运维打铁: Kubernetes 集群管理与故障排除
Kubernetes 集群管理和故障排除是运维工作中的重要任务。通过深入理解 Kubernetes 的架构组件和核心概念,掌握集群部署、节点管理和资源管理的方法,以及学会使用故障排查工具和最佳实践,可以有效地管理和维护 Kubernetes 集群,确保集群的稳定运行。同时,不断学习和实践,积累经验,才能在面对复杂的故障时迅速定位和解决问题。
·
文章目录
思维导图
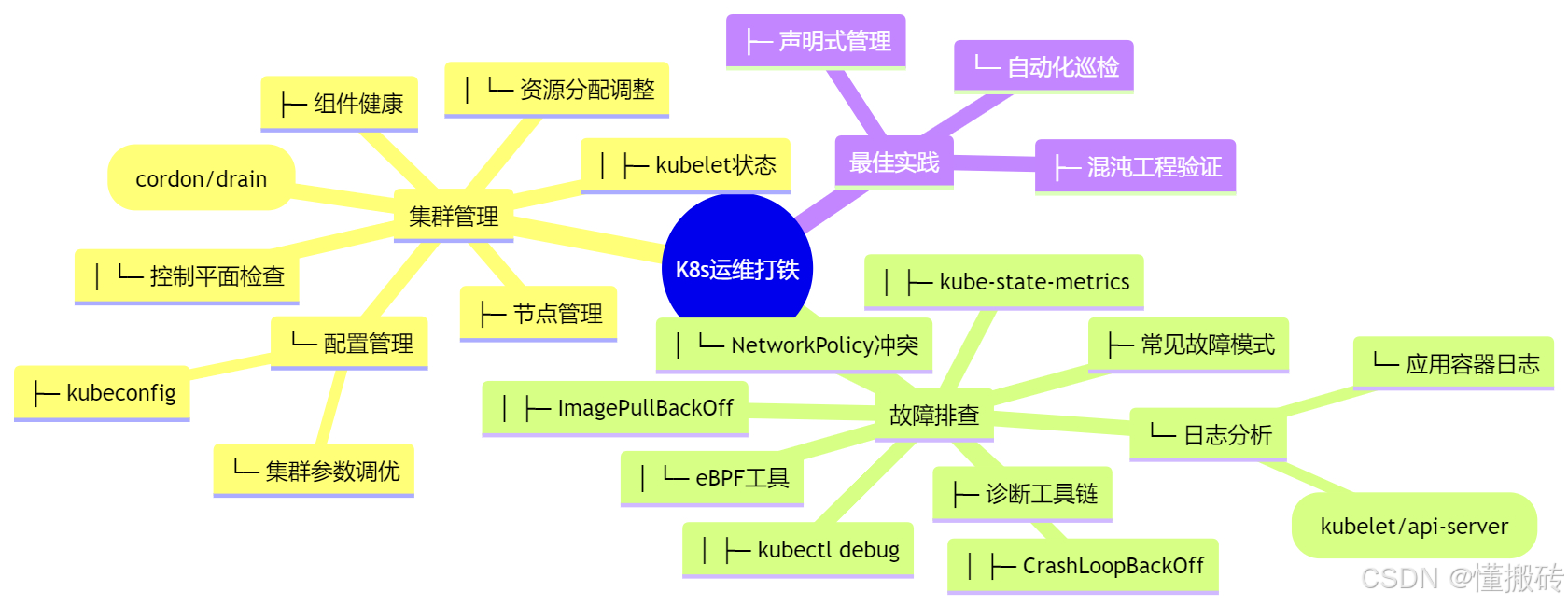
中心主题
运维打铁: Kubernetes 集群管理与故障排除
一级分支
- Kubernetes 集群基础
- 架构组件
- 核心概念
- 集群管理
- 集群部署
- 节点管理
- 资源管理
- 故障排除
- 常见故障类型
- 故障排查方法
- 最佳实践
- 监控与日志
- 自动化运维
正文内容
一、Kubernetes 集群基础
1. 架构组件
Kubernetes 集群主要由控制平面组件(如 API Server、Controller Manager、Scheduler 等)和工作节点组件(如 kubelet、kube-proxy 等)组成。
- API Server:作为 Kubernetes 集群的核心,提供了 RESTful API 接口,用于与其他组件进行通信。
- Controller Manager:负责管理集群中的各种控制器,如节点控制器、副本控制器等,确保集群状态符合预期。
- Scheduler:根据节点资源情况和调度策略,将 Pod 调度到合适的节点上。
- Kubelet:运行在每个工作节点上,负责管理节点上的 Pod 生命周期。
- Kube-proxy:实现了集群内部的网络代理和负载均衡。
2. 核心概念
- Pod:Kubernetes 中最小的可部署单元,一个 Pod 可以包含一个或多个容器。
- Deployment:用于管理 Pod 的副本数量和滚动更新。
- Service:为一组 Pod 提供统一的访问入口,实现负载均衡。
二、集群管理
1. 集群部署
使用 kubeadm 工具可以快速部署一个 Kubernetes 集群。以下是一个简单的部署示例:
# 在主节点上初始化集群
kubeadm init --pod-network-cidr=10.244.0.0/16
# 配置 kubectl
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
# 安装网络插件(以 Flannel 为例)
kubectl apply -f https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
# 在工作节点上加入集群
kubeadm join <master-ip>:<master-port> --token <token> --discovery-token-ca-cert-hash <hash>
2. 节点管理
- 添加节点:使用
kubeadm join命令将新节点加入集群。 - 删除节点:首先将节点标记为不可调度,然后删除节点上的 Pod,最后从集群中移除节点。
# 标记节点为不可调度
kubectl cordon <node-name>
# 驱逐节点上的 Pod
kubectl drain <node-name> --ignore-daemonsets
# 从集群中移除节点
kubectl delete node <node-name>
3. 资源管理
- 创建 Deployment:
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80
使用 kubectl apply -f deployment.yaml 命令创建 Deployment。
- 创建 Service:
apiVersion: v1
kind: Service
metadata:
name: nginx-service
spec:
selector:
app: nginx
ports:
- protocol: TCP
port: 80
targetPort: 80
type: LoadBalancer
使用 kubectl apply -f service.yaml 命令创建 Service。
三、故障排除
1. 常见故障类型
- Pod 无法启动:可能是镜像拉取失败、资源不足等原因导致。
- 网络问题:Pod 之间无法通信、Service 无法访问等。
- 节点故障:节点不可用、磁盘空间不足等。
2. 故障排查方法
- 查看 Pod 状态:使用
kubectl get pods命令查看 Pod 的状态。 - 查看 Pod 日志:使用
kubectl logs <pod-name>命令查看 Pod 的日志。 - 查看节点状态:使用
kubectl get nodes命令查看节点的状态。 - 使用
kubectl describe命令:可以获取更详细的资源信息,如kubectl describe pod <pod-name>。
四、最佳实践
1. 监控与日志
- Prometheus 和 Grafana:用于监控 Kubernetes 集群的性能指标,如 CPU、内存使用情况等。
- ELK Stack:用于收集和分析集群中的日志信息。
2. 自动化运维
- GitOps:通过 Git 仓库来管理 Kubernetes 集群的配置,实现自动化部署和更新。
- Helm:用于管理 Kubernetes 应用的包,简化应用的部署和管理。
总结
Kubernetes 集群管理和故障排除是运维工作中的重要任务。通过深入理解 Kubernetes 的架构组件和核心概念,掌握集群部署、节点管理和资源管理的方法,以及学会使用故障排查工具和最佳实践,可以有效地管理和维护 Kubernetes 集群,确保集群的稳定运行。同时,不断学习和实践,积累经验,才能在面对复杂的故障时迅速定位和解决问题。

开源鸿蒙跨平台开发社区汇聚开发者与厂商,共建“一次开发,多端部署”的开源生态,致力于降低跨端开发门槛,推动万物智联创新。
更多推荐
 16
16 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)