【技术】从POD创建看Kubernetes源码实现 (四)- kube-scheduler
【技术】从POD创建看Kubernetes源码实现 (四)- kube-scheduler
✍️ 作者:茶水间Tech
🏷️ 标签:#云计算#云原生#kubernetes#容器
📖 前言
kubernetes的模块比较多,架构复杂,代码量更是庞大,看代码比较麻烦,我们从现实场景出发,从创建POD分析在Kubernetes内部的代码流程,本系列文章从POD创建,整体梳理Kubernetes源码实现,其中本节主要分析kube-scheduler侧的流程实现。
本文基于 Client Version: v1.34.3 , Server Version: v1.34.2
📌 POD创建的整体架构图:
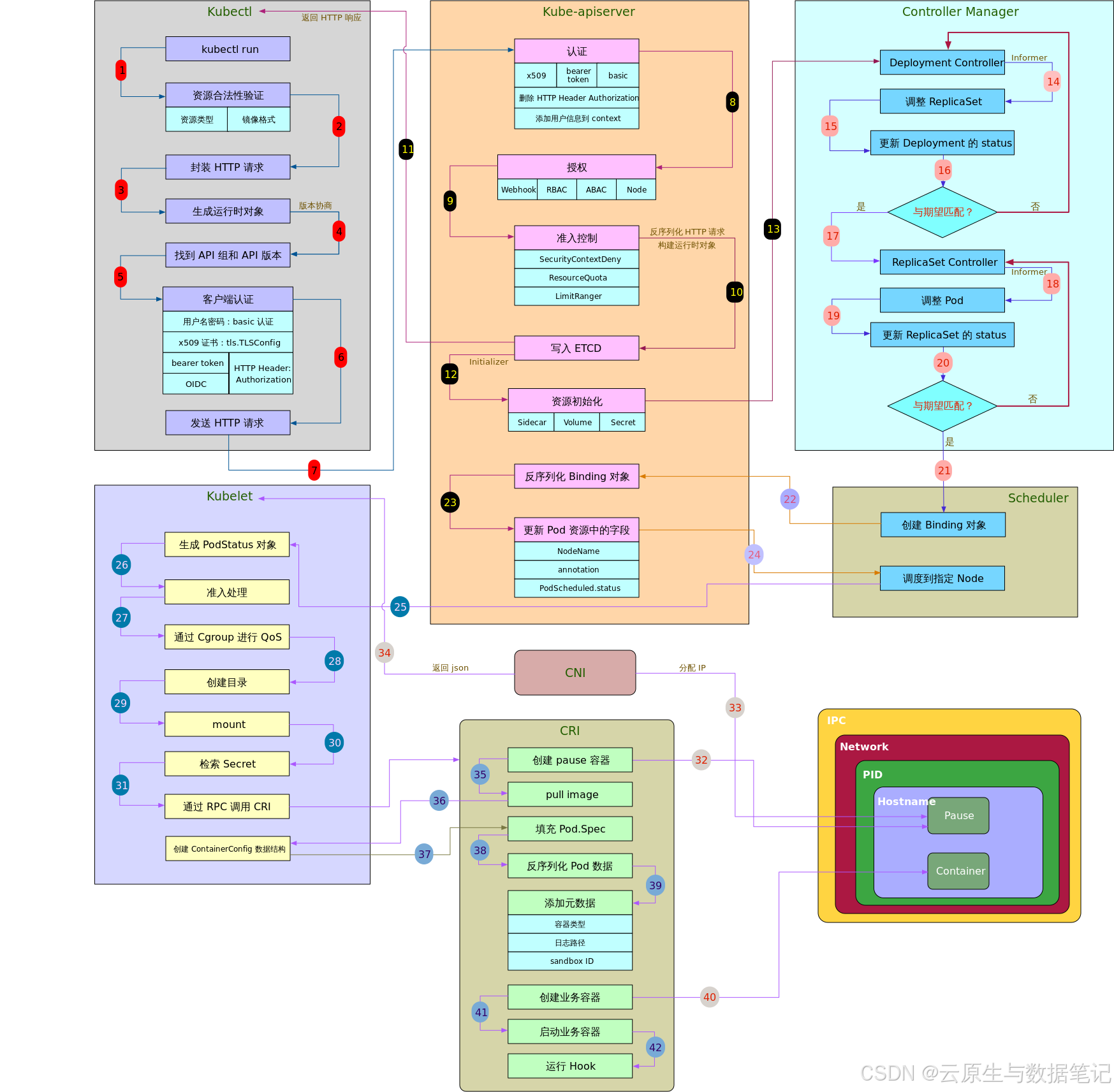
💻 正文
📑 一、关于kube-scheduler
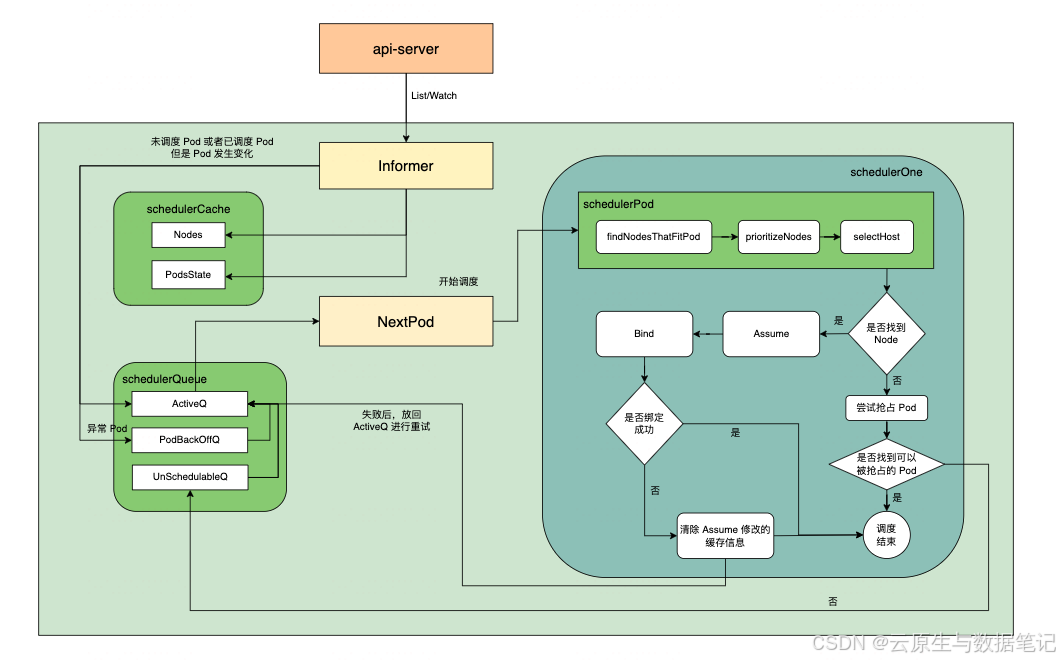
kube-scheduler组件是Kubernetes集群的默认调度器,负责将Pod调度到合适的集群节点上运行,只负责调度,监听到所有nodeName为空的Pod时,为他们选择一个最合适的Node,白话点是个”只动嘴不动手“的组件。
📑 二、代码分析
详细流程如下:
程序入口:Run (scheduler.go)
阻塞读取有NodeName为空的POD,然后进行调度POD
代码路径:kubernetes/pkg/scheduler/scheduler.go
func (sched *Scheduler) Run(ctx context.Context) {
logger := klog.FromContext(ctx)
// 阻塞直到有 NodeName 为空的 Pod 出现
sched.SchedulingQueue.Run(logger)
if sched.APIDispatcher != nil {
sched.APIDispatcher.Run(logger)
}
//开启调度POD
// We need to start scheduleOne loop in a dedicated goroutine,
// because scheduleOne function hangs on getting the next item
// from the SchedulingQueue.
// If there are no new pods to schedule, it will be hanging there
// and if done in this goroutine it will be blocking closing
// SchedulingQueue, in effect causing a deadlock on shutdown.
go wait.UntilWithContext(ctx, sched.ScheduleOne, 0)
<-ctx.Done()
if sched.APIDispatcher != nil {
sched.APIDispatcher.Close()
}
sched.SchedulingQueue.Close()
// If the plugins satisfy the io.Closer interface, they are closed.
err := sched.Profiles.Close()
if err != nil {
logger.Error(err, "Failed to close plugins")
}
}
2.1 调度POD(scheduler_one.go)
ScheduleOne会监听阻塞,直到取到了node通知。然后通过调度框架对node进行filter,当调度出主机node后,调度器开启一个 Goroutine 异步执行 Bind 操作,向 API Server 发送一个 Binding 对象,修改 Pod 的 spec.nodeName。
代码路径:kubernetes/pkg/scheduler/scheduler_one.go
func (sched *Scheduler) ScheduleOne(ctx context.Context) {
logger := klog.FromContext(ctx)
// 阻塞直到有 NodeName 为空的 Pod 出现
podInfo, err := sched.NextPod(logger)
if err != nil {
utilruntime.HandleErrorWithContext(ctx, err, "Error while retrieving next pod from scheduling queue")
return
}
// ...(略)
logger.V(4).Info("About to try and schedule pod", "pod", klog.KObj(pod))
// 选择POD的调度框架,schedulerName未指定则使用默认调度框架
fwk, err := sched.frameworkForPod(pod)
// ...(略)
schedulingCycleCtx, cancel := context.WithCancel(ctx)
defer cancel()
// 开始根据框架filter规则调度POD
scheduleResult, assumedPodInfo, status := sched.schedulingCycle(schedulingCycleCtx, state, fwk, podInfo, start, podsToActivate)
if !status.IsSuccess() {
sched.FailureHandler(schedulingCycleCtx, fwk, assumedPodInfo, status, scheduleResult.nominatingInfo, start)
return
}
//异步将pod绑定到host
// bind the pod to its host asynchronously (we can do this b/c of the assumption step above).
go func() {
bindingCycleCtx, cancel := context.WithCancel(ctx)
defer cancel()
metrics.Goroutines.WithLabelValues(metrics.Binding).Inc()
defer metrics.Goroutines.WithLabelValues(metrics.Binding).Dec()
status := sched.bindingCycle(bindingCycleCtx, state, fwk, scheduleResult, assumedPodInfo, start, podsToActivate)
if !status.IsSuccess() {
sched.handleBindingCycleError(bindingCycleCtx, state, fwk, assumedPodInfo, start, scheduleResult, status)
return
}
}()
}
2.2 核心调度:SchedulePod (scheduler_one.go)
调度器调用 sched.schedulePod(),这是最烧脑的地方。它基于 Scheduling Framework (调度框架) 设计,通过各种插件(Plugins)来执行逻辑。
- Filter (过滤阶段)
- 检查节点资源够不够(CPU/RAM)。
- 检查是否有污点(Taints/Tolerations)。
- 检查端口是否冲突。
- 源码位置:
pkg/scheduler/framework/plugins/下有大量实现。
- Score (打分阶段)
- LeastRequestedPriority: 选剩余资源最多的节点(负载均衡)。
- ImageLocalityPriority: 选已经有该镜像的节点(启动快)。
- NodeAffinity: 节点亲和性打分。
乐观假设:
为了提高并发效率,调度器不会等 API Server 写入成功再处理下一个 Pod。它会先在内存缓存 (Scheduler Cache) 中把这个 Pod “假装”已经分配到了该节点上。
绑定 (Bind) —— 最终动作
最后,调度器开启一个 Goroutine 异步执行 Bind 操作。
逻辑:向 API Server 发送一个 Binding 对象,修改 Pod 的 spec.nodeName。
代码路径:kubernetes/pkg/scheduler/scheduler_one.go
func (sched *Scheduler) schedulingCycle(
ctx context.Context,
state fwk.CycleState,
schedFramework framework.Framework,
podInfo *framework.QueuedPodInfo,
start time.Time,
podsToActivate *framework.PodsToActivate,
) (ScheduleResult, *framework.QueuedPodInfo, *fwk.Status) {
logger := klog.FromContext(ctx)
pod := podInfo.Pod
scheduleResult, err := sched.SchedulePod(ctx, schedFramework, state, pod)
// ...(略)
// This allows us to keep scheduling without waiting on binding to occur.
assumedPodInfo := podInfo.DeepCopy()
assumedPod := assumedPodInfo.Pod
// 乐观假设
// assume modifies `assumedPod` by setting NodeName=scheduleResult.SuggestedHost
err = sched.assume(logger, assumedPod, scheduleResult.SuggestedHost)
if err != nil {
// This is most probably result of a BUG in retrying logic.
// We report an error here so that pod scheduling can be retried.
// This relies on the fact that Error will check if the pod has been bound
// to a node and if so will not add it back to the unscheduled pods queue
// (otherwise this would cause an infinite loop).
return ScheduleResult{nominatingInfo: sched.newFailureNominatingInfo()}, assumedPodInfo, fwk.AsStatus(err)
}
// Run the Reserve method of reserve plugins.
if sts := schedFramework.RunReservePluginsReserve(ctx, state, assumedPod, scheduleResult.SuggestedHost); !sts.IsSuccess() {
// trigger un-reserve to clean up state associated with the reserved Pod
schedFramework.RunReservePluginsUnreserve(ctx, state, assumedPod, scheduleResult.SuggestedHost)
if forgetErr := sched.Cache.ForgetPod(logger, assumedPod); forgetErr != nil {
utilruntime.HandleErrorWithContext(ctx, forgetErr, "Scheduler cache ForgetPod failed")
}
if sts.IsRejected() {
fitErr := &framework.FitError{
NumAllNodes: 1,
Pod: pod,
Diagnosis: framework.Diagnosis{
NodeToStatus: framework.NewDefaultNodeToStatus(),
},
}
fitErr.Diagnosis.NodeToStatus.Set(scheduleResult.SuggestedHost, sts)
fitErr.Diagnosis.AddPluginStatus(sts)
return ScheduleResult{nominatingInfo: sched.newFailureNominatingInfo()}, assumedPodInfo, fwk.NewStatus(sts.Code()).WithError(fitErr)
}
return ScheduleResult{nominatingInfo: sched.newFailureNominatingInfo()}, assumedPodInfo, sts
}
// Run "permit" plugins.
runPermitStatus := schedFramework.RunPermitPlugins(ctx, state, assumedPod, scheduleResult.SuggestedHost)
if !runPermitStatus.IsWait() && !runPermitStatus.IsSuccess() {
// trigger un-reserve to clean up state associated with the reserved Pod
schedFramework.RunReservePluginsUnreserve(ctx, state, assumedPod, scheduleResult.SuggestedHost)
if forgetErr := sched.Cache.ForgetPod(logger, assumedPod); forgetErr != nil {
utilruntime.HandleErrorWithContext(ctx, forgetErr, "Scheduler cache ForgetPod failed")
}
if runPermitStatus.IsRejected() {
fitErr := &framework.FitError{
NumAllNodes: 1,
Pod: pod,
Diagnosis: framework.Diagnosis{
NodeToStatus: framework.NewDefaultNodeToStatus(),
},
}
fitErr.Diagnosis.NodeToStatus.Set(scheduleResult.SuggestedHost, runPermitStatus)
fitErr.Diagnosis.AddPluginStatus(runPermitStatus)
return ScheduleResult{nominatingInfo: sched.newFailureNominatingInfo()}, assumedPodInfo, fwk.NewStatus(runPermitStatus.Code()).WithError(fitErr)
}
return ScheduleResult{nominatingInfo: sched.newFailureNominatingInfo()}, assumedPodInfo, runPermitStatus
}
// At the end of a successful scheduling cycle, pop and move up Pods if needed.
if len(podsToActivate.Map) != 0 {
sched.SchedulingQueue.Activate(logger, podsToActivate.Map)
// Clear the entries after activation.
podsToActivate.Map = make(map[string]*v1.Pod)
}
return scheduleResult, assumedPodInfo, nil
}
schedulePod尝试在node列表中为已知POD调度选择一台node,成功会返回node名称,失败会返回失败原因
代码路径:kubernetes/pkg/scheduler/scheduler_one.go
func (sched *Scheduler) schedulePod(ctx context.Context, fwk framework.Framework, state fwk.CycleState, pod *v1.Pod) (result ScheduleResult, err error) {
trace := utiltrace.New("Scheduling", utiltrace.Field{Key: "namespace", Value: pod.Namespace}, utiltrace.Field{Key: "name", Value: pod.Name})
defer trace.LogIfLong(100 * time.Millisecond)
if err := sched.Cache.UpdateSnapshot(klog.FromContext(ctx), sched.nodeInfoSnapshot); err != nil {
return result, err
}
trace.Step("Snapshotting scheduler cache and node infos done")
if sched.nodeInfoSnapshot.NumNodes() == 0 {
return result, ErrNoNodesAvailable
}
feasibleNodes, diagnosis, err := sched.findNodesThatFitPod(ctx, fwk, state, pod)
if err != nil {
return result, err
}
trace.Step("Computing predicates done")
if len(feasibleNodes) == 0 {
return result, &framework.FitError{
Pod: pod,
NumAllNodes: sched.nodeInfoSnapshot.NumNodes(),
Diagnosis: diagnosis,
}
}
// When only one node after predicate, just use it.
if len(feasibleNodes) == 1 {
return ScheduleResult{
SuggestedHost: feasibleNodes[0].Node().Name,
EvaluatedNodes: 1 + diagnosis.NodeToStatus.Len(),
FeasibleNodes: 1,
}, nil
}
priorityList, err := prioritizeNodes(ctx, sched.Extenders, fwk, state, pod, feasibleNodes)
if err != nil {
return result, err
}
host, _, err := selectHost(priorityList, numberOfHighestScoredNodesToReport)
trace.Step("Prioritizing done")
return ScheduleResult{
SuggestedHost: host,
EvaluatedNodes: len(feasibleNodes) + diagnosis.NodeToStatus.Len(),
FeasibleNodes: len(feasibleNodes),
}, err
}
2.3 找出node:findNodesThatFitPod(scheduler_one.go)
基于调度框架从所有nodes中filter出合适的node
代码路径:kubernetes/pkg/scheduler/scheduler_one.go
func (sched *Scheduler) findNodesThatFitPod(ctx context.Context, schedFramework framework.Framework, state fwk.CycleState, pod *v1.Pod) ([]fwk.NodeInfo, framework.Diagnosis, error) {
logger := klog.FromContext(ctx)
diagnosis := framework.Diagnosis{
NodeToStatus: framework.NewDefaultNodeToStatus(),
}
// 取出所有node列表
allNodes, err := sched.nodeInfoSnapshot.NodeInfos().List()
if err != nil {
return nil, diagnosis, err
}
// Run "prefilter" plugins.
preRes, s, unscheduledPlugins := schedFramework.RunPreFilterPlugins(ctx, state, pod)
diagnosis.UnschedulablePlugins = unscheduledPlugins
if !s.IsSuccess() {
if !s.IsRejected() {
return nil, diagnosis, s.AsError()
}
// All nodes in NodeToStatus will have the same status so that they can be handled in the preemption.
diagnosis.NodeToStatus.SetAbsentNodesStatus(s)
// Record the messages from PreFilter in Diagnosis.PreFilterMsg.
msg := s.Message()
diagnosis.PreFilterMsg = msg
logger.V(5).Info("Status after running PreFilter plugins for pod", "pod", klog.KObj(pod), "status", msg)
diagnosis.AddPluginStatus(s)
return nil, diagnosis, nil
}
// "NominatedNodeName" can potentially be set in a previous scheduling cycle as a result of preemption.
// This node is likely the only candidate that will fit the pod, and hence we try it first before iterating over all nodes.
if len(pod.Status.NominatedNodeName) > 0 {
feasibleNodes, err := sched.evaluateNominatedNode(ctx, pod, schedFramework, state, diagnosis)
if err != nil {
utilruntime.HandleErrorWithContext(ctx, err, "Evaluation failed on nominated node", "pod", klog.KObj(pod), "node", pod.Status.NominatedNodeName)
}
// Nominated node passes all the filters, scheduler is good to assign this node to the pod.
if len(feasibleNodes) != 0 {
return feasibleNodes, diagnosis, nil
}
}
nodes := allNodes
if !preRes.AllNodes() {
nodes = make([]fwk.NodeInfo, 0, len(preRes.NodeNames))
for nodeName := range preRes.NodeNames {
// PreRes may return nodeName(s) which do not exist; we verify
// node exists in the Snapshot.
if nodeInfo, err := sched.nodeInfoSnapshot.Get(nodeName); err == nil {
nodes = append(nodes, nodeInfo)
}
}
diagnosis.NodeToStatus.SetAbsentNodesStatus(fwk.NewStatus(fwk.UnschedulableAndUnresolvable, fmt.Sprintf("node(s) didn't satisfy plugin(s) %v", sets.List(unscheduledPlugins))))
}
feasibleNodes, err := sched.findNodesThatPassFilters(ctx, schedFramework, state, pod, &diagnosis, nodes)
// always try to update the sched.nextStartNodeIndex regardless of whether an error has occurred
// this is helpful to make sure that all the nodes have a chance to be searched
processedNodes := len(feasibleNodes) + diagnosis.NodeToStatus.Len()
sched.nextStartNodeIndex = (sched.nextStartNodeIndex + processedNodes) % len(allNodes)
if err != nil {
return nil, diagnosis, err
}
feasibleNodesAfterExtender, err := findNodesThatPassExtenders(ctx, sched.Extenders, pod, feasibleNodes, diagnosis.NodeToStatus)
if err != nil {
return nil, diagnosis, err
}
if len(feasibleNodesAfterExtender) != len(feasibleNodes) {
// Extenders filtered out some nodes.
//
// Extender doesn't support any kind of requeueing feature like EnqueueExtensions in the scheduling framework.
// When Extenders reject some Nodes and the pod ends up being unschedulable,
// we put framework.ExtenderName to pInfo.UnschedulablePlugins.
// This Pod will be requeued from unschedulable pod pool to activeQ/backoffQ
// by any kind of cluster events.
// https://github.com/kubernetes/kubernetes/issues/122019
if diagnosis.UnschedulablePlugins == nil {
diagnosis.UnschedulablePlugins = sets.New[string]()
}
diagnosis.UnschedulablePlugins.Insert(framework.ExtenderName)
}
return feasibleNodesAfterExtender, diagnosis, nil
}
2.4 filter Node:findNodesThatPassFilters(scheduler_one.go)
findNodesThatPassFilters 是 Kubernetes 调度器中筛选节点的关键部分,遍历所有node进行filter,并发检查所有node直到找出符合预期数量的node。
代码路径:kubernetes/pkg/scheduler/scheduler_one.go
func (sched *Scheduler) findNodesThatPassFilters(
ctx context.Context,
schedFramework framework.Framework,
state fwk.CycleState,
pod *v1.Pod,
diagnosis *framework.Diagnosis,
nodes []fwk.NodeInfo) ([]fwk.NodeInfo, error) {
numAllNodes := len(nodes)
numNodesToFind := sched.numFeasibleNodesToFind(schedFramework.PercentageOfNodesToScore(), int32(numAllNodes))
if !sched.hasExtenderFilters() && !sched.hasScoring(schedFramework) {
numNodesToFind = 1
}
// Create feasible list with enough space to avoid growing it
// and allow assigning.
feasibleNodes := make([]fwk.NodeInfo, numNodesToFind)
if !schedFramework.HasFilterPlugins() {
for i := range feasibleNodes {
feasibleNodes[i] = nodes[(sched.nextStartNodeIndex+i)%numAllNodes]
}
return feasibleNodes, nil
}
errCh := parallelize.NewErrorChannel()
var feasibleNodesLen int32
ctx, cancel := context.WithCancelCause(ctx)
defer cancel(errors.New("findNodesThatPassFilters has completed"))
type nodeStatus struct {
node string
status *fwk.Status
}
result := make([]*nodeStatus, numAllNodes)
// 核心检查函数
checkNode := func(i int) {
// We check the nodes starting from where we left off in the previous scheduling cycle,
// this is to make sure all nodes have the same chance of being examined across pods.
// 计算要检查的节点索引,使用轮询机制
nodeInfo := nodes[(sched.nextStartNodeIndex+i)%numAllNodes]
// 运行所有过滤插件检查节点是否适合
status := schedFramework.RunFilterPluginsWithNominatedPods(ctx, state, pod, nodeInfo)
if status.Code() == fwk.Error {
errCh.SendErrorWithCancel(status.AsError(), func() {
cancel(errors.New("some other Filter operation failed"))
})
return
}
if status.IsSuccess() {
// 原子操作增加可行节点计数
length := atomic.AddInt32(&feasibleNodesLen, 1)
// 如果找到足够的节点,取消继续查找
if length > numNodesToFind {
cancel(errors.New("findNodesThatPassFilters has found enough nodes"))
atomic.AddInt32(&feasibleNodesLen, -1)
} else {
feasibleNodes[length-1] = nodeInfo
}
} else {
result[i] = &nodeStatus{node: nodeInfo.Node().Name, status: status}
}
}
beginCheckNode := time.Now()
statusCode := fwk.Success
defer func() {
// We record Filter extension point latency here instead of in framework.go because framework.RunFilterPlugins
// function is called for each node, whereas we want to have an overall latency for all nodes per scheduling cycle.
// Note that this latency also includes latency for `addNominatedPods`, which calls framework.RunPreFilterAddPod.
metrics.FrameworkExtensionPointDuration.WithLabelValues(metrics.Filter, statusCode.String(), schedFramework.ProfileName()).Observe(metrics.SinceInSeconds(beginCheckNode))
}()
// Stops searching for more nodes once the configured number of feasible nodes
// are found.
//并发检查node
schedFramework.Parallelizer().Until(ctx, numAllNodes, checkNode, metrics.Filter)
feasibleNodes = feasibleNodes[:feasibleNodesLen]
for _, item := range result {
if item == nil {
continue
}
diagnosis.NodeToStatus.Set(item.node, item.status)
diagnosis.AddPluginStatus(item.status)
}
if err := errCh.ReceiveError(); err != nil {
statusCode = fwk.Error
return feasibleNodes, err
}
return feasibleNodes, nil
}
2.5 Filter 匹配:RunFilterPlugins (framework.go)
调用调度框架对POD进行Filter匹配,执行RunFilterPluginsWithNominatedPods() 运行RunFilterPlugins ,遍历 f.filterPlugins 对node 进行所有插件进行**Filter()**判断
代码路径:kubernetes/pkg/scheduler/framework/runtime/framework.go
func (f *frameworkImpl) RunFilterPluginsWithNominatedPods(ctx context.Context, state fwk.CycleState, pod *v1.Pod, info fwk.NodeInfo) *fwk.Status {
var status *fwk.Status
podsAdded := false
// We run filters twice in some cases. If the node has greater or equal priority
// nominated pods, we run them when those pods are added to PreFilter state and nodeInfo.
// If all filters succeed in this pass, we run them again when these
// nominated pods are not added. This second pass is necessary because some
// filters such as inter-pod affinity may not pass without the nominated pods.
// If there are no nominated pods for the node or if the first run of the
// filters fail, we don't run the second pass.
// We consider only equal or higher priority pods in the first pass, because
// those are the current "pod" must yield to them and not take a space opened
// for running them. It is ok if the current "pod" take resources freed for
// lower priority pods.
// Requiring that the new pod is schedulable in both circumstances ensures that
// we are making a conservative decision: filters like resources and inter-pod
// anti-affinity are more likely to fail when the nominated pods are treated
// as running, while filters like pod affinity are more likely to fail when
// the nominated pods are treated as not running. We can't just assume the
// nominated pods are running because they are not running right now and in fact,
// they may end up getting scheduled to a different node.
logger := klog.FromContext(ctx)
logger = klog.LoggerWithName(logger, "FilterWithNominatedPods")
ctx = klog.NewContext(ctx, logger)
for i := 0; i < 2; i++ {
stateToUse := state
nodeInfoToUse := info
if i == 0 {
var err error
podsAdded, stateToUse, nodeInfoToUse, err = addGENominatedPods(ctx, f, pod, state, info)
if err != nil {
return fwk.AsStatus(err)
}
} else if !podsAdded || !status.IsSuccess() {
break
}
status = f.RunFilterPlugins(ctx, stateToUse, pod, nodeInfoToUse)
if !status.IsSuccess() && !status.IsRejected() {
return status
}
}
return status
}
代码路径:`kubernetes/pkg/scheduler/framework/runtime/framework.go
func (f *frameworkImpl) RunFilterPlugins(
ctx context.Context,
state fwk.CycleState,
pod *v1.Pod,
nodeInfo fwk.NodeInfo,
) *fwk.Status {
logger := klog.FromContext(ctx)
verboseLogs := logger.V(4).Enabled()
if verboseLogs {
logger = klog.LoggerWithName(logger, "Filter")
}
// 遍历所有插件进行filter判断
for _, pl := range f.filterPlugins {
if state.GetSkipFilterPlugins().Has(pl.Name()) {
continue
}
ctx := ctx
if verboseLogs {
logger := klog.LoggerWithName(logger, pl.Name())
ctx = klog.NewContext(ctx, logger)
}
if status := f.runFilterPlugin(ctx, pl, state, pod, nodeInfo); !status.IsSuccess() {
if !status.IsRejected() {
// Filter plugins are not supposed to return any status other than
// Success or Unschedulable.
status = fwk.AsStatus(fmt.Errorf("running %q filter plugin: %w", pl.Name(), status.AsError()))
}
status.SetPlugin(pl.Name())
return status
}
}
return nil
}
func (f *frameworkImpl) runFilterPlugin(ctx context.Context, pl framework.FilterPlugin, state fwk.CycleState, pod *v1.Pod, nodeInfo fwk.NodeInfo) *fwk.Status {
if !state.ShouldRecordPluginMetrics() {
return pl.Filter(ctx, state, pod, nodeInfo)
}
startTime := time.Now()
// 对nodeInfo进行Filter判断
status := pl.Filter(ctx, state, pod, nodeInfo)
f.metricsRecorder.ObservePluginDurationAsync(metrics.Filter, pl.Name(), status.Code().String(), metrics.SinceInSeconds(startTime))
return status
}
由前面可知,pod调度成功后scheduler就向 API Server 发送一个 Binding 对象,修改 Pod 的 spec.nodeName,任务完成。
📝 总结与展望
调度器最大的特点是“只动嘴不动手” :它只负责在 Pod 对象上写一个 nodeName 的值。至于容器怎么拉起来、网络怎么通,它完全不管,那是 Kubelet 的事。Kubernetes scheduler的调度机制和openstack的实现方式很相似,都是基于插件filter以及打分机制筛选合适的node,从而调度出主机。
📚 参考资料
https://cloud.tencent.com/developer/article/2450522

开源鸿蒙跨平台开发社区汇聚开发者与厂商,共建“一次开发,多端部署”的开源生态,致力于降低跨端开发门槛,推动万物智联创新。
更多推荐



 5
5 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)