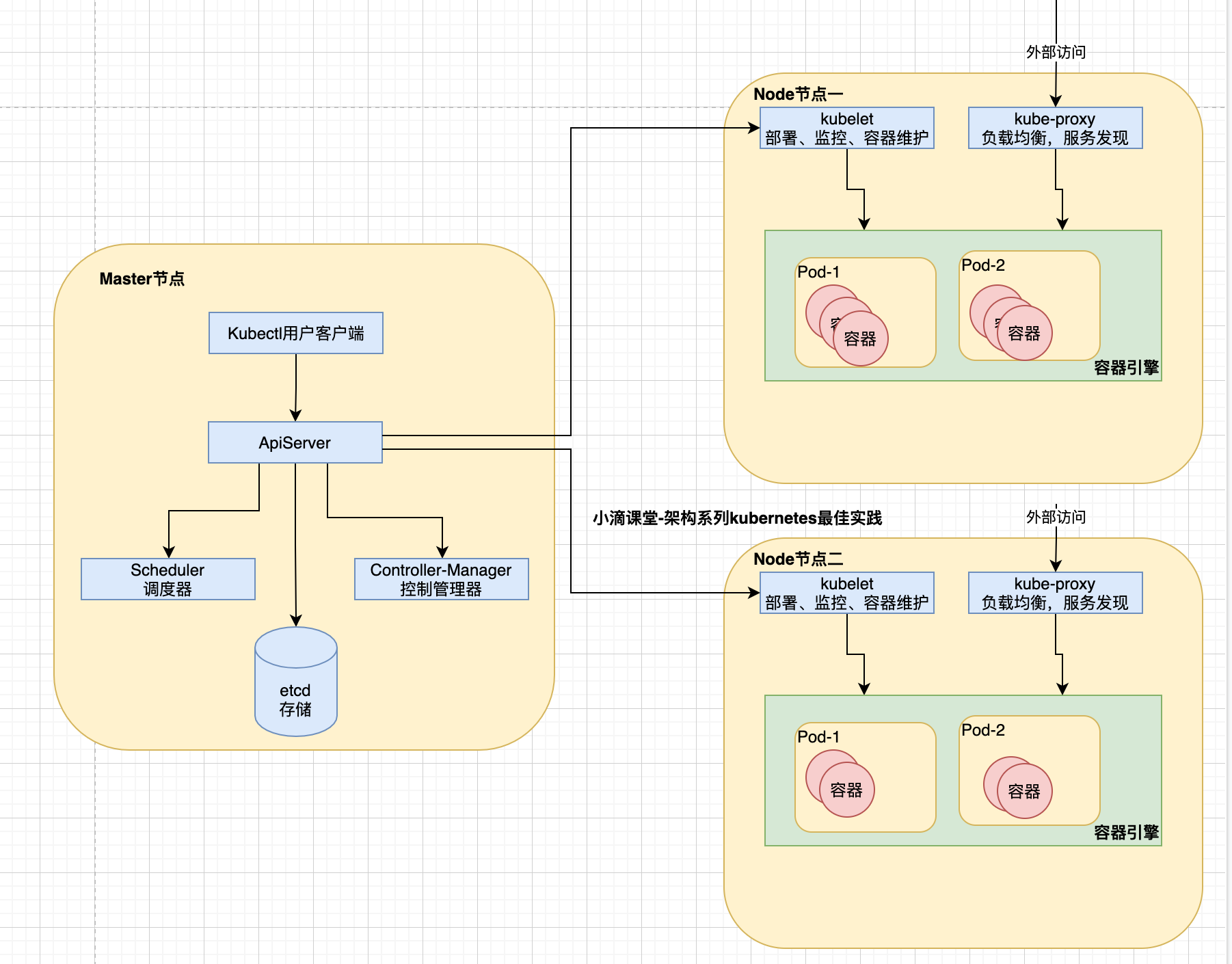
5. Pod的调度策略
- 在默认情况下,一个Pod在哪个Node节点上运行,是由Scheduler组件采用相应的算法计算出来的,这个过程是不受人工控制的。但是在实际使用中,这并不满足的需求,因为很多情况下,我们想控制某些Pod到达某些节点上,那么应该怎么做呢?这就要求了解k8s对Pod的调度规则
- 影响pod调度的因素:
-
- pod资源限制:scheduler根据requests找到足够大小的node进行调度
- 节点选择器标签(nodeSelector)
-
-
- 把节点进行区分,例如dev开发环境和prod生产环境
- 例如,当前需要把pod调度到开发环境中,则可以通过scheduler将pod调度到标签选择器中为env_role:dev的node中
-
nodeSelector:
env_role:dev/prod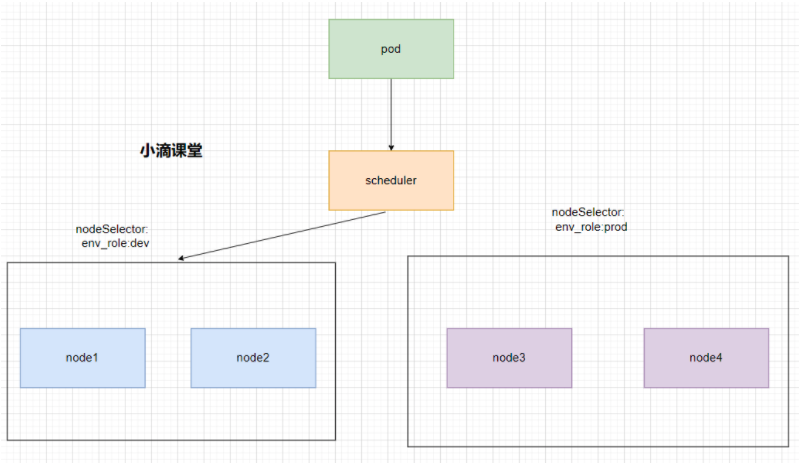

开源鸿蒙跨平台开发社区汇聚开发者与厂商,共建“一次开发,多端部署”的开源生态,致力于降低跨端开发门槛,推动万物智联创新。
更多推荐

 12
12 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)