深入浅出Kubernetes调度器:从基础原理到扩展实战全解析
本文深入解析Kubernetes调度器的核心原理与扩展机制,包括调度流程(过滤、打分、绑定)、两种扩展方案(Scheduler Extender和Scheduler Framework)的对比选择,并以异构算力调度案例HAMI展示实践应用。关键要点:理解调度器工作流程,根据业务需求合理选择扩展方案(Extender适合快速验证,Framework适合高性能场景),参考HAMI实现资源调度优化。文章
深入浅出Kubernetes调度器:从基础原理到扩展实战全解析
掌握Kubernetes调度器的核心机制,让你的集群资源利用率提升300%
今天要带大家深入探讨Kubernetes集群的"大脑"——调度器。无论是初学者还是资深运维,理解调度器的工作原理和扩展机制都是提升集群管理能力的关键!
一、Kubernetes调度器:集群的"智能调度中心"
核心功能解析
想象一下调度器就像一个大公司的HR总监,负责把新员工(Pod)安排到合适的部门(Node)工作。它的核心使命很简单但至关重要:
- 决策引擎:解决"哪个Pod该放到哪个节点上"的核心问题
- 资源优化器:确保应用能够稳定运行同时高效利用集群资源
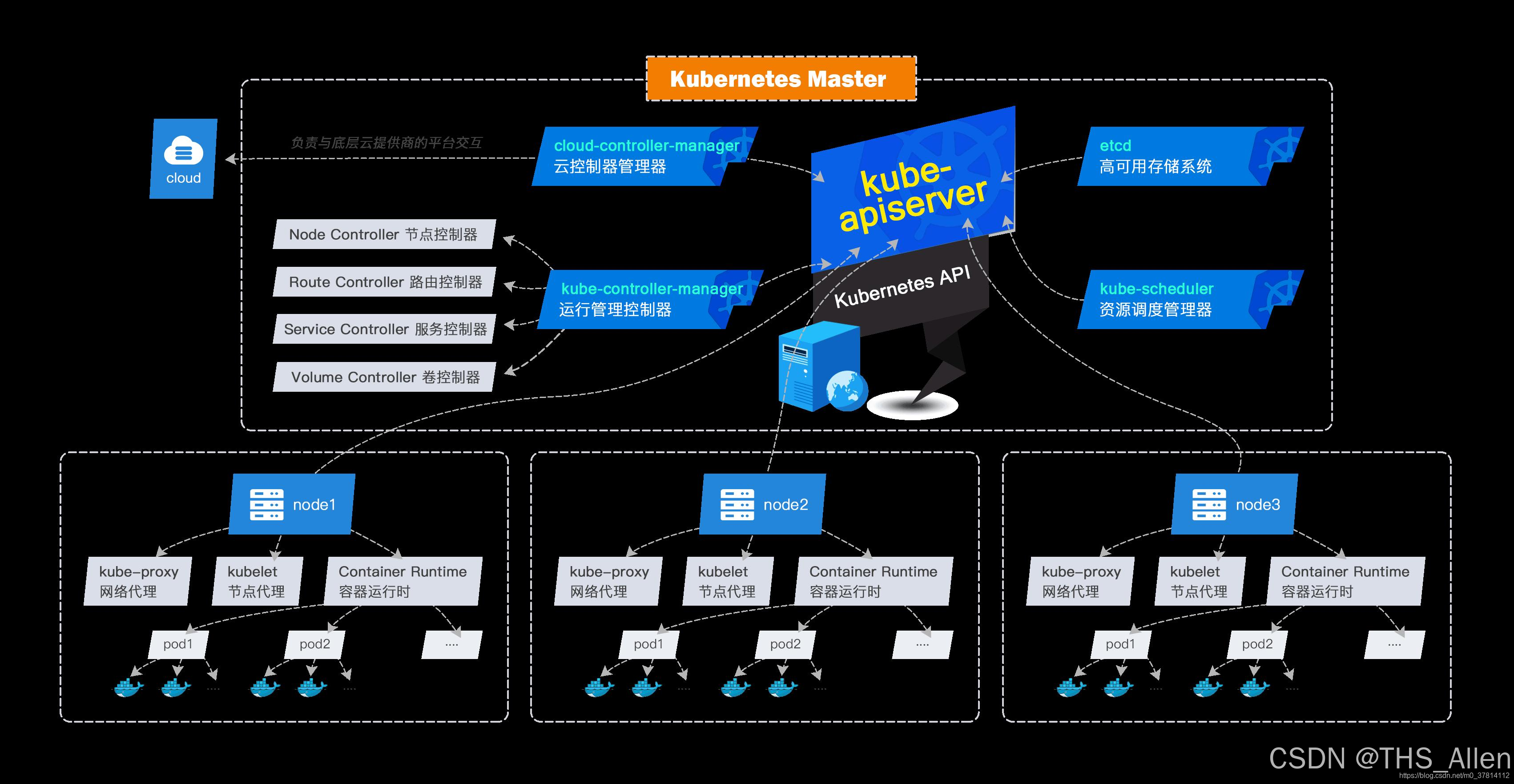
核心组件架构
kube-scheduler (调度核心)
↓
kube-apiserver (交互枢纽)
↓
etcd (状态存储)
工作流程就像一条精密的流水线:
- 调度队列 → Pod按优先级排队等待
- 调度周期 → 筛选合适的节点
- 绑定周期 → 最终确定并执行调度
二、调度流程深度拆解
从Pending到ContainerCreating的完整旅程
Pod创建 → 进入调度队列 → 过滤阶段 → 打分阶段 → 绑定执行 → Kubelet部署
过滤阶段(Filtering):淘汰不合格的节点
- 资源需求检查(CPU、内存)
- 端口冲突检测
- 节点亲和性验证
- 污点和容忍度匹配
打分阶段(Scoring):给合格节点评分
LeastRequestedPriority:倾向资源更充足的节点BalancedResourceAllocation:追求资源使用均衡- 自定义评分策略
三、调度器扩展机制:两种武器的选择
当默认调度策略无法满足业务需求时,Kubernetes提供了两种强大的扩展机制:
方案一:Scheduler Extender - “外部顾问”
工作原理:调度器通过HTTP/HTTPS与外部服务通信,在关键决策点寻求"专家建议"。
# kube-scheduler配置示例
apiVersion: kubescheduler.config.k8s.io/v1alpha1
kind: KubeSchedulerConfiguration
extenders:
- urlPrefix: "http://extender-service:80/"
filterVerb: "filter"
prioritizeVerb: "prioritize"
nodeCacheCapable: true
httpTimeout: 10s
ignorable: false
三大扩展点:
- Filter扩展:进一步过滤节点
- Score扩展:提供附加评分
- Bind扩展:执行自定义绑定逻辑
优势:
- 🎯 语言无关,可以用任何语言开发
- 🔄 版本兼容性好,不影响调度器升级
- 🚀 独立部署,故障隔离
劣势:
- ⚡ 网络通信带来性能开销
- 🔌 扩展点有限,只有三个关键阶段
- 📊 数据序列化/反序列化成本
方案二:Scheduler Framework - “原生插件”
从Kubernetes 1.15开始引入的新一代扩展机制,就像给调度器安装了"可插拔模块"。
核心思想:通过编译时插件的方式,在调度器的各个生命周期阶段注入自定义逻辑。
四、Scheduler Framework:调度器的"乐高积木"
Framework提供了丰富的扩展点,让开发者可以像搭积木一样构建自定义调度策略:
完整的扩展点生态
Scheduling Cycle:
Sort → PreFilter → Filter → PreScore → Score → Reserve → Permit
Binding Cycle:
PreBind → Bind → PostBind
核心扩展点详解
1. Sort(排序)
type QueueSortPlugin interface {
Plugin
Less(*PodInfo, *PodInfo) bool
}
- 调整Pod在调度队列中的顺序
- 只能启用一个Sort插件
2. PreFilter(预过滤)
- 预处理Pod信息
- 检查集群级约束条件
- 失败会终止整个调度周期
3. Filter(过滤)
- 并发检查节点可行性
- 任何插件拒绝即淘汰该节点
4. Score(打分)
type ScorePlugin interface {
Plugin
Score(ctx context.Context, state *CycleState, p *v1.Pod, nodeName string) (int64, *Status)
ScoreExtensions() ScoreExtensions
}
- 为节点评分,范围必须为[0,100]
- 支持分数归一化
5. Reserve(资源预留)
- 在实际绑定前预留节点资源
- 防止调度竞争条件
- 失败时会触发Unreserve进行清理
6. Permit(许可控制)
- 调度周期的最后关卡
- 三种决策:Approve(批准)、Deny(拒绝)、Wait(等待)
插件开发实战
// 自定义插件示例
type ThsFramework struct {
args *Args
handle framework.FrameworkHandle
}
func (t *ThsFramework) Name() string {
return "ThsFramework"
}
func New(configuration *runtime.Unknown, f framework.FrameworkHandle) (framework.Plugin, error) {
args := &Args{}
if err := framework.DecodeInto(configuration, args); err != nil {
return nil, err
}
return &ThsFramework{
args: args,
handle: f,
}, nil
}
配置文件:
apiVersion: kubescheduler.config.k8s.io/v1alpha1
kind: KubeSchedulerConfiguration
schedulerName: custom-scheduler
plugins:
queueSort:
enabled:
- name: "ThsFramework"
filter:
enabled:
- name: "ThsFramework"
score:
enabled:
- name: "ThsFramework"
pluginConfig:
- name: "ThsFramework"
args:
master: "master"
kubeconfig: "kubeconfig"
五、实战案例:异构算力调度-HAMI
在AI、大数据时代,GPU、NPU等异构计算资源的管理成为刚需。HAMI项目为我们展示了如何通过调度器扩展实现复杂的异构资源调度。
HAMI架构全景
Mutating Webhook → Scheduler Extender → Device Plugin → Container Runtime
支持的硬件生态:
- 🟢 NVIDIA GPU
- 🔵 Huawei NPU
- 🟠 Cambricon MLU
- 🟣 天数智芯 DCU
- … 更多国产芯片
四核心接口设计
-
/filter- 资源过滤- 解析Pod的显存、核心数、拓扑约束
- 调用设备插件打分逻辑
- 筛选并排序节点
-
/bind- 资源绑定- 设备级加锁防止并发争抢
- 调用kube-apiserver完成绑定
- 异常时回滚保障数据一致性
-
/webhook- Pod变异- 自动补齐GPU资源默认值
- 限制特权容器
- 注入环境变量和资源配置
-
/healthz- 健康检查
智能打分机制
HAMI实现了双层打分策略:
节点层面:
- 基于整体资源利用率评分
- 支持Binpack(装箱优化)和Spread(分散部署)策略
设备层面:
// 核心打分逻辑
DeviceListsScore.ComputeScore()
- 计算已分配GPU数量、核心使用率、显存使用率
- 归一化处理得到最终分数
- NUMA感知,优先选择同NUMA资源
原子性绑定保障
HAMI的绑定过程体现了企业级稳定性设计:
- 数据一致性:实时拉取最新Pod和Node信息
- 并发控制:设备级锁机制防止资源竞争
- 事务保障:绑定失败自动回滚释放资源
- 状态追踪:通过注解记录绑定阶段状态
设备插件深度集成
HAMI的设备插件基于NVIDIA官方插件扩展,实现:
- 自动发现:通过NVML、MIG拓扑构建设备列表
- 资源注册:将物理设备映射为Kubernetes资源
- 动态配置:为容器注入环境变量、库文件挂载
- 生命周期管理:监听kubelet重启,自动重建插件
六、扩展方案选型指南
什么时候选择Scheduler Extender?
✅ 适合场景:
- 快速验证调度策略
- 多语言技术栈环境
- 需要与外部系统深度集成
- 希望独立于调度器版本升级
什么时候选择Scheduler Framework?
✅ 适合场景:
- 性能要求极高的生产环境
- 需要精细化的调度控制
- 与Kubernetes生态深度集成
- 长期维护的核心调度策略
七、总结与最佳实践
通过本文的深度解析,我们可以看到Kubernetes调度器提供了极其灵活和强大的扩展机制。无论是简单的节点过滤还是复杂的异构资源调度,都能找到合适的解决方案。
关键收获:
- 理解核心流程:掌握调度周期和绑定周期的每个阶段
- 合理选择方案:根据业务需求选择Extender或Framework
- 学习最佳实践:参考HAMI等成熟项目的架构设计
- 注重稳定性:原子操作、异常回滚、状态管理
未来展望:
随着云原生和AI的深度融合,调度器将面临更多挑战:跨集群调度、QoS保障、能耗优化等。掌握调度器扩展技术,将成为云原生工程师的核心竞争力。
思考题:在你的业务场景中,最需要什么样的自定义调度策略?欢迎在评论区分享你的需求和挑战!
本文基于Kubernetes官方文档和HAMI项目实践整理,希望对你的云原生之旅有所帮助!

开源鸿蒙跨平台开发社区汇聚开发者与厂商,共建“一次开发,多端部署”的开源生态,致力于降低跨端开发门槛,推动万物智联创新。
更多推荐
 32
32 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)