Delving Into Instance Modeling for Weakly Supervised Video Anomaly Detection
弱监督视频异常检测(Weakly-Supervised Video Anomaly Detection, WS-VAD)旨在从稀疏的视频级标签中识别细粒度的异常事件。近年来,由于其在灾害预警、公共安全等领域的广泛应用,该任务受到越来越多的关注。现有研究通常将WS-VAD建模为多实例学习(Multi-Instance Learning, MIL)问题。然而,这些方法忽视了实例构建过程,仅采用统一时间
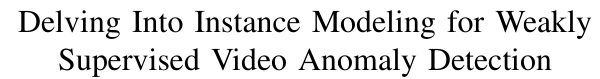
TCSVT(CCF-B)
https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=10908237
摘要
弱监督视频异常检测(Weakly-Supervised Video Anomaly Detection, WS-VAD)旨在从稀疏的视频级标签中识别细粒度的异常事件。近年来,由于其在灾害预警、公共安全等领域的广泛应用,该任务受到越来越多的关注。现有研究通常将WS-VAD建模为多实例学习(Multi-Instance Learning, MIL)问题。然而,这些方法忽视了实例构建过程,仅采用统一时间池化(Uniform Temporal Pooling, UTP)操作来生成训练实例,从而导致严重的异常污染(anomaly contamination)与异常稀释(anomaly dilution)问题。
本文强调实例建模过程的重要性,并提出了两个简单而有效的模块:动态片段合并(Dynamic Segment Merging, DSM)模块和检索增强的异常恢复(Retrieval-Augmented Anomaly Restoration, RA2^22R)模块,分别从片段级和特征级应对上述问题。我们在多种先进的WS-VAD模型中集成所提方法,并在具有挑战性的数据集(如UCF-Crime和XD-Violence)上进行了全面实验。结果表明,所提方法能够持续提升模型性能,并在多个基准上达到新的最先进水平(state-of-the-art)。
关键词——视频异常检测,多实例学习,动态合并。
I. INTRODUCTION
视频异常检测(Video Anomaly Detection, VAD)旨在检测给定视频中的异常帧,由于其在监控、公共安全等多个领域的重要作用,近年来在工业界和学术界均引起了广泛关注[1]–[7]。早期的研究主要采用全监督方法[8],[9],这类方法依赖于详尽的帧级异常标注,虽能实现较高的检测精度,但由于标注成本极高,其实际应用往往受限。相比之下,无监督方法[10]–[13]仅使用正常视频作为训练样本,在推理阶段将偏离正常模式的数据识别为异常,从而避免了对异常标签的依赖。然而,完全收集无异常的正常视频在实际中往往难以实现,更不用说模型在缺乏异常数据的情况下容易产生误报。近年来,弱监督方法[3],[5],[14]–[20]作为一种更优的替代方案逐渐兴起。这类方法仅利用稀疏的视频级标签(video-level labels)来识别异常事件,大幅减少了标注需求,并对视频资源的约束更少,因而相比以往方法更具实际可行性。
尽管弱监督视频异常检测(Weakly-Supervised Video Anomaly Detection, WS-VAD)方法具有诸多优势,但从稀疏的视频级标注中沿时间维度学习识别细粒度异常仍然是一个极具挑战性的问题。大多数现有的WS-VAD工作[3],[5],[14]–[20]通常将此类弱监督问题建模为多实例学习(Multi-Instance Learning, MIL)[14]框架。如图1(a)所示,这些基于MIL的方法通常将视频均匀划分为等长时间片段(例如,每视频划分为32个片段[3],[14],[19],[20]),用作正负训练实例。每个片段包含固定数量的更细粒度的snippet(例如,平均每视频包含数百个snippet),这些snippet在特征空间中被聚合为一个统一的表示,作为损失计算的最小单元。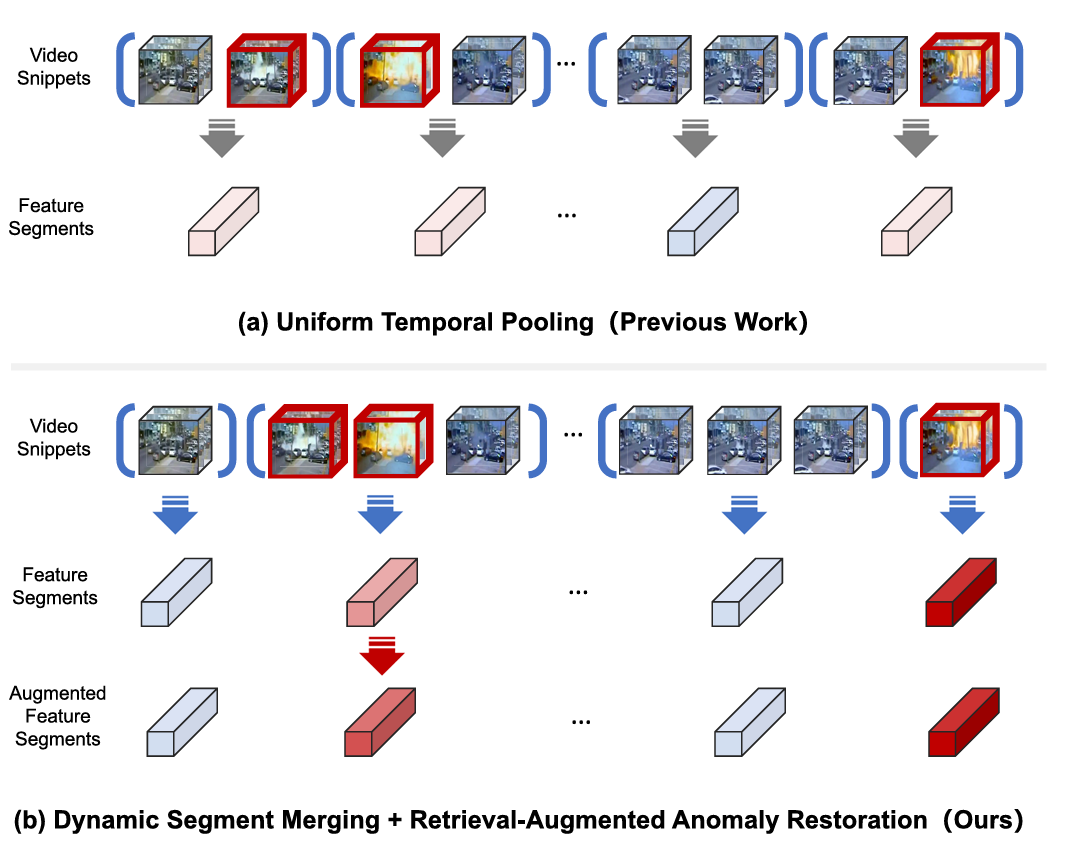
图1展示了包含爆炸事件的异常视频的实例建模过程。(a) 基于统一时间池化(Uniform Temporal Pooling, UTP)的实例建模方式,其中异常信息遭受严重的稀释(dilution)现象;(b) 我们提出的动态片段合并(Dynamic Segment Merging, DSM)与检索增强的异常恢复(Retrieval-Augmented Anomaly Restoration,RA2^22R)方法,能够更好地保留异常信息。
从上述内容可以看出,此类实例建模过程涉及两种时间维度上的操作:片段级划分(segment-level partition)和特征级池化(feature-level pooling)。我们推测,这两种操作都可能对多实例学习(MIL)的效能产生显著影响,然而在以往的研究中却未被充分重视。具体而言,片段级划分的目标是在不同片段之间精确区分异常与正常内容,以确保训练实例内部的特征一致性。然而,现有方法普遍采用统一时间池化(Uniform Temporal Pooling, UTP)[14]来实现这一划分,不可避免地导致了以下问题:
(1)片段级异常污染(segment-level anomaly contamination)——即同一片段中正常内容与异常内容混合,使得异常信号被正常内容“污染”。另一方面,特征级池化旨在将多个 snippet 的特征聚合为一个统一的片段表示,以减少计算冗余和训练噪声。但这种操作同样会引发:
(2)特征级异常稀释(feature-level anomaly dilution)——特别是当异常特征因均匀划分而与大量正常特征混合时,其异常性在聚合过程中被显著削弱。如图2所示,在近期的大规模视频异常检测(VAD)数据集(例如 UCF-Crime[14]和 XD-Violence[21])中,超过一半的异常视频所含异常帧的比例低于20%。这一现象进一步加剧了上述异常稀释问题。
本文为应对上述问题,提出了一种新颖的弱监督视频异常检测(WS-VAD)训练范式,该范式由两个专门设计的模块组成:动态片段合并(Dynamic Segment Merging, DSM)和检索增强的异常恢复(Retrieval-Augmented Anomaly Restoration, RA2^22R)。
具体而言,DSM模块利用累积梯度指导训练过程中正常片段的动态合并,同时保留异常片段,从而有效减轻片段间的异常污染(anomaly contamination)问题。我们进一步提出RA2^22R模块,通过从一个细粒度的异常记忆库(anomaly memory bank)中检索并恢复信息,来增强已被稀释的异常特征;该记忆库存储了那些尚未被严重稀释的特征。简而言之,本文的主要贡献可概括如下:
- 据我们所知,这是首个系统性探讨MIL框架下时间维度上异常污染与稀释问题的工作,而这些问题在以往的弱监督视频异常检测方法中被长期忽视;
- 提出了两个针对性模块:DSM用于缓解片段级异常污染,RA2^22R用于缓解特征级异常稀释;
- 所提出的DSM与RA2^22R模块可无缝集成到现有多种基于MIL的WS-VAD方法中(如[3],[14],[18],[20],[22],[23]),并在多个主流VAD数据集(如UCF-Crime[14]、XD-Violence[21]等)上持续提升性能,取得新的最先进(state-of-the-art)结果。
II. RELATED WORK
A. Video Anomaly Detection
视频异常检测(Video Anomaly Detection, VAD)的研究可归纳为三大类:全监督(fully-supervised)[8],[9]、无监督(unsupervised)[4],[10]–[13],[24],[26]–[35]以及弱监督(weakly-supervised)方法[3],[5],[14]–[20],[36],[37]。
-
全监督 VAD[8],[9]利用帧级标注(甚至包含异常事件的精确边界框)来训练模型,虽然性能优越,但依赖大量人工标注,成本高昂。
-
无监督方法仅使用正常视频进行训练,在推理阶段将偏离正常模式的样本判别为异常。例如:
- 基于重建的方法[10]–[13]采用自编码器(autoencoder)将正常样本编码至潜在空间,将重建误差较大的样本视为异常;
- 基于距离的方法[26],[28]–[30]则通过高斯混合模型(Gaussian Mixture Models)或一类支持向量机(one-class SVMs)构建决策边界,将偏离正常分布的数据筛选为异常。
然而,由于训练集中完全不含异常样本,这类方法在面对边界模糊的正常行为时容易产生误报(false alarms)。
-
弱监督 VAD[3],[5],[14],[15]则在利用异常数据训练模型的同时,大幅减轻标注负担。这类方法通常将任务建模为多实例学习(Multi-Instance Learning, MIL),仅需视频级标签(video-level annotations)即可训练模型,并在实际应用中展现出优异的性能。
B. Weakly Supervised Video Anomaly Detection
弱监督视频异常检测(Weakly Supervised Video Anomaly Detection, WS-VAD)近年来引起了广泛关注[3],[5],[14]–[20],[23],[38],[39],大多数方法将该任务建模为多实例学习(Multiple Instance Learning, MIL)问题。
除了标准的MIL损失函数[14]外,研究者们还提出了多种正则化技术以提升性能,例如:
- Tian 等人[3]提出了鲁棒时序特征幅值学习(Robust Temporal Feature Magnitude, RTFM),通过扩大正常与异常特征之间的幅值间隔来增强判别能力;
- Chen 等人[20]设计了幅值对比式的“一瞥-聚焦”网络(Magnitude-Contrastive Glance-and-Focus Network),以强化特征幅值的区分性;
- Zhou 等人[18]提出不确定性调控的双记忆单元(Uncertainty-Regulated Dual Memory Units, UR-DMU)模型,分别学习正常与异常特征的原型(prototypes),从而提升对异常事件的判别能力;
- Lv 等人[40]构建了无偏多实例学习(Unbiased MIL, UMIL)框架,以缓解传统MIL在VAD中因正负样本不平衡导致的偏差问题,有效减少误报并提升性能;
- Fan 等人[36]引入了一种异常注意力机制,首先生成片段级(snippet-level)的异常注意力图,再将其与原始异常分数融合,输入到多分支监督模块中;
- Wu 等人[23]提出了一种新方法,直接利用冻结的CLIP模型(Contrastive Language–Image Pretraining),无需任何额外的预训练或微调,即可实现弱监督VAD;
- Yang 等人[39]则构建了一个伪标签生成与自训练框架,利用CLIP模型的语言-视觉知识,将视频事件描述文本与对应视频帧对齐,从而生成高质量的伪标签用于训练。
这些工作共同推动了WS-VAD在仅依赖视频级标签条件下的性能边界,而本文进一步指出,尽管上述方法在学习目标和网络结构上不断优化,但其实例建模过程(尤其是统一时间池化)仍存在异常污染与异常稀释问题,亟需改进。
为了减少冗余并促进模型训练,现有的弱监督视频异常检测(VAD)方法[3],[14],[16],[18],[20],[25]通常采用一种预处理步骤:将每个视频划分为固定数量的片段,并对每个片段内的特征进行平均池化,以用于异常检测。然而,在处理长时长视频时,每个片段可能包含大量snippet(短时视频单元),而当异常事件持续时间较短时,这种池化操作往往会稀释异常snippet的信息。为缓解这一问题,Feng 等人[5]设计了一种稀疏连续采样策略,而Lv 等人[40]则采用更细粒度、持续时间更短的片段进行建模。与上述方法不同,我们提出了一种基于梯度驱动的动态合并策略:根据训练过程中snippet的梯度信息,动态地将不同数量的snippet合并为片段,从而在保留异常信息的同时有效减轻异常特征的稀释问题。
C. Memory Mechanism
近年来,利用外部记忆库(memory banks)的方法已在多项研究中得到探索[10],[41]–[45]。例如,一些对比学习方法[46],[47]使用记忆库存储实例的原型(prototypes),以支持对比优化;而记忆增强的Transformer则被用于视频识别[48]和视频超分辨率[49]任务中,以捕捉长距离时空依赖关系。在视频异常检测领域,Park 等人[10]构建了记忆增强型自编码器,通过记忆库存储正常模式的多样性,同时抑制模型对异常样本的重建能力;Zhou 等人[18]则在弱监督视频异常检测中引入记忆增强模块,用于学习正常与异常两类原型,从而提升模型对异常事件的判别能力。本文不同于上述工作,我们利用记忆库存储对异常检测有贡献的snippet(即梯度幅值较高、未被严重稀释的片段特征),以便在动态合并过程中更好地召回这些有价值的细粒度信息,从而支持后续的异常特征恢复(通过RA2^22R模块)。
III. METHODOLOGY
A. Problem Formulation
我们首先对弱监督视频异常检测(Weakly-Supervised Video Anomaly Detection, WS-VAD)进行简要回顾。在该任务中,训练集 V\mathcal{V}V 包含时长各异的视频,从数十秒到数千分钟不等。每段训练视频均带有二值标签 y∈{0,1}y \in \{0,1\}y∈{0,1},分别表示正常或异常。
如图4所示,我们以第 kkk 段训练视频为例说明整体流程: 首先,将该视频划分为 LkL_kLk 个非重叠的snippet(片段),每个snippet由固定数量的连续帧组成(例如16帧); 为获得视频的高层语义表示,所有snippet被输入一个冻结的特征编码器(如 I3D[50]或 C3D[51]),以提取其 DDD 维特征向量 x∈RD\mathbf{x} \in \mathbb{R}^Dx∈RD; 记第 kkk 个视频的特征序列为 X={xi}i=1Lk\mathbf{X} = \{\mathbf{x}_i\}_{i=1}^{L_k}X={xi}i=1Lk,其中 xi\mathbf{x}_ixi 表示第 iii 个snippet的特征。
WS-VAD 的目标是学习一个模型 fff,使其能根据预测的异常分数 f(x)f(\mathbf{x})f(x) 判断输入snippet是否为异常。
该优化过程包含两个关键步骤:
- 实例建模(Instance Modeling)
- 多实例学习(Multi-Instance Learning, MIL)
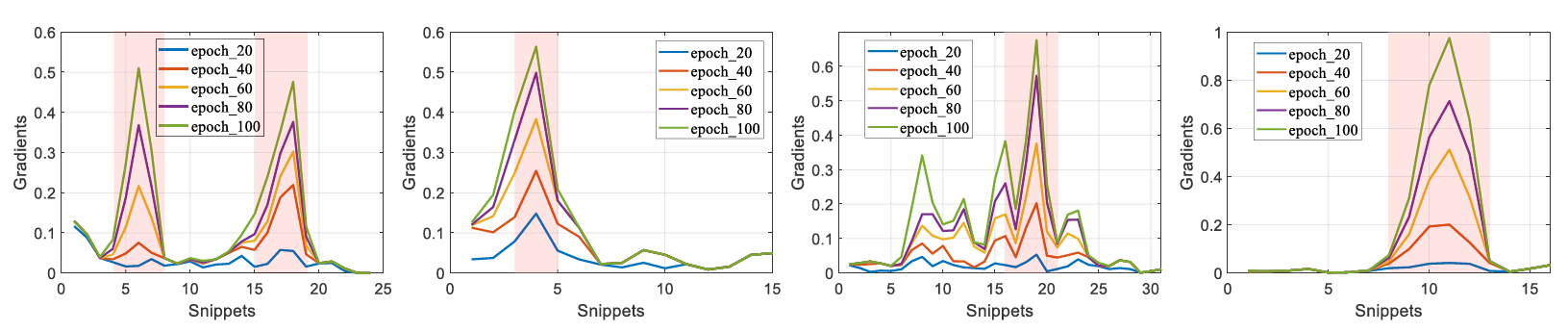
图3展示了在ShanghaiTech[24]训练集上,采用多实例学习(MIL)损失训练视频异常检测(VAD)模型[14]过程中,各snippet累积梯度幅值的变化情况。其中,粉色区域表示异常snippet的真值(ground truth),可以看出,异常snippet在训练过程中倾向于累积更高的梯度幅值,验证了本文利用梯度信息指导动态片段合并(DSM)的合理性。
图4展示了基于多实例学习(MIL)的弱监督视频异常检测(WS-VAD)训练流程。 上半部分描绘了典型的训练流程; 下半部分详细展示了所提出的动态片段合并(Dynamic Segment Merging, DSM)与检索增强的异常恢复(Retrieval-Augmented Anomaly Restoration, RA2^22R)模块的具体实现方式。 该方法可无缝集成到大多数基于MIL的WS-VAD方法中,以增强其实例建模阶段(instance modeling stage)的异常信息保留能力。
- 步骤1:实例建模(Instance Modeling)
遵循以往文献,我们将若干连续的 snippet(例如每个snippet包含16帧)组合为一个 segment(片段)。为了更好地处理未修剪(untrimmed)的长视频并加速训练过程,每段视频提取出的特征会被合并为 NfinalN_{\text{final}}Nfinal 个片段。例如,先前的工作[3],[14],[16],[18]采用统一时间池化(Uniform Temporal Pooling, UTP)策略:首先将视频划分为 LkL_kLk 个非重叠的 snippet,然后通过平均特征池化(average feature pooling)将其合并为 Nfinal=32N_{\text{final}} = 32Nfinal=32 个片段。需要注意的是,实例建模步骤默认仅在训练阶段进行。 - 步骤2:多实例学习(Multi-Instance Learning, MIL)
现有方法将弱监督视频异常检测(WS-VAD)建模为多实例学习问题。具体而言,对每段视频,取其所有 snippet 预测异常分数中的 top-kkk 个,并对其求平均,作为该视频的预测标签 y^\hat{y}y^。随后,模型通过最小化以下二元交叉熵损失(binary cross-entropy loss)进行优化:
L=−ylog(y^)+(1−y)log(1−y^),(1) \mathcal{L} = -y \log(\hat{y}) + (1 - y) \log(1 - \hat{y}), \tag{1} L=−ylog(y^)+(1−y)log(1−y^),(1)
其中 y∈{0,1}y \in \{0, 1\}y∈{0,1} 为视频级真实标签(0 表示正常,1 表示异常),y^∈(0,1)\hat{y} \in (0, 1)y^∈(0,1) 为模型预测的视频级异常概率。
在本文中,我们聚焦于实例建模(instance modeling)这一关键步骤,旨在尽可能完整地保留异常信息。我们指出,统一时间池化(Uniform Temporal Pooling, UTP)操作会引发以下两个未被充分重视的问题:
- 片段级异常污染(segment-level anomaly contamination):现有方法在时间维度上采用均匀划分策略,导致异常片段与正常片段混合于同一训练实例中,破坏了实例内部的语义一致性;
- 特征级异常稀释(feature-level anomaly dilution):平均池化操作将多个 snippet 特征融合为单一片段表示,尤其当异常 snippet 占比较小时,其异常信号在聚合过程中被显著稀释。
- 上述问题严重阻碍了高质量异常实例的构建,进而损害后续多实例学习(MIL)阶段的优化效果。
为应对这些挑战,我们提出了两个专门设计的模块:
- 动态片段合并(Dynamic Segment Merging, DSM):通过梯度驱动的自适应合并策略,在保留异常片段的同时合并正常片段,缓解片段级污染;
- 检索增强的异常恢复(Retrieval-Augmented Anomaly Restoration, RA2^22R):利用细粒度异常记忆库存储未被稀释的高价值 snippet 特征,并在池化后通过检索机制恢复异常信息,减轻特征级稀释。
这两个模块协同作用,显著增强了训练实例的异常表征能力,为后续 MIL 学习提供了更可靠的基础。
B. Dynamic Segment Merging
我们首先引入动态片段合并(Dynamic Segment Merging, DSM)模块,以更有效地生成时序训练实例。为了减少冗余并提升训练效率,以往方法[3],[5],[10],[14],[24],[27],[52]通常采用统一时间池化(Uniform Temporal Pooling, UTP)操作,为每段视频均匀地生成固定数量的片段。然而,对于长时间未修剪(long-duration untrimmed)视频而言,其中稀疏分布的异常事件可能会与大量正常 snippet 在同一个片段内被平均池化,从而导致片段级异常污染(segment-level anomaly contamination)[40]。
我们观察到,在基于多实例学习(MIL)的框架中[14],随着训练轮次(epoch)的推进,异常 snippet 倾向于累积更高的梯度幅值,如图3所示。受此现象启发,我们提出了动态片段合并(Dynamic Segment Merging, DSM)方案:根据 snippet 的梯度信息,自适应地将不同数量的 snippet 合并为片段,如图4左下部分所示。
考虑到一段视频可能包含过多的 snippet 而难以直接处理,我们首先采用均匀合并策略(uniform merging technique)将原始 snippet 合并为 NinitN_{\text{init}}Ninit 个初始片段(满足 Lk≫Ninit≫NfinalL_k \gg N_{\text{init}} \gg N_{\text{final}}Lk≫Ninit≫Nfinal)。随后,出于计算效率的考虑,我们对这些初始片段(而非原始 snippet)执行动态合并(dynamic merging)操作。
最后,我们可以将动态片段合并(DSM)过程形式化为一个优化问题。具体而言,每个初始片段 x^i\hat{\mathbf{x}}_ix^i 被赋予一个代价 cic_ici,该代价基于多个训练轮次中累积的梯度计算得到,即:
ci=∑j=1EGrad∥∂Lj∂x^i∥2,(2) c_i = \sum_{j=1}^{E_{\text{Grad}}} \left\| \frac{\partial \mathcal{L}_j}{\partial \hat{\mathbf{x}}_i} \right\|_2, \tag{2} ci=j=1∑EGrad
∂x^i∂Lj
2,(2)
其中:Lj\mathcal{L}_jLj 表示 VAD 模型在第 jjj 个训练轮次(epoch)的训练损失;EGradE_{\text{Grad}}EGrad 是用于梯度累积的轮次数;∥⋅∥2\|\cdot\|_2∥⋅∥2 表示 ℓ2\ell_2ℓ2 范数(即梯度向量的欧几里得范数)。该代价 cic_ici 反映了片段 x^i\hat{\mathbf{x}}_ix^i 在训练过程中对损失函数的敏感程度——异常片段通常具有更高的梯度幅值,因此其 cic_ici 更大。DSM 利用这一性质,优先保留高代价(可能为异常)的片段,而合并低代价(可能为正常)的相邻片段。
我们定义一次合并操作的总合并代价为两个相邻片段合并代价之和。随后,动态合并通过优化以下问题,将初始的 NinitN_{\text{init}}Ninit 个片段划分为最终的 NfinalN_{\text{final}}Nfinal 个片段:
O∗←argminO⊂OF(Ninit,Nfinal∣O),(3) \mathcal{O}^* \leftarrow \arg\min_{\mathcal{O} \subset \mathbb{O}} F(N_{\text{init}}, N_{\text{final}} \mid \mathcal{O}), \tag{3} O∗←argO⊂OminF(Ninit,Nfinal∣O),(3)
其中,NinitN_{\text{init}}Ninit 表示合并前的片段数量,NfinalN_{\text{final}}Nfinal 表示合并后的最终片段数量,且满足 Nfinal≪NinitN_{\text{final}} \ll N_{\text{init}}Nfinal≪Ninit。O\mathcal{O}O 表示一组合并操作,而 F(Ninit,Nfinal∣O)F(N_{\text{init}}, N_{\text{final}} \mid \mathcal{O})F(Ninit,Nfinal∣O) 是在给定操作集 O\mathcal{O}O 下,将 NinitN_{\text{init}}Ninit 个片段合并为 NfinalN_{\text{final}}Nfinal 个片段的代价函数。
我们通过以下两种方法对式 (3) 进行优化:
- 动态规划(Dynamic Programming, DP):我们首先采用动态规划(DP)[53]来求解该优化问题,以获得更高的合并精度。在忽略式 (3) 中的合并操作集合 O\mathcal{O}O 后,该代价函数可递归地表示如下:
F(s,t,j)={minm∈[s,t){F(s,m,j)+F(m+1,t,j)}+∑i=stci,j=1minm∈[s,t){F(s,m,j−1)+F(m+1,t,1)},1<j<l0,j=l(4) F(s, t, j) = \begin{cases} \displaystyle \min_{m \in [s, t)} \Big\{ F(s, m, j) + F(m+1, t, j) \Big\} + \sum_{i=s}^{t} c_i, & j = 1 \\ \displaystyle \min_{m \in [s, t)} \Big\{ F(s, m, j - 1) + F(m+1, t, 1) \Big\}, & 1 < j < l \\ 0, & j = l \end{cases} \tag{4} F(s,t,j)=⎩ ⎨ ⎧m∈[s,t)min{F(s,m,j)+F(m+1,t,j)}+i=s∑tci,m∈[s,t)min{F(s,m,j−1)+F(m+1,t,1)},0,j=11<j<lj=l(4)
其中:F(s,t,j)F(s, t, j)F(s,t,j) 表示将从第 sss 个到第 ttt 个初始片段合并为 jjj 个最终片段的最小总代价;mmm 是在区间 [s,t)[s, t)[s,t) 内枚举的分割点;l=t−s+1l = t - s + 1l=t−s+1 表示当前考虑的片段序列长度;cic_ici 是第 iii 个初始片段的合并代价(由式 (2) 定义);当 j=1j = 1j=1 时,整个区间被合并为一个片段,总代价为子问题代价之和加上该区间所有片段的原始代价之和;当 j=lj = lj=l 时,不进行任何合并,代价为 0。该动态规划算法的总体时间复杂度约为 O(n4)O(n^4)O(n4),其中 nnn 为初始片段数量 NinitN_{\text{init}}Ninit。 - 贪心策略(Greedy Strategy):我们进一步研究了一种次优的贪心算法,其时间复杂度为 O(n2)O(n^2)O(n2)。其核心思想非常直接:在每一轮合并中,选择相邻两个片段中合并代价之和最小的一对进行合并。具体而言,需与第 i+1i+1i+1 个片段合并的第 iii 个片段的索引由下式确定:
i∗←argmini(c~i+c~i+1),(5) i^* \leftarrow \arg\min_{i} \left( \tilde{c}_i + \tilde{c}_{i+1} \right), \tag{5} i∗←argimin(c~i+c~i+1),(5)
其中:
- c~i\tilde{c}_ic~i 表示第 iii 个片段当前的合并代价;
- 初始时,c~i=ci\tilde{c}_i = c_ic~i=ci(即由式 (2) 计算得到的梯度累积代价);
- 每次合并后,新生成片段的合并代价可更新为其组成片段代价的加权和或重新计算(依具体实现而定)。
该贪心策略虽然无法保证全局最优,但显著降低了计算复杂度,适用于对效率要求较高的场景。
C.Retrieval-Augmented Anomaly Restoration
实例建模中的另一项时间维度操作是片段级特征聚合(segment-level feature aggregation)。以往工作[3],[5],[10],[14],[24],[27],[52]在采用统一时间池化(UTP)时,直接将其实现为平均池化(average pooling)过程,这不可避免地在特征空间中引入了片段级的异常稀释(anomaly dilution)。
尽管我们提出的动态片段合并(DSM)模块致力于保留异常片段并避免其被正常片段污染,但它无法保证异常与正常片段的完全分离,因而仍可能导致异常稀释。这一问题在异常片段数量超过合并后的最终片段数(即 NfinalN_{\text{final}}Nfinal)时尤为突出——此时多个异常片段必须被合并到同一个最终片段中,或与正常片段混合,导致其异常特征在平均池化过程中被显著削弱。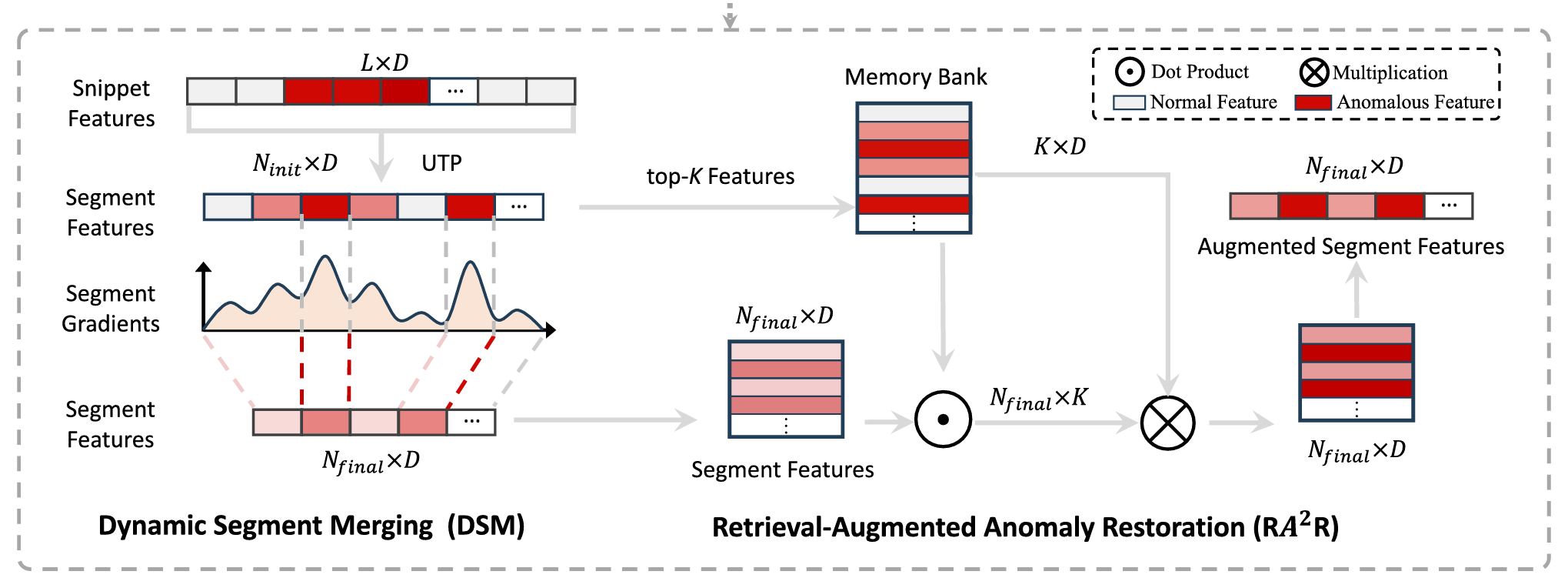
为解决这一问题,我们提出了如图4所示的检索增强的异常恢复(Retrieval-Augmented Anomaly Restoration, RA2^22R)模块。该模块在片段合并前将未被稀释的特征保存至一个记忆库(memory bank)中,并在需要时通过检索机制利用这些特征来恢复已被稀释的异常特征。
-
记忆库(Memory Bank):对于每段训练视频,我们构建一个记忆库,用于存储在合并操作前梯度幅值排名前 KKK 的片段特征,从而保留未被稀释的细粒度异常信息。记该记忆库为 M∈RK×D\mathbf{M} \in \mathbb{R}^{K \times D}M∈RK×D,其中第 kkk 行 Mk\mathbf{M}_kMk(k=1,…,Kk = 1, \dots, Kk=1,…,K)表示一个保存的片段特征向量,维度为 DDD。
-
检索与恢复(Retrieval and Restoration):为了从记忆库 M∈RK×D\mathbf{M} \in \mathbb{R}^{K \times D}M∈RK×D 中检索与查询片段特征 x^j∈RD\hat{\mathbf{x}}_j \in \mathbb{R}^Dx^j∈RD 相关的细粒度特征,我们计算其与每个记忆项的点积相似度,并通过 softmax 归一化,得到注意力权重:
wj,k=exp(Mk⋅x^j)∑k′=1Kexp(Mk′⋅x^j),(6) w_{j,k} = \frac{\exp(\mathbf{M}_k \cdot \hat{\mathbf{x}}_j)}{\sum_{k'=1}^{K} \exp(\mathbf{M}_{k'} \cdot \hat{\mathbf{x}}_j)}, \tag{6} wj,k=∑k′=1Kexp(Mk′⋅x^j)exp(Mk⋅x^j),(6)
其中 ⋅\cdot⋅ 表示向量点积。
我们设定一个相似度阈值 TwT_wTw,仅保留满足 wj,k>Tww_{j,k} > T_wwj,k>Tw 的记忆特征用于后续恢复。随后,对这些筛选出的记忆特征进行加权求和,得到增强后的特征 x~j\tilde{\mathbf{x}}_jx~j:
x~j=∑k′=1Kwj,k′Mk′,(7) \tilde{\mathbf{x}}_j = \sum_{k'=1}^{K} w_{j,k'} \mathbf{M}_{k'}, \tag{7} x~j=k′=1∑Kwj,k′Mk′,(7)
该增强特征 x~j\tilde{\mathbf{x}}_jx~j 将替代原始已被稀释的特征 x^j\hat{\mathbf{x}}_jx^j,用于后续的多实例学习(MIL)训练阶段。通过这种方式,RA2^22R 模块有效恢复了因平均池化而丢失的异常信息。
D.Training Pipeline
图4展示了整体训练流程。我们在前 EGradE_{\text{Grad}}EGrad 个训练轮次中累积梯度,并在第 EGradE_{\text{Grad}}EGrad 轮时执行动态合并操作,将初始的 NinitN_{\text{init}}Ninit 个片段合并为最终的 NfinalN_{\text{final}}Nfinal 个片段。值得注意的是,DSM(动态片段合并)和RA2^22R(检索增强的异常恢复)模块仅在训练阶段使用,因此在推理阶段不会引入任何额外计算开销。
我们的训练过程如算法1所示,可无缝集成到现有的弱监督视频异常检测(WS-VAD)方法中[3],[14],[18],[20],[22]。具体而言,在第 EGradE_{\text{Grad}}EGrad 轮训练时,我们依次执行两个与所提出模块对应的步骤:
- 首先,使用DSM模块动态合并正常片段,同时保留异常片段,从而获得合并后的特征 X~i\widetilde{\mathbf{X}}_iX i,其中正常片段数量显著减少;
- 随后,应用RA2^22R模块,对每个合并后的片段特征 x^j\hat{\mathbf{x}}_jx^j 检索记忆库中的细粒度异常信息,并生成增强后的特征 x~j\tilde{\mathbf{x}}_jx~j。
上述两个操作可迭代执行,直至每段视频被合并为 NfinalN_{\text{final}}Nfinal 个片段,且每个片段均完成增强。总训练轮数 ETE_TET 可根据不同WS-VAD方法灵活调整。
IV. EXPERIMENTS
B. Implementation Details
所提出的模型使用PyTorch实现,并采用Taichi库[64]加速动态片段合并的计算。超参数设置如下:初始片段数量NinitN_{\text{init}}Ninit设为512,用于梯度累积的训练轮数EGradE_{\text{Grad}}EGrad设为15。每个视频的特征库大小设置为40,检索阈值TwT_wTw设为0.6。我们使用这些基线模型[3]官方发布的代码和I3D特征来评估所提出的方法,并继承了它们的超参数,包括学习率、训练轮数和所采用的优化器。
C. Results on Benchmarks
我们选取了六种最先进的视频异常检测(VAD)模型[3],[14],[18],[20],[22],[23]来集成我们提出的方法。在实例建模阶段,我们将这些模型中原有的统一时间池化(uniform temporal pooling)替换为所提出的动态片段合并(dynamic segment merging),并对基线模型不做其他修改。具体而言,最终片段数量NfinalN_{\text{final}}Nfinal的设置遵循各工作的默认训练配置:对于文献[3],[14],[20],[22]中的模型设为32;对于文献[18]中的模型设为200;对于文献[23]中的模型则设为256。由于部分模型在某些基准数据集上缺乏评估结果(例如RTFM[3]未在TAD数据集上进行评估),我们使用其官方实现代码在相应数据集上进行训练,并报告实验结果。
根据表I的主要结果,所有集成了我们方法(动态片段合并DSM和检索增强的异常恢复RA2^22R)的模型均获得了性能的持续提升,这充分证明了所提出方法的通用性和有效性。在DSM和RA2^22R的辅助下,大多数模型实现了显著的性能改进。值得注意的是,由我们方法增强的VadCLIP[23]在全部四个基准数据集上均达到了新的最先进(state-of-the-art, SoTA)性能水平。此外,集成了我们方法的基础MIL[14]模型在XD-Violence数据集上获得了78.55%的平均精度(AP),甚至超过了近期工作NG-MIL[58]。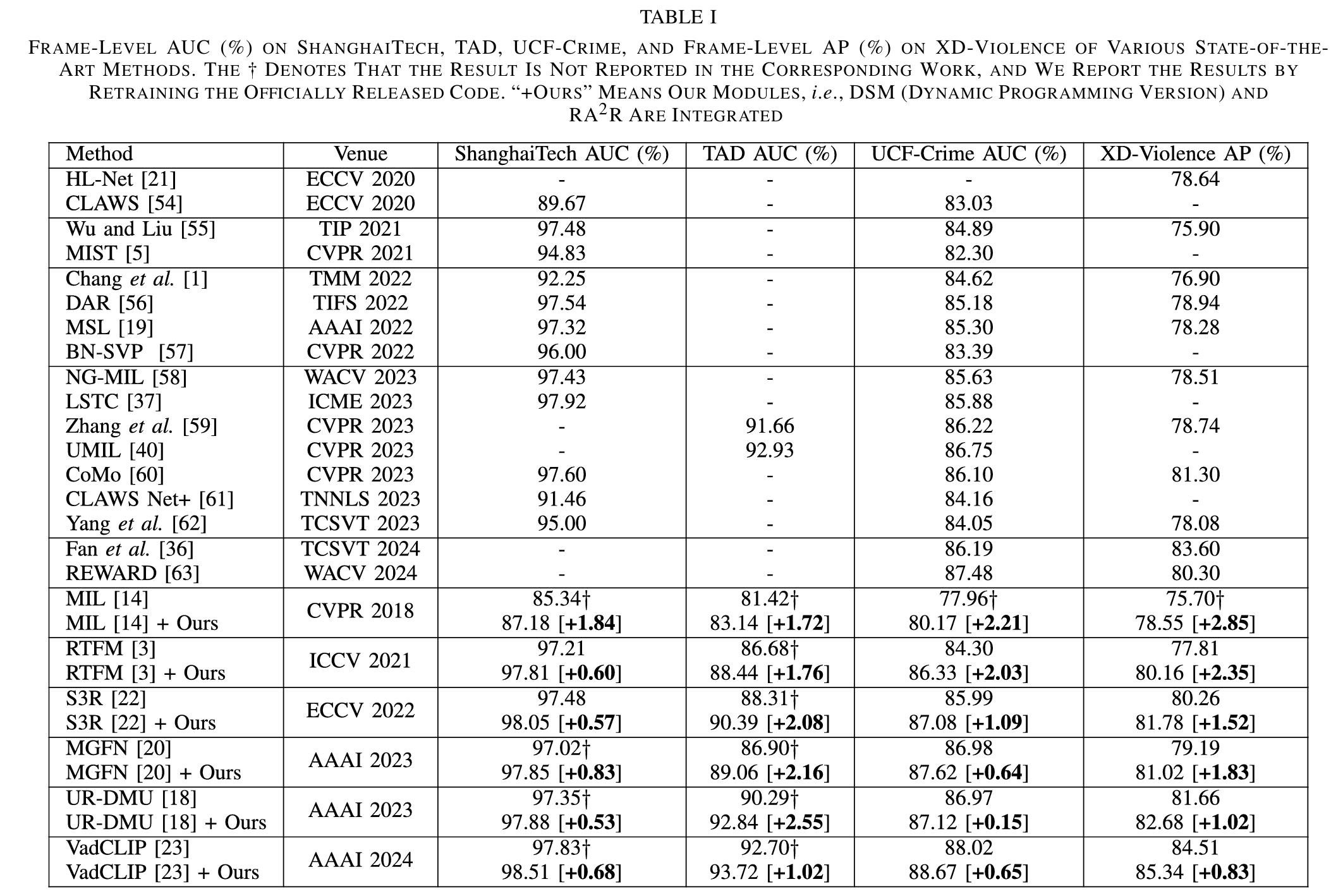
V. CONCLUSION
本文指出现有弱监督视频异常检测(WS-VAD)方法在时间维度上普遍面临两个关键局限性:异常污染(anomaly contamination)与异常稀释(anomaly dilution)。为解决这些问题,我们提出了一种新颖的训练范式,包含两个核心模块:动态片段合并(Dynamic Segment Merging, DSM)和检索增强的异常恢复(Retrieval-Augmented Anomaly Restoration, RA2^22R)。
- DSM模块通过在训练过程中动态合并正常片段、同时保留异常片段,有效避免了视频级异常被正常内容污染的问题;
- RA2^22R模块则通过在合并前从记忆库中检索并恢复细粒度的异常特征,为片段注入高价值的异常信息,从而缓解特征级的异常稀释。
大量实验表明,所提出的DSM与RA2^22R模块可无缝集成到现有主流WS-VAD方法中,并显著提升其性能。例如,在XD-Violence数据集上,某些方法的平均精度(AP)从0.83%提升至2.85%。这充分验证了本方法在增强实例建模阶段有效性与通用性。

开源鸿蒙跨平台开发社区汇聚开发者与厂商,共建“一次开发,多端部署”的开源生态,致力于降低跨端开发门槛,推动万物智联创新。
更多推荐
 9
9 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)