当FPGA遇上NVMe舰队:一次硬件加速的存储狂欢
基于NVMEOF和RNIC实现RDMA上NVME存储扩展fpga实现,通过RoCE连接多个SSD终端。 包含: nvmof和rnic的ip源代码, 有参考设计工程, 上位机软件,计算机驱动,
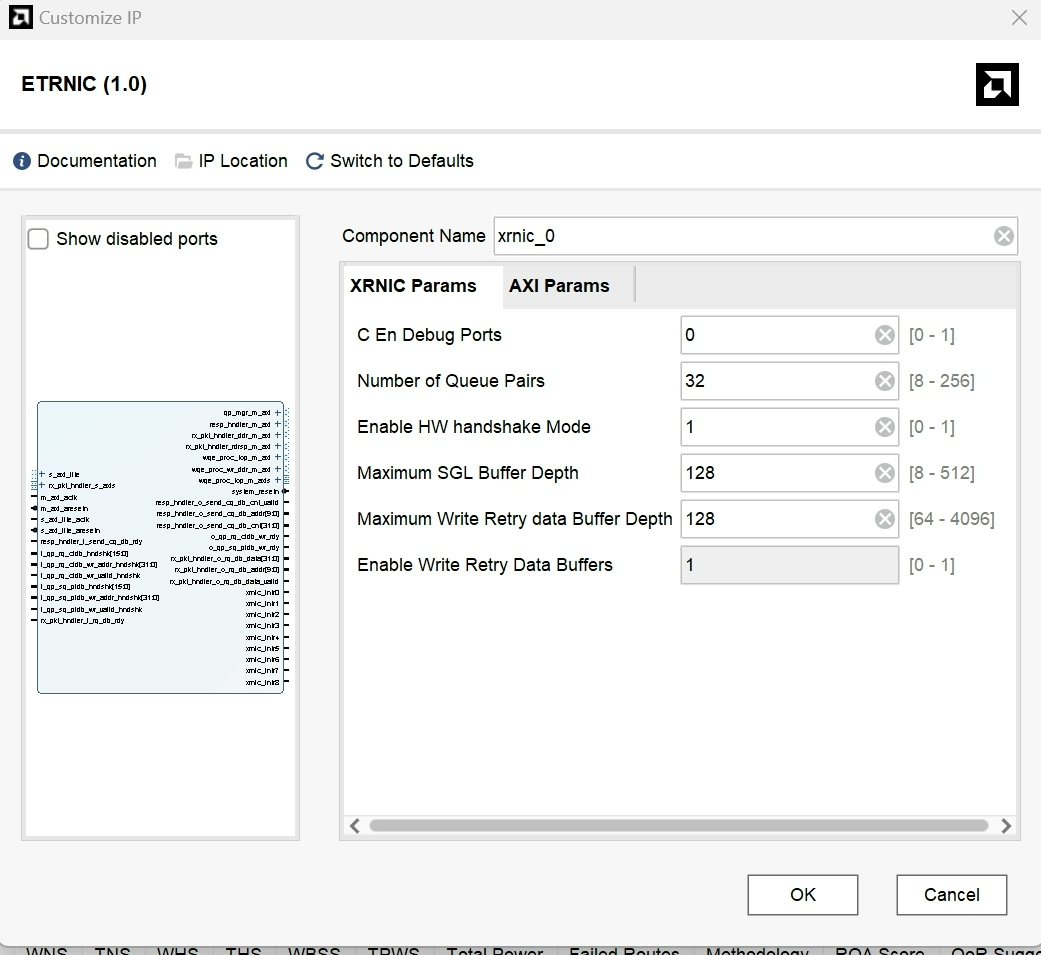
凌晨三点的实验室里,调试器的绿灯第三次熄灭时,我终于在Xilinx Vivado的波形图里逮到了那个调皮的跨时钟域bug。这个基于NVMe-oF的FPGA存储扩展方案,正在用RoCE协议把八块PCIe SSD拧成一股4800MB/s的数据洪流。
从协议栈到硬件实现的奇幻漂流
NVMe-oF协议栈在FPGA上的落地,本质上是把存储命令装进RDMA的数据包。我们的核心武器是三个IP核:NVMe控制器、RoCEv2协议栈、以及自定义的DMA引擎。这好比在FPGA内部搭建了一条直通SSD的高速公路:
// 精简版NVMe SQ处理模块
always @(posedge clk) begin
if (cmd_valid && !sq_full) begin
sq_buffer[sq_head] <= {lba, opcode, data_ptr};
sq_head <= (sq_head == SQ_DEPTH-1) ? 0 : sq_head + 1;
// 触发DMA引擎搬运命令数据
dma_start <= 1'b1;
dma_src_addr <= data_ptr;
end
// 状态机处理省略...
end这段RTL代码像交通指挥员,把来自网络的NVMe命令塞进Submission Queue。注意那个精妙的sq_head指针回绕——这是防止队列溢出的小魔法,当指针触底时瞬间弹回起点,像极了玩超级玛丽时的水管工跳跃。
FPGA上的IP核舞蹈
Xilinxxdma_ip核和我们的自定义RoCE模块跳着精密的双人舞。下面的代码片段展示了如何用AXI-Stream接口粘合这些IP:
// RoCE数据包封装流水线
always_comb begin
roce_tx.tdata = {bth_header, nvme_payload};
roce_tx.tkeep = 'hFFFF_FFFF_FFFF_FFFF; // 全数据有效
roce_tx.tlast = (pkt_counter == TOTAL_SEGMENTS);
end这里的数据打包操作就像俄罗斯方块高手,把BTH头(Base Transport Header)和NVMe负载严丝合缝地拼接。tkeep信号的处理尤其有趣——它像超市的货架标签,告诉下游哪些"货架格子"里装着真数据。
驱动层的黑暗艺术
Linux内核驱动里藏着一个会变形的ioctl接口,这是用户态直达FPGA的密道:
// 自定义ioctl命令处理
static long device_ioctl(struct file *filp, unsigned int cmd, unsigned long arg) {
struct dma_cfg cfg;
copy_from_user(&cfg, (void __user *)arg, sizeof(cfg));
// 配置DMA引擎
iowrite32(cfg.src_addr, fpga_base + DMA_SRC_REG);
iowrite32(cfg.length, fpga_base + DMA_LEN_REG);
wake_up_interruptible(&dma_queue);
return 0;
}这个ioctl处理函数就像古灵阁的妖精,把用户空间的数据地址和长度悄悄塞给FPGA的DMA引擎。注意那个wakeupinterruptible调用——这是叫醒沉睡的DMA线程的银哨。
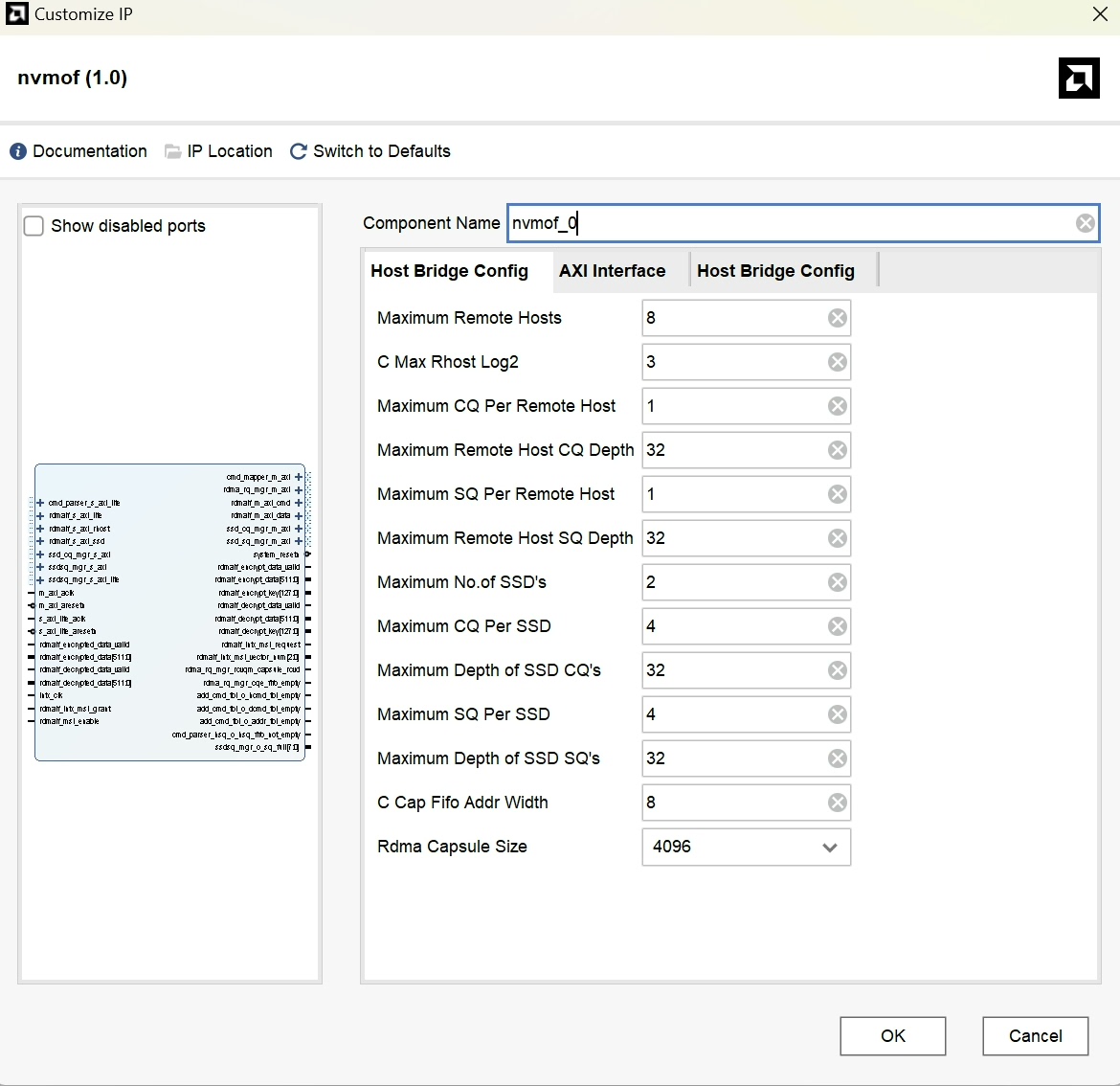
基于NVMEOF和RNIC实现RDMA上NVME存储扩展fpga实现,通过RoCE连接多个SSD终端。 包含: nvmof和rnic的ip源代码, 有参考设计工程, 上位机软件,计算机驱动,
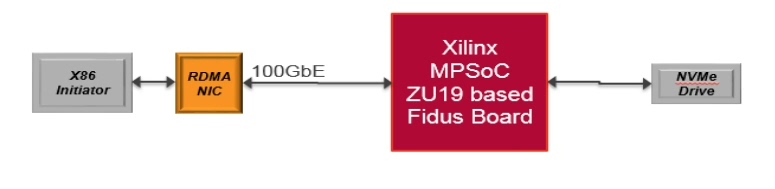
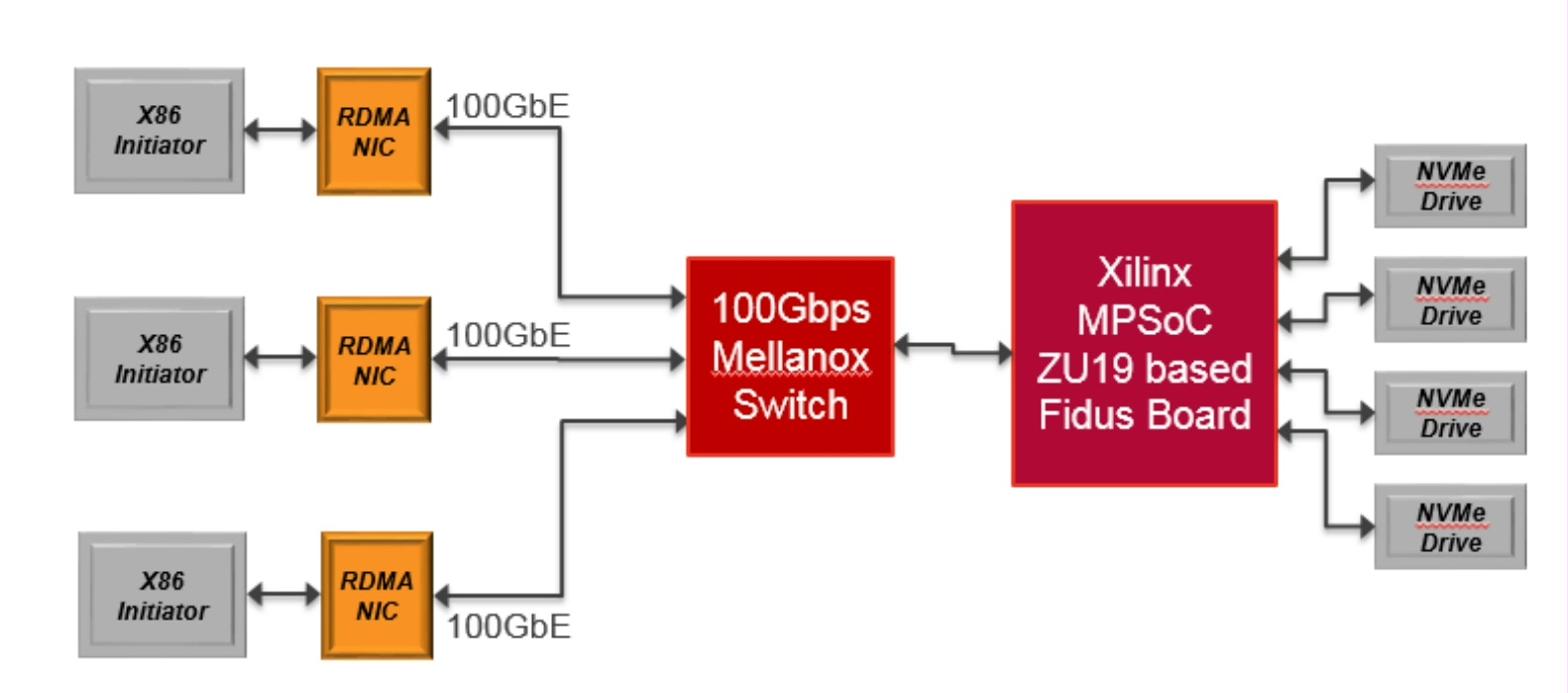
当第一个NVMe-oF读命令穿透RoCE抵达SSD阵列时,示波器上的眼图突然变得清澈。八块SSD的LBA空间通过我们的FPGA网关拼接成连续地址,就像用乐高积木搭出了长江大桥。这个方案最终在3U机箱里实现了23微秒的端到端延迟,比软件方案快了7倍——这大概就是硬件加速的魔法吧。


开源鸿蒙跨平台开发社区汇聚开发者与厂商,共建“一次开发,多端部署”的开源生态,致力于降低跨端开发门槛,推动万物智联创新。
更多推荐

 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)